
Ms sql tempdb добавить несколько файлов
Обновлено: 04.07.2024
Системная база данных tempdb активно используется базами данных 1С:Предприятие 8.3 для хранения временных таблиц, промежуточных расчетов, версий строк при использовании режима версионирования и прочих временных данных. То есть для задач 1С:Предприятие интенсивность обращений к базе tempdb находится на высоком уровне, поэтому нужно подумать о размещении этой базы на выделенном быстром дисковом устройстве.Подходящими кандидатами на роль диска под tempdb будут выделенные быстрые дисковые RAID-группы уровня RAID1, выделенные накопители SSD или вообще RAM-диск.
В большинстве сценариев рекомендуется разбивать базу tempdb на несколько файлов данных с одинаковом начальным размером (Initial size) от 1GB и больше и увеличенным показателем прироста, например, в 512MB.
При определении количества файлов можно руководствоваться принципом: количество процессорных ядер = количество файлов данных tempdb, но при этом стоит помнить о том, что использование более 8 файлов (даже при количестве ядер более 8) далеко не всегда может иметь положительный эффект. Возможно по этой причине в инсталляторе SQL Server 2016 даже при большом количестве процессорных ядер по умолчанию предлагается 8 файлов tempdb.
Относительно 1С:Предприятие 8.3 можно встретить рекомендацию о том, что общий размер Initial size для всех файлов БД tempdb должен быть от 25% до 40% от размера рабочей БД 1С:Предприятие.
Саму процедуру переноса файлов tempdb на другой диск мы рассматривали ранее в заметке SQL Server 2008 - Перенос файлов БД tempdb на отдельный диск. Эта процедура может использоваться и на новых версиях СУБД, вплоть до SQL Server 2016.
Рассмотрим частный пример распределения файлов tempdb по разным дисковым томам, имеющим разные показатели производительности. В нашем примере имеется два тома NTFS:
R: менее производительный, но больший по объёму дискЧасть файлов данных в файловой группе tempdb, а также файл лога размещены на быстром диске. Файлы данных, расположенные на быстром диске установлены фиксированного размера без возможности авторасширения (исключением здесь является только файл лога). Другая часть файлов данных размещена на менее производительном дисковом томе, но при этом для файлов включено авторасширение.
В результате такой конфигурации, файлы tempdb в нашем случае будут распределены по дисковым томам следующим образом: 4 файла данных и лог tempdb окажутся на быстром томе T:
Другие 4 файла данных tempdb окажутся на менее производительном дисковом томе R:
В случае если в ходе работы экземпляра SQL Server потребуется дополнительное расширение ёмкости tempdb, то файлы начнут прирастать на меньшем по производительности, но большем по объёму дисковом томе R.
К операциям, которые могут вызвать бурный рост tempdb при работе БД 1С:Предприятие 8.3 можно отнести, например, регламентные процедуры с конфигурацией 1С, выполняемые из конфигуратора (обновление конфигурации, перерасчёт итогов и т.п.). Кроме того, активный рост tempdb может вызвать построение в 1С каких-то тяжёлых отчётов с большим количеством данных и за длительные периоды при условии, что код отчётов неоптимален или вообще содержит ошибки. В практической среде при размере БД около 170GB во время построения подобного отчёта мы наблюдали рост tempdb до 350GB. Учитывая эти моменты стоит подумать о полной изоляции файлов tempdb на выделенных дисковых томах, чтобы их возможный бурный рост не смог нарушить функционирования других БД SQL Server.
Используемый в нашем примере дисковый том T: представляет собой RAM-диск, подключенный к серверу SQL Server по методике, описанной в отдельной статье нашего Блога : Организуем RAM-диск для кластера Windows Server с помощью Linux-IO FC Target
Имеется два сервера MSSQL 2012 SP1, основной и тестовый.
Хочу создать несколько файлов данных для TempDB (по числу ядер процессора)
Создаю либо руками через Management Studio, либо скриптом командой вида
ALTER DATABASE tempdb ADD FILE (NAME = tempdev4_1, FILENAME = 'e:\TempDB\tempdb4_1.mdf', SIZE = 256 MB, MAXSIZE = 512 MB,FILEGROWTH = 50MB);
Файлы успешно создаются, но на основном сервере после рестарта службы MS SQL Server в TempDB остается только один файл данных, а на тестовом все в порядке.
Имеется два сервера MSSQL 2012 SP1, основной и тестовый.
Хочу создать несколько файлов данных для TempDB (по числу ядер процессора)
Создаю либо руками через Management Studio, либо скриптом командой вида
ALTER DATABASE tempdb ADD FILE (NAME = tempdev4_1, FILENAME = 'e:\TempDB\tempdb4_1.mdf', SIZE = 256 MB, MAXSIZE = 512 MB,FILEGROWTH = 50MB);
Файлы успешно создаются, но на основном сервере после рестарта службы MS SQL Server в TempDB остается только один файл данных, а на тестовом все в порядке.
Гм. Возможно я неточно описал проблему. Пробуем еще раз.
1. После каждого рестарта сервера база tempdb состоит из 1 файла данных ( и 1 файла лога, но его опустим), пусть будет X.
2. Создаем еще файлы, c именами X_1,X_2 - итого tempdb состоит из 3 файлов
3. Перезагружаемся, получаем п.1 - база tempdb состоит из 1 файла данных X.
4. Файлов с именами X_1,X_2 в свойствах tempdb уже нет, но и создать их уже не можем:
"Логическое имя файла "X_1" уже используется. Выберите другое имя."
Т.е. где-то (может в master?) информация о файлах с логическими именами X_1,X_2 остается.
Соответствующие физические файлы на диске можно удалять - они более не блокируются процессом SQL Server и не используются для TempDB.
Приложил. Сегодня был рестарт сервера.
Опа. :) А здесь и есть все мои уже использованные логические имена.
В аттачменте.
| select @@version |
Microsoft SQL Server 2012 - 11.0.5058.0 (X64)
May 14 2014 18:34:29
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
Microsoft SQL Server 2012 - 11.0.5058.0 (X64)
May 14 2014 18:34:29
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
temp_dd1 - это логическое имя ткущего (единственного!) файла данных в БД TempDB на основном сервере.
Замечательно, мы нашли логические имена, теперь видимо я могу просто удалить эти записи?
Но почему созданные файлы не сохраняются после перезагрузки в свойствах TempDB? Почему там остается только temp_dd1?
Смотрите, вот данные с тестового сервера.
Системная база данных tempdb — это глобальный ресурс, доступный всем пользователям, подключенным к экземпляру SQL Server или Базе данных SQL Azure. tempdb содержит:
Временные пользовательские объекты, созданные явно. К ним относятся глобальные или локальные временные таблицы и индексы, временные хранимые процедуры, табличные переменные, возвращаемые функциями с табличными значениями таблицы и курсоры.
Внутренние объекты, создаваемые ядром СУБД. К ним относятся следующие:
- Рабочие таблицы, хранящие промежуточные результаты буферов, курсоры, сортировки и временное хранилище больших объектов (LOB).
- рабочие файлы для операций хэш-соединения или статистических хэш-выражений;
- промежуточные результаты сортировки для таких операций, как создание или перестроение индексов (если указать SORT_IN_TEMPDB ), либо определенных запросов GROUP BY , ORDER BY или UNION .
Отдельные базы данных и эластичные пулы Базы данных SQL Azure поддерживают глобальные временные таблицы и глобальные временные хранимые процедуры, которые хранятся в tempdb и имеют область действия на уровне базы данных.
Глобальные временные таблицы и глобальные временные хранимые процедуры являются общими для всех сеансов пользователей в рамках одной базы данных SQL. Сеансы пользователей, связанные с другими базами данных SQL, не имеют доступа к глобальным временным таблицам. Дополнительные сведения см. в разделе Глобальные временные таблицы (база данных SQL Azure) в области базы данных. Управляемый экземпляр SQL Azure поддерживает те же временные объекты, что и SQL Server.
Для эластичных пулов и отдельных баз данных Базы данных SQL Azure применяются только базы master и tempdb . Дополнительные сведения см. в статье Что являет собою сервер Базы данных SQL Azure?. Описание tempdb в контексте эластичных пулов и отдельных баз данных Базы данных SQL Azure см. в разделе База данных tempdb в Базе данных SQL Azure.
Для Управляемого экземпляра SQL Azure применяются все системные базы данных.
Хранилища версий. Это коллекции страниц данных со строками данных, которые поддерживают функции управления версиями строк. Существует два типа хранилищ: общее хранилище версий и хранилище версий для построения индекса в подключенном режиме. Хранилища версий содержат следующее:
- версии строк, создаваемые транзакциями изменения данных в базе данных, которая использует READ COMMITTED через транзакции изоляции моментальных снимков и транзакции изоляции управления версиями строк;
- версии строк, создаваемые транзакциями изменения данных для таких функций, как операции с индексами в подключенном режиме, функции MARS (множественный активный результирующий набор) и триггеры AFTER .
Операции в tempdb в минимальном объеме записываются в журнал, что позволяет откатывать транзакции. tempdb создается заново при каждом запуске SQL Server, чтобы система всегда запускалась с чистой копией базы данных. Временные таблицы и хранимые процедуры удаляются автоматически при отключении, и при выключении системы нет активных соединений.
tempdb не требует сохранения каких-либо данных между сеансами SQL Server. Операции резервного копирования и восстановления для tempdb недопустимы.
Физические свойства tempdb в SQL Server
В следующей таблице приводятся исходные значения конфигурации для файлов данных и журналов tempdb в SQL Server. Значения основаны на значениях по умолчанию для базы данных model . Размеры этих файлов могут немного отличаться в зависимости от выпуска SQL Server.
Количество вторичных файлов данных зависит от числа логических процессоров на компьютере. Как правило, если число логических процессоров меньше или равно восьми, используйте равное ему число файлов данных. Если число логических процессоров больше восьми, используйте восемь файлов данных. Если состязание сохраняется, увеличьте число файлов данных на значение, кратное четырем, пока состязание не снизится до приемлемого уровня, или внесите изменения в рабочую нагрузку или код.
Количество файлов данных по умолчанию основано на общих рекомендациях, приведенных в статье KB 2154845.
Чтобы проверить текущий размер и параметры увеличения для tempdb , выполнить запрос к представлению tempdb.sys.database_files .
Перемещение данных и файлов журналов базы данных tempdb в SQL Server
Сведения о перемещении файлов журналов и данных tempdb см. в статье Перемещение системных баз данных.
Параметры базы данных для tempdb в SQL Server
В следующей таблице приводится список значений по умолчанию для каждого параметра базы данных tempdb , а также возможность его изменения. Чтобы просмотреть текущие настройки этих параметров, используйте представление каталога sys.databases .
База данных tempdb в Базе данных SQL
Размеры базы данных tempdb для уровней служб на основе DTU
| Целевой уровень обслуживания | Максимальный размер файла данных tempdb (ГБ) | Число файлов данных tempdb | Максимальный размер данных tempdb (ГБ) |
|---|---|---|---|
| Basic | 13.9 | 1 | 13.9 |
| S0 | 13.9 | 1 | 13.9 |
| S1 | 13.9 | 1 | 13.9 |
| S2 | 13.9 | 1 | 13.9 |
| S3 | 32 | 1 | 32 |
| S4 | 32 | 2 | 64 |
| S6 | 32 | 3 | 96 |
| S7 | 32 | 6 | 192 |
| S9 | 32 | 12 | 384 |
| S12 | 32 | 12 | 384 |
| P1 | 13.9 | 12 | 166.7 |
| P2 | 13.9 | 12 | 166.7 |
| P4 | 13.9 | 12 | 166.7 |
| P6 | 13.9 | 12 | 166.7 |
| P11 | 13.9 | 12 | 166.7 |
| P15 | 13.9 | 12 | 166.7 |
| Эластичные пулы уровня "Базовый" (все конфигурации DTU) | 13.9 | 12 | 166.7 |
| Эластичные пулы ценовой категории "Стандартный" (50 eDTU) | 13.9 | 12 | 166.7 |
| Эластичные пулы ценовой категории "Стандартный" (100 eDTU) | 32 | 1 | 32 |
| Эластичные пулы ценовой категории "Стандартный" (200 eDTU) | 32 | 2 | 64 |
| Эластичные пулы ценовой категории "Стандартный" (300 eDTU) | 32 | 3 | 96 |
| Эластичные пулы ценовой категории "Стандартный" (400 eDTU) | 32 | 3 | 96 |
| Эластичные пулы ценовой категории "Стандартный" (800 eDTU) | 32 | 6 | 192 |
| Эластичные пулы ценовой категории "Стандартный" (1200 eDTU) | 32 | 10 | 320 |
| Эластичные пулы ценовой категории "Стандартный" (1600–3000 eDTU) | 32 | 12 | 384 |
| Эластичные пулы уровня "Премиум" (все конфигурации DTU) | 13.9 | 12 | 166.7 |
Размеры базы данных tempdb для уровней служб на основе виртуальных ядер
Ограничения
С базой данных tempdb нельзя выполнять следующие операции:
- Добавление файловых групп.
- Резервное копирование и восстановление из копии.
- Изменение параметров сортировки. Параметрами сортировки по умолчанию являются параметры сортировки сервера.
- Изменение владельца базы данных. Владельцем tempdb является sa
- Создание моментального снимка базы данных.
- Удаление базы данных.
- Удаление пользователя guest из базы данных.
- Включение отслеживания измененных данных.
- Участие в зеркальном отображении базы данных.
- Удаление первичной файловой группы, первичного файла данных или файла журнала.
- Переименование базы данных или первичной файловой группы.
- Выполнение DBCC CHECKALLOC .
- Выполнение DBCC CHECKCATALOG .
- Перевод базы данных в режим OFFLINE .
- Перевод базы данных или первичной файловой группы в режим READ_ONLY .
Разрешения
Любой пользователь может создавать временные объекты в tempdb . Если не предоставлены дополнительные разрешения, пользователям доступны только принадлежащие им объекты. Можно отозвать разрешение на подключение к tempdb , чтобы запретить пользователю работать с tempdb . Но делать это не рекомендуется, так как tempdb требуется для выполнения некоторых стандартных операций.
Оптимизация производительности базы данных tempdb в SQL Server
Размер и физическое размещение базы данных tempdb может влиять на производительность системы. Например, если для базы данных tempdb установлен слишком малый размер, часть системной нагрузки может приходиться на автоувеличение tempdb до размера, требуемого для поддержки рабочей нагрузки при каждом перезапуске экземпляра SQL Server.
По возможности используйте мгновенную инициализацию файлов, чтобы повысить производительность операций увеличения файлов данных.
Заранее выделите место для всех файлов tempdb , установив для файла размер, достаточный для обеспечения обычной рабочей нагрузки в среде. Предварительное выделение позволяет избежать слишком частого расширения tempdb , способного повлиять на производительность. Следует установить автоувеличение для базы данных tempdb , чтобы увеличить место на диске для незапланированных исключений.
Файлы данных в каждой файловой группе должны иметь одинаковый размер, так как SQL Server использует алгоритм пропорционального заполнения, который повышает вероятность выделения памяти в файлах с большим объемом свободного пространства. Разделение tempdb на множество файлов данных равного размера обеспечивает эффективное выполнение использующих tempdb операций с высокой степенью параллелизма.
Установите приемлемое значение шага увеличения размера файла, чтобы оно не было слишком низким для файлов базы данных tempdb . Если увеличение размера файлов будет слишком малым по сравнению с объемом записываемых в tempdb данных, tempdb может постоянно требовать расширения. Это скажется на производительности.
Чтобы проверить текущий размер и параметры увеличения для tempdb , используйте следующий запрос:
Поместите базу данных tempdb в быструю подсистему ввода-вывода. Если имеется много непосредственно присоединенных дисков, то используйте чередование дисков. Отдельные файлы данных tempdb или их группы не обязательно должны располагаться на разных дисках или шпинделях, если только у вы не наблюдаете узкие места в подсистеме ввода-вывода.
Расположите базу данных tempdb на дисках, отличающихся от используемых пользовательскими базами данных.
Увеличение производительности базы данных tempdb в SQL Server
Начиная с версии SQL Server 2016 (13.x);, производительность tempdb дополнительно оптимизирована следующим образом:
- Временные таблицы и табличные переменные кэшируются. Кэширование позволяет операциям удаления и создания временных объектов выполняться очень быстро. Кэширование также снижает вероятность возникновения состязаний, связанных с метаданными и выделением страниц.
- Усовершенствован протокол кратковременных блокировок выделения страниц для снижения количества используемых кратковременных блокировок UP (обновление).
- Снижены затраты ресурсов на ведение журнала tempdb — уменьшено потребление пропускной способности подсистемы ввода-вывода файлом журнала tempdb .
- Программа установки добавляет множество файлов данных tempdb при установке нового экземпляра. Эту задачу можно выполнить с помощью нового элемента управления для ввода в пользовательском интерфейсе в разделе Настройка ядра СУБД и параметра командной строки /SQLTEMPDBFILECOUNT . По умолчанию программа установки добавляет столько файлов данных tempdb , сколько имеется логических процессоров, но их может быть не больше восьми.
- При наличии множества файлов данных tempdb автоматическое увеличение выполняется для всех файлов в одно время и в равном объеме согласно параметрам увеличения. Флаг трассировки 1117 больше не требуется.
- Для всех операций распределения в tempdb используются единообразные экстенты. Флаг трассировки 1118 больше не требуется.
- Для первичной файловой группы свойство AUTOGROW_ALL_FILES включено и не может быть изменено.
Дополнительные сведения об улучшениях производительности в tempdb см. в статье блога TEMPDB — Files and Trace Flags and Updates, Oh My! (TEMPDB — файлы, флаги трассировки и обновления).
Оптимизированные для памяти метаданные tempdb
Состязание метаданных tempdb всегда было узким местом для масштабируемости многих рабочих нагрузок, выполняющихся в SQL Server. В SQL Server 2019 (15.x) появилась новая функция оптимизированных для памяти метаданных tempdb, входящая в семейство функций выполняющейся в памяти базы данных.
Она эффективно устраняет существующее узкое место и открывает новый уровень масштабируемости для рабочих нагрузок, активно использующих tempdb. В SQL Server 2019 (15.x) системные таблицы, связанные с управлением метаданными временных таблиц, можно переместить в неустойчивые таблицы без кратковременной блокировки, оптимизированные для памяти.
Сейчас функция оптимизированных для памяти метаданных tempdb недоступна для Базы данных SQL Azure и Управляемых экземпляров SQL Azure.
Просмотрите это 7-минутное видео, чтобы узнать, как и когда следует использовать метаданные tempdb, оптимизированные для памяти:
Настройка и использование метаданных оптимизированной для памяти базы данных tempdb
Чтобы согласиться на применение этой новой функции, используйте следующий скрипт:
Чтобы это изменение конфигурации вступило в силу, нужно перезапустить службу.
Вы можете проверить, является ли tempdb оптимизированной для памяти, используя следующую команду T-SQL:
Если по какой-то причине не удается запустить сервер после включения оптимизированных для памяти метаданных tempdb , можно обойти эту функцию, запустив экземпляр SQL Server в минимальной конфигурации с помощью параметра запуска -f. После этого вы можете отключить функцию и перезапустить SQL Server в нормальном режиме.
Чтобы защитить сервер от потенциальных состояний нехватки памяти, можно привязать tempdb к пулу ресурсов. В этом случае вместо действий, которые обычно выполняются при привязке пула ресурсов к базе данных, следует использовать команду ALTER SERVER .
Кроме того, даже если метаданные оптимизированной для памяти базы данных tempdb уже включены, чтобы это изменение вступило в силу, требуется перезагрузка.
Ограничения оптимизированной для памяти базы данных tempdb
Включение и отключение функции не является динамическим. Из-за внутренних изменений, которые необходимо внести в структуру tempdb , для включения или отключения этой функции требуется перезапуск.
Отдельная транзакция не может обратиться к таблицам, оптимизированным для памяти, в более чем одной базе данных. Все транзакции, связанные с таблицей, оптимизированной для памяти, в пользовательской базе данных, не смогут обратиться к системным представлениям tempdb в той же транзакции. Если вы попытаетесь обратиться к системным представлениям tempdb в транзакции с участием таблицы, оптимизированной для памяти, в пользовательской базе данных, возникнет следующая ошибка:
Запросы к таблицам, оптимизированным для памяти, не поддерживают указания блокировки и изоляции, поэтому запросы к представлениям каталога оптимизированной для памяти tempdb не будут учитывать указания блокировки и изоляции. Как и в случае с другими системными представлениями каталога в SQL Server, все транзакции для системных представлений будут находиться в изоляции READ COMMITTED (или READ COMMITTED SNAPSHOT в нашем случае).
Если оптимизированные для памяти метаданные tempdb включены, индексы columnstore нельзя создавать во временных таблицах.
В связи с ограничением на индексы columnstore использование системной хранимой процедуры sp_estimate_data_compression_savings с параметром сжатия данных COLUMNSTORE или COLUMNSTORE_ARCHIVE не поддерживается, если включены оптимизированные для памяти метаданные tempdb .
Эти ограничения применяются только при создании ссылок на системные представления tempdb . При необходимости вы сможете создать временную таблицу в той же транзакции, где обращаетесь к таблице, оптимизированной для памяти, в пользовательской базе данных.
Планирование ресурсов для tempdb в SQL Server
Определение требуемого размера tempdb в рабочей среде SQL Server зависит от многих факторов. Как описано выше, эти факторы включают текущую рабочую нагрузку и используемые функции SQL Server. Рекомендуется проанализировать текущую рабочую нагрузку, выполнив следующие задачи в среде тестирования SQL Server:
Это 1 файл на ядро? Итак, quad-core = 4 файла tempdb, создавая три новых?
3 ответа
Чтобы переместить файлы tempdb , вам просто нужно сделать следующее:
Если вы хотите добавить новый файл в tempdb , вам просто нужно сделать следующее (если вы хотите добавить его в файловую группу PRIMARY ) или создать собственное):
Чтобы эти изменения вступили в силу, вам необходимо перезапустить службу SQL Server. Таким образом, , насколько минимизируется время простоя, вы ограничены количеством времени, которое потребуется для перезапуска службы . Вам не нужно беспокоиться о перемещении ранее существовавших файлов базы данных tempdb , так как SQL Server всегда воссоздает файлы, а новые местоположения /файлы будут созданы при запуске службы.
Что касается «1 файла данных tempdb для ядра», это в значительной степени миф. Правильный подход заключается в мониторинге конфликта файлов tempdb для страницы свободного пространства (PFS), глобальной карты распределения (GAM) и общих страниц глобальной карты распределения (SGAM). Обращайтесь к этой статье, чтобы получить запрос , который просматривает sys.dm_os_waiting_tasks DMV, чтобы увидеть, сколько существует файл tempdb . Затем вам нужно уйти от этого, а не просто использовать tempdb с тем же количеством файлов, что и ядра. Это более целесообразный подход.
Чтобы переместить tempdb, выполните:
Затем перезапустите службу SQL Server (MSSQLServer).
Как правило, если число логических процессоров меньше или равно 8, используйте то же количество файлов данных, что и логические процессоры.
Если количество логических процессоров больше 8, используйте 8 файлов данных, а затем, если конфликт продолжается, увеличьте количество файлов данных кратным 4 (вплоть до количества логических процессоров), пока соперничество не будет уменьшено до приемлемого уровней или внести изменения в рабочую нагрузку /код.
Перемещение файлов TempDB - это двухэтапный процесс:
- Сообщите SQL , где , что вы хотите, чтобы ваши новые файлы TempDB переходили (это не имеет времени простоя)
- Перезапустите службу SQL Server , чтобы изменения вступили в силу (это минимальное время простоя )
Чтобы указать SQL, где создавать новые файлы TempDB, вы можете использовать:
Это сгенерирует операторы T-SQL, которые нужно запустить, чтобы переместить файлы на новый диск drive:\folder , который вы хотите. (щелкните изображение, чтобы увеличить)

Когда вы запустили свои движущиеся операторы, вы можете снова запустить указанный выше запрос, чтобы проверить, что столбец Current Location теперь показывает ваш новый диск drive:\folder .

После того, как вы довольны своими изменениями, перезапустите службу SQL Server .
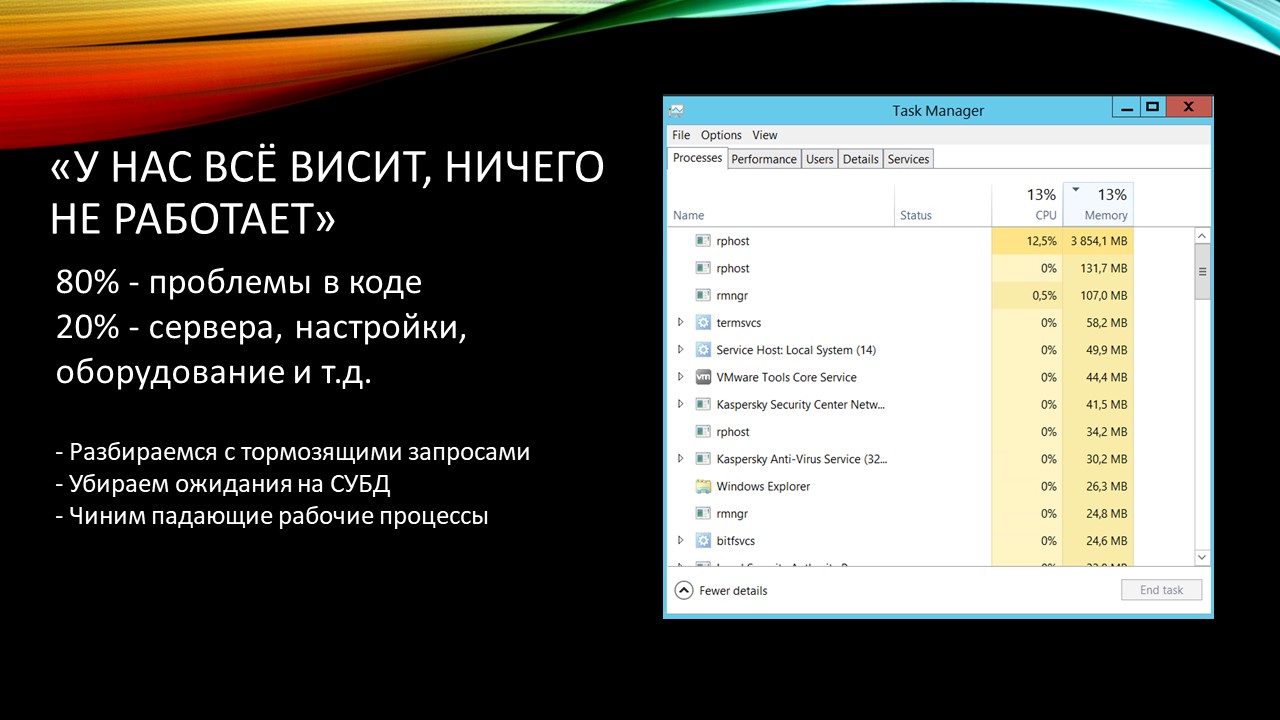
Что, как правило, делает 1С-ник? Открывает диспетчер задач, в лучшем случае видит загрузку памяти и начинает ее чистить, в худшем – видит картину, когда все вроде бы хорошо, но все тормозит. Тогда начинаются рестарты всего, что можно рестартовать.
В какой-то момент мне надоели рестарты и чистки кэша, я начал разбираться с вопросами производительности и попутно получил сертификат эксперта по технологическим вопросам.
По своему опыту и опыту коллег скажу, что все тормоза, как правило, возникают из-за неоптимального кода 1С, написанного программистами. Реже – из-за настройки серверов, СУБД и т.д. В любом случае, нет волшебной «галочки», которую можно поставить – и все летает.
разберем тормозящие запросы и что с ними делать;
научимся убирать ожидания на СУБД MS SQL Server;
узнаем, как чинить падающие рабочие процессы сервера 1С.
Первая проблема

Это был старт проекта на ERP:
Из типовой ERP использовалось очень мало, буквально пара подсистем. При этом был очень большой самописный модуль.
Серверы 1С и СУБД совмещены.
Оборудование не загружено.
Но при этом все тормозит.
Начали разбираться. Взяли для примера одну типовую операцию – открытие формы документа. Причем, это был простой самописный документ без сложных наворотов.
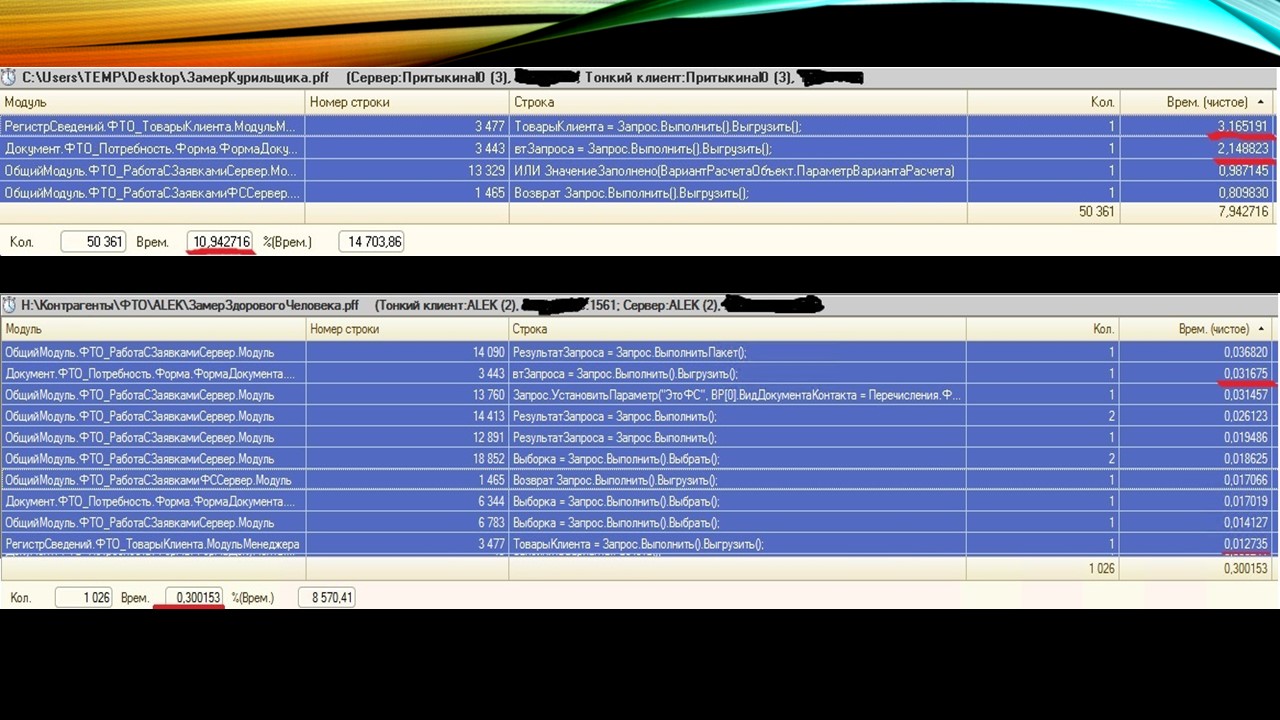
Обычный замер производительности из конфигуратора показал, что под полными правами все работает и открывается быстро, а под неполными открывается 11 секунд.
Сразу же видно разницу в запросах. На первом месте у меня запрос, который выполняется больше трех секунд под неполными правами, а подо мной выполняется за сотые доли секунды.
Наверное, все подумали о том, что проблема во все-таки включенном RLS, потому все и тормозит. Я тоже так решил и пошел его проверять. Оказалось, что он отключен.
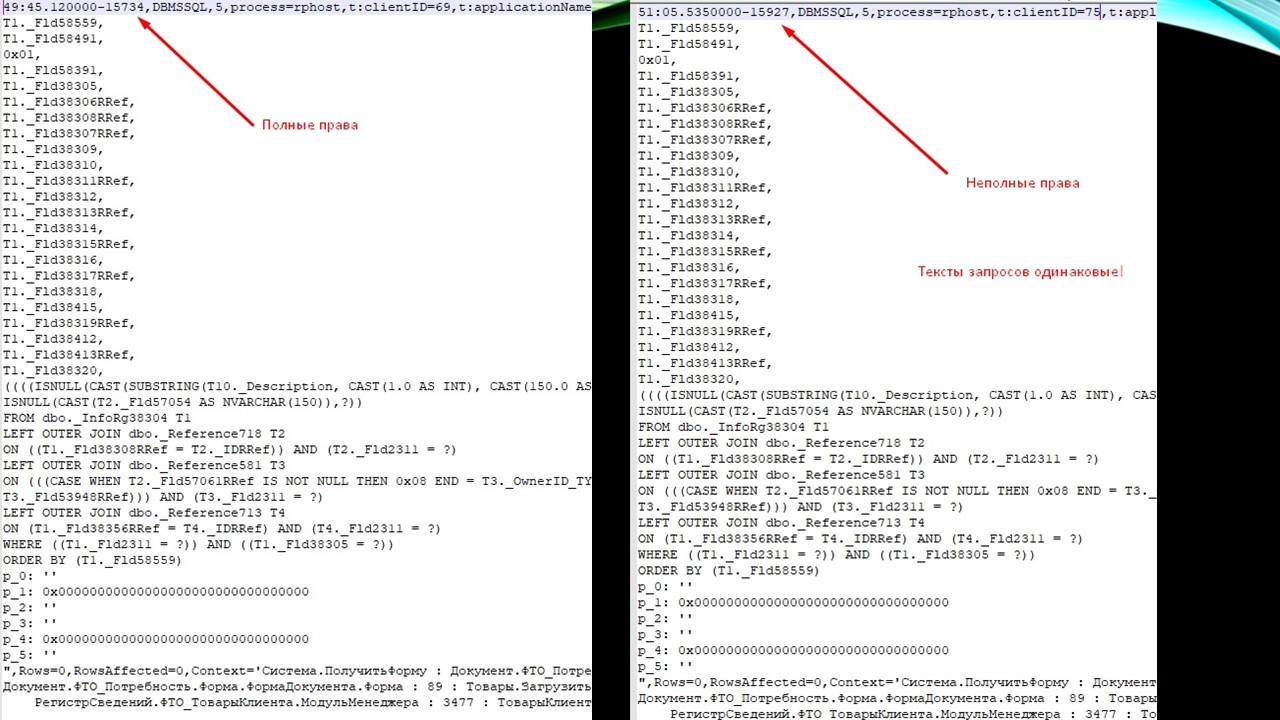
Я собрал технологический журнал конкретно по проблемному запросу, выполнил его под собой и под пользователем с неполными правами.
Оказалось, что тексты запросов, которые передавались на SQL, были абсолютно одинаковые. И, что более важно, абсолютно одинаковым было и время выполнения.
На слайдах отмечено время в микросекундах – оба запроса выполняются почти мгновенно.

Откуда тогда могло взяться 3 секунды?
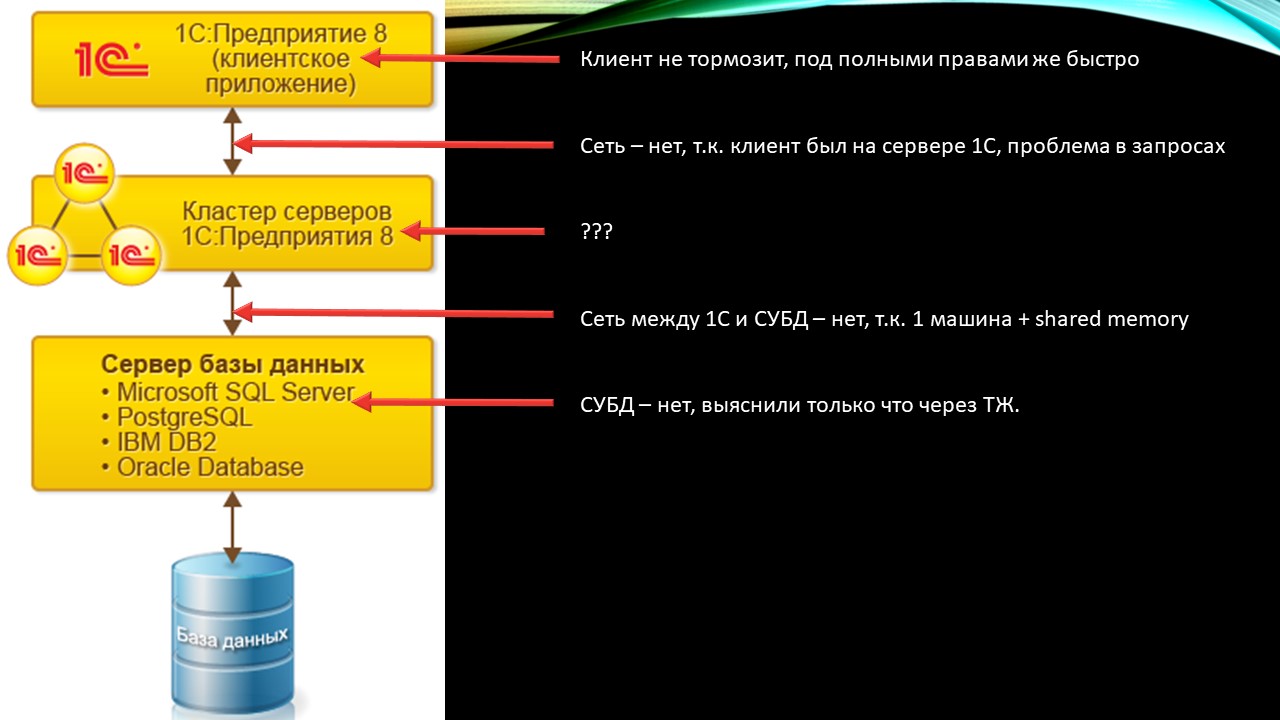
Какие компоненты могут тормозить?
Первое – СУБД, но она у нас не тормозит. Техжурнал показал, что запрос выполняется быстро.
Второе – сеть между 1С и СУБД. Но она тоже не может тормозить, потому что ее попросту нет – у нас для сервера СУБД и сервера 1С используется одна машина. Плюс включен протокол Shared memory – используется общая оперативная память. Сети вообще нет, грубо говоря.
Клиенты и сеть между клиентами сервера тормозить вообще не могли, потому что у нас проблема в запросе. Клиентов мы сразу отметаем, все запросы выполняются на сервере.
Остается одно звено – сервер 1С, с ним что-то было не так.
А что было не так?

Посмотрел, сколько ролей у проблемных пользователей. Оказалось – 1261 роль.
Напоминаю, что у нас ERP с подсистемами, которые не использовались. И однажды был создан профиль, который назывался «Для всех». Туда были добавлены вообще все типовые роли ERP без разбора – получилось столько ролей.
Также я сохранил конфигурацию в файлы, когда каждый объект метаданных сохраняется в отдельный файлик.
Посмотрел размер файлов ролей, и получилось так, что когда мы добавляем самописную роль, мы ставим в нее только пару галочек, поэтому она весит буквально несколько килобайт. А типовые роли за счет ограничений доступа, написанных для RLS, достаточно тяжелые. Они весят мегабайты, максимально – 25 мегабайт.
Убрали лишние роли, оставили порядка 150 штук, и все заработало быстро.
Точно не могу сказать, что повлияло: количество или вес ролей. Такого эксперимента мы не проводили, но суть в том, что убрали лишнее – заработало.

Не давать пользователю все роли без разбора, 1261 роль – это достаточно много.
Если порассуждать по поводу запроса, на котором были тормоза, то это был очень простой запрос с выборкой из основной таблицы одного регистра сведений. Без соединений, но с одним нюансом – там выбиралось порядка сотни полей.
Такое ощущение, что три секунды уходило на то, чтобы сервер 1С сформировал из текста запроса на языке 1С текст запроса на языке SQL. Возможно, он пытался для каждого поля поискать ограничения в выбранных для пользователя ролях. Но, так как он их не находил, то отправлял запрос точно такой же.
На слайде стоят знаки вопросов. Возможно, кто-то меня поддержит, а кто-то опровергнет мои догадки и кинет в меня ссылкой, потому что официального подтверждения своим догадкам я так и не нашел. Такой повод для дискуссий.
Вторая проблема

Перейдем к следующей проблеме:
Нагрузочный тест на 600 пользователей.
Использовалась также ERP, но практически типовая.
Серверы 1С и СУБД разнесены.
При начале итерации теста CPU на сервере СУБД возрастало до 100% и не отпускало несколько минут.
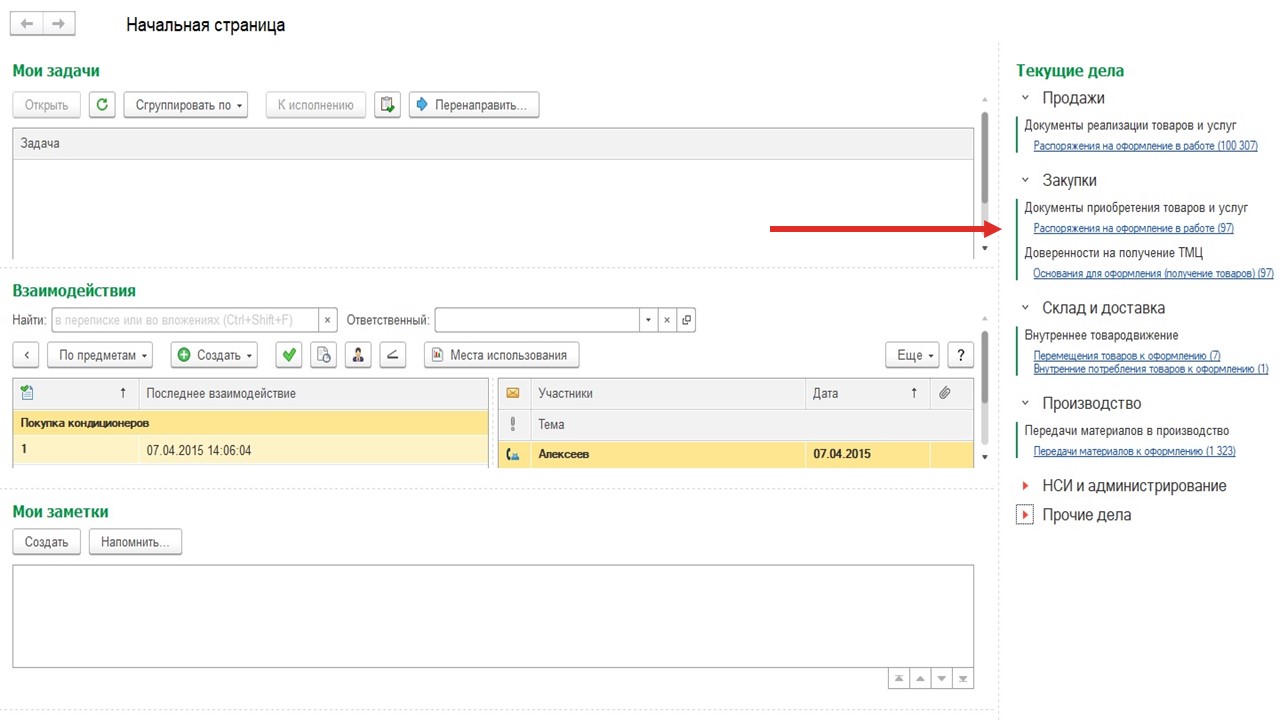
Предприняли самые простые действия.
Собрали трассировку запросов на SQL, сгруппировали, отсортировали по CPU.
На первом месте с большим отрывом – занимал в десять раз больше CPU, чем второе место – оказалось заполнение панельки «Текущие дела». По мере наполнения базы у нас этот запрос выполнялся порядка 15-20 минут. Оно крутится в фоне, никто этого не замечает, но оно нагружает базу.
Удалили эту панельку, стало легче.

Но раз уж я занимался СУБД, решил заглянуть в механизм ожиданий на SQL. Тут тоже будет немного теории.
Наверное, многие знают, что в SQL есть механизм системных динамических административных представлений – DMV. С помощью него можно посмотреть всевозможные данные о работе сервера: размер баз, таблиц, состояние индексов, когда делаются бэкапы, все, что угодно.

Одно из таких представлений –
Есть несколько основных типов ожидания – они перечислены на слайде, подробно рассказывать не буду.
В целом, я ожидал увидеть первый тип, который называется SOS_SHEDULER_YIELD. Если вы его видите на SQL – это значит, что у вас просто малоядерное ЦПУ. Так как у нас была нагрузка, я ожидал увидеть его.
Также есть несколько типов, которые говорят о недостаточной производительности дисков – PAGEIOLATCH и WRITELOG
И еще один тип ASYNC_NETWORK_IO, который означает, что у вас либо проблема с сетью, либо сервер 1С перегружен настолько, что не может принять результат какого-то запроса.
Самое простое – LCK, блокировки.

Итак, мы выполнили запрос к DMV sys.dm_os_wait_stats:
SOS_SHEDULER_YELD, который я ожидал увидеть, оказался на втором месте и занимал всего 6% от всех ожиданий;
а на первом месте был некий PAGELATCH_UP.
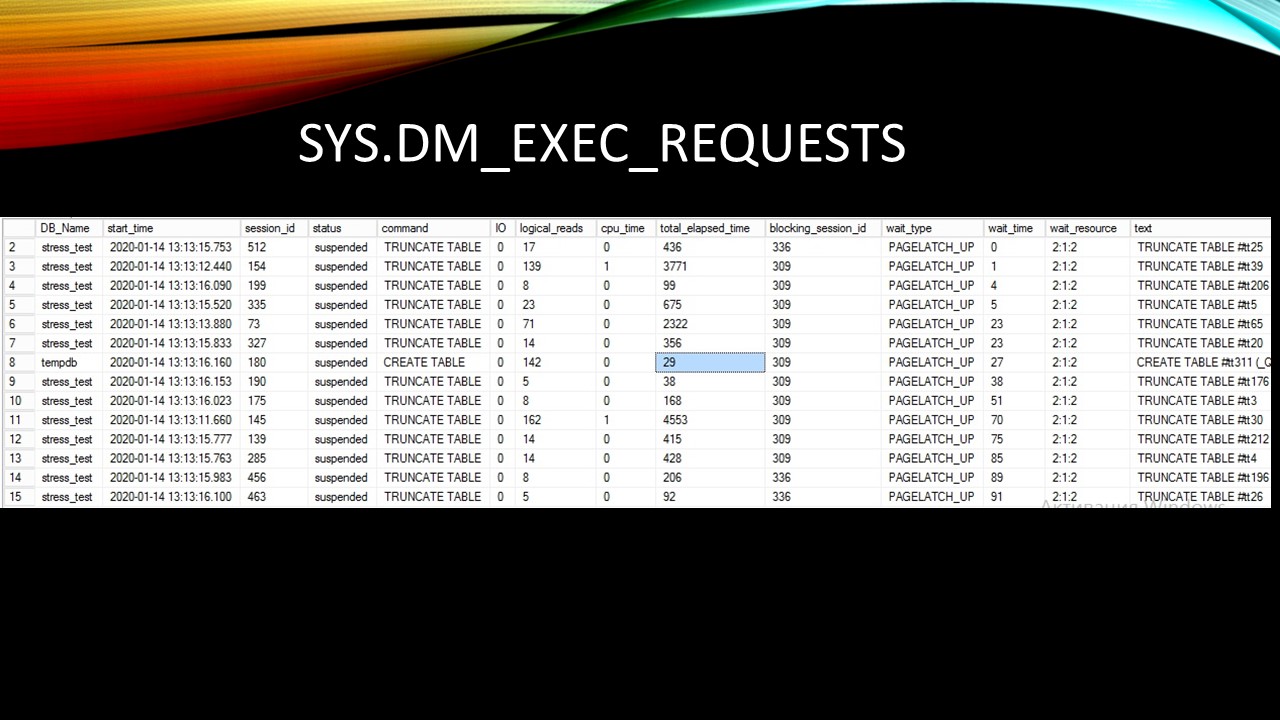
Еще скриншоты с таблицы sys.dm_exec_requests, где показан список запросов, которые выполняются прямо сейчас.
На этом слайде показано 15 запросов, и все они ждут.

Здесь – 12 запросов.

В пике уходило до 100 запросов, и время ожидания доходило до полсекунды. Это очень долго и очень плохо.

Прочел раза четыре, ничего не понял, и начал искать более понятное определение.

Выяснил, что Latches – внутренние блокировки SQL-сервера, которые должны быть очень легкими и короткими, незаметными. И они блокируют доступ не на диске, а в оперативной памяти.
Давайте посмотрим, откуда они могли у нас взяться.
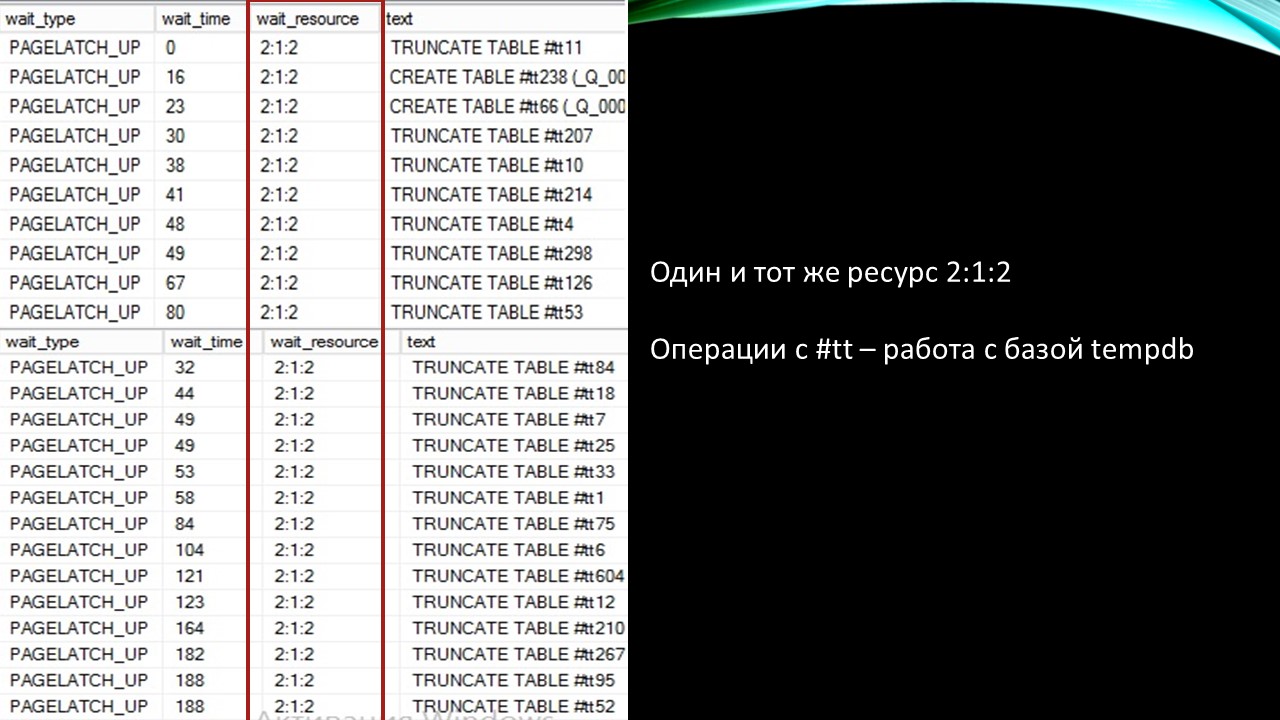
Если посмотреть внимательно на скриншоты таблички sys.dm_exec_requests – с запросами, которые выполнялись прямо сейчас – видно, что:
мы всегда ждем один и тот же ресурс – это некая страница 2:1:2;
мы видим здесь команды CREATE TABLE (создание таблицы) и TRUNCATE TABLE (очистка таблицы).

Здесь еще несколько скриншотов и везде – CREATE TABLE и TRUNCATE TABLE, только страницы другие – 2:3:2, 2:4:2, 2:5:2.

Чтобы понять, что это за страницы, еще раз обращусь к теории.
Многие знают, что в MS SQL Server данные хранятся в страницах. Каждая страница занимает 8 килобайт. И это не настраивается. В PostgreSQL, по-моему, настраивается, но тоже лучше не менять.
В MS SQL Server есть два типа экстентов: однородные и смешанные.
однородные – когда в экстенте хранятся данные только по одной таблице;
а смешанные – когда можем положить в него 8 разных страниц с данными по разным таблицам и индексам.

На слайде приведено куча определений – их можно не читать, я постараюсь донести суть.
В каждой базе на MS SQL Server есть ряд служебных страниц, которые контролируют заполненность наших страниц и экстентов.
Когда мы пытаемся добавить, записать какие-то данные, MS SQL Server обращается к картам, смотрит, что у него тут экстент свободный, тут – половинка и там – половинка, и решает, куда класть данные. После этого делает отметку в карте, что экстент заполнен, туда больше ничего не положить.
При очистке – то же самое, только наоборот. MS SQL Server данные из страницы убирает и ставит отметку в карту, что там свободно, можно что-то класть.
В случае с обычной базой данных это не так критично, потому что мы в нее не так часто пишем и удаляем данные. Чтобы увидеть такие ожидания в запросах пользовательской базы данных, у этой базы должна быть очень крутая загрузка. Как минимум тысяча пользователей.
В случае с базой tempdb все как раз наоборот. 1С-ка с ней работает очень интенсивно – постоянно создает и очищает таблицы, на скриншотах это как раз и было видно – CREATE TABLE, TRUNCATE TABLE. Они на tempdb выполняются постоянно.
Как раз на этих картах у нас и было ожидание – страница 2:1:2 как раз отвечает за то, какие экстенты у нас заняты.

Решение здесь простое:
Разбить базу tempdb на несколько файлов. На сколько разбить? Рекомендации сайта ИТС говорят, что надо разбивать на 4 части.
Я нашел более универсальную формулу: если у вас количество ядер меньше 8, то количество файлов должно быть равно количеству ядер, а если больше или равно – то количество файлов = 8. В целом, думаю, можно бить просто на 8 файлов и не париться – хуже не будет. Мы так и сделали, ожидания ушли.
Вторая рекомендация с сайта ИТС: флаг трассировки 1118. Этот флаг запрещает создание смешанных экстентов. Я этого не делал – мне хватило первой рекомендации. Но если у вас конкуренция за доступ к ресурсу 2:1:3, который отвечает как раз за смешанные экстенты – можно попробовать включить этот флаг. Но пользоваться этим нужно аккуратно, потому что если вы отключите смешанные экстенты, база будет расти.
Третья проблема
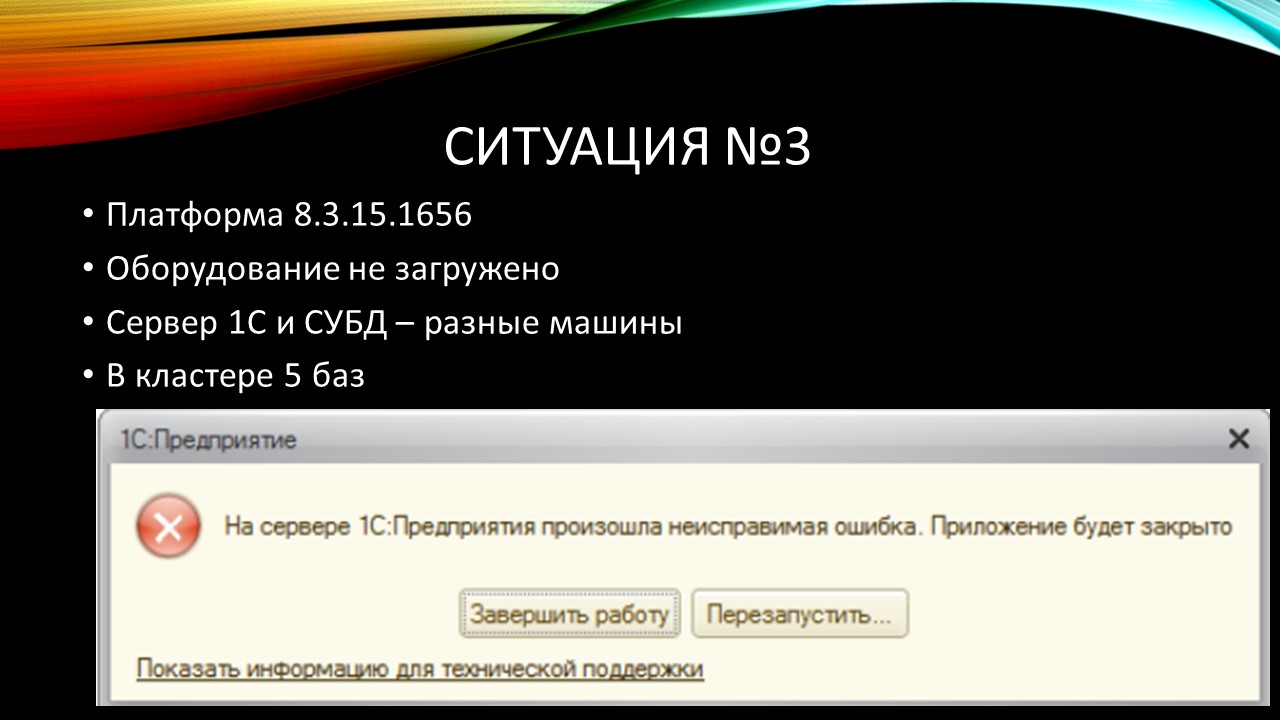
Еще одна ситуация:
Сервер 1С и сервер СУБД разнесены,
На сервере 1С – пять баз.
Оборудование не загружено, проблем с производительностью не было никаких, работало все достаточно быстро.
Но периодически вываливались непонятные ошибки.
Например, на слайде показана ошибка, с которой закрывалась 1С в разных базах, у разных пользователей. Это доставляло дискомфорт, с этим нужно было что-то сделать.
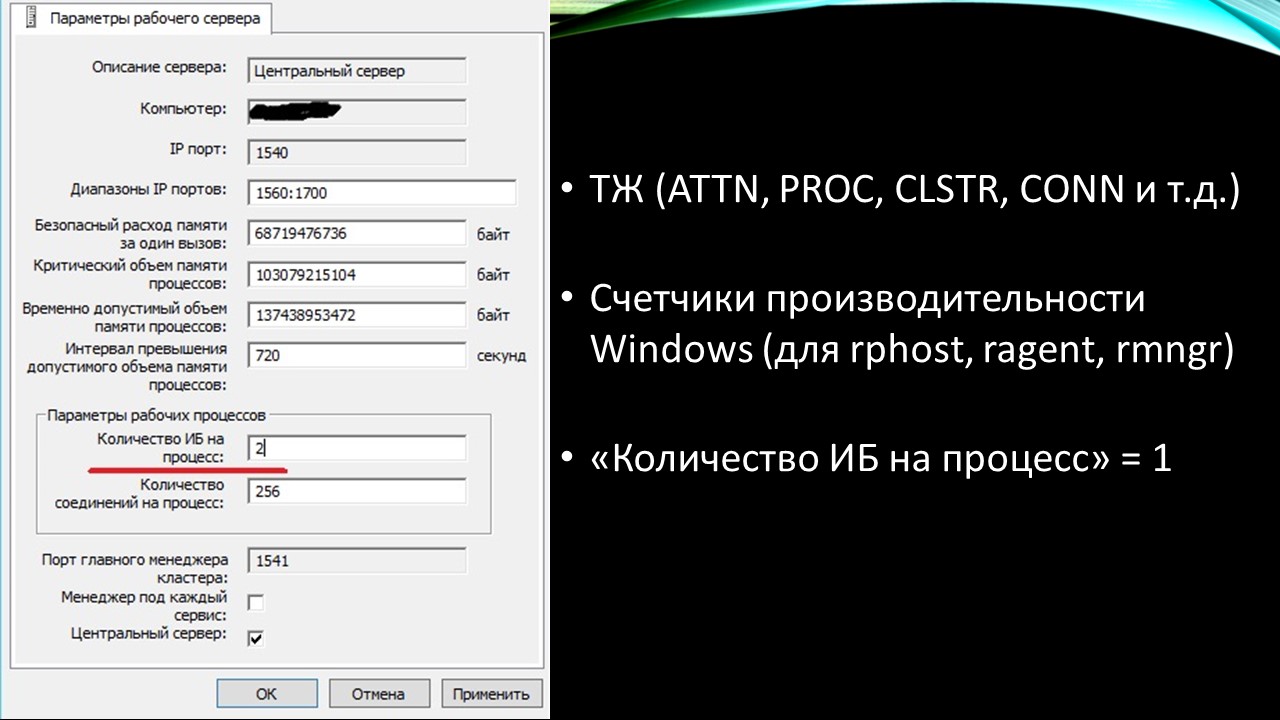
Для исследования настроили все возможные мониторинги.
Техжурнал с событиями, которые отвечают за работу сервера 1С: ATTN, PROC, CLSTR и тд.
Счетчики производительности Windows конкретно для процессов 1С: rphost, ragent, rmngr.
Изменили одну настройку: количество ИБ на процесс. У нас было 2, установили единицу.
Для чего это сделано? Когда количество ИБ=2, у вас один rphost хоть каждый день может обслуживать разные базы: в первый день у вас rphost обслуживает 1С:ERP и 1C:Документооборот, во второй день – 1С:Документооборот и БП, в третий – ЗУП и ERP и т. д. Когда возникает ошибка с падением – мы вылетаем из двух разных баз.
Чтобы понять: проблемы в какой-то из баз или платформа падает сама по себе – сделана вот такая настройка, что один rphost обслуживает одну базу.
Это дало результат – мы обнаружили, что падает только ERP. Мы хотя бы починили 4 базы из 5 – они падать перестали.
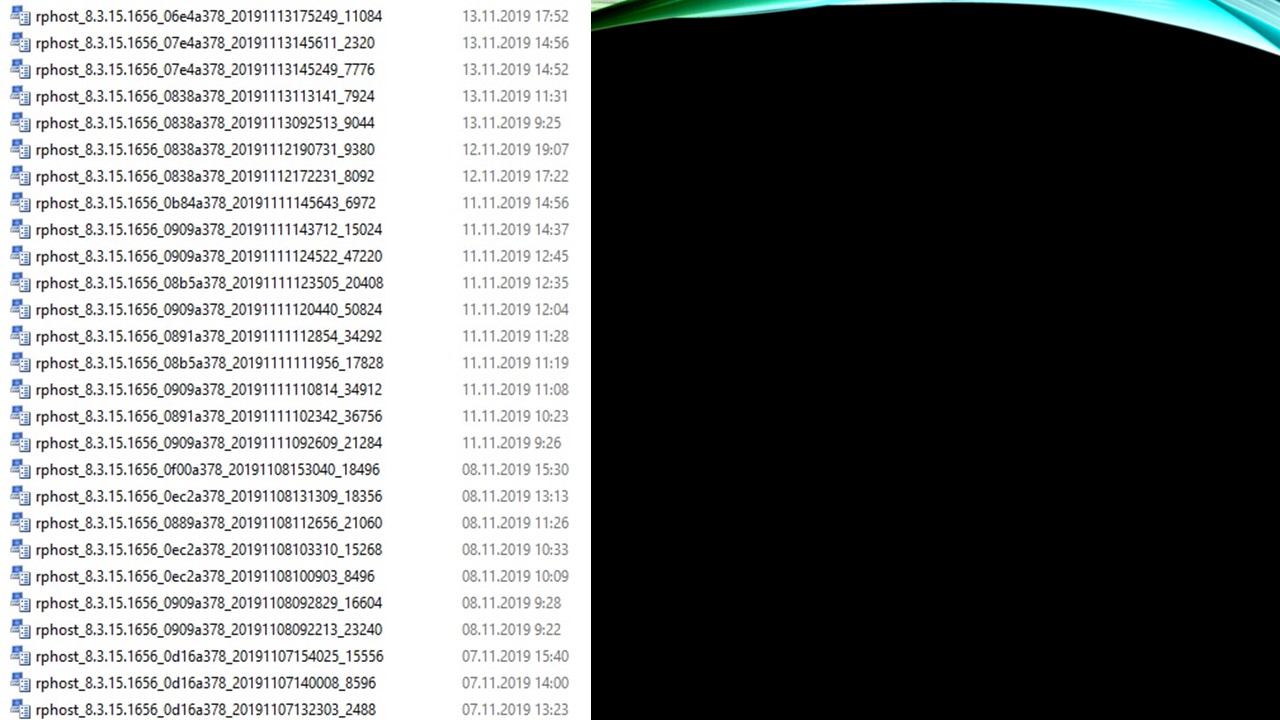
На слайде показан скриншот дампов, которые создавались из-за падений процессов. Здесь видно, что нет никакой закономерности, база падает каждый день по несколько раз. Из этого ничего было особо непонятно.
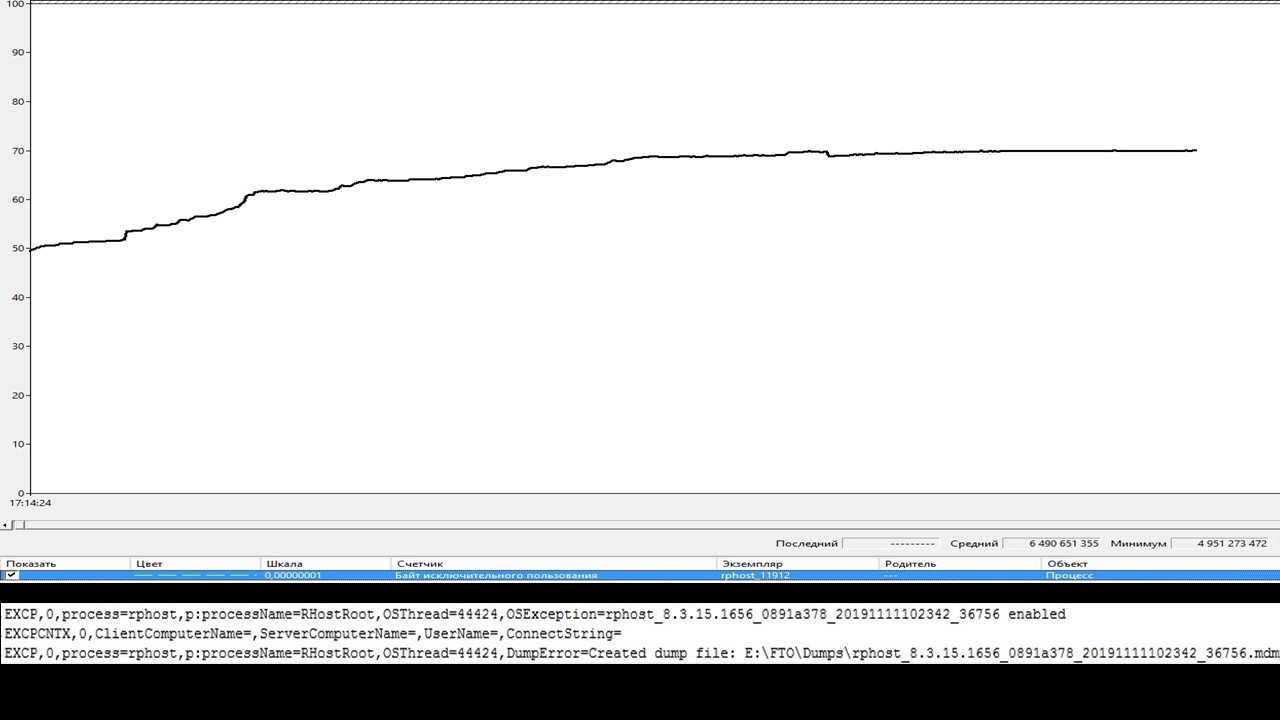
Это график потребления памяти одним из упавших rphost-ов. График получен с помощью стандартного мониторинга производительности Windows – Perfmon.
Мы видим график памяти:
перед падением нет никакого скачка, роста потребления;
нет и падения – не видно, что он пытается это отпустить, передать соединение на другой rphost;
он просто идет, живет своей жизнью и резко обрывается.
Снизу – запись rphost-а перед падением. В них нет описания ошибки, есть исключение операционной системы и больше никакой информации: «Я устал, я ухожу – вот тебе дамп, делай с ним, что хочешь».
Зачастую, когда падают rphost-ы, в логах rphost последней записью бывает прямо строчка кода, из-за чего он рухнул. И тогда сразу становится понятно, куда смотреть и что произошло. Но тут такого не было.
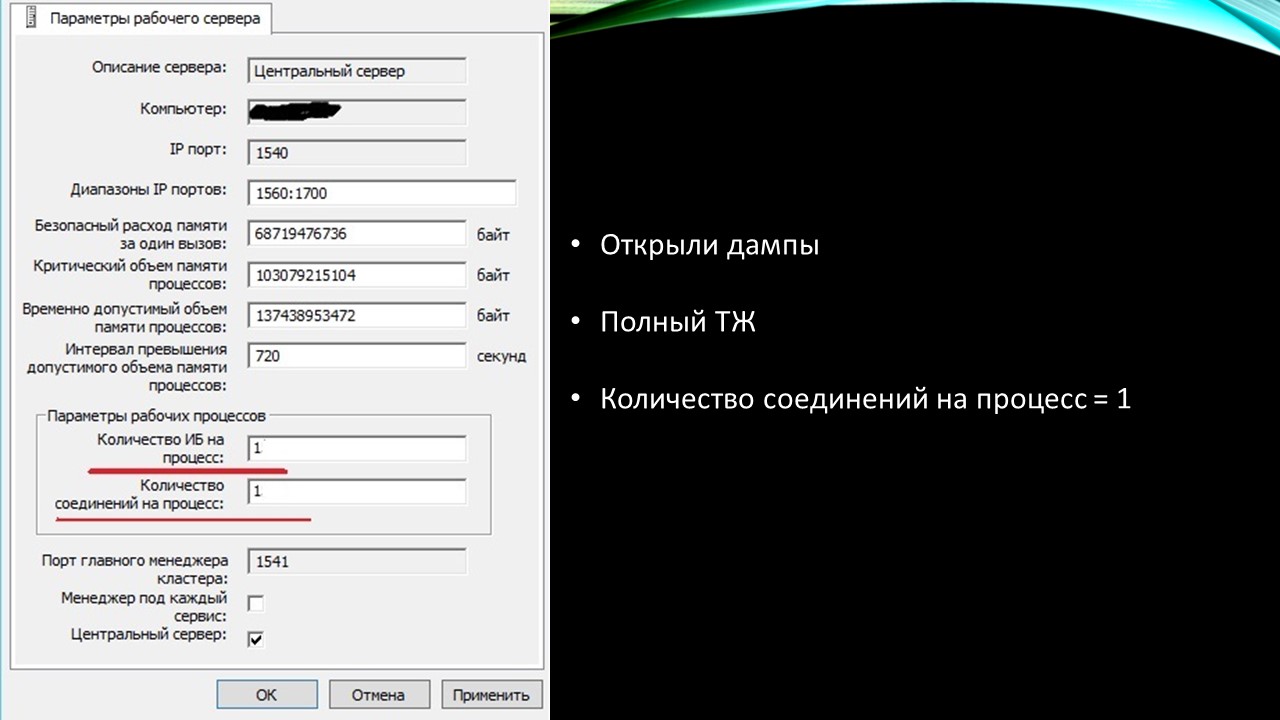
Попробовали открывать наши созданные дампы. Там были ссылки на библиотеку Windows, которая не могла быть источником проблемы.
Пособирали полный техжурнал, попытались найти закономерности – это нам тоже ничего не дало.
Тогда мы поставили экстремальную настройку, количество соединений на процесс = 1, из-за которой для каждого соединения создавался свой rphost. Нам повезло, что заказчик был достаточно лояльный и пошел нам навстречу с тяжелыми экспериментами. В результате rphost-ов было больше 100, все очень сильно тормозило, пользователи так поработали полдня. За эти полдня мы выловили несколько падений, надеялись увидеть какую-то закономерность: какой пользователь падает, выполняется ли перед этим какой-то запрос или форма. Нам это ничего не дало. Каждое падение было уникальным.

Идеи стали заканчиваться. Мы исследовали багборд 1С на предмет ошибок платформы и ERP, но ничего похожего по нашим симптомам не нашли. Google тоже ничего похожего не дал.
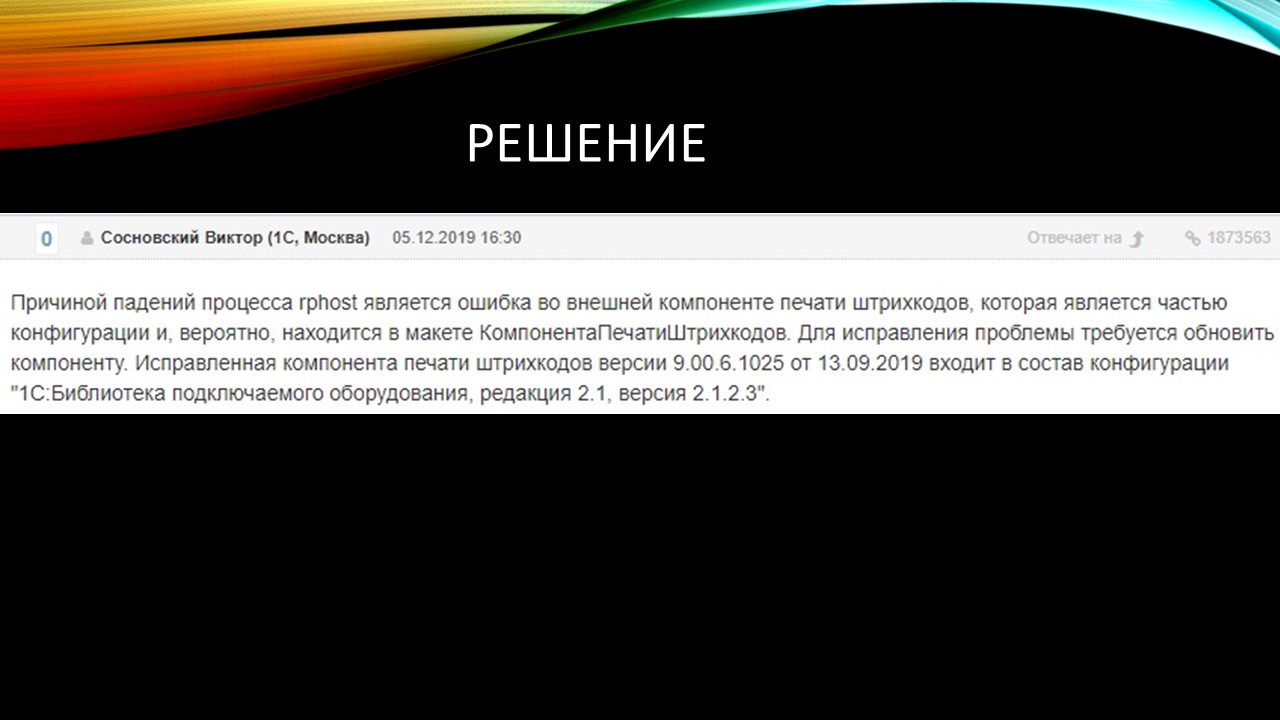
Решение нашлось случайно на партнерском форуме 1С. Там уже была создана тема с точно такими же симптомами, как у нас. Оказалось, что проблема была во внешней компоненте печати штрихкодов, которая лежит в общем макете в базе ERP.
Мы не нашли никаких ошибок, потому что эта компонента входит в состав библиотеки подключаемого оборудования. Когда мы искали ошибки на багборде, их нужно было искать не в платформе, не в системе, а в библиотеке.
Скачали новую библиотеку, обновили этот макет и падения ушли.
Вопросы
Создаваемые вами роли были отдельные (одна роль на один объект) или составные? И как вы догадались, что вес роли влияет на производительность? Это просто был перебор всех возможных комбинаций?
Роли мы создавали отдельные на каждый объект, составных ролей не было. А по поводу веса – не знаю, как догадался. То ли вычитал в интернете, то ли сам решил сделать это. Я до сих пор не уверен, что именно вес здесь вызвал проблему. Возможно, проблема была в количестве полей.
Поделитесь, какая версия MS SQL Server была, что вы словили проблему с tempbd с PAGELATCH_UP. Современный MS SQL Server по умолчанию ставит 8 файлов для tempdb.
У нас был MS SQL Server 2014. И там по умолчанию стоял один файл для tempdb.
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Ekaterinburg.Online. Больше статей можно прочитать здесь.
Приглашаем всех принять участие в тематических митапах Инфостарта и INFOSTART EVENT 2021 (6-8 мая, СПб).
Читайте также: