
Какой уровень иерархической модели сети как правило содержит сетевой трафик между компьютером
Обновлено: 07.07.2024
B последние годы специалисты в области локальных сетей все чаще склоняются к тому, что сети с сотнями, тысячами или даже десятками тысяч узлов должны быть структурированы в соответствии с иерархической моделью, превосходство которой перед плоской, неиерархической, моделью кажется убедительным.
Казалось бы, после замены медленных маршрутизаторов на более производительные коммутаторы третьего уровня ничто больше не сможет помешать распространению этой модели. Однако удешевление коммутаторов способствует выбору в пользу решений полностью на базе второго уровня. Преимущества структурированных сетей при этом игнорируются.
ПРЕИМУЩЕСТВА ИЕРАРХИЧЕСКОЙ МОДЕЛИ
В иерархической модели вся сеть делится на несколько уровней, работа с которыми производится по отдельности. Это весьма облегчает постановку задач при проектировании, поскольку каждый отдельный уровень можно реализовать в соответствии со специфическими требованиями определенной области охвата. Уменьшение размеров подсетей позволяет добиться снижения числа коммуникационных связей каждого конечного устройства. Так, например, широковещательные «штормы» быстро растут вместе с увеличением числа систем в плоской сети.
Ответственность за обслуживание отдельных подобластей сетевого дерева в иерархической модели легко делегируется без каких-либо серьезных проблем с интерфейсом, что невозможно в случае плоской сети. Кроме того, наглядность сетевой структуры в случае иерархической модели также оправдывает себя при поиске ошибок. При иерархическом построении сети различного рода изменения реализовать гораздо проще, поскольку, как правило, они затрагивают лишь часть системы. В плоской же модели они способны повлиять на всю сеть. Это обстоятельство значительно упрощает наращивание иерархических сетей: оно реализуется добавлением новой сетевой области к существующему уровню или следующего уровня без необходимости перекройки всей структуры.
ОТ МАРШРУТИЗАЦИИ К КОММУТАЦИИ НА ТРЕТЬЕМ УРОВНЕ
Долгое время успешному распространению иерархической схемы построения сети мешали высокая стоимость и низкая производительность имеющихся устройств. Классические маршрутизаторы не могли соперничать с коммутаторами второго уровня ни по скорости передачи пакетов, ни по стоимости портов. Реализация необходимой комбинации маршрутизации и коммутации второго уровня на практике оказалась проблематичной. Поэтому на многих предприятиях выбор для коммуникаций в пределах подсетей IP или виртуальных локальных сетей (Virtual Local Area Network, VLAN) был сделан в пользу комбинированной коммутации кадров второго уровня и АТМ. Между тем высокопроизводительного оборудования для коммуникаций по IP между виртуальными сетями не было. Оно наконец-то стало доступным с появлением коммутации на третьем уровне (с исправлением первоначальных недостатков ее можно теперь считать вполне зрелой).
Коммутаторы третьего уровня осуществляют маршрутизацию каждого пакета в отдельности с помощью специализированных интегральных схем (Applications Specific Integrated Circuit, ASIC), при этом они анализируют содержимое пакетов и принимают решения о выборе пути на основе информации с более высоких уровней. Коммуникация между VLAN происходит так же быстро, как и внутри, т. е. с максимальной пропускной способностью сети. На рынке уже появились продукты со скоростью передачи до 100 млн пакетов в секунду.
Замена имеющихся маршрутизаторов на коммутаторы третьего уровня осуществляется очень просто: заменить требуется только соответствующие устройства. Все навыки и потенциал ноу-хау, накопленный за годы эксплуатации маршрутизаторов, могут быть использованы в дальнейшей работе.
Коммутаторы второго и третьего уровней в настоящее время мало чем отличаются друг от друга в плане производительности, поэтому вопрос выбора типа устройства зависит — наряду с функциональностью — от стоимости портов. Вместе с тем, даже несмотря на заметное удешевление коммутаторов третьего уровня, простые коммутаторы второго уровня по-прежнему стоят намного меньше. Тем самым область применения первых — главным образом сетевые магистрали, а последних — рабочие группы.
ЧЕТКОЕ ЛОКАЛЬНОЕ ПОДЧИНЕНИЕ
Связанная с коммутацией второго уровня технология виртуальных локальных сетей появилась вследствие стремления свести к минимуму коммуникации между подсетями IP, поскольку они осуществляются по медленным соединениям с маршрутизаторами. Увеличить долю коммуникаций внутри VLAN и снизить таковую между VLAN можно путем отображения на виртуальные локальные сети подсетей IP и выделенных организационных структур. При этом одна и та же подсеть может распространяться на несколько зданий — как правило, для виртуальных локальных сетей география не имеет никакого значения.
Коммутация третьего уровня все же дает шанс на последовательное претворение в жизнь иерархических принципов построения сети. Тем самым особое значение снова приобретает вопрос о так называемом плоском или иерархическом подходе. Логическая структура плоской неструктурированной сети соответствует представленной на Рисунке 1 схеме. Связь между местоположением конечных устройств и их IP-адресами отсутствует. Третий октет IP-адреса (на рисунке: «1», «2» или «3») не дает никакой информации о расположении конечного устройства.
Альтернативой может быть инфраструктура третьего уровня в ядре сети с подключенными коммутаторами второго уровня, возможно, так, как это представлено на Рисунке 2. Структурированная сеть соответствует изображенной на Рисунке 3 логической схеме, в которой отчетливо прослеживается зависимость между местоположением конечных устройств и их IP-адресами. Третий октет IP-адреса дает точную информацию о том, где находится конечное устройство. В четвертом и последнем октете указываются конкретные конечные устройства.
СТРУКТУРИРОВАННЫЕ СЕТИ ВТОРОГО/ТРЕТЬЕГО УРОВНЕЙ
При исследовании достоинств и недостатков рассматриваемых топологий все-таки можно найти один значительный позитивный аспект плоских сетей второго уровня: при перемещениях оборудования не требуется менять IP-адреса и не надо перенастраивать приложения, в которых IP-адреса используются в качестве идентификационных признаков.
Однако этому можно противопоставить целый ряд преимуществ структурированных сетей второго/третьего уровня:
- отсутствие отрицательных последствий потенциального дублирования IP-адресов для всей сети в целом;
- разделение доменов широковещательной рассылки и, тем самым, значительное снижение нагрузки на конечные устройства;
- повсеместное соответствие адресов сетевого уровня зданиям и коммутаторам: «говорящие» адреса облегчают локализацию возникающих ошибок;
- возможность реализации функций безопасности на границах между подсетями;
- обеспечение нужного качества сервиса на сетевом и транспортном уровнях, например путем определения приоритета для некоторых приложений;
- более эффективное управление широковещательными рассылками благодаря применению маршрутизации широковещательного трафика в коммутаторах третьего уровня;
- значительное сокращение времени, необходимого для обеспечения сходимости при реализации избыточных соединений. К примеру, при первоочередном выборе кратчайшего маршрута (Open Shortest Path First, OSPF) для этого понадобится всего несколько секунд, в то время как протоколу Spanning Tree — от 40 до 50 с. На уровне подсетей IP в качестве механизма избыточности для маршрутизатора по умолчанию можно применять протокол маршрутизатора «горячего» резерва/виртуальный протокол избыточной маршрутизации (Hot Standby Router Protocol/Virtual Router Redundancy Protocol, HSRP/VRRP).
КОНКУРИРУЮЩИЕ ПОДХОДЫ К ДИЗАЙНУ
Структурированная сеть второго/третьего уровня, по-видимому, лучше всего подходит для обеспечения безопасной и стабильной работы даже в крупных сетях. К таким выводам приходят практически все архитекторы сетей, однако в последнее время немало приверженцев получают новый подход к дизайну сети, в основу которого положены исключительно коммутаторы второго уровня. Это связано с тем, что многие предприятия вынуждены искать возможности для уменьшения инвестиций, в том числе и в локальные сети.
Подобные концепции базируются преимущественно на применении недорогих коммутаторов второго уровня и заключаются в составлении из них, к примеру, кольцевой структуры. Механизм реализации избыточности в кольцевых структурах опирается на протокол Rapid Spanning Tree. Этот подход поддерживается стандартом IEEE 802.1w, где определена быстрая реконфигурация покрывающего дерева, целью разработки которого было сокращение до нескольких секунд времени сходимости протокола Spanning Tree, пользующегося за свою медлительность дурной славой.
Подобные «недорогие» схемы, где модель иерархической сетевой структуры остается за бортом, на первый взгляд выглядят привлекательными: экономия исчисляется в десятках процентов. Однако умеренный скепсис не повредит. Дешевые коммутаторы второго уровня должны иметь стабильные коды для поддержки Rapid Spanning Tree. Однако это кажется очень смелым предположением с учетом того, сколько времени потребовалось, чтобы исходный алгоритм стал работать более-менее стабильно. К тому же нельзя забывать, что малое значение времени сходимости при наличии избыточных соединений — всего лишь одна из причин, по которым применяется инфраструктура третьего уровня. А как же тогда «говорящие» IP-адреса, защита от ошибочно заданных адресов, сокращение широковещательного трафика и более эффективное управление широковещательным трафиком в сетях на третьем уровне?
При такой точке зрения ценовый аспект приобретает относительный характер, ведь, в конце концов, эти два подхода к сетевому дизайну нельзя сравнивать. Конечно же, полностью избыточный дизайн с топологией «двойная звезда» стоит гораздо больше каскадной структуры с недорогими компонентами. Впрочем, проект сети с применением устройств третьего уровня тоже можно несколько удешевить: вовсе не обязательно брать за основу аппаратное обеспечение «с избытком». Это поможет построить сеть третьего уровня и сэкономить при этом порядка 35% ее стоимости.

Рассмотрим следующую схему трёхуровневой иерархической модели, которая используется во многих решениях построения сетей:
Распределение объектов сети по уровням происходит согласно функционалу, который выполняет каждый объект, это помогает анализировать каждый уровень независимо от других, т.е. распределение идёт в основном не по физическим понятиям, а по логическим.
Базовый уровень (Core)
На уровне ядра необходима скоростная и отказоустойчивая пересылка большого объема трафика без появления задержек. Тут необходимо учитывать, что ACL и неоптимальная маршрутизация между сетями может замедлить трафик.
Обычно при появлении проблем с производительностью уровня ядра приходиться не расширять, а модернизировать оборудование, и иногда целиком менять на более производительное. Поэтому лучше сразу использовать максимально лучшее оборудование не забывая о наличии высокоскоростных интерфейсов с запасом на будущее. Если применяется несколько узлов, то рекомендуется объединять их в кольцо для обеспечения резерва.
На этом уровне применяют маршрутизаторы с принципом настройки — VLAN (один или несколько) на один узел уровня Distribution.
Уровень распространения (Distribution)
Тут происходит маршрутизация пользовательского трафика между сетями VLAN’ов и его фильтрация на основе ACL. На этом уровне описывается политика сети для конечных пользователей, формируются домены broadcast и multicast рассылок. Также на этом уровне иногда используются статические маршруты для изменения в маршрутизации на основе динамических протоколов. Часто применяют оборудование с большой ёмкостью портов SFP. Большое количество портов обеспечит возможность подключения множества узлов уровня доступа, а интерфейс SFP предоставит выбор в использовании электрических или оптических связей на нижестоящий уровень. Также рекомендуется объедение нескольких узлов в кольцо.
Часто применяются коммутаторы с функциями маршрутизации (L2/3) и с принципом настройки: VLAN каждого сервиса на один узел уровня Access.
Уровень доступа (Access)
К уровню доступа непосредственно физически присоединяются сами пользователи.
Часто на этом уровне трафик с пользовательских портов маркируется нужными метками DSCP.
Тут применяются коммутаторы L2 (иногда L2/3+) с принципом настройки: VLAN услуги на порт пользователя + управляющий VLAN на устройство доступа.
Практическое применение сетевых технологий в трёхуровневой модели
При рассмотрении следующих технологий используется оборудование уровня ядра и распределения Cisco Catalyst, а для уровня доступа — D-Link DES. На практике такое разделение брендов часто встречается из-за разницы в цене, т.к. на уровень доступа в основном необходимо ставить большое количество коммутаторов, наращивая ёмкость портов, и не все могут себе позволить, чтобы эти коммутаторы были Cisco.

Соберём следующую схему:
Схема упрощена для понимания практики: каждое ядро включает в себя только по одному узлу уровня распределения, и на каждый такой узел приходится по одному узлу уровня доступа.
На практике при больших масштабах сети смысл подобной структуры в том, что трафик пользователей с множества коммутаторов уровня доступа агрегируется на родительском узле распределения, маршрутизируется или коммутируется по необходимости на вышестоящее ядро, на соседний узел распределения или непосредственно между самими пользователями с разных узлов доступа. А каждое ядро маршрутизирует или коммутирует трафик между несколькими узлами распределения, которые непосредственно включены в него, или между соседними ядрами.
VLAN — Virtual Local Area Network
- разделить одно физическое устройство (коммутатор) на несколько логических по уровню L2
- если назначить подсети различным VLAN'ам, то хосты подключенные в одно и тоже устройство (содержащее несколько VLAN'ов) будут иметь различные подсети, также можно хосты с разных устройств объединять в одни подсети
- сегментация трафика VLAN'ами приводит к образованию независимых широковещательных доменов, тем самым уменьшая количество широковещательного трафика на сети в целом
- разделение трафика на VLAN'ы также обеспечивает безопасность между разными сетями

Распределим VLAN'ы по схеме:
Начнём с уровня доступа.
На коммутаторе DES_1 (D-Link) создадим VLAN 100 для управления:
create vlan 100 tag 100
Добавим его тегированным на 25 порт:
config vlan 100 add tagged 25
Лучше запретить управляющий VLAN на портах (1-24), к которым подключаются пользователи:
config vlan 100 add forbidden 1-24
Дефолтный VLAN устройства удалим:
config vlan default delete 1-26
Поставим IP адрес коммутатора в управляющий VLAN:
config ipif System vlan 100 ipaddress 172.16.0.2/24 state enable
Пропишем шлюз, которым будет являться логический интерфейс устройства на вышестоящем уровне распределения:
create iproute default 172.16.0.1 1
Создадим VLAN 500, в котором предоставляется сервис DHCP (сам DHCP сервер будет находиться на уровне распределения) и сделаем его нетегированным на пользовательских портах (1-24) и тегированным на аплинке (25):
create vlan 500 tag 500
config vlan 500 add untagged 1-23
config vlan 500 add tagged 25
На DES_2 все те же настройки, кроме IP адреса (172.16.1.2) и шлюза (172.16.1.1).
Теперь перейдём к уровню распределения.
Настраиваем Cat_1.
Если мы используем коммутатор Catalyst, то VLAN'ы создаются в режиме конфигурации ( conf t ) следующим образом:
Vlan <список VLAN’ов через запятую>
Предварительно лучше VTP переключить в прозрачный режим:
vtp mode transparent
Необходимо создать три VLAN'а: управление узлами доступа – VLAN 100, для связи между Cat_1 и Core_1 — VLAN 20 и у нас один узел доступа на каждый уровень распределения, поэтому для сервиса DHCP создаётся один VLAN – 500, на реальной сети нужно на каждый коммутатор доступа по своему VLAN'у с DHCP:
Vlan 100,20,500
Если на порту уже есть какие-то VLAN'ы, то необходимо использовать команду: switchport trunk allowed vlan add <список VLAN’ов> , т.к. если не указать add , то уже существующие VLAN’ы пропадут.
Теми же командами добавляем VLAN’ы 100, 500 на gi 0/2 к которому подключен DES_1.
Cat_2 настраиваем так же, только меняем адреса в VLAN'ах 100 и 20. VLAN 100 – 172.16.1.1 255.255.255.0, VLAN 20 – 10.20.0.2 255.255.255.248
На Core_1 создаём VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_2 и 20 на интерфейс gi 0/2, к которому подключен узел уровня распределения, ставим IP адреса: VLAN 10 – 10.0.0.1 255.255.255.248, VLAN 20 – 10.10.0.1 255.255.255.248.
На Core_2 создаём также VLAN’ы 10 и 20, добавляем 10 на gi 0/1, куда подключен Core_1 и 20 на интерфейс gi 0/2, к которому подключен Cat_2, ставим IP адреса: VLAN 10 – 10.0.0.2 255.255.255.248, VLAN 20 – 10.20.0.1 255.255.255.248.
DHCP — Dynamic Host Configuration Protocol
Для Cat_2 делаем по аналогии, используя в VLAN'е 500 сеть 192.168.1.0 255.255.255.224
После этого пользователи DES_1 и DES_2 будут получать адреса по DHCP.
OSPF — Open Shortest Path First
OSPF — удобный протокол динамической маршрутизации с учётом состояния каналов. Он позволяет составить полную схему сети, а затем выбрать на основе этого оптимальный маршрут. Функционирование основано на получении данных о состоянии сетевых связей или каналов. Подробное описание есть в википедии. Мы будем использовать именно этот протокол.

В реальной сети каждое ядро содержит area 0 (для связи с другими ядрами) и несколько других зон, в которые входят узлы уровня распределения. Эти узлы в пределах одной зоны удобно объединять в кольца, благодаря чему будет резерв и оптимальная маршрутизация. Например, это может выглядеть так:

Определим зоны в нашей сети:
Обычно прописывают ещё вручную Router-id (идентификатор маршрутизатора), указывая при этом IP адрес этого маршрутизатора. Если этого не делать, то Router-id будет выбран автоматически.
На Core_2 делаем всё точно также как и на Core_1.
5 — это метрика для перераспределённого маршрута
1 – это тип внешней метрики – OSPF
После этой команды все сети в VLAN'ах Cat_1 будут доступны через ospf.
Редистрибьюцию пользовательских сетей DHCP также можно сделать через route-map и access-list или целиком указать в network x.x.x.x x.x.x.x area x. Всё это зависит от того, как и что нужно анонсировать в маршрутизации по сети.
Cat_2 настраиваем аналогично, только в area 10 надо указать network 10.20.0.0 0.0.0.7
По сути, теперь мы имеем работающую сеть, в которой пользователи с разных коммутаторов уровня доступа смогут обмениваться трафиком.
STP — Spanning Tree Protocol
- на сети выбирается root bridge
- все не root узлы вычисляют оптимальный путь к root bridge, и порт (через который проходит этот путь) становится root port
- если путь к root bridge проходит через какой то узел, то такой узел сети становиться designated bridge и порт соответственно designated port
- порты, участвующие в дереве stp и не являющиеся root или designated блокируются
После этого Core_2 станет root bridge, а один из портов Cat_3 или Cat_2 заблокируется для передачи трафика по VLAN'у 20 в сторону Core_2. Если необходимо указать, чтобы определённый VLAN не участвовал в STP, то делается это такой командой:
no spanning-tree vlan <имя_VLAN'а>
Следует заметить, что BPDU пакеты Cisco и D-Link, при помощи которых строится STP, не совместимы между собой, поэтому stp между оборудованием этих двух производителей скорее всего построить будет очень затруднительно.
SNMP — Simple Network Management Protocol
SNMP – протокол простого управления сетью. При помощи него как правило собирается статистика работы оборудования, и он часто используется при автоматизации выполнения каких-либо операций на этом оборудовании.
На узлах всех уровней определим community, которое определяет доступ к узлу на read или write по этому протоколу, при условии, что это community совпадает у источника и получателя.
На Cisco:
Read — snmp-server community <название_snmp_community> RO
Write — snmp-server community <название_snmp_community> RW
Название snmp_community чувствительно к регистру.
На D-link:
Удаляем всё дефолтное:
delete snmp community public
delete snmp community private
delete snmp user initial
delete snmp group initial
delete snmp view restricted all
delete snmp view CommunityView all
Создаём community на read — DLINK_READ и на write — DLINK_WRITE:
create snmp view CommunityView 1 view_type included
create snmp group DLINK_READ v1 read_view CommunityView notify_view CommunityView
create snmp group DLINK_READ v2c read_view CommunityView notify_view CommunityView
create snmp group DLINK_WRITE v1 read_view CommunityView write_view CommunityView notify_view CommunityView
create snmp group DLINK_WRITE v2c read_view CommunityView write_view CommunityView notify_view CommunityView
create snmp community DLINK_READ view CommunityView read_only
create snmp community DLINK_WRITE view CommunityView read_write
ACL — Access Control List
Списки контроля доступа – это условия, которые проходят проверку при выполнении каких-либо операций.
ACL используется в связке со многими протоколами и сетевыми механизмами, фильтруя трафик на интерфейсах и протоколах NTP, OSPF и других.
Тем самым запретив на int vlan500 Cat_2 входящий трафик ip и udp от 192.168.0.0 255.255.255.224 на любой адрес.
NTP — Network Time Protocol
Cisco:
Синхронизация внутреннего времени узла с внешним сервером (можно использовать несколько серверов):
ntp server <IP вашего NTP сервера>
Указание часового пояса (GMT +3):
clock timezone MSK 3
Начальная и конечная дата перехода на летнее время:
clock summer-time MSK recurring last Sun Mar 2:00 last Sun Oct 3:00
Эти команды следует выполнить на всех узлах сети, либо указать на роутере ядра ntp master и остальные узлы синхронизировать с ним.
Также можно указать время вручную:
clock set 18:00:00 20 Feb 2011
Но это делать крайне не рекомендуется — лучше использовать NTP.
D-Link:
Используем SNTP – более простая версия NTP.
Включаем SNTP:
enable sntp
Указание часового пояса (GMT +3):
config time_zone operator + hour 3 min 0
Задаём NTP сервера:
config sntp primary <IP вашего NTP сервера_1> secondary <IP вашего NTP сервера_2> poll-interval 600
poll-interval — интервал времени в секундах между запросами на обновление SNTP информации.
Начальная и конечная дата перехода на летнее время:
config dst repeating s_week 1 s_day sun s_mth 4 s_time 0:3 e_week last e_day sun e_mth 10 e_time 0:3 offset 60
Мы рассмотрели теорию трёхуровневой модели сети и некоторые базовые технологии, которые помогут в изучении таких сетей.
Вопрос 3
ISR имеет общий IP-адрес, выданный ISP. Каково назначение общего IP-адреса?
a. позволяет внутренним хостам обмениваться данными с другими хостами в Интернет
b. позволяет внутренним хостам обмениваться данными друг с другом в локальной сети
c. позволяет ISR обмениваться данными с локальными хостами в сети
Вопрос 4
Укажите, какое устройство относят к устройствам хранения информации:
Вопрос 5
Вопрос 6
Гиперссылки на web-странице могут обеспечить переход:
Вопрос 7
Вопрос 8
Вопрос 9
Вопрос 10
a. документ, в котором хранится вся информация по сети
b. документ специального формата, опубликованный в Internet
Вопрос 11
Вопрос 12
Вопрос 13
Вопрос 14
Вопрос 15
Какое утверждение является истинным в отношении адресов в частной сети?
a. они обеспечивают легкий доступ внешних пользователей к внутренним веб-серверам
b. они могут одновременно использоваться только одной компанией
c. они являются более защищенными, поскольку они видимы только для локальной сети
Вопрос 16
Какое сокращение связано с использованием телефонной связи через сеть «Интернет»?
Вопрос 17
Как называются программы, позволяющие просматривать Web- страницы:
Вопрос 18
Вопрос 19
Услуга по размещению и хранению файлов клиента на сервере организации, предоставляющей подобную услугу – это:
Вопрос 20
Вопрос 21
Вопрос 22
Для передачи в сети web-страниц используется протокол:
Вопрос 23
Компьютер, подключенный к сети «Internet», обязательно имеет:
Вопрос 24
a. часть адреса, определяющая адрес компьютера пользователя в сети
b. название программы, для осуществления связи между компьютерами
c. название устройства, осуществляющего связь между компьютерами
Вопрос 25
Вопрос 26
Вопрос 27
Укажите устройство для подключения компьютера к сети:
Вопрос 28
Какой протокол является базовым протоколом сети «Интернет»?
Вопрос 29
Данный способов подключения к сети «Интернет» обеспечивает наибольшие возможности для доступа к информационным ресурсам:
a. терминальное соединение по коммутируемому телефонному каналу
b. постоянное соединение по выделенному телефонному каналу
Вопрос 30
Какой уровень иерархической модели сети, как правило, содержит сетевой трафик между компьютером и принтером, находящимися в одной сети?
Программное обеспечение коммутаторов D-Link предоставляет набор программных сервисов, предназначенных для выполнения различных функций, обеспечивающих безопасность , отказоустойчивость сети, управление многоадресной рассылкой, качество обслуживания ( QoS ), а также развитые средства настройки и управления. Помимо этого, программное обеспечение коммутаторов взаимодействует с приложениями D-Link D-View v.6, представляющими собой прикладные программы сетевого управления. Эти управляющие программы поддерживаются всей линейкой управляемых коммутаторов D-Link.
Системное программное обеспечение располагается во Flash -памя-ти коммутатора, размер которой, в зависимости от модели, может быть до 32 Мбайт . Компания D-Link предоставляет возможность бесплатного обновления программного обеспечения коммутаторов по мере появления новых версий с обновленным функционалом.
Общие принципы сетевого дизайна
Грамотный сетевой проект основывается на многих принципах, базовыми из которых являются:
- изучение возможных точек отказа сети. Для того чтобы единичный отказ не мог изолировать какой-либо из сегментов сети, в ней может быть предусмотрена избыточность. Под избыточностью понимается резервирование жизненно важных компонентов сети и распределение нагрузки. Так, в случае отказа в сети может существовать альтернативный или резервный путь к любому ее сегменту. Распределение нагрузки используется в том случае, если к пункту назначения имеется два или более пути, которые могут использоваться в зависимости от загруженности сети. Требуемый уровень избыточности сети меняется в зависимости от ее конкретной реализации;
- определение типа трафика сети. Например, если в сети используются клиент-серверные приложения, то поток вырабатываемого ими трафика является критичным для эффективного распределения ресурсов, таких как количество клиентов, использующих определенный сервер, или количество клиентских рабочих станций в сегменте;
- анализ доступной полосы пропускания. Например, в сети не должно быть большого различия в доступной полосе пропускания между различными уровнями иерархической модели (описание иерархической модели сети находится в следующем разделе). Важно помнить, что иерархическая модель ссылается на концептуальные уровни, которые обеспечивают функциональность;
- создание сети на базе иерархической или модульной модели. Иерархия позволяет объединить через межсетевые устройства отдельные сегменты, которые будут функционировать как единая сеть. Фактическая граница между уровнями не обязательно должна проходить по физическому каналу связи — ею может быть и внутренняя магистраль определенного устройства.
Трехуровневая иерархическая модель сети
Иерархическая модель определяет подход к проектированию сетей и включает в себя три логических уровня ( рис. 1.20):
- уровень доступа (access layer);
- уровень распределения/ агрегации (distribution layer);
- уровень ядра (core layer).
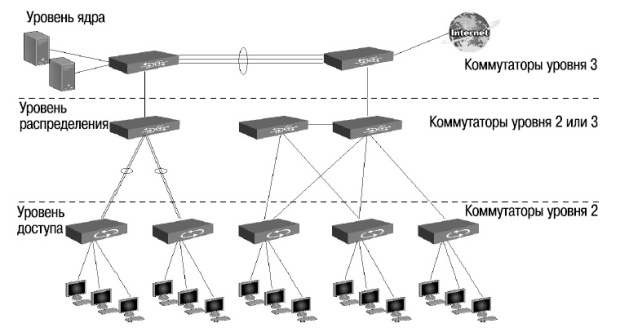
Для каждого уровня определены свои функции. Три уровня не обязательно предполагают наличие трех различных устройств. Если провести аналогию с иерархической моделью OSI , то в ней отдельный протокол не всегда соответствует одному из семи уровней. Иногда протокол соответствует более чем одному уровню модели OSI , а иногда несколько протоколов реализованы в рамках одного уровня. Так и при построении иерархических сетей, на одном уровне может быть как несколько устройств, так и одно устройство, выполняющее все функции, определенные на двух соседних уровнях.
Уровень ядра находится на самом верху иерархии и отвечает за надежную и быструю передачу больших объемов данных. Трафик, передаваемый через ядро , является общим для большинства пользователей. Сами пользовательские данные обрабатываются на уровне распределения, который, при необходимости, пересылает запросы к ядру.
Для уровня ядра большое значение имеет его отказоустойчивость , поскольку сбой на этом уровне может привести к потере связности между уровнями распределения сети.
Уровень распределения, который иногда называют уровнем рабочих групп, является связующим звеном между уровнями доступа и ядра. В зависимости от способа реализации уровень распределения может выполнять следующие функции:
- обеспечение маршрутизации, качества обслуживания и безопасности сети;
- агрегирование каналов;
- переход от одной технологии к другой (например, от 100Base-TX к 1000Base-T).
Уровень доступа управляет доступом пользователей и рабочих групп к ресурсам объединенной сети. Основной задачей уровня доступа является создание точек входа/выхода пользователей в сеть . Уровень выполняет следующие функции:

Открытая сетевая модель OSI (Open Systems Interconnection model) состоит из семи уровней. Что это за уровни, как устроена модель и какова ее роль при построении сетей — в статье.
Модель OSI является эталонной. Эталонная она потому, что полное название модели выглядит как «Basic Reference Model Open Systems Interconnection model», где Basic Reference Model означает «эталонная модель». Вначале рассмотрим общую информацию, а потом перейдем к частным аспектам.

Принцип устройства сетевой модели
Сетевая модель OSI имеет семь уровней, иерархически расположенных от большего к меньшему. То есть, самым верхним является седьмой (прикладной), а самым нижним — первый (физический). Модель OSI разрабатывалась еще в 1970-х годах, чтобы описать архитектуру и принципы работы сетей передачи данных. Важно помнить, что данные передаются не только по сети интернет, но и в локальных сетях с помощью проводных или беспроводных соединений.
На седьмом уровне информация представляется в виде данных, на первом — в виде бит. Процесс, когда информация отправляется и переходит из данных в биты, называется инкапсуляцией. Обратный процесс, когда информация, полученная в битах на первом уровне, переходит в данные на седьмом, называется декапсуляцией. На каждом из семи уровней информация представляется в виде блоков данных протокола — PDU (Protocol Data Unit).
Рассмотрим на примере: пользователь 1 отправляет картинку, которая обрабатывается на седьмом уровне в виде данных, данные должны пройти все уровни до самого нижнего (первого), где будут представлены как биты. Этот процесс называется инкапсуляцией. Компьютер пользователя 2 принимает биты, которые должны снова стать данными. Этот обратный процесс называется декапсуляция. Что происходит с информацией на каждом из семи уровней, как и где биты переходят в данные мы разберем в этой статье.
Первый, физический уровень (physical layer, L1)
Начнем с самого нижнего уровня. Он отвечает за обмен физическими сигналами между физическими устройствами, «железом». Компьютерное железо не понимает, что такое картинка или что на ней изображено, железу картинка понятна только в виде набора нулей и единиц, то есть бит. В данном случае бит является блоком данных протокола, сокращенно PDU (Protocol Data Unit).
Каждый уровень имеет свои PDU, представляемые в той форме, которая будет понятна на данном уровне и, возможно, на следующем до преобразования. Работа с чистыми данными происходит только на уровнях с пятого по седьмой.
Устройства физического уровня оперируют битами. Они передаются по проводам (например, через оптоволокно) или без проводов (например, через Bluetooth или IRDA, Wi-Fi, GSM, 4G и так далее).
Второй уровень, канальный (data link layer, L2)
Когда два пользователя находятся в одной сети, состоящей только из двух устройств — это идеальный случай. Но что если этих устройств больше?
У канального уровня есть два подуровня — это MAC и LLC. MAC (Media Access Control, контроль доступа к среде) отвечает за присвоение физических MAC-адресов, а LLC (Logical Link Control, контроль логической связи) занимается проверкой и исправлением данных, управляет их передачей.
На втором уровне OSI работают коммутаторы, их задача — передать сформированные кадры от одного устройства к другому, используя в качестве адресов только физические MAC-адреса.
Третий уровень, сетевой (network layer, L3)
На третьем уровне появляется новое понятие — маршрутизация. Для этой задачи были созданы устройства третьего уровня — маршрутизаторы (их еще называют роутерами). Маршрутизаторы получают MAC-адрес от коммутаторов с предыдущего уровня и занимаются построением маршрута от одного устройства к другому с учетом всех потенциальных неполадок в сети.
На сетевом уровне активно используется протокол ARP (Address Resolution Protocol — протокол определения адреса). С помощью него 64-битные MAC-адреса преобразуются в 32-битные IP-адреса и наоборот, тем самым обеспечивается инкапсуляция и декапсуляция данных.
Четвертый уровень, транспортный (transport layer, L4)
Все семь уровней модели OSI можно условно разделить на две группы:
- Media layers (уровни среды),
- Host layers (уровни хоста).
Уровни группы Media Layers (L1, L2, L3) занимаются передачей информации (по кабелю или беспроводной сети), используются сетевыми устройствами, такими как коммутаторы, маршрутизаторы и т.п. Уровни группы Host Layers (L4, L5, L6, L7) используются непосредственно на устройствах, будь то стационарные компьютеры или портативные мобильные устройства.
Четвертый уровень — это посредник между Host Layers и Media Layers, относящийся скорее к первым, чем к последним, его главной задачей является транспортировка пакетов. Естественно, при транспортировке возможны потери, но некоторые типы данных более чувствительны к потерям, чем другие. Например, если в тексте потеряются гласные, то будет сложно понять смысл, а если из видеопотока пропадет пара кадров, то это практически никак не скажется на конечном пользователе. Поэтому, при передаче данных, наиболее чувствительных к потерям на транспортном уровне используется протокол TCP, контролирующий целостность доставленной информации.
Для мультимедийных файлов небольшие потери не так важны, гораздо критичнее будет задержка. Для передачи таких данных, наиболее чувствительных к задержкам, используется протокол UDP, позволяющий организовать связь без установки соединения.
При передаче по протоколу TCP, данные делятся на сегменты. Сегмент — это часть пакета. Когда приходит пакет данных, который превышает пропускную способность сети, пакет делится на сегменты допустимого размера. Сегментация пакетов также требуется в ненадежных сетях, когда существует большая вероятность того, что большой пакет будет потерян или отправлен не тому адресату. При передаче данных по протоколу UDP, пакеты данных делятся уже на датаграммы. Датаграмма (datagram) — это тоже часть пакета, но ее нельзя путать с сегментом.
Главное отличие датаграмм в автономности. Каждая датаграмма содержит все необходимые заголовки, чтобы дойти до конечного адресата, поэтому они не зависят от сети, могут доставляться разными маршрутами и в разном порядке. Датаграмма и сегмент — это два PDU транспортного уровня модели OSI. При потере датаграмм или сегментов получаются «битые» куски данных, которые не получится корректно обработать.
Первые четыре уровня — специализация сетевых инженеров, но с последними тремя они не так часто сталкиваются, потому что пятым, шестым и седьмым занимаются разработчики.
Пятый уровень, сеансовый (session layer, L5)
Пятый уровень оперирует чистыми данными; помимо пятого, чистые данные используются также на шестом и седьмом уровне. Сеансовый уровень отвечает за поддержку сеанса или сессии связи. Пятый уровень оказывает услугу следующему: управляет взаимодействием между приложениями, открывает возможности синхронизации задач, завершения сеанса, обмена информации.
Службы сеансового уровня зачастую применяются в средах приложений, требующих удаленного вызова процедур, т.е. чтобы запрашивать выполнение действий на удаленных компьютерах или независимых системах на одном устройстве (при наличии нескольких ОС).
Примером работы пятого уровня может служить видеозвонок по сети. Во время видеосвязи необходимо, чтобы два потока данных (аудио и видео) шли синхронно. Когда к разговору двоих человек прибавится третий — получится уже конференция. Задача пятого уровня — сделать так, чтобы собеседники могли понять, кто сейчас говорит.
Шестой уровень, представления данных (presentation layer, L6)
О задачах уровня представления вновь говорит его название. Шестой уровень занимается тем, что представляет данные (которые все еще являются PDU) в понятном человеку и машине виде. Например, когда одно устройство умеет отображать текст только в кодировке ASCII, а другое только в UTF-8, перевод текста из одной кодировки в другую происходит на шестом уровне.
Шестой уровень также занимается представлением картинок (в JPEG, GIF и т.д.), а также видео-аудио (в MPEG, QuickTime). Помимо перечисленного, шестой уровень занимается шифрованием данных, когда при передаче их необходимо защитить.
Седьмой уровень, прикладной (application layer)
Седьмой уровень иногда еще называют уровень приложений, но чтобы не запутаться можно использовать оригинальное название — application layer. Прикладной уровень — это то, с чем взаимодействуют пользователи, своего рода графический интерфейс всей модели OSI, с другими он взаимодействует по минимуму.
Все услуги, получаемые седьмым уровнем от других, используются для доставки данных до пользователя. Протоколам седьмого уровня не требуется обеспечивать маршрутизацию или гарантировать доставку данных, когда об этом уже позаботились предыдущие шесть. Задача седьмого уровня — использовать свои протоколы, чтобы пользователь увидел данные в понятном ему виде.
Критика модели OSI
Семиуровневая модель была принята в качестве стандарта ISO/IEC 7498, действующего по сей день, однако, модель имеет свои недостатки. Среди основных недостатков говорят о неподходящем времени, плохой технологии, поздней имплементации, неудачной политике.
Первый недостаток — это неподходящее время. На разработку модели было потрачено неоправданно большое количество времени, но разработчики не уделили достаточное внимание существующим в то время стандартам. В связи с этим модель обвиняют в том, что она не отражает действительность. В таких утверждениях есть доля истины, ведь уже на момент появления OSI другие компании были больше готовы работать с получившей широкое распространение моделью TCP/IP.
Вторым недостатком называют плохую технологию. Как основной довод в пользу того, что OSI — это плохая технология, приводят распространенность стека TCP/IP. Протоколы OSI часто дублируют другу друга, функции распределены по уровням неравнозначно, а одни и те же задачи могут быть решены на разных уровнях.
Разделение на семь уровней было скорее политическим, чем техническим. При построении сетей в реальности редко используют уровни 5 и 6, а часто можно обойтись только первыми четырьмя. Даже изначальное описание архитектуры в распечатанном виде имеет толщину в один метр.
Кроме того, в отличие от TCP/IP, OSI никогда не ассоциировалась с UNIX. Добиться широкого распространения OSI не получилось потому, что она проектировалась как закрытая модель, продвигаемая Европейскими телекоммуникационными компаниями и правительством США. Стек протоколов TCP/IP изначально был открыт для всех, что позволило ему набрать популярность среди сторонников открытого программного кода.
Даже несмотря на то, что основные проблемы архитектуры OSI были политическими, репутация была запятнана и модель не получила распространения. Тем не менее, в сетевых технологиях, при работе с коммутацией даже сегодня обычно используют модель OSI.
Вывод, роль модели OSI при построении сетей
В статье мы рассмотрели принципы построения сетевой модели OSI. На каждом из семи уровней модели выполняется своя задача. В действительности архитектура OSI сложнее, чем мы описали. Существуют и другие уровни, например, сервисный, который встречается в интеллектуальных или сотовых сетях, или восьмой — так называют самого пользователя.
Как мы упоминали выше, оригинальное описание всех принципов построения сетей в рамках этой модели, если его распечатать, будет иметь толщину в один метр. Но компании активно используют OSI как эталон. Мы перечислили только основную структуру словами, понятными начинающим.
Модель OSI служит инструментом при диагностике сетей. Если в сети что-то не работает, то гораздо проще определить уровень, на котором произошла неполадка, чем пытаться перестроить всю сеть заново.
Зная архитектуру сети, гораздо проще ее строить и диагностировать. Как нельзя построить дом, не зная его архитектуры, так невозможно построить сеть, не зная модели OSI. При проектировании важно учитывать все. Важно учесть взаимодействие каждого уровня с другими, насколько обеспечивается безопасность, шифрование данных внутри сети, какой прирост пользователей выдержит сеть без обрушения, будет ли возможно перенести сеть на другую машину и т.д. Каждый из перечисленных критериев укладывается в функции одного из семи уровней.
Читайте также: