
Какую хэш функцию вы используете когда начинаете искать слово в словаре
Обновлено: 07.07.2024
Функции хэширования могут использоваться для детерминированного псевдослучайного разбрасывания элементов.
Simhash – это хеш-функция, которая для близких значений возвращает близкий хеш.
halfMD5
Интерпретирует все входные параметры как строки и вычисляет хэш MD5 для каждой из них. Затем объединяет хэши, берет первые 8 байт хэша результирующей строки и интерпретирует их как значение типа UInt64 с big-endian порядком байтов.
Функция относительно медленная (5 миллионов коротких строк в секунду на ядро процессора).
По возможности, используйте функцию sipHash64 вместо неё.
Аргументы
Функция принимает переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
Значение хэша с типом данных UInt64.
Пример
Вычисляет MD4 от строки и возвращает полученный набор байт в виде FixedString(16).
sipHash64
Генерирует 64-х битное значение SipHash.
Это криптографическая хэш-функция. Она работает по крайней мере в три раза быстрее, чем функция MD5.
Функция интерпретирует все входные параметры как строки и вычисляет хэш MD5 для каждой из них. Затем комбинирует хэши по следующему алгоритму.
- После хэширования всех входных параметров функция получает массив хэшей.
- Функция принимает первый и второй элементы и вычисляет хэш для массива из них.
- Затем функция принимает хэш-значение, вычисленное на предыдущем шаге, и третий элемент исходного хэш-массива, и вычисляет хэш для массива из них.
- Предыдущий шаг повторяется для всех остальных элементов исходного хэш-массива.
Аргументы
Функция принимает переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
Значение хэша с типом данных UInt64.
Пример
sipHash128
Вычисляет SipHash от строки.
Принимает аргумент типа String. Возвращает FixedString(16).
Отличается от sipHash64 тем, что финальный xor-folding состояния делается только до 128 бит.
cityHash64
Генерирует 64-х битное значение CityHash.
Это не криптографическая хэш-функция. Она использует CityHash алгоритм для строковых параметров и зависящую от реализации быструю некриптографическую хэш-функцию для параметров с другими типами данных. Функция использует комбинатор CityHash для получения конечных результатов.
Аргументы
Функция принимает переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
Значение хэша с типом данных UInt64.
Примеры
А вот так вы можете вычислить чексумму всей таблицы с точностью до порядка строк:
intHash32
Вычисляет 32-битный хэш-код от целого числа любого типа.
Это сравнительно быстрая не криптографическая хэш-функция среднего качества для чисел.
intHash64
Вычисляет 64-битный хэш-код от целого числа любого типа.
Работает быстрее, чем intHash32. Качество среднее.
SHA1, SHA224, SHA256, SHA512
Вычисляет SHA-1, SHA-224, SHA-256, SHA-512 хеш строки и возвращает полученный набор байт в виде FixedString.
Синтаксис
Функция работает достаточно медленно (SHA-1 — примерно 5 миллионов коротких строк в секунду на одном процессорном ядре, SHA-224 и SHA-256 — примерно 2.2 миллионов).
Рекомендуется использовать эти функции лишь в тех случаях, когда вам нужна конкретная хеш-функция и вы не можете её выбрать.
Даже в этих случаях рекомендуется применять функцию офлайн — заранее вычисляя значения при вставке в таблицу, вместо того чтобы применять её при выполнении SELECT .
Параметры
Возвращаемое значение
- Хеш SHA в виде шестнадцатеричной некодированной строки FixedString. SHA-1 хеш как FixedString(20), SHA-224 как FixedString(28), SHA-256 — FixedString(32), SHA-512 — FixedString(64).
Пример
Используйте функцию hex для представления результата в виде строки с шестнадцатеричной кодировкой.
URLHash(url[, N])
farmFingerprint64
farmHash64
Создает 64-битное значение FarmHash, независимое от платформы (архитектуры сервера), что важно, если значения сохраняются или используются для разбиения данных на группы.
Эти функции используют методы Fingerprint64 и Hash64 из всех доступных методов.
Аргументы
Функция принимает переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
Значение хэша с типом данных UInt64.
Пример
javaHash
Вычисляет JavaHash от строки. JavaHash не отличается ни скоростью, ни качеством, поэтому эту функцию следует считать устаревшей. Используйте эту функцию, если вам необходимо получить значение хэша по такому же алгоритму.
Возвращаемое значение
Хэш-значение типа Int32 .
Пример
javaHashUTF16LE
Вычисляет JavaHash от строки, при допущении, что строка представлена в кодировке UTF-16LE .
Синтаксис
Аргументы
Возвращаемое значение
Хэш-значение типа Int32 .
Пример
Верный запрос для строки кодированной в UTF-16LE .
hiveHash
Вычисляет HiveHash от строки.
HiveHash — это результат JavaHash с обнулённым битом знака числа. Функция используется в Apache Hive вплоть до версии 3.0.
Возвращаемое значение
Хэш-значение типа Int32 .
Пример
metroHash64
Генерирует 64-х битное значение MetroHash.
Аргументы
Функция принимает переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
Значение хэша с типом данных UInt64.
Пример
jumpConsistentHash
Вычисляет JumpConsistentHash от значения типа UInt64.
Имеет два параметра: ключ типа UInt64 и количество бакетов. Возвращает значение типа Int32.
Дополнительные сведения смотрите по ссылке: JumpConsistentHash
murmurHash2_32, murmurHash2_64
Аргументы
Обе функции принимают переменное число входных параметров. Аргументы могут быть любого поддерживаемого типа данных.
Возвращаемое значение
- Функция murmurHash2_32 возвращает значение типа UInt32.
- Функция murmurHash2_64 возвращает значение типа UInt64.
Пример
gccMurmurHash
Вычисляет 64-битное значение MurmurHash2, используя те же hash seed, что и gcc.
ЦЕЛИ ЗАЩИТЫ ИНФОРМАЦИИ
1. Соблюдение конфиденциальности информации ограниченного доступа.
2. Предотвращение несанкционированного доступа к информации и (или) передачи ее лицам, не имеющим права на доступ к такой информации.
3. Предотвращение несанкционированных действий по уничтожению, модификации, копированию, блокированию и предоставлению информации, а также иных неправомерных действий в отношении такой информации.
4. Реализация конституционного права граждан на доступ к информации.
5. Недопущение воздействия на технические средства обработки информации, в результате которого нарушается их функционирование.
ОСНОВНЫЕ ЗАДАЧИ СИСТЕМЫ ЗАЩИТЫ ИНФОРМАЦИИ
1. Проведение единой политики, организация и координация работ по защите информации в оборонной, экономической, политической, научно-технической и других сферах деятельности.
2. Исключение или существенное затруднение добывания информации средствами разведки.
3. Предотвращение утечки информации по техническим каналам и несанкционированного доступа к ней.
4. Предупреждение вредоносных воздействий на информацию, ее носителей, а также технические средства ее создания, обработки, использования, передачи и защиты.
5. Принятие правовых актов, регулирующих общественные отношения в области защиты информации.
6. Анализ состояния и прогнозирование возможностей технических средств разведки, а также способов их применения.
7. Формирование системы информационного обмена сведениями об осведомленности иностранных разведок о силах, методах, средствах и мероприятиях, обеспечивающих защиту информации внутри страны и за ее пределами.
8. Организация сил, разработка научно обоснованных методов, создание средств защиты информации и контроля за ее эффективностью.
9. Контроль состояния защиты информации в органах государственной власти, учреждениях, организациях и на предприятиях всех форм собственности, использующих в своей деятельности охраняемую законом информацию.
Что такое шифрование?
Видео YouTube
Один из методов защиты информации от неправомерного доступа — это шифрование, то есть кодирование специального вида.Шифрование — это преобразование (кодирование) открытой информации в зашифрованную, недоступную для понимания посторонних. Она состоит из двух ветвей: криптографии и криптоанализа. Криптография — это наука о способах шифрования информации.
Криптоанализ — это наука о методах и способах вскрытия шифров.
Все шифры (системы шифрования) делятся на две группы — симметричные и несимметричные (с открытым ключом). В системах с открытым ключом используются два ключа — открытый и закрытый, которые связаны друг с другом с помощью некоторых ма тематических зависимостей.
Видео YouTube
Видео YouTube
Криптостойкость шифра — это устойчивость шифра к расшифровке без знания ключаХэширование и пароли
В современных информационных системах часто используется вход по паролю. Если при этом где-то хранить пароли всех пользователей, система становится очень ненадежной, потому что “утечка” паролей позволит сразу получить доступ к данным. С другой стороны, кажется, что пароли обязательно где-то нужно хранить, иначе пользователи не смогут войти в систему. Однако это не совсем так. Можно хранить не пароли, а некоторые числа, полученные в результате обработки паролей. Простейший вариант — сумма кодов символов, входящих в пароль. Для пароля “ A 123” такая сумма равна
215 = 65 (код “ A ”) + 49 (код “1”) + 50 (код “2”) + 51 (код “3”).
Итак, вместо пароля “ A 123” мы храним число 215. Когда пользователь вводит пароль, мы считаем сумму кодов символов этого пароля и разрешаем вход в систему только тогда, когда она равна 215. И вот здесь возникает проблема: существует очень много паролей, для которых наша хэш-функция дает значение 215, например, “ B 023”. Такая ситуация — совпадение хэш-кодов различных исходных строк — называется коллизией (англ. collision — “столкновение”). Коллизии будут всегда — ведь мы “сжимаем” длинную цепочку байт до числа. Казалось бы, ничего хорошего не получилось: если взломщик узнает хэш-код, то, зная алгоритм его получения, он сможет легко подобрать пароль с таким же хэшем и получить доступ к данным. Однако это произошло потому, что мы выбрали плохую хэш-функцию.
Математики разработали надежные (но очень сложные) хэш-функции, обладающие особыми свойствами:
1) хэш-код очень сильно меняется при малейшем изменении исходных данных;
Здесь выражение “невозможно за приемлемое время” (или “вычислительно невозможно”) означает, что эта задача решается только перебором вариантов (других алгоритмов не существует), а количество вариантов настолько велико, что на решение уйдут сотни и тысячи лет. Поэтому даже если взломщик получил хэш-код пароля, он не сможет за приемлемое время получить сам пароль (или пароль, дающий такой же хэш-код).
Чем длиннее пароль, тем больше количество вариантов. Кроме длины, для надежности пароля важен используемый набор символов. Например, очень легко подбираются пароли, состоящие только из цифр. Если же пароль состоит из 10 символов и содержит латинские буквы (заглавные и строчные) и цифры, перебор вариантов (англ. brute force — метод “грубой силы”) со скоростью 10 млн. паролей в секунду займет более 2000 лет.
Надежные пароли должны состоять не менее чем из 8 символов; пароли, состоящие из 15 символов и более, взломать методом “грубой силы” практически невозможно. Нельзя использовать пароли типа “12345”, “ qwerty ”, свой день рождения, номер телефона. Плохо, если пароль представляет собой известное слово, для этих случаев взломщики используют подбор по словарю. Сложнее всего подобрать пароль, который представляет собой случайный набор заглавных и строчных букв, цифр и других знаков.
Сегодня для хэширования в большинстве случаев применяют алгоритмы MD 5, SHA 1 и российский алгоритм, изложенный в ГОСТ Р 34.11 94 (он считается одним из самых надежных). В криптографии хэш-коды чаще всего имеют длину 128, 160 и 256 бит.
Хэширование используется также для проверки правильности передачи данных. Различные контрольные суммы, используемые для проверки правильности передачи данных, — это не что иное, как хэш-коды.

В рамках данной статьи, я расскажу вам что такое Хэш, зачем он нужен, где и как применяется, а так же наиболее известные примеры.
Многие задачи в области информационных технологий весьма критичны к объемам данных. Например, если нужно сравнить между собой два файла размером по 1 Кб и два файла по 10 Гб, то это совершенно разное время. Поэтому алгоритмы, позволяющие оперировать более короткими и емкими значениями, считаются весьма востребованными.
Одной из таких технологий является Хэширование, которое нашло свое применение при решении массы задач. Но, думаю вам, как обычному пользователю, все еще непонятно, что же это за зверь такой и для чего он нужен. Поэтому далее я постараюсь объяснить все наиболее простыми словами.
Примечание: Материал рассчитан на обычных пользователей и не содержит многих технических аспектов, однако для базового ознакомления его более, чем достаточно.
Что такое Хэш или Хэширование?
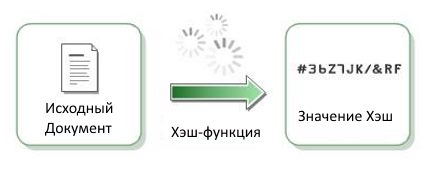
Начну с терминов.
Хэш-функция, Функция свертки - это специального вида функция, которая позволяет преобразовывать произвольной длины тексты к коду фиксированной длины (обычно, короткая цифро-буквенная запись).
Хэширование - это сам процесс преобразования исходных текстов.
Хэш, Хеш-код, Значение Хэш, Хэш-сумма - это выходное значение Хэш-функции, то есть полученный блок фиксированный длины.
Как видите, у терминов несколько образное описание, из которого сложно понять для чего это все нужно. Поэтому сразу приведу небольшой пример (об остальных применениях расскажу чуть позже). Допустим, у вас есть 2 файла размером 10 Гб. Как можно быстро узнать какой из них нужный? Можно использовать имя файла, но его легко переименовать. Можно смотреть даты, но после копирования файлов даты могут быть одинаковыми или в иной последовательности. Размер, как сами понимаете, мало чем может помочь (особенно, если размеры совпадают или вы не смотрели точные значения байтов).
Вот тут-то и нужен этот самый Хэш, который представляет собой короткий блок, формирующийся из исходного текста файла. У этих двух файлов по 10 Гб будет два разных, но коротких Хэш-кода (что-то вроде "ACCAC43535" и "BBB3232A42"). Используя их, можно будет быстро узнать нужный файл, даже после копирования и смены имен.
Примечание: В связи с тем, что Хэш в компьютером мире и в интернете весьма известное понятие, то нередко все то, что имеет отношение к Хэшу, сокращают до этого самого слова. Например, фраза "у меня используется Хэш MD5" в переводе означает, что на сайте или где-то еще используется алгоритм хэширования стандарта MD5.
Свойства Хеш-функций
Теперь, расскажу о свойствах Хэш-функций, чтобы вам было легче понять где применяется и для чего нужно Хэширование. Но, сначала еще одно определение.
Коллизия - это ситуация, когда для двух разных текстов получается одна и та же Хэш-сумма. Как сами понимаете, раз блок фиксированной длины, то он имеет ограниченное число возможных значений, а следовательно возможны повторы.
А теперь к самим свойствам Хэш-функций:
1. На вход может подаваться текст любого размера, а на выходе получается блок данных фиксированной длины. Это следует из определения.
2. Хэш-сумма одних и тех же текстов должна быть одинаковой. В противном случае, такие функции просто бесполезны - это аналогично случайному числу.
3. Хорошая функция свертки должна иметь хорошее распределение. Согласитесь, что если размер выходного Хэша, к примеру, 16 байт, то если функция возвращает всего 3 разных значения для любых текстов, то толку от такой функции и этих 16 байт никакого (16 байт это 2^128 вариантов, что примерно равно 3,4 * 10^38 степени).
4. Как хорошо функция реагирует на малейшие изменения в исходном тексте. Простой пример. Поменяли 1 букву в файле размером 10 Гб, значение функции должно стать другим. Если же это не так, то применять такую функцию весьма проблематично.
5. Вероятность возникновения коллизии. Весьма сложный параметр, рассчитываемый при определенных условиях. Но, суть его в том, что какой смысл от Хэш-функции, если полученная Хэш-сумма будет часто совпадать.
6. Скорость вычисления Хэша. Какой толк от функции свертки, если она будет долго вычисляться? Никакой, ведь тогда проще данные файлов сравнивать или использовать иной подход.
7. Сложность восстановления исходных данных из значения Хэша. Эта характеристика больше специфическая, нежели общая, так как не везде требуется подобное. Однако, для наиболее известных алгоритмов эта характеристика оценивается. Например, исходный файл вы вряд ли сможете получить из этой функции. Однако, если имеет место проблема коллизий (к примеру, нужно найти любой текст, который соответствует такому Хэшу), то такая характеристика может быть важной. Например, пароли, но о них чуть позже.
8. Открыт или закрыт исходный код такой функции. Если код не является открытым, то сложность восстановления данных, а именно криптостойкость, остается под вопросом. Отчасти, это проблема как с шифрованием.
Вот теперь можно переходить к вопросу "а для чего это все?".
Зачем нужен Хэш?
Основные цели у Хэш-функций всего три (вернее их предназначения).
1. Проверка целостности данных. В данном случае все просто, такая функция должна вычисляться быстро и позволять так же быстро проверить, что, к примеру, скачанный из интернета файл не был поврежден во время передачи.
2. Рост скорости поиска данных. Фиксированный размер блока позволяет получить немало преимуществ в решении задач поиска. В данном случае, речь идет о том, что, чисто технически, использование Хэш-функций может положительно сказываться на производительности. Для таких функций весьма важное значение представляют вероятность возникновения коллизий и хорошее распределение.
3. Для криптографических нужд. Данный вид функций свертки применяется в тех областях безопасности, где важно чтобы результаты сложно было подменить или где необходимо максимально усложнить задачу получения полезной информации из Хэша.
Где и как применяется Хэш?
Как вы, вероятно, уже догадались Хэш применяется при решении очень многих задач. Вот несколько из них:
1. Пароли обычно хранятся не в открытом виде, а в виде Хэш-сумм, что позволяет обеспечить более высокую степень безопасности. Ведь даже если злоумышленник получит доступ к такой БД, ему еще придется немало времени потратить, чтобы подобрать к этим Хэш-кодам соответствующие тексты. Вот тут и важна характеристика "сложность восстановления исходных данных из значений Хэша".
2. В программировании, включая базы данных. Конечно же, чаще всего речь идет о структурах данных, позволяющих осуществлять быстрый поиск. Чисто технический аспект.
4. Для различных алгоритмов, связанных с безопасностью. Например, Хэш применяется в электронных цифровых подписях.
5. Для проверки целостности файлов. Если обращали внимание, то нередко в интернете можно встретить у файлов (к примеру, архивы) дополнительные описания с Хэш-кодом. Эта мера применяется не только для того, чтобы вы случайно не запустили файл, который повредился при скачивании из Интернета, но и бывают просто сбои на хостингах. В таких случаях, можно быстро проверить Хэш и если требуется, то перезалить файл.
6. Иногда, Хэш-функции применяются для создания уникальных идентификаторов (как часть). Например, при сохранении картинок или просто файлов, обычно используют Хэш в именах совместно с датой и временем. Это позволяет не перезаписывать файлы с одинаковыми именами.
На самом деле, чем дальше, тем чаще Хэш-функции применяются в информационных технологиях. В основном из-за того, что объемы данных и мощности самых простых компьютеров сильно возрасли. В первом случае, речь больше о поиске, а во втором речь больше о вопросах безопасности.
Известные Хэш-функции
Самыми известными считаются следующие три Хэш-функции:
1. CRC16, CRC32, CRC64 - эти Хэш-функции очень просты и применяются только для проверки целостности данных. Например, при передачи данных по сети. При этом цифра после CRC - это не более, чем количество бит в выходном блоке. Самым известным из них является CRC32, размер Хэш-кода которого составляет всего 4 байта.
Примечание: Данная функция свертки состоит всего из одной операции XOR, которая последовательно выполняется ко всем входным блокам исходного текста. Поэтому ее обычно применяют только для проверки целостности данных.
2. MD5 - в свое время эта Хэш-функция была очень популярна для хранения паролей и прочих целей безопасности. Размер выходного блока составляет 128 бит. В принципе, применяется и до сих пор, однако стоит знать, что стойкость этого алгоритма уже не столько хороша (банально мощности компьютеров выросли - смотрите пример в статье, которую указал в предыдущем подразделе).
3. SHA-1, SHA-2 - самым известным и поддерживаемым многими системами является стандарт SHA-1 (160 бит). Однако, постепенно идет переход на SHA-2 (от 224 бит до 512), так как стойкость первого алгоритма постепенно снижается, как и у MD5.
На самом деле, в РФ существует и применяется собственный криптостойкий алгоритм ГОСТ Р 34.11-2012 (ранее использовался ГОСТ Р 34.11-94), однако распространенность его в интернете очень мала (в плане известности).
Теперь, вы знаете что такое Хэш, для чего он применяется и ряд других аспектов.
Хэширование, или хэш-функция — одна из основных составляющих современной криптографии и протокола блокчейна.
Но, что это такое? Как наглядно представить сущность хэша?
Начнем с того, что хэширование — это особое преобразование любого массива информации, в результате которого получается некое отображение, образ или дайджест, называемый хэшем (hash) — уникальная короткая символьная строка, которая присуща только этому массиву входящей информации.
Из этого следует, что для любого объема информации, будь-то одна буква или роман Льва Толстого «Война и мир» (или даже всё Полное собрание сочинений этого атвора) существует уникальный и неповторимый хэш — короткая символьная строка. Причем, если в той же «Войне и мире» изменить хотя бы один символ, добавить один лишь знак, — хэш изменится кардинально.
Как такое может быть? Целый многотомный роман и коротокая строчка, которая отражает его!
В этом смысле хэш подобен отпечатку пальца человека.

Как известно, отпечаток пальца уникален и в природе не существует людей с одинаковыми отпечатками. Даже у близнецов отпечатки пальцев разные.
То же касается и структуры ДНК человека. Она уникальна! Нет людей с одинаковым набором ДНК.
Но, ведь, ДНК, а тем более отпечаток пальцев — относительно короткие наборы информации. И, тем не менее, они являются неким кодом, присущим конкретному человеку. Можно считать, что это и есть «хэши» этого человека. С тем лишь отличием, что эти «хэши» не меняются с возрастом человека.
Итак, первое свойство хэша — его уникальность:
- Каждому набору (массиву) информации присущ строго определенный, уникальный хэш.
Тем не менее, иногда встречаются т.н. коллизии — случаи, когда хеш-функция для разных входных блоков информации вычисляет одинаковые хэш-коды.
Математики-криптографы стараются создать такие хэш-функции, вероятность коллизий в которых стремилась бы к нолю.
Следует отметить, что функций, которые вычисляют хэш, существует множество. Но, наиболее распространена (в частности, используется в протоколе блокчейна биткоина) хэш-функция под названием SHA-256 (от Secure Hash Algorithm — безопасный алгоритм хеширования). Эта хэш-функция формирует хэш в виде строки из 64 символов (длина — 256 бит или 32 байта).
Попробуем при помощи SHA-256 hash калькулятора получить хэш для заголовка этой статьи («Хэширование: Просто и наглядно»).
Это будет: ef3c82303f3896044125616982c715e7757d4cd1f84c34c6b2e64167d2fde766
А теперь изменим заголовок всего лишь на один символ — добавим знак восклицания в конце («Хэширование: Просто и наглядно!»).
Получилось: a6123e137d1d7f0aad800cdbc0918a65bb7a778a607cb993043d99718ec5a9e1
Как видите, изменение всего лишь на один знак исходного массива информации привело к кардинальному изменению его хэша!
И это второе важное свойство хэша:
- При самом незначительном изменении входной информации её хэш меняется кардинально.
Это свойство важно при использовании хэширования в цифровой подписи, т.к. позволяет удостовериться, что подписанная информация не была изменена во время её передачи по каналам связи. Но, подробнее об этом в следующей моей статье.
Третье важное свойство хэша, вытекает из того, что хэш-функция необратима. Другими словами:
- Не существует обратной функции, которая из хэша может восстановить исходный массив информации.
Из этого следует, что восстановить по хэшу соответствующий ему массив информации возможно только перебором всех возможных вариантов. Что практически невозможно, поскольку количество информации бесконечно!
Это свойство важно, поскольку делает взлом хэша (восстановление исходной информации по её хэшу) или невозможным или весьма дорогостоящим занятием.
Еще одно важное свойство хэш-функций — это высокая скорость работы.
- Хэширование позволяет достаточнобыстровычислить искомый хэш из весьма большого массива входной информации.
Этим хэширование существенно отличается от кодирования (шифрования) и декодирования (дешифрования).
Хэширование или хэш-функция используется во многих алгоритмах и протоколах. В частности, в электронной (цифровой) подписи и блокчейне.
Просто и наглядно, как это делается, я расскажу в следующих статьях.
А пока прочитайте мою предыдущую статью из цикла «Просто и наглядно» о Шифровании с открытым ключом.
Читайте также: