
Не могу выбрать подходящий парсер для файла pascal
Обновлено: 07.07.2024
Иногда в проекте на Си++ необходимо иметь небольшой математический парсер. Он может пригодиться, например, для разбора математических выражений, которые прописываются в XML-конфиге программы.
Наиболее простые способы это сделать - либо воспользоваться C/C++ биндингами к скриптовым языкам программирования (например, можно интегрировать вызовы функций LUA или Perl ), либо включить в проект готовую системную или стороннюю библиотеку математического парсинга (например, muparser , ExprTk или CMathParser ). Однако бывают ситуации, когда сделать это невозможно: например, программа пишется для сертифицированной среды, в которой нет нужных библиотек и инструментов, а сторонние запрещены; либо использование ПО предполагается на очень ограниченных встраиваемых системах. Именно для таких ситуаций хорошо бы иметь небольшой самописный математический парсер.
В Интернете есть много информации по методам создания математических парсеров. Но, к сожалению, нет готового компактного решения, которое содержало бы в себе основной базис. Можно найти куски реализации того или иного аспекта разбора и преобразования математического выражения, но готовые реализации "всего вместе" можно пересчитать по пальцам. И эти реализации, зачастую, могут иметь фундаментальные странности - например тот же CMathParser заточен только под Windows и без правки исходного кода не будет работать в Linux, достаточно посмотреть на его заголовки:
Ниже приведен рабочий пример математического парсера, который умеет работать с целыми и вещественными числами, и поддерживает четыре основных математических действия - сложение, вычитание, умножение, деление. Парсер имеет стандартный математический приоритет операций. Так же в этом парсере поддерживаются круглые скобки и запись отрицательного числа. Переменные и константы не поддерживаются, но парсер настолько прост, что их внедрение не представляет особого труда, если возникнет такая задача.
Данный парсер содержит выдернутые из интернета реализации абстрактного синтаксического дерева (AST) и генератора прямой польской нотации (а не обратной, просто потому что первым рабочим примером была найдена именно эта парочка). Вычисление итогового значения по прямой польской нотации дописано самостоятельно с использованием библиотеки Qt, просто потому что в ней есть готовые удобные контейнерные классы, да и целевой проект написан на Qt. Перевод с Qt на STD этой части кода пусть будет домашним упражнением для студентов факультетов информатики.
Репутация: 0
Откуда взялись эти классы? Тебе что, задано их определение (без реализации), и тебе надо с их помощью реализовать парсер? Или у тебя есть задание, и ты думаешь, что классы TCustomToken/TNumberToken/TCustomTokens должны выглядеть именно так?
Слишком уж много непонятного в этих описаниях. Начнем с определения "парсер". Что делает этот парсер? Если переводит выражение в постфикс - это одно, тогда я еще как-то могу согласиться, что в TCustomTokens организован массив (имитирующий стек), который хранит только Char-ы, большего, чем хранение скобок и знаков арифм. операций от того стека не требуется. Но вот если придется еще и вычислять, то тут без стека, хранящего числа, никак не обойтись, следовательно чего-то в TCustomTokens уже не хватает.
Второе: чего это в TCustomToken есть метод LoadFromString (насколько я понимаю, читающий знак очередного оператора из входной строки с определенной позиции), а в TNumberToken такого метода нет? Что, числа не читаются с той же строки? Тогда откуда они берутся?
Третье: зачем присутствуют 3 разных не связанных друг с другом класса? Я понимаю, если бы TCustomToken и TNumberToken были наследниками какого-то базового класса, тогда можно было бы и стек сделать один, способный хранить и числа и знаки операций. Но у тебя вообще нет наследования.
Есть исходники еще одного парсера, он не выложен на моем сайте, который вычисляет выражения, содержащие +-*/^ и тригонометрические функции (включая обратные: arcsin/arccos/arctan), для FPC, но должно отработать и в Дельфи с небольшой корректировкой, если надо - скажи. Там, правда, тоже нет иерархии классов, все одним классом реализовано.
Репутация: 0
Да, задано именно такое определение классов.
Их надо было реализовать + в классах можно прописывать свои методы, свойства, поля(т.е. с ними можно делать что угодно, как я поняла, даже организовать наследование, надо только, чтобы основная структура сохранилась).
А три класса из-за того, что нас хотят научить работать с классами)
В условиях только не было прописано, что FItems: array [0..FCount-1] должен иметь тип char, это уже мои домыслы.
А так, по идее, должна быть первоначальная строка, в которую пользователь вводит выражение. Далее бежим по строке, если видим цифру, то её в TNumberToren, если знак, то в TCustomToken. Потом надо из двух классов, всё что получилось занести в третий класс. А далее посчитать выражение.
Написать парсер - задача несложная. Гораздо сложней написать хороший парсер, но мы пока такой цели и не ставим. В нашем учебном примере ограничимся разбором и арфиметической оценкой строки на Паскале, зависящей от единственного аргумента, обозначенного x. Писать парсер мы будем тоже на Паскале, поэтому обойдемся только стандартными средствами этого языка. По-хорошему стоило бы сделать всё на Си через структуры и указатели (см., например, парсер выражений из этого моего архива, 4 Кб).
В чем, собственно состоит задача?
У нас есть выражение, записанное по правилам языка Паскаль, например, такое:
- Проверить формальную синтаксическую правильность этого выражения.
- Вычислить выражение для любого значения x.
Желательно также, чтоб парсер не был слишком капризен к лишней паре скобок, умел понимать числа в любом формате и вылавливал элементарные математические ошибки вроде деления на ноль. Для удобства стоит оформить парсер в виде отдельного модуля, чтоб потом подключать его к своим программам. Поддержка вычислений вида 1+++x - также не проблема, раз Паскаль такое принимает, а 1+-x и -x+1 тем более могут понадобиться.
Будем действовать самым очевидным образом - сначала разделим строку на отдельные лексемы, потом перепишем эти лексемы в массив, проверим правильность цепочки лексем, наконец, после этого будем вычислять выражение по правилам языка, постепенно сокращая массив, пока на выходе не останется единственное число - результат расчета.
Под лексемой я имею в виду "минимальную единицу" выражения - скобку, знак операции, имя функции или число.
В интерфейсной части модуля опишем следующие глобальные данные:
- (,) - открывающая и закрывающая скобки;
- f - стандартная функция;
- n - число, а также функция без аргументов pi;
- x - аргумент нашего выражения x;
- o - арифметическая операция.
При анализе выражения понадобятся также отдельные метки начала (S) и конца (E) выражения - некоторые лексемы меняют правила, оказываясь в начале или конце выражения. Все эти метки будут помещаться в массив types. Поскольку мы работаем изначально со строкой, получаемые нами числа придется возвращать также в строковые массивы что чревато большими потерями точности при использовании стандартной процедуры str. Поэтому все числа, получаемые при "упаковке" массива лексем будем дополнительно копировать в вещественный массив numbers и брать их для расчета именно оттуда.
Формально правильное выражение не обязательно способно вычислиться - при расчете могут всплыть деление на ноль, извлечение корня из отрицательного числа и другие неприятности. Поэтому введем строку runerror, куда будем писать арифметические ошибки вычисления.
Самое первое, что следует сделать со строкой выражения - убрать лишние пробелы и привести все символы к одному регистру. Следующие 2 функции это и делают, на всякий случай lowcase работает и с кириллицей DOS, понимаемой Паскалем.
Основная функция парсера parse проконтролирует, не пуста ли оставшаяся строка, вызовет функцию проверки и разбора выражения check, и наконец, если выражение верно, вызовет функцию eval, выполняющую расчет. Можно вызывать check и eval независимо друг от друга, если нужно только проверить выражение или вычислить без проверки. Выглядеть функция parse будет следующим образом:
- проверить парность и правильное вложение круглых скобок;
- излечь из строки все, какие возможно, числа;
- извлечь знаки операций, стандартные функции и аргумент x.
На этапе 2 нужно внимательно учесть, что знаки "+" и "-" могут обозначать как операцию сложения или вычитания, так и знак числа или аргумента x.
Этот алгоритм расставит метки типов в строку s0 той же размерности, что исходная строка s, содержащая выражение. Для приведенного выше выражения, например, получится:
Для исключения лишних цепочек плюсов и минусов вызывается функция replace_strings, делающая строковые замены:
Однако, выражения типа -x+1 после нее остаются, почему и необходим дополнительный контроль (блок "").
Функция oper, которая будет вычислять выражения, тоже может получить подобные конструкции после сокращения цепочки лексем, так что постараемся в нее тоже не забыть вставить блок для дополнительного контроля знаков "+" и "-".
Все неверные лексемы мы помечали подчеркиванием в s0, осталось выбрать их и сообщить, если есть ошибка (продолжение функции check):
Теперь все лексемы помечены буквами типов.
На втором этапе своей работы функция check проверяет, выполняются ли формальные правила следования лексем друг за другом, и заодно наполняет данными массивы lex, types и numbers. Все эти действия выполняются путем вызова подпрограммы get_lexem_arrays:
В свою очередь, get_lexem_arrays вызывает функцию check_rool, передавая ей типы и строковые значения каждой пары соседних лексем. Чтобы отследить начало и конец цепочки, они помечаются специальными лексемами S и E. В check_rool заложены правила следования двух соседних лексем, поэтому ее логика довольно наглядна.
Итак, если все нормально, функция check вернула истину, и можно вызывать функцию eval для вычисления.
Пока в выражении есть нераскрытые скобки, eval будет раскрывать их, обращаясь к рекурсивной функции skobka. Последняя функция, в свою очередь, вызовет функции обслуживания стандартных подпрограмм и арифметических выражений. Попутно функция eval смотрит, не возникло ли глобальной ошибки выполнения runerror и, в случае чего, возвращает значение "ложь", показывающее, что при данном x посчитать формулу нельзя. Когда скобок не осталось, достаточно оценить последнее арифметическое выражение, в которое превратилась цепочка расчетов.
Для оценки количества оставшихся скобочных выражений (непарные и неправильные скобки мы исключили ранее), не мудрствуя лукаво, вызывается функция kol_items.
Функция skobka имеет следующий вид:
Кроме обработки скобок, она вызывает подпрограмму для вычисления стандартных функций func:
и подпрограмму поиска арифметических выражений find_oper:
Если в самых внутренних скобках удалось найти подходящее выражение, оно вычисляется функцией oper.
Эта функция "доводит" свое выражение до одного значения. "Тонкая" операция исключения лишнего + и -, объявившегося перед числом после сокращения цепочки лексем, возложена на процедуру pack_number_sign:
Непосредственный расчет выражения вида A+B делает подпрограмма do_oper:
После вычислений цепочку лексем необходимо "паковать", исключая уже обработанное:
Заодно pack_lexems борется с неточным сохранением чисел стандартной процедурой str, дублируя эти числа в массив numbers.
Наконец, функция number_skob нужна для обработки оставшегося в скобках единственного аргумента
а функция number - просто аргумента без скобок:
При этом функция берет ранее сохраненные в массиве numbers значения.
Остается соединить все в один модуль и получится файл parser.pas, который можно скачать по этой ссылке:
парсер выражений на Паскале (архив *.zip со всеми файлами .pas из статьи и скомпилированным parser.tpu, 12 Кб).
Для тестирования модуля напишем маленький файл parse_me.pas.
Надеюсь, Вы не забыли, что для подключения модуля его нужно иметь скомпилированным в одной из папок, прописанных в настройке EXE & TPU Directory меню Options.Directories Турбо Паскаля. Скомпилировать исходник модуля на диск можно, если открыть в редакторе файл parser.pas, в меню Compile.Destination выставить значение Disk и выполнить команду меню Compile.Build.
Вместо содержимого строки s и выражения, присвоенного переменной rr, можно поставить и любое другое выражение, например,
тоже прекрасно сработает. Кстати, и
теперь наш парсер не смутит.
На практике удобнее один раз проверить с помощью check правильность заданной пользователем функции, а потом уже вычислять ее для разных значений x с помощью eval. Правда, тогда придется снабдить наш модуль дополнительной функцией, возвращающей вызывающей программе данные разбора, такие как переменная clex, массивы lex и types - мы-то все делаем в глобальных переменных и массивах. Но эту задачу я возлагаю на Вас, а в примере ниже буду просто предварительно проверять правильность введенной функции с помощью check, а потом вызывать parse, которая повторит всю ее трудоемкую работу. Лучше было бы вызвать eval напрямую.
Чтобы не быть голословными, давайте построим любимый мной с детства интерполяционный сплайн. Это такая гладкая кривая с неперерывной второй производной, проходящая через набор заданных точек.
Далее приводится листинг файла spline.pas, содержащего подпрограммы для построения интерполяционного сплайна, а также подключающего парсер для того, чтобы построить сплайн по таблице значений произвольной функции. В программе не делаются все проверки корректности, их легко добавить. Обратите внимание на вызов парсера из функции f, а также на ввод строки s в главной программе модуля.
Вот скриншот тестового прогона программы spline.pas:
Если программа найдет ошибку времени исполнения, соответствующее значение f(x) будет вычислено как 0. Например, такое произойдет в первой точке при вводе функции 1-2/x, интервала от 0 до 1 и шага 0.5.
Эту статью я написал в надежде помочь всем, только начавшим изучение БАСа и задающим много вопросов по поводу этого софта.
В процессе статьи научимся писать основные шаблоны для сайтов - парсеры, спамеры и тд. Это мы сделаем всеми возможными методами, которые только сайт нам позволит!
Также попытаюсь максимально подробно объяснить разницу между тем, в чем путался сам и ответить на наиболее часто встречаемые мне вопросы, научимся создавать спинтаксы, уравнения xPath и многое другое. Статья будет длинной, но главное, чтобы мои труды принесли тебе, читатель, пользу!
P.S. В конце статьи я приложу сам шаблон, чтобы Вы могли его поковырять и увидеть своими глазами.
Делать парсер на вебе - это извращение) поэтому сделаем его на запросах.
Создаем проект нажав кнопку "Запись"
Для начала нарисуем примерный макет будущего шаблона. Иметь он будет примерно такой вид:
- загружаем первую страницу с перечнем видео
- вытаскиваем с нее ссылки на видео
- записываем это в текстовик для дальнейшего применения
- переходим на следующую страницу
- повторяем пункт 2, 3 и 4.
Как это будет выглядеть в шаблоне?
Параллельно открываем эту же страницу в окне обычного браузера и открываем код элемента.
В коде элемента нужная нам ссылка находится вот в таком селекторе

Составляем xPath уравнение.
Нужная нам ссылка находится в селекторе с классом 'a', в этом селекторе присутствует класс а нужная нам ссылка - в элементе href. Уравнение xPath будет иметь следующий вид
//a[@class='swp']/@href
Уравнение составлено, необходимо проверить его работоспособность.

В поле "xPath запрос" вписываем наше уравнение, жмем ОК и выводим в лог переменную, в которую мы сохранили собранные ссылки. Общая картина следующая:
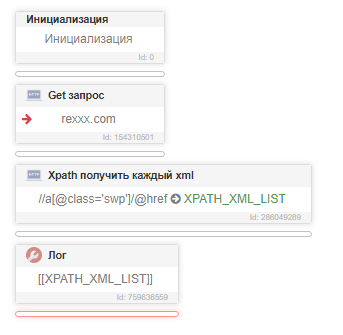
кнопочку и наблюдаем, выводятся ли нужные нам ссылки в лог:

После этого необходимо, чтобы все записывалось в текстовый файл.
Для этого выбираем действие "Записать список в файл", находящийся во вкладке "Файловая система".

Для этого в начале проекта устанавливаем переменную одноименным действием, находящимся по такому пути: Логика скрипта -> установить переменную
Задаем ей значение "0" и в конце проекта увеличиваем её на 60. Итого переменная у нас будет изменяться таким образом: 0-60-120-180-240. .
Подставляем нашу переменную в ссылку, заменяя число переменной. Получается у нас:
Заменяем в GET-запросе чистую ссылку на ссылку с переменной.
Зацикливаем этот процесс посредством меток (в нашем случае они будут наилучшим вариантом).
В конечном итоге шаблон имеет вид:


Написать шаблон - это хорошо, но запустить его - еще лучше! Поэтому возвращаемся к зелёной
кнопочке, тыкаем её и наслаждаемся своими трудами.
Подведём итог: мы научились писать самый простенький шаблон парсера для сайта, который будет собирать данные в текстовый документ, который мы потом сможем использовать в дальнейшем.
Читайте также: