
Могут ли сегменты виртуальной памяти быть разделяемыми между несколькими процессами
Обновлено: 02.07.2024
С понятием управления паметью в ОС связаны следующие технологии:
- Функции управления памятью в ОС
- Типы адресов
- Методы распределения памяти в ОС
- Принцип кэширования данных в ОС
Содержание
Функции управления памятью в ОС
Операционная система решает следующие задачи:
- Отслеживание свободной и занятой памяти.
- Выделение и освобождение памяти по запросам процессов.
- Обеспечение настройки адресов.
- Поддержка механизма виртуальной памяти
Типы адресов
Для идентификации переменных и команд используются символьные имена (метки), виртуальные адреса и физические адреса.
Символьные имена
Символьные имена присваивает пользователь при написании программы.
Виртуальные адреса
Виртуальные адреса вырабатывает компилятор. Так как не известно, в какое место оперативной памяти будет загружена программа, то компилятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство.
Физические адреса
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами.
В первом случае замену виртуальных адресов на физические делает специальная системная программа - перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной компилятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, при этом операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический.
Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти. Вместе с тем использование перемещающего загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае - каждый раз при обращении по данному адресу.
Иногда (обычно в специализированных системах) заранее точно известно, в какой области оперативной памяти будет выполняться программа, и компилятор выдает исполняемый код сразу в физических адресах.
В стандарте POSIX-2001 разделяемый объект памяти определяется как объект , представляющий собой память , которая может быть параллельно отображена в адресное пространство более чем одного процесса.
Таким образом, процессы могут иметь общие области виртуальной памяти и разделять содержащиеся в них данные. Единицей разделяемой памяти являются сегменты . Разделение памяти обеспечивает наиболее быстрый обмен данными между процессами.
Работа с разделяемой памятью начинается с того, что один из взаимодействующих процессов посредством функции shmget() создает разделяемый сегмент , специфицируя первоначальные права доступа к нему и его размер в байтах.
Чтобы получить доступ к разделяемому сегменту , его нужно присоединить (для этого служит функция shmat() ), т. е. разместить сегмент в виртуальном пространстве процесса. После присоединения, в соответствии с правами доступа, процессы могут читать данные из сегмента и записывать их (быть может, синхронизируя свои действия с помощью семафоров ). Когда разделяемый сегмент становится ненужным, его следует отсоединить с помощью функции shmdt() .
Предусмотрена возможность выполнения управляющих действий над разделяемыми сегментами ( функция shmctl() ).
Описание перечисленных функций представлено в листинге 8.40.
Листинг 8.40. Описание функций для работы с разделяемыми сегментами памяти.Структура shmid_ds , ассоциированная с идентификатором разделяемого сегмента памяти, должна содержать по крайней мере следующие поля.
Функция shmget() аналогична msgget() и semget() ; аргумент size задает нижнюю границу размера сегмента в байтах; реализация, учитывающая, например, правила выравнивания, имеет право создать разделяемый сегмент большего размера.
Структура shmid_ds инициализируется в соответствии с общими для средств межпроцессного взаимодействия правилами. Поле shm_segsz устанавливается равным значению аргумента size .
Число уникальных идентификаторов разделяемых сегментов памяти ограничено; попытка его превышения ведет к неудачному завершению shmget() (возвращается -1 ). Вызов shmget() завершится неудачей и тогда, когда значение аргумента size меньше минимально допустимого либо больше максимально допустимого размера разделяемого сегмента .
Чтобы присоединить разделяемый сегмент , используется функция shmat() . Аргумент shmid задает идентификатор разделяемого сегмента ; аргумент shmaddr - адрес , по которому сегмент должен быть присоединен, т. е. тот адрес в виртуальном пространстве процесса, который получит начало сегмента . Поскольку свойства сегментов зависят от аппаратных особенностей управления памятью, не всякий адрес является приемлемым. Если установлен флаг SHM_RND , адрес присоединения округляется до величины, кратной константе SHMLBA .
Если shmaddr задан как пустой указатель , реализация выбирает адрес присоединения по своему усмотрению.
По умолчанию присоединяемый сегмент будет доступен и на чтение, и на запись (если процесс обладает необходимыми правами). Флаг SHM_RDONLY предписывает присоединить сегмент только для чтения.
При успешном завершении функции shmat() результат равен адресу, который получил присоединенный сегмент ; в случае неудачи возвращается -1 . (Разумеется, для использования результата shmat() в качестве указателя его нужно преобразовать к требуемому типу.)
Отсоединение сегментов производится функцией shmdt() ; аргумент shmaddr задает начальный адрес отсоединяемого сегмента .
Аппарат разделяемых сегментов предоставляет нескольким процессам возможность одновременного доступа к общей области памяти. Обеспечивая корректность доступа, процессы тем или иным способом должны синхронизировать свои действия. В качестве средства синхронизации удобно использовать семафор . В листинге 8.41 показана реализация так называемого критического интервала - механизма, обеспечивающего взаимное исключение разделяющих общие данные процессов.
Для "создания" подобного механизма необходимо породить разделяемый сегмент памяти , присоединить его во всех процессах, которым предоставляется доступ к разделяемым данным, а также породить и проинициализировать простейший семафор . После этого монопольный доступ к разделяемой структуре обеспечивается применением P- и V-операций.
Листинг 8.41. Пример работы с разделяемыми сегментами памяти.Результат работы приведенной программы может выглядеть так, как показано в листинге 8.42.
Листинг 8.42. Возможный результат синхронизации доступа к разделяемым данным.В листинге 8.43 представлен пример использования разделяемых сегментов памяти в сочетании с обработкой сигнала SIGSEGV , который посылается процессу при некорректном обращении к памяти. Идея в том, чтобы создавать разделяемые сегменты , "накрывающие" запрашиваемые адреса. При некотором воображении пример можно считать основой программной реализации виртуальной памяти .
Листинг 8.43. Пример работы с разделяемыми сегментами памяти и сигналами.Обратим внимание на использование флагов округления адреса присоединения разделяемого сегмента ( SHM_RND ) и присоединения только на чтение ( SHM_RDONLY ), а также обработчика сигналов, задаваемого полем sa_sigaction структуры типа sigaction (в сочетании с флагом SA_SIGINFO ) и имеющего доступ к расширенной информации о сигнале и его причинах.

Разделяемая память — самый быстрый способ обмена данными между процессами. Но в отличие от потоковых механизмов (трубы, сокеты всех мастей, файловые очереди . ), здесь у программиста полная свобода действий, в результате пишут кто во что горазд.
Так и автор однажды задался мыслью, а что если … если произойдёт вырождение адресов сегментов разделяемой памяти в разных процессах. Вообще-то именно это происходит, когда процесс с разделяемой памятью делает fork, а как насчет разных процессов? Кроме того, не во всех системах есть fork.
Казалось бы, совпали адреса и что с того? Как минимум, можно пользоваться абсолютными указателями и это избавляет от кучи головной боли. Станет возможно работать со строками и контейнерами С++, сконструированными из разделяемой памяти.
Отличный, кстати, пример. Не то, чтобы автор сильно любил STL, но это возможность продемонстрировать компактный и всем понятный тест на работоспособность предлагаемой методики. Методики, позволяющей (как видится) существенно упростить и ускорить межпроцессное взаимодействие. Вот работает ли она и чем придётся заплатить, будем разбираться далее.
Введение
Идея разделяемой памяти проста и изящна — поскольку каждый процесс действует в своём виртуальном адресном пространстве, которое проецируется на общесистемное физическое, так почему бы не разрешить двум сегментам из разных процессов смотреть на одну физическую область памяти.
А с распространением 64-разрядных операционных систем и повсеместным использованием когерентного кэша, идея разделяемой памяти получила второе дыхание. Теперь это не просто циклический буфер — реализация “трубы” своими руками, а настоящий “трансфункционер континуума” — крайне загадочный и мощный прибор, причем, лишь его загадочность равна его мощи.
Рассмотрим несколько примеров использования.
-
Протокол “shared memory” при обмене данными с MS SQL. Демонстрирует некоторое улучшение производительности (

Для проверки концепции требуется минимально-осмысленная задача:
- есть аналог std::map<std::string, std::string>, расположенный в разделяемой памяти
- имеем N процессов, которые асинхронно вносят/меняют значения с префиксом, соответствующим номеру процесса (ex: key_1_… для процесса номер 1)
- в результате, конечный результат мы можем проконтролировать
Аллокатор STL
Допустим, для работы с разделяемой памятью существуют функции xalloc/xfree как аналоги malloc/free. В этом случае аллокатор выглядит так:
Этого достаточно, чтобы подсадить на него std::map & std::string
Прежде чем заниматься заявленными функциями xalloc/xfree, которые работают с аллокатором поверх разделяемой памяти, стоит разобраться с самой разделяемой памятью.
Разделяемая память
Разные потоки одного процесса находятся в одном адресном пространстве, а значит каждый не thread_local указатель в любом потоке смотрит в одно и то же место. С разделяемой памятью, чтобы добиться такого эффекта приходится прилагать дополнительные усилия.
Windows
-
Создадим отображение файла в память. Разделяемая память так же как и обычная покрыта механизмом подкачки, здесь помимо всего прочего определяется, будем ли мы пользоваться общей подкачкой или выделим для этого специальный файл.
segment size 0 означает, что будет использован размер, с которым создано отображение с учетом сдвига.
Linux
Здесь принципиально всё то же самое.
-
Создаём объект разделяемой памяти
Ограничения на подсказку
Что касается подсказки (hint), каковы ограничения на её значение? Вообще-то, есть разные виды ограничений.
Во-первых, архитектурные/аппаратные. Здесь следует сказать несколько слов о том, как виртуальный адрес превращается в физический. При промахе в кэше TLB, приходится обращаться в древовидную структуру под названием “таблица страниц” (page table). Например, в IA-32 это выглядит так:

Фиг.2 случай 4K страниц, взято здесь
В AMD64 картина выглядит немного по-другому.

Фиг.3 AMD64, 4K страницы, взято отсюда
В CR3 теперь 40 значимых разрядов вместо 20 ранее, в дереве 4 уровня страниц, физический адрес ограничен 52 разрядами при том, что виртуальный адрес ограничен 48 разрядами.
И лишь в(начиная с) микроархитектуре Ice Lake(Intel) дозволено использовать 57 разрядов виртуального адреса (и по-прежнему 52 физического) при работе с 5-уровневой таблицей страниц.
До сих пор мы говорили лишь об Intel/AMD. Просто для разнообразия, в архитектуре Aarch64 таблица страниц может быть 3 или 4 уровневой, разрешая использование 39 или 48 разрядов в виртуальном адресе соответственно (1).
Во вторых, программные ограничения. Microsoft, в частности, налагает (44 разряда до 8.1/Server12, 48 начиная с) таковые на разные варианты ОС исходя из, в том числе, маркетинговых соображений.
Между прочим, 48 разрядов, это 65 тысяч раз по 4Гб, пожалуй, на таких просторах всегда найдётся уголок, куда можно приткнуться со своим hint-ом.
Аллокатор разделяемой памяти
Во первых. Аллокатор должен жить на выделенной разделяемой памяти, размещая все свои внутренние данные там же.
Во вторых. Мы говорим о средстве межпроцессного общения, любые оптимизации, связанные с использованием TLS неуместны.
В третьих. Раз задействовано несколько процессов, сам аллокатор может жить очень долго, особую важность принимает уменьшение внешней фрагментации памяти.
В четвертых. Обращения к ОС за дополнительной памятью недопустимы. Так, dlmalloc, например, выделяет фрагменты относительно большого размера непосредственно через mmap. Да, его можно отучить, завысив порог, но тем не менее.
В пятых. Стандартные внутрипроцессные средства синхронизации не годятся, требуются либо глобальные с соответствующими издержками, либо что-то, расположенное непосредственно в разделяемой памяти, например, спинлоки. Скажем спасибо когерентному кэшу. В posix на этот случай есть еще безымянные разделяемые семафоры.
Итого, учитывая всё вышесказанное а так же потому, что под рукой оказался живой аллокатор методом близнецов (любезно предоставленный Александром Артюшиным, слегка переработанный), выбор оказался несложным.
Описание деталей реализации оставим до лучших времён, сейчас интересен публичный интерфейс:
Деструктор тривиальный т.к. никаких посторонних ресурсов BuddyAllocator не захватывает.
Последние приготовления
Раз всё размещено в разделяемой памяти, у этой памяти должен быть заголовок. Для нашего теста этот заголовок выглядит так:
- own_addr_ прописывается при создании разделяемой памяти для того, чтобы все, кто присоединяются к ней по имени могли узнать фактический адрес (hint) и пере-подключиться при необходимости
- вот так хардкодить размеры нехорошо, но для тестов приемлемо
- вызывать конструктор(ы) должен процесс, создающий разделяемую память, выглядит это так:
Эксперимент
Сам тест очень прост:
Curid — это номер процесса/потока, процесс, создавший разделяемую память имеет нулевой curid, но для теста это неважно.
Qmap, LOCK/UNLOCK для разных тестов разные.
Проведем несколько тестов
- THR_MTX — многопоточное приложение, синхронизация идёт через std::recursive_mutex,
qmap — глобальная std::map<std::string, std::string> - THR_SPN — многопоточное приложение, синхронизация идёт через спинлок:
| 1 | 2 | 4 | 8 | 16 | |
|---|---|---|---|---|---|
| THR_MTX | 1’56’’ | 5’41’’ | 7’53’’ | 51’38’’ | 185’49 |
| THR_SPN | 1’26’’ | 7’38’’ | 25’30’’ | 103’29’’ | 347’04’’ |
| PRC_SPN | 1’24’’ | 7’27’’ | 24’02’’ | 92’34’’ | 322’41’’ |
| PRC_MTX | 4’55’’ | 13’01’’ | 78’14’’ | 133’25’’ | 357’21’’ |
Эксперимент проводился на двухпроцессорном (48 ядер) компьютере с Xeon® Gold 5118 2.3GHz, Windows Server 2016.
Итого
- Да, использовать объекты/контейнеры STL (размещенные в разделяемой памяти) из разных процессов можно при условии, что они сконструированы надлежащим образом.
- По производительности явного проигрыша нет, скорее наоборот, PRC_SPN даже чуть быстрее THR_SPN. Поскольку разница здесь только в аллокаторе, значит BuddyAllocator чуть быстрее malloc\free от MS (при невысокой конкуренции).
- Проблемой является высокая конкуренция. Даже самый быстрый вариант — многопоточность + std::mutex в этих условиях работает безобразно медленно. Здесь были бы полезны lock-free контейнеры, но это уже тема для отдельного разговора.
Вдогонку
Разделяемую память часто используют для передачи больших потоков данных в качестве своеобразной “трубы”, сделанной своими руками. Это отличная идея даже несмотря на необходимость устраивать дорогостоящую синхронизацию между процессами. То, что она не дешевая, мы видели на тесте PRC_MTX, когда работа даже без конкуренции, внутри одного процесса ухудшила производительность в разы.
Объяснение дороговизны простое, если std::(recursive_)mutex (критическая секция под windows) умеет работать как спинлок, то именованный мутекс — это системный вызов, вход в режим ядра с соответствующими издержками. Кроме того, потеря потоком/процессом контекста исполнения это всегда очень дорого.
Но раз синхронизация процессов неизбежна, как же нам уменьшить издержки? Ответ давно придуман — буферизация. Синхронизируется не каждый отдельный пакет, а некоторый объем данных — буфер, в который эти данные сериализуются. Если буфер заметно больше размера пакета, то и синхронизироваться приходится заметно реже.
Удобно смешивать две техники — данные в разделяемой памяти, а через межпроцессный канал данных (ex: петля через localhost) отправляют только относительные указатели (от начала разделяемой памяти). Т.к. указатель обычно меньше пакета данных, удаётся сэкономить на синхронизации.
А в случае, когда разным процессам доступна разделяемая память по одному виртуальному адресу, можно еще немного добавить производительности.
- не сериализуем данные для отправки, не десериализуем при получении
- отправляем через поток честные указатели на объекты, созданные в разделяемой памяти
- при получении готового (указателя) объекта, пользуемся им, затем удаляем через обычный delete, вся память автоматически освобождается. Это избавляет нас от возни с кольцевым буфером
- можно даже посылать не указатель, а (минимально возможное — байт со значением “you have mail”) уведомление о факте наличия чего-нибудь в очереди
Напоследок
Чего нельзя делать с объектами, сконструированными в разделяемой памяти.
- Использовать RTTI. По понятным причинам. Std::type_info объекта существует вне разделяемой памяти и недоступен в разных процессах.
- Использовать виртуальные методы. По той же причине. Таблицы виртуальных функций и сами функции недоступны в разных процессах.
- Если говорить об STL, все исполняемые файлы процессов, разделяющих память, должны быть скомпилированы одним компилятором с одними настройками да и сама STL должна быть одинаковой.
UPD: исходники BuddyAllocator выложены здесь под BSD лицензией.
Подсистема виртуальной памяти представляет собой удобный механизм для решения задачи совместного доступа нескольких процессов к одному и тому же сегменту памяти, который в этом случае называется разделяемой памятью (shared memory).
Хотя основной задачей операционной системы при управлении памятью является защита областей оперативной памяти, принадлежащей одному из процессов, от доступа к ней остальных процессов, в некоторых случаях оказывается полезным организовать контролируемый совместный доступ нескольких процессов к определенной области памяти. Например, в том случае, когда несколько пользователей одновременно работают с некоторым текстовым редактором, нецелесообразно многократно загружать его код в оперативную память. Гораздо экономичней загрузить всего одну копию кода, которая обслуживала бы всех пользователей, работающих в данное время с этим редактором (для этого код редактора должен быть реентерабельным). Очевидно, что сегмент данных редактора не может присутствовать в памяти в единственном разделяемом экземпляре — для каждого пользователя должна быть создана своя копия этого сегмента, в которой помещается редактируемый текст и значения других переменных редактора, например его конфигурация, индивидуальная для каждого пользователя, и т. п.
Другим примером применения разделяемой области памяти может быть использование ее в качестве буфера при межпроцессном обмене данными. В этом случае один процесс пишет в разделяемую область, а другой — читает.
Для организации разделяемого сегмента при наличии подсистемы виртуальной памяти достаточно поместить его в виртуальное адресное пространство каждого процесса, которому нужен доступ к данному сегменту, а затем настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области оперативной памяти. Детали такой настройки зависят от типа используемой в ОС модели виртуальной памяти: сегментной или сегментно-страничной (чисто страничная организация не поддерживает понятие «сегмент», что делает невозможным решение рассматриваемой задачи). Например, при сегментной организации необходимо в дескрипторах виртуального сегмента каждого процесса указать один и тот же базовый физический адрес. При сегментно-страничной организации отображение на одну и ту же область памяти достигается за счет соответствующей настройки таблицы страниц каждого процесса.
В приведенном выше описании подразумевалось, что разделяемый сегмент помещается в индивидуальную часть виртуального адресного пространства каждого процесса (рис. 5.23, а) и описывается в каждом процессе индивидуальным дескриптором сегмента (и индивидуальными дескрипторами страниц, если используется сегментно-страничный механизм). «Попадание» же этих виртуальных сегментов на общую часть оперативной памяти достигается за счет согласованной настройки операционной системой многочисленных дескрипторов для множества процессов.

Рис. 5.23. Два способа создания разделяемого сегмента памяти
Возможно и более экономичное для ОС решение этой задачи — помещение единственного разделяемого виртуального сегмента в общую часть виртуального адресного пространства процессов, то есть в ту часть, которая обычно используется для модулей ОС (рис. 5.23, б). В этом случае настройка дескриптора сегмента (и дескрипторов страниц) выполняется только один раз, а все процессы пользуются такой настройкой и совместно используют часть оперативной памяти.
При работе с разделяемыми сегментами памяти ОС должна выполнять некоторые функции, общие для любых разделяемых между процессами ресурсов — файлов, семафоров и т. п. Эти функции состоят в поддержке схемы именования ресурсов, проверке прав доступа определенного процесса к ресурсу, а также в отслеживании количества процессов, пользующихся данным ресурсом (чтобы удалить его в случае ненадобности). Для того чтобы отличать разделяемые сегменты памяти от индивидуальных, дескриптор сегмента должен содержать поле, имеющее два значения: shared (разделяемый) или private (индивидуальный).
Операционная система может создавать разделяемые сегменты как по явному запросу, так и по умолчанию. В первом случае прикладной процесс должен выполнить соответствующий системный вызов, по которому операционная система создает новый сегмент в соответствии с указанными в вызове параметрами: размером сегмента, разрешенными над ним операциями (чтение/запись) и идентификатором. Все процессы, выполнившие подобные вызовы с одним и тем же идентификатором, получают доступ к этому сегменту и используют его по своему усмотрению, например в качестве буфера для обмена данными.
Во втором случае операционная система сама в определенных ситуациях принимает решение о том, что нужно создать разделяемый сегмент. Наиболее типичным примером такого рода является поступление нескольких запросов на выполнение одного и того же приложения. Если кодовый сегмент приложения помечен в исполняемом файле как реентерабельный и разделяемый, то ОС не создает при поступлении нового запроса новую индивидуальную для процесса копию кодового сегмента этого приложения, а отображает уже существующий разделяемый сегмент в виртуальное адресное пространство процесса. При закрытии приложения каким-либо процессом ОС проверяет, существуют ли другие процессы, пользующиеся данным приложением, и если их нет, то удаляет данный разделяемый сегмент.
Разделяемые сегменты выгружаются на диск системой виртуальной памяти по тем же алгоритмам и с помощью тех же механизмов, что и индивидуальные.
Кэширование данных
Иерархия запоминающих устройств
Память вычислительной машины представляет собой иерархию запоминающих устройств (ЗУ), отличающихся средним временем доступа к данным, объемом и стоимостью хранения одного бита (рис. 5.24). Фундаментом этой пирамиды запоминающих устройств служит внешняя память, как правило, представляемая жестким диском. Она имеет большой объем (десятки и сотни гигабайт), но скорость доступа к данным является невысокой. Время доступа к диску измеряется миллисекундами.
На следующем уровне располагается более быстродействующая (время доступа1 равно примерно 10-20 наносекундам) и менее объемная (от десятков мегабайт до нескольких гигабайт) оперативная память, реализуемая на относительно медленной динамической памяти DRAM.
Для хранения данных, к которым необходимо обеспечить быстрый доступ, используются компактные быстродействующие запоминающие устройства на основе статической памяти SRAM, объем которых составляет от нескольких десятков до нескольких сотен килобайт, а время доступа к данным обычно не превышает 8 нс.
1 Все перечисленные характеристики ЗУ быстро изменяются по мере совершенствования вычислительной аппаратуры. В данном случае важны не абсолютные значения времени доступа или объема памяти, а их соотношение для разных типов Запоминающих устройств.
И наконец, верхушку в этой пирамиде составляют внутренние регистры процессора, которые также могут быть использованы для промежуточного хранения данных. Общий объем регистров составляет несколько десятков байт, а время доступа определяется быстродействием процессора и равно в настоящее время примерно 2-3 нс.
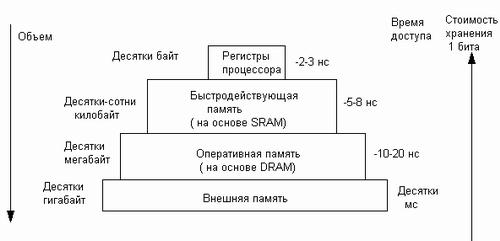
Рис. 5.24. Иерархия запоминающих устройств
Таким образом, можно констатировать печальную закономерность — чем больше объем устройства, тем менее быстродействующим оно является. Более того, стоимость хранения данных в расчете на один бит также увеличивается с ростом быстродействия устройств. Однако пользователю хотелось бы иметь и недорогую, и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы.
Кэш-память, или просто кэш (cache), — это способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который за счет динамического копирования в «быстрое» ЗУ наиболее часто используемой информации из «медленного» ЗУ позволяет, с одной стороны, уменьшить среднее время доступа к данным, а с другой стороны, экономить более дорогую быстродействующую память.
Неотъемлемым свойством кэш-памяти является ее прозрачность для программ и пользователей. Система не требует никакой внешней информации об интенсивности использования данных; ни пользователи, ни программы не принимают никакого участия в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
Кэш-памятью, или кэшем, часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств — «быстрое» ЗУ.
Оно стоит дороже и, как правило, имеет сравнительно небольшой объем. «Медленное» ЗУ далее будем называть основной памятью, противопоставляя ее вспомогательной кэш-памяти.
Кэширование — это универсальный метод, пригодный для ускорения доступа к оперативной памяти, к диску и к другим видам запоминающих устройств. Если кэширование применяется для уменьшения среднего времени доступа к оперативной памяти, то в качестве кэша используют быстродействующую статическую память. Если кэширование используется системой ввода-вывода для ускорения доступа к данным, хранящимся на диске, то в этом случае роль кэш-памяти выполняют буферы в оперативной памяти, в которых оседают наиболее активно используемые данные. Виртуальную память также можно считать одним из вариантов реализации принципа кэширования данных, при котором оперативная память выступает в роли кэша по отношению к внешней памяти — жесткому диску. Правда, в этом случае кэширование используется не для того, чтобы уменьшить время доступа к данным, а для того, чтобы заставить диск частично подменить оперативную память за счет перемещения временно неиспользуемого кода и данных на диск с целью освобождения места для активных процессов. В результате наиболее интенсивно используемые данные «оседают» в оперативной памяти, остальная же информация хранится в более объемной и менее дорогостоящей внешней памяти.
Читайте также: