
Нужен ли мощный компьютер для нейронных сетей
Обновлено: 17.05.2024
Глубокое обучение требует больших вычислительных ресурсов, поэтому очень важно какой графический процессор (видеокарту) вы выберете для своих исследований. Надежный GPU позволит быстро вычислять оптимальные архитектуры и настройки глубоких сетей, проводить эксперименты за дни вместо месяцев, часы вместо дней, минуты вместо часов.
Для машинного обучения важно количество ядер и объём памяти. По сути, алгоритмы машинного обучения — это всего лишь куча линейной алгебры. Поэтому графические процессоры, рассчитанные на большое количество параллельных вычислений, так превосходят процессоры центральные.
Если тренируете модели не часто, то стоит обратить внимание на облачные сервисы. Вероятно, вам хватит возможностей, предоставляемых бесплатными тарифами. Однако даже если вы решите заплатить, это может оказаться выгодней, чем приобретать собственную карту.
При регулярном обучении моделей становится разумнее приобрести свой ускоритель. Основных производителей графических чипов два: Nvidia и AMD. Intel только выпускает на рынок свои первые дискретные видеокарты, а встроенная в центральные процессоры графика обладает малой производительностью.
Изначально библиотеки использовали технологию CUDA, присутствующую только на картах Nvidia. Благодаря этому Nvidia стала стандартом в машинном обучении и остается им сейчас. Позже в популярные библиотеки стали добавлять поддержку OpenCL для работы на картах AMD, но сообщество пользователей малочисленно и смело называйте себя энтузиастом, если решите заниматься обучением моделей на AMD.
Далее в статье будем рассматривать только Nvidia, т.к. кроме большого сообщества, которое уже столкнулось с множеством проблем до вас и готово подсказать решение, есть и другое важное преимущество. Для работы современных версий библиотек подойдут видеокарты архитектуры Maxwell и новее. Часть карт архитектуры Kepler также подходят.
На что еще следует обратить внимание:
1. Объем видеопамяти.
Перемещение данных, из памяти и в неё, очень сильно ограничивает вычислительный процесс, поэтому чем больше памяти есть на карте, тем лучше. Недостаток памяти вынудит вас уменьшать Batch size, либо вовсе отказаться от задуманного.
Вот несколько ориентировочных рекомендаций объема видеопамяти:
- при использовании предобученных моделей в Transformer ≥ 11 ГБ;
- обучение больших моделей в Transformer или в сверточных нейронных сетях ≥ 24 ГБ;
- прототипирование нейронных сетей ≥ 10 ГБ;
- для Kaggle ≥ 8 ГБ;
- компьютерное зрение ≥ 10 ГБ.
Примеры нехватки видеопамяти можно посмотреть на изображениях ниже (нули в ячейках).


Центральный процессор (ЦП) не оптимизирован для одновременного выполнения большого количества простых операций. Для параллельных вычислений лучше подходит графический процессор (ГП):
- ГП состоит из множества арифметико-логических устройств ( АЛУ );
- б о́ льшая часть транзисторов обрабатывает данные, а не занимается кэшированием и управлением потоками;
- процесс создания, управления и удаления потоков происходит эффективнее, чем у ЦП.
2.1. CUDA
Графический процессор состоит из набора независимых мультипроцессоров, которые включают в себя :
На одном ядре CUDA (архитектура параллельных вычислений от NVIDIA) выполняется одна нить, иначе – поток. Каждому потоку соответствует один элемент вычисляемых данных. Потоки образуют блоки, которые общаются между собой через:
При частоте 1 ГГц процессор делает 10 9 циклов в секунду. Операции занимают больше времени, чем один цикл, поэтому создается конвейер , где для начала новой операции необходимо дождаться окончания предыдущей .
Мультипроцессор на каждом такте выполняет одну и ту же инструкцию над варпом (warp) – группой из 32 потоков. Потоки одного варпа принадлежат одному блоку и могут взаимодействовать только между собой. Каждому потоку и блоку присваивается идентификатор – трехмерный целочисленный вектор:
Блоки группируются в сетки блоков . Размеры блока и сетки блоков задаются переменными blockDim и gridDim при вызове ядра. Потокам из одного блока доступна разделяемая память (shared memory). Их выполнение может быть синхронизировано.
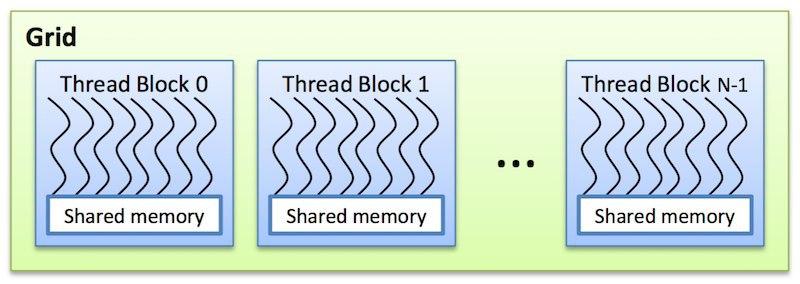
Рис. 5. Сетка блоков в CUDA
Алгоритм работы технологии CUDA выглядит следующим образом.
- Выделение памяти на ГП.
- Копирование расчетных данных в выделенную память ГП.
- Вычисления на ядрах ГП.
- Перенос результатов вычислений в оперативную память для обработки ЦП.
- Освобождение памяти ГП.
2.2. Иерархия памяти
Локальная память (local memory):
Разделяемая память (shared memory):
Глобальная память (global memory):
Константная память (constant memory):
Текстурная память (texture memory):
Последовательность шагов при выборе ГП.
- Определить область применения: соревнования в Kaggle, глубокое обучение, исследования в области компьютерного зрения, обработка естественного языка и т. д.
- Выбрать необходимый объем памяти.
- Узнать: сколько видеокарт поместится в системном блоке; правильно ли организована циркуляция воздуха в системном блоке; хватит ли мощности блока питания.
3.1. Когда достаточно менее 11 ГБ памяти
Базовые навыки в глубоком обучении можно освоить, тренируясь на небольших задачах с малыми входными параметрами , поэтому достаточно RTX 3070 (8 ГБ, GDDR6) и RTX 3080 (10 ГБ, GDDR6X). Для прототипирования лучший выбор – RTX 3080.

Рис. 10. Видеокарта NVIDIA RTX 3080
3.2. Когда нужно больше 11 ГБ памяти
Не менее 11 ГБ памяти нужно при работе с архитектурой Transformer , распознаванием медицинских изображений, компьютерным зрением и работой с большими изображениями.
3.3. Тензорные ядра
Тензорные ядра быстрее CUDA-ядер , потому что им требуется меньше циклов для операций с матрицами. В чипах Ampere (линейка RTX 30) стало меньше тензорных ядер, но возросла их производительность .

Рис. 11. Архитектура тензорных ядер в GeForce RTX 2080 Super и GeForce RTX 3080
3.4. Пропускная способность памяти
Тензорные ядра быстрые и обычно простаивают до 70% времени, ожидая данные из глобальной памяти. Поэтому выбирайте ГП с максимальной пропускной способностью памяти. Еще нужна большая разделяемая память и кэш L1, чтобы сократить число обращений к внешней памяти и держать данные ближе к АЛУ.
Сколько нужно памяти:
- при использовании предобученных моделей в Transformer ≥ 11 ГБ;
- обучение больших моделей в Transformer или в сверточных нейронных сетях ≥ 24 ГБ;
- прототипирование нейронных сетей ≥ 10 ГБ;
- для Kaggle ≥ 8 ГБ;
- компьютерное зрение ≥ 10 ГБ.
3.5. Система охлаждения
В конструкции системы охлаждения Reference RTX 30 (NVIDIA) первый вентилятор расположен на верхней стороне видеокарты. Он выдувает воздух в пространство, где расположена оперативная память и процессор. Второй вентилятор выдувает воздух сразу из корпуса (Рис. 12).
Рис. 12. Cистема охлаждения Reference RTX 30
Еще нет тестов, подтверждающих эффективность решения и необходимость замены штатной системы охлаждения. Установка нескольких ГП в одном корпусе может негативно сказаться на циркуляции потоков воздуха внутри корпуса и охлаждении видеокарт.
3.6. Электропитание
Картам может не хватить мощности блока питания. Четыре карты RTX 3090 потребляют на пике 1400 Вт. Продаются блоки питания на 1600 Вт, но остальным комплектующим 200 Вт может быть недостаточно.

Рис. 13. Блок питания Super Flower Leadex Titanium SF-1600F14HT на 1600 Вт
3.7. Рекомендации для кластеров
Для кластеров важно надежное электропитание , доступное в дата-центрах, но по лицензионному соглашению карты RTX в них размещать запрещено . Для небольшой системы подойдет Supermicro 8 GPU.

Рис. 14. Сервер SuperMicro Superserver 4028gr-tvrt, до 8 Tesla v100 sxm2
Для кластера из 256+ ГП – NVIDIA DGX SuperPOD.

Рис. 15. Суперкомпьютер NVIDIA DGX SuperPOD
При 1024+ ГП – Google TPU Pod и NVIDIA DGX SuperPod.

Рис. 16. Суперкомпьютер Google TPU Pod на тензорных процессорах
3.8. Не покупайте эти карты
Не покупайте более одной видеокарты RTX Founders Editions или RTX Titans, если нет PCIe-удлинителей для решения проблем с охлаждением.

Рис. 17. Видеокарта NVIDIA RTX Titan
Tesla V100 или A100 рентабельны только в кластерах. Карты серии GTX 16 имеют низкую производительность, так как из них убрали тензорные ядра. Аналоги GTX 16: б/у RTX 2070, RTX 2060 или RTX 2060 Super.

Рис. 18. Видеокарта NVIDIA Tesla V100
При наличии RTX 2080 Ti и выше, обновление до RTX 3090 невыгодно . Прирост производительности мал, а риск получить проблемы с питанием и охлаждением в картах RTX 30 высокий. Апгрейд оправдан, если для задач требуется больше памяти.
3.9. Нужен ли PCI 4.0?
Для бюджетной домашней сборки PCI 4.0 не нужен . PCI 4.0 позволит лучше распараллелить и ускорить передачу данных на 1-7% в сравнении с PCIe 3.0 при использовании более четырех ГП. При работе с большими файлами «узким местом» может оказаться SSD-диск, но не передача данных с ГП на ЦП.
3.10. Необходимы только 8x/16x PCIe-слоты?
Использовать исключительно 8x и 16x PCIe-слоты необязательно. Допускается работа двух ГП на слотах 4х. При установке четырех ГП предпочтение отдавайте слотам 8x на каждый ГП, так как производительность слота 4x ниже на 5-10%.

Рис. 19. Слоты PCIe x1, x4, x16
3.11. Можно ли использовать разные карты вместе?
Да, можно! Но будет сложно эффективно распараллелить графические процессоры разных типов, т. к. быстрый ГП будет ждать, пока медленный ГП дойдет до точки синхронизации.
3.12. Что такое NVLink и полезно ли это?
NVLink – высокоскоростное соединение между ГП. В небольших кластерах (< 128 ГП) он не даст преимущества по сравнению с передачей по PCIe.

Рис. 20. Производительность NVLink M40, P100, V100 и A100
3.13. Что делать, если не хватает денег на топовые ГП?
Купить подержанные ГП, либо воспользоваться облачными сервисами. Бюджетные варианты (в порядке убывания цены и производительности):
- RTX 2070 или RTX 2060;
- GTX 1070 или GTX 1070 Ti;
- GTX 980 Ti (6 GB) или GTX 1650 Super.
3.14. Итог
- топовые карты: RTX 3080, RTX 3090;
- вторая лига: RTX 3070, RTX 2060 Super;
- бюджетный вариант: RTX 2070, RTX 2060, GTX 1070, GTX 1070 Ti, GTX 1650 Super, GTX 980 Ti;
- новичкам: RTX 3070;
- просто попробовать: RTX 2060 Super, GTX 1050 Ti, облачные сервисы;
- соревнования Kaggle: RTX 3070;
- компьютерное зрение, машинный перевод: четыре RTX 3090;
- NLP с простыми вычислениями: RTX 3080;
- кластеры менее 128 ГП: 66% 8x RTX 3080 и 33% 8x RTX 3090;
- кластеры от 128 до 512 ГП: 8x Tesla A100;
- кластеры более 512 ГП: DGX A100 SuperPOD;
Напоследок несколько сравнительных гистограмм характеристик различных GPU.
Рис. 21. Производительность видеокарт относительно RTX 2080 Ti. Рис. 22. Производительность на доллар (US) ГП относительно RTX 3080. Рис. 23. Производительность на доллар (US) четырех ГП относительно четырех RTX 3080. Рис. 24. Производительность на доллар (US) восьми ГП относительно восьми RTX 3080.
В этом руководстве мы рассмотрели устройство графического процессора и определили параметры, которые влияют на производительность в задачах глубокого обучения. Если запускаете расчет нейросеток время от времени, то апгрейд можно проводить через одно поколение графических процессоров.
Собственно, как понятно из заголовка, я хочу попытаться собрать домашний компьютер для работы с нейронками (Tenserflow + CUDA под Ubuntu) и не разориться – хочу это сделать по двум причинам: у меня нет ноута с Nvidia карточкой и я устал платить за сервера EC2 на Amazon (дорого), а тренировка модели на CPU может занять буквально месяцы.
Само собой, второй ОС я туда поставлю Windows и буду играть в какие-нибудь игры вроде лучших игр на свете, но это не основная причина сбора компьютера.
Немного поискав в интернете, я наткнулся на эту инструкцию:
Building a desktop after a decade of MacBook Airs and cloud serversНиже я приведу конфигурацию которую предлагает автор и хотел попросить кого-то кто разбирается в теме оценить конфигурацию и посоветовать что-то лучше чем у автора и где лучше заказывать комплектующие (я нахожусь в Европе).
Видеокарта – 829$
Автор предлагает выбрать из GTX 1070, GTX 1070 Ti, GTX 1080, GTX 1080 Ti и Titan X. Видео-карта нужна Nvidia, так как CUDA уже стандарт для работы с TF. Тут нечего менять мне кажется, самая дорогая часть конфигурации – бы выбрал GTX 1080 Ti (с перспективой докупить еще одну позже, когда вторую почку купят).
Процессор – 200$
Автор предлагает Intel i5 7500, но отмечает, что если взять два титана GPU, то процессор будет работать в 16 PCIe lanes , а для двух титанов нужно 32 PCIe lanes – я не знаю что это все значит, просто вставил сюда, надеюсь поможет кому-то в чем-то.
Тут все просто, две планки по 16 – 32 GB RAM DDR4 DRAM 2666MHz
Жесткий диск – 189$ + 54$
Материнская плата – 185$
Для поддержки потенциально двух GPU и выбранного процессора автор предлагает Asus TUF Z270
Блок питания – 89$
Как пишет автор «Блок питания должен обеспечивать достаточное количество манны для CPU, двух GPU и 100 ватт сверху», поэтому он предлагает – EVGA 750 GQ
Мне пофигу как бы он выглядел, главное чтобы все влезло – автор предлагает такой корпус:
В общем, помогите выбрать конфигурацию, пожалуйста.
Да ясно чем он там собрался заниматься
Вживую лучше же:
Всякие Таркины, Леи и даже Танос курят в сторонке.
GitHub is where people build software. More than 28 million people use GitHub to discover, fork…Как говорится, если гора не идет к Магомеду.
Intel i5 7500
присмотрись лучше к AMD Ryzen что то типа 1600x/2600x, +/-(лень гуглить цену) за те же деньги, ты получишь камень который будет актуален еще много лет, а у 7500 нет будущего, если уж на интел смотреть, то покупку i5-8500 еще как то можно оправдать
Спасибо, а материнская плата остается та же? AMD Ryzen с такими же сокетами как и i5? Я давно последний раз компы трогал, еще разные сокеты были в ходу
нет, для AMD сокет AM4, если нужен будет SLI нужно смотреть на чипсеты x370/x470, если SLI не нужен, то B350/B450
PCI Express, или PCIe, или PCI-E (также известная как 3GIO for 3rd Generation I/O; не путать с…Если вычисления умеют работать с SLI то двух 1080 обычных хватит за глаза. Проц лучше взять i7, core i5 не раскроет эти мощные карточки.
Обзор Intel Core i7-8700K Coffee Lake (3700MHz/LGA1151/L3 12288Kb): цена, фото, технические… PCI-E 3.0, ядро - 1632 МГц, Boost - 1797 МГц, память - 8 Гб GDDR5X 10010 МГц, 256 бит, DVI, HDMI…Если вычисления умеют работать с SLI то двух 1080 обычных хватит за глаза. Проц лучше взять i7, core i5 не раскроет эти мощные карточки.
Ну давай поиграй на селероне с 1080ti в какой нибудь батлфилд.
C таким же успехом могу привести в пример какой нибудь сталкер или крайзис первый где со старым Core 2 Quad и 1080 гпу будет загружен почти на 100%. Посмотри видос и не неси бред про какое то "расскрытие".
Не. СПС. Не доверяю видосам всяких личностей в маске с ютаба.
Какой то он черезчур агрессивный.
Прям как свидетели АМД.
ну тогда пиши на своем лбе "я - мракобес" ред.
Жалко тут подписей нет, я б поставил. Мне не жалко.
Твой кор 2 куард задохнется даже в уже не совсем новом бф1, это проц для серфинга интернета и для "мамкиных кибер спортсменов", которые играют только в доту, кс и танки.
Интересно, с чем "несогласны" те, кто ставит минусы? Их кор куард "уникальный" и все тащит? Ну давайте хоть одно подтверждение этого, которого, естественно, нет. У меня 2 таких проца, в том числе и максимальный для сокета 775, я его тестил в максимальном разгоне которого удалось добиться (4Ггц) и он НЕ ТАЩИТ, все. Я даже думаю что у этих людей и проца ни одного нет с 775, но надо же выпендриться своими нулевыми знаниями, чтобы почувствовать собственную важность.
А что такое раскрытие? Я просто совсем не в теме
мракобесие для несведущих. Не стоит обращать внимания.
под "раскрытием" имеется в виду сценарий, когда процессор нагружается первым на 100% и далее видеокарту приложение нагрузить не может, эдакое бутылочное горлышко (bottleneck)
А материнская плата остается та же?
Согласен. Я дебил. 1080ti лучше из за 11 гигов против 8 vram.
Так ты еще видеокарты по объему видеопамяти выбираешь, мол чем больше тем лучше? Ясно, понятно.
4 гига 4 ядра! Ага.
Но вообще то у чувака тут дип лернинг. Разве для этого не требуется овердохера видеопамяти?
Нужно же где то хранить все эти тыщи картинок.
На счет объема видеопамяти не, могу сказать не вникал, но знаю что для DL нужны тензорные или CUDA ядра, которых у 1080ti на 1к больше чем у обычной 1080, да и ПСП у ti выше на 30%
Ну тогда и правду нужна ti. Я что то проступил, да.
Вполне сойдет и такая. Хорошая плата от Асуса с неплохой системой питания.
Обзор ASUS ROG MAXIMUS X HERO: цена, фото, технические характеристики и комплектация.А если покупать комплектующие, я слышал кто-то советовал это делать в Германии, это так?
На мой взгляд лучше здесь. Случись что с гарантией проще обращаться.
Computeruniverse и ждать скидки
Не, ну вдруг у человека не только cuda вычисления. Тогда i7 будет намного лучше i5.
Но надо учесть, что SLI бесполезно в играх, оно там просто не работает и его поддержку производители вроде как сворачивают окончательно.
В оригинальной статье хотя бы есть пример того, с какими данными он работает (MNIST). А вы какие задачи решать собираетесь?
Собирать армию НейроИлюхеров, видимо.
Она и на регулярках работает нормально ;)
Это как в West World?))
Илюхер слишком прост и умешается в пару регулярок?))
Как оказалось, да :)
Я так себе погромист, зато я умею следовать инструкциям, так что это скорее просто хобби – находить какие-то исходники на гитхабе и смотреть.
Или deepface, или wavenet. Вообще у меня долгий список нейронок, я их выкладываю в свой канал на эту тему, но ссылку не дам, чтобы не было рекламой :)
MNIST – это просто с чего все начинают в этой теме.
Возьмите лучше Intel Xeon E5-1650 6 ядер 12 потоков или E5-2680v2 10 ядер 20 потоков и китайскую мать, второй проц в те же 200$ выйдет, первый и того дешевле, а производительность как небо и земля, особенно в мультипотоке, для задач которые хорошо параллелятся. Не знаю правда ваши к ним относятся, какая нагрузка на проц идет при них, но i5 7500 это несерьезно уже даже для того, чтобы в игрушки поиграть.
Там как раз все расчеты в основном на GPU, поэтому акцент на на них – но я изучу, спасибо.
Всеравно 6 ядер проца под игрушки лучше и с запасом на будущее, а 8700К будет стоить раза в 3-4 дороже. Про оперативку я вообще молчу, сейчас на неё цены бешенные, а серверная оператива для зеона стоит по 60$ за 16 гб. Можно ещё е5 1620, там 4 ядра 8 потоков, стандарт на сегодняшний день за смешную цену меньше 100 $. Я вообще уже давно начал статью писать, но все никак не напишу, там как раз про подобные экзотические сборки с Китая. Решил написать, так сам на такой сижу с недавних пор, на e5 1650. ред.
Бери GTX 1080 Ti, хотя бы просто из-за VRAM. При обучении на картинках она понадобится. В целом конфигурация из статьи - вполне хорошая машина для разработки.
Видеокарта
Если расчеты в приоритете, то может найти по-дешевке пару 980ti?
Явно быстрее одиночной 1080ti
нужно 32 PCIe lanes – я не знаю что это все значит
количество линий PCI-express, у i5 7500 16 линий, у рязяни 24. Для расчетов не важно, для игр - ну на 8x PCEe народ не особо жалуется, особенно с большим количеством видеопамяти (8Gb+). .
Смысл кому-то продавать 980ti, она же ещё актуальна и неплохо тащит. Если кто-то и продаёт такую карту, то с ней явно что-то не так, зачем так рисковать.

Эффективность работы нейросетевых моделей во многом зависит от их размера и от размера обучающей выборки. Например, лидирующая на момент написания заметки модель обработки естественного языка — GPT-3 — имеет 175 миллиардов параметров и была обучена на 570 гигабайтах текстов. Но для обучения подобного масштаба требуется соответствующая вычислительная мощность, которая из-за дороговизны зачастую недоступна исследовательским группам, не входящим в состав крупных IT-компаний.
Во многих областях науки есть проекты распределенных вычислений, решающие эту проблему с помощью волонтеров: любой человек с доступом к интернету может установить у себя программу, которая будет в фоновом режиме проводить нужные ученым вычисления. Вместе, тысячи или даже миллионы компьютеров бесплатно предоставляют ученым вычислительную сеть с мощностью лидирующих суперкомпьютеров: в 2020 году мощность сети биомолекулярных симуляций Folding@home перешла рубеж в один экзафлопс и продолжила расти. Но сети распределенных вычислений имеют недостатки: каждый компьютер может в любой момент отключиться или передавать данные медленно и нестабильно, а кроме того, не все типы вычислений одинаково легко разбиваются на подзадачи для распределения по отдельным вычислительным узлам.
Максим Рябинин (Maksim Riabinin) из Высшей школы экономики и Яндекса вместе с коллегой Антоном Гусевым (Anton Gusev) разработали платформу Learning@home, позволяющую распределять обучение нейросетевых моделей на множество компьютеров. В основе платформы лежит метод коллектива экспертов, при котором за обработку разных входящих данных отвечают определенные «эксперты» — отдельные алгоритмы или компьютеры. Разработчики предложили разбивать слои обучаемой нейросети на набор экспертов. Каждый из экспертов может иметь свою специализацию, к примеру, выступать в качестве части нейросети сверточного или другого типа.
Читайте также: