
Обмен данными между базами oracle
Обновлено: 07.07.2024
Из этого руководства вы узнаете, как перенести базы данных Oracle в SQL Server с использованием Помощника по миграции SQL Server для Oracle (SSMA для Oracle).
Предварительные требования
Прежде чем приступить к переносу базы данных Oracle в SQL Server, сделайте следующее:
- Убедитесь, что ваша исходная среда поддерживается.
- Скачайте и установите SQL Server.
- Скачайте и установите SSMA для Oracle.
- Получите необходимые разрешения для SSMA для Oracle и поставщик.
- Получите возможность подключения и требуемые разрешения для доступа к исходному и целевому объектам.
Подготовка к миграции
При подготовке к миграции в облако убедитесь в том, что исходная среда поддерживается и все остальные предварительные требования выполнены. Так вам будет проще успешно и эффективно выполнить миграцию.
Этот этап процесса включает в себя инвентаризацию баз данных для переноса, проверку этих баз данных на отсутствие проблем или препятствий для миграции и устранение возможных проблем.
Обнаружить
Чтобы лучше понять процесс миграции и подготовиться к нему, используйте набор средств Microsoft Assessment and Planning Toolkit (MAP), который поможет выявить существующие источники данных и получить сведения о функциях, используемых вашей организацией. Этот процесс включает в себя сканирование сети для обнаружения всех экземпляров, версий и компонентов Oracle в организации.
Для проведения инвентаризации с помощью набора средств MAP сделайте следующее:
На панели Overview (Обзор) выберите Create/Select database (Создание или выбор базы данных).

В разделе Create or select a database (Создание или выбор базы данных) щелкните Create an inventory database (Создать базу данных инвентаризации), введите имя и краткое описание для новой базы данных инвентаризации, а затем нажмите кнопку ОК.

Щелкните Collect inventory data (Сбор данных инвентаризации), чтобы открыть мастер инвентаризации и оценки.

В этом мастере выберите Oracle, а затем щелкните Next (Далее).

Выберите оптимальный вариант для поиска компьютеров с учетом среды и потребностей вашей организации, а затем щелкните Next (Далее).

Введите существующие учетные данные или создайте их для нужных систем, а затем щелкните Next (Далее).

Укажите очередность учетных данных и нажмите кнопку Next.

Укажите учетные данные для каждого компьютера, который требуется обнаружить. Вы можете указать уникальные учетные данные для каждого компьютера или выбрать их из списка Computers (Компьютеры).

Проверьте выбранные настройки и нажмите кнопку Finish (Готово).

После завершения сканирования просмотрите сводный отчет Data Collection (Сбор данных). Это сканирование может занять несколько минут в зависимости от количества баз данных. По завершении нажмите кнопку Close (Закрыть).

Выберите Options (Параметры), чтобы создать отчет об оценке баз данных Oracle. Для создания отчета поочередно выберите оба параметра.
Оценка
Завершив выбор источников данных, с помощью SSMA для Oracle оцените тот экземпляр Oracle, который вы переносите на виртуальную машину SQL Server, чтобы увидеть различия между ними. Используя помощник по миграции, можно изучить объекты баз данных и данные в них, оценить возможности переноса баз данных, перенести объекты баз данных в SQL Server, а затем перенести данные в SQL Server.
Чтобы создать оценку, сделайте следующее:
Выберите File (Файл) и New Project (Создать проект).
Укажите имя и расположение проекта, а затем в раскрывающемся списке выберите целевой объект для миграции в SQL Server. Щелкните ОК.

Щелкните Connect to Oracle (Подключиться к Oracle), введите сведения о подключении к Oracle и нажмите кнопку Connect (Подключиться).

На панели Filter objects (Фильтрация объектов) выберите схемы Oracle, которые вы намерены перенести, и щелкните OK (ОК).

На панели Oracle Metadata Explorer (Обозреватель метаданных Oracle) выберите нужную схему Oracle и щелкните Create Report (Создать отчет), чтобы создать отчет в формате HTML со статистикой преобразований и списком ошибок и предупреждений (при их наличии). Можно также выбрать вкладку Create Report (Создать отчет) в правом верхнем углу.

Ознакомьтесь с отчетом в формате HTML, чтобы получить сведения о статистике преобразований, а также об ошибках или предупреждениях. Также можно открыть отчет в Excel, чтобы получить список объектов Oracle и действий, необходимых для выполнения преобразований схемы. По умолчанию этот отчет находится в папке report в каталоге SSMAProjects. Пример:

Обновление типов данных
Проверьте сопоставления типов данных по умолчанию и измените их в зависимости от требований, если это необходимо. Для этого сделайте следующее:
Щелкните Tools (Средства) и выберите Project Settings (Параметры проекта).
Перейдите на вкладку Type mapping (Сопоставление типов).

Сопоставление типов для каждой таблицы можно изменить, выбрав имя нужной таблицы в области Oracle Metadata explorer (Обозреватель метаданных Oracle).
Преобразовать схему
Чтобы преобразовать схему, сделайте следующее:
(Необязательно.) Чтобы преобразовать динамические или специализированные запросы, щелкните нужный узел правой кнопкой мыши и выберите пункт Add statement (Добавить инструкцию).
Перейдите на вкладку Connect to SQL Server (Подключение к SQL Server), а затем введите сведения о подключении к экземпляру SQL Server.
а. В раскрывающемся списке Database (База данных) выберите целевую базу данных или введите неиспользуемое имя, чтобы создать базу данных на целевом сервере.
b. Предоставьте сведения о проверке подлинности.
c. Выберите Подключиться.

На панели Oracle Metadata Explorer (Обозреватель метаданных Oracle) щелкните правой кнопкой мыши схему, с которой вы работаете, и выберите действие Convert Schema (Преобразовать схему). Также можно выбрать вкладку Convert Schema (Преобразовать схему) в правом верхнем углу.

Когда преобразование завершится, сравните преобразованные объекты с исходными, чтобы выявить возможные проблемы, и устраните их в соответствии с рекомендациями.

Сравните преобразованный текст Transact-SQL с исходным кодом и просмотрите рекомендации.

На панели выходных данных щелкните значок Review results (Проверка результатов), а затем просмотрите ошибки в области Error list (Список ошибок).
В качестве упражнения по исправлению схемы в автономном режиме сохраните проект на локальном устройстве, выбрав File > Save Project (Файл > Сохранить проект). Это позволит вам оценить исходную и целевую схемы в автономном режиме и устранить проблемы перед публикацией схемы в экземпляре SQL Server.
Перенос базы данных
Когда будут выполнены все предварительные условия и завершены задачи, связанные с подготовкой к миграции, вы можете переходить к переносу схемы и базы данных. Перенос состоит из двух этапов: публикация схемы и перенос базы данных.
Чтобы опубликовать схему и перенести базу данных, сделайте следующее:
Опубликуйте схему. В области SQL Server Metadata Explorer (Обозреватель метаданных SQL Server) щелкните базу данных правой кнопкой мыши и выберите Synchronize with Database (Синхронизировать с базой данных). Схема Oracle будет опубликована в экземпляре SQL Server.

Проверьте результаты сопоставления исходного и целевого проектов, как показано ниже:

Перенесите данные. В области Oracle Metadata Explorer (Обозреватель метаданных Oracle) щелкните правой кнопкой мыши схему или объект, которые вы хотите перенести, и выберите Migrate Data (Перенос данных). Также можно выбрать вкладку Migrate Data (Миграция данных) в правом верхнем углу.
Чтобы перенести данные всей базы данных, установите флажок рядом с ее именем. Чтобы перенести данные из отдельных таблиц, разверните базу данных, разверните Таблицы и установите флажок рядом с нужной таблицей. Чтобы не переносить данные из определенной таблицы, снимите флажок.

На панели Migrate Data (Перенос данных) введите сведения о подключении к Oracle и SQL Server.
После завершения миграции изучите отчет о переносе данных.

Подключитесь к экземпляру SQL Server с помощью SQL Server Management Studio и проверьте результаты миграции, просмотрев данные и схему.

Помимо SSMA, для переноса данных можно использовать службы SQL Server Integration Services (SSIS). Дополнительные сведения см. на следующих ресурсах:
После миграции
После успешного завершения этапа миграции необходимо выполнить ряд дополнительных задач, чтобы обеспечить бесперебойную и эффективную работу всех компонентов.
Исправление приложений
После переноса данных в целевую среду все приложения, которые раньше использовали источник, должны переключиться на использование целевого объекта миграции. Для этого в некоторых случаях потребуется внести изменения в приложения.
Data Access Migration Toolkit — это расширение для Visual Studio Code, с помощью которого можно анализировать исходный код Java и отслеживать вызовы и запросы к API доступа к данным. Этот набор средств содержит представление с одной областью для задач, которые нужно решить для поддержки новой серверной части базы данных. Дополнительные сведения см. в записи блога Перенос приложения Java из Oracle.
Выполнение тестов
Тестирование переноса базы данных проводится следующим образом.
Разработка проверочных тестов. Чтобы протестировать перенос базы данных, необходимо использовать SQL-запросы. Следует создать проверочные запросы, которые будут выполняться в исходной и в целевой базах данных. Проверочные запросы должны охватывать всю определенную ранее область.
Настройка тестовой среды. Тестовая среда должна содержать копию исходной и целевой баз данных. Не забудьте изолировать тестовую среду.
Выполнение проверочных тестов. Выполните проверочные тесты в исходной и целевой базах данных, а затем проанализируйте результаты.
Выполнение тестов производительности. Запустите тесты производительности для исходной и целевой баз данных, а затем проанализируйте и сравните результаты.
Оптимизация
Проверка после миграции — очень важный шаг, позволяющий добиться точности и полноты данных и устранить проблемы с производительностью рабочей нагрузки.
Дополнительную информацию об этих проблемах и мерах по их устранению см. в руководстве по проверке и оптимизации после миграции.
Ресурсы, посвященные миграции
Дополнительную помощь по этому сценарию миграции можно получить в приведенных ниже ресурсах. Они разработаны как вспомогательные материалы по реализации реальных проектов миграции.
Эти ресурсы разработали специалисты по разработке данных SQL. Основная задача этой команды — включить и ускорить комплексную модернизацию проектов миграции платформы данных на платформу данных Microsoft Azure.
Дальнейшие действия
Матрицу служб и средств, предоставляемых корпорацией Майкрософт и сторонними разработчиками для оказания помощи с разными сценариями переноса баз данных и данных, а также для специализированных задач, см. в статье Службы и инструменты для переноса данных.
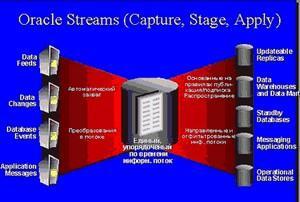
С разрастанием компаний появляется потребность в наличии возможности совместного использования информации между несколькими базами данных и приложениями. Применение разнородных технологий для совместного использования информации лишь усложняет эффективную репликацию. Технология Oracle Streams (Потоки Oracle) представляет собой единое универсальное решение для осуществления обмена информацией по всему предприятию.
В контексте Oracle Streams каждая единица информации называется событием (event), и обмен всеми такими событиями осуществляется в потоке. Поток передает указываемую информацию в указываемые пункты назначения. Oracle Streams захватывает происходящие в базе данных изменения за счет использования как активных, так и архивных журналов повторного выполнения. Он перехватывает их и сохраняет в очередях после выполнения надлежащего форматирования, а затем передает в другие базы данных и, если нужно, применяет их там. С его помощью информацию можно захватывать (собирать), передавать и применять и в пределах одной и той же базы данных Oracle, и между двумя базами данных Oracle, и между несколькими базами данных Oracle и даже между базой данных Oracle и базой данных другого типа (не Oracle).
На заметку! Oracle Streams может применяться на нескольких уровнях: на уровне базы данных, на уровне схемы и даже на уровне отдельных таблиц, и использовать для осуществления перехвата изменений на этих уровнях различные правила.
Архитектура Oracle Streams
Тремя базовыми элементами технологии Oracle Streams являются этап захвата, этап подготовки и этап потребления событий внутри базы данных Oracle.
- Сервер считывания, который считывает журналы повторного выполнения и разбивает их на разделы.
- Один или несколько серверов подготовки, которые сканируют разделы журналов параллельным образом и выполняют предварительную фильтрацию изменений.
- Сервер построения, объединяющий записи из журналов повторного выполнения, которые он получает от серверов подготовки и передает их процессу захвата.
Далее процесс захвата преобразует объединенные записи данных повторного выполнения в логические записи изменений (Logical Change Records — LCR) и передает их на этап подготовки для дальнейшей обработки. Каждая LCR-запись описывает изменения, внесенные в одну строку оператором DML. Один оператор DML может приводить к генерации нескольких LCR-записей. LCR-запись, которая представляет собой набор захваченных изменений, также называется событием (event). LCR-записи, содержащие информацию о данных таблицы, называются логическими записями изменений строк (row LCR), а те, что содержат информацию о DDL-изменениях — логическими записями изменений DDL (DDL LCR). Правила, используемые в процессе захвата, зависят от того, какие изменения захватываются. Обратите внимание, что Oracle Streams можно настраивать так, чтобы база данных могла извлекать изменения из потока данных повторного выполнения в исходном месте и затем передавать в целевое место либо отдельно только LCR-записи, либо весь поток данных повторного выполнения с последующим извлечением необходимых LCR-записей непосредственно в самом целевом месте.
На этапе подготовки (staging) процесс Oracle Streams сохраняет события в очереди. В число этих событий могут входить изменения, захваченные как явным, так и не явным образом.
На последнем этапе, этапе потребления (consumption), находящиеся в очереди события начинают использоваться в целевой базе данных. Перед использованием событие должно удаляться из очереди. Пользователи и приложения могут удалять события из очереди явным образом. Однако по большей части их удаление из очереди происходит все-таки в рамках неявного процесса применения (apply process). Удаление из очереди и обработка захваченных данных осуществляется в соответствии с правилами. В ходе процесса применения захваченные данные могут как применяться напрямую, так предварительно преобразовываться с использованием кода PL/SQL.
Настройка Oracle Streams
Ниже перечислены шаги, которые необходимо выполнить для настройки механизма Oracle Streams и администрирования осуществляемых с его помощью операций по передаче изменений между несколькими базами данных. Следует иметь в виду, что тут предлагается лишь очень краткий обзор процесса настройки Oracle Stream, чтобы у вас могло сложиться общее впечатление о том, что он собой представляет. Для настоящей настройки Oracle Streams следует обязательно использовать соответствующие инструкции, предлагаемые в руководствах по Oracle.
1. Сначала нужно внести необходимые изменения в файл init.ora или SPFILE.
- Проверить, чтобы в параметре COMPATIBLE была указана версия 10.2.0 или выше в обеих базах данных (на самом деле в нем можно даже указывать версию 9.2 или выше).
- Проверить, чтобы для параметра JOB_QUEUE_PROCESSES в исходной базе данных было установлено, как минимум, значение 2.
- Проверить, чтобы для параметра GLOBAL_NAMES как в исходной, так и в целевой базе данных было установлено значение true.
- Установить параметр LOG_ARCHIVE_DEST_n. Нужно, чтобы на сайте, отвечающего за основной процесс захвата, присутствовало хотя бы одно место для размещения архива журналов.
- Проверить, чтобы под компонент памяти STREAMS_POOL_SIZE в SGA было выделено хотя бы 200 Мбайт.
- Удостовериться в том, что табличное пространство является достаточно большим для того, чтобы удовлетворять требования параметра UNDO_RETENTION.
- Удостовериться в том, что исходная база данных функционирует в режиме архивирования журналов (ARCHIVELOG).
2. Затем необходимо создать нового пользователя для управления Oracle Streams. Перед его созданием может потребоваться создать для него новое табличное пространство:
Теперь можно создать в базе данных самого пользователя, ответственного за администрирование Oracle Streams, как показано ниже:
3. Далее нужно выдать пользователю–администратору Oracle Streams (strmadmin) привилегии CONNECT, RESOURCE и DBA:
4. Для предоставления необходимых привилегий администратору Oracle Streams следует использовать процедуру GRANT_ADMIN_PRIVILEGE из пакета DBMS_STREAMS_AUTH:
5. Затем необходимо создавать канал связи между исходной и целевой базой данных, как показано ниже:
6. Oracle Streams осуществляет перемещение данных между исходной и целевой базой данных с помощью очередей. Поэтому далее необходимо создать очередь как в исходной, так и в целевой базе данных. Для этого потребуется выполнить в той и другой следующую процедуру, которая подразумевает создание обеих очередей с принятыми по умолчанию именами.
7. Далее нужно включить дополнительную журнализацию для всех тех таблиц в исходной базе данных, для которых планируется перехватывать изменения. Делается это следующим образом:
8. И, наконец, напоследок необходимо сконфигурировать процесс захвата в исходной базе данных с использованием процедуры ADD_TABLE_RULES из пакета DBMS_STREAMS_ADM:
После настройки Oracle Streams в соответствие с перечисленными выше шагами можно тестировать настроенную конфигурацию, запустив процесс захвата и применив процесс применения для репликации данных таблицы (в данном примере — emp) из исходной базы данных в аналогичную таблицу в целевой базе данных. Для захвата изменений используется следующая процедура:
Для переноса захваченных изменений в целевую базу данных служит такая процедура:
Технология Oracle Streams была рассмотрена в этой статье моего блога очень кратко. Тем не менее, она представляет собой очень мощное и полезное средство для выполнения в базах данных операций по репликации, переносу и обновлению данных. Главным интерфейсом к Oracle Streams служит соответствующая коллекция поставляемых Oracle пакетов PL/SQL. Здесь было показано, как применять некоторые из этих пакетов для настройки и управления механизмом Oracle Streams, чтобы вы могли посмотреть, что конкретно происходит на этапе захвата и передачи изменений. Для оказания помощи пользователям в настройке, администрировании и мониторинге сред Oracle Streams компания Oracle поставляет специальный инструмент Streams в составе интерфейса OEM Console. Для удобства работы с Oracle Streams рекомендуется использовать именно его.
Этапы импорта и экспорта данных базы данных Oracle (начало работы)
Описание:
1. Существует много способов импорта и экспорта данных базы данных, вы можете импортировать и экспортировать с помощью команды exp / imp, или вы можете использовать сторонний инструмент для экспорта, такой как: PLSQL
2. Если вы знакомы с командами, рекомендуется использовать команду exp / imp для импорта и экспорта, чтобы избежать проблем, вызванных различиями версий сторонних инструментов, и в то же время это более эффективно, но обратите особое внимание: обратите внимание на детали пользователя и его разрешения при использовании команды. к
3. Когда целевая база данных импортируется, необходимо создать то же имя пользователя, что и при экспорте (стараться быть согласованным), и предоставить не более низкие права, чем пользователь во время экспорта, и в то же время создать то же имя табличного пространства, что и исходная база данных, если локальная база данных уже существует. Одно и то же табличное пространство может быть только расширено.
1. Подготовка перед импортом (работа в целевой базе данных)
Дополнение знаний:
Табличное пространство
База данных Oracle хранит физические таблицы в табличных пространствах. Экземпляр базы данных может иметь N табличных пространств, а табличное пространство может иметь N таблиц. к
Табличное пространство является логическим разделением баз данных, и каждая база данных имеет по крайней мере одно табличное пространство (так называемое табличное пространство SYSTEM). Чтобы упростить управление и повысить эффективность работы, некоторые дополнительные табличные пространства могут использоваться для разделения пользователей и приложений. Например: табличное пространство USER предназначено для обычных пользователей, а табличное пространство RBS - для сегмента отката. Табличное пространство может принадлежать только одной базе данных.
1. Войдите на сервер
Вы можете использовать инструменты Xshell или secureCRT
2. Проверьте, достаточно ли места на диске
Выполните команду df -h или df -H для запроса. Если свободного места недостаточно, замените целевую среду новой целевой средой и продолжите другие операции.
3. Запрос информации о табличном пространстве
UsingВойдите в систему с помощью терминала и выполните команды в последовательности:
[oracle @ orac
] $ su-oracle (переключиться на пользователя oracle (имя пользователя для linux))
Создайте новую папку в каталоге / home / oracle / app / oradata, которая позже будет использоваться для создания табличного пространства. Путь не является уникальным и зависит от расположения целевой базы данных, где хранятся файлы данных.
OgВойдите в базу данных
Вы можете получить табличное пространство текущей базы данных, как показано ниже:

Вы также можете войти в базу данных с помощью стороннего инструмента для выполнения вышеуказанного оператора SQL (также возможны следующие шаги)
*Заметка: Если имя табличного пространства импортируемой базы данных совпадает с именем текущего существующего табличного пространства, нет необходимости создавать новое табличное пространство (не может быть перестроено), но вы должны убедиться, что размер существующего табличного пространства достаточен, или он был настроен для автоматического увеличения и автоматического увеличения максимума. Если значение достаточно велико, расширять табличное пространство не нужно, просто используйте уровень табличного пространства напрямую, пропустите четвертый шаг. к
Напротив, если нет табличного пространства с именем или табличное пространство недостаточно велико для хранения импортируемых данных, табличное пространство необходимо расширить и выполнить четвертый шаг.
4. Расширение табличного пространства
Есть много способов расширить табличное пространство, кратко представив некоторые из распространенных методов:
① напрямую увеличить размер табличного пространства:
Сначала проверьте расположение файла данных в табличном пространстве
После определения местоположения файла данных выполните команду:
Измените размер файла базы данных «путь к файлу данных», чтобы изменить размер
например:
нота : Этот метод сообщит об ошибке при увеличении табличного пространства с табличными данными, указывая, что увеличение не удалось. Рекомендуется следующий метод
② увеличить количество файлов данных
Изменить имя табличного пространства табличного пространства Добавить файл данных «Путь к добавленному файлу данных» Размер файла данных
например:
③ Установите табличное пространство для автоматического расширения
Изменение файла данных базы данных - табличного пространства, подлежащего расширению, - автоматическое расширение до следующего размера блока расширения. Максимальный максимальный размер расширения.
например:
замечания Методы могут использоваться в комбинации, особенно если вы не уверены в окончательном размере импортируемого файла, например:
После расширения табличного пространства вы можете выполнить sql, чтобы проверить размер табличного пространства на шаге 3., чтобы убедиться, что расширение табличного пространства прошло успешно.
5. Создайте временное табличное пространство и табличное пространство данных
Перед созданием пользователя необходимо сначала создать два табличных пространства: временное табличное пространство и табличное пространство базы данных, в противном случае системное табличное пространство по умолчанию вызовет другие проблемы. к
TemporaryСоздать временное табличное пространство
Создайте временное имя табличного пространства временного табличного пространства временный файл - расположение временного табличного пространства - размер размера временного табличного пространства автоматически расширяется на следующие 100 м maxsize 10240 м локальное управление экстентом;
например:
TableСоздать табличное пространство данных
Параметры примерно такие же, как при создании временного табличного пространства
например:
нота : Если вы выполняете шаг 4., то есть табличное пространство расширяется вместо нового, вам не нужно создавать табличное пространство данных (но также необходимо создать временное табличное пространство - личное мнение)
6. Создайте пользователя базы данных и укажите табличное пространство
Этот пользователь используется для управления данными, которые будут импортированы. При импорте он также переключится на этого пользователя для операции импорта (если вы используете команду imp для импорта, лучше всего, если это имя пользователя совпадает с именем пользователя, используемым при экспорте. Если оно отличается, это может быть Нужно сделать картографию), формат такой:
Создать имя пользователя пользователя, идентифицированное паролем пользователя. Табличное пространство по умолчанию. Указанное имя табличного пространства. Временное табличное пространство. Временное имя табличного пространства.
например:
7. Предоставьте права пользователя
Поскольку пользователь будет использоваться для операций импорта, разрешения, которые должны быть предоставлены пользователю, включают как минимум разрешения dba, IMP_FULL_DATABASE, и некоторые люди предполагают, что они должны соответствовать разрешениям пользователя при экспорте данных базы данных. к
SQL авторизации: (в зависимости от конкретной ситуации)
Во-вторых, используйте команду exp / imp
Расширение знаний:
Роль экспорта и импорта данных (EXPDP и IMPDP)
1. Реализовать логическое резервное копирование и логическое восстановление. к
2, перемещать объекты между пользователями базы данных. к
3. Перемещение объектов между базами данных
4, реализовать движение табличного пространства. к
Разница между экспортом и импортом данных и традиционным экспортом и импортом:
До 10g традиционный экспорт и импорт используют инструмент EXP и IMP соответственно. Начиная с 10g, сохраняются не только оригинальные инструменты EXP и IMP, но и инструменты экспорта и импорта данных EXPDP и IMPDP. При использовании EXPDP и IMPDP вам следует Вопросы, требующие внимания:
EXP и IMP являются инструментальными программами на стороне клиента, их можно использовать как на стороне клиента, так и на стороне сервера. к
EXPDP и IMPDP являются инструментами на стороне сервера и могут использоваться только на стороне сервера ORACLE, а не на стороне клиента.
IMP применяется только к файлам экспорта EXP, но не к файлам экспорта EXPDP; IMPDP применяется только к файлам экспорта EXPDP, но не к файлам экспорта EXP.
1. Экспортная команда
Существует три способа экспорта и импорта:
ExportПолный режим экспорта (импорта):
Экспортируйте все содержимое базы данных, но для работы требуются специальные разрешения,
Exp username / password buffer = 32000 file = экспортированный каталог заполнен = y
например:
ExportПользовательский режим экспорта (импорта)
Экспортировать все объекты указанного пользователя, например:
Table Экспорт (импорт) табличный режим
Экспортируйте все данные таблицы пользователя, например:
замечания : Вы можете выполнить exp help = y, imp help = y, чтобы просмотреть справочные команды, и выполнить exp или imp, чтобы просмотреть соответствующий номер версии.
Шаги экспорта:
Сначала переключитесь на пользователя оракула (администратор базы данных)
Экспорт в соответствии с требуемым режимом экспорта
Параметр COMPRESS объединит фрагменты при экспорте, попытайтесь сжать данные в начальный экстент, по умолчанию N, как правило, рекомендуется. Параметр DIRECT сообщит EXP, что нужно читать данные напрямую, вместо использования SELECT для чтения данных в таблице, как в традиционном EXP, что уменьшает обработку операторов SQL. Как правило, рекомендуется. Однако в некоторых случаях параметр DIRECT не может быть использован. к
Другие параметры могут ссылаться на справочные команды или другие материалы для обучения. Я не буду повторять их здесь.
2. Импортировать команду
Войдите на сервер и переключитесь на пользователя оракула.
Выполнить команду импорта:
При импорте необходимо использовать нового пользователя, созданного в подготовительной работе, например: имя пользователя abc, пароль ABC
Imp username / password file = путь к файлу dmp log = полный путь к выходному журналу = y ignore = y;
например:
подсказки : Процесс импорта данных часто сталкивается с проблемами, поэтому рекомендуется обратиться к дополнительной информации, всегда есть способ ее решить. Я считаю, что всему есть необходимость в его существовании, проблема только временная, а успех неизбежен!
3. Используйте сторонние инструменты (возьмите PLSQL в качестве примера)
1. Введение в формат экспорта
① Формат Dmp: .dmp - это двоичный файл, который может быть кроссплатформенным и содержать разрешения, что является эффективным.
② Формат Sql: файлы в формате .sql можно просматривать с помощью текстового редактора. Он обладает большей гибкостью и не так эффективен, как первый. Он подходит для импорта и экспорта небольших данных. Особенно обратите внимание, что в таблице не может быть больших полей (blob, clob, long), если они есть, будет сообщено об ошибке.
③ Формат pde: файлы в формате .pde. .Pde - это собственный формат файлов PL / SQL Developer, который можно импортировать и экспортировать только с помощью инструмента PL / SQL Developer, и который нельзя просмотреть в текстовом редакторе. к
Примечания: Хотя формат dmp является наиболее предпочтительным, его нелегко реализовать по двум причинам: во-первых, этот формат требует установки полной версии oracle, поскольку при экспорте необходимо выбрать соответствующий exp.exe и imp.exe, а экспорт - это установленная версия для экспорта. Версия базы данных данных такая же, и то же самое применяется при импорте, иначе будут несовместимые версии (введенные в справочный материал, лично не подтвержденные), во-вторых, экспорт этого формата часто сталкивается с процессом экспорта в одно мгновение, но Причина неудачного экспорта неизвестна (вы можете сослаться на конфигурацию переменной среды. Конфигурация ORACLE_HOME верна, я пробовал много раз, но все еще есть проблемы, и, наконец, у меня нет выбора, кроме как экспортировать в формат pde).
2. Метод экспорта

Войдите в инструмент plsql. Используемый пользователь - это пользователь, имеющий разрешения на экспорт (exp_full_database, dba и т. Д.) Для исходной базы данных. к
Port Экспортировать оператор построения таблицы (включая структуру хранения)
Инструменты шага экспорта -> экспорт объекта пользователя, выберите объект для экспорта и экспортируйте файл .sql, как показано ниже:
Дождитесь завершения экспорта
Data Экспорт данных
Инструменты шага экспорта -> таблицы экспорта, выберите таблицу для экспорта и формат экспорта для экспорта. к
Экспорт в формат DMP, как показано ниже:

Экспорт в формат sql, как показано ниже:

Экспорт в формат pde, как показано ниже:

замечания : Если вы используете сторонний инструмент для экспорта и импорта всей базы данных, это займет много времени, и у вас должно быть достаточно времени для работы (это займет несколько часов, если объем данных большой)
3. Способ импорта
Интеллектуальная рекомендация
совместный запрос mysql с тремя таблицами (таблица сотрудников, таблица отделов, таблица зарплат)
1. Краткое изложение проблемы: (внизу есть инструкция по созданию таблицы, копирование можно непосредственно практиковать с помощью (mysql)) Найдите отделы, в которых есть хотя бы один сотрудник. Отоб.

[Загрузчик классов обучения JVM] Третий день пользовательского контента, связанного с загрузчиком классов

IP, сеанс и cookie
Я пытаюсь решить проблему, которая, на этот раз, я не создавал.
Я работаю в среде со многими веб-приложениями, поддерживаемыми различными базами данных на разных серверах.
каждая база данных довольно уникальна в своем дизайне и применении, но в каждой из них все еще остаются общие данные, которые я хотел бы абстрагировать. Каждая база данных, например, имеет таблицу поставщиков, таблицу пользователей и т. д.
Я хотел бы абстрагировать эти общие данные в один но все же пусть другие базы данных присоединяются к этим таблицам, даже имеют ключи для обеспечения ограничений и т. д. Я в среду в MSSQL.

какие варианты? Как я это вижу, у меня есть следующие варианты:
- связанные серверы
- только для чтения Логинов, чтобы дать доступ к представлениям
что-нибудь еще рассмотреть?
есть много способов решить эту проблему. Я настоятельно рекомендую либо решения 1, 2 или 3 в зависимости от ваших бизнес-потребностей:
Я использовал репликацию транзакций, чтобы вытеснить более 100 таблиц из хранилища данных для разделения нижестоящих приложений, которым необходим доступ к агрегированным данным из нескольких систем. Поскольку наше хранилище данных обновлялось ежечасно по расписанию из зеркальных и логарифмических источников данных, производственные приложения имели данные из многочисленных систем в пределах скользящего окна от 20 до 80 минут каждый час.
одноранговой репликация транзакций как тип публикации может быть лучше подходит для случая использования, который вы предоставили. Это может быть очень полезно, если вы хотите развернуть схему или репликацию изменений узла за узлом. Стандартная репликация транзакций имеет некоторые ограничения в этой области.
типы публикаций репликации моментальных снимков имеют большую задержку, чем публикации транзакций, но вы можете рассмотреть ее, если допустима степень задержки.
хотя вы упомянули Вы магазин Microsoft SQL Server, пожалуйста, имейте в виду, что другие СУБД имеют аналогичные технологии. Поскольку вы говорите о MS SQL Server конкретно, обратите внимание, что репликация транзакций также позволяет реплицироваться в базы данных Oracle. Так что если у вас есть несколько из них в вашей организации, это решение может работать.
недостатком использования репликации транзакций является то, что если вы центральный сервер идет вниз, вы можете начать испытывать задержку с данными в нижестоящих копиях реплицируемый объект. Если реплицированные объекты (статьи) действительно большие, и вам нужно повторно инициализировать таблицу, то это может занять очень много времени.
Связанные Серверы: похоже, вы уже думали об этом. Вы можете предоставить данные через связанные серверы. Я не думаю, что это хорошее решение. Если вы действительно хотите пройти этот маршрут, подумайте о настройке асинхронного зеркала из центральной базы данных на другой сервер, а затем настройте связанные подключения сервера к зеркалу. Это по крайней мере уменьшит риск того, что запрос из веб-приложений вызовет блокировку или проблемы с производительностью Центральной производственной базы данных.
IMO, связанные серверы, как правило, являются опасным методом обмена данными для приложения. Этот подход по-прежнему рассматривает данные как гражданина второго класса в вашей базе данных. Это приводит к некоторым довольно плохим привычкам кодирования, особенно потому, что ваши разработчики могут работать на разных серверах на разных языках с разными методами подключения. Вы не знаете, если кто-то напишет по-настоящему henious запрос против ваших основных данных. Если вы установили стандарт, который требует нажатия полной копии общих данных на неосновной сервер, вам не нужно беспокоиться о независимо от того, пишет ли разработчик плохой код. По крайней мере, с точки зрения того, что их плохой код не будет jeapordize производительность других хорошо написанных систем.
есть много, много ресурсов, которые объясняют, почему использование связанных серверов может быть плохим в этом контексте. Неисчерпывающий перечень причин включает: (a)учетная запись, используемая для связанного сервера, должна иметь разрешения DBCC SHOW STATISTICS, иначе запросы не смогут использовать существующую статистику, (b) подсказки запроса не могут быть uesd, если они не представлены как OPENQUERY, (c) параметры не могут быть переданы при использовании с OPENQUERY, (d) сервер не имеет достаточной статистики о связанном сервере, следовательно, создает довольно ужасные планы запросов, (e) проблемы с сетевым подключением могут вызвать сбои, (f) любой из этих пяти вопросов производительности, и (g)страшная ошибка контекста SSPI при попытке проверки подлинности учетных данных Windows active directory в двойном прыжке сценарий. Связанные серверы могут быть полезны для некоторых конкретных сценариев, но создание доступа к центральной базе данных вокруг этой функции, хотя и технически возможно, не рекомендуется.
массовый процесс ETL: если высокая степень задержки приемлема для веб-приложений, то вы можете написать массовые процессы ETL с SSIS (много хороших ссылок в этом вопросе StackOverflow) которые выполняются заданиями агента SQL Server для перемещения данных между сервера. Существуют также другие альтернативные инструменты ETL, такие как Informatica, Pentaho и т. д. используй то, что лучше для тебя.
Это не хорошее решение, если вам нужна низкая степень задержки. Я использовал это решение при синхронизации с сторонним CRM-решением для полей, которые могут переносить высокую задержку. Для полей, которые не могли выдержать высокую задержку (основные данные создания учетной записи), мы полагались на создание дубликатов записей в CRM через вызовы веб-службы в точке генерация счета.
ночное резервное копирование и восстановление: Если ваши данные могут переносить высокую степень задержки (до дня) и периоды недоступности, вы можете создавать резервные копии и восстанавливать базу данных в разных средах. Это не очень хорошее решение для веб-приложений, которым требуется 100% время работы. Идея заключается в том, что вы берете базовую резервную копию, восстанавливаете ее до отдельного имени восстановления, а затем переименовываете исходную базу данных и новую, как только новая будет готова к использованию. Я видел, как это делается для некоторых внутренних веб-приложений, но я обычно не рекомендую этот подход. Это лучше подходит для более низкой среды разработки, а не для производственной среды.
Журнал Доставки Вторичных: вы можете настроить доставку журналов между основным и любым количеством второстепенных. Это похоже на ночной процесс резервного копирования и восстановления, за исключением того, что вы можете обновлять базу данных чаще. В одном случае это решение было использовано для предоставления данных из одной из наших основных основных систем нижестоящим пользователям путем переключения между двумя получателями доставки журналов. Был еще один сервер, который указывал на две базы данных и переключался между ними, когда новая была доступна. Я действительно ненавижу это решение, но один раз я видел эту реализацию, она отвечала потребностям бизнеса.
Читайте также: