
Кэш память малоэффективна в том случае когда
Обновлено: 02.07.2024
В элементах каталога страниц и таблиц страниц имеются 2 бита, которые применяются для управления выходными сигналами процессора и участвуют в кэшировании страниц.
Бит PCD запрещает ( PCD = 1 ) или разрешает ( PCD = 0 ) кэширование страницы. Запрещение кэширования необходимо для страниц, которые содержат порты ввода/вывода с отображением на память . Оно также полезно для страниц, кэширование которых не дает выигрыша в быстродействии, например, страниц, содержащих программу инициализации.
Бит PWT определяет метод обновления ОЗУ и внешней кэш -памяти ( кэш 2-го уровня). Если PWT = 1 , то для данных в соответствующей странице определяется кэширование со сквозной записью, при PWT = 0 применяется способ обратной записи. Используется в микропроцессорах начиная с Pentium. Так как внутренняя кэш - память в МП i486 работает со сквозной записью, состояние бита PWT на нее не влияет. Бит PWT в этом случае действует только на внешнюю КП.
Обеспечение согласованности кэш-памяти микропроцессоров в мультипроцессорных системах
Рассмотрим особенности работы кэш -памяти в том случае, когда одновременно несколько микропроцессоров используют общую оперативную память (рис. 4.4). В этом случае могут возникнуть проблемы, связанные с кэшированием информации из оперативной памяти в кэш - память микропроцессоров.

Рис. 4.4. Структура мультимикропроцессорной системы с общей оперативной памятью
Предположим, что МП А считал некоторую строку данных из ОЗУ в свою внутреннюю КП и изменил данные в этой строке в процессе работы.
Мы отмечали, что существует два основных механизма обновления оперативной памяти:
- сквозная запись, которая подразумевает, что как только изменилась информация во внутренней кэш-памяти, эта же информация копируется в то же место оперативной памяти, и
- обратная запись, при которой микропроцессор после изменения информации во внутреннем кэше отражает это изменение в оперативной памяти не сразу, а лишь в тот момент, когда происходит вытеснение данной строки из кэш-памяти в оперативную. То есть существуют определенные моменты времени, когда информация, предположим, по адресу 2000 имеет разные значения: микропроцессор ее обновил, а в оперативной памяти осталось старое значение. Если в этот момент другой микропроцессор (МП В), использующий ту же оперативную память, обратится по адресу 2000 в ОЗУ , то он прочитает оттуда старую информацию, которая к этому времени уже не актуальна.
Для обеспечения согласованности ( когерентности ) памяти в мультипроцессорных системах используются аппаратные механизмы , позволяющие решить эту проблему. Такие механизмы называются протоколами когерентности кэш-памяти. Эти протоколы призваны гарантировать, что любое считывание элемента данных возвращает последнее по времени записанное в него значение .
Существует два класса протоколов когерентности :
- протоколы на основе справочника ( directory based ): информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы);
- протоколы наблюдения ( snooping ): каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии; централизованная система записей отсутствует; обычно кэши расположены на общей шине , и контроллеры всех кэшей наблюдают за шиной (просматривают ее), чтобы определять, какие обращения по адресам в пределах этого блока происходят со стороны других микропроцессоров.
В мультипроцессорных системах с общей памятью наибольшей популярностью пользуются протоколы наблюдения, поскольку для опроса состояния кэшей они могут использовать уже существующее физическое соединение - шину памяти.
Для поддержания когерентности применяется два основных метода.
Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных . Этот тип протоколов называется протоколом записи с аннулированием ( write invalidate protocol ), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных .
Этот тип протокола называется протоколом записи с обновлением ( write update protocol ), или протоколом записи с трансляцией ( write broadcast protocol ).
Эти две схемы во многом похожи на схемы работы кэш -памяти со сквозной и с обратной записью. Ключевым моментом реализации в многопроцессорных системах с небольшим числом процессоров как схемы записи с аннулированием , так и схемы записи с обновлением данных, является использование для выполнения этих операций механизма шины. Для выполнения операции обновления или аннулирования процессор просто захватывает шину и транслирует по ней адрес , по которому должно производиться обновление или аннулирование данных. Все процессоры непрерывно наблюдают за шиной, контролируя появляющиеся на ней адреса.
Процессоры проверяют, не находится ли в их кэш -памяти адрес , появившийся на шине. Если это так, то соответствующие данные в кэше либо аннулируются, либо обновляются в зависимости от используемого протокола.
Рассмотрим один из наиболее распространенных протоколов, обеспечивающих согласованную работу кэш -памяти нескольких микропроцессоров и основной памяти в мультимикропроцессорных системах, протокол MESI, который относится к группе протоколов наблюдения с аннулированием. Будем знакомиться с ним на примере двухпроцессорной системы, состоящей из микропроцессоров A и B.
Этот протокол использует 4 признака состояния строки кэш -памяти микропроцессора, по первым буквам которых и называется протокол:
- измененное состояние ( Modified ): информация, хранимая в кэш-памяти микропроцессора А, достоверна только в этом кэше; она отсутствует в оперативной памяти и в кэш-памяти других микропроцессоров;
- исключительная копия ( Exclusive ): информация, содержащаяся в кэше А, содержится еще только в оперативной памяти;
- разделяемая информация ( Shared ): информация, содержащаяся в кэше А, содержится в кэш-памяти по крайней мере еще одного МП, а также в оперативной памяти;
- недостоверная информация ( Invalid ): в строке кэш-памяти находится недостоверная информация.
Таким образом, состояние признаков потокола MESI отражает следующие состояния (по отношению к МПА) строки кэш -памяти (табл. 4.2):
При работе микропроцессора А с точки зрения обеспечения когерентности памяти возможны следующие ситуации:
- RH ( Read Hit ) - кэш-попадание при чтении;
- WH ( Write Hit ) - кэш-попадание при записи;
- RME ( Read Miss Exclusive ) - кэш-промах при чтении;
- RMS ( Read Miss Shared ) - кэш-промах при чтении, но соответствующий блок есть в кэш-памяти другого микропроцессора;
- WM ( Write Miss ) - кэш-промах при записи;
- SHR ( Snoop Hit Read ) - обнаружение копии блока при прослушивании операции чтения другого кэша;
- SHW ( Snoop Hit Write ) - обнаружение копии блока при прослушивании операции записи другого кэша.
Наибольший интерес здесь представляют две последние позиции.
Современные микропроцессоры имеют двунаправленную шину адреса.
Выдавая информацию на эту шину, микропроцессор адресует ячейки оперативной памяти или устройства ввода-вывода. В силу того, что в рассматриваемой мультипроцессорной системе микропроцессоры связаны общей шиной, в том числе и шиной адреса, принимая информацию по адресным линиям, микропроцессор определяет, было ли обращение по адресам, содержащимся в его кэш -памяти, со стороны других микропроцессоров. При обнаружении такого обращения меняется состояние строки кэш -памяти микропроцессора.
Изменения признака состояния блока кэш -памяти МП в зависимости от различных ситуаций в его работе и работе мультимикропроцессорной системы в целом представлены на рис. 4.5.
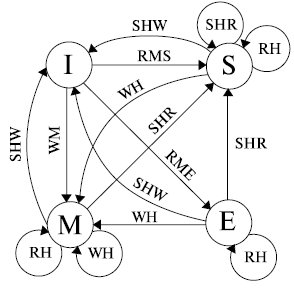
Рис. 4.5. MESI-диаграмма обеспечения когерентности кэш-памяти
Проиллюстрируем некоторые из представленных переходов.
Пусть блок кэш -памяти находится в состоянии Modified , то есть достоверная информация находится только в кэш -памяти данного МП. Тогда в случае обнаружения при прослушивании адресной шины обращения со стороны другого микропроцессора для чтения информации по входящим в данную строку адресам микропроцессор должен передать эту строку кэшпамяти в ОЗУ , откуда она уже будет прочитана другим микропроцессором.
При этом состояние строки в кэш -памяти рассматриваемого микропроцессора изменится с модифицированного на разделяемое ( Shared ).
Если строка кэш -памяти находилась в состоянии Invalid , то есть информация в ней была недостоверной, то по отношению к этой строке следует рассматривать только ситуации, связанные с кэш-промахами. Так, если произошел кэш-промах при выполнении операции записи, то необходимая строка будет занесена в кэш - память данного МП, в эту строку будут записаны измененные данные, и она приобретет статус исключительного владельца новой информации ( Modified ).
Краткие итоги. В лекции рассмотрены общие принципы функционирования кэш -памяти микропроцессора, организация кэш -памяти с прямым отображением, полностью ассоциативной и множественно-ассоциативной КП. Рассмотрены основные механизмы обновления оперативной памяти: кэширование со сквозной и с обратной записью. Представлена организация внутренней кэш -памяти микропроцессора. Разобраны способы обеспечения согласованности кэш -памяти микропроцессоров в мультипроцессорных системах.
Кэш-память (КП), или кэш, представляет собой организованную в виде ассоциативного запоминающего устройства (АЗУ) быстродействующую буферную память ограниченного объема, которая располагается между регистрами процессора и относительно медленной основной памятью и хранит наиболее часто используемую информацию совместно с ее признаками (тегами), в качестве которых выступает часть адресного кода.
В процессе работы отдельные блоки информации копируются из основной памяти в кэш - память . При обращении процессора за командой или данными сначала проверяется их наличие в КП. Если необходимая информация находится в кэше, она быстро извлекается. Это кэш-попадание. Если необходимая информация в КП отсутствует ( кэш-промах ), то она выбирается из основной памяти, передается в микропроцессор и одновременно заносится в кэш - память . Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи.
Зададимся вопросом: "А как определить наиболее часто используемую информацию? Неужели сначала кто-то анализирует ход выполнения программы, определяет, какие команды и данные чаще используются, а потом, при следующем запуске программы, эти данные переписываются в кэш - память и уже тогда программа выполняется эффективно?" Конечно нет. Хотя в современных микропроцессорах имеется определенный механизм, который позволяет в некоторой степени реализовать этот принцип. Но в основном, конечно, кэш - память сама отбирает информацию, которая чаще всего используется. Рассмотрим, как это происходит.
Механизм сохранения информации в кэш-памяти
При включении микропроцессора в работу вся информация в его кэш-памяти недостоверна.
При обращении к памяти микропроцессор, как уже отмечалось, сначала проверяет, не содержится ли искомая информация в кэш-памяти.
Для этого сформированный им физический адрес сравнивается с адресами ячеек памяти, которые были ранее кэшированы из ОЗУ в КП.
При первом обращении такой информации в кэш -памяти, естественно, нет, и это соответствует кэш-промаху. Тогда микропроцессор проводит обращение к оперативной памяти, извлекает нужную информацию, использует ее в своей работе, но одновременно записывает эту информацию в кэш .
Если бы в кэш - память заносилась только востребованная микропроцессором в данный момент информация , то, скорее всего, при следующем обращении вновь произошел бы кэш-промах: вряд ли следующее обращение произойдет к той же самой команде или к тому же самому операнду. Кэш-попадания происходили бы лишь после того, как в КП накопится достаточно большой фрагмент программы, содержащий некоторые циклические участки кода, или фрагмент данных, подлежащих повторной обработке. Для того чтобы уже следующее обращение к КП приводило как можно чаще к кэш-попаданиям, передача из оперативной памяти в кэш - память происходит не теми порциями (байтами или словами), которые востребованы микропроцессором в данном обращении, а так называемыми строками. То есть кэш - память и оперативная память с точки зрения кэширования организуются в виде строк. Длина строки превышает максимально возможную длину востребованных микропроцессором данных. Обычно она составляет от 16 до 64 байт и выровнена в памяти по границе соответствующего раздела (рис. 4.1).
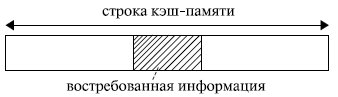
Рис. 4.1. Организация обмена между оперативной и кэш-памятью
Высокий процент кэш-попаданий в этом случае обеспечивается благодаря тому, что в большинстве случаев программы обращаются к ячейкам памяти, расположенным вблизи от ранее использованных. Это свойство, называемое принципом локальности ссылок, обеспечивает эффективность использования КП. Оно подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным).
Например, микропроцессору для своей работы потребовалось 2 байта информации. Если строка имеет длину 16 байт , то в кэш переписываются не только нужные 2 байта, но и некоторое их окружение. Когда микропроцессор обращается за новой информацией, в силу локальности ссылок, скорее всего, обращение произойдет по соседнему адресу. Затем опять по соседнему, опять по соседнему и т. д. Таким образом, ряд следующих обращений будет происходить непосредственно к кэш -памяти, минуя оперативную память (кэш-попадания). Когда очередной сформированный микропроцессором физический адрес выйдет за пределы строки кэш -памяти (произойдет кэш-промах ), будет выполнена подкачка в кэш новой строки, и вновь ряд последующих обращений вызовет кэш-попадания.
Чем длиннее используемая при обмене между оперативной и кэшпамятью строка, тем больше вероятность того, что следующее обращение произойдет в пределах этой строки. Но в то же время чем длиннее строка, тем дольше она будет перекачиваться из оперативной памяти в кэш . И если очередная команда окажется командой перехода или выборка данных начнется из нового массива, то есть следующее обращение произойдет не по соседнему адресу, то время, затраченное на передачу длинной строки, будет использовано напрасно. Поэтому при выборе длины строки должен быть разумный компромисс между соотношением времени обращения к оперативной и кэш -памяти и вероятностью достаточно удаленного перехода от текущего адреса при выполнении программы. Обычно длина строки определяется в результате моделирования аппаратно-программной структуры системы .
После того как в КП накопится достаточно большой объем информации, увеличивается вероятность того, что формирование очередного адреса приведет к кэш-попаданию. Особенно велика вероятность этого при выполнении циклических участков программы.
Старая информация по возможности сохраняется в кэш -памяти. Ее замена на новую определяется емкостью, организацией и стратегией обновления кэша.
Типы кэш-памяти
Если каждая строка ОЗУ имеет только одно фиксированное место , на котором она может находиться в кэш -памяти, то такая кэш - память называется памятью с прямым отображением.
Предположим, что ОЗУ состоит из 1000 строк с номерами от 0 до 999, а кэш - память имеет емкость только 100 строк. В кэш -памяти с прямым отображением строки ОЗУ с номерами 0, 100, 200, . 900 могут сохраняться только в строке 0 КП и нигде иначе, строки 1, 101, 201, …, 901
ОЗУ - в строке 1 КП, строки ОЗУ с номерами 99, 199, …, 999 сохраняются в строке 99 кэш -памяти (рис. 4.2). Такая организация кэш -памяти обеспечивает быстрый поиск в ней нужной информации: необходимо проверить ее наличие только в одном месте. Однако емкость КП при этом используется не в полной мере: несмотря на то, что часть кэш -памяти может быть не заполнена, будет происходить вытеснение из нее полезной информации при последовательных обращениях, например, к строкам 101, 301, 101 ОЗУ .
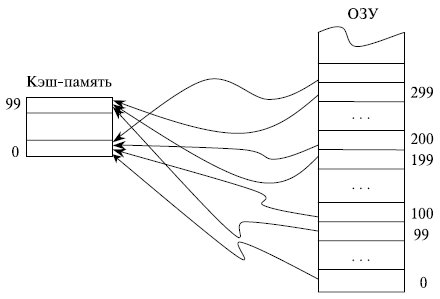
Рис. 4.2. Принцип организации кэш-памяти с прямым отображением
Кэш - память называется полностью ассоциативной, если каждая строка ОЗУ может располагаться в любом месте кэш -памяти.
В полностью ассоциативной кэш -памяти максимально используется весь ее объем: вытеснение сохраненной в КП информации проводится лишь после ее полного заполнения. Однако поиск в кэш -памяти, организованной подобным образом, представляет собой трудную задачу.
Компромиссом между этими двумя способами организации кэш -памяти служит множественно-ассоциативная КП, в которой каждая строка ОЗУ может находиться по ограниченному множеству мест в кэш -памяти.
При необходимости замещения информации в кэш -памяти на новую используется несколько стратегий замещения. Наиболее известными среди них являются:
- LRU - замещается строка, к которой дольше всего не было обращений;
- FIFO - замещается самая давняя по пребыванию в кэш-памяти строка;
- Random - замещение проходит случайным образом.
Последний вариант, существенно экономя аппаратные средства по сравнению с другими подходами, в ряде случаев обеспечивает и более эффективное использование кэш -памяти. Предположим, например, что КП имеет объем 4 строки, а некоторый циклический участок программы имеет длину 5 строк. В этом случае при стратегиях LRU и FIFO кэш - память окажется фактически бесполезной ввиду отсутствия кэш -попаданий. В то же время при использовании стратегии случайного замещения информации часть обращений к КП приведет к кэш -попаданиям.
Некоторые эвристические оценки вероятности кэш -промаха при разных стратегиях замещения (в процентах) представлены в табл. 4.1.
Анализ таблицы показывает, что:
- увеличением емкости кэша, естественно, уменьшается вероятность кэш-промаха, но даже при незначительной на сегодняшний день емкости кэш-памяти в 16 Кбайт около 95 % обращений происходят к КП, минуя оперативную память;
- чем больше степень ассоциативности кэш-памяти, тем больше вероятность кэш-попадания за счет более полного заполнения КП (время поиска информации в КП в данном анализе не учитывается);
- механизм LRU обеспечивает более высокую вероятность кэш-попадания по сравнению с механизмом случайного замещения Random , однако этот выигрыш не очень значителен.
Соответствие между данными в оперативной памяти и в кэш -памяти обеспечивается внесением изменений в те области ОЗУ , для которых данные в кэш -памяти подверглись изменениям. Существует два основных способа реализации этих действий: со сквозной записью ( writethrough ) и с обратной записью ( write-back ).
При считывании оба способа работают идентично. При записи кэширование со сквозной записью обновляет основную память параллельно с обновлением информации в КП. Это несколько снижает быстродействие системы, так как микропроцессор впоследствии может вновь обратиться по этому же адресу для записи информации, и предыдущая пересылка строки кэш -памяти в ОЗУ окажется бесполезной. Однако при таком подходе содержимое соответствующих друг другу строк ОЗУ и КП всегда идентично. Это играет большую роль в мультипроцессорных системах с общей оперативной памятью.
Кэширование с обратной записью модифицирует строку ОЗУ лишь при вытеснении строки кэш -памяти, например, в случае необходимости освобождения места для записи новой строки из ОЗУ в уже заполненную КП. Операции обратной записи также инициируются механизмом поддержания согласованности кэш -памяти при работе мультипроцессорной системы с общей оперативной памятью.
Промежуточное положение между этими подходами занимает способ, при котором все строки, предназначенные для передачи из КП в ОЗУ , предварительно накапливаются в некотором буфере. Передача осуществляется либо при вытеснении строки, как в случае кэширования с обратной записью, либо при необходимости согласования кэш -памяти нескольких микропроцессоров в мультипроцессорной системе, либо при заполнении буфера. Такая передача проводится в пакетном режиме, что более эффективно, чем передача отдельной строки.
Перед началом основной беседы о важности объема кэш-памяти у процессоров остановлюсь на криптовалюте Raptoreum, которая, собственно, и подтолкнула меня написать этот блог. Кто хочет узнать, что ожидает всех майнеров и геймеров в следующем году, когда появятся видеокарты на рынке, вероятный прогноз развития событий можно найти здесь.
реклама

А теперь о Raptoreum. Важно! Не поддавайтесь на провокации, относительно этой криптовалюты, которая добывается на мощностях кэш-памяти центральных процессоров! Чем больше кэш-память второго и любого последующего уровня (при его наличии), тем быстрее происходят расчёты, результатом которых является условный доход. Так как сейчас на рынке именно у процессоров AMD самый «жирный» кэш, то наличие их на полках магазинов и соответственно рекомендованной стоимости этих процессоров под угрозой со стороны новой криптовалюты. Под удар могут попасть старейшие модели AMD Ryzen и все Threadripper.
MSI RTX 3070 сливают дешевле любой другой, это за копейки Дешевая 3070 Gigabyte Gaming - успей пока не началосьА теперь поговорим о кэш-памяти процессора. При решении задач процессор получает из оперативной памяти необходимые блоки информации, обработав их, он записывает в память результаты вычислений и получает для обработки следующие блоки. Этот процесс продолжается, пока задача не будет на 100% выполнена.

Все эти операции производятся на очень высоких скоростях, от десятков гигабайт в секунду у процессоров 20-ти летней давности, до сотен гигабайт в секунду у современных процессоров. Все это время процессор обменивается данными с оперативной памятью, которая работает в разы медленнее самого процессора. Каждое считывание из нее и обратная запись информации в неё отнимают уйму времени.
реклама
var firedYa28 = false; window.addEventListener('load', () => < if(navigator.userAgent.indexOf("Chrome-Lighthouse") < window.yaContextCb.push(()=>< Ya.Context.AdvManager.render(< renderTo: 'yandex_rtb_R-A-630193-28', blockId: 'R-A-630193-28' >) >) >, 3000); > > >);Несмотря на такой дисбаланс, процессор не простаивает в ожидании очередной порции данных из оперативной памяти, так как эти данные подгружаются в его кэш-память.
Кэш-память процессора – это небольшая по объему, но супербыстрая оперативная память. Она встроена в процессор и является своеобразным буфером, при обмене CPU данными с медленной оперативной памятью, а в современных реалиях еще и с NVME SSD и видеокартой.

В большинстве процессоров используется многоуровневая система кэша:
реклама
• Кэш-память первого уровня или L1 – самая маленькая, но и самая быстрая область кэш-памяти. Её объем не превышает пару десятков килобайт. Работает L1 без каких-либо задержек. В нем содержатся данные, которые чаще всего используются процессором.
• Кэш-память второго уровня (L2) чуть медленнее кэш-памяти L1, но и объем ее в современных процессорах измеряется уже в мегабайтах. Служит она для временного хранения важных данных, вероятность запроса которых ниже, чем у данных, находящихся в L1 кэше.
• Кэш-память третьего уровня (L3) – еще более объемная и еще более медленная. Но она все равно быстрее любой оперативной памяти, даже новой DDR5. Со скоростями в несколько сотен гигабайт в секунду пока еще приходится считаться. Ее размер в современных процессорах в мейнстрим сегменте достигает нескольких десятков мегабайт, а в серверных AMD Epyc счет пошел уже на сотни мегабайт. В отличие от L1 и L2, кэш третьего уровня является общим для всех ядер процессора.
L3 кэш служит для временного хранения важной информации с относительно низкой вероятностью запроса, а также для обеспечения обменом данными между ядрами процессора.
реклама

А теперь небольшой экскурс в развитие и эволюцию кэш-памяти. Если за отправную точку взять Pentium 1, то кэша L2 у него не было. L1 был объёмом 32 Кб. L2 как правило распаивался на материнской плате. Когда появился Pentium II, то L2 сразу стал равным 512 Кб, но он располагался рядом с ядром процессора на отдельной микросхеме и имел низкую скорость, но все равно это лучше, чем ничего.
Pentium-III с Socket 370 имел уже половину объема от Pentium II – 256 Кб, но зато этот кэш был быстрее, так как он был интегрирован в кристалл процессора. Pentium 4 вначале удвоил этот объём до 512 Кб, так называемый Nothwood, а последовавшее за ним ядро Prescott довел L2 до 1 Мб. Это уже объём дней сегодняшних.

Во времена Pentium 4 случилось еще одно важное событие: у Pentium 4 Extreme Edition впервые появился L3 кэш. До этого момента в десктопах такого явления не было. Объем L3 равнялся «жирным» 2 мегабайтам, что положительно влияло на производительность и цену процессора.

После смены с 478 на 775 контактов без ножек, первые “новые” Pentium с ядрами Prescott-2M и Cedar Mill увеличили L2 до 2-х мегабайт, а L1 так и оставался в пределах 32 Кб.
Микроархитектура Core2 и Core2 Quad значительно увеличили объемы кэшей. Так, объем L2 кэша уже варьировался от 4 до 12 Мб, но эти цифры нужно поделить на два, из особенности организации кэша, так как группы ядер по факту взаимодействовали только с половиной этого объема, но суммарный объем был именно таким.
Микроархитектура Sandy Bridge поделила процессоры на различные линейки в зависимости от объема L2 кэша. В этот момент времени, именно объем кэш-памяти начинает решать главенствующую роль в позиционировании и производительности процессоров.

Так, i5-2500К отличался от i7-2600K только объемом кэша. И надо отметить, речь уже идет о L3 кэше, который начинает появляться уже повсеместно. В первом случае L3 = 6 Мб, во втором 8 Мб. L2 у обеих моделей равнялся 256 Кб на одно ядро, а L1 был равен по-прежнему 32 Кб.
Далее происходит рост L3 у последующих поколений. У i9-9900K он уже равен 16 Мб. Параллельно развивается HEDT линейка процессоров Intel, где L3 уже достигает 24.5 Мб. Но дальнейшее развитие всей процессорной архитектуры меняют процессоры AMD с микроархитектурой ZEN и производные от них. Стартовало первое поколение AMD Ryzen c L2 = 512 Кб и L3 = 8 Мб, а на сегодняшний день топовый Ryzen Gen3 уже обладает 64 Мб L3 кэша. Недавний анонс новых серверных процессоров AMD Epyс вообще увеличил объем L3 до астрономических 768 Мб.

Таким образом, система кэшей процессора позволяет частично уйти от зависимости от низкой производительности оперативной памяти, ведь процесс развития процессоров и скорости их кэшей намного опережает скорость оперативной памяти. Важно отметить и тот факт, что чем больше кэша у процессора, тем выше его производительность.
Поэтому при выборе того или иного процессора, обращайте внимание на объем L3 кэша процессора. Возможно, в будущем, объемы порядка пары гигабайт L3 кэша станут нормой, но а пока следим за стоимостью AMD Ryzen, в зависимости от популярности Raptoreum. Надеюсь, этот блог оказался для вас полезным.
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | LostKeys |
|---|---|---|---|
| 5 | 4 | 80.03% | 800345 |
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.

На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей ( k / N , где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:

На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:

Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.

Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде t otal_users_count_1 , total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Читайте также: