
Какую кодировку используют все современные компьютеры для хранения и обработки информации
Обновлено: 05.07.2024
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Процессор берёт команды программ и данные для обработки из памяти. Память является электронным устройством и состоит из микросхем, которые, в свою очередь, состоят из тысяч более мелких электронных компонентов. Подобные электронные компоненты могут находиться только в двух состояниях — «включено» или «выключено», что соответствует двум цифрам двоичной системы счисления 1 или 0 или одному биту.
Таким образом, любая информация в памяти компьютера представляется в виде последовательности битов, каждый из которых находится в одном из допустимых состояний.
При использовании одного бита можно представить в памяти компьютера только два различных символа. Одному из них будет сопоставлен двоичный код — ноль, а второму — единица.
Если мы увеличим длину кодовой комбинации символа до двух цифр, то получим следующие коды: 00, 01, 10, 11. Таким образом, в памяти компьютера можно будет представить четыре различных символа. При последовательном наращивании длины двоичной кодовой комбинации увеличивается количество символов, которые могут быть закодированы. Кодом длиной в три символа представляются 8 различных символов (000, 001, 010, 011, 100, 101, 110, 111) и т. д.
При длине кодовой комбинации L количество кодовых комбинаций K определяется по формуле:
K = 2 L ,
Текстовая информация состоит из букв, цифр, знаков препинания, специальных символов, таких, как пробел, символ перевода строки и др. Для кодирования текстовой информации в компьютере используются равномерные коды. В случае, когда код каждого символа занимает в памяти компьютера 1 байт, или 8 бит, общее количество символов, которые можно закодировать, равно 2 8 = 256. Если кодовое слово состоит из двух байтов, можно закодировать 2 16 = 65 536 символов.
Существуют стандартные таблицы кодов. Они могут использовать один или два байта для кодирования одного символа.
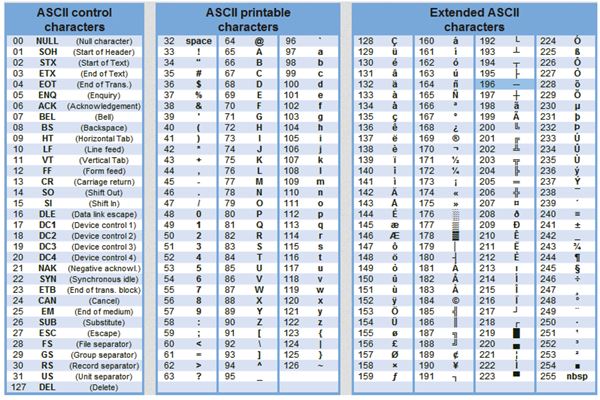
Широко используется таблица кодов, известная как стандарт ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией), использующая один байт для кодирования одного символа. ASCII представляет собой кодировку для представления десятичных цифр, символов латинского и национального алфавитов, знаков препинания, символов арифметических операций и управляющих символов. Управляющие символы называют непечатаемыми символами, к ним относятся такие, как «перевод строки» (код символа 10), «возврат каретки» (код 13) и др.
Первая половина кодовой таблицы содержит стандартные символы ASCII (символы с кодами 0 — 127), они одинаковые во всех странах.
Коды в таблице записаны в шестнадцатеричной системе счисления, как принято в информатике. Код символа А, например, 4116 = 6510. Таблицу кодов не надо запоминать, но следует помнить последовательность символов:
- знаки препинания и арифметических операций;
- цифры от 0 до 9;
- прописные символы латинского алфавита;
- строчные символы латинского алфавита.
Вторая часть кодовой таблицы (символы с кодами 128 — 255) называют расширенными кодами ASCII. В расширенные коды ASCII включают символы национальных алфавитов, например символы кириллицы. Но даже с учётом этих дополнительных знаков алфавиты многих языков не удаётся охватить при помощи 256 знаков. По этой причине существуют различные варианты кодировки ASCII, включающие символы разных языков.
Отсутствие согласованных стандартов привело к появлению различных кодовых таблиц (вернее, различных вторых частей кодовых таблиц) для кодирования символов кириллицы, среди которых
- международный стандарт ISO 8859;
- кодовая таблица фирмы Microsoft CP-1251 (кодировка Windows);
- кодовая таблица, применяемая в ОС Unix KOI8R и др.
По этой причине тексты на русском языке, набранные с использованием одной кодовой таблицы, невозможно прочитать при использовании другой кодовой таблицы.
В настоящее время в компьютерах широко применяется стандарт кодирования Unicode (Юникод), в котором для кодирования одного символа отводятся один байт, два байта или четыре байта. Первые 128 символов Юникода совпадают с символами ASCII. Остальная часть кодовой таблицы включает символы, используемые в основных языках мира.
Изображение на экране монитора формируется набором экранных точек —пикселей. Каждая экранная точка имеет свой цвет. Картинка на экране — это отображение информации из памяти компьютера.
Первые мониторы были монохромными. Точка на экране монохромного монитора может быть только светлой (белой) или тёмной (чёрной). Для кодирования цвета пикселя используется один бит памяти, значение 1 соответствует белому цвету, 0 — чёрному. Подобные экраны используются в недорогих сотовых телефонах, системах видеонаблюдения и других устройствах.
Каждый пиксель современного дисплея определяется компонентами трёх основных цветов: красного (Red, R), зелёного (Green, G) и синего (Blue, B). В памяти необходимо сохранять информацию о состоянии каждой точки изображения, т. е. о состоянии каждой из её трёх составляющих. Управление яркостью каждой составляющей позволяет влиять на цвет экранной точки.
Цветовой моделью называется правило представления цвета в виде наборов чисел (обычно трёх-четырёх). В компьютерной графике используется несколько видов цветовых моделей.
Рассмотрим цветовую модель, связанную с представлением пикселя составляющими красного, зелёного и синего цветов. Она называется RGB(Red-Green-Blue)-моделью.
В RGB-модели происходит сложение цветов и добавление их к чёрному цвету экрана, поэтому она называется аддитивной (additive). Разные цвета образуются смешиванием трёх основных цветов в разных пропорциях, т. е. с разными яркостями.
Глубина цвета (color depth) — это число бит, используемых для представления каждого пикселя изображения.
В модели RGB каждый цвет может кодироваться тремя байтами (режимTrueColor). Каждый байт отвечает за яркость красной, зеленой и синей составляющей пикселя соответственно. Таким образом, глубина цвета в режиме TrueColor составляет 24 бита. Изображения, пиксели которых закодированы таким способом, называются 24-битными изображениями.
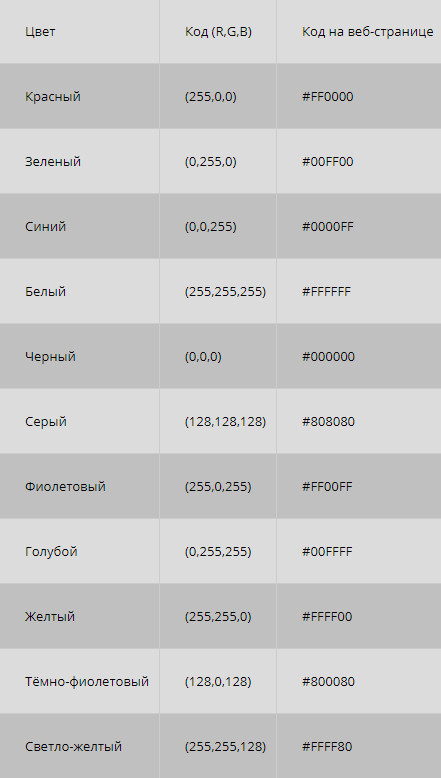
Чтобы указать цвет пикселя в модели RGB, достаточно перечислить разделённые точками яркости каждой составляющей, например: 255.255.0 — код жёлтой точки, записанный при помощи десятичных кодов яркостей. Значения яркости варьируются от 0 («выключено») до 255 («включено на максимум»). Если значения яркостей всех трёх составляющих равны, получим оттенки серого цвета.
Если изменять интенсивность каждого цвета для смешанных цветов, например задать цвет 127.127.0, то мы получим на экране болотный цвет, а не более тёмный оттенок жёлтого цвета, как можно было ожидать. Это связано с тем, что человеческий глаз более чувствителен к зелёному цвету. Чем ниже интенсивности составляющих, тем темнее цвет на экране. И наоборот — чем выше интенсивности цветов, тем светлее оттенки.
Модель CMY использует также три основных цвета: голубой (Cyan), фуксин (Magenta, иногда его называют «пурпурный» или «малиновый») и жёлтый (Yellow). Эти цвета описывают отражённый от белой бумаги свет трёх основных цветов RGB-модели.
Модель CMY является субтрактивной (основанной на вычитании) цветовой моделью. Краситель, нанесённый на белую бумагу, вычитает часть спектра из падающего белого света. Например, на поверхность бумаги нанесли жёлтый (Yellow) краситель. Теперь синий свет, падающий на бумагу, полностью поглощается. Таким образом, жёлтый носитель вычитает синий свет из падающего белого.
При смешении двух субтрактивных составляющих результирующий цвет затемняется, а при смешении всех трёх должен получиться чёрный цвет. Но при использовании реальных полиграфических красок получается не чёрный, а неопределённый тёмный цвет. Поэтому к трём основным цветам CMY-модели добавляют чёрный (Black) и получают новую цветовую модель CMYK.
Цветовая модель CMYK используется в основном в полиграфии при выводе изображения на печать.
Количество различных цветов K и количество битов для их кодирования (глубина цвета) L связаны формулой K = 2 L . При L = 24 бита можно закодировать 2 24 = 16 777 216 различных цветов.
Если известно разрешение экрана (количество точек по горизонтали и вертикали) и глубина цвета, можно определить объём видеопамяти для хранения одного кадра (одной страницы) изображения. Например, при разрешении экрана 640 × 480 и использовании 24 бит на точку объём видеопамяти равен 640 ∙ 480 ∙ 24 = 7 372 800 бит = 900 Кбайт.
Все компьютерные изображения делятся на два больших класса — растровые и векторные. Различие между ними определяет способ хранения изображений в памяти компьютера.
Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда сигнала, тем громче звук; чем больше частота сигнала (число колебаний в секунду), тем выше тон.
В настоящее время существует два основных способа записи звука —аналоговый (непрерывный) и цифровой (дискретный). Виниловая пластинка является примером аналогового хранения звуковой информации, так как звуковая дорожка изменяет свою форму непрерывно. Компакт-диски являются примером цифрового хранения звуковой информации, так как звуковая дорожка компакт-диска содержит участки с различной отражающей способностью.
Для того чтобы записать звук на какой-нибудь носитель, его нужно преобразовать в электрический сигнал. Это делается с помощью микрофона. Микрофоны имеют мембрану, которая колеблется под воздействием звуковых волн. К мембране присоединена катушка, перемещающаяся синхронно с мембраной в магнитном поле. В катушке возникает переменный электрический ток. Так звуковые волны преобразуются микрофоном в электрический ток переменного напряжения, который представляет собой аналоговый сигнал. Применительно к электрическому сигналу термин «аналоговый» обозначает, что этот сигнал непрерывен по времени и амплитуде (см. рис. 11а).
Для того чтобы компьютер мог обрабатывать звук, непрерывный сигнал должен быть превращён в последовательность электрических импульсов (двоичных нулей и единиц). В процессе кодирования непрерывного звукового сигнала производится его дискретизация по времени. Дискретизация — это преобразование непрерывных сигналов в набор дискретных значений, каждому из которых присваивается число — кодовое слово.
Для дискретизации надо несколько раз в секунду измерять величину аналогового сигнала и кодировать её, например, с помощью 256 значений.
Фактически плоскость, на которой изображён непрерывный сигнал, разбивается вертикальными и горизонтальными линиями (см. рис. 11б), и считается, что график проходит строго через узлы полученной сетки, непрерывная плавная линия заменяется ломаной.

Дискретизация по времени соответствует разбиению вертикальными линиями. Она характеризуется частотой дискретизации. Частота дискретизации звукового компакт-диска 44,1 кГц, DVD — примерно 96 кГц. Это значит, что величина аналогового сигнала измеряется 44 100 и 96 000 раз в секунду соответственно. Если кодируется стереозвук, отдельно кодируются два канала.
Горизонтальное разбиение также важно: чем меньше расстояние между горизонтальными линиями сетки, тем качественнее будет цифровой звук. Количество линий сетки определяет количество уровней звука, поэтому горизонтальное разбиение называется квантованием по уровню. Для кодирования полученных значений уровней используют двоичные числа. Количество используемых для кодирования бит называется глубиной звука. Если глубина звука 8 бит или 16 бит, можно закодировать соответственно 2 8 = 256 уровней или 2 16 = 65 536 уровней сигналов. Это значит, что интервал от нулевого до максимального напряжения аналогового сигнала разбивается на 256 или 65 536 уровней, что соответствует количеству высот звука (тонов).
Преобразование непрерывной звуковой волны в последовательность звуковых импульсов различной амплитуды производится с помощью аналого-цифрового преобразователя (АЦП), размещённого на звуковой плате.
С помощью специальных программных средств (редакторов звукозаписей) открываются широкие возможности по созданию, редактированию и прослушиванию звуковых файлов. Но, как видно из примера, звуковые файлы занимают очень много места в памяти. Поэтому используются методы сжатия звуковых файлов. Качество музыки после сжатия несколько ухудшается, но это практически незаметно, так как при разработке алгоритмов сжатия учитываются законы восприятия музыки человеком.

Какую кодировку используют все современные компьютеры для хранения и обработки информации?
- двоичную
- десятичную
- шестнадцатеричную
Вопрос 4
В чём состоит принцип однородности памяти?
- Ни одна область памяти не имеет преимуществ перед другой
- Команды программ и данные хранятся в одной и той же памяти и внешне неразличимы
- Внутренняя и внешняя память выполняют одни и те же функции
Вопрос 5
Что такое разрядность ячеек памяти?
- Используемая в них система счисления
- Скорость доступа к содержащейся в них информации
- Количество битов в ячейке
Вопрос 6
Какое из этих требований предъявляется к памяти компьютера?
- Её объём должен быть как можно больше
- Время доступа к ней должно быть как можно меньше
- Оба этих требования
Вопрос 7
В чём состоит принцип иерархической организации памяти?
- В использовании нескольких различных видов памяти, связанных друг с другом
- В разделении памяти на разные классы производительности
- В создании разных уровней прав доступа к памяти
Вопрос 8
Каково главное отличие компьютеров от всех других технических устройств?
- Многозадачность
- Программное управление их работой
- Широкий спектр применения
Вопрос 9
Что такое контроллер?
- Центральный процессор компьютера
- Специальный микропроцессор, предназначенный для управления внешними устройствами
- Специальная программа, предназначенная для управления внешними устройствами
Вопрос 10
В чём состоит главное достоинство магистрально-модульной архитектуры компьютера?
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
Существует три основных способа кодирования информации:- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Читайте также: