
Не удалось собрать данные об использовании физической памяти numa
Обновлено: 02.07.2024
При размещении виртуальных рабочих нагрузок наиболее важным для общей производительности аппаратным ресурсом является, пожалуй, физическая память. Крайне важно распределять память так, чтобы каждая виртуальная машина (ВМ) располагала необходимой ей памятью, но при этом память не тратилась бы без толку. Ниже приведены несколько ключевых соображений для распределения памяти при работе с Microsoft Hyper-V.
Соображения архитектуры NUMA
Управление памятью для Hyper-V является своего рода искусством. Необходимо гарантировать, что каждой ВМ будет предоставлен адекватный объем памяти. В то же время необходимо избежать предоставления ВМ большего объема памяти, чем необходимо.
Причины этого представляются очевидными. Выделение избыточной памяти одной ВМ ограничивает объем памяти, который можно выделить другим ВМ на том же сервере. Но порой выделение ВМ чрезмерной памяти может также и снизить ее производительность.
Большинство новых серверов используют память с архитектурой неоднородного доступа (NUMA). Память NUMA разработана для улучшения производительности путем выделения памяти отдельным процессорам. Отдельные блоки выделенной памяти известны как узлы NUMA. ЦП может выполнять доступ к своему локальному узлу NUMA (памяти, непосредственно выделенной данному ЦП) быстрее, чем к прочим узлам NUMA.
Версии Hyper-V для Windows Server 2008 и 2008 R2 не поддерживают соответствие памяти узлам NUMA напрямую. Другими словами, ВМ нельзя напрямую настроить на использование определенного узла NUMA. Сообщается, что эта возможность будет существовать в версии Hyper-V для Windows Server 8. Тем не менее, возможно предпринять действия, сокращающие шансы использования нелокального узла NUMA ВМ.
Фокус в том, чтобы рассчитать размер каждого узла NUMA. Например, предположим, что наш сервер снабжен двумя восьмиядерными процессорами и 128 ГБ ОЗУ. Размер узла NUMA можно рассчитать, разделив объем памяти (128 ГБ) на число ядер ЦП (16). В данном конкретном случае размер узла NUMA будет составлять 8 ГБ.
Hyper-V пока не позволяет нам назначить определенный узел NUMA определенной ВМ. Однако, поскольку известно, что размер узлов NUMA на данном сервере составляет 8 ГБ, можно догадаться, что любая ВМ, которой выделено более 8 ГБ памяти, будет использовать память из нескольких узлов NUMA. Ограничение памяти, выделяемой ВМ, 8 ГБ или менее (в рассматриваемом случае) увеличивает шансы, что ВМ будет использовать память из единственного узла NUMA, тем самым повышая производительность.
Издержки Hyper-V
Узлы NUMA – не единственный фактор, который следует учесть при управлении памятью. При планировании способов использования памяти несущего сервера крайне важно учесть издержки, связанные с виртуализацией. В отношении этих издержек нужно учесть два основные фактора. Во-первых, родительский раздел требует выделения памяти.
Необходимо зарезервировать минимум 300 МБ для низкоуровневой оболочки и 512 МБ для несущей ОС, работающей в родительском разделе. Однако большинство рекомендаций утверждают, что для родительского раздела следует зарезервировать 2 ГБ.
Несущий раздел следует использовать только для Hyper-V (хотя в нем также можно запускать ПО инфраструктуры и безопасности, такое как агенты управления, агенты резервного копирования и брандмауэры). Следовательно, рекомендованный объем в 2 ГБ предполагает, что родительский раздел не будет использоваться для дополнительных приложений или ролей сервера.
Hyper-V не позволяет выделять напрямую несущему разделу. По сути, он использует то, что останется. Поэтому следует помнить, что 2 ГБ памяти несущего сервера следует оставить невыделенными, чтобы они были доступны родительскому разделу.
Выделение памяти гостевым машинам
Другой фактор издержек памяти, который следует учесть, — это использование ВМ небольшого объема памяти для служб интеграции и других процессов, связанных с виртуализацией. Этот объем памяти довольно незначителен, так что обычно нет нужды волноваться о выделении для него дополнительной памяти, если только не планируется предоставить каждой ВМ лишь минимально необходимую память.
ВМ с 1 ГБ ОЗУ или менее используют только около 32 МБ памяти на издержки, связанные с виртуализацией. Сюда следует добавлять 8 МБ за каждый дополнительный гигабайт ОЗУ. Например, ВМ с 2 ГБ ОЗУ будет использовать 40 МБ (32+8) памяти на издержки, связанные с виртуализацией. Аналогично, ВМ с 4 ГБ памяти будет терять таким образом 64 МБ.
Динамическая память
В Windows Server 2008 R2 с пакетом обновления 1 была представлена новая функция динамической памяти, позволявшая ВМ потреблять память динамически, в зависимости от текущей нагрузки. Это также позволяет использовать физическую память сервера сверх обычного, для использования большего числа ВМ, чем было бы возможно иначе. Несмотря на все преимущества динамической памяти, при ее использовании важно следовать некоторым правилам, чтобы избежать недостатка памяти у ВМ.
Во-первых, не во всех случаях использование динамической памяти оптимально. Включать или отключать динамическую память можно для каждой отдельной ВМ. Важно включать ее лишь для тех ВМ, которым она действительно может пригодиться.
Одним из наиболее важных соображений здесь является рабочая нагрузка ВМ. Если приложение на ВМ разработано для использования фиксированного объема памяти, лучше дать ВМ именно тот объем памяти, который нужен этому приложению, вместо использования динамической памяти.
То же касается приложений, требующих большого объема памяти. Некоторые приложения разработаны так, чтобы потреблять столько памяти, сколько возможно. Такие приложения могут быстро поглотить всю физическую память сервера, если им разрешено использовать динамическую память. ВМ, на которых работают приложения таких типов, лучше выделять фиксированный объем памяти.
Наконец, производительность сервера может пострадать, если ВМ попытается использовать память из нескольких узлов NUMA. Следовательно, если сервер использует память архитектуры NUMA и производительность является важной проблемой, может быть необходимо воздержаться от использования динамической памяти.
ОЗУ для запуска
Одной из наиболее важных для понимания концепций в области динамической памяти является ОЗУ для запуска. При использовании динамической памяти каждой ВМ необходимо назначить ее значение ОЗУ для запуска. Это значение отражает объем физической памяти, который ВМ будет первоначально использовать после загрузки. Что более важно, ОЗУ для запуска также представляет минимальный объем физической памяти, потребляемый ВМ. Использование памяти ВМ не может быть ниже значения ОЗУ для запуска.
Учитывая это, корпорация Майкрософт рекомендует избегать назначения ВМ больших объемов ОЗУ для запуска. ОЗУ для запуска лучше всего основать на ОС, используемой ВМ. Корпорация Майкрософт рекомендует использовать 512 МБ ОЗУ для запуска ВМ, использующих Windows 7, Windows Vista, Windows Server 2008 и Windows Server 2008 R2. Если ВМ будут использовать Windows Server 2003 или Windows Server 2003 R2, корпорация Майкрософт рекомендует 128 МБ ОЗУ для запуска.
Для использования ВМ динамической памяти последняя должна поддерживаться ОС, работающей на этой ВМ. Windows XP не поддерживает динамическую память. При попытке запустить Windows XP на ВМ, настроенной для использования динамической памяти, ОС может получить доступ только к ОЗУ для запуска.
Перед переходом к другим задачам конфигурации важно убедиться, что общая сумма ОЗУ для запуска, выделенная всем существующим ВМ, не превышает физический объем ОЗУ на сервере. В ином случае нужно будет либо удалить часть ВМ, либо добавить памяти.
Также может понадобиться скорректировать значение максимального объема ОЗУ. Это значение указывает верхний предел физической памяти, который может использовать ВМ. По умолчанию Hyper-V устанавливает максимальный объем ОЗУ каждой ВМ на 64 ГБ. Если некоторые ВМ не требуют столько физической памяти, может потребоваться снизить значение максимального объема ОЗУ.
Вес памяти
Вся суть идеи динамической памяти состоит в возможности более интенсивного использования памяти. Она позволяет ВМ получать доступ к памяти, которая им нужна, когда она им нужна. Большим недостатком интенсивного использования любого аппаратного ресурса является возможность его исчерпания в определенный момент. В случае динамической памяти ВМ вполне могут поглотить всю доступную физическую память и потребовать еще.
Долгосрочным решением для этой проблемы является обеспечение сервера достаточной памятью для обслуживания требований ВМ. Временным же решением является приоритизация использования памяти.
Почти на всех несущих серверах имеются ВМ, которые важнее других. Hyper-V позволяет определять приоритетность ВМ, так что в случае недостатка физической памяти память будет выделяться ВМ с более высоким приоритетом в первую очередь. Определить приоритет потребности ВМ в динамической памяти можно, корректируя ее вес памяти. ВМ с более высоким весом памяти имеют приоритет перед ВМ в меньшими весами памяти.
Другой параметр, который необходимо настроить для каждой ВМ, использующей динамическую память, – буфер памяти. Параметр буфера памяти контролирует, сколько памяти каждой ВМ следует попытаться зарезервировать в качестве буфера. Это значение выражается как процент. Например, если ВМ использует 4 ГБ выделенной памяти, а буфер памяти установлен на 50 процентов, ВМ может поглотить до 6 ГБ памяти.
Буфер памяти не гарантирует, что память в буфере будет доступна для ВМ. Он просто контролирует, сколько памяти ВМ следует попытаться запросить. Следует отметить, что поскольку буфер памяти выражается как процент, объем памяти в буфере меняется в соответствии с объемом памяти, используемой ВМ в конкретный момент времени. Все ВМ, использующие динамическую память, запускаются используя минимальный объем памяти. Они динамически корректируют использование памяти в зависимости от требований, предъявляемых к их памяти рабочими нагрузками.
Конфигурация памяти
Собственно процесс настройки использования памяти ВМ прост. Откройте диспетчер Hyper-V и щелкните правой кнопкой мыши ВМ (поскольку память каждой ВМ управляется независимо). Выберите команду «Параметры» из контекстного меню. При появлении диалогового окна «Параметры» щелкните «Память».
Hyper-V предоставляет возможность либо выделить ВМ статический объем памяти, либо использовать динамическую память (см. рис. 1). При выборе динамической памяти параметры ОЗУ для запуска, максимального объема ОЗУ, буфера памяти и веса памяти можно настроить прямо в диалоговом окне «Параметры».
.jpg)
Рис. 1. Выделение памяти для виртуальной машины можно скорректировать через диалоговое окно «Параметры».
Если ресурсы физической памяти несущего сервера ограничены, обычно необходим компромисс между использованием статической и динамической памяти. Статическая память обычно обеспечивает лучшую производительность в целом (при адекватном выделении памяти). Динамическая память может вызвать сложности, но она обычно допускает большую плотность ВМ.
Доброго дня все никак не могу вкурить что к чему в NUMA
Итак есть сервак HP GEN8 DL160 два ксеона каждый по 8 ядер 16 потоков итого имеем 32 потока(виртуальных процессора) и 224 гига оперативной памяти.
Установлена роль гипервизора с охватом NUMA
2ве виртульные машины
1 терминал Citrix xenapp 6.5
Выделенные ресурсы
12 Процессоров
45 гигов памяти
В настройках показывает
Узлов NUMA -1
Cокетов-1
(Если машине выделяю больше оперативы то в параметрах показывает как и на SQL Узлов NUMA -2
Cокетов-2)
2 SQL 2014
Выделенные ресурсы
12 Процессоров
135 гигов памяти
В настройках показывает
Узлов NUMA -2
Cокетов-2
Суть вопроса такова
Чему ровен 1 NUMA узел -сколько процессоров это или сокетов.
Может кто на примере разложить что к чему и сколько нужно указывать максимальное чило NUMA на сокет
Архитектура NUMA делит память и процессоры на группы, которые называются узлами NUMA. Для каждого отдельного процессора в системе память, расположенная в том же узле NUMA, что и сам процессор, является локальной, а память в другом узле NUMA — удаленной. Доступ к локальной памяти осуществляется быстрее.
Большинство современных операционных систем и высокопроизводительных приложений, рассчитанных на использование сразу нескольких процессоров и большого объема памяти, например Microsoft SQL Server, включают оптимизации, которые распознают топологию NUMA компьютера и адаптируются к ней. Чтобы избежать потерь при удаленном доступе, приложения с поддержкой NUMA выделяют хранилище для данных и направляют потоки процессоров на доступ к данным в том же узле NUMA Подобная оптимизация позволяет сократить время доступа к памяти и уменьшить трафик обращений к памяти.
При запуске виртуальной машины Hyper-V пытается выделить всю необходимую для нее память в одном физическом узле NUMA (если объем доступной памяти это позволяет). Если на одном узле памяти недостаточно, Hyper-V выделяет память еще на одном узле NUMA. Это называется охватом NUMA. Дополнительные сведения об охвате NUMA см. в разделе Параметры сервера: охват NUMA, который приводится ниже.
Еще одна ссылка с подробным описанием и схемами Hyper-V Design for NUMA Architecture and AlignmentНеоднородная архитектура памяти (NUMA) как особый вид организации подсистемы памяти существует уже довольно давно. Ее наиболее наглядный и доступный вариант представлен подсистемой памяти многопроцессорных платформ AMD Opteron, и существует он, можно сказать, с момента анонса самих процессоров AMD Opteron 200-х и 800-х серий, поддерживающих многопроцессорные конфигурации. Вместе с тем, изучение этой архитектуры памяти (здесь и далее мы будем иметь в виду исключительно ее «AMD-шный вариант») на низком уровне, анализ ее преимуществ и недостатков до сих пор не проводились. Этим мы и решили заняться в настоящей статье, благо в распоряжении нашей тестовой лаборатории оказалась очередная двухпроцессорная система на базе процессоров AMD Opteron. Но для начала, напомним основные особенности этой архитектуры.
Большинство типовых многопроцессорных систем реализовано в виде симметричной многопроцессорной архитектуры (SMP), предоставляющей всем процессорам общую системную шину (а, следовательно, и шину памяти).

Упрощенная блок-схема SMP-системы
С одной стороны, эта схема обеспечивает практически одинаковые задержки при доступе к памяти со стороны любого процессора. Но с другой стороны, общая системная шина является потенциальным узким местом всей подсистемы памяти по такому не менее (и даже намного более) важному показателю, как пропускная способность. Действительно, если многопоточное приложение оказывается требовательным к пропускной способности, его производительность будет во многом сдерживаться такой организацией подсистемы памяти.

Упрощенная блок-схема NUMA-системы
В случае NUMA-системы задержки при обращении процессора к «своей» памяти оказываются невысоки (в особенности, по сравнению с SMP-системой). В то же время, доступ к «чужой» памяти, принадлежащей другому процессору, сопровождается более высокими задержками. Понятие «неоднородности» такой организации памяти берет свое начало именно отсюда. Вместе с тем, нетрудно догадаться, что при правильной организации доступа к памяти (когда каждый процессор оперирует данными, находящимися исключительно в «своей» памяти) такая схема будет выгодно отличаться от классического SMP-решения благодаря отсутствию ограничения по пропускной способности общей системной шины. Суммарная пиковая пропускная способность подсистемы памяти в этом случае будет равняться удвоенной пропускной способности используемых модулей памяти.
Однако «правильная организация доступа к памяти» здесь — ключевое и критически важное понятие. Платформы с архитектурой NUMA должны поддерживаться как со стороны ОС (хотя бы для того, чтобы сама система и приложения могли «увидеть» память всех процессоров, как единый блок памяти), так и со стороны приложений. Последние версии Windows XP (SP2) и Windows Server 2003 полностью поддерживают NUMA-системы (для 32-разрядных версий необходимо включение режима Physical Address Extension (ключ /PAE в boot.ini), который, к счастью, для AMD64-платформ включен по умолчанию, поскольку необходим для реализации Data Execution Prevention). Что касается приложений, здесь, прежде всего, имеется в виду нежелательность возникновения ситуации, когда приложение размещает свои данные в области памяти одного процессора, после чего обращается к ним с другого процессора. А как влияет соблюдение или несоблюдение этой рекомендации, мы сейчас и рассмотрим.
Конфигурация тестового стенда и ПО
- Процессоры: 2x Opteron 250, 2.4 ГГц
- Материнская плата: TYAN Thunder K8WE (S2895), BIOS версии 2003Q2 от 03/28/2005
- Чипсет: NVIDIA nForce Professional 2200 & 2050, AMD 8131 PCI-X Tunnel
- Память: 4x Corsair 512MB DDR-400 ECC Registered, 3-3-3-8
- Видео: Leadtek PX350 TDH, nVidia PCX5900
- HDD: WD Raptor WD360, SATA, 10000 rpm, 36Gb
- Драйверы: NVIDIA Forceware 77.72
Результаты исследований
Исследование проводилось в стандартном режиме тестирования подсистемы памяти любой платформы. Измерялись: средняя реальная пропускная способность памяти (ПСП) при операциях простого линейного чтения и записи данных из памяти/в память, максимальная реальная ПСП при операциях чтения (с программной предвыборкой данных, Software Prefetch) и записи (методом прямого сохранения данных, Non-Temporal Store), а также латентность памяти при псевдослучайном и случайном обходе 16-МБ блока данных.
Симметричный режим «2+2», No Node Interleave
Настроек подсистемы памяти в BIOS двухпроцессорной системы AMD Opteron оказалось довольно много. А именно, настраиваются как минимум три параметра (по принципу Disabled/Enabled, или Disabled/Auto), что дает нам общее число вариантов — 8. Это: Node Interleave (чередование памяти между «узлами», то есть интегрированными контроллерами процессоров — замечательная возможность, которую мы подробно рассмотрим ниже), Bank Interleave (классическое чередование доступа к логическим банкам модулей памяти), а также Memory Swizzle (нечто похожее на Bank Interleave, но так до конца и не понятое :)). Поскольку изменение последнего параметра не оказывало ощутимого влияния на результаты тестов, было решено оставить его по умолчанию (Enabled). Остальные параметры варьировались, и в первой серии тестов была выбрана симметричная конфигурация «2+2» (по 2 модуля на каждый процессор), Node Interleave был отключен, а параметр Bank Interleave варьировался между Disabled и Auto (последнее означает, что чередование банков осуществляется в соответствии с характеристиками самого модуля).
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3618 (±3) | 2369 (±2) | 3654 (±5) | 2387 (±2) |
| Средняя реальная ПСП на запись, МБ/с | 1616 (±2) | 1415 (±2) | 2417 (±56) | 1878 (±29) |
| Максимальная реальная ПСП на чтение, МБ/с | 6286 | 3116 | 6344 | 3133 |
| Максимальная реальная ПСП на запись, МБ/с | 5924 | 3032 | 6143 | 3033 |
| Минимальная латентность псевдослучайного доступа, нс | 45.6 | 70.9 | 44.1 | 70.5 |
| Максимальная латентность псевдослучайного доступа, нс | 48.3 | 74.7 | 47.3 | 74.3 |
| Минимальная латентность случайного доступа, нс | 74.7 | 112.3 | 74.7 | 112.3 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.3 | 78.6 | 116.3 |
Таким образом, «неоднородность» подсистемы памяти, о которой мы упоминали в теоретической части — налицо (и, разумеется, не только в терминах латентности, но и ПСП). Что подтверждает необходимость использования не только NUMA-aware OS, но и специально оптимизированных многопоточных приложений, в которых каждый поток самостоятельно выделяет память под свои данные и работает со своей областью памяти. В противном случае (однопоточные приложения и многопоточные, «не задумывающиеся» о правильном с точки зрения NUMA размещении данных в памяти) следует ожидать снижение производительности подсистемы памяти. Рассмотрим это на примере однопоточных приложений, на сегодняшний день по-прежнему представляющих большинство ПО. Известно, что в многопроцессорной системе диспетчер ОС назначает приложениям процессорное время так, чтобы разделить его поровну между всеми имеющимися процессорами (таким образом, в случае двухпроцессорной системы примерно 50% приходится на первый процессор, и 50% — на второй). Таким образом, момент размещения памяти обязательно придется на какой-нибудь из процессоров (например, CPU0), в то время как код приложения, осуществляющий доступ к этим данным, будет исполняться как на CPU0, так и на CPU1. И половину времени подсистема памяти будет работать с полной эффективностью, а половину — со вдвое сниженной, как показывают наши тесты. Поэтому, как это ни странно, эффективность работы с памятью таких приложений можно повысить, принудительно «привязав» их к одному из процессоров (задав Process Affinity), что, в общем-то, сделать не так и сложно.
Несимметричный режим «4+0»
А пока мы решили немного. «удешевить» систему — то есть имитировать ситуацию, преобладающую среди более дешевых двухпроцессорных плат под AMD Opteron, когда модули памяти можно установить всего для одного процессора — для второго процессора такая память принудительно становится «чужой». Собственно, исходя из теоретических предположений, ожидать сильно отличающихся результатов в этом случае явно не стоит — ситуация отличается ровно тем, что у «своего» процессора памяти стало в 2 раза больше, а у «чужого» ее как не было, так и нет. Поэтому приводим мы их исключительно для полноты картины.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 3623 (±5) | 2375 (±2) | 3684 (±33) | 2397 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1611 (±2) | 1418 (±2) | 2090 (±136) | 1932 (±31) |
| Максимальная реальная ПСП на чтение, МБ/с | 6249 | 3128 | 6358 | 3128 |
| Максимальная реальная ПСП на запись, МБ/с | 5878 | 3032 | 6234 | 3032 |
| Минимальная латентность псевдослучайного доступа, нс | 44.3 | 70.6 | 43.9 | 70.0 |
| Максимальная латентность псевдослучайного доступа, нс | 47.6 | 74.4 | 47.1 | 73.7 |
| Минимальная латентность случайного доступа, нс | 74.7 | 111.8 | 77.0 | 111.8 |
| Максимальная латентность случайного доступа, нс | 78.6 | 116.0 | 80.7 | 115.9 |
Симметричный режим «2+2», Node Interleave
Вот мы и добрались до самого интересного момента — решения для обычных приложений, ничего не знающих об архитектуре NUMA. Суть его весьма проста, и заключается она в чередовании памяти по 4-КБ страницам между модулями, находящимися на разных «узлах» (контроллерах памяти). В случае двухпроцессорной системы можно сказать, что все четные страницы «достаются» первому процессору, а все нечетные — второму. В результате получается — независимо от того, на какой из процессоров приходится момент размещения данных в памяти, данные будут размещены поровну в пространстве памяти обоих процессоров. И независимо от того, на каком из процессоров исполняется код, половина обращений к памяти будет относиться к «своей» памяти, а половина — к «чужой». Что же, посмотрим, как это проявляет себя на практике.
| Характеристика | No Bank Interleave | Bank Interleave = Auto | ||
|---|---|---|---|---|
| CPU 0 | CPU 1 | CPU 0 | CPU 1 | |
| Средняя реальная ПСП на чтение, МБ/с | 2893 (±3) | 2890 (±3) | 2899 (±5) | 2914 (±3) |
| Средняя реальная ПСП на запись, МБ/с | 1897 (±20) | 1895 (±20) | 2065 (±34) | 2070 (±34) |
| Максимальная реальная ПСП на чтение, МБ/с | 4211 | 4217 | 4220 | 4231 |
| Максимальная реальная ПСП на запись, МБ/с | 4029 | 4026 | 4029 | 4025 |
| Минимальная латентность псевдослучайного доступа, нс | 57.5 | 58.0 | 57.4 | 58.0 |
| Максимальная латентность псевдослучайного доступа, нс | 60.5 | 60.2 | 60.4 | 60.0 |
| Минимальная латентность случайного доступа, нс | 94.5 | 94.3 | 94.5 | 94.2 |
| Максимальная латентность случайного доступа, нс | 96.3 | 96.0 | 96.6 | 95.9 |
Заключение
| Платформа | Пиковая пропускная способность подсистемы памяти, ГБ/с (двухканальная DDR-400) | |||
|---|---|---|---|---|
| Однопоточное приложение | Несколько однопоточных приложений | Многопоточное приложение | NUMA-aware многопоточное приложение | |
| SMP | 6.4 | 6.4 | 6.4 | 6.4 |
| Несимметричная NUMA | 4.2 (6.4 * ) | 6.4 | 6.4 | 6.4 |
| Симметричная NUMA | 4.2 (6.4 * ) | 8.4 (12.8 * ) | 6.4 | 12.8 |
| Симметричная NUMA, Node Interleave | 4.2 | 8.4 | 8.4 | 8.4 |
* в случае «привязки» приложения к одному из процессоров
Недорогие, несимметричные NUMA-системы выглядят не многим лучше, а то и хуже традиционных SMP-систем. Хуже — в случае однопоточных приложений, если их не «привязывать» к тому процессору, который обращается с памятью. Пиковая ПСП во всех остальных случаях здесь также ограничена цифрой 6.4 ГБ/с — то есть пропускной способностью единственного имеющегося в системе интерфейса памяти.
Симметричные NUMA-системы практически во всех случаях обладают преимуществом как над SMP, так и несимметричными NUMA-системами. Достигнуть пиковой ПСП 12.8 ГБ/с на таких платформах могут либо специальные NUMA-оптимизированные приложения, либо. два обычных, однопоточных приложения, «раскиданных» каждое по своему процессору.
Современные серверные решения на базе архитектуры x86, которые сейчас используются почти во всех программно-аппаратных комплексах, имеют некоторые нюансы. Многопроцессорные сервера, имеющие на материнской плате 2, 4 или даже 8 процессорных сокетов, являются по сути NUMA-архитектурой. NUMA (Non-Uniform Memory Architecture) означает, что каждый процессорный сокет имеет свой пул локальных модулей оперативной памяти и такая связка называется узлом NUMA (рис. 1).
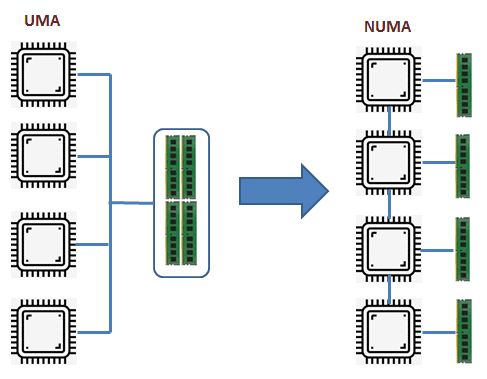 |
| Рис. 1. UMA и NUMA архитектуры. |
Все процессорные ядра и вся оперативная память объединены в одну систему, но обращение процессора к своим (локальным) модулям памяти происходит с большей скоростью (или меньшими задержками), чем к памяти соседнего процессора.
Все современные операционные системы и программные решения более высокого уровня (например, виртуальный гипервизор или СУБД) понимают особенности этой архитектуры. В идеале, это понимание позволяет большинство операций выполнять с памятью локального процессора, не ходя в "дальние края" за памятью соседа.
vSphere от VMware тоже прекрасно разбирается в NUMA. При конфигурировании виртуальной машины (если вы не активируете опцию "Enable CPU Hot Add") и при её работе гипервизор будет размещать виртуальные процессорные ядра (vCPU) и память виртуальной машины в один узел NUMA. Причём, эта функция работает по умолчанию, ничего отдельно настраивать не надо.
Это всё прекрасно работает для небольших виртуальных машин, которые занимают гораздо меньше памяти, чем имеется в одном узле NUMA. Для работы большого количества таких относительно небольших виртуальных машин на одном сервере решения виртуализации и были прежде всего разработаны. Но у нас немного другой профиль - SAP системы, которые обычно требуют много ресурсов процессора и памяти.
Хочу на своём примере показать недостаточно корректную настройку размера виртуальных машин, с учётом NUMA архитектуры. На проекте, про который хочу рассказать, были сервера двух типов:
- 4-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 384 Гб оперативной памяти,
- 2-х сокетный сервер (8 ядер/16 потоков в каждом процессоре) и 256 Гб оперативной памяти.
Понимая, всю ситуацию с NUMA архитектурой я разместил на серверах первого типа виртуальные машины с характеристиками:
- 16 vCPU + 192 Гб памяти,
- 8 vCPU + 96 Гб памяти.
Но после прокачки своих знаний по VMware, мне открылось, что я совершил ошибку при конфигурации объёмов памяти.
Для мониторинга работы виртуальных машин на узлах ESXi есть команда esxtop (аналог команды top в Linux) (рис. 2). Так вот, для мониторинга работы с памятью и NUMA диагностики, необходимо запустить команду esxtop , нажать "m", перейдя в мониторинг памяти. После этого нажать "f" и добавить к формату вывод статистику по NUMA (рис. 3).
 |
| Рис. 2. Основной экран утилиты esxtop. |
 |
| Рис. 3. Активация просмотра статистики по NUMA узлам. |
После этого на экране появится несколько важных полей:
- NHN - текущий домашний узел для виртуальной машины,
- NMIG - количество NUMA миграций с узла на узел,
- NRMEM (MB) - текущее количество "дальней памяти" (из соседней NUMA), используемой виртуальной машиной,
- NLMEM (MB) - текущее количество локальной памяти, используемой виртуальной машиной,
- N%L - текущий процент запрошенной виртуальной машиной памяти, являющейся локальной.
Последний параметр помогает проанализировать итог работы виртуальной машины на NUMA узлах. Если он равен 100%, значит производительность оптимальна. Если же ниже 100%, значит не всегда в процессе работы на реальных процессорных ядрах для текущей виртуальной машины идёт попадание в память локального узла NUMA.
По моей ситуации. Первые две большие виртуальные машины не всегда попадают в память локального NUMA узла (рис. 4 и 5). Напомню, что обе машины работают на серверах с размером узла NUMA = 16 ядер (с учётом HT) + 96 Гб.
 |
| Рис. 4. Статистика по NUMA виртуальной машины 8 vCPU + 96 Гб. |
 |
| Рис. 5. Статистика по NUMA виртуальной машины 16 vCPU + 192 Гб. |
Процент попадания в локальный NUMA узел 93% и 92% соответственно. Причём, если посмотреть по другим параметрам статистики: виртуальной машине при работе не хватает всего 6-7 Гб памяти на локальном узле.
"Небольшие" виртуальные машины, работающие на серверах второго типа (с размером узла NUMA = 16 ядер (с учётом HT) + 128 Гб памяти), отлично умещаются в локальных NUMA узлах (рис. 6). Забора "чужой" памяти нет, всё работает оптимально.
 |
| Рис. 6. Статистика по NUMA виртуальной машины, работающей на сервере второго типа. |
Максим Мошков рекомендует пользоваться правилом при конфигурировании любых ресурсов в среде VMware - 80% ресурсов можно использовать, а 20% всегда оставлять на запас, накладные расходы и тому подобное.
Если у меня будет возможность, то я переконфигурирую данные виртуальные машины, которые не оптимально попадают в узлы NUMA. И потом поделюсь с вами результатами статистики.
Читайте также: