
Объясните почему с некоторого момента при повторном сжатии файла его размер увеличивается
Обновлено: 07.07.2024
В данной статье я расскажу вам о широко известном алгоритме Хаффмана, и вы наконец разберетесь, как все там устроено изнутри. После прочтения вы сможете своими руками(а главное, головой) написать архиватор, сжимающий реальные, черт подери, данные! Кто знает, быть может именно вам светит стать следующим Ричардом Хендриксом!
Да-да, об этом уже была статья на Хабре, но без практической реализации. Здесь же мы сфокусируемся как на теоретической части, так и на программерской. Итак, все под кат!
Немного размышлений
В обычном текстовом файле один символ кодируется 8 битами(кодировка ASCII) или 16(кодировка Unicode). Далее будем рассматривать кодировку ASCII. Для примера возьмем строку s1 = «SUSIE SAYS IT IS EASY\n». Всего в строке 22 символа, естественно, включая пробелы и символ перехода на новую строку — '\n'. Файл, содержащий данную строку будет весить 22*8 = 176 бит. Сразу же встает вопрос: рационально ли использовать все 8 бит для кодировки 1 символа? Мы ведь используем не все символы кодировки ASCII. Даже если бы и использовали, рациональней было бы самой частой букве — S — дать самый короткий возможный код, а для самой редкой букве — T (или U, или '\n') — дать код подлиннее. В этом и заключается алгоритм Хаффмана: необходимо найти оптимальный вариант кодировки, при котором файл будет минимального веса. Вполне нормально, что у разных символов длины кода будут отличаться — на этом и основан алгоритм.
Кодирование
Ни один код не должен быть префиксом другого
Это правило является ключевым в алгоритме. Поэтому создание кода начинается с частотной таблицы, в которой указана частота (количество вхождений) каждого символа:

Символы с наибольшим количеством вхождений должны кодироваться наименьшим возможным количеством битов. Приведу пример одной из возможных таблиц кодов:

Код каждого символа я разделил пробелом. По-настоящему в сжатом файле такого не будет!
Вытекает вопрос: как этот салага придумал код как создать таблицу кодов? Об этом пойдет речь ниже.
Построение дерева Хаффмана
Здесь приходят на выручку бинарные деревья поиска. Не волнуйтесь, здесь методы поиска, вставки и удаления не потребуются. Вот структура дерева на java:
Это не полный код, полный код будет ниже.
Вот сам алгоритм построения дерева:
- Извлечь два дерева из приоритетной очереди и сделать их потомками нового узла (только что созданного узла без буквы). Частота нового узла равна сумме частот двух деревьев-потомков.
- Для этого узла создать дерево с корнем в данном узле. Вставить это дерево обратно в приоритетную очередь. (Так как у дерева новая частота, то скорее всего она встанет на новое место в очереди)
- Продолжать выполнение шагов 1 и 2, пока в очереди не останется одно дерево — дерево Хаффмана

Здесь символ «lf»(linefeed) обозначает переход на новую строку, «sp» (space) — это пробел.
А что дальше?
Мы получили дерево Хаффмана. Ну окей. И что с ним делать? Его и за бесплатно не возьмут А далее, нужно отследить все возможные пути от корня до листов дерева. Условимся обозначить ребро 0, если оно ведет к левому потомку и 1 — если к правому. Строго говоря, в данных обозначениях, код символа — это путь от корня дерева до листа, содержащего этот самый символ.

Таким макаром и получилась таблица кодов. Заметим, что если рассмотреть эту таблицу, то можно сделать вывод о «весе» каждого символа — это длина его кода. Тогда в сжатом виде исходный файл будет весить: 2 * 3 + 2*4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 бит. Вначале он весил 176 бит. Следовательно, мы уменьшили его аж в 176/65 = 2.7 раза! Но это утопия. Такой коэффициент вряд ли будет получен. Почему? Об этом пойдет речь чуть позже.
Декодирование
Ну, пожалуй, осталось самое простое — декодирование. Я думаю, многие из вас догадались, что просто создать сжатый файл без каких-либо намеков на то, как он был закодирован, нельзя — мы не сможем его декодировать! Да-да, мне было тяжело это осознать, но придется создать текстовый файл table.txt с таблицей сжатия:
Запись таблицы в виде 'символ'«код символа». Почему 01110 без символа? На самом деле он с символом, просто средства java, используемые мной при выводе в файл, символ перехода на новую строку — '\n' -конвертируют в переход на новую строку(как бы это глупо не звучало). Поэтому пустая строка сверху и есть символ для кода 01110. Для кода 00 символом является пробел в начале строки. Сразу скажу, что нашему коэффициенту ханаэтот способ хранения таблицы может претендовать на самый нерациональный. Но он прост для понимания и реализации. С удовольствием выслушаю Ваши рекомендации в комментариях по поводу оптимизации.
Имея эту таблицу, очень просто декодировать. Вспомним, каким правилом мы руководствовались, при создании кодировки:
Ни один код не должен являться префиксом другого
Реализация
Пришло время унижать мой код писать архиватор. Назовем его Compressor.
Начнем с начала. Первым делом пишем класс Node:
Класс, создающий дерево Хаффмана:
Класс, облегчающий чтение из файла:
Ну, и главный класс:
Файл с инструкциями readme.txt предстоит вам написать самим :-)
Заключение
Наверное, это все что я хотел сказать. Если у вас есть что сказать по поводу моей некомпетентности улучшений в коде, алгоритме, вообще любой оптимизации, то смело пишите. Если я что-то недообъяснил, тоже пишите. Буду рад услышать вас в комментариях!
Да-да, я все еще здесь, ведь я не забыл про коэффициент. Для строки s1 кодировочная таблица весит 48 байт — намного больше исходного файла, да и про добавочные нули не забыли(количество добавленных нулей равно 7)=> коэффициент сжатия будет меньше единицы: 176/(65 + 48*8 + 7)=0.38. Если вы тоже это заметили, то только не по лицу вы молодец. Да, эта реализация будет крайне неэффективной для малых файлов. Но что же происходит с большими файлами? Размеры файла намного превышают размер кодировочной таблицы. Вот здесь-то алгоритм работает как-надо! Например, для монолога Фауста архиватор выдает реальный (не идеализированный) коэффициент, равный 1.46 — почти в полтора раза! И да, предполагалось, что файл будет на английском языке.
Выпустил upgrade: добавил GUI + изменил алгоритм обработки исходного текста так, чтобы не читать весь файл в память. Короче, кидаю ссылку на git для любознательных: сами всё увидите.
Благодарности
Как и автор каждой хорошей книги, я созидал эту статью не без помощи других людей. Имхо, очень мало людей сделало что-то крутое в одиночку.
Огромное спасибо Исаеву Виталию Вячеславовичу за небходимую теоретическую поддержку.
Также, часть материала этой статьи взята из книги Роберта Лафоре «Data Structures and Algorithms in Java». Если сомневаетесь как или окуда начать свой путь в теории алгоритмов и структур данных — берите, не прогадаете.

Как отправлять большие файлы PDF по электронной почте.
Основываясь на идее, что заархивированный файл - это новый двоичный файл, почему я не могу уменьшить размер Zip-архива, архивируя его снова и снова - до очень маленького результирующего файла?
- 3 По теме: Могу ли я снова сжать файл RAR, чтобы уменьшить его размер?
Основываясь на идее, что заархивированный файл - это новый двоичный файл, почему я не могу уменьшить его размер, повторно заархивируя его до очень маленького файла?
Поскольку сжатие работает на основе поиска закономерностей и сокращения похожих данных.
Например, RLE (кодирование длин серий) - это простой метод сжатия, при котором данные проверяются, а серии похожих данных сжимаются следующим образом:
Как видите, заменяя повторяющиеся данные только данными и подсчетом того, сколько раз они встречаются, вы можете уменьшить этот конкретный пример с 35 до 20 байтов. Это не огромный снижение, но все равно на 42% меньше. Более того, это небольшой надуманный пример; более крупные примеры из реальной жизни могут иметь еще лучшее сжатие. (The OO остался один, потому что заменил его на 2O ничего бы не спасло.)
Текстовые файлы часто сжимаются очень хорошо, потому что они, как правило, содержат множество шаблонов, которые можно сжать. Например, слово в очень распространен в английском языке, поэтому вы можете отбросить каждое отдельное слово с идентификатором, который состоит только из одного байта (или даже меньше). Вы также можете сжать больше с части слов, похожих на cAKE , bAKE , shAKE , undertAKE , и так далее.
Так почему же вы не можете сжать уже сжатый файл? Потому что, когда вы выполняли начальное сжатие, вы удалил шаблоны.
Посмотрите на сжатый пример RLE. Как можно это сжать дальше? Нет серий идентичных данных для сжатия. На самом деле, часто, когда вы пытаетесь сжать уже сжатый файл, вы можете получить больше файл. Например, если вы принудительно перекодировали приведенный выше пример, вы можете получить что-то вроде этого:
Теперь данные сжатия (счетчики запусков) сами обрабатываются как данные, так что вы получаете файл большего размера, чем был в начале.
Что ты мог try - использовать другой алгоритм сжатия, потому что возможно, что результат одного алгоритма сжатия может быть первичным для другого алгоритма, однако это обычно маловероятно.
Конечно, речь идет о сжатии без потерь, когда распакованные данные должны быть в точности идентичны исходным данным. При сжатии с потерями обычно можно удалить больше данных, но качество падает. Кроме того, сжатие с потерями обычно использует какую-то схему на основе шаблонов (это не только отбросить данные), так что в конечном итоге вы все равно достигнете точки, где просто не будет шаблонов для поиска.
Файл, который был оптимально сжат, не будет иметь шаблонов или чего-либо, что можно уменьшить.
Представим себе простой файл, содержащий это.
Если мы сжимаем его, мы можем сказать, что это 20 знаков A, новая строка, за которыми следуют 20 B, новая строка, а затем 20 C. Или что-то вроде 20xA\\\\n20xB\\\\n20xC\\\\n . После того, как мы выполнили первое сжатие, новых шаблонов для сжатия не будет. Каждый бит информации уникален.
Если все сжатые файлы после повторного сжатия уменьшат свои размеры (или будут иметь размеры не больше, чем их родительские), то в какой-то момент размер станет равным 0, что не может быть правдой. Если это правда, нам практически не нужны файловые хранилища.
Я бы сказал, ты не можешь сжать произвольный двоичные файлы в значительной степени - подумайте об изображениях JPEG, видео x264 и так далее. Тем более, что вы хотите реконструировать ваш исходный файл точно (т.е. побитно) вам понадобится сжатие без потерь. 1
Энтропия эффективно ограничивает производительность сильнейшего возможного сжатия без потерь (или почти без потерь), которое может быть реализовано теоретически с использованием типичного набора или на практике с использованием кодирования Хаффмана, Лемпеля-Зива или арифметического кодирования. (. )
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
3–5 декабря, Онлайн, Беcплатно
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
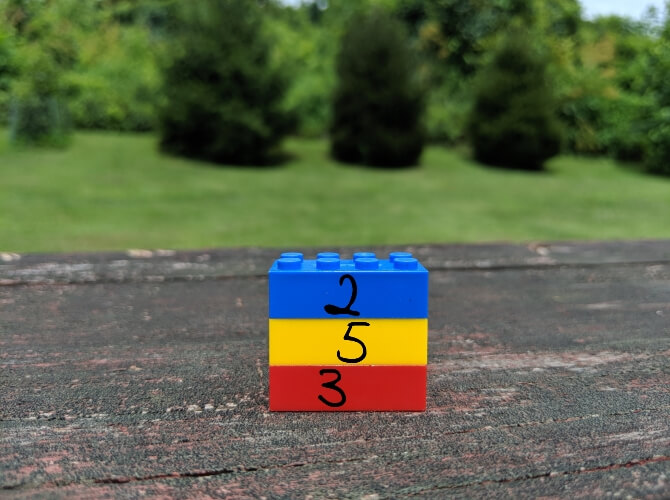
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Э-э, в цифровом видео как это произойдет (именно ШУМЫ проникнут)? Да, при Full Processing у вас будет распаковка в RGB а потом обратно в ту или иную разновидность YUV представления и сжатие. ТЕОРЕТИЧЕСКИ возможно проникновение части данных из каналов цветности (точнее - цветоразностных каналов) в канал яркости. Но настолько мизерные .
Тут простое объяснение про DirectStream Copy если видео не меняете (кроме резки) - не будет повторного пережатия, значит, доп. искажений не будет, особенно при сильным сжатии.
Откуда она взялась (АВИшка) и отчего решили, что несжатое? С фотика/видеокамеры/телефона? Так там сжатие всегда используется то или иное.
Или такое возможно объяснение именно 50% увеличению размера - да, у вас было типа несжатое видео, но с форматом пикселя YUY2, например, что соответствует 16 битам на пиксель. VirtualDub при FullProcessing режиме (дефолтный для видео)преобразует в RGB 24 бита на пиксель. И так и сохранит результат, если тут же пересохраняете без компрессии. Вот вам и 50% увеличение.
Ну как вам сказать . От задачи зависит. Если тупо порезать видео без эффектов и наложений и сохранить в AVI с нужным сжатием - Виртуал Даб прост, бесплатен и легок в освоении. И нетребователен к ресурсам компа (в отличие от полноценных современных монтажек). У автора темы проблемы со свободным местом на ЖД, например, уже присутствует.
Да и , действительно, ту же чистку от шумов в нем (+ AVISynth, если есть желание) делать проще и эффективнее.
Если что - я начинал с Премьера, долго основной монтажкой был Ликвид, работал и с Вегасом (еще с первым в том числе) и с Пиннаклевскими студиями. В FCP было дело монтажил одно время. Поэтому защищаю VirtualDub не от неумения работать в "больших" монтажках, а потому, что и у него есть своя ниша, где он эффективнее того же Премьера, скажем.
Все - IMHO, конечно :-) А вот про преобразование YUY2 в RGB24 я чет сразу и не подумала))) Ну конечно же.
А что там вы говорите про шумы, которые проникают? откуда они проникают и куда? Хотя для меня это уже высшая математика((( Но все равно интересно.
Сама то я снимаю на цифровую камеру. А вот те "АВИшки" о которых я писала, у меня в результате оцифровки аналоговых видеоматериалов архива школы. За 20 лет накопилось много чего интересного из жизни школы, но 90% надо вырезать, просто неинтересный никому балласт. некоторые кассеты уже стали уникальными. Поэтому пришло решение перевести все в цифру, в будущем можно будет смонтировать интересные ролики.
Только для вас рассказываю на простом языке. Если вы оцифровали аналоговое видео, то у вас формат представления данных трехканальный, но не красно-сине-зеленый как в фотографии, а чернобелый-красный-синий. Зеленого нет. Так принято в видеозаписи. Для красного и синего используется вдвое и даже в четверо меньше данных, чем для чернобелого, потому что в них об'единяют по два или по четыре пиксела в один цвет.
Если бы все видеоредакторы работали в таком формате, это было бы здорово. Но Дуб работает в RGB и в нем же сохраняет результат. Это связано с тем, что большинство фильтров для Дуба работают в RGB, потому что их исходный код позаимствован из фотофильтров.
Вас могло сбить с толку то что в выпадающем меню "компрессия" первым пунктом стоит "без сжатия RGB/yuv". Но никакого "yuv" там нет. И судя по ответу Эвери Ли в обозримом будущем не будет. Только RGB. И в каком бы представлении данные о цвете ни были бы на входе, нa выходе всегда будет RGB.
Теперь о шумах. Не тех, что доносятся в окно с улицы, а об электрических. Вы замечали, что когда телевизор показывает хорошо, то картинка чистая, а когда плохо, то она с мурашками. Эти мурашки и есть шумы. Если убавить цвет до нуля, то получится чернобелое изображение и шумов на нем будет гораздо меньше. Если посмотреть внимательно, то на чернобелой картинке шумы в виде быстрых мелких снежинок и крупинок. А если добавить цвет, то появятся более медленные красные и синие пятнышки и черточки.
С шумами надо бороться и не только потому что они портят красивую картинку, а еще потому что они мешают эффективному сжатию файла. И даже если шумов не видно на экране, они все равно есть и немалые, и не дают нормально сжаться файлу. Убедиться в этом можно просматривая на осциллографе видеосигнал, подаваемый на монитор. Для борьбы с ними применяют фильтры. Но фильтры для удаления чернобелых и для цветных шумов работают по разным алгоритмам. Поэтому никогда нельзя допускать, чтобы эти шумы смешались. Но как только видео сохранится в RGB, то шумы смешаются и все пропало!
Всегда надо следить чтобы в Дубе стояла галочка "прямая копия потока". А если стоит галочка "режим полной обработки", то независимо от целей и задач вашей работы ВСЕГДА первым применяйте фильтр "колорденойзер", например ССD от Сергея Столяровского.
Ну как то так)))
Читайте также: