
Можно ли распознать фотографию текста записанную в виде файла
Обновлено: 04.07.2024
Применяя сканер можно не только получать "электронные" фотографии, но и использовать его для преобразования текста, напечатанного на бумаге в "текст пригодный для редактирования".
Конечно текст сам собой превращаться не будет - необходима программа распознавания текста (OCR) - например FineReader .
Принцип действия таких программ следующий: сканируется фотография текста, затем методом сравнения множества образцов, черно-белая фотография (читай: картинка текста) преобразуется в "обычный текст", такой, если бы вы его напечатали с клавиатуры.
Пользователю остается только сохранить текст на диске или скопировать его через буфер обмена в любой текстовый редактор.
FineReader автоматически распознает разные участки текста: текст как таковой, картинку (рисунок), таблицу и так называемые "нераспознаваемые" блоки.
Несколько слов о параметрах сканирования. Для "хорошего" текста (белая бумага, качественная печать) достаточно разрешения 200 dpi. Газетные статьи и текст, отпечатанный на матричном принтере, сканируйте с разрешением 300 - 400 dpi.
В программе есть возможность "настройки" на конкретный текст (меню - сервис - параметры - установки сканера). Если вы сканируете документ из графического редактора - устанавливайте режим "B\W" и разрешение 300 dpi.
Перед началом работы следует включить сканер и положить оригинал (обычно лицом вниз, если только вы не используете ручной сканер).
После запуска FineReader появляется "совет дня" - краткое описание какой-либо операции. Для продолжения работы вам нужно закрыть это окно. Шпаргалка - необходима лишь самым "ленивым" пользователям.
На панели инструментов находятся кнопки "сканировать", "выделить блоки" и "распознать". Можно выполнять указанные операции и через меню (Scan&Read).
Для получения "фотографии текста" используем кнопку "сканировать". Наш компьютер все ресурсы во время выполнения этой операции отдает сканеру.

На рисунке: фрагмент окна FineReader с "распознанным" текстом.
Когда процесс завершается, вы увидите окно с изображением текста.
Ручную установку блоков [1] (рамка с помощью левой кнопки мыши) применяйте, если нужно распознать только часть текста.
Для большинства случаев сразу нажимайте на кнопку инструмента "распознать" и подтвердите автоматическое определение блоков. Процесс распознавания будет "иллюстрироваться" серой закраской участков текста.
В новом окне с именем "текст" вы увидите распознанный программой текст, который был напечатан на листе бумаги.
Если вы будете распознавать и другие документы, тогда сохраните содержимое окна текст в виде файла (инструмент "дискета" или команда меню - файл - сохранить.
К сведению: на панели инструментов есть "поля" с режимами распознавания ("авто" и "русско-английский"). Для сканирования документов с другим языком выберите нужный из списка.
ВОПРОСЫ И ЗАДАНИЯ:
1. Какие типы сканеров вы знаете?
2. Что такое "разрешение", в каких единицах оно измеряется?
3. Даны две оцифрованные картинки. Первая - получена в режиме " Gray ", вторая в режиме " Color ". Какая из них будет занимать больше места на жестком диске, если при сканировании использовался один и тот же образец?
4. Назначение и сфера применения программ OCR
5. Можно ли распознать фотографию текста записанную в виде файла?
6. Какой стороной нужно помещать "оригинал" в сканер?
7. Какие типы распознаваемых блоков вы знаете?
8. Как распознать только часть текста сканируемого документа?
9. Опишите последовательность сканирования фотографии в редакторе растровой графики.
10. С каким разрешением Вы будете сканировать большую фотографию, которую в дальнейшем собираетесь показывать на экране компьютера?
[1] Размер блока регулируется как размер окна - с помощью левой кнопки мыши. На крупном плане можно установить границы блока более точно.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.




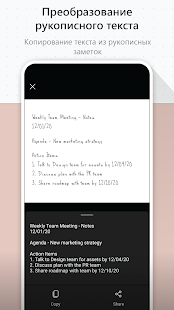


2. Adobe Scan
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.


3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.
Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.
Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.
В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.
Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
который поможет получить напечатанный текст из PDF документов и фотографий
Принцип работы ресурса

Отсканируйте или сфотографируйте текст для распознавания

Загрузите файл

Выберите язык содержимого текста в файле

После обработки файла, получите результат * длительность обработки файла может составлять до 60 секунд
- Форматы файлов
- Изображения: jpg, jpeg, png
- Мульти-страничные документы: pdf
- Сохранение результатов
- Чистый текст (txt)
- Adobe Acrobat (pdf)
- Microsoft Word (docx)
- OpenOffice (odf)
Наши преимущества
- Легкий и удобный интерфейс
- Мультиязычность
Сайт переведен на 9 языков - Быстрое распознавание текста
- Неограниченное количество запросов
- Отсутствие регистрации
- Защита данных. Данные между серверами передаются по SSL + автоматически будут удалены
- Поддержка 35+ языков распознавания текста
- Использование движка Tesseract OCR
- Распознавание области изображения (в разработке)
- Обработано более чем 23.1M+ запросов
Основные возможности

Распознавание отсканированных файлов и фотографий, которые содержат текст
Форматирование бумажных и PDF-документов в редактируемые форматы
Приветствуем студентов, офисных работников или большой библиотеки!
У Вас есть учебник или любой журнал, текст из которого необходимо получить, но нет времени чтобы напечатать текст?
Наш сервис поможет сделать перевод текста с фото. После получения результата, Вы сможете загрузить текст для перевода в Google Translate, конвертировать в PDF-файл или сохранить его в Word формате.
OCR или Оптическое Распознавание Текста никогда еще не было таким простым. Все, что Вам необходимо, это отсканировать или сфотографировать текст, далее выбрать файл и загрузить его на наш сервис по распознаванию текста. Если изображение с текстом было достаточно точным, то Вы получите распознанный и читабельный текст.
Сервис не поддерживает тексты написаны от руки.
Поддерживаемые языки:
Русский, Українська, English, Arabic, Azerbaijani, Azerbaijani - Cyrillic, Belarusian, Bengali, Tibetan, Bosnian, Bulgarian, Catalan; Valencian, Cebuano, Czech, Chinese - Simplified, Chinese - Traditional, Cherokee, Welsh, Danish, Deutsch, Greek, Esperanto, Estonian, Basque, Persian, Finnish, French, German Fraktur, Irish, Gujarati, Haitian; Haitian Creole, Hebrew, Croatian, Hungarian, Indonesian, Icelandic, Italiano, Javanese, Japanese, Georgian, Georgian - Old, Kazakh, Kirghiz; Kyrgyz, Korean, Latin, Latvian, Lithuanian, Dutch; Flemish, Norwegian, Polish Język polski, Portuguese, Romanian; Moldavian, Slovakian, Slovenian, Spanish; Castilian, Spanish; Castilian - Old, Serbian, Swedish, Syriac, Tajik, Thai, Turkish, Uzbek, Uzbek - Cyrillic, Vietnamese

Технология оптического распознавания символов (Optical Character Recognition, OCR ) и приложения для распознавания текста помогут вам получить текст из картинок, PDF-документов, сканов, фото или других типов файлов.
OCR может быть очень мощным инструментом для любой компании или организации с интенсивным документооборотом. Ведь тогда не придется перепечатывать документы вручную и быстро находить нужную информацию в файлах с уже распознанным текстом.
Программа конвертации в PDF (ПДФ) и другие форматы + OCR приложение

DocuFreezer (ДокуФризер) – это простой и удобный инструмент офлайн-конвертер различных файлов (поддерживается 70+ входных форматов файлов) для Windows. Эта программа помогает сэкономить время при сохранении сразу нескольких файлов в популярные форматы PDF, JPEG, TIFF, PNG, TXT. Также доступны функции объединения (слияния) файлов, работы с вложениями и архивами. В недавно вышедшей версии 3.0 программа получает встроенный OCR-компонент.
Как распознать текст из фото JPG, PNG, TIFF и других форматов
Вместо того, чтобы вручную перепечатывать текст с картинки или отсканированного документа, можно значительно сэкономить время, скача в приложение, которое распознает текст с фото или скана документа. Распознанный текст можно будет копировать и редактировать в удобном вам редакторе.
Для распознавания текста существует много различных сервисов, программ, и целых OCR-систем , которые можно найти в Интернете. Одним из простых и удобных способов является программа DocuFreezer. Это офлайн PDF-конвертер для Windows c возможностью сохранить ваши документы или изображения в универсальный формат PDF или TXT, а также популярные форматы изображений – JPEG, PNG, TIFF.
Оптическое распознавание символов при конвертировании
В последнем обновлении 3.0 стала доступна функция OCR. Так что теперь DocuFreezer – не только мощный конвертер файлов, но и программа распознающая текст с фото , сканов и других типов файлов. Ключевое преимущество программы в том, что можно конвертировать сразу много файлов в пакетном режиме.
Новую функцию распознавания текста в DocuFreezer можно протестировать, скачав бесплатную версию – OCR доступен и в бесплатн ой версии конвертера. Кстати, программа распознает тексты и на русском языке (всего доступно 6 языков).
Как распознать текст с картинки или фото – пошаговая инструкция

-
Откройте программу DocuFreezer;
Чтобы обеспечить наилучший результат распознавания
- Картинки или сканы должны быть большого размера, чтобы высота букв текста была не менее 20 пикселей
- В настройках должны быть выбраны только те языки, которые содержатся в ваших входных файлах
- Текст входного файла не имеет никакого поворота или искажения
- Не должно быть темных границ, деталей и шумов рядом с текстом, иначе они будут неверно распознаны как символы
В противном случае текст может неверно или неправильно отображаться после "осиара". И, возможно, его придется отредактировать. В идеале, исходные файлы должны быть хорошего качества и иметь высокое разрешение.
Особенности OCR в DocuFreezer
Распознавание текста происходит автоматически, прямо во время групповой конвертации добавленных файлов. Ниже представлены некоторые особенности встроенной функции OCR в DocuFreezer.
Поддерживаемые входные типы файлов
Поддерживаемые выходные типы файлов
Поддерживаемые языки
Поддерживаемые виды документов
- Английский
- Немецкий
- Иврит
- Японский
- Русский
- Испанский
- PDF-документы
- практически любые растровые изображения: фотографии, картинки, сканы
- чертежи Автокад
- таблицы Excel
Как указано выше, на выходе вы получите простой текст TXT или PDF с возможностью поиска текста. Чтобы найти и выделить нужный текст в получившемся PDF-файле, достаточно открыть документ, нажать комбинацию клавиш Ctrl + F и ввести нужные слова или символы. Также текст внутри PDF-а можно будет выделять мышкой и копировать.
Читайте также: