
Oracle получить стек вызовов
Обновлено: 02.07.2024
Я пишу процедуру регистрации в Oracle 10g, которая записывает в таблицу следующую вставку:
Эта процедура повторно используется в нескольких различных packages/procedures,, но так, как это происходит сейчас, программист должен передать свое имя пакета / процедуры в процедуру регистрации ( strPackage и strProcedure ).
Мне интересно, есть ли представление v$ или что-то в Oracle, что может сказать мне, из какого пакета/процедуры была вызвана эта процедура, таким образом устраняя необходимость для программиста проходить в strPackage и strProcedure .
Если я назову эти две процедуры:
Из этого пакета:
Я хотел бы иметь возможность оценить log_test / TestProc1 и log_test / TestProc2 из insdie метода write_exec_log .
3 ответа
У меня есть отчет в SSRS VS2008, который должен запустить процедуру Stord из Oracle. В прошлом я запускал функции из Oracle, которые возвращали таблицы для отображения данных. А также прямолинейные заявления SELECT Например: select * from table(MyFunction(:parm1, :parm2)) select * from MyTable Я.
Я набрал процедуру, используя веб-интерфейс Oracle 10g. Скомпилируйте код и никаких ошибок вообще. Для выполнения этой процедуры я должен использовать имя команды EXECUTE, но когда я помещаю ее в окно SQL, она вообще не работает и говорит, что это недопустимая команда SQL. Вопрос, который у меня.
Короткий пример, если вас просто интересует процедура вызова: DBMS_OUTPUT.PUT_LINE(UTL_Call_Stack.Concatenate_Subprogram(UTL_Call_Stack.Subprogram(2)));
Или распечатать полный стек вызовов:
Пример с вашим пакетом:
(К сожалению, нет sqlfiddle, нет 12c, доступных на момент написания статьи)
Вот реализация (backport) utl_call_stack для Oracle 9. И для Oracle 10 и 11 .
Другое решение (с пакетом p_stack):
В примере GWu он будет выводить:
Это только последние звонки. Или, если вам нужны полные стопки:
Он работает для Oracle версий от 9 до 12.
Я создал пакет в своей базе данных Oracle, который включает в себя несколько процедур, теперь я хочу вызвать процедуру из программы java процедура требует двух входных параметров и ничего не возвращает. Пожалуйста, помогите мне сделать это, я использую приведенное ниже соединение для подключения к.
Я использую DreamFactory для доступа к базе данных Oracle, я получаю таблицы без проблем, но когда я пытаюсь получить доступ к процедурам или функциям, я могу получить доступ только к тому же пользователю, как я могу вызвать хранимую процедуру, сохраненную в другом пользователе?
Похожие вопросы:
Я пытаюсь вызвать хранимую процедуру Oracle в пакете и получаю эту ошибку: SQL ошибка: ORA-06576: недопустимое имя функции или процедуры Я использую SQL Developer, и это команда, которую я использую.
Я пишу процедуру Oracle, используя TOAD. Я выполнил процедуру с помощью инструкции execute. Но я не в состоянии получить результат. Вместо этого я получаю только ошибку. Пожалуйста, помогите, как.
Я хочу написать хранимую процедуру Oracle, в которой я бы передал (из ColdFusion) массив структур и зацикливался на каждой итерации, чтобы вставить биты и фрагменты внутри структур в DB., Я никогда.
У меня есть отчет в SSRS VS2008, который должен запустить процедуру Stord из Oracle. В прошлом я запускал функции из Oracle, которые возвращали таблицы для отображения данных. А также прямолинейные.
Я набрал процедуру, используя веб-интерфейс Oracle 10g. Скомпилируйте код и никаких ошибок вообще. Для выполнения этой процедуры я должен использовать имя команды EXECUTE, но когда я помещаю ее в.
Я создал пакет в своей базе данных Oracle, который включает в себя несколько процедур, теперь я хочу вызвать процедуру из программы java процедура требует двух входных параметров и ничего не.
Я использую DreamFactory для доступа к базе данных Oracle, я получаю таблицы без проблем, но когда я пытаюсь получить доступ к процедурам или функциям, я могу получить доступ только к тому же.
Oracle 11г Пакет oracle с примерно 200 процедурами. Внешнее приложение подключается к этой базе данных Oracle и вызывает одну процедуру в этом пакете. Загружается ли весь пакет в память на сервере.
Я установил Oracle 12c на свой локальный хост (Win 10), но когда я пишу какую-либо процедуру или функцию, я не могу вызвать пакет utils . Я использую utils.convert_to_nvarchar2 в 11g на другом.
У меня есть 10 хранимых процедур, и каждая из них делает вставки в одну таблицуX.
Возможно ли в теле триггера tableX получить, какой объект вызывает модификацию tableX (хранится в proc1 или sp2 или . )?
Да, можно определить работающий код, используя системную функцию @@ procid , и лучше присвоить OBJECT_NAME (@@ PROCID) полное имя.
Определение: «Возвращает идентификатор объекта (ID) текущего модуля Transact-SQL. Модуль Transact-SQL может быть хранимой процедурой, пользовательской функцией или триггером. @@ PROCID нельзя указывать в модулях CLR или в обработчик доступа к данным. "
Вы можете прочитать об этом здесь .
Другой вариант - проверить план sql текущего spid и сохранить эту информацию в таблице журналов. Пример запроса, который будет использоваться в каждой процедуре для сохранения данных аудита:
Может быть, там слишком много деталей .. но я верю, что вы поняли идею.
Третий вариант - использовать информацию context_info для текущего сеанса SP. И связать где-нибудь контекстную информацию, сохраненную там с каждой процедурой. Например, в процедуре1 вы пишете 111 в контекст, в процедуре2 вы пишете 222 .. и так далее.
Много больше информации о context_info вы можете прочитать в этом вопросе SO .
1) OBJECT_NAME (@@ PROCID) в триггере возвращает имя триггера :(. 2) необходимо иметь информацию только в триггере. 3) context_info - это решение. Благодарю. Да, внутри триггера OBJECT_NAME(@@PROCID) возвращается имя триггера, а не вызывающий процесс. Это просто неправильно. Он возвращает имя триггера, а не процедуры вызова, как запросил OP Согласитесь, ответ неверный. CONTEXT_INFO работает, если вы можете изменить вышестоящую процедуру.Я тоже хотел это сделать. Спасибо за ответ. Поскольку я все еще здесь, я опубликую свой тест, чтобы сэкономить время других :)
XEvents предоставляют другой способ получения стека T-SQL, хотя SQL Server 2008 может не поддерживать используемый тип событий. Решение состоит из триггера, ошибки и сеанса XEvent. Я взял пример Джима Брауна, чтобы показать, как он работает.
Прежде всего, я протестировал решение для SQL Server 2016 SP2CU2 Dev Edition. SQL Server 2008 поддерживает некоторые EXevent, но у меня нет ни одного экземпляра, чтобы я не смог его протестировать.
Идея состоит в том, чтобы сгенерировать пользовательскую ошибку в фиктивном блоке try-catch, а затем перехватить ошибку в сеансе XEvent с tsql_stack действием. SQLSERVER.error_reported Тип XEvent может перехватывать все ошибки, даже если блок try-catch их перехватывает. В конце sys.dm_exec_sql_text извлеките запросы T-SQL из дескрипторов запросов, которые tsql_stack дает действие.
Пример из ответа Джима Брауна, который я разработал, показан ниже. Триггер вызывает ошибку с текстом «поймай меня». Сессия XEvent ловит ошибки только с текстом типа «поймай меня».
Теперь, если вы запустите сеанс XEvent (SSMS, Обозреватель объектов, Управление, Расширенные события, Сеансы, catch_insertion_into_Test), выполните usp_RootProcIDTest и посмотрите кольцевой буфер сеанса XEvent, вы должны увидеть XML, который состоит из узла <action name="tsql_stack" package="sqlserver"> . Существует последовательность узлов кадра. Поместите значения handle атрибута в системную функцию 'sys.dm_exec_sql_text' и вуаля:
XEvent позволит вам сделать гораздо больше, чем это! Не упустите возможности узнать их!
Убедительная просьба, рассматривать данный текст только как продолжение к статье о "Событийной модели логирования". Эта статья будет полезна тем, у кого уже реализовано логирование событий в БД и кто хотел бы осуществлять сбор статистики и начать проводить аналитику этих событий. Только представьте, что ваша БД сможет информировать вас о критичных сбоях системы, накапливать информацию о событиях в БД (кол-во повторений, период повторений и т.д.). И всё это без использования стороннего ПО силами одного PL/SQL.
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий (статья)
Собственную нумерацию и идентификацию событий происходящих в БД
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. В этой (второй) статье создадим собственную нумерацию кодов для событий, а также создадим функционал идентификации событий происходящих в БД.
Для чего это нужно?
Для начала давайте рассмотрим пример. Вы реализовали логирование ошибок в вашей БД. С течением времени в ваш лог «прилетают» самые разнообразные ошибки. Предположим, имеются две ошибки вида «no_data_found» возникшие в двух разных процедурах при двух разных запросах (select). Первая ошибка возникла при попытке найти «email» клиента, что в принципе не является критичной ошибкой. Вторая ошибка возникла при попытке найти номер лицевого счета клиента, что вполне может являться критичной ошибкой. При этом если мы посмотрим в таблицу лога (из статьи), то увидим, что указанные ошибки будут храниться с одинаковым кодом 1403 (ORA-01403) в столбце msgcode. Более того, текст указанных ошибок будет практически аналогичным (текст полученный с помощью функции SQLERRM) за исключением имен объектов, на которых произошла ошибка. Для того чтобы понять является ли критичной конкретная ошибка, разработчику необходимо вникать в текст ошибки, смотреть в каком объекте возникла ошибка и на основе этой информации сделать вывод о срочности исправления. При этом, если мы сможем задать более четкое описание ошибки отличное от текста Oracle (SQLERRM), то это позволит упростить понимание причин возникновения и способов решения ошибки.
Как должно быть (в идеале)
Не найдена запись в таблице содержащей адреса электронной почты клиентов
ORA-01403: данные не найдены
USR0001: Не найден адрес электронной почты клиента (идентификатор клиента)
Не найдена запись в таблице содержащей лицевые счета клиентов
ORA-01403: данные не найдены
USR0002: Не найден лицевой счет клиента (идентификатор клиента)
Из этого примера видно, что одна и та же ошибка «no_data_found» (ORA-01403: данные не найдены) может иметь совершенно разное значение с точки зрения бизнес логики, а значит нам необходимо разработать механизм, который позволит идентифицировать каждое событие происходящее в БД как отдельное событие с нашим внутренним уникальным кодом и текстом события (отличную от Oracle). Таким образом мы решаем две проблемы:
1) В месте возникновения ошибки мы устанавливаем уникальный код ошибки. В будущем это позволяет достаточно быстро найти место возникновения ошибки. Также, наличие уникальных кодов позволяет нам произвести точечный подсчет повторений и на основании этой информации принять решение об устранении данной ошибки.
2) Дополнительный "читаемый" текст позволяет сильно упростить понимание ошибки. В таблице выше показано, как одна и та же ошибка может запутать или разъяснить пользователю сведения об ошибке.
Надеюсь мне удалось объяснить зачем необходимо кодировать события в таблице логов. Далее по тексту, будут введены термины «Архитектурный лог» и «Пользовательский лог». На примере процедуры поиска активного номера телефона клиента будет показано как и зачем создано разделение на архитектурный и пользовательский лог.
Архитектурное логирование событий
Давайте рассмотрим пример, имеется процедура поиска активного номера телефона принадлежащего конкретному клиенту (для примера его Предположим, что при постановке задачи для разработчика не было описания каких-либо особых условий т.е. по условиям задачи предполагалось, что для конкретного пользователя (id = 43, идентификатор передается в качестве параметра) в таблице client_telnumbers всегда будет хотя бы одна запись с номером телефона клиента и признаком «активный» (значение поля enddate равно дате 31.12.5999 23:59:59, что означает что номер используется клиентом. В случае, любой другой даты в указанном поле означает, что номер перестал быть активным и более не используется), поэтому наша процедура будет выглядеть примерно так:
Исходный код демонстрационной процедуры
Важно! Представленный код является примерным (примитивным) и служит только для демонстрации логирования в рамках данной статьи. В своих статьях я не выкладываю текст кода из реально действующих БД. Надеюсь, вы понимаете, что в реальности указанная процедура написана гораздо сложнее.
*Исходный код других используемых объектов смотрите в Git
Если мы будем использовать логирование ошибок как показано в предыдущей статье, то с течением времени обнаружим, что идентифицировать ошибки из данной процедуры будет сложно. Поэтому для всех ошибок попадающих в обработку исключения «WHEN OTHERS» реализована процедура pkg_msglog.p_log_archerr, которая при первом возникновении ошибки автоматически присваивает ей уникальный код и сохраняет ошибку в таблице лога. В дальнейшем, при повторении данной ошибки процедура найдет ранее созданный код и использует его при логировании в таблице лога.
В итоге, после добавления блока «архитектурного» логирования (строки с 18 по 24), наша процедура будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
На этапе написания текста процедуры разработчик не всегда может предугадать возникновение той или иной ошибки (если честно, не всегда есть на это время), поэтому на начальном этапе ему достаточно «отлавливать» абсолютно все ошибки возникающие в данной процедуре с помощью оператора «WHEN OTHERS». Таким образом мы можем ввести новый термин (в рамках данного цикла статей), «Архитектурные логирование» - это логирование всех ошибок, возникновение которых не предполагается при штатной работе алгоритма. Для функционала «Архитектурных ошибок» были созданы объекты: отдельный справочник ошибок messagecodes_arch и процедура pkg_msglog.p_log_archerr создания записи в таблице лога для указанного типа ошибок.
Исходный код таблицы
Ограничение в таблице на комбинацию (Имя объекта, код ошибки SQLCODE). При первом появлении ошибки создается запись в таблице и генерируется код ошибки "SYS0000" + счетчик ошибок. При повторном появлении указанной ошибки будет взят уже сгенерированный ранее код ошибки.

рис. Пример содержимого таблицы messagecodes_arch
*Исходный код других используемых объектов смотрите в Git
Обратите внимание, что при использовании описанной модели «архитектурного» логирования у вас появляется функционал позволяющий максимально быстро реагировать на первое появление ошибки (в конкретной функции/процедуре). Для этого необходимо реализовать отдельный мониторинг архитектурных ошибок, который постараюсь продемонстрировать в следующей (третьей) статье. Использование процедуры pkg_msglog.p_log_archerr не требует каких-либо действий кроме описания входных параметров.
Таким образом мы можем создать базовый шаблон процедуры (функции), использование которого позволит вам гарантированно отлавливать все архитектурные ошибки в вашем коде.
Шаблон процедуры/функции с архитектурным логированием
Рекомендую использовать данный шаблон для построения "Событийной модели логирования".
*Исходный код других используемых объектов смотрите в Git
В рамках событийной модели логирования, предполагается, что все архитектурные ошибки будут исправляться отдельной задачей т.е. основная цель это устранить повторное появление ошибок с кодом "SYS****" в таблице лога. В указанной задаче вам необходимо либо устранить причины возникновения данной ошибки, либо добавить отдельную обработку ошибки отличную от «when others», которую в дальнейшем будем назвать «пользовательское» логирование (в рамках данного цикла статей).
Пользовательское логирование событий
Предположим, что однажды в нашей процедуре get_telnumber произошла «архитектурная ошибка». В частности, для конкретного пользователя в таблице client_telnumbers хранится два номера телефона с признаком «активный». В таком случае, процедура «упадёт» с ошибкой «ORA-01422: too_many_rows». При этом, наш функционал архитектурного логирования сгенерировал новый код ошибки «SYS0061» и создал запись в таблице лога.
![]()
рис. Код архитектурной ошибки SYS0061
Самое важно в такой ситуации это не откладывать «на потом» исправление архитектурных ошибок. В идеале, необходимо создать отдельную задачу (баг) и в рамках неё устранить ошибку.
Предположим ,что была создана отдельная задача для устранения ошибки и назначена разработчику. В рамках этой задачи, разработчик совместно с технологом, аналитиком и др. коллегами пришел к выводу, что указанная ошибка носит систематический характер, является некорректной работой системы и требует исправления. В качестве мер исправления было решено добавить обработку события «too_many_rows» с последующим логированием события в таблице лога и выводом текста ошибки для пользователя.
Для этого в процедуре get_telnumber добавлено исключение (exception) «too_many_rows» пользовательского логирования. Также, был создан справочник пользовательских ошибок отличный от архитектурного справочника, тем что в него все записи добавляются разработчиком "вручную". Наверное это самое слабое место во всей архитектуре логирования. Предполагается, что разработчик должен описать исключение (exception) и создать для него уникальный код ошибки. Также, желательно к указанной ошибке сформулировать читаемый текст ошибки (для своих коллег, пользователя, техподдержки и т.д.), что бывает иногда очень сложным (из личного опыта).
Таблица пользовательских ошибок и процедура их "регистрации" будет выглядеть следующим образом:
Исходный код таблицы пользовательских ошибок и процедуры регистрации
Обратите внимание, что текст ошибок имеет параметризацию т.е. для ошибки в тексте имеются специальные символы $1, $2, $3 и т.д. Например, рассмотрим ошибку "USR0003" с текстом "Для клиента найдено два и более активных номеров телефона!" при вызове функции f_get_errcode на вход подаётся код ошибки и параметры ошибки. Далее, функция по коду ошибки найдет строку, в тексте ошибки заменит подстроку "$1" на значение параметра to_char(p_userid) т.е. подставит значение to_char(p_userid).
В случае если в тексте ошибки будут два и более спецсимвола $1, $2, $3 и т.д., то параметры передаются с использованием символа-разделителя ";".
Итого, содержимое справочника пользовательских ошибок будет выглядеть следующим образом:

рис. Пример содержимого справочника пользовательских ошибок
*Исходный код других используемых объектов смотрите в Git
После того, как мы "зарегистрировали" пользовательскую ошибку "USR0003" и добавив отдельную обработку пользовательского логирования (строки с 19 по 28), наша процедура get_telnumber будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
При повторном возникновении ошибки «too_many_rows» обработка события пройдет по нашему сценарию «пользовательского» логирования. Таким образом мы можем ввести второй термин (в рамках данного цикла статей), «Пользовательские логирование» - это логирование всех ошибок, возникновение которых предполагается и ожидается при нештатной работе алгоритма. В итоге, пользователь получит читаемый текст ошибки с кодом «USR0003», также, мы же всегда сможем подсчитать количество ошибок с указанным кодом. В случае большого количества ошибок у нас на руках будет «живая» статистика частоты возникновения ошибки и их количества, что позволит нам выйти на руководство с предложением по доработке/оптимизации процесса.
Давайте рассмотрим еще один пример (кейс из реального случая), в момент когда процедура get_telnumber по id клиента находит один "активный" номер телефона иногда возникает ситуация, что номер телефона не принадлежит мобильному оператору. Ситуации бывают разные иногда указанный номер мог быть номером городской телефонной сети, иногда номером международного оператора, а иногда вообще набор из нескольких цифр и т.д. Основным требованием от бизнес-заказчика было использование номера телефона российских операторов мобильной связи. Поэтому было решено добавить проверку соответствия найденного номера некому "корректному" шаблону (строки с 18 по 29). В случае обнаружения некорректного номера, логировать данное событие отдельным кодом "USR0004" и типом "WRN". Добавим функцию проверки корректности номера телефона, если номер соответствует шаблону (требованиям), то вернем номер телефона, иначе пустое значение.
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
После сбора статистических данных по конкретной ошибке с кодом "USR0004", руководству стало понятно, что ошибка актуальна и количество ошибок с течением времени не только не уменьшается, а наоборот растет с линейной прогрессией. В дальнейшем, были выявлены источники "кривых" данных и были установлены внутренние требования по первичной обработке номера телефона клиентов. В итоге, со временем количество ошибок уменьшилось до нуля. И этого нельзя было добиться до тех пор, пока у всех участвующих лиц не возникло понимание о масштабе проблемы.
Исходный код запроса
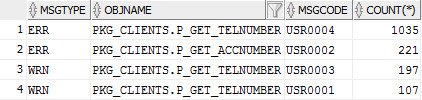
рис. Пример результата запроса с группировкой
*Исходный код других используемых объектов смотрите в Git
Заключение
В заключении наверное скажу банальную вещь, о том что ваша БД является сложным механизмом ежесекундно выполняющая рутинные операции. Прямо сейчас в БД могут происходить различные ошибки. Критичные, которые вы исправляете практически сразу или некритичные, о которых вы можете вообще не знать. И если у вас нет информации о подобных ошибках, то возникает вопрос: "Нужно ли их вообще исправлять? Или можно подождать до тех пор, пока проблема не всплывёт?". Вопрос наверное "риторический".
Я же данной статьёй хотел показать один из способов ведения логирования с кодированием отдельных событий. Данный метод требует некоторых "обязательств" от разработчика и в нынешнее время этого тяжело добиться. В следующей статье постараюсь показать один из способов мониторинга ошибок основанный напрямую по кодам ошибок созданных в текущей статье.
В окне Стек вызовов отображаются модули в стеке вызова, а также типы данных и значения всех параметров, передаваемых в модули. Transact-SQL включают в себя хранимые процедуры, функции и триггеры. Чтобы отобразить стек вызова, необходимо находиться в режиме отладки.
Эта функция работает с SSMS версии 17.9.1 и предшествующими версиями.
Список задач
Доступ к окну «Стек вызовов»
Изменение текущего кадра стека в стеке вызова
Можно использовать любую из следующих процедур, чтобы сделать один из кадров стека текущим.
Щелкните правой кнопкой мыши кадр стека и выберите команду Перейти к кадру.
Дважды щелкните кадр стека.
Просмотр источника кадра, отличного от текущего кадра
- Щелкните правой кнопкой мыши кадр стека и выберите команду К исходному коду.
Кадры стека
Каждая строка в окне Стек вызовов называется кадром стека и представляет либо вызов модуля из файла скрипта Transact-SQL , либо вызов одного модуля из другого модуля. Нижний кадр стека на экране показывает ту строку в окне редактора запросов компонента Компонент Database Engine , в которой был сделан первый вызов в стеке. Верхняя строка указывает строку, на которой отладчик приостановил выполнение, и обозначается желтой стрелкой в левом поле окна. Каждая промежуточная строка указывает модуль и номер строки исходного кода, в котором произошел вызов следующего, вышестоящего кадра стека.
Все выражения в окнах Локальные значения, Контрольные значения и Быстрая проверка вычисляются на основе текущего кадра стека. В окне «Редактор запросов» отображается код текущего кадра. По умолчанию текущим кадром стека является кадр, в котором отладчик Transact-SQL приостановил выполнение. После перехода от текущего кадра стека к другому кадру выражения в окнах Локальные переменные, Контрольные значения и Быстрая проверка повторно вычисляются в контексте нового кадра и в окне редактора запросов отображается исходный код нового кадра.
Столбцы
имя;
Отображается информация о модуле в стеке вызова.
В нижней строке в стеке вызова в поле Имя указано окно источника редактора запросов и номер строки первого вызова в стеке. В других строках поле Имя имеет формат Модуль(Экземпляр.База_данных)(Список_параметров) Номер_строки.
Модуль
Представляет собой имя хранимой процедуры, функции или хранимой процедуры, вызвавшей следующий кадр.
Экземпляр.База_данных
Указывает экземпляр компонента Компонент Database Engine и базу данных, в которой содержится модуль.
Список_параметров
Указывает тип данных, имя и значение каждого параметра, переданного во время вызова в модуль.
LineNumber
Для всех строк, кроме верхней строки, значение Номер_строки указывает, в какой строке модуля вызван этот кадр. Для верхней строки значение Номер_строки указывает строку, которая в настоящее время находится в фокусе в отладчике.
Язык
Для языка отображается значение Transact-SQL Transact-SQL.
Читайте также: