
Какой процесс позволяет записывать файлы в кластеры последовательно идущие друг за другом
Обновлено: 04.07.2024
Форматирование дисков. Для того чтобы на диске можно было хранить информацию, диск должен быть отформатирован, то есть должна быть создана физическая и логическая структура диска.
Формирование физической структуры диска состоит в создании на диске концентрических дорожек, которые, в свою очередь, делятся на секторы. Для этого в процессе форматирования магнитная головка дисковода расставляет в определенных местах диска метки дорожек и секторов.
- информационная емкость сектора - 512 байтов;
- количество секторов на дорожке - 18;
- дорожек на одной стороне - 80;
- сторон - 2.
| Рис 4.24. Физическая структура дискеты |
Логическая структура гибких дисков. Логическая структура магнитного диска представляет собой совокупность секторов (емкостью 512 байтов), каждый из которых имеет свой порядковый номер (например, 100). Сектора нумеруются в линейной последовательности от первого сектора нулевой дорожки до последнего сектора последней дорожки.
На гибком диске минимальным адресуемым элементом является сектор.
При записи файла на диск будет занято всегда целое количество секторов, соответственно минимальный размер файла - это размер одного сектора, а максимальный соответствует общему количеству секторов на диске.
Файл записывается в произвольные свободные сектора, которые могут находиться на различных дорожках. Например, Файл_1 объемом 2 Кбайта может занимать сектора 34, 35 и 47, 48, а Файл_2 объемом 1 Кбайт - сектора 36 и 49.
| Таблица 1.4. Логическая структура гибкого диска формата 3,5" (2-я сторона) |
Для того чтобы можно было найти файл по его имени, на диске имеется каталог, представляющий собой базу данных.
Запись о файле содержит имя файла, адрес первого сектора, с которого начинается файл, объем файла, а также дату и время его создания (табл. 4.5).
| Таблица 4.5. Структура записей в каталоге |
Полная информация о секторах, которые занимают файлы, содержится в таблице размещения файлов (FAT - File Allocation Table). Количество ячеек FAT соответствует количеству секторов на диске, а значениями ячеек являются цепочки размещения файлов, то есть последовательности адресов секторов, в которых хранятся файлы.
Например, для двух рассмотренных выше файлов таблица FAT с 1 по 54 сектор принимает вид, представленный в табл. 4.6.
| Таблица 4.6. Фрагмент FAT |
Для размещения каталога - базы данных и таблицы FAT на гибком диске отводятся секторы со 2 по 33. Первый сектор отводится для размещения загрузочной записи операционной системы. Сами файлы могут быть записаны, начиная с 34 сектора.
Виды форматирования. Существуют два различных вида форматирования дисков: полное и быстрое форматирование. Полное форматирование включает в себя как физическое форматирование (проверку качества магнитного покрытия дискеты и ее разметку на дорожки и секторы), так и логическое форматирование (создание каталога и таблицы размещения файлов). После полного форматирования вся хранившаяся на диске информация будет уничтожена.
Быстрое форматирование производит лишь очистку корневого каталога и таблицы размещения файлов. Информация, то есть сами файлы, сохраняется и в принципе возможно восстановление файловой системы.
1. В контекстном меню выбрать пункт Форматировать. Откроется диалоговая панель Форматирование. С помощью переключателя Способ форматирования выбрать пункт Полное.
В поле Метка можно ввести название диска. Для получения сведения о результатах форматирования установить флажок Вывести отчет о результатах. Щелкнуть по кнопке Начать.
2. После окончания форматирования диска появится информационная панель Результаты форматирования.
Вы увидите, что доступный для размещения данных информационный объем диска оказался равен 1 459 664 байта (2047 секторов), а системные файлы и поврежденные сектора отсутствуют.
В целях защиты информации от несанкционированного копирования можно задавать нестандартные параметры форматирования диска (количество дорожек, количество секторов и др.). Такое форматирование возможно в режиме MS-DOS.
1. Ввести команду [Программы-Сеанс MS-DOS]. Появится окно приложения Сеанс MS-DOS.
2. Ввести команду нестандартного форматирования гибкого диска А:, на котором будет 79 дорожек и 19 секторов на каждой дорожке:
Информационная емкость гибких дисков. Рассмотрим различие между емкостью неформатированного гибкого магнитного диска, его информационной емкостью после форматирования и информационной емкостью, доступной для записи данных.
Заявленная емкость неформатированного гибкого магнитного диска формата 3,5" составляет 1,44 Мбайт.
Рассчитаем общую информационную емкость отформатированного гибкого диска:
Количество секторов: N = 18 х 80 х 2 = 2880.
512 байт х N = 1 474 560 байт = 1 440 Кбайт = 1,40625 Мбайт.
Однако для записи данных доступно только 2847 секторов, то есть информационная емкость, доступная для записи данных, составляет:
512 байт х 2847 = 1 457 664 байт = 1423,5 Кбайт » 1,39 Мбайт.
Логическая структура жестких дисков. Логическая структура жестких дисков несколько отличается от логической структуры гибких дисков. Минимальным адресуемым элементом жесткого диска является кластер, который может включать в себя несколько секторов. Размер кластера зависит от типа используемой таблицы FAT и от емкости жесткого диска.
На жестком диске минимальным адресуемым элементом является кластер, который содержит несколько секторов.
Таблица FAT16 может адресовать 2 16 = 65 536 кластеров. Для дисков большой емкости размер кластера оказывается слишком большим, так как информационная емкость жестких дисков может достигать 150 Гбайт.
Например, для диска объемом 40 Гбайт размер кластера будет равен:
40 Гбайт/65536 = 655 360 байт = 640 Кбайт.
Файлу всегда выделяется целое число кластеров. Например, текстовый файл, содержащий слово "информатика", составляет всего 11 байтов, но на диске этот файл будет занимать целиком кластер, то есть 640 Кбайт дискового пространства для диска емкостью 150 Гбайт. При размещении на жестком диске большого количества небольших по размеру файлов они будут занимать кластеры лишь частично, что приведет к большим потерям свободного дискового пространства.
Эта проблема частично решается с помощью использования таблицы FAT32, в которой объем кластера принят равным 8 секторам или 4 килобайтам для диска любого объема.
В целях более надежного сохранения информации о размещении файлов на диске хранятся две идентичные копии таблицы FAT.
Преобразование FAT16 в FAT32 можно осуществить с помощью служебной программы Преобразование диска в FAT32, которая входит в состав Windows.
Дефрагментация дисков. Замедление скорости обмена данными может происходить в результате фрагментации файлов. Фрагментация файлов (фрагменты файлов хранятся в различных, удаленных друг от друга кластерах) возрастает с течением времени, в процессе удаления одних файлов и записи других.
Так как на диске могут храниться сотни и тысячи файлов в сотнях тысяч кластеров, то фрагментированность файлов будет существенно замедлять доступ к ним (магнитным головкам придется постоянно перемещаться с дорожки на дорожку) и в конечном итоге приводить к преждевременному износу жесткого диска. Рекомендуется периодически проводить дефрагментацию диска, в процессе которой файлы записываются в кластеры, последовательно идущие друг за другом.
1. Для запуска программы Дефрагментация диска, необходимо из Главного меню ввести команду [Стандартные-Служебные-Дефрагментация диска].
2. Диалоговая панель Выбор диска позволяет выбрать диск, нуждающийся в процедуре дефрагментации. После нажатия кнопки ОК появится петель Дефрагментация диска.
3. Процесс дефрагментации диска можно визуально наблюдать, если щелкнуть по кнопке Сведения. Каждый квадратик соответствует одному кластеру, при этом неоптимизированные, уже оптимизированные, а также считываемые и записываемые в данный момент кластеры имеют различные цвета.
- на гибком магнитном диске;
- на жестком магнитном диске.
2. Какова последовательность размещения файла Файл_2 из приведенного примера на секторах гибкого диска?
3. Почему различаются величины емкости отформатированного диска и информационной емкости, доступной для записи данных?
4. Чем различаются полное и быстрое форматирование диска?
5. Чем различаются таблицы размещения файлов FAT16 и FAT32?
6. С какой целью необходимо периодически проводить дефрагментацию жестких дисков?
4.14. Отформатировать гибкий диск с нестандартными параметрами.
4.15. Вычислить объем кластера вашего жесткого диска в системе FAT16.
4.16. С помощью служебной программы Сведения о системе определить тип FAT, используемый на ваших дисках.
4.17. С помощью служебной программы Проверка диска провести проверку целостности файловой системы.
4.18. С помощью служебной программы Дефрагментация диска провести дефрагментацию дисков вашего компьютера.

100 баллов)1. Дан ряд утверждений. Выберите неверное утверждение.Наименьшая составная часть таблицы – ячейка.Столбцом называются две ячейки, находящие … ся в середине таблицы.Горизонтальный ряд ячеек, от одного края таблицы до другого, образует строку2. Какую форму представления информационной модели следует выбрать при описании объекта, который обладает одинаковыми наборами свойств?Таблицу «объект — объект»ДеревоВзвешенный графТаблицу «объект — свойство»3. Какую форму представления информационной модели необходимо использовать, если нужно отразить взаимосвязь между объектами одного или нескольких классов?ДеревоТаблицу «объект — объект»Таблицу «объект — свойство»Взвешенный граф4. Примером какой модели является расписание движения поездов?Графической информационной моделиМатематической информационной моделиКомпьютерной информационной моделиТабличной информационной модели5. Какие из примеров можно отнести к табличным информационным моделям?Расписание уроковСписок гостейТаблица умноженияАлфавит6. Как называется матрица, состоящая из нулей и единиц? Ответ введите строчными буквами.7. Как называется табличная информационная модель, отражающая качественный характер связей между объектами (есть дорога – нет дороги, посещает – не посещает и так далее)? Ответ введите строчными буквами.8. Что содержит в себе двоичная матрица?Цифры и числаЕдиницы и двойкиНули и единицыДве строки9. Что представляет собой табличная информационная модель?Описание иерархической структуры строения моделируемого объекта.Систему математических формул.Описание объектов (или их свойств) в виде совокупности значений, размещаемых в таблице.Последовательность предложений на естественном языке.Набор графиков, рисунков, чертежей, схем, диаграмм.10. Информационной моделью, которая имеет табличную структуру, НЕ является:столицы стран мирасхема метрорасписание поездовсписок класса11. К какому типу относится таблица – информационная модель «Баскетбольная секция»?СпортсменДата рожденияРостВесИванов02.02.199918175Сидоров30.03.200117070--------------------------------Объект – объектМатрицаОбъект – свойствоДвоичная матрица12. Отметьте текст с одиночными свойствами объекта.Расстояние от школы до городского парка культуры и отдыха – 1 км.Расстояние между планетами Солнечной системы различно.Столица Германии – Берлин.Средний балл учащихся 6-го класса по информатике – 4,5.13. Что содержит в себе форма информационной модели таблица типа «объект – свойства»?Информацию о свойствах однородных объектов.Информацию обо всех свойствах одного объекта.Информацию о свойствах неоднородных объектов.14. К какой форме информационной модели можно отнести таблицу, в которой содержится информация о расстояниях между городами?Таблице типа «объект – объект»Двоичной матрицеТаблице типа «объект – свойства»15. Какую информацию следует представлять в таблице типа «объект – объект»?Расстояния между планетами Солнечной системы.Информацию о городских достопримечательностях.Сведения о морях, расположенных на территории России.Сведения о погоде за определённый месяц.
Конспект информатика 7 класс программное обеспечение компьютера
помогите срочняк пжпжпж, информатика 7 классЭти 2 вопроса пожалуйста
ПОЖАЛУЙСТА ПОМОГИТЕ ОЧЕНЬ СРОЧНО Черепашке был дан для Повтори 11 [Вперёд 40 Налево 15 Налево зо] Какая фигура появится на экране? 1) правильный шести … угольник 2) правильный восьмиугольник 3) правильный девятиугольник 4) незамкнутая ломаная линия Ответ:
В своей дипломной работе я проводил обзор и сравнительный анализ алгоритмов кластеризации данных. Подумал, что уже собранный и проработанный материал может оказаться кому-то интересен и полезен.
О том, что такое кластеризация, рассказал sashaeve в статье «Кластеризация: алгоритмы k-means и c-means». Я частично повторю слова Александра, частично дополню. Также в конце этой статьи интересующиеся могут почитать материалы по ссылкам в списке литературы.
Так же я постарался привести сухой «дипломный» стиль изложения к более публицистическому.
Понятие кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта — как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.
После того, как мы определили вектор характеристик, можно провести нормализацию, чтобы все компоненты давали одинаковый вклад при расчете «расстояния». В процессе нормализации все значения приводятся к некоторому диапазону, например, [-1, -1] или [0, 1].
- Евклидово расстояние
Наиболее распространенная функция расстояния. Представляет собой геометрическим расстоянием в многомерном пространстве: - Квадрат евклидова расстояния
Применяется для придания большего веса более отдаленным друг от друга объектам. Это расстояние вычисляется следующим образом: - Расстояние городских кварталов (манхэттенское расстояние)
Это расстояние является средним разностей по координатам. В большинстве случаев эта мера расстояния приводит к таким же результатам, как и для обычного расстояния Евклида. Однако для этой меры влияние отдельных больших разностей (выбросов) уменьшается (т.к. они не возводятся в квадрат). Формула для расчета манхэттенского расстояния: - Расстояние Чебышева
Это расстояние может оказаться полезным, когда нужно определить два объекта как «различные», если они различаются по какой-либо одной координате. Расстояние Чебышева вычисляется по формуле: - Степенное расстояние
Применяется в случае, когда необходимо увеличить или уменьшить вес, относящийся к размерности, для которой соответствующие объекты сильно отличаются. Степенное расстояние вычисляется по следующей формуле:
,
где r и p – параметры, определяемые пользователем. Параметр p ответственен за постепенное взвешивание разностей по отдельным координатам, параметр r ответственен за прогрессивное взвешивание больших расстояний между объектами. Если оба параметра – r и p — равны двум, то это расстояние совпадает с расстоянием Евклида.
Классификация алгоритмов
- Иерархические и плоские.
Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями — наиболее мелкие кластера.
Плоские алгоритмы строят одно разбиение объектов на кластеры. - Четкие и нечеткие.
Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
Объединение кластеров
- Одиночная связь (расстояния ближайшего соседа)
В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки. - Полная связь (расстояние наиболее удаленных соседей)
В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден. - Невзвешенное попарное среднее
В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. - Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров. - Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. - Взвешенный центроидный метод (медиана)
Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Обзор алгоритмов
Алгоритмы иерархической кластеризации
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.
Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:
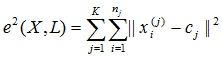
где cj — «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
- Если критерий остановки алгоритма не удовлетворен, вернуться к п. 2.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
- Выбрать начальное нечеткое разбиение n объектов на k кластеров путем выбора матрицы принадлежности U размера n x k.
- Используя матрицу U, найти значение критерия нечеткой ошибки:
,
где ck — «центр масс» нечеткого кластера k:
. - Перегруппировать объекты с целью уменьшения этого значения критерия нечеткой ошибки.
- Возвращаться в п. 2 до тех пор, пока изменения матрицы U не станут незначительными.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E), вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.
Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R. Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R, лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.
Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.
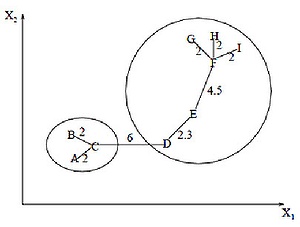
Путём удаления связи, помеченной CD, с длиной равной 6 единицам (ребро с максимальным расстоянием), получаем два кластера: и . Второй кластер в дальнейшем может быть разделён ещё на два кластера путём удаления ребра EF, которое имеет длину, равную 4,5 единицам.
Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c. Например, если расстояние между объектами , то .
Алгоритм послойной кластеризации формирует последовательность подграфов графа G, которые отражают иерархические связи между кластерами:

,

где G t = (V, E t ) — граф на уровне с t ,
,
с t – t-ый порог расстояния,
m – количество уровней иерархии,
G 0 = (V, o), o – пустое множество ребер графа, получаемое при t 0 = 1,
G m = G, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку t m = 1.
Посредством изменения порогов расстояния с 0 , …, с m >, где 0 = с 0 < с 1 < …< с m = 1, возможно контролировать глубину иерархии получаемых кластеров. Таким образом, алгоритм послойной кластеризации способен создавать как плоское разбиение данных, так и иерархическое.
Сравнение алгоритмов
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.
В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.
Отдельно хочу сказать, что для достижения наилучшего результата необходимо экспериментировать с выбором мер расстояний, а иногда даже менять алгоритм. Никакого единого решения не существует.

Программы бухгалтерские, конструкторские, педагогические. Компьютерные игры и т.д.
Это программы, выполняющие роль посредника между пользователем и программным обеспечением компьютера.
Программы, позволяющие пользователю писать, рисовать на компьютере, создавать таблицы, базы данных и т.д.
Программы, позволяющие программисту создавать свои собственные компьютерные программы.
Программа, которая управляет работой всех частей компьютера и ведёт диалог с пользователем компьютера.
Прикладное программное обеспечение – это:
справочное приложение к программам
текстовый и графический редакторы, обучающие и тестирующие программы, игры
набор игровых программ
Системное программное обеспечение:
программы для организации совместной работы устройств компьютера как единой системы
программы для организации удобной системы размещения программ на диске
набор программ для работы устройства системного блока компьютера
Системные оболочки – это:
специальная кассета для удобного размещения дискет с операционной системой
специальная программа, упрощающая диалог пользователь – компьютер, выполняет команды операционной системы
система приемов и способов работы конкретной программы при загрузке программ и завершении работы
Конфигурация устройств и программы диагностики работоспособности компьютера это:
Интерфейс - это
механизм взаимодействия систем (техническое и информационное согласование, регламент)
набор программ, выполняющих прикладные задачи пользователя
справочное приложение к программ
Сервисное ПО - это:
Набор утилит, которые позволяют пользователю управлять ресурсами компьютера
Набор программ, выполняющих прикладные задачи пользователя
Программы, предназначенные для создания других программ
Какой процесс позволяет записывать файлы в кластеры, последовательно идущие друг за другом?
а) форматирование b) фрагментация
с) дефрагментация d) установка драйвера
Файл ежик.bmp находится в папке Животные, вложенной в папку Картинки. Папка Картинки находится на диске D. Укажите полное имя файла.
а) D:\Картинки \Животные\ ежик.bmp b) D:/Картинки /Животные/ежик.bmp
с) D:\ Картинки \ ежик.bmp d) D:\Животные\ ежик.bmp
Читайте также: