
Организация данных в компьютерных системах кодирование информации структуры данных типы данных
Обновлено: 04.07.2024
Кодирование информации применяют для унификации формы представления данных, которые относятся кразличным типам, в целях автоматизации работы с информацией.
Кодирование – это выражение данных одного типа через данные другого типа. Например, естественные человеческие языки можно рассматривать как системы кодирования понятий для выражения мыслей посредством речи, к тому же и азбуки представляют собой системы кодирования компонентов языка с помощью графических символов.
В вычислительной технике применяется двоичное кодирование. Основой этой системы кодирования является представление данных через последовательность двух знаков: 0 и 1. Данные знаки называются двоичными цифрами (binаrу digit), или сокращенно bit (бит). Одним битом могут быть закодированы два понятия: 0 или 1 (да или нет, истина или ложь и т. п.). Двумя битами возможно выразить четыре различных понятия, а тремя – закодировать восемь различных значений.
Наименьшая единица кодирования информации в вычислительной технике после бита – байт. Его связь с битом отражает следующее отношение: 1 байт = 8 бит = 1 символ.
Обычно одним байтом кодируется один символ текстовой информации. Исходя из этого для текстовых документов размер в байтах соответствует лексическому объему в символах.
Более крупной единицей кодирования информации служит килобайт, связанный с байтом следующим соотношением: 1 Кб = 1024 байт.
Другими, более крупными, единицами кодирования информации являются символы, полученные с помощью добавления префиксов мега (Мб), гига (Гб), тера (Тб):
1 Мб = 1 048 580 байт;
1 Гб = 10 737 740 000 байт;
Для кодирования двоичным кодом целого числа следует взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, которая записывается справа налево вместе с последним частным, и будет являться двоичным аналогом десятичного числа.
В процессе кодирования целых чисел от 0 до 255 достаточно использовать 8 разрядов двоичного кода (8 бит). Применение 16 бит позволяет закодировать целые числа от 0 до 65 535, а с помощью 24 бит – более 16,5 млн различных значений.
Для того чтобы закодировать действительные числа, применяют 80-разрядное кодирование. В этом случае число предварительно преобразовывают в нормализованную форму, например:
2,1427926 = 0,21427926 ? 101;
500 000 = 0,5 ? 106.
Первая часть закодированного числа носит название мантиссы, а вторая часть – характеристики. Основная часть из 80 бит отводится для хранения мантиссы, и некоторое фиксированное число разрядов отводится для хранения характеристики.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
Существует три основных способа кодирования информации:- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
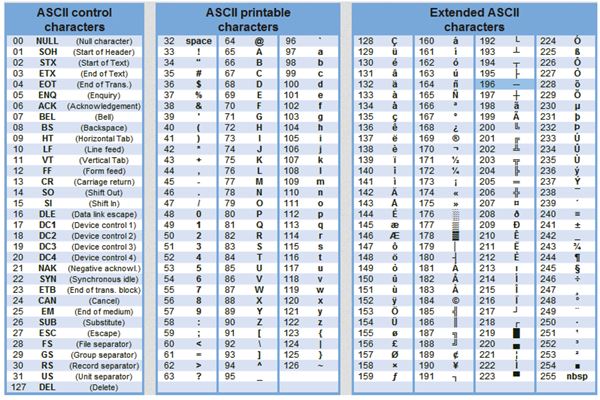
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
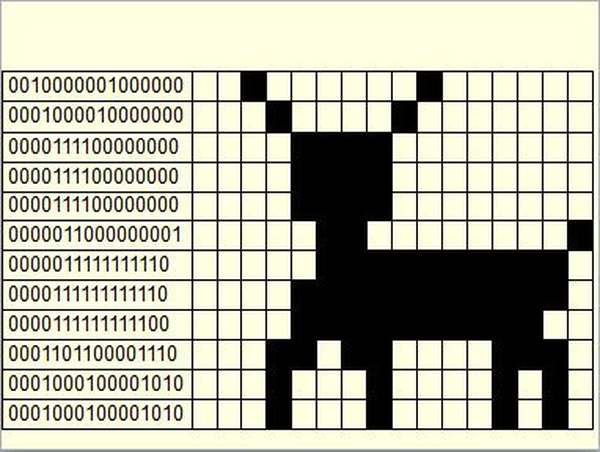
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Теоретический материал для самостоятельного изучения:
В основе любой информационной деятельности лежат так называемые информационные процессы — совокупность последовательных действий (операций), производимых над информацией для получения какого-либо результата (достижения цели). Информационные процессы могут быть различными, но все их можно свести к трем основным: обработка информации, передача информации и хранение информации.
Обработка информации
Обработка информации — это целенаправленный процесс изменения формы ее представления или содержания.
Из курса информатики основной школы вам известно, что существует два различных типа обработки информации:
- обработка, связанная с получением новой информации (например, нахождение ответа при решении математической задачи; логические рассуждения и др.);
- обработка, связанная с изменением формы представления информации, не изменяющая ее содержания. К этому типу относятся:
— кодирование — переход от одной формы представления информации к другой, более удобной для восприятия, хранения, передачи или последующей обработки; один из вариантов кодирования — шифрование, цель которого — скрыть смысл информации от посторонних;
— структурирование — организация информации по некоторому правилу, связывающему ее в единое целое (например, сортировка);
— поиск и отбор информации, требуемой для решения некоторой задачи, из информационного массива (например, поиск в словаре).
Общая схема обработки информации может быть представлена следующим образом:

Исходные данные — это информация, которая подвергается обработке.
Правила — это информация процедурного типа. Они содержат сведения для исполнителя о том, какие действия требуется выполнить, чтобы решить задачу.
Исполнитель — тот объект, который осуществляет обработку. Это может быть человек или компьютер. При этом человек, как правило, является неформальным, творчески действующим исполнителем. Компьютер же способен работать только в строгом соответствии с правилами, т.е. является формальным исполнителем обработки информации.
Рассмотрим отдельные процессы обработки информации более подробно.
Кодирование информации
Кодирование информации — это обработка информации, заключающаяся в ее преобразовании в некоторую форму, удобную для хранения, передачи, обработки информации в дальнейшем.
Код — это система условных обозначений (кодовых слов), используемых для представления информации.
Кодовая таблица — это совокупность используемых кодовых слов и их значений.
Нам уже знакомы примеры равномерных двоичных кодов — пятиразрядный код Бодо и восьмиразрядный код ASCII.
Самый известный пример неравномерного кода — код Морзе. В этом коде все буквы и цифры кодируются в виде различных последовательностей точек и тире.

Чтобы отделить коды букв друг от друга, вводят еще один символ — пробел (пауза). Например, слово «byte», закодированное с помощью кода Морзе, выглядит следующим образом:
При использовании неравномерных кодов важно понимать, сколько различных кодовых слов они позволяют построить.
Пример 1. Имеющаяся информация должна быть закодирована в четырехбуквенном алфавите . Выясним, сколько существует различных последовательностей из 7 символов этого алфавита, которые содержат ровно пять букв А.
Нас интересует семибуквенная последовательность, т. е.

Если бы у нас не было условия, что в ней должны содержаться ровно пять букв А, то для первого символа было бы 4 варианта, для второго — тоже 4, и т. д.
Тогда мы получили бы: 4 · 4 · 4 · 4 · 4 · 4 · 4 = 16384 варианта.
Теперь вернемся к имеющемуся условию и заполним пять первых мест буквой А. Получим:

Так как на 6-м и 7-м местах могут стоять любые из трех оставшихся букв B, C, D, то всего существует 9 (3 · 3) вариантов последовательностей.
Но ведь буквы А могут находиться на любых пяти из семи имеющихся позиций. А сколько таких вариантов всего?
Префиксный код — код со словом переменной длины, обладающий тем свойством, что никакое его кодовое слово не может быть началом другого (более длинного) кодового слова.
- Код, состоящий из слов 0, 10 и 11, является префиксным.
- Код, состоящий из слов 0, 10, 11 и 100, не является префиксным.
Также достаточным условием однозначного декодирования неравномерного код является обратное условие Фано. В нем требуется, чтобы никакой код не был окончанием другого (более длинного) кода.
Пример 2. Двоичные коды для 5 букв латинского алфавита представлены в таблице:

Можно заметить, что для заданных кодов не выполняется прямое условие Фано:
B=01, E=011, и D=10, C=100.
А вот обратное условие Фано выполняется: никакое кодовое слово не является окончанием другого. Следовательно, имеющуюся строку нужно декодировать справа налево (с конца). Получим
01 10 100 011 000 = BDCEA
Для построения префиксных кодов удобно использовать бинарные деревья, в которых от каждого узла отходят только два ребра, помеченные цифрами 0 и 1.
Пример 3. Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. При этом используются такие кодовые слова: А — 0, Б — 10, В — 110. Каким кодовым словом может быть закодирована буква Г? Если таких слов несколько, укажите кратчайшее из них.
Построим бинарное дерево:

Чтобы найти код символа, нужно пройти по стрелкам от корня дерева к нужному листу, выписывая метки стрелок, по которым мы переходим.
Определим положение букв А, Б и В на этом дереве, зная их коды. Получим:

Чтобы код был префиксным, ни один символ не должен лежать на пути от корня к другому символу. Уберем лишние стрелки:

На получившемся дереве можно определить подходящее расположение буквы Г и его код.
Поиск информации
Задача поиска обычно формулируется следующим образом. Имеется некоторое хранилище информации — информационный массив (телефонный справочник, словарь, расписание поездов, диск с файлами и др.). Требуется найти в нем информацию, удовлетворяющую определенным условиям поиска (телефон какой-то организации, перевод слова, время отправления поезда, нужную фотографию и т. д.). При этом, как правило, необходимо сократить время поиска, которое зависит от способа организации данных и используемого алгоритма поиска.
Алгоритм поиска, в свою очередь, также зависит от способа организации данных.
Если данные никак не упорядочены, то мы имеем дело с неструктурированным набором данных. Для осуществления поиска в таком наборе применяется метод последовательного перебора.
При последовательном переборе просматриваются все элементы подряд, начиная с первого. Поиск при этом завершается в двух случаях:
— искомый элемент найден;
— просмотрен весь набор данных, но искомого элемента среди них не нашлось.
— искомый элемент оказался первым среди просматриваемых. Тогда просмотр всего один;
Если же информация упорядочена, то мы имеем дело со структурой данных, в которой поиск осуществляется быстрее, можно построить оптимальный алгоритм.

Одним из оптимальных алгоритмов поиска в структурированном наборе данных может быть метод половинного деления.
Напомним, что при этом методе искомый элемент сначала сравнивается с центральным элементом последовательности. Если искомый элемент меньше центрального, то поиск продолжается аналогичным образом в левой части последовательности. Если больше, то — в правой. Если же значения искомого и центрального элемента совпадают, то поиск завершается.
Пример 4. В последовательности чисел 61 87 180 201 208 230 290 345 367 389 456 478 523 567 590 требуется найти число 180.
Процесс поиска представлен на схеме:

Передача информации
Передача информации — это процесс распространения информации от источника к приемнику через определенный канал связи.
На рисунке представлена схема модели процесса передачи информации по техническим каналам связи, предложенная Клодом Шенноном.

Работу такой схемы можно пояснить на примере записи речи человека с помощью микрофона на компьютер.
Источником информации является говорящий человек. Кодирующим устройством — микрофон, с помощью которого звуковые волны (речь) преобразуются в электрические сигналы. Канал связи — провода, соединяющие микрофон и компьютер. Декодирующее устройство — звуковая плата компьютера. Приемник информации — жесткий диск компьютера.
При передаче сигнала могут возникать разного рода помехи, которые искажают передаваемый сигнал и приводят к потере информации. Их называют «шумом».
В современных технических системах связи борьба с шумом (защита от шума) осуществляется по следующим двум направлениям:
Но чрезмерная избыточность приводит к задержкам и удорожанию связи. Поэтому очень важно иметь алгоритмы получения оптимального кода, одновременно обеспечивающего минимальную избыточность передаваемой информации и максимальную достоверность принятой информации.
Важной характеристикой современных технических каналов передачи информации является их пропускная способность — максимально возможная скорость передачи информации, измеряемая в битах в секунду (бит/с). Пропускная способность канала связи зависит от свойств используемых носителей (электрический ток, радиоволны, свет). Так, каналы связи, использующие оптоволоконные кабели и радиосвязь, обладают пропускной способностью, в тысячи раз превышающей пропускную способность телефонных линий.
Современные технические каналы связи обладают, перед ранее известными, целым рядом достоинств:
— высокая пропускная способность, обеспечиваемая свойствами используемых носителей;
— надёжность, связанная с использованием параллельных каналов связи;
— помехозащищённость, основанная на автоматических системах проверки целостности переданной информации;
— универсальность используемого двоичного кода, позволяющего передавать любую информацию — текст, изображение, звук.
Объём переданной информации I вычисляется по формуле:
где v — пропускная способность канала (в битах в секунду), а t — время передачи.
Рассмотрим пример решения задачи, имеющей отношение к процессу передачи информации.
Пример 5. Документ объемом 10 Мбайт можно передать с одного компьютера на другой двумя способами.
А. Передать по каналу связи без использования архиватора.
Б. Сжать архиватором, передать архив по каналу связи, распаковать.
Какой способ быстрее и насколько, если:
— средняя скорость передачи данных по каналу связи составляет 2 18 бит/с;
— объем сжатого архиватором документа равен 25% от исходного объема;
— время, требуемое на сжатие документа — 5 секунд, на распаковку — 3 секунды?
Для решения данной задачи диаграмма Гантта не нужна; достаточно выполнить расчёты для каждого из имеющихся вариантов передачи информации.
Рассмотрим вариант А. Длительность передачи информации в этом случае составит:
Рассмотрим вариант Б. Длительность передачи информации в этом случае составит:
Итак, вариант Б быстрее на 232 с.
Хранение информации
Сохранить информацию — значит тем или иным способом зафиксировать её на некотором носителе.
Носитель информации — это материальная среда, используемая для записи и хранения информации.
Основным носителем информации для человека является его собственная память. По отношению к человеку все прочие виды носителей информации можно назвать внешними.
Основное свойство человеческой памяти — быстрота, оперативность воспроизведения хранящейся в ней информации. Но наша память не надёжна: человеку свойственно забывать информацию. Именно для более надёжного хранения информации человек использует внешние носители, организует внешние хранилища информации.
Виды внешних носителей менялись со временем: в древности это были камень, дерево, папирус, кожа и др. Долгие годы основным носителем информации была бумага. Развитие компьютерной техники привело к созданию магнитных (магнитная лента, гибкий магнитный диск, жёсткий магнитный диск), оптических (CD, DVD, BD) и других современных носителей информации.
В последние годы появились и получили широкое распространение всевозможные мобильные электронные (цифровые) устройства: планшетные компьютеры, смартфоны, устройства для чтения электронных книг, GPS-навигаторы и др. Появление таких устройств стало возможно, в том числе, благодаря разработке принципиально новых носителей информации, которые:
- Обладают большой информационной ёмкостью при небольших физических размерах.
- Характеризуются низким энергопотреблением при работе, обеспечивая наряду с этим высокие скорости записи и чтения данных.
- Энергонезависимы при хранении.
- Имеют долгий срок службы.
Всеми этими качествами обладает флеш-память (англ. flash-memory). Выпуск построенных на их основе флеш-накопителей, называемых в просторечии «флэшками», был начат в 2000 году.
Кодирование – это процесс преобразования данных из исходной формы представления в коды.
Код – это набор условных символов для представления информации.
К целям использования кодирования относятся:
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
- компактное хранение, удобство при обработке и передаче информации через автоматические устройства с программным обеспечением;
- удобство при обмене данными между субъектами;
- четкое отображение информации;
- распознавание объектов и субъектов;
- шифровка конфиденциальной информации.
Виды кодирования информации, какие бывают способы изменения вида
Перевести в систему кодов можно текст, цвета, графическое изображение, числа, звук, видео и т.д.
Кодирование текстовой информации
Выделяют 3 основных вида кодирования текста:
- графический – текст переводится в рисунки;
- символьный – преобразование происходит с помощью знаков алфавита, в котором представлен исходный текст;
- числовой – текст кодируется в числа.
Поскольку вся информация представлена в памяти компьютера в двоичной системе, для работы с текстом в ЭВМ используют числовой способ кодирования.
Изначально кодирование символов осуществлялось по 7-битному стандарту. В этой системе вычислительная машина записывала в свою память 128 разных состояний. Каждому из них соответствовала определенная буква, знак или символ.
Двоичное кодирование предполагает, что каждый знак соответствует уникальному двоичному коду. В стандартном коде информационного обмена ASCII регламентируется присвоение символу такой последовательности. Первые 33 кода – это операции, такие как пробел, ввод и т.п. Коды 33 – 127 соответствуют буквам латинского алфавита, цифрам, арифметическим символам и знакам препинания. Коды 128 – 255 – это буквы национального алфавита.
Впервые русские буквы были закодированы в стандарте КОИ-8 на вычислительных машинах с операционной системой UNIX. На сегодняшний день более широко используется стандартная кодировка Microsoft Windows с обозначением «Кириллица». Русские буквы для операционной системы MS-DOS преобразуются в стандарте СР866. В устройствах серии Macintosh компании Apple – это кодировка Мас. Еще один стандарт для представления русского алфавита – ISO 8859-5.
Неудобство существования разных кодовых языков состоит в том, что они не адаптированы. Следовательно, текст, созданный в одном стандарте, не будет отображаться в другой кодовой системе. Разработчики нашли решение этой проблемы и предусмотрели автоматическую перекодировку текстовой информации при работе с разными кодовыми стандартами.
Кодирование цвета
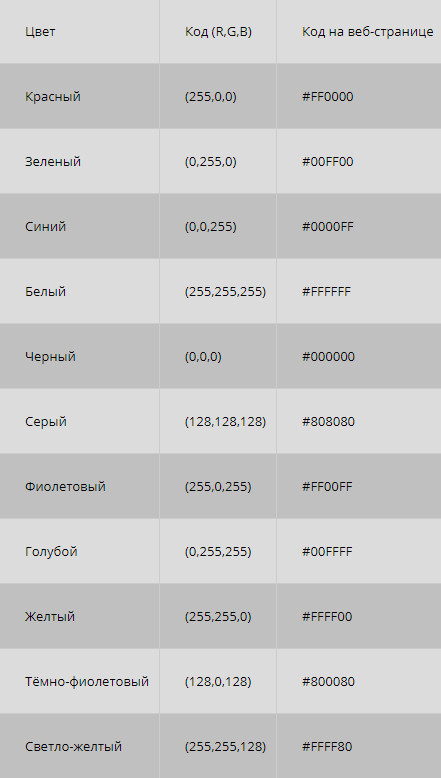
Основой всех цветов являются красный, зеленый и синий. На этом свойстве базируется одна из моделей представления цветового разнообразия, названная по первым буквам данных цветов RGB (red, green, blue). Этот стандарт использует всего 3 байта, по одному на каждый цвет. При единице цвет включен, при нуле – выключен. Из трех базовых цветов можно составить 8 двоичных кодов , значит, 8 разных цветов: красный, зеленый синий, желтый, белый, голубой, лиловый, черный.
Для управления яркостью вводят еще один бит, и получается модель IRGB (от английского Intensity – интенсивность). При этом образуются 8 дополнительных кодов, соответственно, цветовая гамма расширяется до 16 оттенков. Добавляются серый, ярко-синий, ярко-зеленый, ярко-голубой, ярко-красный, ярко-лиловый, ярко-желтый, ярко-белый.
Создание более богатой палитры осуществляется в 6-битной системе, называемой RrGgBb. Код 00 означает, что цвет выключен, 01 – это слабый цвет, 10 – обычный оттенок и 11 – интенсивный. В этом случае можно закодировать 64 цвета. Несмотря на это, на экране параллельно могут отражаться до 16 оттенков, поскольку кодирование в кадровом буфере происходит в 4-битной системе. Представление цвета в RrGgBb применяется на видеоадаптерах EGA.
В принтерах используется иная цветовая модель – CMYK. Она базируется на голубом, фиолетовом, желтом и черном цветах (Cyan, Magenta, Yellow, Key color – обозначение черного цвета). Так как эти тона получены при вычитании из белого основных цветов, модель называется субстрактивной.
Выбор такой цветовой модели для полиграфии объясняется техническим удобством. Так как печать производится на бумаге, нужно учитывать свойство поверхности отражать. В этом случае проще считать, сколько света отразилось, чем поглотилось.
Кодирование графической информации
Представление графической информации в компьютерах подразделяется на два формата:
- растровая графика;
- векторная графика.
Растровый формат можно назвать точечным. Расположенные строго по строкам и столбцам точки имеют отдельные координаты нахождения на дисплее, цвет и уровень интенсивности. Качество изображения напрямую зависит от количества точек – чем их больше, тем картинка качественнее. Растровый способ кодирования подходит для фотографий.
Векторная графика опирается на закодированные геометрические фигуры. В числовой формат приведены размеры объектов, координаты вершин, толщина контуров цвет заливки. Векторное кодирование удобно применять при создании рекламной продукции.
Кодирование числовой информации
Числа в памяти вычислительных машин хранятся в двоичной системе счисления. Выделяют два способа представления чисел:
- форма с фиксированной точкой – для целых чисел;
- форма с плавающей точкой – для действительных чисел.
Целочисленные значения в компьютере представлены с фиксированной запятой.
Целое положительное число переводят в двоичную систему счисления. К полученному коду приписывают 2 нуля слева. Крайний разряд слева в положительном числе равен 0.
Целое отрицательное число преобразуется следующим образом. Число без минуса переводят в двоичную систему, дополняют его нулями слева. Образовавшийся код переводят в обратный, заменяя нули единицами, а единицы – нулями. К полученной комбинации чисел прибавляют 1.
Порядок кодирования действительного или вещественного числа выглядит следующим образом. Число десятичной системы счисления переводят в двоичную. Определяют так называемую мантиссу числа: перемещают запятую в нужную сторону, чтобы слева не было ни одной единицы. Далее определяют значение порядка – количество знаков, на которое перемещена запятая для определения мантиссы.
Кодирование звуковой информации
Звук – это волны с постоянно меняющейся частотой и интенсивностью, вызванные колебанием частиц. Человек распознает звук благодаря меняющемуся давлению акустической волны на препятствия. Громкость звука зависит от акустики звуковой волны, а тон – от частоты.
При оцифровке непрерывная акустическая волна временно превращается в прерывистую. Дискретная форма представляет собой короткие отрезки с неизменным сигналом.
Частота дискретизации – количество измерений громкости в секунду.
Глубина кодирования звука – количество данных, необходимое для преобразования прерывистых уровней громкости звукового сигнала.
От частоты дискретизации глубины кодирования звука зависит точность воспроизведения оригинального звука. Чем выше эти показатели, тем корректнее представление звуковой информации.
Кодирование видеозаписи
Видеофайл состоит из звукового элемента и графического изображения, поэтому эти составляющие подвергаются раздельной кодировке.
Принципы преобразования звука видеозаписи в двоичную систему аналогичны с кодированием обычной звуковой информации.
Последовательность кодирования графики также схожа с переводом обычного изображения в двоичный код. В случае с видео шифруется лишь первый кадр. Последующие изображения преобразуются относительно предыдущей картинки посредством записи изменений.
По завершении процесса кодирования звуковой дорожки и графики получается двоичный код для хранения в памяти ПК и других электронных носителях. Синхронность воспроизведения видеозаписи осуществляется путем разделения этих операций.
Читайте также: