
Oracle найти таблицу по полю
Обновлено: 08.07.2024
Добрый день!
Можно ли на SQL написать запрос к базе данных Oracle, который бы выполнил поиск строкового значения по ячейкам всех имеющихся таблиц и вывел в качестве результата список имён этих таблиц (в которых присутствует искомое значение) ?
Может у кого есть подобный уже готовый примерчик?
Или есть стандартные средства реализующие подобный функционал?
Заранее спасибо
-------
"Не соглашайся ни на что, кроме совершенства!" - Анонимный автор.
"Совершенство достигается только к моменту полного краха." - К.Н.Паркинсон.
Любопытно, с какой целью такое потребовалось.
-------
*Origin: Lots of people talking, few of them - no. (2:5020/****.**)
Для отключения данного рекламного блока вам необходимо зарегистрироваться или войти с учетной записью социальной сети.
EvgeniyQQQ, встроенными путями такое сделать не получится. Необходимо минимум 2 цикла - первый берет список таблиц из указанной базы, второй - список полей в таблице . Ну и далее уже в циклах - выборка. noname00.pas, есть у нас PLM-система, она использует СУБД Oracle. Я проводил эксперименты с помощью внешнего приложения, вносил и удалял некоторую информацию. это приложение обращается к базе не напрямую, а через саму PLM. Так вот, я удалил идентификатор одного объекта PLM с помощью внешнего приложения. Пока PLM была запущена, всё работало, но стоило её перезапустить, как она стала ругаться, что не может найти объект с удалённым мной идентификатором и при этом вылетает (завершает свою работу). Вернуть идентификатор на место с помощью внешнего приложения я не могу, так как PLM не запущена. Остаётся только внести его назад в базу в ручную. но вот засада. таблиц много. очень много, а где хранятся идентификаторы не известно С помощью поиска я хочу попытаться найти таблицу в которой хранятся идентификаторы.-------
"Не соглашайся ни на что, кроме совершенства!" - Анонимный автор.
"Совершенство достигается только к моменту полного краха." - К.Н.Паркинсон.
Так как в SQL я чайник и разбираться нет времени, то написал поиск используя симбиоз Java и SQL.
Вот сам код, может кому пригодится:
-------
"Не соглашайся ни на что, кроме совершенства!" - Анонимный автор.
"Совершенство достигается только к моменту полного краха." - К.Н.Паркинсон.
Можно ли искать каждое поле каждой таблицы для определенного значения в Oracle?
В некоторых таблицах есть сотни таблиц с тысячами строк, поэтому я знаю, что это может занять очень много времени. Но единственное, что я знаю, это то, что значение для поля, к которому я хотел бы запросить, - это 1/22/2008P09RR8 . <
Я попытался использовать этот оператор ниже, чтобы найти соответствующий столбец, основанный на том, что, по моему мнению, он должен быть назван, но не дал никаких результатов.
В этой базе данных нет документации, и я понятия не имею, откуда это поле извлекается.
Я пробовал использовать этот оператор ниже найти соответствующий столбец на основе что я думаю, это нужно назвать, но это не получило результатов. *
Столбец не является объектом. Если вы имеете в виду, что вы ожидаете, что имя столбца будет похоже на "% DTN%", запрос, который вы хотите, следующий:
Но если строка "DTN" - это просто догадка с вашей стороны, это, вероятно, не поможет.
Кстати, насколько вы уверены, что "1/22/2008P09RR8" - это значение, выбранное непосредственно из одного столбца? Если вы вообще не знаете, откуда это происходит, это может быть конкатенация нескольких столбцов или результат некоторой функции или значение, находящееся в вложенном объекте таблицы. Таким образом, вы можете оказаться на дикой охоте на гусей, пытаясь проверить каждый столбец за это значение. Не можете ли вы начать с того, какое клиентское приложение отображает это значение и попытаться выяснить, какой запрос он использует для его получения?
В любом случае, ответ diciu дает один метод генерации SQL-запросов для проверки каждого столбца каждой таблицы для значения. Вы также можете делать подобные вещи полностью в одном сеансе SQL, используя блок PL/SQL и динамический SQL. Вот несколько поспешно написанный код для этого:
Есть несколько способов сделать его более эффективным.
В этом случае, учитывая значение, которое вы ищете, вы можете четко исключить любой столбец с типом NUMBER или DATE, что уменьшит количество запросов. Возможно, даже ограничьте его столбцами, где тип похож на "% CHAR%".
Вместо одного запроса на столбец можно построить один запрос для таблицы следующим образом:
Как запросить базу данных Oracle, чтобы отобразить имена всех таблиц в ней?
@MartinThoma Нету. попробовал сначала, прежде чем прибегнуть к GoogleЭто предполагает, что у вас есть доступ к представлению DBA_TABLES словаря данных. Если у вас нет этих привилегий, но они нужны, вы можете запросить, чтобы администратор БД явно предоставил вам привилегии для этой таблицы, или чтобы администратор БД предоставил вам SELECT ANY DICTIONARY привилегию или SELECT_CATALOG_ROLE роль (любая из которых позволит вам запросить любую таблицу словаря данных). ). Конечно, вы можете захотеть исключить определенные схемы, такие как SYS и SYSTEM имеющие большое количество таблиц Oracle, которые вам, вероятно, не нужны .
Кроме того, если у вас нет доступа DBA_TABLES , вы можете просмотреть все таблицы, к которым у вашей учетной записи есть доступ, через ALL_TABLES представление:
Хотя это может быть подмножеством таблиц, доступных в базе данных ( ALL_TABLES показывает информацию обо всех таблицах, к которым у вашего пользователя есть доступ).
Если вас интересуют только те таблицы, которыми вы владеете, а не те, к которым у вас есть доступ, вы можете использовать USER_TABLES :
Поскольку он USER_TABLES содержит информацию только о тех таблицах, которыми вы владеете, у него нет OWNER столбца - владельцем по определению является вы.
Oracle также имеет ряд устаревших данных словаря views-- TAB , DICT , TABS и CAT для example-- , которые можно было бы использовать. В целом, я бы не советовал использовать эти устаревшие представления, если вам абсолютно не нужно перенести свои сценарии в Oracle 6. Oracle не изменяла эти представления в течение длительного времени, поэтому у них часто возникают проблемы с объектами более новых типов. Например, TAB и CAT представления, и представления показывают информацию о таблицах, которые находятся в корзине пользователя, в то время как [DBA|ALL|USER]_TABLES все представления отфильтровывают их. CAT также показывает информацию о материализованных журналах представлений с TABLE_TYPE «TABLE», что вряд ли будет тем, что вы действительно хотите. DICT объединяет таблицы и синонимы и не говорит вам, кто владеет объектом.
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
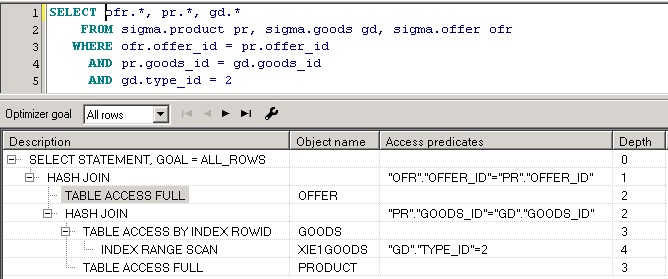
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
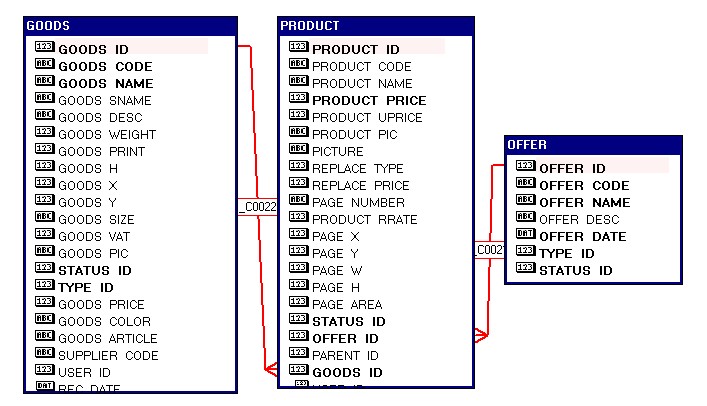
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
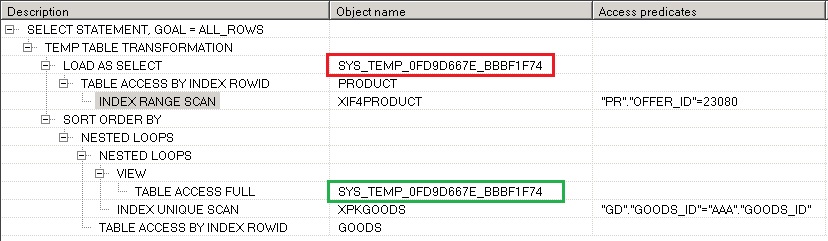
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Читайте также: