
Как вывести структуру в отдельный файл
Обновлено: 04.07.2024
В программировании есть много случаев, когда может понадобиться больше одной переменной для представления определенного объекта.
Зачем нужны структуры?
Например, для представления самого себя, вы, скорее всего, захотите указать свое имя, день рождения, рост, вес или любую другую информацию:
Но теперь у вас есть 6 отдельных независимых переменных. Если вы захотите передать информацию о себе в функцию, то вам придется передавать каждую переменную по отдельности. Кроме того, если вы захотите хранить информацию о ком-то еще, то вам придется дополнительно объявить еще 6 переменных на каждого человека! Невооруженным глазом видно, что такая реализация не очень эффективна.
К счастью, язык C++ позволяет программистам создавать свои собственные пользовательские типы данных — типы, которые группируют несколько отдельных переменных вместе. Одним из простейших пользовательских типов данных является структура. Структура позволяет сгруппировать переменные разных типов в единое целое.
Объявление и определение структур
Поскольку структуры определяются программистом, то вначале мы должны сообщить компилятору, как она вообще будет выглядеть. Для этого используется ключевое слово struct :
Мы определили структуру с именем Employee . Она содержит 3 переменные:
salary типа double.
Предупреждение: Одна из самых простых ошибок в C++ — забыть точку с запятой в конце объявления структуры. Это приведет к ошибке компиляции в следующей строке кода. Современные компиляторы, такие как Visual Studio версии 2010, а также более новых версий, укажут вам, что вы забыли точку с запятой в конце, но более старые компиляторы могут этого и не сделать, из-за чего такую ошибку будет трудно найти. О том, как установить Visual Studio или какую выбрать IDE мы уже говорили на уроке №4.
Чтобы использовать структуру Employee , нам нужно просто объявить переменную типа Employee :
Employee john ; // имя структуры Employee начинается с заглавной буквы, а переменная john - с маленькойЗдесь мы определили переменную типа Employee с именем john . Как и в случае с обычными переменными, определение переменной, типом которой является структура, приведет к выделению памяти для этой переменной.
Объявить можно и несколько переменных одной структуры:
Employee john ; // создаем отдельную структуру Employee для John Employee james ; // создаем отдельную структуру Employee для JamesДоступ к членам структур
Когда мы объявляем переменную структуры, например, Employee john , то john ссылается на всю структуру. Для того, чтобы получить доступ к отдельным её членам, используется оператор выбора члена ( . ). Например, в коде, приведенном ниже, мы используем оператор выбора членов для инициализации каждого члена структуры:
Employee john ; // создаем отдельную структуру Employee для John john . id = 8 ; // присваиваем значение члену id структуры john john . age = 27 ; // присваиваем значение члену age структуры john john . salary = 32.17 ; // присваиваем значение члену salary структуры john Employee james ; // создаем отдельную структуру Employee для James james . id = 9 ; // присваиваем значение члену id структуры james james . age = 30 ; // присваиваем значение члену age структуры james james . salary = 28.35 ; // присваиваем значение члену salary структуры jamesКак и в случае с обычными переменными, переменные-члены структуры не инициализируются автоматически и обычно содержат мусор. Инициализировать их нужно вручную.
В примере, приведенном выше, легко определить, какая переменная относится к структуре John , а какая — к структуре James . Это обеспечивает гораздо более высокий уровень организации, чем в случае с обычными отдельными переменными.
Переменные-члены структуры работают так же, как и простые переменные, поэтому с ними можно выполнять обычные арифметические операции и операции сравнения:
++ john . age ; // используем пре-инкремент для увеличения возраста John на 1 годИнициализация структур
Инициализация структур путем присваивания значений каждому члену по порядку — занятие довольно громоздкое (особенно, если этих членов много), поэтому в языке C++ есть более быстрый способ инициализации структур — с помощью списка инициализаторов. Он позволяет инициализировать некоторые или все члены структуры во время объявления переменной типа struct:
Employee john = < 5 , 27 , 45000.0 >; // john.id = 5, john.age = 27, john.salary = 45000.0 Employee james = < 6 , 29 >; // james.id = 6, james.age = 29, james.salary = 0.0 (инициализация по умолчанию) Employee john < 5 , 27 , 45000.0 >; // john.id = 5, john.age = 27, john.salary = 45000.0 Employee james < 6 , 29 >; // james.id = 6, james.age = 29, james.salary = 0.0 (инициализация по умолчанию)Если в списке инициализаторов не будет одного или нескольких элементов, то им присвоятся значения по умолчанию (обычно, 0 ). В примере, приведенном выше, члену james.salary присваивается значение по умолчанию 0.0 , так как мы сами не предоставили никакого значения во время инициализации.
C++11/14: Инициализация нестатических членов структур
В C++11 добавили возможность присваивать нестатическим (обычным) членам структуры значения по умолчанию. Например:
z . length = 3.0 ; // вы также можете присваивать членам структуры и другие значенияК сожалению, в C++11 синтаксис инициализации нестатических членов структуры несовместим с синтаксисом списка инициализаторов или uniform-инициализацией. В C++11 следующая программа не скомпилируется:
double length = 2.0 ; // нестатическая инициализация членовСледовательно, вам нужно будет решить, хотите ли вы использовать инициализацию нестатических полей или uniform-инициализацию. uniform-инициализация более гибкая, поэтому рекомендуется использовать именно её.
Однако в C++14 это ограничение было снято, и оба варианта можно использовать. Мы еще поговорим детально о статических членах структуры на соответствующем уроке.
Присваивание значений членам структур
До C++11, если бы мы захотели присвоить значения членам структуры, то нам бы пришлось это делать вручную каждому члену по отдельности:
Это боль, особенно когда членов в структуре много. В C++11 вы можете присваивать значения членам структур, используя список инициализаторов:
Структуры и функции
Большим преимуществом использования структур, нежели отдельных переменных, является возможность передать всю структуру в функцию, которая должна работать с её членами:
В примере, приведенном выше, мы передали структуру Employee в функцию printInformation(). Это позволило нам не передавать каждую переменную по отдельности. Более того, если мы когда-либо захотим добавить новых членов в структуру Employee , то нам не придется изменять объявление или вызов функции!
Результат выполнения программы:
ID: 21
Age: 27
Salary: 28.45
ID: 22
Age: 29
Salary: 19.29
Функция также может возвращать структуру (это один из тех немногих случаев, когда функция может возвращать несколько переменных). Например:
Результат выполнения программы:
The point is zero
Вложенные структуры
Одни структуры могут содержать другие структуры. Например:
Employee CEO ; // Employee - это структура внутри структуры CompanyВ этом случае, если бы мы хотели узнать, какая зарплата у CEO (исполнительного директора), то нам бы пришлось использовать оператор выбора членов дважды:
Сначала мы выбираем поле CEO из структуры myCompany , а затем поле salary из структуры Employee .
Вы можете использовать вложенные списки инициализаторов c вложенными структурами:
Employee CEO ; // Employee является структурой внутри структуры CompanyРазмер структур
std :: cout << "The size of Employee is " << sizeof ( Employee ) << "\n" ;Результат выполнения программы (на компьютере автора):
The size of Employee is 16
В структуре Employee компилятор неявно добавил 2 байта после члена id , увеличивая размер структуры до 16 байтов вместо 14. Описание причины, по которой это происходит, выходит за рамки этого урока, но если вы хотите знать больше, то можете прочитать о выравнивании данных в Википедии.
Доступ к структурам из нескольких файлов
Поскольку объявление структуры не провоцирует выделение памяти, то использовать предварительное объявление для нее вы не сможете. Но есть обходной путь: если вы хотите использовать объявление структуры в нескольких файлах (чтобы иметь возможность создавать переменные этой структуры в нескольких файлах), поместите объявление структуры в заголовочный файл и подключайте этот файл везде, где необходимо использовать структуру.
Переменные типа struct подчиняются тем же правилам, что и обычные переменные. Следовательно, если вы хотите сделать переменную структуры доступной в нескольких файлах, то вы можете использовать ключевое слово extern.
Заключение
Задание №1
У вас есть веб-сайт и вы хотите отслеживать, сколько денег вы зарабатываете в день от размещенной на нем рекламы. Объявите структуру Advertising , которая будет отслеживать:
сколько объявлений вы показали посетителям (1);
сколько процентов посетителей нажали на объявления (2);
сколько вы заработали в среднем за каждое нажатие на объявления (3).
Значения этих трех полей должен вводить пользователь. Передайте структуру Advertising в функцию, которая выведет каждое из этих значений, а затем подсчитает, сколько всего денег вы заработали за день (перемножьте все 3 поля).
До этого при вводе-выводе данных мы работали со стандартными потоками — клавиатурой и монитором. Теперь рассмотрим, как в языке C реализовано получение данных из файлов и запись их туда. Перед тем как выполнять эти операции, надо открыть файл и получить доступ к нему.
В языке программирования C указатель на файл имеет тип FILE и его объявление выглядит так:
С другой стороны, функция fopen() открывает файл по указанному в качестве первого аргумента адресу в режиме чтения ("r"), записи ("w") или добавления ("a") и возвращает в программу указатель на него. Поэтому процесс открытия файла и подключения его к программе выглядит примерно так:
Примечание. В случае использования относительной адресации текущим/рабочим каталогом в момент исполнения программы должен быть тот, относительно которого указанный относительный адрес корректен. Место нахождения самого исполняемого файла не важно.
При чтении или записи данных в файл обращение к нему осуществляется посредством файлового указателя (в данном случае, myfile).
Если в силу тех или иных причин (нет файла по указанному адресу, запрещен доступ к нему) функция fopen() не может открыть файл, то она возвращает NULL. В реальных программах почти всегда обрабатывают ошибку открытия файла в ветке if , мы же далее опустим это.
Объявление функции fopen() содержится в заголовочном файле stdio.h, поэтому требуется его подключение. Также в stdio.h объявлен тип-структура FILE.
После того, как работа с файлом закончена, принято его закрывать, чтобы освободить буфер от данных и по другим причинам. Это особенно важно, если после работы с файлом программа продолжает выполняться. Разрыв связи между внешним файлом и указателем на него из программы выполняется с помощью функции fclose() . В качестве параметра ей передается указатель на файл:
В программе может быть открыт не один файл. В таком случае каждый файл должен быть связан со своим файловым указателем. Однако если программа сначала работает с одним файлом, потом закрывает его, то указатель можно использовать для открытия второго файла.
Чтение из текстового файла и запись в него
fscanf()
Функция fscanf() аналогична по смыслу функции scanf() , но в отличии от нее осуществляет форматированный ввод из файла, а не стандартного потока ввода. Функция fscanf() принимает параметры: файловый указатель, строку формата, адреса областей памяти для записи данных:
Возвращает количество удачно считанных данных или EOF. Пробелы, символы перехода на новую строку учитываются как разделители данных.
Допустим, у нас есть файл содержащий такое описание объектов:
Тогда, чтобы считать эти данные, мы можем написать такую программу:
В данном случае объявляется структура и массив структур. Каждая строка из файла соответствует одному элементу массива; элемент массива представляет собой структуру, содержащую строковое и два числовых поля. За одну итерацию цикл считывает одну строку. Когда встречается конец файла fscanf() возвращает значение EOF и цикл завершается.
fgets()
Функция fgets() аналогична функции gets() и осуществляет построчный ввод из файла. Один вызов fgets() позволят прочитать одну строку. При этом можно прочитать не всю строку, а лишь ее часть от начала. Параметры fgets() выглядят таким образом:
Такой вызов функции прочитает из файла, связанного с указателем myfile, одну строку текста полностью, если ее длина меньше 50 символов с учетом символа '\n', который функция также сохранит в массиве. Последним (50-ым) элементом массива str будет символ '\0', добавленный fgets() . Если строка окажется длиннее, то функция прочитает 49 символов и в конце запишет '\0'. В таком случае '\n' в считанной строке содержаться не будет.
В этой программе в отличие от предыдущей данные считываются строка за строкой в массив arr. Когда считывается следующая строка, предыдущая теряется. Функция fgets() возвращает NULL в случае, если не может прочитать следующую строку.
getc() или fgetc()
Функция getc() или fgetc() (работает и то и другое) позволяет получить из файла очередной один символ.
Приведенный в качестве примера код выводит данные из файла на экран.
Запись в текстовый файл
Также как и ввод, вывод в файл может быть различным.
- Форматированный вывод. Функция fprintf ( файловый_указатель, строка_формата, переменные ) .
- Посточный вывод. Функция fputs ( строка, файловый_указатель ) .
- Посимвольный вывод. Функция fputc() или putc( символ, файловый_указатель ) .
Ниже приводятся примеры кода, в которых используются три способа вывода данных в файл.
Запись в каждую строку файла полей одной структуры:
Построчный вывод в файл ( fputs() , в отличие от puts() сама не помещает в конце строки '\n'):
Пример посимвольного вывода:
Чтение из двоичного файла и запись в него
С файлом можно работать не как с последовательностью символов, а как с последовательностью байтов. В принципе, с нетекстовыми файлами работать по-другому не возможно. Однако так можно читать и писать и в текстовые файлы. Преимущество такого способа доступа к файлу заключается в скорости чтения-записи: за одно обращение можно считать/записать существенный блок информации.
При открытии файла для двоичного доступа, вторым параметром функции fopen() является строка "rb" или "wb".
Тема о работе с двоичными файлами достаточно сложная, для ее изучения требуется отдельный урок. Здесь будут отмечены только особенности функций чтения-записи в файл, который рассматривается как поток байтов.
Функции fread() и fwrite() принимают в качестве параметров:
- адрес области памяти, куда данные записываются или откуда считываются,
- размер одного данного какого-либо типа,
- количество считываемых данных указанного размера,
- файловый указатель.
Эти функции возвращают количество успешно прочитанных или записанных данных. Т.е. можно "заказать" считывание 50 элементов данных, а получить только 10. Ошибки при этом не возникнет.
Пример использования функций fread() и fwrite() :
Здесь осуществляется попытка чтения из первого файла 50-ти символов. В n сохраняется количество реально считанных символов. Значение n может быть равно 50 или меньше. Данные помещаются в строку. То же самое происходит со вторым файлом. Далее первая строка присоединяется ко второй, и данные сбрасываются в третий файл.
среда, 7 января 2015 г.
Структуры в языке Си.
На ум сразу приходит следующий вариант реализации. Завести для каждого отдельного качества отдельный массив. Например:
int book_date[100]; // дата изданияint book_pages[100]; // количество страниц
char book_author[100][50]; // автор
char book_title[100][100]; // название книги
float book_price[100]; //стоимость
Тогда, обращаясь по i -му номеру к соответствующему массиву, мы могли бы получить требуемую информацию. Например, вот так мы могли бы вывести на экран автора, название и количество страниц четвертой книги (не забываем, что нумерация элементов массива начинается с нуля).
printf( "%s-%s %d page" , book_author[3], book_title[3], book_pages[3]);Оставим пока что эту реализацию, и посмотрим, как выполнить такую же задачу с использованием структур. Но прежде всего, определим, что такое структура.
Возвращаясь к нашему примеру, опишем структуру book с полями date, pages, author, title, price соответствующих типов.
struct bookint date; // дата издания
int pages; // количество страниц
char author[50]; // автор
char title[100]; // название книги
float price; // стоимость
>;
Попутно отметим, что в качестве полей структуры могут выступать любые встроенные типы данных и даже другие структуры. Подробнее об этом я расскажу в другом уроке. На имена полей накладываются те же ограничения, что и на обычные переменные. Внутри одной структуры не должно быть полей с одинаковыми именами. Имя поля не должно начинаться с цифры. Регистр учитывается.
После того, как мы описали внутреннее устройство структуры, можно считать, что мы создали новый тип данных, который устроен таким вот образом. Теперь этот тип данных можно использовать в нашей программе.
ПРИМЕЧАНИЕ: Обычно структуры описываются сразу после подключения заголовочных файлов. Иногда, для удобства, описание структур выносят в отдельный заголовочный файл.
Объявление структурной переменной происходит по обычным правилам.
struct book kniga1;
Такое объявление создает в памяти переменную типа book , с соответствующими полями.

Отличие структурной переменной от обычной переменной удобно проиллюстрировать на примере с коробками. Считаем, что обычная переменная это просто коробка, в которую можно положить объект определенного типа, например, целое число.
Структурная переменная, это тоже коробка, внутри которой есть отдельные секции для хранения различных данных. Количество этих секций и типы данных, которые мы можем там хранить, задаются шаблоном структуры. На рисунке я постарался схематично изобразить устройство структурной переменной.
Отмечу, что я сознательно не касаюсь вопроса о том, как хранится структура в памяти, так как считаю, что для новичков эти тонкости будут излишни.
Кроме того, еще одну удобную интерпретацию структуры дает нам книга K&R. Можно думать о ней, как о строчке в таблице, где столбцами выступают поля структуры.

Если кто-то имел дело с реляционными базами данных (MySQL, Oracle), то вам эта такая интерпретация будет очень знакома.
Хорошо, переменную мы объявили. Самое время научиться сохранять в неё данные, иначе, зачем она нам вообще нужна. Мы можем присвоить значения сразу всем полям структуры при объявлении. Это очень похоже на то, как мы присваивали значения массиву при его объявлении.

Важный момент. Порядок и тип аргументов, должен совпадать с порядком и типом полей, описанных в шаблоне структуры. В нашем примере мы сначала записали дату, потом количество страниц, имя автора, название книги и стоимость. Пропустить какой-то аргумент нельзя, но можно не объявлять несколько последних. Т.е. вполне допустима следующая конструкция:
Для обращения к отдельным полям структуры используется оператор доступа "." . Да-да, обычная точка.
Примеры:
// значение 250.
printf( "%s-%s %d page" , kniga1.author, kniga1.title, kniga1.pages);
Задание: Проверить, что хранится в полях структуры до того, как им присвоено значение.
Сейчас, в одной переменной типа book храниться вся информация об одной книге. Но так как в каталоге вряд ли будет всего одна книга, нам потребуется много переменных одного и того же типа book . А значит что? Правильно, нужно создать массив таких переменных, то есть массив структур. Делается это аналогично, как если бы мы создавали массив переменных любого стандартного типа.
Каждый элемент этого массива это переменная типа book . Т.е. у каждого элемента есть свои поля date, pages, author, title, price . Тут-то и удобно вспомнить о второй интерпретации структуры. В ней массив структур будет выглядеть как таблица.
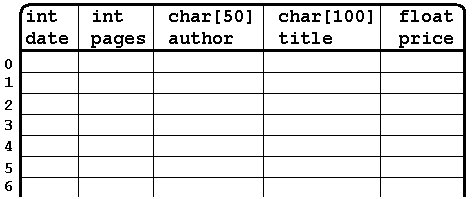
Используя массив структур получить информацию об отдельной книге можно следующим образом.
printf( "%s-%s %d page" , kniga[3].author, kniga[3].title, kniga[3].pages);Обращаясь к kniga[3].author мы обращаемся к четвертой строке нашей таблицы и столбику с именем author . Удобная интерпретация, не правда ли?
На данном этапе мы научились основам работы со структурами. Точнее мы переписали с использованием структур тот же код, который использовал несколько массивов. Кажется, что особой разницы нет. Да, на первый взгляд это действительно так. Но дьявол, как обычно, кроется в мелочах.
Например, очевидно, что в нашей программе нам часто придется выводить данные о книге на экран. Разумным решением будет написать для этого отдельную функцию.
Если бы мы пользуемся несколькими массивами, то эта функция выглядела бы примерно так:
char *title, float price)
printf( "%s-%s %d page.\nDate: %d \nPRICE: %f rub.\n" ,
author, title, pages,date, price);
>
А её вызов выглядел как-то вот так:
print_book (book_date[3], book_pages[3], book_author[3],book_title[3], book_price[3]);
Не очень-то и компактно получилось, как вы можете заметить. Легче было бы писать каждый раз отдельный printf(); .
Совсем другое дело, если мы используем структуры. Так как структура представляет собой один целый объект (большую коробку с отсеками), то и передавать в функцию нужно только его. И тогда нашу функцию можно было бы записать следующим образом:
printf( "%s-%s %d page.\nDate: %d \nPRICE: %f rub." ,
temp.author,temp.title, temp.pages,
temp.date, temp.price);
>
И вызов, выглядел бы приятнее:
Вот это я понимаю, быстро и удобно, и не нужно каждый раз писать пять параметров. А представьте теперь, что полей у структуры бы их было не 5, а допустим 10? Вот-вот, и я о том же.
Стоит отметить, что передача структурных переменных в функцию, как и в случае обычных переменных осуществляется по значению. Т.е. внутри функции мы работаем не с самой структурной переменной, а с её копией. Чтобы этого избежать, как и в случае переменных стандартных типов используют указатель на структуру. Там есть небольшая особенность, но об этом я расскажу в другой раз.
Кроме того, мы можем присваивать структурные переменные, если они относятся к одному и тому же шаблону. Зачастую это очень упрощает программирование.
Например, вполне реальная задача для каталога книг, упорядочить книги по количеству страниц.
Если бы мы использовали отдельные массивы, то сортировка выглядела бы примерно так.
for ( int j = 0; j < i; j++)
if (book_pages[j] > book_page[j+1])
//меняем местами значения во всех массивах
int temp_date;
int temp_pages;
char temp_author[50];
char temp_title[100];
float temp_price;
temp_date = book_date[i];
book_date[i] = book_date[j];
book_date[j] = temp_date;
temp_pages = book_pages[i];
book_pages[i] = book_pages[j];
book_pages[j] = temp_pages;
//и так далее для остальных трех массивов
>
Совсем другой дело, если мы используем структуры.
for ( int i = 99; i > 0; i--)for ( int j = 0; j < i; j++)
if (knigi[j].pages > knigi[j+1].pages)
struct book temp;
temp = knigi[j]; //присваивание структур
knigi[j] = knigi[j+1];
knigi[j+1] = temp;
>
Неоспоримое удобство, не правда ли?
Надеюсь, у меня получилось достаточно убедительно показать преимущества использования структур.
На этой радостной ноте, я и завершаю сегодняшний урок.
, Когда тип используется в файле (т.е. func.c файле), это должно быть видимо. Очень худшим способом сделать это является вставка копии, этому в каждом исходном файле был нужен он.
правильный путь помещает его в заголовочный файл, и включайте этот заголовочный файл при необходимости.
мы будем открывать новый заголовочный файл и объявлять структуру там и включать тот заголовок в func.c?
Это - решение, мне нравится больше, потому что оно делает код очень модульным. Я кодировал бы Вашу структуру как:
я поместил бы функции с помощью этой структуры в том же заголовке (функция, которые являются "семантически" частью ее "интерфейса").
И обычно, я мог назвать файл в честь имени структуры, и использование, которые называют снова для выбора защиты заголовка, определяет.
, Если необходимо объявить функцию с помощью указателя на структуру, Вам не будет нужно полное определение структуры. Простое предописание как:
будет достаточно, и это уменьшает связь.
или мы можем определить общую структуру в заголовочном файле и включать это и в source.c и в func.c?
Это иначе, легче несколько, но менее модульное: Некоторый код, нуждающийся только в Вашей структуре для работы, должен был бы все еще включать все типы.
В C++, это могло привести к интересной сложности, но это вне темы (никакой тег C++), таким образом, я не уточню.
тогда, как объявить что структура как экстерн в обоих файлы.?
буду мы определение типа это тогда как?
- при использовании C++ не делать.
- при использовании C Вы должны.
причина, являющаяся этим, управление структуры C может быть болью: необходимо объявить ключевое слово структуры везде оно используется:
, В то время как определение типа позволит Вам записать его без ключевого слова структуры.
Это важно , Вы все еще сохраняете название структуры. Запись:
просто создаст анонимную структуру с именем редактора определения типа, и Вы не будете в состоянии передать - объявляют его. Поэтому придерживайтесь следующего формата:
Таким образом, Вы будете в состоянии использовать MyStruct везде, Вы не хотите добавить ключевое слово структуры, и все еще использовать MyStructTag, когда определение типа не будет работать (т.е. предописание)
Редактирование:
Исправленное неправильное предположение об объявлении структуры C99, как законно отмечено Jonathan Leffler .
Редактирование 01.06.2018:
Craig Barnes напоминает нам в своем комментарии, что Вы не должны разделять названия имени "тега" структуры и его имени "определения типа", как я сделал выше ради ясности.
Действительно, код выше мог быть записан как:
IIRC, это на самом деле, что C++ делает с его более простым объявлением структуры, негласно, для хранения его совместимым с C:
Читайте также: