
Конструктор копирования с динамическим выделением памяти c
Обновлено: 05.07.2024
На этом уроке мы рассмотрим поверхностное и глубокое копирование в языке C++.
Поверхностное копирование
Поскольку язык C++ не может знать наперед всё о вашем классе, то конструктор копирования и оператор присваивания, которые C++ предоставляет по умолчанию, используют почленный метод копирования — поверхностное копирование. Это означает, что C++ выполняет копирование для каждого члена класса индивидуально (используя оператор присваивания по умолчанию вместо перегрузки оператора присваивания и прямую инициализацию вместо конструктора копирования). Когда классы простые (например, в них нет членов с динамически выделенной памятью), то никаких проблем с этим не должно возникать.
Рассмотрим следующий класс Drob:
m_numerator ( numerator ) , m_denominator ( denominator ) friend std :: ostream & operator << ( std :: ostream & out , const Drob &d1 ) ; std :: ostream & operator << ( std :: ostream & out , const Drob &d1 )Конструктор копирования и оператор присваивания по умолчанию, предоставляемые компилятором автоматически, выглядят примерно следующим образом:
m_numerator ( numerator ) , m_denominator ( denominator ) m_numerator ( d . m_numerator ) , m_denominator ( d . m_denominator ) friend std :: ostream & operator << ( std :: ostream & out , const Drob &d1 ) ; std :: ostream & operator << ( std :: ostream & out , const Drob &d1 ) // Возвращаем текущий объект, чтобы иметь возможность выполнять цепочку операций присваиванияПоскольку эти конструктор копирования и оператор присваивания по умолчанию отлично подходят для выполнения копирования с объектами этого класса, то действительно нет никакого смысла писать здесь свои собственные версии конструктора копирования и перегрузки оператора.
Однако при работе с классами, в которых динамически выделяется память, почленное (поверхностное) копирование может вызывать проблемы! Это связано с тем, что при поверхностном копировании указателя копируется только адрес указателя — никаких действий по содержимому адреса указателя не предпринимается. Например:
assert ( source ) ; // проверяем не является ли source нулевой строкой // Определяем длину source + еще один символ для нуль-терминатора (символ завершения строки) // Выделяем достаточно памяти для хранения копируемого значения в соответствии с длиной этого значения // Копируем значение по символам в нашу выделенную памятьВышеприведенный класс — это обычный строковый класс, в котором выделяется память для хранения передаваемой строки. Здесь мы не определяли конструктор копирования или перегрузку оператора присваивания. Следовательно, язык C++ предоставит конструктор копирования и оператор присваивания по умолчанию, которые будут выполнять поверхностное копирование. Конструктор копирования выглядит примерно следующим образом:
m_length ( source . m_length ) , m_data ( source . m_data ) SomeString copy = hello ; // используется конструктор копирования по умолчанию > // объект copy является локальной переменной, которая уничтожается здесь. Деструктор удаляет значение-строку объекта copy, оставляя, таким образом, hello с висячим указателем std :: cout << hello . getString ( ) << '\n' ; // здесь неопределенные результатыХотя этот код выглядит достаточно безвредным, но он имеет в себе коварную проблему, которая приведет к сбою программы! Можете найти эту проблему? Если нет, то ничего страшного.
Разберем этот код по строкам:
SomeString copy = hello ; // используется конструктор копирования по умолчаниюЭта строка также кажется достаточно безвредной, но именно она и является источником нашей коварной проблемы! При обработке этой строки C++ будет использовать конструктор копирования по умолчанию (так как мы не предоставили своего). Выполнится поверхностное копирование, результатом чего будет инициализация copy.m_data адресом, на который указывает hello.m_data . И теперь copy.m_data и hello.m_data оба указывают на одну и ту же часть памяти!
Когда объект-копия выходит из области видимости, то вызывается деструктор SomeString для этой копии. Деструктор удаляет динамически выделенную память, на которую указывают как copy.m_data , так и hello.m_data ! Следовательно, удаляя копию, мы также (случайно) удаляем и данные hello . Объект copy затем уничтожается, но hello.m_data остается указывать на удаленную память!
std :: cout << hello . getString ( ) << '\n' ; // здесь неопределенные результатыТеперь вы поняли, почему эта программа работает не совсем так, как нужно. Мы удалили значение-строку, на которую указывал hello , а сейчас пытаемся вывести это значение.
Корнем этой проблемы является поверхностное копирование, выполняемое конструктором копирования по умолчанию. Такое копирование почти всегда приводит к проблемам.
Глубокое копирование
Одним из решений этой проблемы является выполнение глубокого копирования. При глубоком копировании память сначала выделяется для копирования адреса, который содержит исходный указатель, а затем для копирования фактического значения. Таким образом копия находится в отдельной, от исходного значения, памяти и они никак не влияют друг на друга. Для выполнения глубокого копирования нам необходимо написать свой собственный конструктор копирования и перегрузку оператора присваивания.
Рассмотрим это на примере с классом SomeString:
// Поскольку m_length не является указателем, то мы можем выполнить поверхностное копирование // m_data является указателем, поэтому нам нужно выполнить глубокое копирование, при условии, что этот указатель не является нулевымКак вы видите, реализация здесь более углубленная, нежели при поверхностном копировании! Во-первых, мы должны проверить, имеет ли исходный объект ненулевое значение вообще (строка №8). Если имеет, то мы выделяем достаточно памяти для хранения копии этого значения (строка №11). Наконец, копируем значение-строку (строки №14-15).
Теперь рассмотрим перегрузку оператора присваивания:
SomeString & SomeString :: operator = ( const SomeString & source ) // Сначала нам нужно очистить предыдущее значение m_data (члена неявного объекта) // Поскольку m_length не является указателем, то мы можем выполнить поверхностное копирование // m_data является указателем, поэтому нам нужно выполнить глубокое копирование, при условии, что этот указатель не является нулевымЗаметили, что код перегрузки очень похож на код конструктора копирования? Но здесь есть 3 основных отличия:
Мы добавили проверку на самоприсваивание.
Мы возвращаем текущий объект (с помощью указателя *this), чтобы иметь возможность выполнить цепочку операций присваивания.
Мы явно удаляем любое значение, которое объект уже хранит (чтобы не произошло утечки памяти).
При вызове перегруженного оператора присваивания, объект, которому присваивается другой объект, может содержать предыдущее значение, которое нам необходимо очистить/удалить, прежде чем мы выделим память для нового значения. С не динамически выделенными переменными (которые имеют фиксированный размер) нам не нужно беспокоиться, поскольку новое значение просто перезапишет старое. Однако с динамически выделенными переменными нам нужно явно освободить любую старую память до того, как мы выделим любую новую память. Если мы этого не сделаем, сбоя не будет, но произойдет утечка памяти, которая будет съедать нашу свободную память каждый раз, когда мы будем выполнять операцию присваивания!
Лучшее решение
В Стандартной библиотеке C++ классы, которые работают с динамически выделенной памятью, такие как std::string и std::vector, имеют свое собственное управление памятью и свои конструкторы копирования и перегрузку операторов присваивания, которые выполняют корректное глубокое копирование. Поэтому, вместо написания своих собственных конструкторов копирования и перегрузки оператора присваивания, вы можете выполнять инициализацию или присваивание строк, или векторов, как обычных переменных фундаментальных типов данных! Это гораздо проще, менее подвержено ошибкам, и вам не нужно тратить время на написание лишнего кода!
Заключение
Конструктор копирования и оператор присваивания, предоставляемые по умолчанию языком C++, выполняют поверхностное копирование, что отлично подходит для классов без динамически выделенных членов.
Классы с динамически выделенными членами должны иметь конструктор копирования и перегрузку оператора присваивания, которые выполняют глубокое копирование.
Используйте функциональность классов из Стандартной библиотеки C++, нежели самостоятельно выполняйте/реализовывайте управление памятью.
В данной теме рассмотрена работа конструктора копирования на примере unmanaged ( native ) классов. При рассмотрении данной темы рекомендуется прочитать тему:
Содержание
- 1. Какое назначение конструктора копирования (copy constructor)?
- 2. В каких случаях вызывается конструктор копирования?
- 3. В каких случаях целесообразно использовать конструктор копирования?
- 4. Пример объявления конструктора копирования в классе, где нет динамического выделения памяти
- 5. Пример передачи объекта класса в функцию как параметр-значение
- 6. Пример возврата объекта класса из функции по значению с помощью конструктора копирования
- Связанные темы
Поиск на других ресурсах:
1. Какое назначение конструктора копирования ( copy constructor )?
Конструктор копирования – это специальный конструктор, который позволяет получить идентичный к заданному объект. То есть, с помощью конструктора копирования можно получить копию уже существующего объекта. Конструктор копирования еще называется инициализатором копии ( copy initializer ). Конструктор копирования должен получать входным параметром константную ссылку ( & ) на объект такого же класса.
⇑
2. В каких случаях вызывается конструктор копирования?
Конструктор копирования вызывается в случаях, когда нужно получить полную копию объекта. В C++ полная копия объекта нужна в трех случаях.
Случай 1. В момент объявления нового объекта и его инициализации данными другого объекта с помощью оператора = . Следующий фрагмент кода демонстрирует данную ситуацию для некоторого класса ClassName
В этом случае нужно скопировать данные из объекта obj1 в объект obj2 . То есть, нужно создать копию объекта obj1 так, чтобы этот объект мог в дальнейшем корректно использоваться в программе. Поэтому нужна копия. Этим занимается конструктор копирования.
Случай 2. Когда нужно передать объект в функцию как параметр-значение. В этом случае создается полная копия объекта.
Случай 3. Когда нужно вернуть объект из функции по значению. В этом случае также создается полная копия объекта.
⇑
3. В каких случаях целесообразно использовать конструктор копирования?
Конструктор копирования необходимо использовать в тех классах, где осуществляется динамическое выделение памяти для данных. Другими словами, если в классе есть указатель, для которого память выделяется динамически с помощью оператора new (или других функций), то такой класс обязательно должен иметь конструктор копирования. В противном случае, в программе будут возникать проблемы, связанные с недостатками побитового копирования . Кроме того, такой класс должен содержать операторную функцию operator=(), перегружающую оператор копирования (это уже другая тема ).
Если в классе нету динамического выделения памяти для данных, то конструктор копирования можно не использовать. В этом случае побитового копирования (по умолчанию) достаточно для корректной работы класса. Исключение, если при инициализации объекта другим объектом нужно установить некоторые специальные условия копирования.
⇑
4. Пример объявления конструктора копирования в классе, где нет динамического выделения памяти
Данный пример носит демонстрационный характер. Для класса, где нет динамического выделения памяти использовать конструктор копирования необязательно.
Пример. Пусть задан класс CMyPoint , описывающий точку на координатной плоскости. В классе объявляется несколько конструкторов, в том числе и конструктор копирования.
Демонстрация использования конструктора копирования в некотором программном коде (методе)
⇑
5. Пример передачи объекта класса в функцию как параметр-значение
В примере передается объект класса CMyPoint (см. п. 4) в функцию GetLength() , которая вычисляет расстояние от точки CMyPoint к началу координат. Текст функции следующий:
Использование функции в другом программном коде
⇑
6. Пример возврата объекта класса из функции по значению с помощью конструктора копирования
Реализовать функцию GetCenterPoint() , которая возвращает точку, которая есть серединой отрезка, проведенного между точкой CMyPoint и началом координат.
Объявление класса точно такое же как в п. 4.
Реализация двух вариантов функций GetCenterPoint() и GetCenterPoint2() .
Демонстрация использования функций
В первом варианте GetCenterPoint() конструктор копирования вызывается только при передаче параметра mp по значению. При возврате из функции GetCenterPoint() с помощью оператора return , конструктор копирования не вызывается. Вместо него вызывается конструктор с двумя параметрами, объявленными в классе.
Во втором варианте GetCenterPoint2() конструктор копирования вызывается при возвращении из функции оператором return . В операторе return создается временный объект класса CMyPoint , который сразу инициализируется значением mp , в результате этого вызывается конструктор копирования.
⇑
7. Как осуществляется копирование объектов, когда в классе отсутствует конструктор копирования?
Если в классе не объявлен конструктор копирования, то используется конструктор копирования, который автоматически генерируется компилятором. Этот конструктор копирования реализует побитовое копирование для получения копии объекта.
Побитовое копирование есть приемлемым для классов, в которых нет динамического выделения памяти. Однако, если в классе есть динамическое выделение памяти (класс использует указатели), то побитовое копирование приведет к тому, что указатели обоих объектов будут указывать на один и тот же участок памяти. А это ошибка.
- при передаче объекта класса в функцию, как параметра по значению (а не по ссылке);
- при возвращении из функции объекта класса, как результата её работы;
- при инициализации одного объекта класса другим объектом этого класса.
При передаче объекта в функцию как параметра по значению, эта функция начнет работать с его побитовой копией, а не с полями самого объекта. Допустим определены конструктор и деструктор класса. Первый память выделяет, а второй её освобождает. Во время работы функции, указатель побитовой копии объекта указывает на адрес памяти, где расположен оригинальный объект.
Конструктор копирования синтаксически выглядит так:
Ниже разберём несложный, но очень показательный пример. В нём будут рассмотрены все 3 случая в которых желательно применять конструктор копирования. Будет создан класс, содержащий конструктор без параметров, конструктор копирования и деструктор.
Нам отлично будет видно сколько раз сработают конструкторы а сколько раз деструктор. Очевидно, что деструктор (если бы он освобождал память) не должен срабатывать большее количество раз, чем конструктор, выделяющий память.
cout << "\nЭта функция принимает объект класса, как параметр.\n" ; cout << "Сначала срабатывает конструктор копирования (т.к. создается реальная копия объекта).\n" ; cout << "Затем выполняется код функции. А при выходе из нее - сработает деструктор.\n" ; OneClass object ; // тут сработает конструктор без параметров cout << "При выходе из нее, деструктор сработает дважды.\n" ; return object ; // тут сработает конструктор копирования returnObjectFunc ( ) ; // функция returnObjectFunc() возвращает объект OneClass object2 = object1 ; // инициализация объекта object2 при создании // при завершении программы деструктор сработает дваждыЗапустив программу увидим в консоли следующее:
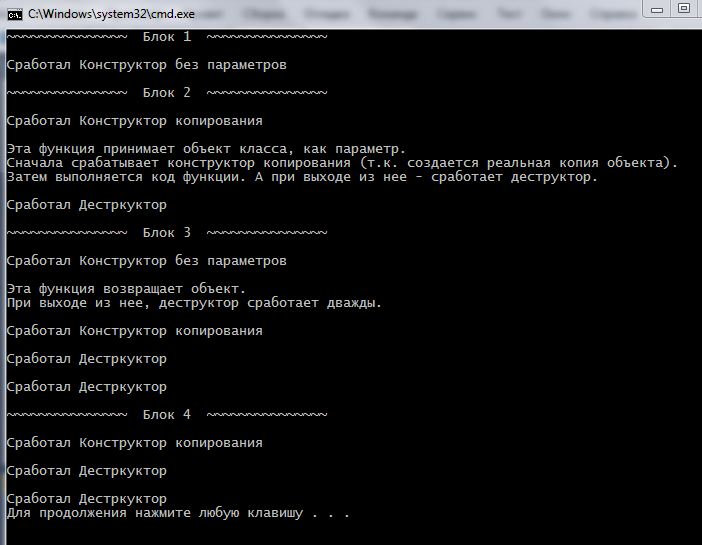
При выходе из этой функции сработал деструктор, так как копия объекта уничтожается. Кстати, то, что передача объекта как параметра по значению, вызывает конструктор копирования, служит отличным поводом для передачи объекта по ссылке. Это сэкономит и время и память.
В четвертом блоке, во время объявления и инициализации нового объекта object2 , сработал конструктор копирования. При завершении работы программы деструктор сработал для копии объекта из четвертого блока и для объекта object1 из первого блока.
В этой ситуации, если бы деструктор освобождал память — в программе возникла бы ошибка.
В предыдущей главе уже обсуждалось, что локальные переменные кладутся на стек и существую до тех пор, пока мы не вышли из функции. С одной стороны, это позволяет автоматически очищать память, с другой стороны, существует необходимость в переменных, время жизни которых мы можем контролировать самостоятельно. Кроме того, нам необходимо динамическое выделение памяти, когда размер используемого пространства заранее не известен. Для этого используется выделение памяти на куче. Недостатков у такого подхода два: во-первых, память необходимо вручную очищать, во-вторых, выдеение памяти – достаточно дорогостоящая операция.
Для выделения памяти на куче в си используется функция malloc (memory allocation) из библиотеки stdlib.h
Функция выделяет size байтов памяти и возвращает указатель на неё. Если память выделить не удалось, то функция возвращает NULL. Так как malloc возвращает указатель типа void, то его необходимо явно приводить к нужному нам типу. Например, создадим указатель, после этого выделим память размером в 100 байт.
После того, как мы поработали с памятью, необходимо освободить память функцией free.
Используя указатель, можно работать с выделенной памятью как с массивом. Пример: пользователь вводит число – размер массива, создаём массив этого размера и заполняем его квадратами чисел по порядку. После этого выводим и удаляем массив.
Здесь (int *) – приведение типов. Пишем такой же тип, как и у указателя.
size * sizeof(int) – сколько байт выделить. sizeof(int) – размер одного элемента массива.
После этого работаем с указателем точно также, как и с массивом. В конце не забываем удалять выделенную память.
Теперь представим на рисунке, что у нас происходило. Пусть мы ввели число 5.
Функция malloc выделила память на куче по определённому адресу, после чего вернула его. Теперь указатель p хранит этот адрес и может им пользоваться для работы. В принципе, он может пользоваться и любым другим адресом.
Когда функция malloc "выделяет память", то она резервирует место на куче и возвращает адрес этого участка. У нас будет гарантия, что компьютер не отдаст нашу память кому-то ещё. Когда мы вызываем функцию free, то мы освобождаем память, то есть говорим компьютеру, что эта память может быть использована кем-то другим. Он может использовать нашу память, а может и нет, но теперь у нас уже нет гарантии, что эта память наша. При этом сама переменная не зануляется, она продолжает хранить адрес, которым ранее пользовалась.
Это очень похоже на съём номера в отеле. Мы получаем дубликат ключа от номера, живём в нём, а потом сдаём комнату обратно. Но дубликат ключа у нас остаётся. Всегда можно зайти в этот номер, но в нём уже кто-то может жить. Так что наша обязанность – удалить дубликат.
Иногда думают, что происходит "создание" или "удаление" памяти. На самом деле происходит только перераспределение ресурсов.
Освобождение памяти с помощью free
Т еперь рассмотри, как происходит освобождение памяти. Переменная указатель хранит адрес области памяти, начиная с которого она может им пользоваться. Однако, она не хранит размера этой области. Откуда тогда функция free знает, сколько памяти необходимо освободить?
- 1. Можно создать карту, в которой будет храниться размер выделенного участка. Каждый раз при освобождении памяти компьютер будет обращаться к этим данным и получать нужную информацию.
- 2. Второе решение более распространено. Информация о размере хранится на куче до самих данных. Таким образом, при выделении памяти резервируется места больше и туда записывается информация о выделенном участке. При освобождении памяти функция free "подсматривает", сколько памяти необходимо удалить.
Работа с двумерными и многомерными массивами
Д ля динамического создания двумерного массива сначала необходимо создать массив указателей, после чего каждому из элементов этого массива присвоить адрес нового массива.
Для удаления массива необходимо повторить операцию в обратном порядке - удалить сначала подмассивы, а потом и сам массив указателей.
- 1. Создавать массивы "неправильной формы", то есть массив строк, каждая из которых имеет свой размер.
- 2. Работать по отдельности с каждой строкой массива: освобождать память или изменять размер строки.
Создадим "треугольный" массив и заполним его значениями
Чтобы создать трёхмерный массив, по аналогии, необходимо сначала определить указатель на указатель на указатель, после чего выделить память под массив указателей на указатель, после чего проинициализировать каждый из массивов и т.д.
calloc
Ф ункция calloc выделяет n объектов размером m и заполняет их нулями. Обычно она используется для выделения памяти под массивы. Синтаксис
realloc
Е щё одна важная функция – realloc (re-allocation). Она позволяет изменить размер ранее выделенной памяти и получает в качестве аргументов старый указатель и новый размер памяти в байтах:
Функция realloc может как использовать ранее выделенный участок памяти, так и новый. При этом не важно, меньше или больше новый размер – менеджер памяти сам решает, где выделять память.
Пример – пользователь вводит слова. Для начала выделяем под слова массив размером 10. Если пользователь ввёл больше слов, то изменяем его размер, чтобы хватило места. Когда пользователь вводит слово end, прекращаем ввод и выводим на печать все слова.
Хочу обратить внимание, что мы при выделении памяти пишем sizeof(char*), потому что размер указателя на char не равен одному байту, как размер переменной типа char.
Ошибки при выделении памяти
1. Бывает ситуация, при которой память не может быть выделена. В этом случае функция malloc (и calloc) возвращает NULL. Поэтому, перед выделением памяти необходимо обнулить указатель, а после выделения проверить, не равен ли он NULL. Так же ведёт себя и realloc. Когда мы используем функцию free проверять на NULL нет необходимости, так как согласно документации free(NULL) не производит никаких действий. Применительно к последнему примеру:
Хотелось бы добавить, что ошибки выделения памяти могут случиться, и просто выходить из приложения и выкидывать ошибку плохо. Решение зависит от ситуации. Например, если не хватает памяти, то можно подождать некоторое время и после этого опять попытаться выделить память, или использовать для временного хранения файл и переместить туда часть объектов. Или выполнить очистку, сократив используемую память и удалив ненужные объекты.
2. Изменение указателя, который хранит адрес выделенной области памяти. Как уже упоминалось выше, в выделенной области хранятся данные об объекте - его размер. При удалении free получает эту информацию. Однако, если мы изменили указатель, то удаление приведёт к ошибке, например
Таким образом, если указатель хранит адрес, то его не нужно изменять. Для работы лучше создать дополнительную переменную указатель, с которой работать дальше.
3. Использование освобождённой области. Почему это работает в си, описано выше. Эта ошибка выливается в другую – так называемые висячие указатели (dangling pointers или wild pointers). Вы удаляете объект, но при этом забываете изменить значение указателя на NULL. В итоге, он хранит адрес области памяти, которой уже нельзя воспользоваться, при этом проверить, валидная эта область или нет, у нас нет возможности.
Эта программа отработает и выведет мусор, или не мусор, или не выведет. Поведение не определено.
Если же мы напишем
то программа выкинет исключение. Это определённо лучше, чем неопределённое поведение. Если вы освобождаете память и используете указатель в дальнейшем, то обязательно обнулите его.
4. Освобождение освобождённой памяти. Пример
Здесь дважды вызывается free для переменной a. При этом, переменная a продолжает хранить адрес, который может далее быть передан кому-нибудь для использования. Решение здесь такое же как и раньше - обнулить указатель явно после удаления:
5. Одновременная работа с двумя указателями на одну область памяти. Пусть, например, у нас два указателя p1 и p2. Если под первый указатель была выделена память, то второй указатель может запросто скомпрометировать эту область:
Рассмотрим код ещё раз.
Теперь оба указателя хранят один адрес.
А вот здесь происходит непредвиденное. Мы решили выделить под p2 новый участок памяти. realloc гарантирует сохранение контента, но вот сам указатель p1 может перестать быть валидным. Есть разные ситуации. Во-первых, вызов malloc мог выделить много памяти, часть которой не используется. После вызова ничего не поменяется и p1 продолжит оставаться валидным. Если же потребовалось перемещение объекта, то p1 может указывать на невалидный адрес (именно это с большой вероятностью и произойдёт в нашем случае). Тогда p1 выведет мусор (или же произойдёт ошибка, если p1 полезет в недоступную память), в то время как p2 выведет старое содержимое p1. В этом случае поведение не определено.
Два указателя на одну область памяти это вообще-то не ошибка. Бывают ситуации, когда без них не обойтись. Но это очередное минное поле для программиста.
Различные аргументы realloc и malloc.
При вызове функции malloc, realloc и calloc с нулевым размером поведение не определено. Это значит, что может быть возвращён как NULL, так и реальный адрес. Им можно пользоваться, но к нему нельзя применять операцию разадресации.
Вызов realloc(NULL, size_t) эквиваленте вызову malloc(size_t).
Однако, вызов realloc(NULL, 0) не эквивалентен вызову malloc(0) :) Понимайте это, как хотите.
Примеры
1. Простое скользящее среднее равно среднему арифметическому функции за период n. Пусть у нас имеется ряд измерений значения функции. Часто эти измерения из-за погрешности "плавают" или на них присутствуют высокочастотные колебания. Мы хотим сгладить ряд, для того, чтобы избавиться от этих помех, или для того, чтобы выявить общий тренд. Самый простой способ: взять n элементов ряда и получить их среднее арифметическое. n в данном случае - это период простого скользящего среднего. Так как мы берём n элементов для нахождения среднего, то в результирующем массиве будет на n чисел меньше.
Это простой пример. Большая его часть связана со считыванием данных, вычисление среднего всего в девяти строчках.
2. Сортировка двумерного массива. Самый простой способ сортировки - перевести двумерный массив MxN в одномерный размером M*N, после чего отсортировать одномерный массив, а затем заполнить двумерный массив отсортированными данными. Чтобы не тратить место под новый массив, мы поступим по-другому: если проходить по всем элементам массива k от 0 до M*N, то индексы текущего элемента можно найти следующим образом:
j = k / N;
i = k - j*M;
Заполним массив случайными числами и отсортируем
3. Бином Ньютона. Создадим треугольную матрицу и заполним биномиальными коэффициентами
Если Вы желаете изучать этот материал с преподавателем, советую обратиться к репетитору по информатике

Читайте также: