
Как вы понимаете принцип взаимодействия компьютеров в сети клиент сервер
Обновлено: 05.07.2024
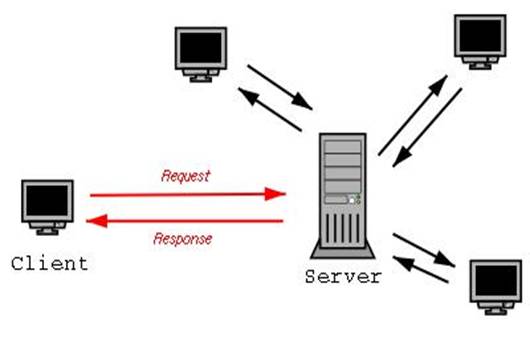
Клиент инициирует взаимодействие с сервером и посылает запрос, содержащий:
• адрес URI ( Uniform Resource Identifier , универсальный идентификатор ресурса);Ответ сервера содержит:
• строку состояния, в которую входит версия протокола и код возврата (успех или ошибка);Передача данных из форм
<title> Отправка формы </title>
<form action color:green;font-weight:bold">handler.php " method=". ">
Логин : <input type="text" name="login">< br >
Пароль : <input type="password" name="pass">< br >
После отправки данные попадают в глобальные массивы, имена которых соответствуют названию метода отправки.
- $_POST — если данные переданы методом POST;
- $_GET — если данные переданы методом GET;
- $_REQUEST — если данные были переданы любым из них.
<?php
if(isset($_POST['login']) && $_POST['login'] != '' && isset($_POST['pass']) && $_POST['pass'] != '')<
echo 'Привет ' . $_POST['login'] . '!';
echo 'Твой пароль: ' . $_POST['pass'] . '<br>';
>else<
echo 'Некорректное имя и пароль!<br>';
>
?>
GET - Запрашивает содержимое указанного ресурса.
HEAD - Аналогичен методу GET, но в ответе отсутствует тело.
POST - Передаёт пользовательские данные заданному ресурсу.
PUT - Загружает указанный ресурс на сервер.
DELETE - Удаляет указанный ресурс.
TRACE - Возвращает полученный запрос так, что клиент может увидеть, что промежуточные сервера добавляют или изменяют в запросе.
CONNECT - Для использования вместе с прокси-серверами, которые могут динамически переключаться в туннельный режим SSL.
Content-type . Этот заголовок предназначен для идентификации типа передаваемых данных. Наименования типов данных указывается в формате стандарта MIME. Это тот самый формат передачи, который используется методами GET и POST. Сервер никак не интерпретирует рассматриваемый заголовок, а просто передает его сценарию через переменную окружения. Переменная окружения CONTENT_TYPE.
Content-length . Этот заголовок содержит длину передаваемых данных в байтах при использо вании метода передачи POST.
Переменная окружения CONTENT_LENGTH.
Location . Получив этот заголовок вместе с указанным в нем URL, браузер немедленно переходит по указанному URL.
Pragma . Данный заголовок используется для различных целей, одна из которых - это запрет кэширования документа.
Server . Данный заголовок содержит название и версию программного обеспечения сервера.
Referer . Содержит URL страницы, откуда клиент пришел на нашу.
Стандарт MIME
MIME-тип задается в виде «тип/подтип». Например: text / html
Стандарт MIME определяет семь типов данных:
- 1xx: Информационный — запрос получен, продолжается обработка.
- 2xx: Успешно — действие было успешно получено, понято и обработано.
- 3xx: Перенаправление — для выполнения запроса должны быть предприняты дальнейшие действия.
- 4xx: Ошибка клиента — запрос имеет плохой синтаксис или не может быть выполнен.
- 5xx: Ошибка сервера — сервер не в состоянии выполнить допустимый запрос.
Функция — это часть программы, обозначенная определенным именем, выполняющая определенную задачу и необязательно возвращающая результат.
О модели взаимодействия клиент-сервер простыми словами. Архитектура «клиент-сервер» с примерами
Модель взаимодействия клиент-сервер. Архитектура «клиент-сервер».
Итак, небольшая аннотация к записи: сначала мы разберемся с концепцией взаимодействия клиент сервер. Затем поговорим о том зачем вообще веб-мастеру нужно понимать модель клиент-сервер. Далее мы посмотрим на архитектуру приложений, которые работают по принципу клиент-сервер и в завершении рассмотрим преимущества и недостатки данной модели.
Концепция взаимодействия клиент-сервер
Также стоит заметить, что в основе взаимодействия клиент-сервер лежит принцип того, что такое взаимодействие начинает клиент, сервер лишь отвечает клиенту и сообщает о том может ли он предоставить услугу клиенту и если может, то на каких условиях. Клиентское программное обеспечение и серверное программное обеспечение обычно установлено на разных машинах, но также они могут работать и на одном компьютере.
Данная концепция взаимодействия была разработана в первую очередь для того, чтобы разделить нагрузку между участниками процесса обмена информацией, а также для того, чтобы разделить программный код поставщика и заказчика. Ниже вы можете увидеть упрощенную схему взаимодействия клиент-сервер.
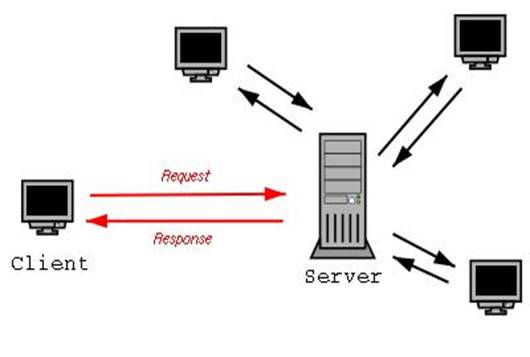
Простая схема взаимодействия клиент-сервер
Мы видим, что к одному серверу может обращаться сразу несколько клиентов (действительно, на одном сайте может находиться несколько посетителей). Также стоит заметить, что количество клиентов, которые могут одновременно взаимодействовать с сервером зависит от мощности сервера и от того, что хочет получить клиент от сервера.
Многие сетевые протоколы построены на архитектуре клиент-сервер, поэтому в их основе обычно лежат одинаковые или схожие принципы взаимодействия, а разницу мы видим лишь в деталях, которые обусловлены особенностями и спецификой области, для которой разрабатывался тот или иной сетевой протокол.
Почему веб-мастеру нужно понимать модель взаимодействия клиент-сервер
Давайте теперь ответим на вопрос: «зачем веб-мастеру или веб-разработчику понимать концепцию взаимодействия клиент-сервер?». Ответ, естественно, очевиден. Чтобы что-то делать своими руками нужно понимать, как это работает. Чтобы сделать сайт и, чтобы он правильно работал в сети Интернет или хотя бы просто работал, нам нужно понимать, как работает сеть Интернет.
Мы уже упоминали, что большая часть сетевых протоколов имеют архитектуру клиент-сервер. Например, веб-мастеру или веб-разработчику будут интересны протоколы седьмого и шестого уровня эталонной модели. Сетевым администраторам важно понимать, как происходит взаимодействие на уровнях с пятого по второй. Для инженеров связи наибольший интерес представляют протоколы с четвертого по первый уровень модели OSI.
Поэтому если вы действительно хотите быть профессионалом в сфере web, то сперва вам необходимо понимать, как происходит взаимодействии в сети (именно на седьмом уровне), а уже потом начинать изучать инструменты, которые позволят создавать сайты.
Архитектура «клиент-сервер»
Архитектура клиент-сервер определяет лишь общие принципы взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
Существует два вида архитектуры взаимодействия клиент-сервер: первый получил название двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер (иногда его называют трехуровневая архитектура или трехзвенная архитектура, но это частный случай).
Принцип работы двухуровневой архитектуры взаимодействия клиент-сервер заключается в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рисунке ниже.
Двухуровневая модель взаимодействия клиент-сервер
Здесь четко видно, что есть клиент (1-ый уровень), который позволяет человеку сделать запрос, и есть сервер, который обрабатывает запрос клиента.
Если говорить про многоуровневую архитектуру взаимодействия клиент-сервер, то в качестве примера можно привести любую современную СУБД (за исключением, наверное, библиотеки SQLite, которая в принципе не использует концепцию клиент-сервер). Суть многоуровневой архитектуры заключается в том, что запрос клиента обрабатывается сразу несколькими серверами. Такой подход позволяет значительно снизить нагрузку на сервер из-за того, что происходит распределение операций, но в то же самое время данный подход не такой надежный, как двухзвенная архитектура. На рисунке ниже вы можете увидеть пример многоуровневой архитектуры клиент-сервер.
Многоуровневая архитектура взаимодействия клиент-сервер
Типичный пример трехуровневой модели клиент-сервер. Если говорить в контексте систем управления базами данных, то первый уровень – это клиент, который позволяет нам писать различные SQL запросы к базе данных. Второй уровень – это движок СУБД, который интерпретирует запросы и реализует взаимодействие между клиентом и файловой системой, а третий уровень – это хранилище данных.
Если мы посмотрим на данную архитектуру с позиции сайта. То первый уровень можно считать браузером, с помощью которого посетитель заходит на сайт, второй уровень – это связка Apache + PHP, а третий уровень – это база данных. Если уж говорить совсем просто, то PHP больше ничего и не делает, кроме как, гоняет строки и базы данных на экран и обратно в базу данных.
Преимущества и недостатки архитектуры клиент-сервер
Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен. Если мы говорим про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать (в качестве частного случая можно привести пример: мощности сервера не всегда хватает, чтобы удовлетворит запросы клиентов, если вы хоть раз работали с биллинговыми системами, то понимаете о чем я: время ожидания ответа от сервера может быть очень большим).
В качестве заключения нам стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.

· клиент – компьютерное устройство, которое отсылает запросы серверу, касающиеся выполнения определенных задач или предоставления конкретной информации.
· сервер – компьютерное устройство, гораздо мощнее обычного ПК.
Система работает по следующему принципу:
1. Клиент отправляет запрос серверной машине.
2. Сервер принимает обращение с требованием выполнить определенное действие и выполняет поставленную задачу.
3. Программно-аппаратный комплекс отправляет клиенту результат выполненной работы, обработанного запроса.
Модель клиент-сервер предоставляет возможность разграничить поставленные задачи и работу над вычислениями между теми, кто заказывает услуги и теми, кто их поставляет.
Основные компоненты системы:
· клиент. Рабочая станция считается входной точкой конечного пользователя в данной системе. Отправляет запросы, получает ответы;
· сервер. Взаимодействует с многочисленными клиентами и решает поставленные ими задачи;
· сеть. Здесь происходит передача данных. Посредством сети можно соединить рабочие машины общими ресурсами;
· приложения. Могут обрабатывать информацию, организовывать физическое распределение данных между сервером и клиентом. Программным обеспечением оснащают серверные устройства для сбора данных, работы с ними и хранения. А также ПО устанавливают на компьютерной станции-клиенте.
О технологии клиент-сервер
Серверное устройство поддерживает многопользовательский режим и обеспечивает одновременно работу с несколькими клиентами. Конечно, машина не может решать в прямом смысле слова одновременно несколько поставленных задач, она выстраивает запросы в очередь по мере поступления, обрабатывает обращения и отправляет результаты работы. Запросы можно выстраивать в списке по приоритетности. Чем важнее запрос, тем быстрей его обрабатывают, даже, если он поступил позже.
Именно технология клиент сервер предоставляет возможность реализовать вышеуказанные многочисленные поставленные задачи. Обычно клиент – это браузер конкретного пользователя. А серверами зачастую выступают:
· наборы серверных машин (например, Denwer);
Архитектура клиент-сервер
Благодаря архитектуре клиент и сервер определены позиции взаимной связи между компьютерными машинами лишь в целом. Что же касается нюансов взаимодействия, они определены протоколами. Технология вполне прозрачно намекает на разделение в сети рабочих машин: серверы и клиенты. Рабочий контакт всегда инициирован клиентской машиной. Протокол же описывает, по каким правилам этот контакт установлен и действует.
Архитектура взаимодействия между клиентом и сервером подразделяется на два вида:
· многоуровневая. Речь идет о любой современной архитектуре СУБД. Принципиальное отличие и особенность: запросом клиента занимаются одновременно несколько серверных устройств. Операции перераспределяются, нагрузка на серверную машину снижена и оптимальная. Единственный минус: низкая надежность по сравнению с предыдущим вариантом.
Многоуровневая клиент-серверная архитектура
Обработкой данных занимаются несколько разных серверов. Благодаря такому подходу возможности серверов и клиентов используются более эффективно за счет разделения функций:
К тому же, систему можно точнее разделить на функциональные блоки для выполнения конкретной роли. Для этого между собой взаимодействуют разнообразные серверы приложений. К примеру, реально выделить сервер, необходимый для выполнения всего функционала по управлению персоналом. При этом реально сделать такую настройку, что пользователи смогут пользоваться только его общедоступным функционалом, а детали реализации серверной машины будут недоступны, так как с ней свяжут отдельную базу данных. Подобные системы легко адаптируются под веб, ведь легче организовать доступ пользователей к конкретному функционалу БД посредством html форм, чем ко всей БД.
На веб-технологию очень просто перевести многоуровневую систему. Заменяют клиентскую часть браузером спецтипа или универсального назначения. При этом дополняют веб-сервером и компактными программными модулями сервер приложений. Многоуровневая архитектура также использует менеджеры транзакций. Обмен информацией одновременно происходит между одной серверной машиной приложений и несколькими серверами БД.
· информация защищена и безопасно хранится. Так как серверная машина БД ведет базы данных, можно независимо от программ пользователя обрабатывать информацию в базе;
· повышенная стойкость к сбоям. Сохранена целостность информационных запросов, они доступны другим пользователям, если во время работы клиента случился сбой;
· масштабируемость. Архитектура адаптируется к увеличению количества пользователей. База данных также расширяется в объеме. Однако при этом не поставлена задача менять ПО. Система наращивает аппаратные средства, так происходит подстройка под меняющиеся факторы;
· повышенная защита данных от взлома и опасных атак;
· один пользователь меньше нагружает сеть, поэтому увеличивается ее пропускная способность. Можно удовлетворить запросы большего количества пользователей;
Преимущества и недостатки архитектуры клиент-сервер
Разделен код программы клиентского и серверного приложения. Это главное преимущество архитектуры. Выбрана локальная сеть. Поэтому плюсы следующие:
· к клиентским рабочим станциям выдвигают низкие запросы;
· преимущественно все вычислительные операции выполняются на серверах;
· реально повысить защиту локальной сети.
Но не все так гладко с клиент-серверной архитектурой, есть и недостатки:
· серверные машины стоят в разы дороже, чем клиентские рабочие станции;
· обслуживание серверов доверяют только квалифицированным и профессионально подготовленным специалистам;
· работа клиентских компьютерных устройств остановлена, если в локальной сети «полетело» серверное оборудование.
Важно понимать, что нет четкого разделения оборудования на клиентское и серверное. Просто архитектура к/с дает возможность перераспределить и оптимизировать загруженность и распределить функциональность между этими рабочими станциями.
Как правило компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер. ). Клиент и сервер какого-либо ресурса могут находится как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
- ввод и отображение данных (взаимодействие с пользователем);
- прикладные функции, характерные для данной предметной области;
- функции управления ресурсами (файловой системой, базой даных и т.д.)
- компонент представления данных
- прикладной компонент
- компонент управления ресурсом
Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия клиент-сервер (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя узлами):
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только "картинка", сформированная на центральном компьютере.
Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (СУБД и прикладная программма). Протокол обмена при этом представляет набор низкоуровненых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных СУБД (см. параграф 4.8), имеет очевидные недостатки - высокий сетевой трафик и отсутствие унифицированного доступа к ресурсам.
С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса "клиент-сервер". Однако, сетевой трафик остается достаточно высоким, кроме того, по прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции.
Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL-сервер. Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не SQL-запросы, а вызовы хранимых процедур). Недостаток - ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
- простейшие прикладные функции выполняются хранимыми процедурами на сервере
- более сложные реализуются на клиенте непосредственно в прикладной программе
Сейчас ряд поставщиков коммерческих СУБД объявило о планах реализации механизмов выполнения хранимых процедур с использованием языка Java. Это соответствует концепции "тонкого клиента", функцией которого остается только отображение данных (модель удаленного представления данных).
Для общения прикладной программы с монитором транзакций используется специализированный API (Application Program Interface - интерфейс прикладного программмирования), который реализуется в виде библиотеки, содержащей вызовы основных функций (установить соединение, вызвать определенный сервис и т.д.). Серверы приложений (сервисы) также создаются с помощью этого API, каждому сервису присваивается уникальное имя. Монитор транзакций, получив запрос от прикладной программы, передает ее вызов соответствующему сервису (если тот не запущен, порождается необходимый процесс), после обработки запроса сервером приложений возвращает результаты клиенту. Для взаимодействия мониторов транзакций с серверами баз данных разработан протокол XA. Наличие такого унифицированного интерфейса позволяет использовать в рамках одного приложения несколько различных СУБД.
Читайте также: