
Oracle перенести таблицу в другую схему
Обновлено: 02.07.2024
и оттуда же:
In general, the COPY command was designed to be used for copying data between Oracle and non-Oracle databases. You should use SQL commands (CREATE TABLE AS and INSERT) to copy data between Oracle databases.
> да и чем плох exp/imp?
Не в службу,а в дружбу - научи, как в базу с кодировкой AL32UTF8 и NLS_LENGTH_SEMANTICS = CHAR импортировать базу в кириллице с длинными значениями строковых полей ?
> PS У автора как-будто проблема с разными кодировками и семантиками
> не стояла?
Это у меня проблема
Беда в том, что файл экспорта гигабайт так на 200, да и CHAR там не в одном месте находится.
Можно подробности:
Исходная база данных в CL8MSWIN1251, надо импортировать в AL32UT8, NLS_LENGTH_SEMANTICS в базе данных экспорта - BYTE, в базе данных импорта CHAR. Так сделано для того, чтобы импортируемые таблицы создавались во время иморта, с учетом семантики CHAR, таблиц много, данных тоже.
База с WIN1251 создана с NLS_LENGTH_SEMANTICS по умолчанию. А это был BYTE на момент создания. Хотелось бы максимально безболезненно перелить ее в юникодную базу.
Таблиц много, данных много, размер файла полного эскпорта я озвучил.
1. на базе с NLS_LENGTH_SEMANTICS=BYTE скриптом для всех таблиц с char/varchar2: alter table modify с увеличением размера поля в 4 раза, после чего экспорт и заливка в базу NLS_LENGTH_SEMANTICS=CHAR.
2. в базе с NLS_LENGTH_SEMANTICS=CHAR создать все таблицы(например, из экспорта метаданных базы с BYTE) и увеличить размеры всех полей char/varchar2 в раза, после чего сделать экспорт из базы BYTE и залить в базу CHAR.
Невозможно по определению. База readonly
Спасибо за ссылку.
Как минимум прочитал, что:
"You cannot just export data, and import it into a character semantics database, because export/import preserves original semantics of the exported tables."
Последняя ссылка в дискуссии, увы, не открывается.
В свое время (небольшую базу) пришлось переносить потаблично, PL/SQL Developer-ом, через INSERT-ы. Объем побольше, тоже потаблично, через INSERT INTO SELECT FROM database link.
Еще одна трудность в том, что в желаемой к переносу базе таблиц порядка двух тысяч, писать нужную последовательность, мягко говоря, небыстро.
В предыдущих вариантах слегка поменьше.
Разве Оракл не поддерживает такой формы как INSERT INTO db1. SELECT FROM db2.
Целиком все объекты за один раз ? Поддерживает, называется экспорт/импорт :)
Ну вопрос то был про единственную таблицу, а тут уже монстр вырисовывается, но алгоритм такой же, нужно только чтобы автоинкримент отключался и копировалось как есть.
After you pre-create the schema with the new semantics, you can import the data from the original (source) database with IGNORE=Y. The original semantics saved in the export file will be ignored for pre-created objects.
чем не решение?
Вот это место имеется в виду:
"The original semantics saved in the export file will be ignored for pre-created objects."
Боюсь, что замучаюсь. Сейчас посмотрел файл от дампа небольшой базы, imp show=y нагенерировал 2 мегабайта SQL, пока я из него вытащу нужные объекты, с меня семь потов сойдет.
Почему, собственно, озаботились проблемой без предварительного создания объектов: довольно трудно найти актуальный скрипт для конкретного дампа, объектов, как я и говорил, довольно много, даже по частям их выковыривать не очень удобно.
CREATE UNIQUE INDEX .
ALTER TABLE FOOBAR ADD CONSTRAINT foobar_pk PRIMARY KEY (id) .
в SQL*Plus первой командой выдана ALTER SESSION SET NLS_LENGTH_SEMANTICS=CHAR
выполнен скрипт на создание таблицы
imp foo/bar@ora11u ignore=Y tables=(FOOBAR) fromuser=FROMUSER touser=TOUSER file=expdat.dmp log=foobar.log
ну и, соответственно, данные оттуда
select length(name_nat),lengthb(name_nat) from foobar where rownum < 10
Видно, что как минимум одно из значений длины в байтах (45) больше, чем объявленное при создании таблицы 32
а максимальное значение длины в байтах для этого поля - 48.
кстати, если есть поля пользовательского типа (create type), то метод и вовсе не сработает
PL/SQL умеет делать объектов базы данных с учетом зависимостей. Я в [14] писал, что пользовался. Беда в том, что на больших объемах этот процесс слегка затруднителен.
> Далее пишется процедурка для переноса данных:
И это он тоже умеет, сам.
> Да, умеет. Но многомегабайтный sql, состоящий из кучи insert
> values и работать будет не один час. Гораздо быстрее отработает
> insert select, а dblink сделать не так уж и затруднительно
> :)
ты пост [14] почитай :)
объектов много. в сумме десяток тысяч, из них пара тысяч - таблицы.
> Но многомегабайтный sql
Ты хотел сказать - многогигабайтный :)
В данном материале рассмотрим вопрос перемещения страницы в другое табличное пространство с использованием SQL запроса (команды) alter table xxx move tablespace zzz . В приводимом ниже примере перемещения применялся сервер Oracle 9.2i .
В результате перемещения таблицы в другое табличное пространство достигается очевидная цель - освободить место в разросшемся табличном пространстве. В ответе на вопрос на странице http://www.dba-oracle.com/t_alter_table_move_shrink_space.htm Donald Burleson утверждает, что метод move в отличии от использования запроса alter table mytable shrink space ( не доступен в Oracle 9) не позволяет уменьшить суммарный размер выделенных под таблицу экстентов памяти. Так вот - это не так. Если из таблицы удалено много строк, экстенты с блоками, выше HWM (High Water Mark - номер последнего использованного блока экстентов таблицы при последовательном их рассмотрении) - удаляются. И , кроме того, при перемещении таблицы удается избавиться от так называемых сцепленных и перемещенных строк. Как правило сцепление снижает производительность запроса, поскольку ORACLE вынужден искать одну строку в несколько приемов. Помимо сцепления строк ORACLE может перемещать их. Если строка превышает доступное в блоке место она может быть включена в другой блок. Процесс перемещения строки из одного блока в другой называется "миграцией" строк. . В ходе самого процесса ORACLE динамически управляет местом в нескольких блоках, а так же обращается к списку свободных для вставки данных блоков (free list). По своей сути перемещенная строка не является сцепленной, но перемещение влияет на производительность транзакции в целом!
Команду alter table xxx move tablespace zzz имеет смысл выполнять, когда в таблице много не используемых блоков ниже HWM, и когда таблица имеет сцепленные строки. Для этого достаточно выполнить два запроса
Последний запрос показывает количество обнаруженных в таблице сцепленных или перемещенные строк, а также оценку HWM (поле blocks). Если же нужна детальная информация о таких строках, то воспользуемся следующим способом.
Создадим таблицу CHAINED_ROWS с использованием утилиты rdbms/admin/utlchain.sql , которая содержит следующий код
После создания таблицы запрос analyze table xxx LIST CHAINED ROWS занесет в таблицу chained_rows информацию о всех сцепленных и перемещенных строках таблицы ххх . Если на первичный ключ таблицы не ссылаются другие таблицы, то для устранения сцепления и перемещения строк можно воспользоваться следующим способом.
- Изменим, при необходимости, параметры хранения таблицы ххх .
- Выполним запрос
- Удалим перемещенные и сцепленные строки их таблицы ххх
- Восстановим удаленные строки
- Удалим промежуточную таблицу xxx_tmp и соответствующие ей записи из таблицы chained_rows .
Все достаточно просто, но с таблицей обычно связаны внешние ключи других таблиц, и если этот ключ создан с опцией каскадного удаления, то мы потеряем записи в других таблицах.
Например , если мы обратимся к БД АСР "Фастком" с запросом select Cc.Table_Name,Cc.Column_Name, c.* from Dba_Constraints c,Dba_Cons_Columns cc where c.R_Owner='FASTCOM25P'
and C.r_Constraint_Name(+)=Cc.Constraint_Name
and cC.Table_Name='CT_T_CONTRACT'
order by C.Constraint_Name, то получим
Сразу видно, что удалить строку договора не удастся. Но и применять команду move к такой таблице без проверки не следует. Только в тестовой БД.
Перемещение таблицы можно выполнять без указания табличного пространства. В этом случае будет создан новый сегмент в том же табличном пространстве. На время перемещения таблица блокируется. Опция online применима только для индекс-ориентированных таблиц. Для обычных таблиц она не имеет смысла. Но перемещение происходит очень быстро.
Перемещение происходит успешно, перестроились все индексы, определенные на таблице. Индексы не имеет смысла перестраивать с опцией online, так как они не валидны. Теперь можно убедиться, что HWM не возрос и исчезли сцепленные и перемещенные строки. Об этом говорилось выше.
Для проверки использовались следующие коды.
Создадим тестовую таблицу и заполним ее данными
Конечно, таблица не содержит сцепленных строк. Так создадим их
Посмотрим экстенты таблицы
Удалим строки и переместим таблицу. Посмотрим экстенты и наличие сцепленных строк.
Общий размер экстентов уменьшился на 512 блоков, HWM уменьшился и в таблице не осталось сцепленных строк. Индексов мы на таблице не создавали, значит и перестраивать нечего.
у меня есть секционированная таблица, которая принадлежит tablespace отчет. Я хочу переместить его в табличное пространство запись вместо.
одна из возможностей-удалить таблицу и воссоздать ее в новом табличном пространстве, но это не вариант для меня, так как в таблице есть данные, которые должны выжить при перемещении.
Я начал с проверки того, что разделы фактически принадлежат отчету табличного пространства с:
тогда я просто попробовал:
но это дает мне ошибку ORA-145111 "не удается выполнить операцию над секционированным объектом".
затем я узнал, что могу перемещать отдельные разделы, используя:
но поскольку есть 60 разделов таблицы (на основе даты), и поскольку мне, возможно, придется сделать это для нескольких систем, я хотел бы перебрать все имена разделов, перемещая каждый в новое табличное пространство. Я попытался это сделать, но не смог заставить SQL работа.
даже если я перемещаю все существующие разделы в новое табличное пространство, все равно возникает проблема при создании новых разделов. Новые разделы по-прежнему создаются в старом табличном пространстве отчет. Как изменить, чтобы новые разделы создавались в новом табличном пространстве запись?
вы должны рассмотреть индексы, которые также могут быть признаны недействительными - чтобы покрыть ваш вопрос о сбросе табличных пространств по умолчанию в дополнение к этому, я думаю, что это полный процесс, который вы хотите реализовать:
1) перемещение разделов (цикл PL/SQL в соответствии с ответом zürigschnäzlets)
Это процедуры, которые я использую в анонимной оболочке блока, которая определяет a_tname, a_destTS, vTname и vTspName - они должны дать вам общее идея:
2) Установите табличное пространство раздела таблицы по умолчанию, чтобы там создавались новые разделы:
3) Установите табличное пространство раздела индекса по умолчанию, чтобы новые разделы индекса (если они есть) создавались там, где вы хотите:
4) перестроить любые секционированные индексы, которые нуждаются в перестроении и не находятся в нужном табличном пространстве:
5) перестроить любой глобальный индексы
вы можете сделать это с помощью PL / SQL или создать операторы с sql. Я решил сгенерировать операторы alter table с помощью простого SQL:
вы можете выполнить вывод из предыдущего оператора.
каждый пользователь имеет табличное пространство по умолчанию. Новые объекты базы данных создаются в табличном пространстве по умолчанию, если при создании/изменении не указано ничего другого
Привет, сейчас мы с Вами рассмотрим технологию Oracle Data Pump, с помощью которой мы можем экспортировать данные в дамп и импортировать данные из дампа в СУБД Oracle. Эта технология подразумевает использование утилит expdp и impdp, которые заменяют традиционные exp и imp, и сегодня мы с Вами научимся использовать их для создания дампа базы данных и импорта данных из этого дампа.
Как Вы, наверное, уже догадались, сейчас речь пойдет о СУБД Oracle, а именно о технологии Oracle Data Pump и начнем мы, конечно же, с обзора данной технологии.
Что такое Oracle Data Pump?

Oracle Data Pump – это технология позволяющая экспортировать и импортировать данные и метаданные в СУБД Oracle Database в специальный формат файлов дампа.
Данная технология впервые появилась в версии 10g и включается во все последующие версии Oracle Database. Для экспорта и импорта данных до Oracle Data Pump, т.е. до версии 10g, использовались традиционные утилиты exp и imp, возможности которых в 10 и выше версиях сохранены в целях совместимости. Особенностью Oracle Data Pump является то, что экспорт и импорт данных происходит на стороне сервера, dmp-файл формируется на файловой системе сервера, а также главным преимуществом Oracle Data Pump перед традиционным способом экспорта и импорта данных является более быстрая выгрузка и загрузка данных.
В Oracle Data Pump для экспорта и импорта данных созданы новые серверные утилиты expdp и impdp. Формат файлов дампа (dmp) используемый в этих утилитах, несовместим с форматом, который используется в exp и imp.
Expdp – утилита для экспорта данных в СУБД Oracle Database в дамп.
Impdp – утилита для импорта данных в СУБД Oracle Database из дампа.
Утилиты expdp и impdp поддерживают несколько режимов работы:
Для того чтобы посмотреть подробную справку (описание параметров) по этим утилитам запустите их с параметром help=y, например
Примечание! Запуск утилит в операционной системе Windows запускается из командной строки. В случае если системный каталог bin СУБД Oracle не добавлен в переменную среды Path, то запускать утилиты нужно из данного каталога, т.е. предварительно перейдя в него (например, с помощью команды cd). Для демонстрации примеров ниже я использую Oracle Database Express Edition 11g Release 2 установленный на операционной системе Windows 7.
Пример создания дампа базы данных Oracle с помощью expdp
Для того чтобы создавать дампы в Oracle с помощью утилиты expdp предварительно необходимо определится с логической директорией, в которую Вы будете экспортировать дампы, т.е. где они будут храниться. Можно использовать стандартную директорию DATA_PUMP_DIR, но Вы, если хотите, можете создать новую, конкретно для Ваших целей отдельную директорию. Давайте создадим отдельный каталог для наших задач с экспортом и импортом данных, заодно и научимся создавать такие директории.
Сначала создаем каталог в файловой системе, например, я создал D:\OracleEX\ExportImport.
Затем уже создаем директорию в Oracle, для этого открываем SQL*Plus или SQLDeveloper и запускаем следующую команду (я запустил в SQL*Plus и директорию назвал ExportImport).
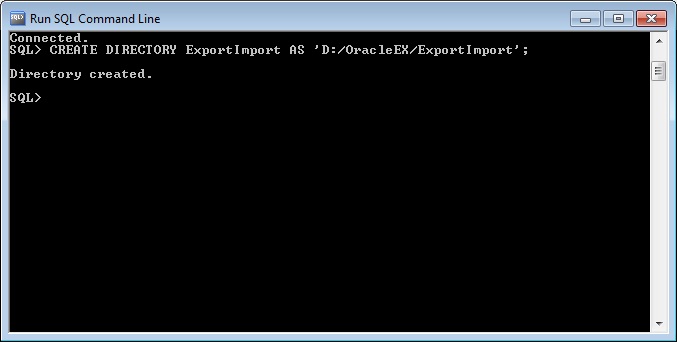
Чтобы посмотреть, какие директории уже созданы, можете использовать следующий запрос.
Теперь давайте перейдем непосредственно к экспорту. Я все действия выполнял от имени системного пользователя Oracle.
Создание дампа всей базы данных
Для того чтобы создать полный дамп базы данных выполните следующую команду в командной строке
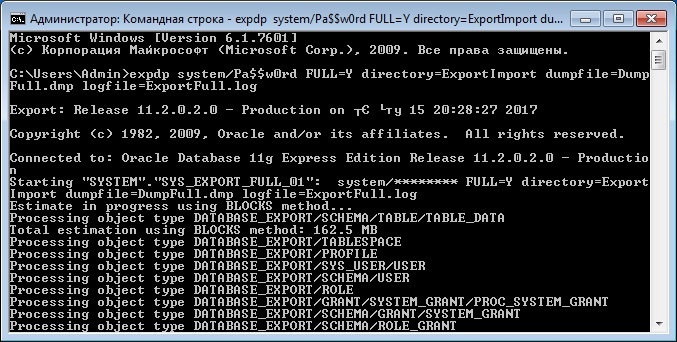
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- FULL=Y – параметр, который указывает, что мы делаем полный экспорт базы данных;
- directory=ExportImport – параметр указывает директорию, в которую мы будем выгружать дамп файл;
- dumpfile=DumpFull.dmp – параметр для указания названия дамп файла;
- logfile=ExportFull.log – параметр для указания названия лог файла экспорта данных.
Создание дампа на основе отдельной схемы базы данных
В большинстве случае все-таки, наверное, понадобится экспортировать отдельную, выбранную схему базы данных, а не всю БД. Для того чтобы выгрузить схему, указываем параметр SCHEMAS.
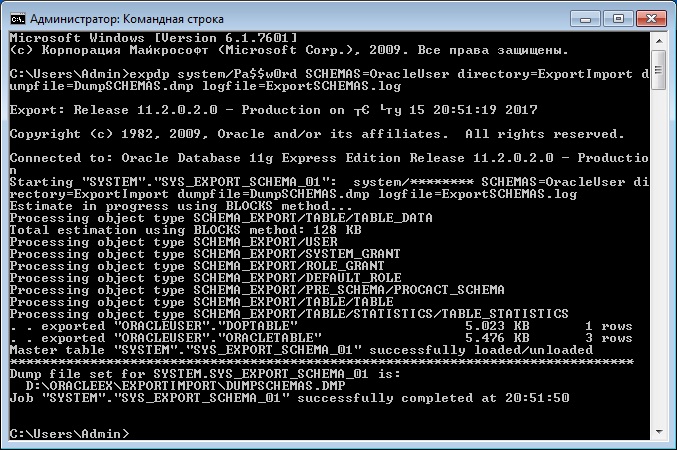
SCHEMAS=OracleUser – параметр, в котором мы указываем схему для экспорта, в нашем случае OracleUser.
Создание дампа на основе отдельных таблиц базы данных
Иногда нужно экспортировать только одну или несколько таблиц, для этого мы можем использовать параметр TABLES. В примере ниже мы экспортируем таблицу OracleTable в схеме OracleUser.
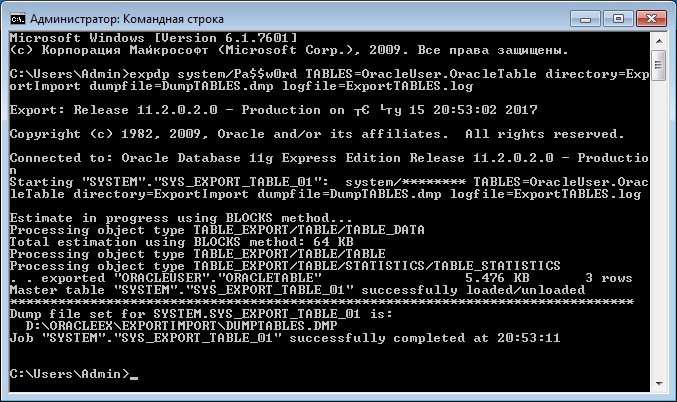
TABLES=OracleUser.OracleTable – это параметр, в котором мы указываем таблицу для экспорта (или несколько таблиц через запятую).
Пример импорта данных из дампа Oracle с помощью impdp
Сейчас давайте перейдем к импорту данных из дампа. Как Вы помните, для этих целей у нас существует утилита impdp.
Импорт схемы из дампа
Для импорта всей схемы запускаем утилиту impdp с параметром SCHEMAS. В случае если у Вас уже создана схема, которую Вы собираетесь импортировать, то ее предварительно нужно удалить. Для удаления схемы используйте следующий запрос в SQL*Plus или SQLDeveloper
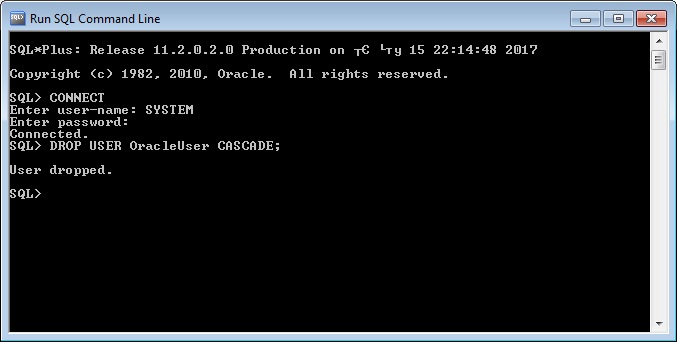
После этого, для того чтобы импортировать схему, запускаем утилиту impdp со следующими параметрами
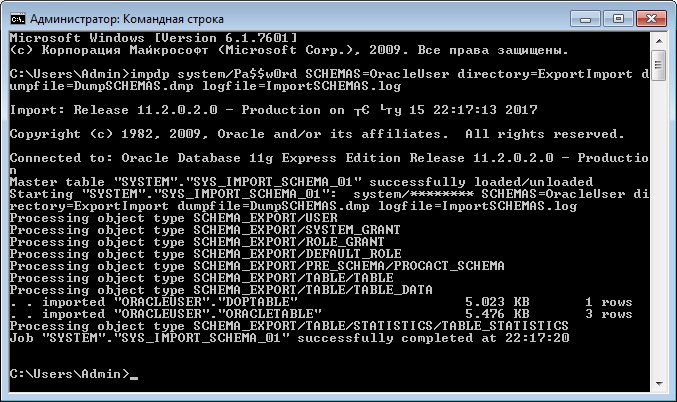
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- SCHEMAS=OracleUser – параметр, который указывает, что мы хотим импортировать конкретную схему (в нашем случае OracleUser);
- directory=ExportImport – параметр указывает директорию, в которой расположен файл дампа данных;
- dumpfile=DumpSCHEMAS.dmp – параметр для указания названия дамп файла;
- logfile=ImportSCHEMAS.log – параметр для указания названия лог файла импорта данных.
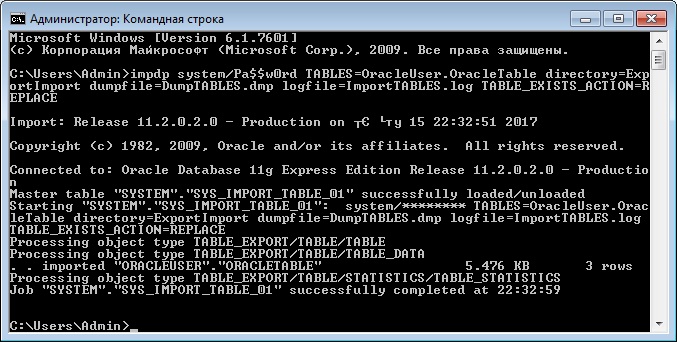
Импорт таблиц из дампа
Если Вы хотите импортировать одну или несколько таблиц, то можете использовать параметр TABLES, также как и при экспорте. В случае если таблица или таблицы уже созданы, т.е. существуют, то их необходимо или удалить вручную (DROP TABLE) или указать параметр TABLE_EXISTS_ACTION, который может принимать следующие значения:
Для примера давайте запустим impdp с параметром TABLE_EXISTS_ACTION=REPLACE, для того чтобы перезаписать существующую таблицу.
Заметка! Для изучения языка SQL как стандарта, чтобы его можно было использовать в любой СУБД, рекомендую почитать книгу «SQL код», в ней рассматриваются конструкции SQL, которые будут работать везде и не привязаны к какой-то конкретной СУБД.
Читайте также: