
Как выгрузить логи из kibana в файл
Обновлено: 06.07.2024
Логи — полезные инструмент для отладки и мониторинга приложений. Только просмотр текстовых логов — дело скучное и неинтересное. Поэтому изучают логи в исключительных ситуациях. Здесь на помощь приходят структурированные логи — когда записи хранятся не просто в виде текста, а в виде структурированных данных с разделением информации на отдельные поля. По таким логам можно настроить фильтры, поиск, при соблюдении определенных условий — отправлять уведомления и т.д.
Elasticsearch и Kibana
Один из вариантов хранения структурированных логов — хранение их в Elasticsearch. Преимущество этого подхода заключается в том, что для этого всё уже готово — вам не нужно допиливать код для хранения данных.
ELK — это стек из трех продуктов: Elasticsearch, Logstash и Kibana:
- Elasticsearch — хранилище данных логов, позволяет искать по большим объемам данных с приемлемой скоростью.
- Kibana — удобный веб-интерфейс к хранилищу данных.
- Logstash — агрегатор, который забирает логи с жесткого диска и отправляет их в Logstash.

Чтобы попробовать ELK можно использовать Docker-образ sebp/elk:
Подробнее о том, как запустить ELK внутри Docker можно почитать в документации.
После запуска Kibana будет доступна через порт 5601 , а Elasticsearch API — через 9200 .
Для реального проекта Elasticsearch весьма требователен к оборудванию (в частности - к RAM). Поэтому хорошим вариантом может быть использование ELK как сервиса. К счастью, таких сервисов очень много, например — раз, два, три.
Отправка в данных в Elasticsearch
Если для отправки данных используется Logstash, то всё сводится к записи логов в файл и настройки Logstash для чтения этих файлов и отправки в Elasticsearch. Альтернативным способом может быть отправка данных напрямую в Elasticsearch, минуя Logstash. Рассмотрим этот способ.
Установим в проект пакет Serilog , а заодно Serilog.Extensions.Logging и Serilog.Sinks.Elasticsearch .
Теперь необходимо добавить Serilog-логгер в DI-контейнер:
И в список логгинг-провайдеров:
Обратите внимание, что при конфигурировании ELK указана конфигурационная секция Logging:Elk . В ней мы указываем параметры фильтров, о которых я писал ранее.
Для данного примера конфигурационный файл может выглядеть так:
Теперь можно воспользоваться стандартным API для логгирования и создавать записи в в ELK:
Однако, гораздо интереснее в таком случае писать в лог структурированную информацию. Для этого немного изменим способ логгирования:
Теперь данные отправляются в ELK в структурированном виде.
Данная статья будет обзорной и не претендует на авторское решение проблем сбора, доставки, хранения и обработки логов.
Выдумывать велосипеды совершенно не нужно, когда есть отличнейший инструмент, позволяющий жонглировать логами так как нам это удобно — и это Elastic Stack. Данное решение проверено временем и стает еще лучше с каждым релизом, а так он еще и бесплатен. Если интересно — тогда добро пожаловать.
Наш стэк не уникален, все как у всех, кроме разбежности в выборе самого коллектора. Здесь выбор был между классическим и зрелым решением Elastic Stack — Logstash и более новым инструментом Fluentd.
Сейчас время сказать: “Стоп, ты же сам сказал, что выдумывать велосипеды совершенно не нужно”. Верно. Поэтому далее объясню почему мы выбрали Fluentd.
Изначально, естественно на этапе планирования, куда же без него, заглянули в будущее 🕒 и прикинули, что неплохо было бы на K8s перебираться (“а чего такого!?” — стильно, модно, молодежно 😃 ), а если так, то нужно смотреть в сторону инструмента, который используется в нем (де факто) и это — Fluentd.
Ну а пока нету K8s, но есть проекты на Docker, нужно сделать так, чтобы потом было меньше проблем.
Архитектура
Архитектурно сервис собран на одном инстансе. Состоит из клиентской части и коллектора (коллектором будем называть весь EFK стэк). Клиент пересылает, а коллектор, в свою очередь, занимается обработкой логов.
Проект был полностью собран на Docker. Деплоится это все с помощью бережно написанных манифестов Puppet. Вообще он забавно деплоит контейнеры прописывая их в Systemd как сервис, поначалу было непривычно, а потом стало даже удобно, так как за состоянием контейнера начинает следить демон Systemd.
Сам сервис выглядит вот так:
Итак, состав нашего стэка следующий:
Наглядно весь EFK стэк (коллектор) изображен на схеме.

Какие логи мы собираем:
- Логи Nginx (access и error).
- Логи с Docker контейнеров (stdout и stderr).
- Логи с Syslog, а именно ssh auth.log.
Тут рисуется вопрос: “А как это все работает под капотом?”.
Клиентская часть (Агент)
Рассмотрим пример доставки лога от Docker контейнера.
Есть два варианта (на самом деле их больше тыц) как писать лог Docker контейнеров. В своем дефолтном состоянии, используется Logging Driver — “JSON file”, т.е. пишет классическим методом в файл. Второй способ — это переопределить Logging Driver и слать лог сразу в Fluentd.
Решили мы попробовать второй вариант.
Далее столкнулись с такой проблемой, что если просто сменить Logging Driver и, если вдруг, TCP сокет Fluentd, куда должны сыпаться логи, не доступен, то контейнер вообще не запустится. А если TCP сокет Fluentd пропадет, когда контейнер ранится, то логи начинают копиться в буфер.
direct — является дефолтным. Приложение падает, когда не может записать лог в stdout и/или stderr.
non-blocking — позволяет записывать логи приложения в буфер при недоступности сокета коллектора. При этом, если буфер полон, новые логи начинают вытеснять старые.
Все эти вещи подтянули дополнительными опциями Logging Driver
(--log-opt).
Но, так как нас не устроил ни первый, ни второй вариант, то мы решили не переопределять Logging Driver и оставить его дефолтным.
Вот тут и настал момент, когда мы задумались о том, что необходимо устанавливать агента, который бы старым, добрым способом вычитывал с помощью tail лог файл. Кстати, я думаю не все задумывались над тем, что происходит с tail, когда ротейтится лог-файл, а оказалось все достаточно просто, так как tail снабжен ключем -F (same as --follow=”name” --retry), который способен следить за файлом и переоткрывать его в случае необходимости.
Итак, первое на что было обращено внимание — это продукт FluentBit.
Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами.
Проблема заключалась в том, что если TCP сокет коллектора не доступен, то FluentBit начинает активно писать в буфер, который находится в памяти и по мере его заполнения, начинает вытеснять (перезаписывать) лог, до тех пор, пока не восстановит соединение с коллектором, а следовательно, мы теряем логи. Это не критикал, но крайне неприятно.
Решили эту проблему следующим образом.
FluentBit в tail плагине имеет следующие параметры:
DB — определяет файл базы данных, в котором будет вестись учет файлов, которые мониторятся, а также позицию в этих файлах (offsets).
DB.Sync — устанавливает дефолтный метод синхронизации (I/O). Данная опция отвечает за то, как внутренний движок SQLite будет синхронизироваться на диск.
И стало все отлично, логи мы не теряли, но столкнулись со следующей проблемой — эта штука очень жутко начала потреблять IOPs. Обратили на это внимание когда заметили, что инстансы начали тупить и упираться в IO, которого раньше хватало за глаза и сейчас объясню почему.
Мы используем EC2 инстансы (AWS) и тип EBS — gp2 (General Purpose SSD). У них есть такая штука, которая называется “Burst performance”. Это когда EBS способен выдерживать некоторые пики возрастающей нагрузки на файловую систему, например запуск какой-нибудь крон задачи, которая требует интенсивного IO и если ему недостаточно “baseline performance”, инстанс начинает потреблять накопленные кредиты на IO т.е. “Burst performance”.
Так вот, наша проблема заключалась в том, что были вычерпаны кредиты IO и EBS начал захлебываться от его недостатка.
Ок. Пройденный этап.
После этого мы решили, а почему бы не использовать тот же Fluentd в качестве агента.
Я создаю доказательство концепции с использованием Elasticsearch Logstash и Kibana для одного из моих проектов. У меня есть приборная панель с графиками работы без каких-либо проблем. Одним из требований к моему проекту является возможность загрузки файла(csv/excel). В kibana единственный вариант, который я видел для загрузки файла, - это нажать кнопку edit на созданной визуализации. Можно ли добавить ссылку на панель мониторинга, которая позволит пользователям загружать файл, не входя в редактирование режим. И во-вторых, я хотел бы отключить / скрыть режим редактирования для всех, кроме меня, кто просматривает панель мониторинга. Спасибо
для экспорта данных в csv / excel из Kibana выполните следующие действия: -
перейдите на вкладку визуализация и выберите визуализацию (если она создана). Если не создано, создайте visualziation.
нажмите на символ каре ( ^ ), которая присутствует в нижней части визуализации.
затем вы получите возможность экспорта: Raw отформатирован в нижней части страницы.
пожалуйста, найдите ниже прилагается изображение, показывающее опцию экспорта после нажатия на символ каретки.

Я полностью пропустил кнопку экспорта в нижней части каждой визуализации. Как только для чтения. Щит с Elasticsearch в Стоит.
FYI : как загрузить данные в CSV из Kibana:
В Kibana--> 1. Перейти к "Discover" в левой части
выберите поле индекса (на основе данных мониторинга ) (***В случае, если вы не уверены, какой индекс выбрать- > перейдите на вкладку Управление->сохраненные объекты- > панель мониторинга->выберите имя панели мониторинга - > прокрутите вниз до JSON->вы увидите имя индекса)
слева вы видите все переменные, доступные в данных-- > нажмите на имя переменной, которое вы хотите иметь в csv-- > нажмите add-->эта переменная будет добавлена в правой части столбцов avaliable
правой верхней части платформы Kibana-->есть фильтр-->нажать -- >выберите продолжительность, для которой вы хотите csv
вверху справа вверху -->отчеты-->сохранить это время / выбор переменной с новым отчетом-- > нажмите Создать CSV
перейти к "управление" в левой части--> "Отчетность" -- > скачать csv

После установки сервисов логи разбросаны по каталогам и серверам, и максимум, что с ними делают, — это настраивают ротацию (кстати, не всегда). Обращаются к журналам, только когда обнаруживаются видимые сбои. Хотя нередко информация о проблемах появляется чуть раньше, чем падает какой-то сервис. Централизованный сбор и анализ логов позволяет решить сразу несколько проблем. В первую очередь это возможность посмотреть на все одновременно. Ведь сервис часто представляется несколькими подсистемами, которые могут быть расположены на разных узлах, и если проверять журналы по одному, то проблема будет не сразу ясна. Тратится больше времени, и сопоставлять события приходится вручную. Во-вторых, повышаем безопасность, так как не нужно обеспечивать прямой доступ на сервер для просмотра журналов тем, кому он вообще не нужен, и тем более объяснять, что и где искать и куда смотреть. Например, разработчики не будут отвлекать админа, чтобы он нашел нужную информацию. В-третьих, появляется возможность парсить, обрабатывать результат и автоматически отбирать интересующие моменты, да еще и настраивать алерты. Особенно это актуально после ввода сервиса в работу, когда массово всплывают мелкие ошибки и проблемы, которые нужно как можно быстрее устранить. В-четвертых, хранение в отдельном месте позволяет защитить журналы на случай взлома или недоступности сервиса и начать анализ сразу после обнаружения проблемы.
Есть коммерческие и облачные решения для агрегации и анализа журналов — Loggly, Splunk, Logentries и другие. Из open source решений очень популярен стек ELK от Elasticsearch, Logstash, Kibana. В основе ELK лежит построенный на базе библиотеки Apache Lucene поисковый движок Elasticsearch для индексирования и поиска информации в любом типе документов. Для сбора журналов из многочисленных источников и централизованного хранения используется Logstash, который поддерживает множество входных типов данных — это могут быть журналы, метрики разных сервисов и служб. При получении он их структурирует, фильтрует, анализирует, идентифицирует информацию (например, геокоординаты IP-адреса), упрощая тем самым последующий анализ. В дальнейшем нас интересует его работа в связке с Elasticsearch, хотя для Logstash написано большое количество расширений, позволяющих настроить вывод информации практически в любой другой источник.
И наконец, Kibana — это веб-интерфейс для вывода индексированных Elasticsearch логов. Результатом может быть не только текстовая информация, но и, что удобно, диаграммы и графики. Он может визуализировать геоданные, строить отчеты, при установке X-Pack становятся доступными алерты. Здесь уже каждый подстраивает интерфейс под свои задачи. Все продукты выпускаются одной компанией, поэтому их развертывание и совместная работа не представляет проблем, нужно только все правильно соединить.
В зависимости от инфраструктуры в ELK могут участвовать и другие приложения. Так, для передачи логов приложений с серверов на Logstash мы будем использовать Filebeat. Кроме этого, также доступны Winlogbeat (события Windows Event Logs), Metricbeat (метрики), Packetbeat (сетевая информация) и Heartbeat (uptime).
Установка Filebeat
Для установки предлагаются apt- и yum-репозитории, deb- и rpm-файлы. Метод установки зависит от задач и версий. Актуальная версия — 5.х. Если все ставится с нуля, то проблем нет. Но бывает, например, что уже используется Elasticsearch ранних версий и обновление до последней нежелательно. Поэтому установку компонентов ELK + Filebeat приходится выполнять персонально, что-то ставя и обновляя из пакетов, что-то при помощи репозитория. Для удобства лучше все шаги занести в плейбук Ansible, тем более что в Сети уже есть готовые решения. Мы же усложнять не будем и рассмотрим самый простой вариант.
Подключаем репозиторий и ставим пакеты:
В Ubuntu 16.04 с Systemd периодически всплывает небольшая проблема: некоторые сервисы, помеченные мейнтейнером пакета как enable при старте, на самом деле не включаются и при перезагрузке не стартуют. Вот как раз для продуктов Elasticsearch это актуально.
Все настройки производятся в конфигурационном файле /etc/filebeat/filebeat.yml, после установки уже есть шаблон с минимальными настройками. В этом же каталоге лежит файл filebeat.full.yml, в котором прописаны все возможные установки. Если чего-то не хватает, то можно взять за основу его. Файл filebeat.template.json представляет собой шаблон для вывода, используемый по умолчанию. Его при необходимости можно переопределить или изменить.
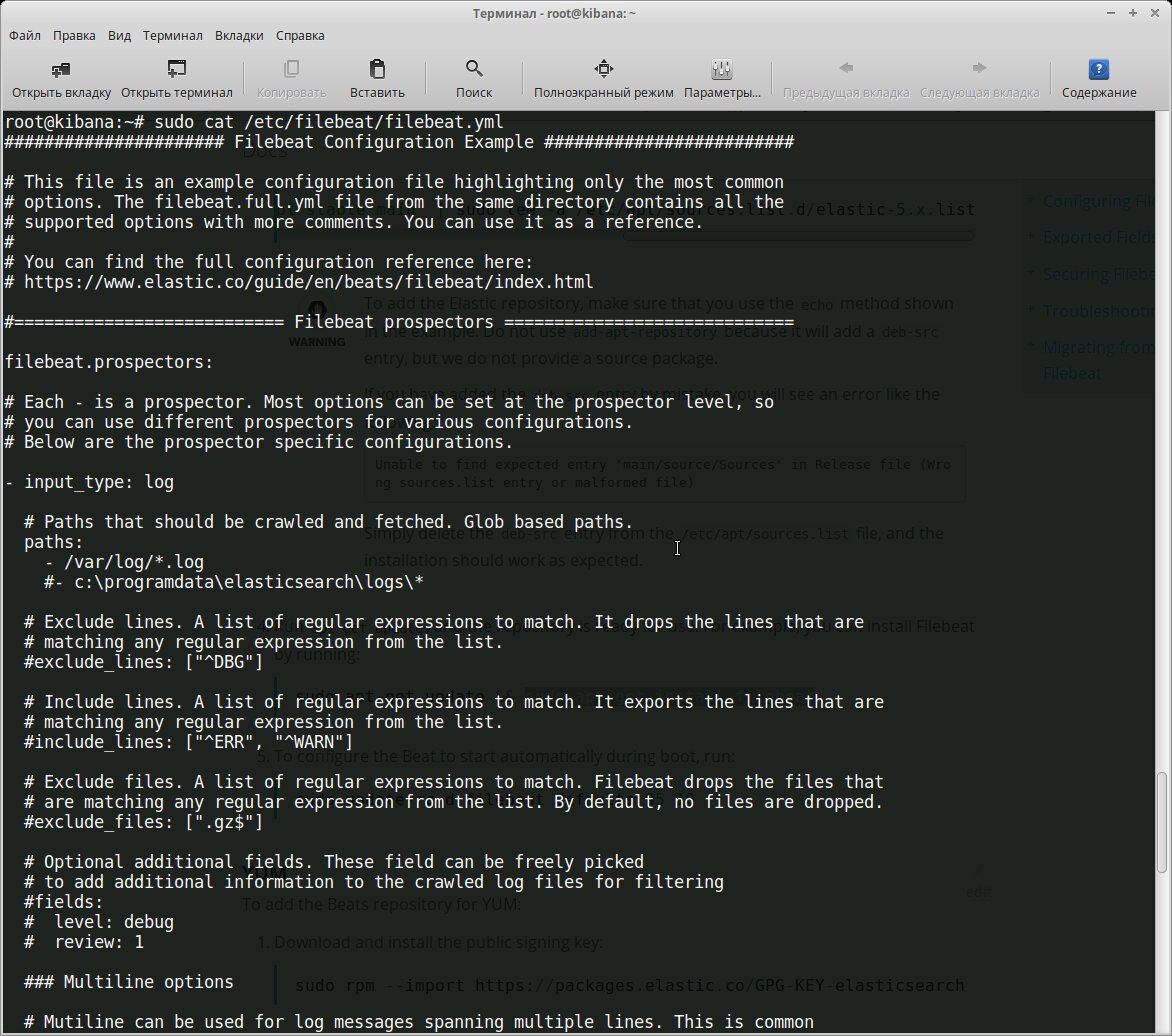
Конфигурационный файл Filebeat
Нам нужно, по сути, выполнить две основные задачи: указать, какие файлы брать и куда отправлять результат. В установках по умолчанию Filebeat собирает все файлы в пути /var/log/*.log , это означает, что Filebeat соберет все файлы в каталоге /var/log/ , заканчивающиеся на .log .
Учитывая, что большинство демонов хранят логи в своих подкаталогах, их тоже следует прописать индивидуально или используя общий шаблон:
Источники с одинаковым input_type, log_type и document_type можно указывать по одному в строке. Если они отличаются, то создается отдельная запись.
Поддерживаются все типы, о которых знает Elasticsearch.
Дополнительные опции позволяют отобрать только определенные файлы и события. Например, нам не нужно смотреть архивы внутри каталогов:
По умолчанию экспортируются все строки. Но при помощи регулярных выражений можно включить и исключить вывод определенных данных в Filebeat. Их можно указывать для каждого paths.
Если определены оба варианта, Filebeat сначала выполняет include_lines , а затем exclude_lines . Порядок, в котором они прописаны, значения не имеет. Кроме этого, в описании можно использовать теги, поля, кодировку и так далее.
Теперь переходим к разделу Outputs. Прописываем, куда будем отдавать данные. В шаблоне уже есть установки для Elasticsearch и Logstash. Нам нужен второй.
Здесь самый простой случай. Если отдаем на другой узел, то желательно использовать авторизацию по ключу. В файле есть шаблон.
Чтобы посмотреть результат, можно выводить его в файл:
Нелишними будут настройки ротации:
Это минимум. На самом деле параметров можно указать больше. Все они есть в full-файле. Проверяем настройки:
Сервис может работать, но это не значит, что все правильно. Лучше посмотреть в журнал /var/log/filebeat/filebeat и убедиться, что там нет ошибок. Проверим:
Еще важный момент. Не всегда журналы по умолчанию содержат нужную информацию, поэтому, вероятно, следует пересмотреть и изменить формат, если есть такая возможность. В анализе работы nginx неплохо помогает статистика по времени запроса.
Ставим Logstash
Для Logstash нужна Java 8. Девятая версия не поддерживается. Это может быть официальная Java SE или OpenJDK, имеющийся в репозиториях дистрибутивов Linux.
Конвейер Logstash имеет два обязательных элемента: input и output . И необязательный — filter . Плагины ввода берут данные из источника, выходные — записывают по назначению, фильтры изменяют данные по указанному шаблону. Флаг -e позволяет указать конфигурацию непосредственно в командной строке, что можно использовать для тестирования. Запустим самый простой конвейер:

Простая проверка Logstash
Все конфигурационные файлы находятся в /etc/logstash . Настройки в /etc/logstash/startup.options , jvm.options определяют параметры запуска, в logstash.yml параметры работы самого сервиса. Конвейеры описываются в файлах в /etc/logstash/conf.d . Здесь пока нет ничего. Как располагать фильтры, каждый решает сам. Можно подключения к сервисам описывать в одном файле, разделять файлы по назначению — input , output и filter . Как кому удобно.
Подключаемся к Filebeat.
Здесь же при необходимости указываются сертификаты, которые требуются для аутентификации и защиты соединения. Logstash самостоятельно может брать информацию с локального узла.
В примере beats и file — это названия соответствующих плагинов. Полный их список для inputs, outputs и filter и поддерживаемые параметры доступны на сайте.
После установки в систему уже есть некоторые плагины. Их список проще получить при помощи специальной команды:
Сверяем список с сайтом, обновляем имеющиеся и ставим нужный:
Если систем много, то можно использовать logstash-plugin prepare-offline-pack для создания пакета и распространения на другие системы.
Отдаем данные на Elasticsearch.
И самое интересное — фильтры. Создаем файл, который будет обрабатывать данные с типом nginx-access .
Для проверки корректности правил можно использовать сайт grokdebug или grokconstructor, там же есть еще готовые паттерны для разных приложений.
Создадим фильтр для отбора события NGINXACCESS для nginx. Формат простой — имя шаблона и соответствующее ему регулярное выражение.
Убеждаемся в журналах, что все работает.
Ставим Elasticsearch и Kibana
Самое время поставить Elasticsearch:
По умолчанию Elasticsearch слушает локальный 9200-й порт. В большинстве случаев лучше так и оставить, чтобы посторонний не мог получить доступ. Если сервис находится внутри сети или доступен по VPN, то можно указать внешний IP и изменить порт, если он уже занят.
Также стоит помнить, что Elasticsearch любит ОЗУ (по умолчанию запускается с -Xms2g -Xmx2g ): возможно, придется поиграть значением, уменьшая или увеличивая его в файле /etc/elasticsearch/jvm.options не выше 50% ОЗУ.
С Kibana то же самое:
По умолчанию Kibana стартует на localhost:5601. В тестовой среде можно разрешить подключаться удаленно, изменив в файле /etc/kibana/kibana.yml параметр server.host . Но так как какой-то аутентификации не предусмотрено, лучше в качестве фронта использовать nginx, настроив обычный proxy_pass и доступ с htaccess .
Первым делом нужно сказать Kibana об индексах Elasticsearch, которые нас интересуют, настроив один или несколько шаблонов. Если Kibana не найдет в базе шаблона, то и не даст его активировать при вводе. Самый простой шаблон * позволяет увидеть все данные и сориентироваться. Для filebeat пишем filebeat-* и в поле Time-feald name — @timestamp .
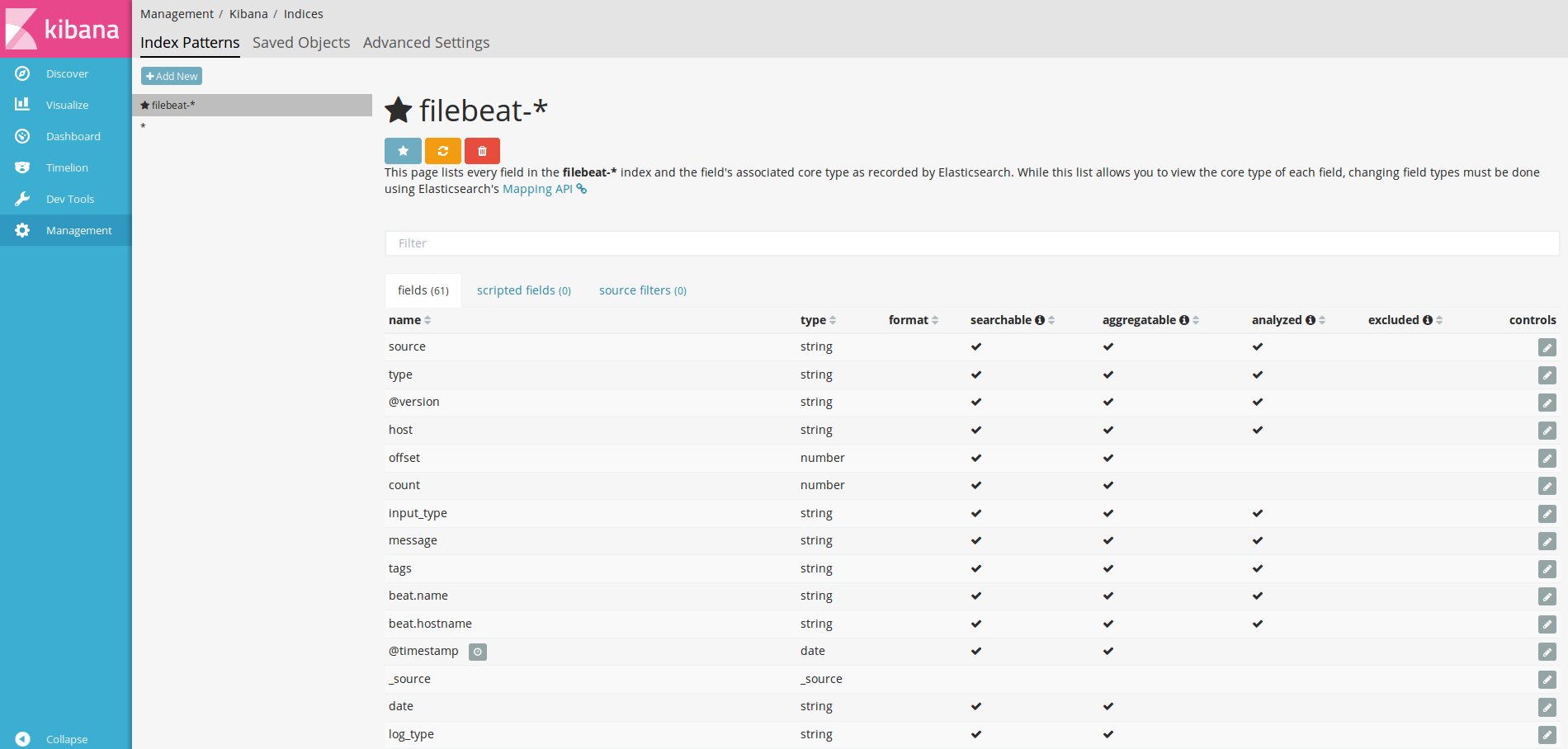
Добавляем шаблон индекса в Kibana
После этого, если агенты подключены нормально, в секции Discover начнут появляться логи.
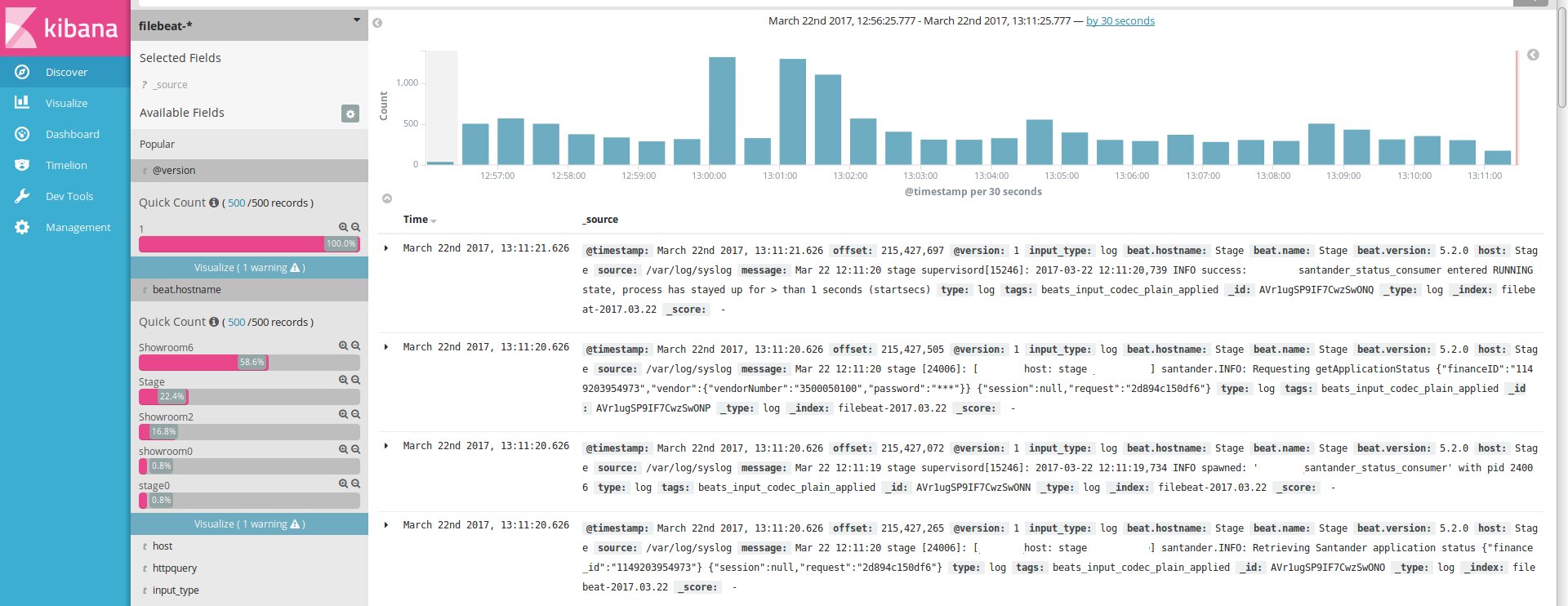
Пошли журналы
Далее последовательно переходим по вкладкам, настраиваем графики и Dashboard.
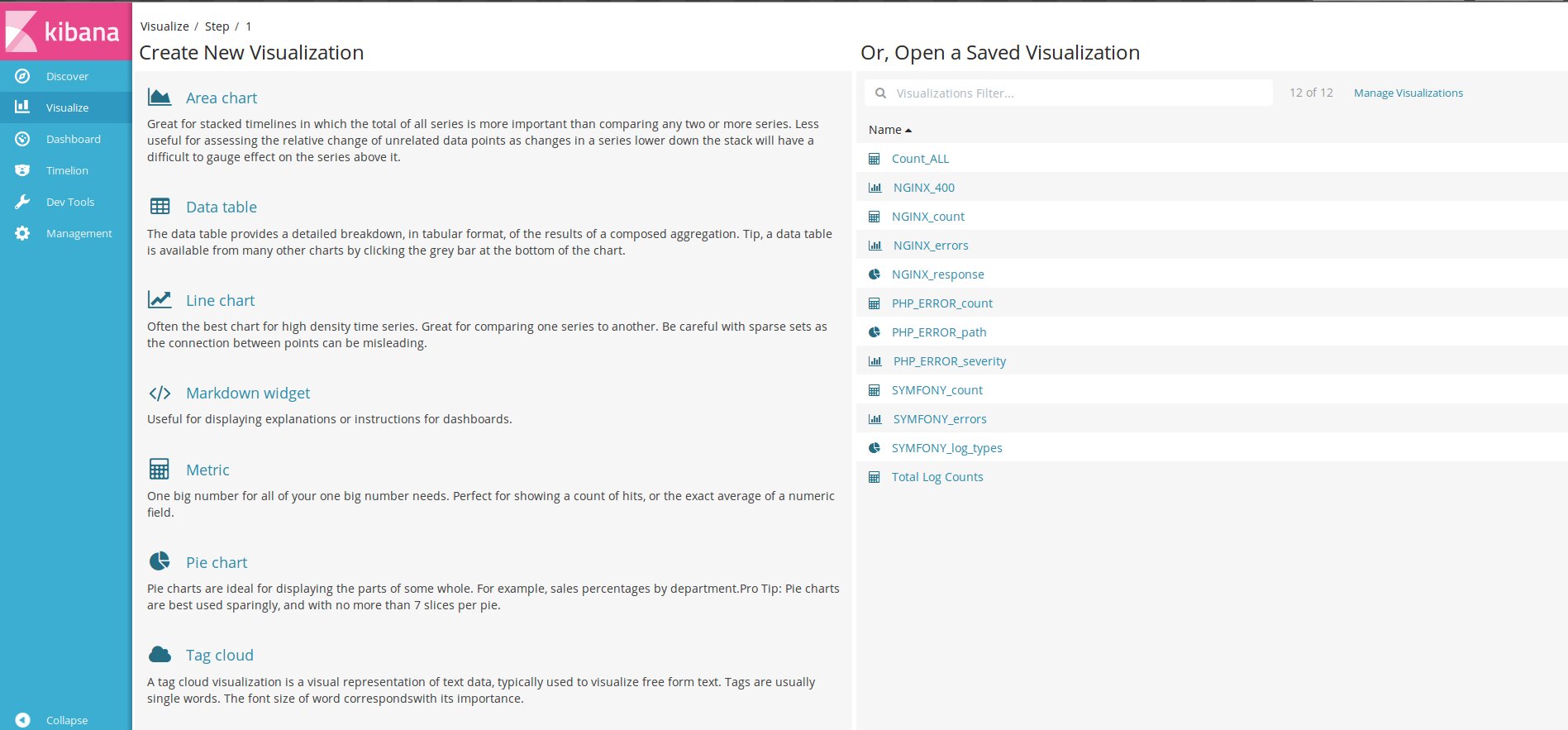
Меню выбора графиков
Готовые установки Dashboard можно найти в Сети и импортировать в Kibana.
После импорта переходим в Dashboard, нажимаем Add и выбираем из списка нужный.
Добавляем Dashboard
Вывод
Готово! Минимум у нас уже есть. Дальше Kibana легко подстраивается индивидуально под потребности конкретной сети.
Читайте также: