
Не выключается виртуальная машина vmware workstation
Обновлено: 04.07.2024
Добрый день всем жителям.
Ну вот возвращаемся к прежней теме.
Были произведены следующие работы:
1.Обновлен vCenter до последнего обновления для 6.0
2. Обновлен хост с зависающим сервером до версии vmware 6.0 U3 от 09,2019
3. Обновлены Firmware на железо сервера в частности: Bios, дискового контроллера, iLo
Но прошивку дискового контроллера пришлось вернуть прежнюю, по причине не понятной после обновления прошивки система не хотела видеть 5 дисков из 24 (и соответственно не стартовали виртуальные машины.)
после обновления сервер проработал 17 дней в нормальном режиме, все было отлично, хотел уже сюда отписаться что все работает, НО.
тут пришел нежданчик, опять мертвое зависание виртуалки на хосте и опять что бы виртуалку оживить пришлось грузить весть хост через iLo.
файлик vmkernel.log прилагаю, сам смотрел его - походу система ругается на тот же диск что и раньше.
Подскажите направление пожалуйста. возможно такое что при обновлении хоста не все драйвера обновились или в обновлении не было каких то конкретных обновлений. Обновлялся с кустомной сборки для серверов HP от 09/2019
e_espinel- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Если при обновлении Firmware контроллера система не хотела видеть 5 из 24 дисков. Скорее всего, это будет про уровень Firmware этих 5 дисков. Важно также обновить Firmware всех дисков.
Важно знать p/n дисков, потому что у некоторых есть серьезные проблемы из-за Firmware. производители часто публикуют оповещения об этих проблемах на дисках.
Вы можете указать, какие диски или исправления (Array) формируют устройство (device) naa.50014ee20bc88943, на котором больше всего ошибок в log (журнале).
Enrique EspinelSenior Technical Support IBM, Lenovo and VMware vSphere.
VMware VSP-SV, VTSP-SV, VTSP-HCI
VMware VTSP 4, VTSP 5.
Please mark my comment as the Correct Answer/Kudos if this solution resolved your problem Thank you.
Пожалуйста, отметьте мой комментарий как "Правильный ответ/Кудос", если это решение решило вашу проблему. Спасибо. Aleks_UPNK2019
- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Добрый день. в том то и дело что я не знаю как определить какой физически диск соответствует device naa.50014ee20bc88943. На данный момент ищу информацию как это узнать. Может кто из форумчан подскажет как определить соответствие физического диска с naa устройством.
Finikiez- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Команда esxcli storage core device list -d naa.50014ee20bc88943 может показать производителя и s/n диска
Но есть подозрение, что дело в физике (в частности контроллер), потому что непонятно почему после обновления FW у вас перестали видеться диски.
Прикрепленный лог работы смогу посмотреть чуть позже.
Finikiez- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Вот список ваших дисков
2019-12-17T18:17:36.357Z cpu7:33141)<4>hpsa 0000:09:00.0: hpsa_update_device_info: dev id inquiry succeeded after 1 retries scsi 1:0:0:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=0 qd=0
2019-12-17T18:17:36.357Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:1:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.359Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:2:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.361Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:3:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.362Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:4:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.404Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:5:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.407Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:6:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.410Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:7:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.414Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:8:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.470Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:9:0: Direct-Access ATA WDC WD40PURZ-85T PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.502Z cpu8:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:10:0: Direct-Access ATA WDC WD40PURZ-85T PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.553Z cpu8:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:11:0: Direct-Access ATA WDC WD40PURZ-85T PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.557Z cpu8:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:12:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.595Z cpu8:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:13:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.598Z cpu8:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:14:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.602Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:15:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.651Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:16:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.654Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:17:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.657Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:18:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.661Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:19:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.664Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:20:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.716Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:21:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.773Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:22:0: Direct-Access ATA WDC WD40PURZ-85T PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:36.817Z cpu9:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:23:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
Плюс у вас явные проблемы с производительностью.
2019-12-12T08:06:21.990Z cpu2:32797)WARNING: ScsiDeviceIO: 1243: Device naa.600508b1001c673d5d4a3c8b8668b8d4 performance has deteriorated. I/O latency increased from average value of 17217 microseconds to 347104 microseconds.
2019-12-12T08:06:39.714Z cpu2:32797)WARNING: ScsiDeviceIO: 1243: Device naa.600508b1001c673d5d4a3c8b8668b8d4 performance has deteriorated. I/O latency increased from average value of 17386 microseconds to 347993 microseconds.
2019-12-12T08:06:41.067Z cpu4:32799)WARNING: ScsiDeviceIO: 1243: Device naa.600508b1001c673d5d4a3c8b8668b8d4 performance has deteriorated. I/O latency increased from average value of 17411 microseconds to 350987 microseconds.
2019-12-12T08:15:25.383Z cpu4:33166)ScsiDeviceIO: 1217: Device naa.600508b1001c673d5d4a3c8b8668b8d4 performance has improved. I/O latency reduced from 350987 microseconds to 69372 microseconds.
2019-12-12T08:31:03.067Z cpu4:37480)ScsiDeviceIO: 1217: Device naa.600508b1001c673d5d4a3c8b8668b8d4 performance has improved. I/O latency reduced from 69372 microseconds to 34600 microseconds.
2019-12-12T09:20:11.035Z cpu5:37484)ScsiDeviceIO: 2636: Cmd(0x43b5802dc780) 0x85, CmdSN 0x142cc from world 34383 to dev "naa.600508b1001c504e14c7a0db17c4899e" failed H:0x0 D:0x2 P:0x0 Valid sense d
Я правильно же вас понял, что у вас каждый диск представляет отдельный датастор и никакого RAID нет?
Aleks_UPNK2019- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
в самом сервере стоит 8 дисков и они в райд.
к серверу присоединено 2 дисковых полки по 12 дисков в каждой и они проброшены(phisical RDM) в две виртуальные машины на этом хосте.
Судя по логам вот с одним из RDM дисков и начинаются проблемы(предположительно с naa.50014ee20bc88943).
а вот naa.600508b1001c504e14c7a0db17c4899e и naa.600508b1001c673d5d4a3c8b8668b8d4 это как я понял два массива сформированых из 8 дисков сервера.
Были произведены действия:
1. обновление vCenter до 3j обновления от 09.2019
2. обновление хоста с зависающем сервером до версии 3j от 09.2019
3. обновление iLo на сервере где работает зависающая VM
при обновлении хоста и vCenter применялась сборка для серверов HP Gen9
Finikiez- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
если можете, прикрепите полный лог бандл с хоста (vm-support) и укажите имя проблемной ВМ
Так проще посмотреть.
Aleks_UPNK2019- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
Бандл слишком большой поэтому выложил на файлообменник. вот ссылка VMware-vCenter-support-2019-12-23@15-23-09.zip — Yandex.Disk
имя проблемной машины vm-video.
Finikiez- Mark as New
- Bookmark
- Subscribe
- Mute
- Email to a Friend
На мой взгляд далее нужно двигаться в сторону физики.
17 декабря проблема началась с выполнения SCSI команд в сторону первого диска в полке, потом полезли и все остальные
2019-12-17T16:59:43.201Z cpu11:32806)NMP: nmp_ThrottleLogForDevice:3302: Cmd 0x8a (0x43b986c846c0, 37480) to dev "naa.50014ee20bc88943" on path "vmhba2:C2:T1:L0" Failed: H:0xb D:0x0 P:0x0 Possible sense data: 0x6 0x29 0x0. Act:NONE
2019-12-17T16:59:43.201Z cpu11:32806)ScsiDeviceIO: 2613: Cmd(0x43b986c846c0) 0x8a, CmdSN 0x80000002 from world 37480 to dev "naa.50014ee20bc88943" failed H:0xb D:0x0 P:0x0 Possible sense data: 0x6 0x29 0x0.
2019-12-17T16:59:51.187Z cpu2:33151)<4>hpsa_ciss_submit:No SG list to reset.
2019-12-17T18:16:02.224Z cpu6:33028)NMP: nmp_ThrottleLogForDevice:3302: Cmd 0x12 (0x43b9802e8ac0, 0) to dev "naa.50014ee20bc88943" on path "vmhba2:C2:T1:L0" Failed: H:0x5 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0. Act:EVAL
2019-12-17T18:16:02.224Z cpu6:33028)WARNING: NMP: nmp_DeviceRequestFastDeviceProbe:237: NMP device "naa.50014ee20bc88943" state in doubt; requested fast path state update.
2019-12-17T18:16:02.224Z cpu6:33028)ScsiDeviceIO: 2652: Cmd(0x43b9802e8ac0) 0x12, CmdSN 0x8e5c3 from world 0 to dev "naa.50014ee20bc88943" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0.
2019-12-17T18:16:42.216Z cpu2:1033976)<4>hpsa 0000:09:00.0: hpsa_slave_alloc: dev link is NULL for hpsa1 C1:B2:T1:L1.
2019-12-17T18:16:42.217Z cpu0:1014527)VMW_SATP_LOCAL: satp_local_updatePathStates:463: Failed to update path "vmhba2:C2:T1:L0" state. Status=Transient storage condition, suggest retry
2019-12-17T18:16:42.226Z cpu6:33028)ScsiDeviceIO: 2652: Cmd(0x43b9802e8ac0) 0x12, CmdSN 0x8e5cc from world 0 to dev "naa.50014ee20bc88943" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0.
2019-12-17T18:16:43.224Z cpu7:33141)<6>hpsa 0000:09:00.0: queue_depth updated. scsi 1:2:0:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:16:52.213Z cpu5:33194)NMP: nmp_ResetDeviceLogThrottling:3446: last error status from device naa.50014ee20bc88943 repeated 1 times
2019-12-17T18:17:28.502Z cpu5:37480)VSCSI: 2595: handle 8206(vscsi0:12):Reset request on FSS handle 33884765 (7 outstanding commands) from (vmm0:vm-video)
2019-12-17T18:17:28.503Z cpu6:37513)VSCSI: 2873: handle 8206(vscsi0:12):Reset [Retries: 0/0] from (vmm0:vm-video)
2019-12-17T18:17:28.503Z cpu7:37513)WARNING: NMP: nmpDeviceTaskMgmt:2288: Attempt to issue lun reset on device naa.50014ee20bc88943. This will clear any SCSI-2 reservations on the device.
2019-12-17T18:17:28.503Z cpu7:37513)NMP: nmp_ThrottleLogForDevice:3302: Cmd 0x88 (0x43b985446240, 37480) to dev "naa.50014ee20bc88943" on path "vmhba2:C2:T1:L0" Failed: H:0x8 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0. Act:EVAL
2019-12-17T18:17:28.503Z cpu7:37513)WARNING: NMP: nmp_DeviceRequestFastDeviceProbe:237: NMP device "naa.50014ee20bc88943" state in doubt; requested fast path state update.
2019-12-17T18:17:28.503Z cpu7:37513)ScsiDeviceIO: 2613: Cmd(0x43b985446240) 0x88, CmdSN 0x80000019 from world 37480 to dev "naa.50014ee20bc88943" failed H:0x8 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0.
2019-12-17T18:17:28.503Z cpu7:37513)<6>hpsa 0000:09:00.0: physical_reset scsi 1:2:1:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=1 qd=10
2019-12-17T18:17:31.214Z cpu11:32947)VSCSI: 2998: Retry 0 on handle 8206 still in progress after 3 seconds
2019-12-17T18:17:31.504Z cpu5:37480)WARNING: VSCSI: 3711: handle 8206(vscsi0:12):WaitForCIF: Issuing reset; number of CIF:1
2019-12-17T18:17:31.504Z cpu5:37480)WARNING: VSCSI: 2632: handle 8206(vscsi0:12):Ignoring double reset
2019-12-17T18:17:36.335Z cpu7:33141)<4>hpsa 0000:09:00.0: aborted: NULL_SDEV_PTR TYPE:ioctl: TAG:0x00000000:00000330 LUN:0000000000801101 CDB:12010000040000000000000000000000
2019-12-17T18:17:36.357Z cpu7:33141)<4>hpsa 0000:09:00.0: hpsa_update_device_info: dev id inquiry succeeded after 1 retries scsi 1:0:0:0: Direct-Access ATA WDC WD40EFRX-68W PHYS DRV SSDSmartPathCap- En- Exp=0 qd=0
naa.50014ee20bc88943 - это первый диск в вашей полке
Display Name: ATA Serial Attached SCSI Disk (naa.50014ee20bc88943)
Has Settable Display Name: true
Device Type: Direct-Access
Multipath Plugin: NMP
Devfs Path: /vmfs/devices/disks/naa.50014ee20bc88943
Model: WDC WD40EFRX-68W
Runtime Name: vmhba2:C2:T1:L0
Device Display Name: ATA Serial Attached SCSI Disk (naa.50014ee20bc88943)
Он же подключен как 41 диск к ВМ
Disk vm-video_41.vmdk is a Passthrough Raw Device Mapping
Maps to: vml.020000000050014ee20bc88943574443205744
Попробуйте его просто поменять. Затем надо разобраться, почему при обновлении FW контроллера не видны диски. Возможно эта проблема уйдет, если нет, то я бы уточнил в технической поддержке HPE этот момент. Либо гуглить и читать release notes к адаптеру.
Плюс еще идея, почему диски не видны после обновления FW контроллера - сама несовместимость прошивки на самих дисках. Потому что у вас есть диски разных типов
VMware Power-Off-Evmware Невозможно выключить виртуальную машину Busy - процесс VMware-VMX.exe Невозможно заканчиваться (отклонение доступа) - решение
оглавление
Система Win10, VMware установлена на виртуальной машине, в первый раз вы можете нормально запустить, когда компьютер перезапускается, VMware включен.
Попробуйте закрыть VMware, не в состоянии выключить, подскажите виртуальную машину занятую.
Менеджер задач напрямую заканчивает основную программу и может закончиться. Затем снова открывайте VMware, на виртуальной машине, ложной смерти, и невозможно отключить. Отказ Отказ
Win10_1903 версия версии

VMware® Workstation 15 Pro
Следующий рисунок - это сеть, чтобы взять:

1. Попробуйте закрыть виртуальную машину напрямую.
Подскажите виртуальную машину занятую и не могут быть закрыты напрямую. Непосредственно на диспетчере задач и End VMware. Это можно отключить.
Решение онлайн-партнера это:
Еще раз закройте главную программу VMware, я обнаружил, что VMware WorkStation VMX.EXE существует. Хорошо, попробуйте закрыть его.
2, попробуйте диспетчер задач, чтобы закрыть рабочую станцию VMware VMX.exe
Откройте диспетчер задач, щелкните правой кнопкой мыши. Совет отказывается посетить

ОК, привилегии администратора, откройте CMD, попробуйте использовать команду tskill, все еще отказавшись.
(Если ваш хост может закончить этот процесс, поздравить, открывайте VMware, вы должны иметь определенный шанс начать виртуальную машину.)
3, Win10 и VMware совместимость
Эта проблема связана с конфликтом между версией Win10 1903 года и VMware. Обновление или замена VMware 15.1, а затем позже вы можете решить его.
Описание проблемы
The virtual machine might be performing concurrent operations. Actions: Complete the concurrent operation and retry the power-off operation. The virtual machine is in an invalid state. Virtual machines can enter an invalid state for many reasons.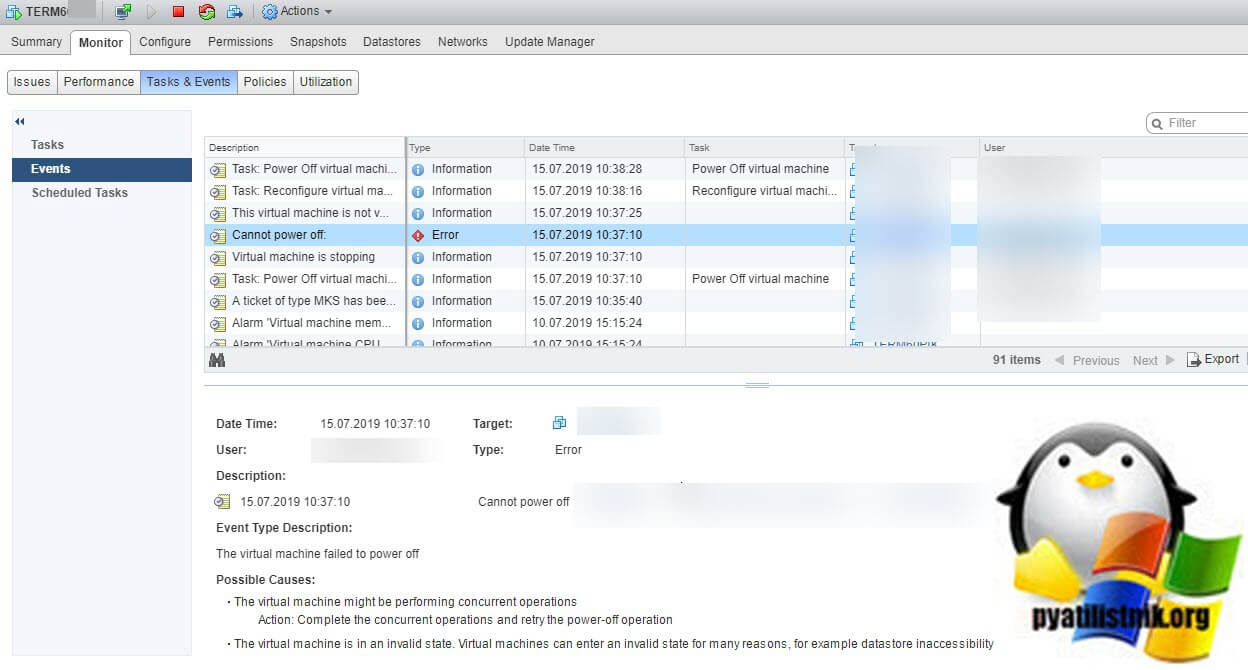
При попытке мигрировать виртуальную машину вы может получить ошибку:
Failed to migrate the virtual machine for reasons described it the event message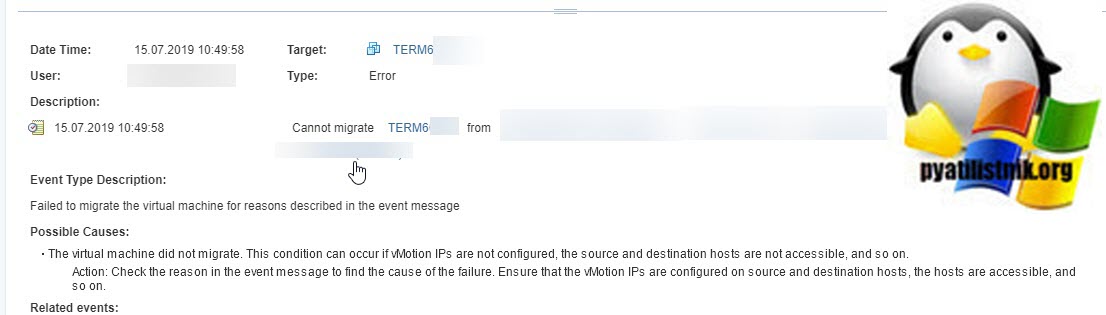
Так же вы можете увидеть ошибку при попытке, выключить или перезапустить виртуалку:
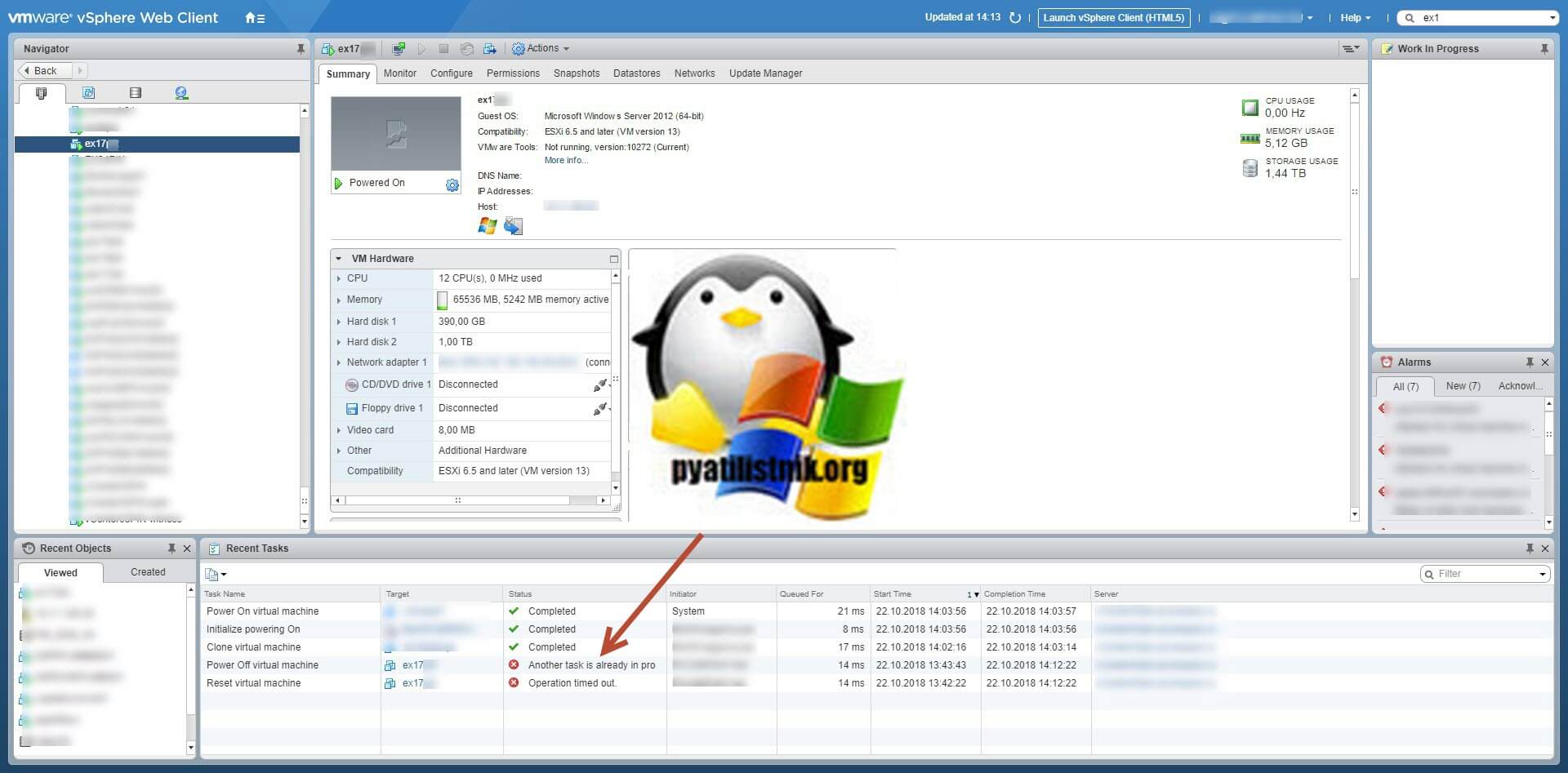
Во всех случаях вам скажут, что данная виртуальная машина имеет некий процесс, который в данный момент не дает выполнить ваши повторные действия. Так же данная виртуалка у меня была членом RDS фермы, при попытке перевода его в режим стока (Drain-Mode) я получил ошибку "Не удалось изменить состояние подключения для сервера".
Как перезапустить зависшую виртуальную машину
Сразу хочу отметить, что если в графическом интерфейсе у вас не выходит, что либо сделать, то у вас остается только командная строка ssh. Включаем на ESXI хосте SSH службу. Далее подключаемся через Putty или MremoteNG. Я подключаюсь через MremoteNG. Первое, что вам необходимо сделать, это как посмотреть список активных процессов, все как в Windows. Для этого есть команда:
В моем примере, я вижу свою виртуальную машину TERM6. Если системные процессы мозолят вам глаза, то вы можете одновременно нажать SHIFT+V, что оставит отображение только виртуальных машин.
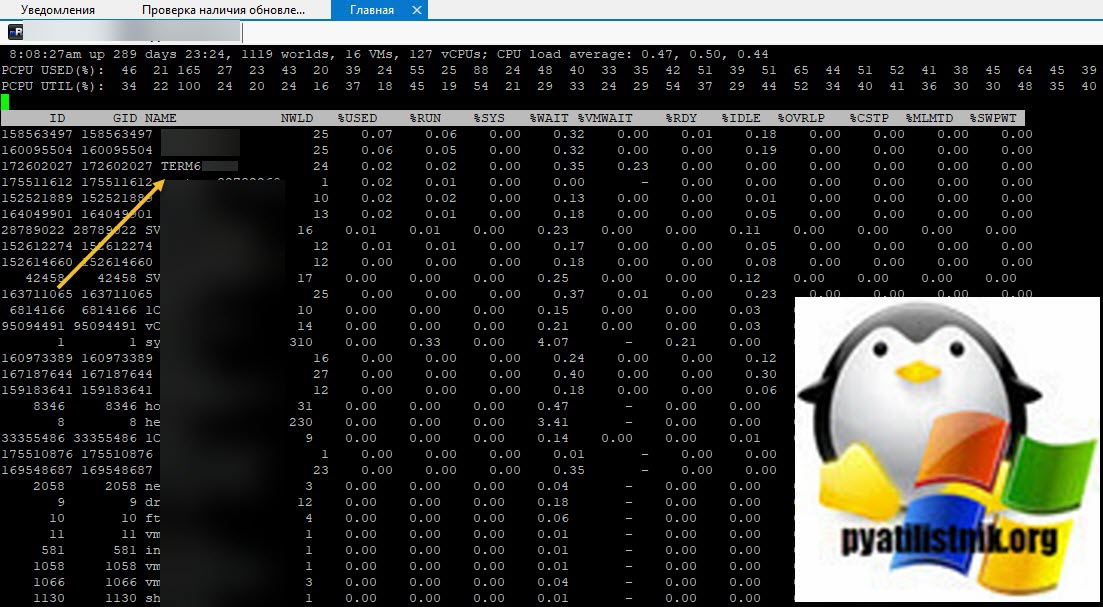
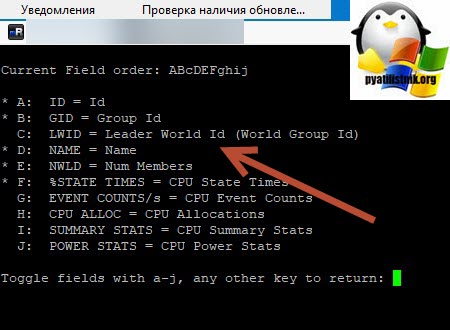
Теперь нам нужно вычислить LWID - Leader World Id, завершив который вы завершите работу нужной виртуалки. ПО умолчанию LWID не отображается, чтобы его включить нажмите клавишу F. У вас откроется меню, где можно добавлять или скрывать поля. Видим, что если нажать клавишу "C", то у вас будет добавлен LWID- Leader World Id. Нажимаем "C" и "Enter".
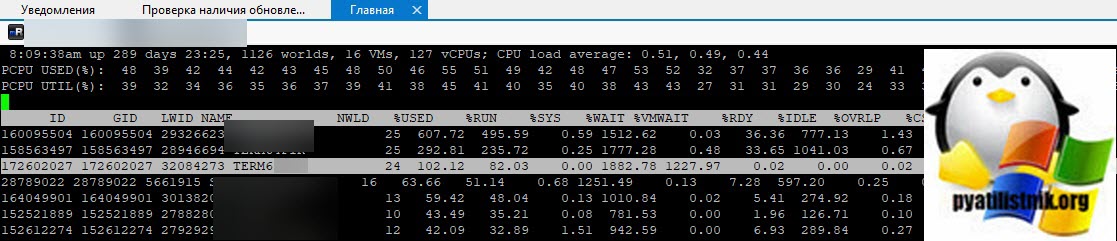
Теперь зная LWID, нажмите клавишу "K", она вызовет меню "World to kill (WID)", данная операция поможет принудительно завершить процесс LWID. Вбиваем наш LWID и нажимаем "Enter".
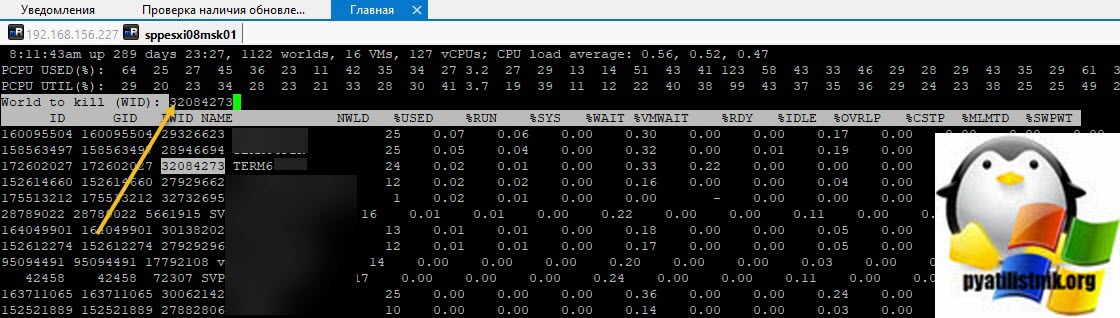
Тут у вас два варианта, чудо произошло (80% вероятности) и чудо не произошло, часто бывает в случаях с ошибкой "Another task is already in progress"
Кстати World ID можно вычисли и просто введя команду:
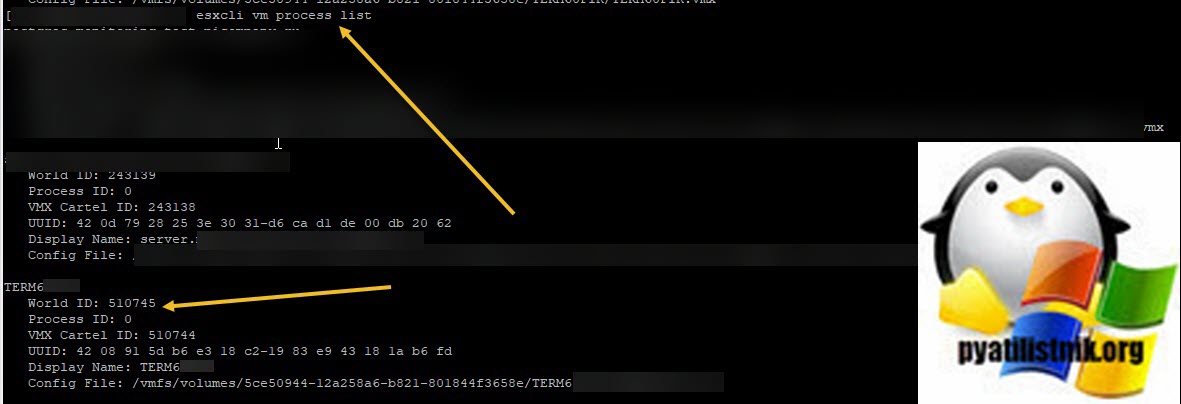
Там вы сможете увидеть World ID, после чего его можно убить командой:
В моем случае чудо произошло, виртуалка перешла в состояние Power OFF, я это вижу в Power-CLI.
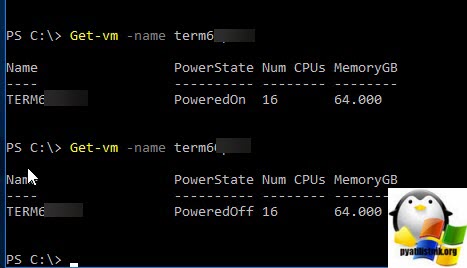
Если принудительное завершение процесса вам не помогло, то делаем вот что, по возможности мигрируйте все остальные виртуальные машины с данного хоста, у вас из-за ошибки останется только сбойная. Все в том же SSH. введите:
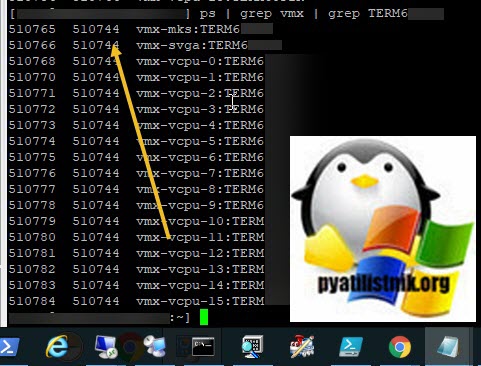
В итоге у вас будет выведен список, где первая колонка это PID процесса, вторая PID родительского процесса, убиваем его для вашей виртуальной машины.
После чего пишем kill PID-родительского процесса. Если не помогло, то пробуем выполнить вот, что (по возможности перевезите другие сервера с данного хоста на другие хосты)
В результате действий хост стал работать нормально, единственное может быть ситуация, что виртуалку придется удалить из inventory и добавить заново. Если и это не помогло, то попробуйте выполнить:
/etc/ init . d / hostd restart && /etc/ init . d / vpxa restartВисит задача create virtual machine snapshot
Еще в своей практике встречал ситуации, что из-за незаконченного задания у меня не выполнялось резервное копирование, задание висело со статусом "create virtual machine snapshot"

Описание проблемной виртуальной машины
Как я и писал выше, виртуальная машина намертво зависла, по RDP или ping она была не доступна. Гостевой операционной системой была Windows Server 2012 R2. Попытавшись запустить Web Console из интерфейса vCenter Server, виртуальная машина ни на что не реагировала.

Диагностика зависшей виртуальной машины
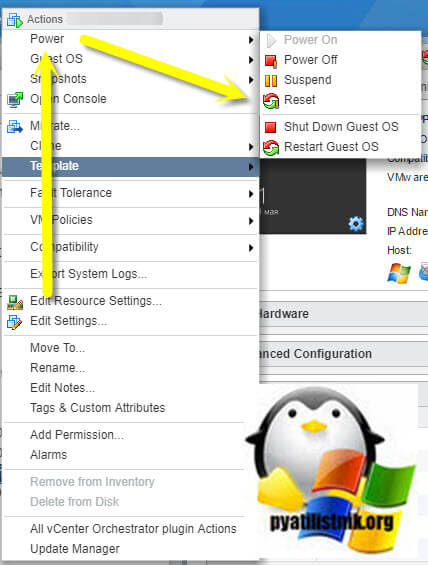
Первым делом, чтобы восстановить сервис, вам необходимо принудительно перезагрузить виртуальную машины, для этого щелкните по ней правым кликом мыши и выберите пункт "Power - Reset".
После того, как операционная система в ней загрузится, я вам советую начать изучение логов Windows. Открываем просмотр событий и делаем поиск ошибок и предупреждений. Мне удалось найти два события, которые косвенно говорили, что проблема с зависанием виртуальной машины связана непосредственно с операционной системой и возможными проблемами с поврежденными системными файлами или драйверами Vmware Tools. Первое событие:
Event ID 11: The driver detected a controller error on \Device\RaidPort0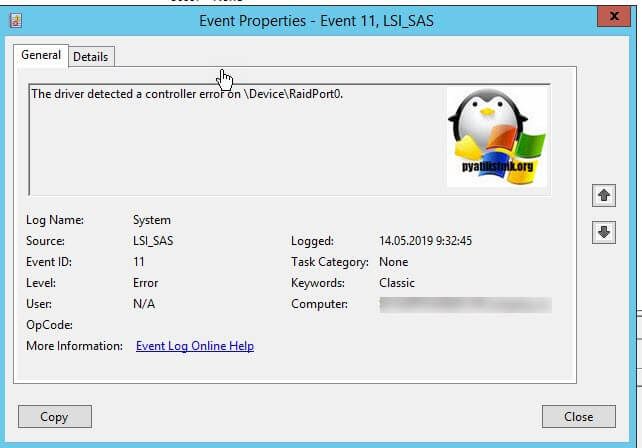

Так же можно обнаружить и ошибки вот такого рода, которые так же заставляю виртуальную машину флапать, зависать с черным экраном.
Код события ID 27 Intel(R) 82574L Gigabit Network ConnectionNetwork link is disconnected.
Данное событие связано с сетевым интерфейсом типа E1000, советую его поменять на паравиртуализованный VMXNET3. E1000 кушает больше ресурсов процессорных мощностей и так же более капризный, но за то не требует установки Vmware Tools.

Так же вы можете посмотреть логи самой виртуальной машины на уровне Vmware ESXI 6.5. Я нашел там вот такую выборку:
2019-05-14T11:06:41.739Z| vmx| I125: GuestMsg: Channel 0, Cannot unpost because the previous post is already completed2019-05-14T11:08:48.012Z| svga| I125: MKSScreenShotMgr: Taking a screenshot
2019-05-14T11:08:53.849Z| mks| I125: SOCKET 1396535 (189) Creating VNC remote connection.
2019-05-14T11:08:53.849Z| mks| I125: MKSControlMgr: New VNC connection 1
2019-05-14T11:08:53.912Z| mks| W115: VNCENCODE 1396535 failed to allocate VNCBlitDetect
2019-05-14T11:08:53.912Z| mks| I125: VNCENCODE 1396535 VNCEncodeChooseRegionEncoder: region encoder adaptive. Resolution: 1024 x 768
2019-05-14T11:08:54.289Z| vmx| I125: Tools_SetGuestResolution: Sending rpcMsg = Resolution_Set 1920 863
2019-05-14T11:08:54.630Z| vcpu-7| I125: VMMouse: CMD Read ID
2019-05-14T11:09:54.289Z| vmx| I125: GuestRpcSendTimedOut: message to toolbox timed out.
2019-05-14T11:10:07.476Z| svga| I125: MKSScreenShotMgr: Taking a screenshot
2019-05-14T11:10:19.546Z| mks| I125: SOCKET 1396535 (189) recv error 0: Success
2019-05-14T11:10:19.546Z| mks| I125: SOCKET 1396535 (189) VNC Remote Disconnect.
2019-05-14T11:10:19.546Z| mks| I125: MKSControlMgr: Remove VNC connection 1
2019-05-14T11:10:31.357Z| vmx| I125: VigorTransportProcessClientPayload: opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571570: Receiving Sched.SetResourceGroup request.
2019-05-14T11:10:31.357Z| vmx| I125: VigorTransport_ServerSendResponse opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571570: Completed Sched request.
2019-05-14T11:10:31.358Z| vmx| I125: VigorTransportProcessClientPayload: opID=HardPowerOpsResolver-applyOnMultiEntity-5384149-ngc:70276545-fb-c5-9d61 seq=2571571: Receiving PowerState.InitiateReset request.
2019-05-14T11:10:31.358Z| vmx| I125: Vix: [8790361 vmxCommands.c:686]: VMAutomation_Reset. Trying hard reset
2019-05-14T11:10:31.358Z| vmx| W115:
2019-05-14T11:10:31.358Z| vmx| W115+
2019-05-14T11:10:31.358Z| vmx| W115+ VMXRequestReset
2019-05-14T11:10:31.358Z| vmx| I125: Vigor_Reset: Attaching to reset.
2019-05-14T11:10:31.358Z| vmx| I125: Stopping VCPU threads.
2019-05-14T11:10:31.360Z| vcpu-0| I125: VMMon_WaitForExit: vcpu-0: worldID=9507337
2019-05-14T11:10:31.360Z| vcpu-7| I125: VMMon_WaitForExit: vcpu-7: worldID=9507347
2019-05-14T11:10:31.360Z| vcpu-3| I125: VMMon_WaitForExit: vcpu-3: worldID=9507343
2019-05-14T11:10:31.360Z| vcpu-1| I125: VMMon_WaitForExit: vcpu-1: worldID=9507341
2019-05-14T11:10:31.360Z| vcpu-5| I125: VMMon_WaitForExit: vcpu-5: worldID=9507345
2019-05-14T11:10:31.360Z| vcpu-10| I125: VMMon_WaitForExit: vcpu-10: worldID=9507350
2019-05-14T11:10:31.360Z| vcpu-9| I125: VMMon_WaitForExit: vcpu-9: worldID=9507349
2019-05-14T11:10:31.360Z| vcpu-8| I125: VMMon_WaitForExit: vcpu-8: worldID=9507348
2019-05-14T11:10:31.360Z| vcpu-6| I125: VMMon_WaitForExit: vcpu-6: worldID=9507346
2019-05-14T11:10:31.360Z| vcpu-4| I125: VMMon_WaitForExit: vcpu-4: worldID=9507344
2019-05-14T11:10:31.360Z| vcpu-2| I125: VMMon_WaitForExit: vcpu-2: worldID=9507342
2019-05-14T11:10:31.360Z| vcpu-11| I125: VMMon_WaitForExit: vcpu-11: worldID=9507351
2019-05-14T11:10:31.360Z| svga| I125: SVGA thread is exiting
2019-05-14T11:10:31.360Z| vmx| I125: MKS thread is stopped
2019-05-14T11:10:31.361Z| vmx| I125:
2019-05-14T11:10:31.361Z| vmx| I125+ OvhdMem: Final (Power Off) Overheads
Алгоритм действий и возможные причины зависания
- Первое, что я вам советую сделать, это избавится от ошибки "Vmware Tools is outdated on this virtual machine" путем обновления Vmware Tools. Напоминаю, что это сделать можно из меню "Guest OS - Update Vmware Tools". Потребуется перезагрузка виртуальной машины.
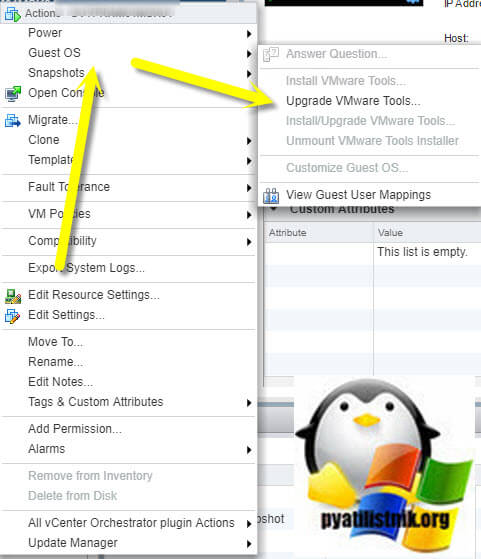
- Следующим пунктом, я вам советую проверить операционную систему на предмет повреждения системных файлов, сделать это просто. Запустите cmd от имени администратора или откройте Power Shell, кому что привычнее и введите команду:
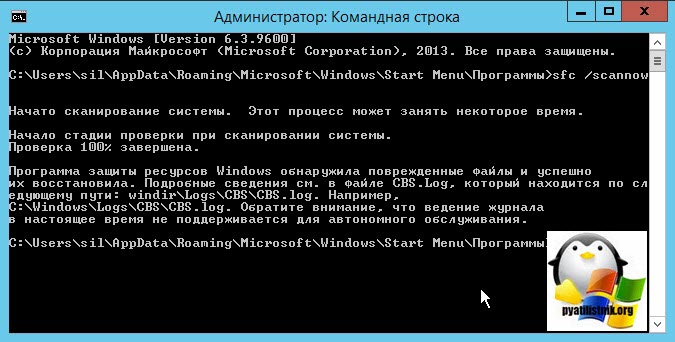
Если ошибки не были устранены, то советую выполнить команду:
Утилита DISM обратится к внешним репозиториям Microsoft и скачает от туда валидные файлы, чтобы восстановить аналогичные в вашей системе. Процесс так же может занимать некоторое время. Как видим:
Восстановление выполнено успешно. Повреждение хранилище компонентов было устранено. Операция успешно завершена.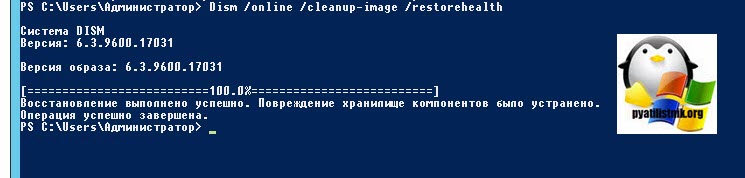
Еще одним пунктом диагностики проблем с ошибками ID 111 и ID 129, я вам советую выполнить сканирование ваших дисков на предмет ошибок. Для этого есть два варианта, старая добрая утилита командной строки ChkDsk и ее графический аналог в свойствах диска "Проверка диска на наличие ошибок файловой системы"
Для проверки локальных дисков через командную строку, вы можете воспользоваться командой:
Ключ /f указывает утилите исправлять ошибки на диске, флаг /R обязывает CHDSK искать на диске повреждённые сектора, и попытаться восстановить данные на них. Если диск системный, то вас попросят перезагрузиться, и проверка диска будет перед загрузкой системы.
Невозможно выполнить команду CHKDSK, так как указанный том используется другим процессом. Следует ли выполнить проверку этого тома при следующей перезагрузке системы? [Y(да)/N(нет)]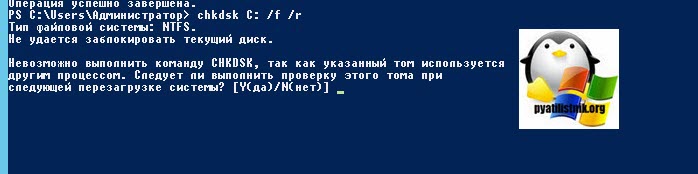
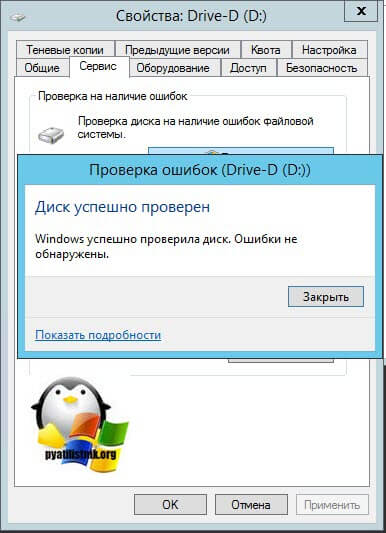
То же самое вы можете сделать и в свойствах локального диска, для этого щелкните по нему правым кликом и перейдите в его свойства. Найдите там вкладку "Сервис" и на ней пункт "Проверка диска на наличие ошибок файловой системы". Нажмите проверить.
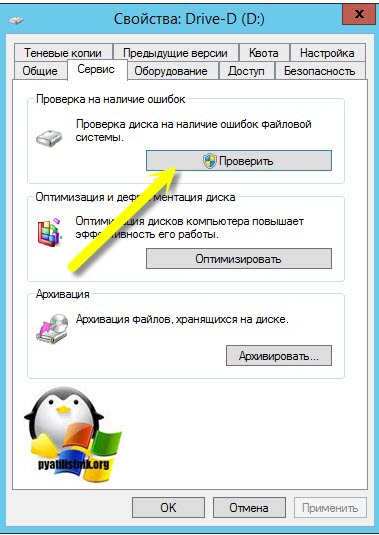
В новом окне нажимаем "Проверить диск".
Будет запущен процесс сканирования диска, обычно он занимает не много времени.
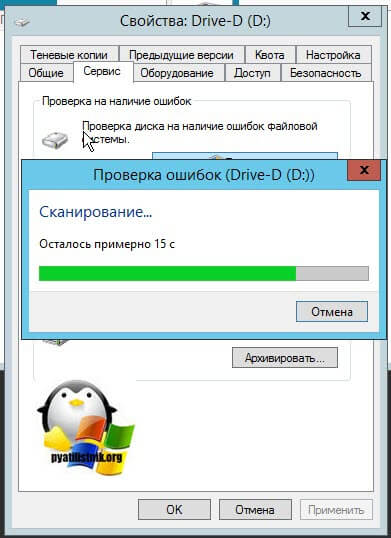
После чего вы получите результат. В моем случае я вижу, что "Диск успешно проверен".
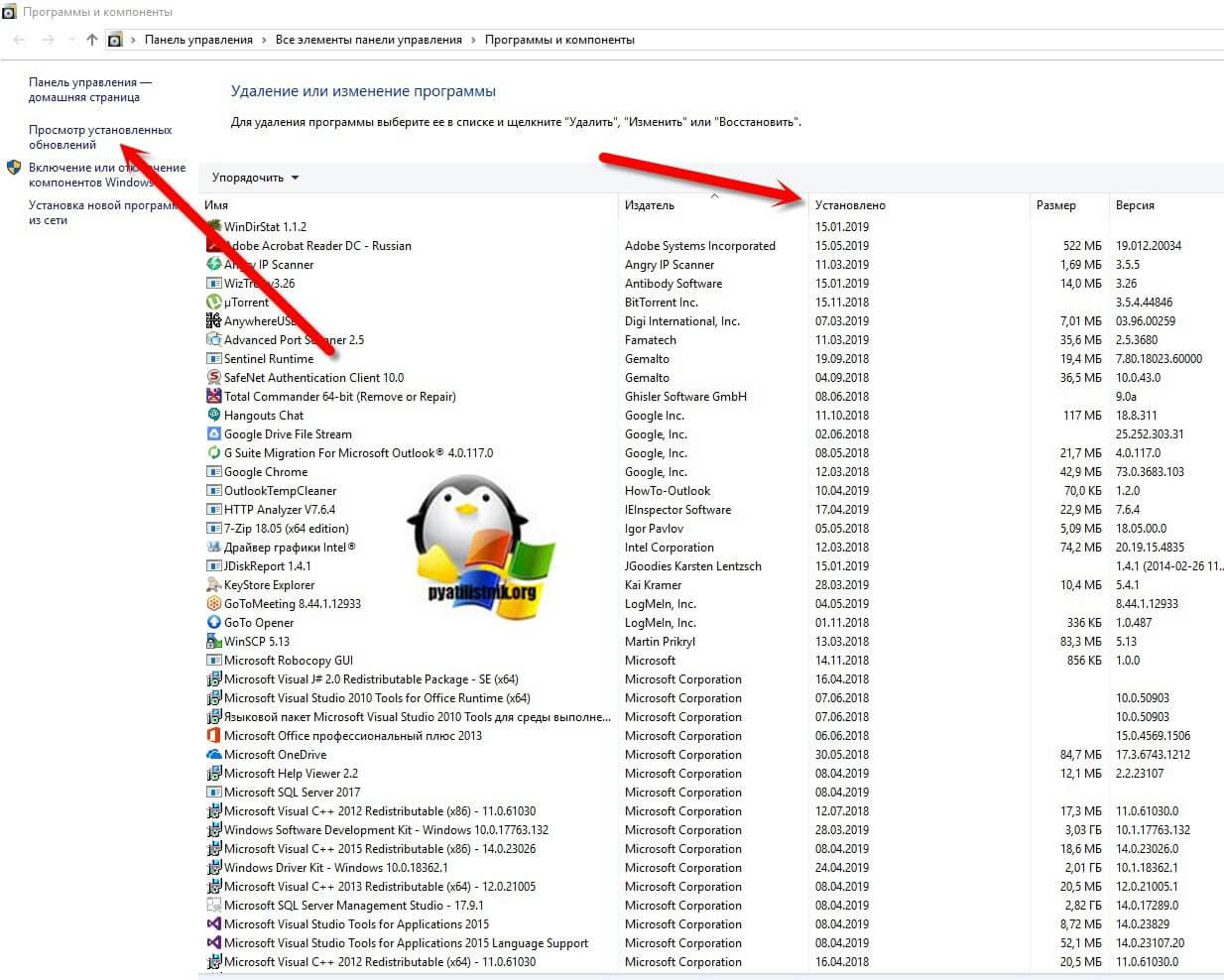
Ранее установленный софт
Очень часто причиной зависания виртуальной машины на ESXI 6.5 выступает недавняя установка обновлений в системе или различного рода программного обеспечения. Обязательно посмотрите в "Панель управления\Все элементы панели управления\Программы и компоненты" по дате установки, что недавно было проинсталлировано.
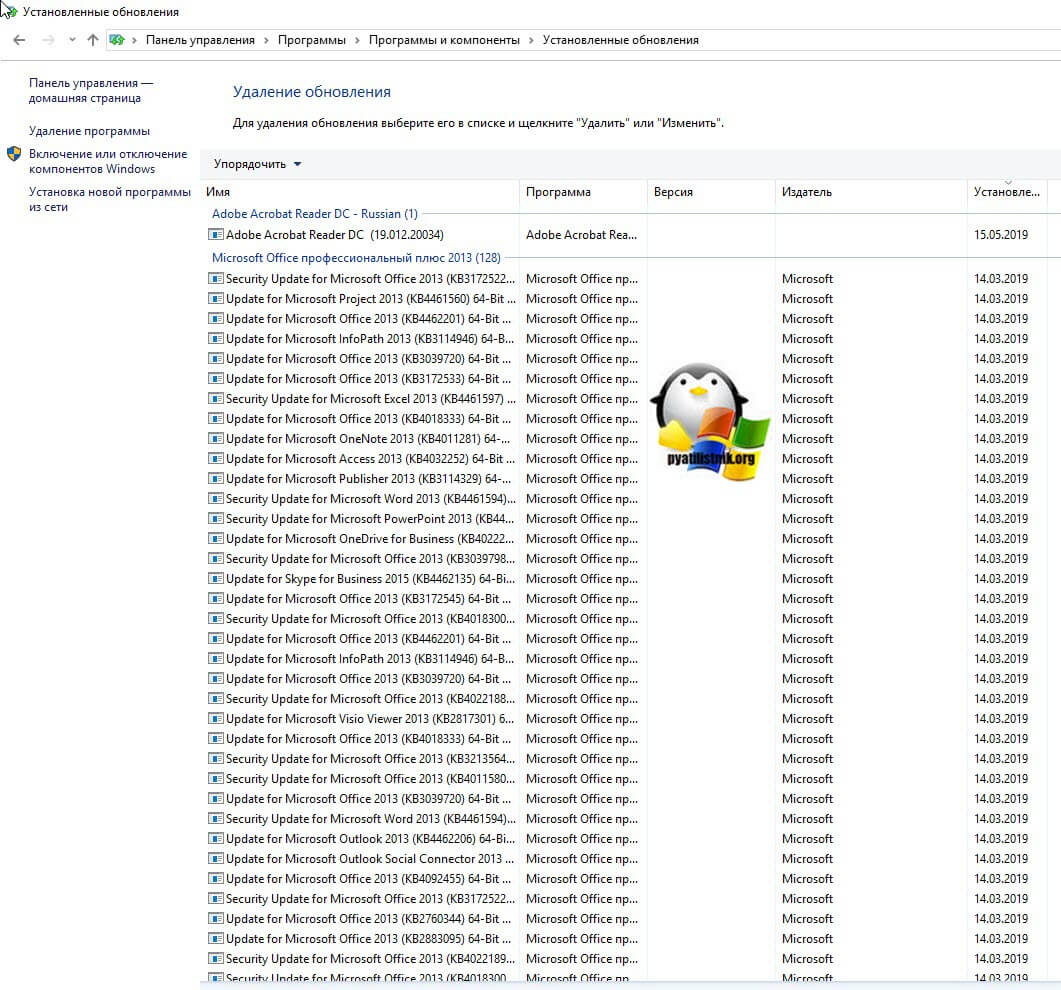
Тут же можно посмотреть установленные обновления. Недавно Microsoft выпустило обновление KB4015553 (Со временем может меняться), которое в Windows Server 2012 R2 стало вызывать зависание. Необходимо удалить KB4015553, kb4019215 и kb4019217, перезагрузить ваш сервер.
Сама компания Symantec рекомендует в ветке (https://support.symantec.com/en_US/article.TECH236543.html) Исключите из проверки следующий каталог, включая все подкаталоги: путь зависит от вашей версии SEP: "C:\ProgramData\Symantec\Symantec Endpoint Protection\<версия>\Data\Definitions". Пример для SEP 14.0 MP1: C:\ProgramData\Symantec\Symantec Endpoint Protection\14.0.2332.0100.105\Data\Definitions. Если вышеуказанное исключение не решает проблему, также исключите следующий каталог: C:\Windows\rescache.
Эти пути могут отличаться в зависимости от сборки продукта или от того, что каталоги ProgramData или Windows были перемещены на другой диск.Сделать, это можно в "Change Settings - Exception - SONAR Exception" нажимаем кнопку "Add" и выбираем нужные каталоги.
Читайте также: