
Как загрузить файл в питон чтобы сделать анализ данных
Обновлено: 07.07.2024
Файлы CSV часто используются для хранения табличных данных в файле. Мы можем легко экспортировать данные из таблиц базы данных или файлов Excel в файлы CSV. В этом руководстве мы узнаем, как анализировать файлы CSV в Python.
Файл может содержать текстовые данные, так называемые текстовые файлы, или они могут быть в виде электронной таблицы.
Что это за файл – CSV?
CSV означает файлы, разделенные запятыми, т.е. данные разделяются запятыми друг от друга. Файлы CSV создаются программой, которая обрабатывает большое количество данных. Данные из файлов CSV можно легко экспортировать в виде электронной таблицы и базы данных, а также импортировать для использования другими программами.
Давайте посмотрим, как разобрать файл CSV. Анализировать файлы CSV в Python довольно просто. Python имеет встроенную библиотеку CSV, которая обеспечивает функциональность как чтения, так и записи данных из файлов CSV и в них. В библиотеке доступны различные форматы файлов CSV, что делает обработку данных удобной для пользователя.
Анализ файла CSV
Чтение файлов CSV с помощью встроенного модуля CSV Python.

Запись файла CSV
Для записи файла мы должны открыть его в режиме записи или в режиме добавления. Здесь мы добавим данные в существующий файл CSV.

Анализируйте файлы CSV с помощью библиотеки Pandas
Есть еще один способ работы с CSV-файлами, который является наиболее популярным и профессиональным, – это использование библиотеки pandas. Она предлагает различные структуры, инструменты и операции для работы и манипулирования данными, которые в основном представляют собой двумерные или одномерные таблицы.
Использование и особенности библиотеки pandas
- Изменение наборов данных.
- Манипулирование данными с индексацией с использованием объектов DataFrame.
- Фильтрация данных.
- Операция слияния и присоединения к наборам данных.
- Нарезка, индексирование и подмножество массивных наборов данных.
- Отсутствует обработка и согласование данных.
- Вставка и удаление строки или столбца.
- Одномерные разные форматы файлов.
- Инструменты для чтения и записи данных в различных форматах файлов.
Для работы с CSV файлом необходимо установить pandas. Это сделать довольно просто, следуйте инструкциям ниже, чтобы установить его с помощью PIP.


После завершения установки все готово.
Чтение файла CSV с помощью модуля Pandas
Вам необходимо знать путь, по которому находится файл данных в файловой системе, и какой у вас текущий рабочий каталог, прежде чем вы сможете использовать pandas для импорта данных файла CSV.
Я предлагаю хранить ваш код и файл данных в одном каталоге или папке, чтобы вам не нужно было указывать путь, это сэкономит ваше время и пространство.

Запись
Написание файлов CSV с помощью pandas так же просто, как чтение. Единственный используемый новый термин – DataFrame, это двумерная неоднородная табличная структура данных (данные расположены в виде таблиц в строках и столбцах.
Pandas DataFrame состоит из трех основных компонентов – данных, столбцов и строк – с помеченными осью x и осью y (строки и столбцы).

Заключение
Мы научились разбирать файл CSV с помощью встроенного модуля CSV и модуля pandas. Есть много разных способов синтаксического анализа файлов, но программисты не используют их широко.
Такие библиотеки, как PlyPlus, PLY и ANTLR, являются некоторыми из библиотек, используемых для анализа текстовых данных. Теперь вы знаете, как использовать встроенную библиотеку CSV и мощный модуль pandas для чтения и записи данных в формате CSV. Приведенные выше коды очень простые и понятные.
Однако манипулировать сложными данными с пустым и неоднозначным вводом данных непросто. Это требует практики и знания различных инструментов в пандах. CSV – лучший способ сохранения и обмена данными. Pandas – отличная альтернатива модулям CSV.
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:

Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:

Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:

Или последние 5 строк:

Или 5 случайных строк:

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
Или, чтобы было понятнее, можно разбить на несколько строк:
В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == 'country_2'] ). Потому берутся три нужные колонки ( [['user_id', 'topic', 'country']] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Блог Владимира Степанова об аналитике. Публикую свои подходы и кейсы по анализу данных, визуализации и работе с дата-инструментами.
Два способа загрузить свой датасет в Python
- Получить ссылку
- Электронная почта
- Другие приложения
Если вы только начинаете осваивать анализ данных, то наверняка задавались вопросом, как загрузить данные в Python, чтобы начать их анализ. В этой статье покажу 2 способа, как это можно сделать.
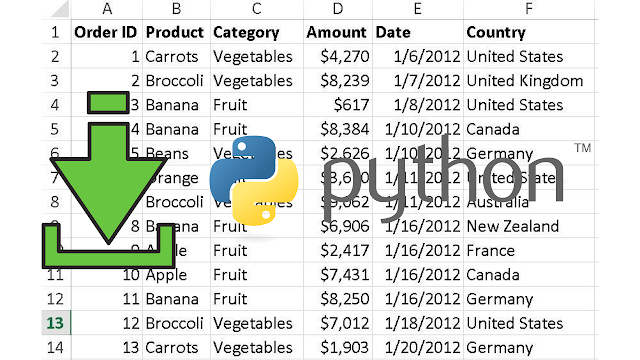
Способ 1. Загружаем данные с помощью модуля csv
Для примера возьмем датасет с рейтингом отзывов по производителям рамена. Рамен - это популярная еда в Азии, лапша быстрого приготовления с различными вкусами. В дальнейших постах мы будет работать именно с этим датасетом. Посмотрим как он выглядит с помощью редактора Notepad++


При таком способе загрузки CSV модуль загружает данные из датасета в список построчно. Каждый элемент списка будет представлять одну строку нашего датасета, которая в свою очередь тоже будет списком с элементами строки. Т.е это будет список списков. Такой способ выглядит довольно громоздко и является малоэффективным для обработки больших датасетов. Поэтому, мы воспользуемся вторым способом для загрузки данных - с помощью библиотеки Pandas
Способ 2. Загружаем данные с помощью библиотеки Pandas
Теперь, мы смогли загрузить данные, используя всего 3 строчки кода!
Pandas - это библиотека Python специально разработанная для анализа больших датасетов с миллионами строк. После загрузки данных из датасета они сохраняются в объект, называемый датафрейм. Датафрейм - это двухмерный массив данных, состоящий из строк и столбцов. Ближайший аналог - это простейшая Excel таблица. Мы видим, что строки датафрейма имеют индекс - автосгенерированный числовой код. Каждая строка обладает уникальным номером индекса. Индексы в Python начинаются с нуля. Датафрейм - это более удобный способ для доступа к данным и работе с ними в среде Python. В следующих постах мы рассмотрим работу с датафреймом более подробно, а также я расскажу о том, с каким трудностями может встретится аналитик еще до того, как данные загрузятся в датафрейм.
Если Вы только начинаете свой путь знакомства с возможностями Python, ваши познания еще имеют начальный уровень — этот материал для Вас. В статье мы опишем, как можно извлекать информацию из данных, представленных в Excel файлах, работать с ними используя базовый функционал библиотек. В первой части статьи мы расскажем про установку необходимых библиотек и настройку среды. Во второй части — предоставим обзор библиотек, которые могут быть использованы для загрузки и записи таблиц в файлы с помощью Python и расскажем как работать с такими библиотеками как pandas, openpyxl, xlrd, xlutils, pyexcel.
В какой-то момент вы неизбежно столкнетесь с необходимостью работы с данными Excel, и нет гарантии, что работа с таким форматами хранения данных доставит вам удовольствие. Поэтому разработчики Python реализовали удобный способ читать, редактировать и производить иные манипуляции не только с файлами Excel, но и с файлами других типов.
Отправная точка — наличие данных
Когда вы начинаете проект по анализу данных, вы часто сталкиваетесь со статистикой собранной, возможно, при помощи счетчиков, возможно, при помощи выгрузок данных из систем типа Kaggle, Quandl и т. д. Но большая часть данных все-таки находится в Google или репозиториях, которыми поделились другие пользователи. Эти данные могут быть в формате Excel или в файле с .csv расширением.
Данные есть, данных много. Анализируй — не хочу. С чего начать? Первый шаг в анализе данных — их верификация. Иными словами — необходимо убедиться в качестве входящих данных.
В случае, если данные хранятся в таблице, необходимо не только подтвердить качество данных (нужно быть уверенным, что данные таблицы ответят на поставленный для исследования вопрос), но и оценить, можно ли доверять этим данным.
Проверка качества таблицы
Чтобы проверить качество таблицы, обычно используют простой чек-лист. Отвечают ли данные в таблице следующим условиям:
- данные являются статистикой;
- различные типы данных: время, вычисления, результат;
- данные полные и консистентные: структура данных в таблице — систематическая, а присутствующие формулы — работающие.
Бест-практикс табличных данных
Читать данные таблицы при помощи Python — это хорошо. Но данные хочется еще и редактировать. Причем редактирование данных в таблице, должно соответствовать следующим условиям:
Если вы работаете с Microsoft Excel, вы наверняка знаете, что есть большое количество вариантов сохранения файла помимо используемых по умолчанию расширения: .xls или .xlsx (переходим на вкладку “файл”, “сохранить как” и выбираем другое расширение (наиболее часто используемые расширения для сохранения данных с целью анализа — .CSV и.ТХТ)). В зависимости от варианта сохранения поля данных будут разделены знаками табуляции или запятыми, которые составляют поле “разделитель”. Итак, данные проверены и сохранены. Начинаем готовить рабочее пространство.
Подготовка рабочего пространства
Подготовка рабочего пространства — одна из первых вещей, которую надо сделать, чтобы быть уверенным в качественном результате анализа.
Первый шаг — проверка рабочей директории.
Когда вы работаете в терминале, вы можете сначала перейти к директории, в которой находится ваш файл, а затем запустить Python. В таком случае необходимо убедиться, что файл находится в директории, из которой вы хотите работать.
Для проверки дайте следующие команды:
Эти команды важны не только для загрузки данных, но и для дальнейшего анализа. Итак, вы прошли все проверки, вы сохранили данные и подготовили рабочее пространство. Уже можно начать чтение данных в Python? :) К сожалению пока нет. Нужно сделать еще одну последнюю вещь.
Установка пакетов для чтения и записи Excel файлов
Несмотря на то, что вы еще не знаете, какие библиотеки будут нужны для импорта данных, нужно убедиться, что у все готово для установки этих библиотек. Если у вас установлен Python 2> = 2.7.9 или Python 3> = 3.4, нет повода для беспокойства — обычно, в этих версиях уже все подготовлено. Поэтому просто убедитесь, что вы обновились до последней версии :)
Для этого запустите в своем компьютере следующую команду:
В случае, если вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь (там же есть инструкции по установке и help).
Установка Anaconda
Установка дистрибутива Anaconda Python — альтернативный вариант, если вы используете Python для анализа данных. Это простой и быстрый способ начать работу с анализом данных — ведь отдельно устанавливать пакеты, необходимые для data science не придется.
Это особенно удобно для новичков, однако даже опытные разработчики часто идут этим путем, ведь Anakonda — удобный способ быстро протестировать некоторые вещи без необходимости устанавливать каждый пакет отдельно.
Anaconda включает в себя 100 наиболее популярных библиотек Python, R и Scala для анализа данных в нескольких средах разработки с открытым исходным кодом, таких как Jupyter и Spyder. Если вы хотите начать работу с Jupyter Notebook, то вам сюда.
Чтобы установить Anaconda — вам сюда.
Загрузка файлов Excel как Pandas DataFrame
Ну что ж, мы сделали все, чтобы настроить среду! Теперь самое время начать импорт файлов.
Один из способов, которым вы будете часто пользоваться для импорта файлов с целью анализа данных — импорт с помощью библиотеки Pandas (Pandas — программная библиотека на языке Python для обработки и анализа данных). Работа Pandas с данными происходит поверх библиотеки NumPy, являющейся инструментом более низкого уровня. Pandas — мощная и гибкая библиотека и она очень часто используется для структуризации данных в целях облегчения анализа.
Если у вас уже есть Pandas в Anaconda, вы можете просто загрузить файлы в Pandas DataFrames с помощью pd.Excelfile ():
Если вы не установили Anaconda, просто запустите pip install pandas, чтобы установить пакет Pandas в вашей среде, а затем выполните команды, приведенные выше.
Для чтения .csv-файлов есть аналогичная функция загрузки данных в DataFrame: read_csv (). Вот пример того, как вы можете использовать эту функцию:
Разделителем, который эта функция будет учитывать, является по умолчанию запятая, но вы можете, если хотите, указать альтернативный разделитель. Перейдите к документации, если хотите узнать, какие другие аргументы можно указать, чтобы произвести импорт.
Как записывать Pandas DataFrame в Excel файл
Предположим, после анализа данных вы хотите записать данные в новый файл. Существует способ записать данные Pandas DataFrames (с помощью функции to_excel ). Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные на несколько листов в файле .xlsx:
Обратите внимание, что в фрагменте кода используется объект ExcelWriter для вывода DataFrame. Иными словами, вы передаете переменную writer в функцию to_excel (), и указываете имя листа. Таким образом, вы добавляете лист с данными в существующую книгу. Также можно использовать ExcelWriter для сохранения нескольких разных DataFrames в одной книге.
То есть если вы просто хотите сохранить один файл DataFrame в файл, вы можете обойтись без установки библиотеки XlsxWriter. Просто не указываете аргумент, который передается функции pd.ExcelWriter (), остальные шаги остаются неизменными.
Подобно функциям, которые используются для чтения в .csv-файлах, есть также функция to_csv () для записи результатов обратно в файл с разделителями-запятыми. Он работает так же, как когда мы использовали ее для чтения в файле:
Если вы хотите иметь отдельный файл с вкладкой, вы можете передать a \ t аргументу sep. Обратите внимание, что существуют различные другие функции, которые можно использовать для вывода файлов. Их можно найти здесь.
Использование виртуальной среды
Общий совет по установке библиотек — делать установку в виртуальной среде Python без системных библиотек. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимое для использования библиотек, которые потребуются для Python.
Чтобы начать работу с virtualenv, сначала нужно его установить. Потом перейти в директорию, где будет находится проект. Создать virtualenv в этой папке и загрузить, если нужно, в определенную версию Python. После этого активируете виртуальную среду. Теперь можно начинать загрузку других библиотек и начинать работать с ними.
Не забудьте отключить среду, когда вы закончите!
Обратите внимание, что виртуальная среда может показаться сначала проблематичной, если вы делаете первые шаги в области анализа данных с помощью Python. И особенно, если у вас только один проект, вы можете не понимать, зачем вообще нужна виртуальная среда.
Но что делать, если у вас несколько проектов, работающих одновременно, и вы не хотите, чтобы они использовали одну и ту же установку Python? Или если у ваших проектов есть противоречивые требования. В таких случаях виртуальная среда — идеальное решение.
Во второй части статьи мы расскажем об основных библиотеках для анализа данных.
Продолжение следует…

Microsoft Excel является наиболее широко используемым программным обеспечением для работы с электронными таблицами в мире, и на то есть веская причина: удобный интерфейс и мощные встроенные инструменты упрощают работу с данными.
Но если вы хотите выполнить более сложную обработку данных, вам нужно выйти за пределы возможностей Excel и начать использовать язык сценариев / программирования, такой как Python. Вместо того, чтобы вручную копировать ваши данные в базы данных, вот краткое руководство о том, как загрузить ваши данные Excel в Python с помощью Pandas.
Примечание. Если вы никогда ранее не использовали Python, этот учебник может оказаться немного сложным. Мы рекомендуем начать с этих сайтов для изучения Python сайтов для изучения программирования на Python сайтов для изучения и эти базовые примеры Python, чтобы начать работу.
Что такое панды?
Библиотека анализа данных Python («Pandas») — это библиотека с открытым исходным кодом для языка программирования Python, которая используется для анализа и манипулирования данными.
Pandas загружает данные в объекты Python, известные как Dataframes , которые хранят данные в строках и столбцах, как в традиционной базе данных. Как только Dataframe создан, им можно манипулировать с помощью Python, открывая целый мир возможностей.
Установка панд
Примечание. Для установки Pandas у вас должен быть установлен Python 2.7 или более поздней версии.
Чтобы начать работать с Pandas на вашем компьютере, вам необходимо импортировать библиотеку Pandas. Если вы ищете решение для тяжеловесов, вы можете скачать Anaconda Python Distribution со встроенным Pandas. Если вы не используете Anaconda, Pandas просто установить в своем терминале.
Pandas — это пакет PyPI, что означает, что вы можете установить PIP для Python через командную строку. Современные системы Mac поставляются с PIP. Для других Windows, Linux и более старых систем легко узнать, как установить PIP для Python.
После того, как вы открыли свой терминал, последнюю версию Pandas можно установить с помощью команды:
Пандам также требуется библиотека NumPy, давайте также установим это в командной строке:
Теперь у вас установлена Pandas и вы готовы создать свой первый DataFrame!
Подготовка данных Excel
Для этого примера, давайте использовать образец набора данных: книгу Excel под названием Cars.xlsx .

Этот набор данных отображает марку, модель, цвет и год автомобилей, внесенных в таблицу. Таблица отображается в виде диапазона Excel. Панды достаточно умен, чтобы правильно читать данные.
Эта книга сохраняется в каталоге Desktop, здесь используется путь к файлу:
Вам нужно будет знать путь к файлу книги, чтобы использовать Pandas. Давайте начнем с открытия кода Visual Studio для написания сценария. Если у вас нет текстового редактора, мы рекомендуем либо Visual Studio Code, либо Atom Editor.
Написание скрипта Python
Теперь, когда у вас есть выбор текстового редактора, начинается самое интересное. Мы собираемся собрать вместе Python и нашу рабочую книгу Cars для создания Pandas DataFrame.
Импорт библиотек Python
Откройте ваш текстовый редактор и создайте новый файл Python. Давайте назовем это Script.py .
Для работы с Pandas в вашем скрипте вам необходимо импортировать его в свой код. Это делается с помощью одной строки кода:
Здесь мы загружаем библиотеку Pandas и присоединяем ее к переменной «pd». Вы можете использовать любое имя, какое захотите, мы используем pd как сокращение от Pandas.
Для работы с Excel с использованием Pandas вам необходим дополнительный объект с именем ExcelFile . ExcelFile встроен в экосистему Pandas, поэтому вы импортируете напрямую из Pandas:
Работа с путем к файлу
Вспомните наш путь в этом примере: /Users/grant/Desktop/Cars.xlsx
Вам потребуется этот путь к файлу, указанный в вашем скрипте, для извлечения данных. Вместо того чтобы ссылаться на путь внутри функции Read_Excel, сохраняйте код чистым, сохраняя путь в переменной:
Теперь вы готовы извлечь данные с помощью функции Pandas!
Извлечение данных Excel с помощью Pandas.Read_Excel ()
После импорта Pandas и установки переменной пути теперь вы можете использовать функции в объекте Pandas для выполнения нашей задачи.
Функция, которую вам нужно будет использовать, имеет соответствующее имя Read_Excel . Функция Read_Excel берет путь к файлу книги Excel и возвращает объект DataFrame с содержимым книги. Панды кодируют эту функцию как:
Аргумент «путь» будет путем к нашей книге Cars.xlsx, и мы уже установили строку пути к переменной Cars_Path.
Вы готовы создать объект DataFrame! Давайте соберем все вместе и установим объект DataFrame в переменную с именем «DF»:
Наконец, вы хотите просмотреть DataFrame, поэтому давайте распечатаем результат. Добавьте оператор print в конец вашего скрипта, используя переменную DataFrame в качестве аргумента:
Время запустить скрипт в вашем терминале!
Запуск скрипта Python
Откройте свой терминал или командную строку и перейдите в каталог, в котором находится ваш скрипт. В этом случае у меня есть «Script.py», расположенный на рабочем столе. Чтобы выполнить скрипт, используйте команду python, за которой следует файл скрипта:

Python вытянет данные из «Cars.xlsx» в ваш новый DataFrame и распечатает DataFrame в терминал!

Пристальный взгляд на объект DataFrame
На первый взгляд, DataFrame выглядит очень похоже на обычную таблицу Excel. В результате Pandas DataFrames легко интерпретировать.
Ваши заголовки помечены в верхней части набора данных, и Python заполнил строки всей вашей информацией, прочитанной из книги «Cars.xlsx».
Обратите внимание на крайний левый столбец, индекс начинается с 0 и нумеруется. Pandas будет применять этот индекс к вашему DataFrame по умолчанию, что может быть полезно в некоторых случаях. Если вы не хотите, чтобы этот индекс генерировался, вы можете добавить дополнительный аргумент в ваш код:
Установка аргумента «index» в значение False приведет к удалению столбца индекса, в результате чего останутся только ваши данные Excel.
Делать больше с Python
Теперь, когда у вас есть возможность читать данные из таблиц Excel, вы можете применять программирование на Python любым способом, который выберете. Работа с Pandas — это простой способ для опытных программистов на Python работать с данными, хранящимися в книгах Excel.
Простота использования Python для анализа и манипулирования данными является одной из многих причин, почему Python является языком программирования будущего
Читайте также: