
Как восстановить изображение по нескольким пикселям
Обновлено: 02.07.2024
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Белим С. В., Селиверстов С. А.
В статье предложен алгоритм восстановления поврежденных пикселей в изображениях со статическими пропусками. Предложенный алгоритм основывается на методе анализа иерархий теории поддержки принятия решений. Выбор цвета поврежденного пикселя происходит на основе ближайших соседей и соседей, следующих за ближайшими. Анализируются три параметра, присущих каждому ближайшему соседу. Во-первых, количество соседей имеющих тот же цвет, что и данный ближайший сосед. Во-вторых, отклонение цвета данного пикселя от среднего значения его соседей. В-третьих, отличие пикселей, расположенных по разную сторону от испорченного. На основе этих трех критериев для каждого ближайшего соседа поврежденного пикселя определяется весовой коэффициент. В качестве цвета поврежденного пикселя выбирается цвет его соседа, имеющего наибольший вес. Проведен компьютерный эксперимент по определению эффективности предложенного метода. Исследована зависимость эффективности предложенного алгоритма от величины повреждения изображения
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Белим С. В., Селиверстов С. А.
Алгоритм поиска поврежденных пикселей и удаления импульсного шума на изображениях с использованием метода ассоциативных правил Фильтрация импульсного шума на изображении на основе алгоритма выявления сообществ на графах Алгоритм сегментации изображения с помощью искусственной нейронной сети без использования других изображений Алгоритм сегментации изображений, основанный на поиске сообществ на графах Математическая модель восстановления поврежденного растрового изображения i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.Текст научной работы на тему «Алгоритм восстановления поврежденных пикселей на зашумленных изображениях на основе метода анализа иерархий»
Наука и Образование
МГТУ им. Н.Э. Баумана
Сетевое научное издание
Наука и Образование. МГТУ им. Н.Э. Баумана. Электрон. журн. 2014. № 11. С. 521-534.
Представлена в редакцию: 11.11.2014
© МГТУ им. Н.Э. Баумана
Алгоритм восстановления поврежденных пикселей на зашумленных изображениях на основе метода анализа иерархий
Белим С. В.1*, Селиверстов С. А.
1Омский государственный университет им. Ф.М. Достоевского,
В статье предложен алгоритм восстановления поврежденных пикселей в изображениях со статическими пропусками. Предложенный алгоритм основывается на методе анализа иерархий теории поддержки принятия решений. Выбор цвета поврежденного пикселя происходит на основе ближайших соседей и соседей, следующих за ближайшими. Анализируются три параметра, присущих каждому ближайшему соседу. Во-первых, количество соседей имеющих тот же цвет, что и данный ближайший сосед. Во-вторых, отклонение цвета данного пикселя от среднего значения его соседей. В-третьих, отличие пикселей, расположенных по разную сторону от испорченного. На основе этих трех критериев для каждого ближайшего соседа поврежденного пикселя определяется весовой коэффициент. В качестве цвета поврежденного пикселя выбирается цвет его соседа, имеющего наибольший вес. Проведен компьютерный эксперимент по определению эффективности предложенного метода. Исследована зависимость эффективности предложенного алгоритма от величины повреждения изображения.
Ключевые слова: восстановление данных, зашумленные изображения, импульсный шум
Проблема восстановления поврежденных пикселей тесно связана с задачей устранения шумов на изображениях. Испорченные пиксели могут возникать на изображениях по нескольким причинам. Во-первых, при хранении графических объектах может происходить повреждение носителей изображения. Во-вторых, поврежденные пиксели могут возникать по причине недостатков средств получения изображений: порча или засвечивание матрицы. В-третьих, повреждения могут быть следствием импульсного шума в каналах передачи данных.
Проблема устранения шумов как правило решается двумя методами. Первый связан с построением фильтров подавления шумов. Данный метод дает хорошие визуальные результаты, однако приводит к размытию изображения, так как преобразовываются не только поврежденные пиксели, но и все изображение целиком. Второй подход основывается на выделении поврежденных пикселей и их восстановлении. Этот подход
обладает меньшим быстродействием по сравнению с фильтрами, но обладает значительно большим потенциалом. При поиске и восстановлении поврежденных пикселей преобразуются только испорченные части изображения, тогда как не поврежденные остаются неизменными. Следует указать, что все методы поиска импульсных шумов характеризуются ненулевым процентом ложных срабатываний, но он составляет не более 10%, что значительно лучше, чем все изображение.
Проблема восстановления поврежденных пикселей с известным расположением, как правило, решается с помощью алгоритмов восстановления таблиц с пропусками. Самым очевидным по построению и быстрым по скорости работы является метод восстановления по среднему значению ближайших соседей [7]. Данный подход может приводить к появлению больших областей одного цвета, делающих изображение неестественным. Несколько лучшие результаты могут быть получены с помощью построения регрессионной модели [8]. Достаточно хорошие результаты демонстрирует интерполяция сплайнами [9], основывающаяся на предположении о возможности представления изображения в виде непрерывной функции с последующей дискретизацией. Наиболее правдоподобные результаты восстановления могут быть получены при использовании факторного анализа [10], однако основанные на нем алгоритмы работают достаточно медленно, вследствие высокой трудоемкости. Применение кластерного анализа [11] позволяет детектировать случаи не допускающие восстановления. Для восстановления поврежденных пикселей могут быть использованы алгоритмы обработки экспериментальных данных, представленных в виде таблиц с пропусками семейства 2БТ [12,13], которые основаны на гипотезе об избыточности табличных данных. Также для восстановления пропущенных пикселей могут применятся искусственные нейронные сети [14,15]. В работе [16] предложен метод восстановления поврежденных пикселей с помощью построения ассоциативных правил.
Целью данной статьи ставиться разработка алгоритма восстановления поврежденных пикселей на основе метода анализа иерархий при принятии решений. Метод анализа иерархий [17] применяется в теории поддержки принятия решений при необходимости выбора одной из нескольких альтернатив. В традиционном подходе
использование этого метода ограничено необходимостью получения экспертных оценок, которые носят субъективный характер. Однако, как показано в работах [18,19], формирование экспертных оценок на основе объективных показателей решаемой задачи без привлечения экспертов позволяет получать хорошие результаты.
1. Постановка задачи
Пусть исходное изображение A задано в виде матрицы цветов Aij. В случае цветного изображения необходимо рассматривать три матрицы, согласно модели RGB. Будем считать, что диапазон значений элементов матрицы имеет вид [0,m]. Пусть поврежденное изображение задается матрицей цветов Bj. Будем считать, что поврежденные пиксели заданы матрицей R. Каждый элемент матрицы повреждений Rj с вероятностью p отличен от нуля и с вероятностью 1-p нулевой. Значение ненулевых элементов матрицы повреждений также задается случайным образом в интервале [0,m]. Значение матрицы поврежденного изображения задается соотношением:
Задачей ставится построение матрицы Cj максимально близкой к матрице Aj по известным матрицам Rj и Bj.
Для сравнения близости матриц изображений использовалась метрика Минковского [20], согласно которой расстояние между изображениями находится по формуле:
d(A, C) = max £ -|A« - C« |.
где Amn и Cmn - значения цветов пикселов изображения A и С, N - количество пикселов.
Результаты работы алгоритма будем оценивать величиной относительного улучшения изображения, вычисленное на основе расстояния от восстановленного изображения до исходного d(orig_fig,r_fig) и расстояния от испорченного изображения до исходного d(origJig, p_Jig):
5 = d(orig_ fig,p_ fig) -d(orig_ fig,r _ fig) 10Q% d (orig _ fig, P _ fig ) .
2. Алгоритм принятия решения о цвете поврежденного пикселя
Будем рассматривать пиксели, окружающие поврежденный. Причем будем анализировать как ближайшие пиксели, так и следующие за ним, как показано на рисунке 1.
d10 с6 с7 с8 d11
d12 d13 d14 d15 d16
Рисунок 1. Анализируемая карта пикселей.
Цвет поврежденного пикселя с будем выбирать из восьми цветов ближайших соседей. Применим для этого метод анализа иерархий, используемый для принятия решений [21]. Введем три критерия, характеризующие ближайших соседей с1, . с8, которые позволят выбрать только один из них.
К1 - отличие цвета данного пикселя от среднего цвета ближайших соседей, без учета поврежденного пикселя. Так, например, для пикселя с5 необходимо проанализировать пиксели с2, с3, с7, с8, ё9, ё11. Данный критерий позволяет выявлять резкие перепады цвета.
К2 - количество соседних пикселей, имеющих тот же цвет. Рассматривается тот же набор соседей, что и в предыдущем критерии. Данный критерий позволяет выявлять области сплошной заливки.
К3 - отличие цвета данного пикселя от пикселя, расположенного с другой стороны от поврежденного. Например, для пикселя с4 противоположным будет с5, а для с6 противоположный - с3. Данный критерий позволяет выявлять случаи, когда поврежденный пиксель находится на границе двух цветовых областей.
Будем считать, что все эти критерии равнозначны и, как следствие, имеют одинаковые весовые коэффициенты. Тогда иерархическое дерево, представленное на рисунке 2, будет двухуровневым.
Определим весовые коэффициенты каждого из решений в рамках одного критерия. Для этого введем характеристики каждого из пикселей и построим матрицу парных сравнений из отношения соответствующих характеристик.
Для критерия К1 будем характеризовать каждый пиксель с^ величиной:
где Ас1 -среднее значение цвета пикселей, окружающих с1. т - максимальное значение цвета в палитре. Например, для пикселя с2 получим значение:
Многие пользователи в интернете для скрытия конфиденциальной информации на видеороликах и фотографиях пользуются пикселизацией (сильное снижение разрешения). Однако теперь этот способ будет малоэффективен — в сети появился алгоритм, который восстанавливает пиксилизированный текст на изображениях.

Источник изображения: antyweb
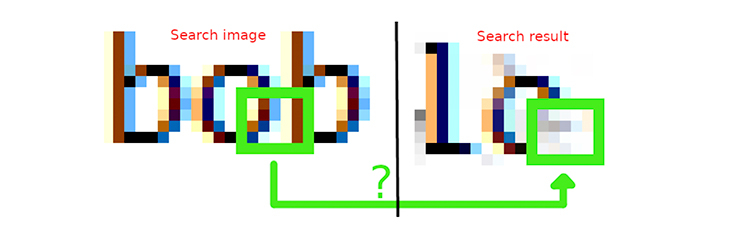
Разработчик с ником Beurtschipper опубликовал на GitHub утилиту дешифровки изображений под названием Depix, написанную на Python.
Источник изображения: linkedin
Фильтр пикселизации работает следующим образом: изображение делится на блоки нужного размера, в каждом из них определяется основной цвет (среднее значение от всех оттенков блока), после чего квадрат заливается сплошным цветом. Что очень важно, одинаковые элементы даже на разных изображениях будут пикселизироваться одинаково.
Алгоритм Depix использует как раз этот принцип — в программу загружается пикселизированное изображение (пока, это работает только с текстом) и алфавит в виде Последовательности де Брёйна с теми же настройками шрифта, что и в пикселизированном фрагменте. К настройкам шрифта относится размер, цвет, сам шрифт, а также цветовая модель HSL (тон, насыщенность и светлота).

Источник изображения: GitHub
После этого алгоритм разбивает на пиксели загруженный в него алфавит и начинает искать совпадения в блоках первоначального пикселизированного изображения, чтобы найти подходящий символ.
Источник изображения: linkedin
Подбор будет завершён, только когда не останется совпадений между двумя картинками. Результат будет экспортирован в формате изображения в «output.jpg».
Для того, чтобы воспользоваться алгоритмом, необходимо скачать на компьютер Python, загрузить Depix с GitHub, сделать скриншот пикселизированного элемента, который нужно расшифровать. Сгенерировать Последовательность де Брёйна на специальном сайте и создать из неё текстовый файл с настройками шрифта, которые могут соответствовать пикселизированному изображению. После этого сделать скриншот текстового документа с Последовательностью де Брёйна и запустить в Python соответствующий код.
В своей статье, где разработчик подробно разобрал работу алгоритма, он отмечает, что ранее подобных утилит в свободном доступе не существовало. А для безопасности стоит полностью удалять конфиденциальную информацию с изображений и видеороликов, так как алгоритмы не стоят на месте.

Восстановить фотографию по нескольким пикселям — пока не как в кино, но уже близко. Кто и зачем пытается показать то, что скрыто, как это нельзя использовать и новый игрок на российском рынке беспилотного транспорта — об этом в программе Вести.net.
Исследователи из проекта Google Brain, который занимается разработками в области искусственного интеллекта и методов глубокого обучения, научили нейросеть улучшать изображения, додумывая фотографии разрешением всего в несколько пикселей. Возможности системы продемонстрировали на примере картинок размером 8х8 точек: нейронная сеть сформировала на их основе новые изображения размером 32х32 пикселя. При этом были добавлены детали, придающие новым фотографиям достаточно большое сходство с исходными изображениями.
Для улучшения картинки авторы использовали две нейросети, обученные на одинаковых наборах данных. Для тренировки использовались изображения из библиотек примерно с двумя сотнями тысяч фотографий лиц знаменитостей и двумя миллионами фотографий спальных комнат. При "создании" изображения одна нейросеть сравнивает образцы низкого разрешения с огромной выборкой реальных фотографий, также сжатых до размера 8х8 пикселей. И пытается найти соответствия, а когда определяет какое-то тождество, то предлагает опираться на эту похожую картинку.
Вторая нейросеть на основе данных, которые определила первая, пытается дорисовать или смоделировать детали изображения. Фактически благодаря первой нейросети вторая "понимает", что, например, несколько коричневых пикселей исходного изображения нужно превратить в волосы. Самые похожие результаты моделирования объединяются и выдают картинку более высокого разрешения. Кстати, эти добавленные пиксели исследователи между собой называют галлюцинациями.
Исходные и воссозданные фото специалисты в качестве эксперимента показали ряду добровольцев. И выяснилось, что в 10 процентах случаев испытуемые приняли сгенерированные изображения знаменитостей за настоящие фотографии. Это очень высокий показатель, потому что самый высокий — это 50 процентов, когда отличить картинки нельзя, и их выбирают случайно. Для фотографий спален этот показатель составил и вовсе 28 процентов.
Журналист издания Ars Technica уверен, что такая технология заинтересует иммиграционные службы, полицию и военные ведомства. Но важно помнить, что это не реальная фотография. Знаменитые сцены из фильмов — "увеличь и почисть эту картинку, это он!" — применить сюда нельзя. Обработанные нейросетью снимки — это фотографии, додуманные системой. Они могут помочь спецслужбам в качестве фоторобота в процессе поиска преступника или свидетеля преступления, но не будут иметь никакой юридической силы в суде.
Интересно, что на этом поле уже есть и другие разработки. Например, ученые из Корнелльского и Остинского университетов разработали алгоритм, позволяющий восстановить детали – лица людей, номера машин и домов – на фотографиях, где эта информация была намеренно скрыта. Техники "заблёривания" или "замазывания" применяют в целях сохранения приватности: таким образом скрывают, например, лица людей на сервисе Google Street View. Разработанный алгоритм практически во всех случаях распознает под "заблёренной" областью печатные и написанные от руки буквы.
С лицами чуть сложнее – компьютер может лишь приблизительно восстановить облик. Другое дело, если поиск задан по конкретному человеку – имея объект для сравнения, алгоритм может точно определить, есть ли он под "замазкой" или нет.
В ряду российских проектов, шагнувших на поле беспилотного транспорта, пополнение: волгоградская компания Volgabus построит робоавтобусы. И уже заручилась государственной поддержкой, получив грант на 200 миллионов рублей от Фонда поддержки проектов Национальной технологической инициативы.
Volgabus планирует построить несколько прототипов беспилотной системы, которые будут интегрированы в транспортную модульную платформу "Матрёшка". Судя по описанию, эта платформа представляет из себя шасси с основным набором датчиков и радаров. Она универсальна и может стать основой почти любого транспортного средства.
В частности, как сообщается в пресс-релизе, на модуль можно "всего за несколько минут" установить пассажирский салон, грузовой отсек или компоненты коммунальной техники. Заявка про "несколько минут", конечно, вызывает сомнения, но идея интересная. В компании также обещают сосредоточиться на "технологиях компьютерного зрения, способных обеспечить транспортному средству полную автономность и скорость реакции, превышающую возможности человека".
Первые тесты микроробоавтобуса на 6-12 человек провели в Сочи в прошлом году. Официальная демонстрация первого прототипа беспилотного модульного пассажирского автобуса Matrёshka состоялась на территории "Сколково" летом 2016 года. Опытный образец вмещал шесть пассажиров. Сюда же в "Сколково" тестовые робоавтобусы вернутся этой весной для дальнейших испытаний — здесь как раз обещают открыть ультрасовременную трассу для беспилотных транспортных средств.
Интересно, что первый прототип беспилотного модульного пассажирского автобуса Matrёshka компании Volgabus помог создать резидент "Сколково" — конструкторское бюро Avrora Robotics. Именно они создали первую беспилотную "Газель", которая несколько лет назад представляла Россию на европейском конкурсе роботизированной техники European Land-Robot Trial. Кроме Volgabus и Avrora Robotics, в России на специальных полигонах и безлюдных трассах, и даже на бездорожье тестируются беспилотные "КамАЗы" и тракторы от Cognitive Technologies.
Команда исследовательского проекта Google Brain разработала алгоритм, способный воссоздать изображение, генерируя его на основе разных пикселей. Об этом пишет Ars Technica.
Алгоритм работает на основе двух нейросетей, обученных на одинаковых наборах данных. В ходе исследования специалисты Google Brain использовали пикселизованные изображения низкого разрешения для создания нового изображения, схожего с оригинальным.
Для «обучения» нейросетей в Google Brain использовали изображения из библиотек CelebA (двести тысяч фотографий лиц знаменитостей ) и LSUN Bedrooms (два миллиона фотографий спален). Специалисты использовали копии картинок, уменьшенные до 32×32 пикселей (высокое разрешение) и 8×8 пикселей (низкое разрешение).
Сначала специалисты использовали нейросеть условий condition network, которая сравнивает изображение низкого разрешение с уже известными изображениями высокого разрешения. После свёрточная нейросеть (prior network) генерирует детали картинки, анализируя необходимость создания определённых черт. Например, нейросеть «понимает» что коричневые пиксели с исходной картинке на изображении высокого качества необходимо превратить в волосы.
Используя 64-цветные пиксели, система способна сгенерировать изображение разрешением 32×32, близкое к исходному снимку, утверждают в Google Brain.

Для проверки результатов Google провела опрос среди добровольцев, попросив их указать, какое из изображений в паре — реальное. В результате в 10% случаев люди приняли сгенерированные картинки за настоящие фотографии знаменитостей. В случае с фотографиями спален этот показатель составил 28%.
О планах по использованию алгоритма в действующих сервисах в Google Brain не сообщили.
Читайте также: