
Oracle with as select с параметрами
Обновлено: 07.07.2024
Ты то стоишь,
То начинаешь
Все сначала.
Путь учения
Не прост.
Шел Кондрат
В Ленинград,
А навстречу – двенадцать ребят.
Реферат
Рассматривается использование рекурсии в вынесенном во фразу WITH подзапросе в Oracle, разрешенное с версии 11.2. Возможности такой рекурсии сопоставляются с возможностями фразы CONNECT BY.
Введение
Рекурсивные запросы используются для обращения к иерархически связаным данным. Этого требуется не всегда: так, запросы по дереву можно свести к простому просмотру таблицы. Однако такое возможно, когда узлы дерева размечены особыми служебными значениями, а это делается рекурсивной процедурой. Если данные изменяются регулярно, рекурсивную процедуру приходится перевычислять часто, и в таких случаях идут на обычное хранение, а к рекурсии приходится прибегать в запросе.
До версии 11.2 в Oracle задача рекурсивных запросов к иерархически организованым данным решалась с помощью фразы CONNECT BY. В то же время в стандарте SQL:1999 была введена фраза WITH для вынесения подзапросов («факторизация» запроса), одна из двух вариантов которой решала задачу рекурсивныз запросов более общим (и стандартным !) образом. В Oracle первый вариант фразы WITH (простое вынесение подзапроса из основного текста) был воплощен в версии 9, а второй, рекурсивный, хотя и с некоторыми вольностями, – в версии 11.2.
Ниже для примера заводится таблица с иерархически связанными данными, далее показывается для сравнения обращение к этим данным с помощью CONNECT BY, а после приведены разные возможности употребления к этим данным рекурсивной фразы WITH. Подготовка данных Для дальнейших примеров создадим таблицу. Выполним:
Обратите внимание, что создана не «таблица с расстояниями», а таблица с направленными маршрутами, предоставляющая расстояния в километрах между городами с точки зрения Москвы (здесь – единственная вершина иерархии). Такое представление данных и приводимые ниже запросы плохо подходят для решения более общей задачи поиска маршрута между двумя произвольными точками.
Примеры рекурсивных запросов с помощью CONNECT BY
Запрос вниз по иерархии от узла 'Москва' (присутствует только в качестве предка):
Запрос вверх по иерархии от узла 'Выборг':
Построение рекурсивных запросов с помощью вынесения подзапроса во фразу WITH
С версии 11.2 фраза WITH может использоваться для формулирования рекурсивных запросов, в соответствии (неполном) со стандартом SQL:1999. В этом качестве она способна решать ту же задачу, что и CONNECT BY, однако (а) делает это похожим с СУБД других типов образом, (б) обладает более широкими возможностями, (в) применима не только к запросам по иерархии и (г) записывается значительно более замысловато.
Общий алгоритм вычисления фразой WITH таков:
Предложение SELECT для исходного множества строк Oracle называет опорным (anchor) членом фразы WITH. Предложение SELECT для получения добавочного множества строк Oracle называет рекурсивным членом.
Простой пример
Простой пример употребления фразы WITH для построения рекурсивного запроса:
Операция UNION ALL здесь используется символически, в рамках определенного контекста, для указания способа рекурсивного накопления результата.
Строка с n = 1 получена из опорного запроса, а остальные строки из рекурсивного. Из примера видна оборотная сторона рекурсивных формулировок: при неаккуратном планировании они допускают «бесконечное» выполнение (на деле – пока хватит ресурсов СУБД для сеанса или же пока администратор не прервет запрос или сеанс). С фразой CONNECT BY «бесконечное» выполнение в принципе невозможно. Программист обязан отнестись к построению рекурсивного запроса ответственно.
Еще один вывод из этого примера: подобно случаю с CONNECT BY, вынесенный рекурсивный подзапрос применим вовсе необязательно только к иерархически организованным данным.
Пример с дополнительным разъяснением способа выполнения:
Использование предыдущих значений при выполнении рекурсии
Рекурсивные запросы с фразой WITH позволяют программисту больше, нежели запросы с CONNECT BY (тоже рекурсивные). Например, они позволяют накапливать изменения, и не испытывают необходимости в функциях LEVEL или SYS_CONNECT_BY_PATH, имея возможность легко их моделировать.
Пример запроса по маршрутам из Москвы с подсчетом километража:
Запрос по маршрутам из Выборга аналогичен, но с поправкою на симметрию, вызванной движением по иерархии снизу вверх, а не сверху вниз:
Обработка зациклености данных
Пример организации зациклености в сведениях о маршрутах:
Реакция на появление цикла (уже получается не иерархия) в этом случае отлична от имевшейся для CONNECT BY и будет:
Упражнение. Проверить это самостоятельно.
Для предупреждения зацикливания вычислений вводится специальное указание CYCLE, где следует указать перечень (в общем случае) столбцов для распознавания хождения по кругу, придумать название столбца- индикатора (он автоматически включается в конечный ответ) и задать пару символов: для обозначения незацикленной строки и для обозначения строки, где было зафиксировано повторение значений в различительных столбцах:
Упорядочение результата
Для придания порядка строкам результата в запросах с CONNECT BY используется особая конструкция ORDER BY SIBLINGS. Аналогично в вынесенном рекурсивном запросе используется специальное указание SEARCH. В рамках последнего, в частности, задается вымышленое имя столбца, в котором СУБД автоматически проставит числовые значения, и который включит автоматически в порождаемый набор столбцов, допуская в последующей обработке его использование во фразе ORDER BY для осуществления упорядочения. Пример:
Подробности и прочие свойства построений указания SEARCH приведены в документации по Oracle.

Чтобы понять рекурсию, сначала надо понять рекурсию. Возможно, поэтому рекурсивные запросы применяют так редко. Наверняка вы представляете что такое SQL-запрос, я расскажу, чем рекурсивные запросы отличаются от обычных. Тема получилась объемная, приготовьтесь к долгому чтению. В основном речь пойдет об Oracle, но упоминаются и другие СУБД.
Суть проблемы
Большинство современных СУБД (Система Управления Базами Данных) — реляционные, т.е. представляют данные в виде двумерной таблицы, в которой есть строки (записи) и столбцы (поля записей). Но на практике мы часто сталкиваемся с иной организацией данных, а именно иерархической.
Взгляните на список файлов на вашем компьютере: все они организованы в виде дерева. Аналогично можно представить книги в библиотеке: Библиотека->Зал->Шкаф->Полка->Книга. То же самое и статьи на сайте: Сайт->Раздел->Подраздел->Статья. Примеры можно приводить долго. Впрочем, тут еще можно разделить все на отдельные таблицы: таблица для хранения списка библиотек, другая таблица для списка залов, третья для шкафов и т.д. Но если заранее не известна глубина вложенности или эта вложенность может меняться, тут уж от иерархии никак не отмашешься.
Проблема в том, что данные, имеющие иерархическую структуру, очень плохо представляются в реляционной модели. В стандарте SQL-92 нет средств для их обработки.
Зато такие средства появились в стандарте SQL-1999. Правда к тому времени в Oracle уже был собственный оператор CONNECT BY. Несмотря на это, в SQL-1999 синтаксис рекурсивных запросов совершенно не похож на синтаксис CONNECT BY в Oracle и использует ключевое слово WITH. Реализация же рекурсивных запросов в других СУБД несколько запоздала, так в MS SQL Server она появилась лишь в версии 2005.
Так же как и в синтаксисе, есть отличия и в терминологии. В Oracle обычно обсуждаемые запросы называются “иерархические”, у всех остальных “рекурсивные”. Суть от этого не меняется, я буду использовать и то и другое.
От слов к делу!
Для демонстрации будем использовать структуру каталогов, нам потребуется тестовая таблица, состоящая из 3-х полей:
id – идентификатор,
pid – идентификатор родителя (ссылается на id другой записи в той же таблице),
title – название каталога (вместо него может быть что угодно, даже несколько полей или ссылок к другим таблицам).
create table test_table (
id int ,
pid int ,
title varchar (256)
);
Здесь я использовал синтаксис mySQL, в других СУБД он несколько отличается. Так, в Oracle используются другие типы данных: вместо int — number, а вместо varchar — varchar2.
Заполнить табличку тестовыми данными не составит труда. Предлагаю записать список серверов, расположенных на территории различных предприятий в разных городах. Таким образом, в единой таблице оказываются и страны, и города, и фирмы, и сервера.
Думаю, остальные строки заполнить не составит сложностей. Получается почти как на картинке, только не в том порядке. Я специально заполнял не по-порядку, чтобы простым SELECT * FROM test_table получалось не иерархическая структура:
Тестовые данные готовы. Приступим к выборкам.
mySQL
Вынужден огорчить пользователей mySQL – в этой СУБД придется рекурсию организовывать внешними по отношению к СУБД средствами, например на php (код приводить не буду, его публиковали не раз, например здесь, достаточно поискать по запросу “mySQL tree” и т.п.).
Впрочем, есть иной подход, заключающийся в создании левой и правой границы для каждого узла, предложенный Джо Селко. Тогда можно будет обойтись обычными, не рекурсивными запросами.
Как-то я выводил дерево объектов в действующем проекте на php. База данных была на mySQL. Поплевавшись на отсутствие удобных операторов, я решил тогда не отображать все дерево целиком, а показать пользователю только первый уровень (схлопнутое дерево). При клике по плюсику в узле дерева отображались дочерние узлы для выбранного объекта, при этом они подгружались через AJAX. Выборка дочерних узлов по известному pid происходит быстро, поэтому интерфейс получился вполне шустрым. Возможно, это не лучшее решение, но оно имеет право на жизнь.
SQL-1999
В отличие от предыдущего стандарта SQL-92, в названии следующего решили отобразить номер тысячелетия, чтобы он не страдал от проблемы двухтысячного года. Помимо этого :-), появились новые типы данных (LOB), новые предикаты SIMILAR и DISTINCT, точки сохранения транзакций, объекты и их методы, и многое другое. Среди нововведений появились также рекурсивные запросы, о которых мы сейчас и поговорим.
Для получения иерархических данных используется временное представление, которое описывается оператором WITH. После этого из нее выбираются данные простым селектом. В общем виде синтаксис примерно такой:
В MS SQL нет ключевого слова RECURSIVE, его следует опустить. Но в остальном все то же самое. Такой синтаксис поддерживается в DB2, Sybase iAnywhere, MS SQL, начиная с версии 2005, и во всех базах данных, которые поддерживают стандарт SQL 1999.
Тогда для получения нашего дерева запрос получится такой:
WITH RECURSIVE
Rec (id, pid, title)
AS (
SELECT id, pid, title FROM test_table
UNION ALL
SELECT Rec.id, Rec.pid, Rec.title
FROM Rec, test_table
WHERE Rec.id = test_table.pid
)
SELECT * FROM Rec
WHERE pid is null ;
Здесь используется рекурсивная таблица Rec, которую мы сами придумали, построив ее по исходной таблице test_table. В описании Rec указано правило, каким образом соединять: WHERE Rec.id = test_table.pid. А в главном запросе отметили, что начинать надо с записи, у которой pid является пустым, т.е. с корневой записи.
Честно говоря, я никогда не работал в MS SQL Server 2005 или другой СУБД, использующей такой синтаксис. Поэтому написал этот запрос чисто из теоретических соображений. Для общности картины, чтобы было с чем сравнить.
В MS SQL 2008 можно применить более новое средство hierarchyid. Спасибо XaocCPS за его описание.
Oracle
Описание синтаксиса в документации напоминает бусы: на единую нить запроса нанизываются нужные операторы. Никому не приходило в голову сделать украшение для гички?
Тут видно, что единственно важное условие для построения иерархического запроса – это оператор CONNECT BY, остальное “нанизывается” по мере надобности.
Необязательный оператор START WITH говорит Ораклу с чего начинать цикл, т.е. какая строка (или строки) будет корневой. Условие может быть практически любым, можно даже использовать функции или внутренние запросы: pid is null, или или даже substr(title, 1, 1) = ‘Р’.
Условие после CONNECT BY нужно указать обязательно. Тут надо сказать Ораклу, как долго продолжать цикл. Что-то в духе while в обычных языках программирования. Например, мы можем попросить достать нам 10 строк: rownum<=10 – он и нафигачит нам в цикле ровно 10 одинаковых строк. Почему одинаковых? Да потому что мы указали какую строку выбрать первой, а как найти следующую нет – вот он и выдает 1-ую строку нужное количество раз. Кстати сказать, rownum это псевдостолбец, в котором нумеруются строки, начиная от 1 в порядке их выдачи. Его можно использовать не только в иерархических запросах. Но это уже другая история.
Как же получить нормальную иерархию? Нужно использовать специальный оператор, который называется PRIOR. Это обычный унарный оператор, точно такой же как + или -. “Позвоните родителям” – говорит он, заставляя Оракл обратиться к предыдущей записи. С его помощью можно написать правило pid = PRIOR id (или PRIOR как говорится, от перестановки мест…).
Что получается? Оракл находит первую запись, удовлетворяющую условию в START WITH, и принимается искать следующую. При этом к той первой записи можно обратиться через PRIOR. Если мы все сделали правильно, то Оракл будет искать записи, в которых в поле для хранения информации о родителе (pid) будет содержаться значение, равное идентификатору id нашей первой записи. Таким образом будут найдены все потомки корневой записи. А так как процесс рекурсивный, аналогичный поиск будет продолжаться с каждой найденной строкой, пока не отыщутся все потомки.
Теперь у нас есть все необходимое, чтобы написать иерархический запрос в Oracle. Но прежде чем мы его напишем, расскажу еще об одной штуке. Порядок строк это хорошо, но нам было бы трудно понять, две строки рядом это родитель и его потомок или два брата-потомка одного родителя. Пришлось бы сверять id и pid. К счастью, Oracle предлагает в помощь дополнительный псевдостолбец LEVEL. Как легко догадаться, в нем записывается уровень записи по отношению к корневой. Так, 1-ая запись будет иметь уровень 1, ее потомки уровень 2, потомки потомков — 3 и т.д.
SELECT level , id, pid, title
FROM test_table
START WITH pid is null
CONNECT BY PRIOR >
Неплохо. Все дочерние строки оказываются под своими родителями. Сортировку бы еще добавить, чтобы записи одного уровня выводились не абы-как, а по алфавиту. Ну чтож, сортировка это просто: добавим в конец запроса конструкцию ORDER BY title.
SELECT level , id, pid, title
FROM test_table
START WITH pid is null
CONNECT BY PRIOR > ORDER BY title;
О, нет! Вся иерархия поломалась. Что же получилось? Оракл честно выбрал нужные строки в порядке иерархии (об этом говорит правильная расстановка level), а затем пересортировал их согласно правилу ORDER BY. Чтобы указать Ораклу, что сортировать надо только в пределах одного уровня иерархии, нам поможет маленькая добавка в виде оператора SIBLINGS. Достаточно изменить условие сортировки на ORDER SIBLINGS BY title – и все встанет на свои места.
Кстати, возможно все еще не понятно, почему этот порядок строк является деревом. Можно убрать все “лишние” поля и добавить отступы, станет более наглядно:
SELECT lpad( ' ' , 3* level )||title as Tree
FROM test_table
START WITH pid is null
CONNECT BY PRIOR > ORDER SIBLINGS BY title;
Ну вот, теперь все в точности, как на картинке в самом начале статьи.
Помните, файловые менеджеры обычно пишут путь к каталогу, в котором вы находитесь: /home/maovrn/documents/ и т.п.? Неплохо было бы и нам сделать так же. А сделать это можно абсолютно не напрягаясь: специалисты из Oracle все уже сделали за нас. Просто берем и используем функцию SYS_CONNECT_BY_PATH(). Она принимает два параметра через запятую: название колонки и строку с символом-разделителем. Будем не оригинальны, напишем так: SYS_CONNECT_BY_PATH(title, ‘/’).
Заодно ограничим вывод, выбрав только одну строку. Для этого, как всегда, нужно добавить условие WHERE. Даже в иерархическом запросе ограничивающее условие применяется ко всем строкам. Вставить его надо до иерархической конструкции, сразу после FROM. Для примера определим путь до “Сервер 1”, который у нас записан с >
SELECT SYS_CONNECT_BY_PATH(title, '/' ) as Path
FROM test_table
WHERE > START WITH pid is null
CONNECT BY PRIOR >
Еще может быть полезен псевдостолбец CONNECT_BY_ISLEAF. Его можно использовать так же, как LEVEL. В этом псевдостолбце напротив каждой строки проставляется 0 или 1. Если есть потомки – проставится 0. Если потомков нет, такой узел в дереве называется “листом”, тогда и значение в поле CONNECT_BY_ISLEAF будет равно 1.
Устали? Осталось немного, самое страшное уже позади. Раньше мы использовали оператор PRIOR, который ссылался к родительской записи. Помимо него есть другой унарный оператор CONNECT_BY_ROOT, который ссылается (ни за что не догадаетесь!) на корневую запись, т.е. на самую первую в выборке.
SELECT id, pid, title, level ,
CONNECT_BY_ISLEAF as IsLeaf,
PRIOR title as Parent,
CONNECT_BY_ROOT title as Root
FROM test_table
START WITH pid is null
CONNECT BY PRIOR > ORDER SIBLINGS BY title;
Стоит отметить, что если в результате выполнения запроса обнаружится петля, Oracle выдаст ошибку. К счастью, ее можно обойти, хотя если в данных содержатся петли – это явно ошибка, в деревьях не бывает петель. На картинке с “бусами” запроса был нарисован оператор NOCYCLE после CONNECT BY – его мы и будем применять. Теперь запрос не будет вылетать. А чтобы определить “больной” участок, воспользуемся псевдостолбцом CONNECT_BY_ISCYCLE – в нем во всех хороших строках будет записано 0, а в тех, которые приводят к петлям, волшебным образом окажется 1.
Чтобы проиллюстрировать это, придется немного подпортить данные. ЛискиПресс ссылается у нас на город Лиски; изменим запись Лиски, чтобы она ссылалась на ЛискиПресс (не забудьте про commit – я вечно забываю):
Если мы запустим какой-нибудь из предыдущих запросов, увидим, что и Лиски, и ЛискиПресс выпали из выборки, будто их нет совсем. Бегая в цикле, Оракл просто перестал на них натыкаться, т.к. нет пути от записи Россия к городу Лиски. Изменим условия START WITH, чтобы начинать с города Лиски – появится ошибка. Умный Оракл видит что запись уже выбиралась ранее и отказывается бегать в бесконечном цикле. Исправляем ошибку:
SELECT CONNECT_BY_ISCYCLE as cycl, id, pid, title
FROM test_table
START WITH > CONNECT BY NOCYCLE PRIOR >
Практические примеры
Иерархические запросы можно применять не только там, где есть явная иерархия.
Например, рассмотрим задачу получения списка пропущенных номеров из последовательности. Это бывает нужно, когда в некоей таблице id генерируется автоматически путем увеличения на 1, но часть записей были удалены. Нужно получить список удаленных номеров. По хорошей традиции, это следует сделать одним селектом.
Подготовим тестовые данные. Удалим из нашей таблицы пару записей:
С чего начнем? Во-первых, неплохо было бы получить список номеров подряд от 1 до максимального значения в нашей таблице, чтобы было с чем сравнивать. Выяснить максимальное значение id из таблицы, думаю, не составит никаких трудностей:
А вот чтобы сгенерировать последовательность от 1 до max как раз и понадобится рекурсивный запрос. Ведь как здорово просто взять и получить нужное количество строк! Достаточно будет их пронумеровать – и вот список готов.
SELECT rownum as rn FROM dual
CONNECT BY level <= ( SELECT max (id) FROM test_table);
Конструкция “SELECT … FROM dual” используется, когда надо вычислить значение функции, не производя при этом выборки данных. Dual – это системная таблица, состоящая из одного столбца и одной строки. Запрос из нее всегда возвращает одну строку со значением ‘X’. Благодаря такой умопомрачительной стабильности, эту таблицу удобно использовать в качестве источника строк.
Обычно таблицу, которую нагло используют для получения нужного количества строк, не выбирая сами данные, называют pivot. В качестве такой таблицы может выступать любая большая таблица, в том числе системная. Но использование dual в Oracle является более разумным решением.
Теперь, когда список номеров подряд уже есть, достаточно пройтись по нему и сравнить, есть ли такой номер в проверяемой таблице:
SELECT sq.rn
FROM ( SELECT rownum as rn FROM dual
CONNECT BY level <= ( SELECT max (id) FROM test_table)) sq
WHERE sq.rn not in ( SELECT id FROM test_table)
ORDER BY rn;
Всё. Ведро начищено до блеска, лошадь вооружена биноклем для остроты зрения. Да не коснется вас ROLLBACK. COMMIT!
Задается временно именованный результирующий набор, называемый обобщенным табличным выражением (ОТВ). Он получается при выполнении простого запроса и определяется в области выполнения одиночной инструкции SELECT, INSERT, UPDATE, DELETE или MERGE. Это предложение может использоваться также в инструкции CREATE VIEW как часть определяющей ее инструкции SELECT. Обобщенное табличное выражение может включать ссылки на само себя. Такое выражение называется рекурсивным обобщенным табличным выражением.
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
expression_name
Является допустимым идентификатором для обобщенного табличного выражения. Имя выражения expression_name должно отличаться от имени другого обобщенного табличного выражения, определенного в том же предложении WITH <common_table_expression>, но expression_name может совпадать с именем базовой таблицы или представления. Любая ссылка на аргумент expression_name в запросе использует обобщенное табличное выражение, но не базовый объект.
column_name
Задается имя столбца в обобщенном табличном выражении. Повторяющиеся имена в определении одного обобщенного табличного выражения не допускаются. Количество заданных имен столбцов должно совпадать с количеством столбцов в результирующем наборе CTE_query_definition. Список имен столбцов необязателен только в том случае, если всем результирующим столбцам в определении запроса присвоены уникальные имена.
CTE_query_definition
Задается инструкция SELECT, результирующий набор которой заполняет обобщенное табличное выражение. Инструкция SELECT для CTE_query_definition должна соответствовать таким же требованиям, что и при создании представления, за исключением того, что обобщенное табличное выражение (ОТВ) не может определять другое ОТВ. Дополнительные сведения см. в подразделе "Замечания" и разделе CREATE VIEW (Transact-SQL).
Если определено несколько параметров CTE_query_definition, определения запроса должны быть соединены одним из следующих операторов над множествами: UNION ALL, UNION, EXCEPT или INTERSECT.
Remarks
Рекомендации по созданию и использованию обобщенных табличных выражений
Следующие рекомендации относятся к нерекурсивным обобщенным табличным выражениям. Рекомендации, применимые к рекурсивным обобщенным табличным выражениям, см. в расположенном ниже разделе Рекомендации по определению и использованию рекурсивных обобщенных табличных выражений.
За обобщенным табличным выражением (ОТВ) должны следовать одиночные инструкции SELECT , INSERT , UPDATE или DELETE , ссылающиеся на некоторые или на все столбцы ОТВ. Обобщенное табличное выражение может задаваться также в инструкции CREATE VIEW как часть определяющей инструкции SELECT представления.
Несколько определений запросов обобщенных табличных выражений (ОТВ) могут быть определены в нерекурсивных ОТВ. Определения могут объединяться одним из следующих операторов над множествами: UNION ALL , UNION , INTERSECT или EXCEPT .
Обобщенные табличные выражения (ОТВ) могут иметь ссылки на самих себя, а также на ОТВ, определенные до этого в том же предложении WITH . Ссылки на определяемые далее обобщенные табличные выражения недопустимы.
Задание в одном обобщенном табличном выражении нескольких предложений WITH недопустимо. Например, если CTE_query_definition содержит вложенный запрос, этот вложенный запрос не может содержать вложенное предложение WITH, определяющее другое обобщенное табличное выражение.
Следующие предложения не могут использоваться в CTE_query_definition:
ORDER BY (за исключением случаев задания предложения TOP )
Предложение OPTION с указаниями запроса
Если обобщенное табличное выражение используется в инструкции, являющейся частью пакета, то за инструкцией, стоящей перед ней, должен следовать символ точки с запятой.
Запрос, ссылающийся на обобщенное табличное выражение, может использоваться для определения курсора.
В обобщенном табличном выражении могут быть ссылки на таблицы, находящиеся на удаленных серверах.
При выполнении обобщенного табличного выражения (ОТВ) между указаниями, ссылающимися на ОТВ, может быть конфликт с другими указаниями, обнаруживаемыми, когда ОТВ обращаются к их базовым таблицам, так же, как если бы указания ссылались на представления в запросах. Когда это происходит, запрос возвращает ошибку.
Рекомендации по созданию и использованию рекурсивных обобщенных табличных выражений
Следующие рекомендации применимы к определению рекурсивных обобщенных табличных выражений.
Определение рекурсивного обобщенного табличного выражения должно содержать по крайней мере два определения обобщенного табличного выражения запросов — закрепленный элемент и рекурсивный элемент. Может быть определено несколько закрепленных элементов и рекурсивных элементов, однако все определения запросов закрепленного элемента должны быть поставлены перед первым определением рекурсивного элемента. Все определения обобщенных табличных выражений запросов (ОТВ) являются закрепленными элементами, если только они не ссылаются на само ОТВ.
Закрепленные элементы должны объединяться одним из следующих операторов над множествами: UNION ALL, UNION, INTERSECT или EXCEPT. UNION ALL является единственным оператором над множествами, который может находиться между последним закрепленным элементом и первым рекурсивным элементом, а также может применяться при объединении нескольких рекурсивных элементов.
Количество столбцов членов указателя и рекурсивных элементов должно совпадать.
Тип данных столбца в рекурсивном элементе должен совпадать с типом данных соответствующего столбца в закрепленном элементе.
Предложение FROM рекурсивного элемента должно ссылаться на обобщенное табличное выражение expression_name только один раз.
Следующие элементы недопустимы в определении CTE_query_definition рекурсивного элемента:
PIVOT (Если уровень совместимости базы данных имеет значение 110 или больше. См. раздел Критические изменения в функциях компонента ядра СУБД в SQL Server 2016).
LEFT , RIGHT , OUTER JOIN ( INNER JOIN допускается)
Указание, применимое к рекурсивной ссылке на обобщенное табличное выражение в определении CTE_query_definition.
Следующие рекомендации применимы к использованию рекурсивных обобщенных табличных выражений.
Все столбцы, возвращаемые рекурсивным обобщенным табличным выражением, могут содержать значения NULL, независимо от того, могут ли иметь значения NULL столбцы, возвращаемые участвующими инструкциями SELECT .
Неправильно составленное рекурсивное ОТВ может привести к бесконечному циклу. Например, если определение запроса рекурсивного элемента возвращает одинаковые значения как для родительского, так и для дочернего столбца, то образуется бесконечный цикл. Для предотвращения бесконечного цикла можно ограничить количество уровней рекурсии, допустимых для определенной инструкции, при помощи указания MAXRECURSION и значения в диапазоне от 0 до 32 767 в предложении OPTION инструкции INSERT , UPDATE , DELETE или SELECT . Это дает возможность контролировать выполнение инструкции до тех пор, пока не будет разрешена проблема с кодом, из-за которой происходит зацикливание программы. Серверное значение по умолчанию равно 100. Если указано значение 0, ограничения не применяются. В одной инструкции может быть указан только одно значение MAXRECURSION . Дополнительные сведения см. в разделе Указания запросов (Transact-SQL).
Представление, содержащее рекурсивное обобщенное табличное выражение, не может использоваться для обновления данных.
Курсоры могут определяться на запросах при помощи обобщенных табличных выражений. Обобщенное табличное выражение является аргументом select_statement, который определяет результирующий набор курсора. Для рекурсивных обобщенных табличных выражений допустимы только однонаправленные и статические курсоры (курсоры моментального снимка). Если в рекурсивном обобщенном табличном выражении указан курсор другого типа, тип курсора преобразуется в статический.
В обобщенном табличном выражении могут быть ссылки на таблицы, находящиеся на удаленных серверах. Если на удаленный сервер имеются ссылки в рекурсивном элементе обобщенного табличного выражения, создается буфер для каждой удаленной таблицы, так что к таблицам может многократно осуществляться локальный доступ. Если это запрос обобщенного табличного выражения, Index Spool/Lazy Spools отображается в плане запроса и будет иметь дополнительный предикат WITH STACK . Это один из способов подтверждения надлежащей рекурсии.
Аналитические и агрегатные функции в рекурсивной части обобщенных табличных выражений применяются для задания текущего уровня рекурсии, а не для задания обобщенных табличных выражений. Такие функции, как ROW_NUMBER , работают только с подмножествами данных, которые передаются им текущим уровнем рекурсии, но не со всем множеством данных, которые передаются в рекурсивную часть обобщенного табличного выражения. Дополнительные сведения см. в примере "Л. Использование аналитических функций в рекурсивном ОТВ" ниже.
Возможности и ограничения общих табличных выражений в Azure Synapse Analytics и Система платформы аналитики (PDW)
Текущая реализация обобщенных табличных выражений в Azure Synapse Analytics и Система платформы аналитики (PDW) имеет следующие возможности и ограничения:
Обобщенное табличное выражение можно задать в инструкции SELECT .
Обобщенное табличное выражение можно задать в инструкции CREATE VIEW .
Обобщенное табличное выражение можно задать в инструкции CREATE TABLE AS SELECT (CTAS).
Обобщенное табличное выражение можно задать в инструкции CREATE REMOTE TABLE AS SELECT (CRTAS).
Обобщенное табличное выражение можно задать в инструкции CREATE EXTERNAL TABLE AS SELECT (CETAS).
Обобщенное табличное выражение может ссылаться на внешнюю таблицу.
Обобщенное табличное выражение может ссылаться на внешнюю таблицу.
В обобщенном табличном выражении можно задать несколько определений запросов обобщенных табличных выражений (ОТВ).
За обобщенным табличным выражением должна следовать одиночная инструкция SELECT . Инструкции INSERT , UPDATE , DELETE , и MERGE не поддерживаются.
Обобщенное табличное выражение, которое включает ссылки на себя (рекурсивное обобщенное табличное выражение), не поддерживается.
Задание в одном обобщенном табличном выражении нескольких предложений WITH недопустимо. Например, если CTE_query_definition содержит вложенный запрос, этот вложенный запрос не может содержать вложенное предложение WITH , определяющее другое обобщенное табличное выражение.
Предложение ORDER BY невозможно использовать в определении CTE_query_definition, кроме случаев, когда задано предложение TOP .
Если обобщенное табличное выражение используется в инструкции, являющейся частью пакета, то за инструкцией, стоящей перед ней, должен следовать символ точки с запятой.
При использовании в инструкциях, подготовленных методом sp_prepare , обобщенные табличные выражения будут вести себя так же, как другие инструкции SELECT в PDW. Однако если обобщенные табличные выражения используются как часть инструкций CETAS, подготовленных методом sp_prepare , их поведение может отличаться от SQL Server и других инструкций PDW. Это обусловлено особенностями реализации привязки для метода sp_prepare . Если инструкция SELECT , ссылающаяся на обобщенное табличное выражение, использует неправильный столбец, который отсутствует в CTE, метод sp_prepare будет передан без обнаружения ошибки, а ошибка вместо этого будет создана при выполнении метода sp_execute .
Примеры
A. Создание простого обобщенного табличного выражения
В следующем примере выводится общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
Б. Использование обобщенного табличного выражения для ограничения общего и среднего количества отчетов
В следующем примере выводится среднее количество заказов на продажу за все годы для коммерческих представителей.
В. Использование нескольких определений ОТВ (обобщенных табличных выражений) в одном запросе
В следующем примере показано, как определить несколько ОТВ в одном запросе. Обратите внимание, что для разделения определений запросов обобщенных табличных выражений используется запятая. Функция FORMAT, используемая для отображения денежных сумм в формате валюты, доступна в SQL Server 2012 и более поздних версиях.
Здесь приводится частичный результирующий набор.
Г. Использование рекурсивного обобщенного табличного выражения для отображения нескольких уровней рекурсии
В следующем примере представлен иерархический список руководителей и служащих, отчитывающихся перед ними. Пример начинается с создания и заполнения таблицы dbo.MyEmployees .
Использование рекурсивного обобщенного табличного выражения для отображения двух уровней рекурсии
В следующем примере представлены руководители и отчитывающиеся перед ними служащие. Количество возвращаемых уровней ограничено двумя.
Использование рекурсивного обобщенного табличного выражения для отображения иерархического списка
В следующем примере добавляются имена руководителя и сотрудников, а также соответствующие им должности. Иерархия руководителей и служащих дополнительно выделяется с помощью соответствующих отступов на каждом уровне.
Использование подсказки MAXRECURSION для отмены инструкции
Подсказка MAXRECURSION может использоваться для предотвращения входа в бесконечный цикл из-за неверно сформированного рекурсивного CTE-выражения. В следующем примере преднамеренно формируется бесконечный цикл и используется указание MAXRECURSION для ограничения числа уровней рекурсии двумя.
После исправления ошибки в коде подсказка MAXRECURSION больше не нужна. В следующем примере приводится правильный код.
Д. Использование обобщенного табличного выражения для выборочного прохождения рекурсивной связи в инструкции SELECT
В следующем примере показана иерархия узлов и компонентов продукции, необходимых для создания велосипеда для ProductAssemblyID = 800 .
Е. Использование рекурсивного обобщенного табличного выражения в инструкции UPDATE
В следующем примере обновляется значение PerAssemblyQty для всех деталей, используемых при сборке продукта Road-550-W Yellow, 44 (ProductAssemblyID``800 ). Обобщенное табличное выражение возвращает иерархический список деталей, которые непосредственно используются для сборки ProductAssemblyID 800 , и компонентов, которые используются для сборки этих деталей и т. д. Изменяются только строки, возвращенные обобщенным табличным выражением.
З. Использование нескольких привязок и рекурсивных элементов
В следующем примере несколько членов указателя и рекурсивных элементов используются для возврата всех предков указанного лица. Создается и заполняется значениями таблица для формирования генеалогии семьи, возвращаемой рекурсивным обобщенным табличным выражением.
I. Использование аналитических функций в рекурсивном обобщенном табличном выражении
Следующий пример демонстрирует проблему, которая может возникнуть при использовании аналитической или агрегатной функции в рекурсивной части обобщенного табличного выражения.
Следующие результаты являются ожидаемыми результатами выполнения запроса.
Следующие результаты являются фактическими результатами выполнения запроса.
N возвращает 1 для каждого прохода рекурсивной части ОТВ, так как в ROWNUMBER передается только подмножество данных для данного уровня рекурсии. Для каждой итерации рекурсивной части запроса в ROWNUMBER передается только одна строка.
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
К. Использование обобщенного табличного выражения в инструкции CTAS
В следующем примере создается новая таблица, содержащая общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
Л. Использование обобщенного табличного выражения в инструкции CETAS
В следующем примере создается новая внешняя таблица, содержащая общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
М. Использование нескольких разделенных запятыми обобщенных табличных выражений в инструкции
В следующем примере показано включение двух обобщенных табличных выражений в одну инструкцию. Обобщенные табличные выражения не поддерживают вложение (рекурсию).
Всем привет! Тема сегодняшнего материала будет посвящена обобщенным табличным выражениям языка T-SQL, мы с Вами узнаем, что это такое, а также рассмотрим примеры написания запросов с использованием этих самых обобщённых табличных выражений.

Для начала, конечно же, давайте поговорим о том, что вообще из себя представляют обобщенные табличные выражения, какие они бывают, рассмотрим синтаксис, для чего их можно использовать и в заключение разберем несколько примеров.
Что такое обобщенное табличное выражение?
Common Table Expression (CTE) или обобщенное табличное выражение (OTB) – это временные результирующие наборы (т.е. результаты выполнения SQL запроса), которые не сохраняются в базе данных в виде объектов, но к ним можно обращаться.
Главной особенностью обобщенных табличных выражений является то, что с помощью них можно писать рекурсивные запросы, но об этом чуть ниже, а сейчас давайте поговорим о том, в каких случаях нам могут пригодиться OTB, в общем, для чего они предназначены:
- Основной целью OTB является написание рекурсивных запросов, можно сказать для этого они, и были созданы;
- OTB можно использовать также и для замены представлений (VIEW), например, в тех случаях, когда нет необходимости сохранять в базе SQL запрос представления, т.е. его определение;
- Обобщенные табличные выражения повышают читаемость кода путем разделения запроса на логические блоки, и тем самым упрощают работу со сложными запросами;
- Также OTB предназначены и для многократных ссылок на результирующий набор из одной и той же SQL инструкции.
Обобщенное табличное выражение определяется с помощью конструкции WITH, и определить его можно как в обычных запросах, так и в функциях, хранимых процедурах, триггерах и представлениях.
Синтаксис:
После обобщенного табличного выражения, т.е. сразу за ним должен идти одиночный запрос SELECT, INSERT, UPDATE, MERGE или DELETE.
Какие бывают обобщенные табличные выражения?
Они бывают простые и рекурсивные.
Простые не включают ссылки на самого себя, а рекурсивные соответственно включают.
Рекурсивные ОТВ используются для возвращения иерархических данных, например, классика жанра это отображение сотрудников в структуре организации (чуть ниже мы это рассмотрим).
Примечание! Все примеры ниже будут рассмотрены в MS SQL Server 2008 R2.
В качестве тестовых данных давайте использовать таблицу TestTable, которая будет содержать идентификатор сотрудника, его должность и идентификатор его начальника.
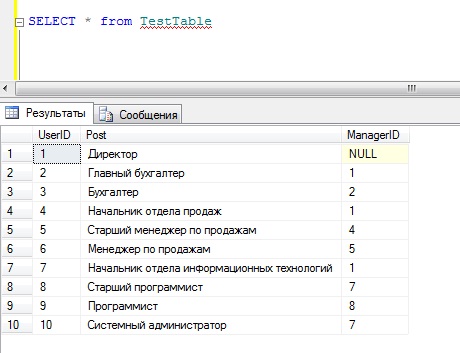
Как видите, у директора отсутствует ManagerID, так как у него нет начальника. А теперь переходим к примерам.
Пример простого обобщенного табличного выражения
Для примера давайте просто выведем все содержимое таблицы TestTable с использованием обобщенного табличного выражения
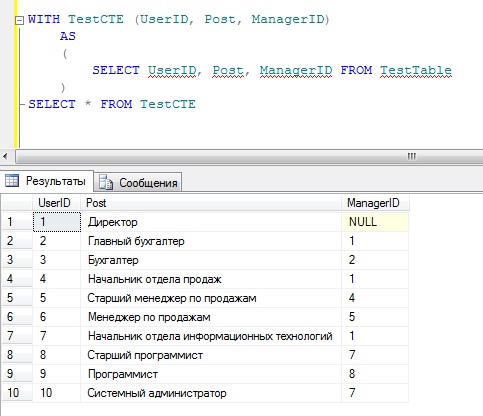
Где TestCTE это и есть псевдоним результирующего набора, к которому мы и обращаемся.
В данном случае мы могли и не перечислять имена столбцов, так как они у нас уникальны. Можно было просто написать вот так:
Пример рекурсивного обобщенного табличного выражения
Теперь допустим, что нам необходимо вывести иерархический список сотрудников, т.е. мы хотим видеть, на каком уровне работает тот или иной сотрудник. Для этого пишем рекурсивный запрос:
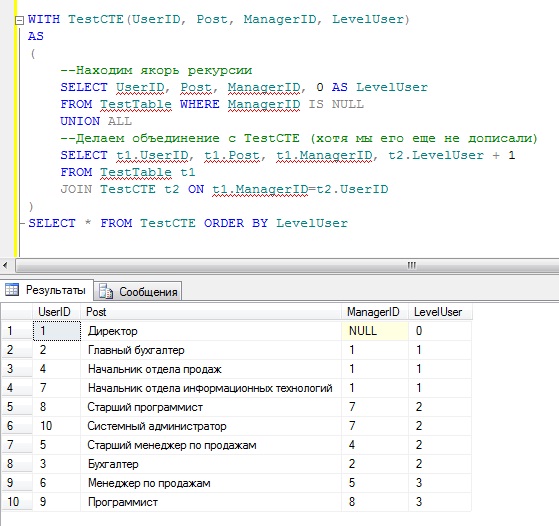
В итоге, если мы захотим, мы можем легко получить список сотрудников определенного уровня, например, нам нужны только начальники отделов, для этого мы просто в указанный выше запрос добавим условие WHERE LevelUser = 1
При написании рекурсивного ОТВ нужно быть внимательным, так как неправильное его составление может привести к бесконечному циклу. Поэтому для этих целей есть опция MAXRECURSION, которая может ограничивать количество уровней рекурсии. Давайте представим, что мы не уверены, что написали рекурсивное обобщенное выражение правильно и для отладки напишем инструкцию OPTION (MAXRECURSION 5), т.е. отобразим только 5 уровня рекурсии, и если уровней будет больше, SQL инструкция будет прервана.
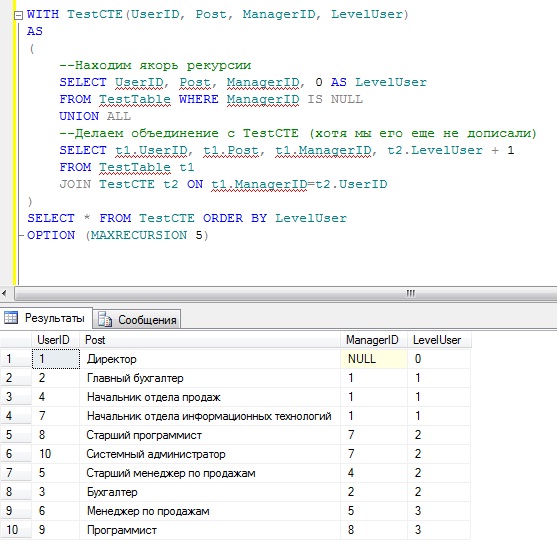
Запрос у нас отработал, что говорит о том, что мы написали его правильно и соответственно OPTION (MAXRECURSION 5) можно смело убрать.
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения специально для начинающих.
Читайте также: