
Параметры команды imp oracle
Обновлено: 07.07.2024
Импорт и экспорт
export data rows (Y)
log file of screen output STATISTICS
CONSTRAINTS export constraints (Y)
direct path (N) TRIGGERS
display progress every x rows (0) maximum size of each dump file select clause used to export a subset of a table
parameter filename cross-table consistency analyze objects
export triggers (Y)
The following keywords only apply to transportable tablespaces TRANSPORT TABLESPACE export transportable tablespace metadata (N) TABLESPACES list of tablespaces to transport Export terminated successfully without warnings.
Давайте подробно рассмотрим наиболее существенные параметры, а также те параметры, которые требуют комментариев. Очевидные параметры, вроде USERID, мы описывать не будем. Параметры, которые я считаю устаревшими, такие как INCTYPE, тоже не описываются:
Этот параметр задает размер буфера извлечения, используемого утилитой ЕХР. Если поделить значение параметра BUFFER на максимальный размер строки в этой таблице, можно определить, сколько строк за раз будет извлекать из таблицы утилита ЕХР. Чем больше размер буфера, тем выше производительность. Я пришел к выводу, что оптимальный размер буфера - около 100 строк.
Учтите, что некоторые таблицы, в частности, содержащие столбцы типа LONG или большие двоичные объекты, считываются по одной строке, независимо от размера буфера. Нужно только проверить, достаточен ли размер буфера для размещения самого большого столбца.
Этот параметр не задает сжатие экспортированных данных. Он управляет генерацией конструкции STORAGE для экспортируемых объектов. Если оставить значение Y, конструкция хранения будет задавать для объектов начальный экстент, размер которого равен суммарному размеру их текущих экстентов. Т.е. утилита ЕХР будет генерировать оператор CREATE и с его помощью попытаться поместить весь объект в одном экстенте.
Рекомендую устанавливать compress = N и
использовать локально управляемые табличные пространства.
Указывает утилите ЕХР, следует экспортировать ли строки данных таблиц или только структуру. Я часто использую этот параметр со значением N для экспортирования структур.
Если имеет положительное значение, файл DMP, создаваемый утилитой экспорта, устанавливается в максимальный размер. Используется при экспорте более двух гигабайт данных. Подробнее см. в разделе Экспортирование больших объемов данных .
Позволяет связывать конструкцию WHERE с экспортируемыми таблицами. Конструкция WHERE будет применяться к строкам в ходе экспорта на уровне таблиц, при этом будут экспортироваться только строки, удовлетворяющие конструкции WHERE. Это позволяет экспортировать срез таблицы. Пример см. в разделе Выделение подмножеств данных .
Если имеет значение Y, экспортируется вся база данных. При этом выбираются все пользователи, определения табличных пространств, системные привилегии и остальное содержимое базы данных.
Позволяет задать список схем для экспорта. Используется для клонирования схемы или переименования пользователя.
Позволяет задать список экспортируемых таблиц.
Задает имя файла параметров, содержащего пары parameter name = values. Может использоваться как альтернативный вариант заданию всех параметров в командной строке. Чаще всего используется для задания длинных списков экспортируемых таблиц или параметра QUERY.
Указывает, должно ли экспортирование выполняться в транзакции только для чтения. Это гарантирует согласованность различных таблиц. Как было описано в главе 3, каждый отдельный запрос выполняется как согласованный по чтению. Транзакция только для чтения (или с уровнем изолированности SERIALIZABLE) распространяет согласованность по чтению до уровня транзакции. Если экспортируются таблицы, связанные декларативным требованием целостности ссылок (Rl - Referential Integrity) или вложенные таблицы и в дальнейшем планируется импортировать их вместе, рекомендуется использовать параметр consistent = Y. Это особенно важно, если велика вероятность изменения таблиц при экспортировании.
Импорт и экспорт 403
Указывает, будет ли утилита ЕХР использоваться для экспортирования метаданных набора переносимых табличных пространств. Подробнее об этом см. в разделе Перенос данных .
Используется совместно с параметром TRANSPORT TABLESPACE, чтобы задать список табличных пространств для переноса.
Параметры утилиты IMP
Вот какой результат выдает утилита IMP при передаче ей параметра HELP = Y:
Import: Release 8.1.6.0.0 - Production on Mon Mar 19 16:10:14 2001
(c) Copyright 1999 Oracle Corporation. All rights reserved.
You can let Import prompt you for parameters by entering the IMP command followed by your username/password:
Example: IMP SCOTT/TIGER
Or, you can control how Import runs by entering the IMP command followed by various arguments. To specify parameters, you use keywords:
Format: IMP KEYWORD=value or KEYWORD=(value1,value2. valueN) Example: IMP SCOTT/TIGER IGNORE=Y TABLES=(EMP,DEPT) FULL=N
or TABLES=(T1:P1,T1:P2), if Tl is partitioned table
USERID must be the first parameter on the command line.
Keyword Description (Default) Keyword
USERID username/password FULL
FILE input files (EXPDAT.DMP) TOUSER SHOW just list file contents (N) TABLES IGNORE ignore create errors (N) RECORDLENGTH GRANTS import grants (Y) INCTYPE
INDEXES import indexes (Y) COMMIT
ROWS import data rows (Y) PARFILE
LOG log file of screen output CONSTRAINTS DESTROY overwrite tablespace data file (N) INDEXFILE write table/index info to specified file SKIP UNUSABLE INDEXES skip maintenance of unusable indexes ANALYZE execute ANALYZE statements in dump file (Y) FEEDBACK display progress every x rows(0)
import entire file (N) list of usernames list of table names length of IO record incremental import type commit array insert (N) parameter filename import constraints (Y)
Поэтому решил описать в примерах, как это реализовано у меня, на реальной системе.
Итак,у меня стоит Oracle XE11 на Debian 7.
Начну я издалека. С создания пользователей и табличных пространств.
далее станет понятно, почему это важно.
у меня в системе два пользователя, которые являются собственниками объектов БД.
и для каждого пользователя свой tablespace.
* пользователь inventory отвечает за объекты, хранящие конфигурации сети.
эта информация модифицируется в режиме реального времени человеками.
и потерять ее будет крайне неприятно. Поэтому она каждую ночь в час наименьшей
нагрузки отправляется в экспорт. хранятся все экспорты за каждый день с момента запуска системы.
* пользователь alarm отвечает за объекты хранящие данные аварийной статистики сети.
потеря этой информации будет неприятна, но не критична. экспорт выполняется каждый день,
но хранятся файлы лишь 7 последних дней.
Создание пользоватей
запускаем
sqlplus /nolog
и последовательно даем команды :
SET LINESIZE 120 сделает ширину экрана 120 символов
connect system/technic@127.0.0.1;
подключиться к локальному Oracle от пользователя system с паролем technic
вам вместо technic нужно написать тот пароль который указвался при установке
create tablespace inventory datafile '/u01/app/oracle/oradata/XE/inventory.dbf' size 512M
autoextend on next 128M maxsize 1024M
/
создает табличное пространство с именем inventory, файлом данных /u01/app/oracle/oradata/XE/inventory.dbf
первоначальным размером 512мб и авторасширением по 128мб вплоть до 1024мб
create tablespace alarms datafile '/u01/app/oracle/oradata/XE/alarms.dbf' size 512M autoextend on next 512M maxsize 4096M
/
строки 1-7:
создаем пользователя inventory
c паролем inventory_p
в табличном пространстве inventory,
временное табл. пространство TEMP
с профилем DEFAULT
и неограниченной квотой в пространстве inventory
строки 9-24:
выдаем права пользователю inventory
у меня так, а вы свои права внимательно выдавайте,
по принципу минимальных привилегий.
например SELECT ANY TABLE возможно и не нужен.
-------------------------------------------------------
аналогично для пользователя alarms:
вводим quit и выходим из sqlplus.
ЭКСПОРТ
существует несколько режимов экспорта.
я использую режим, в котором экспортируются все объекты пользователя
от имени которого запущен экспорт.
USERID= login/password@dbname - идентификатор подключения
FEEDBACK=1000 выводит на экран подобие индикатора прогресса.
COMPRESS=Y включает сжатие данных в файле
FILE=inventory.dat имя файла, куда записывать данные экспорта
LOG=inventory-exp.LOG имя файла, куда записывать лог экспорта
ИМПОРТ
параметры импорта аналогичны параметрам экспорта, но есть один подводный камень :
поскольку импорт в данном случае запускается от имени определенного пользователя,
то этот пользователь должен существовать, и иметь необходимые прививилегии.
например если при импорте у пользователя inventory не будет привилегии create sequence
импорт не сможет импортировать последовательности, т.к. у пользователя нет соответсвующей
привилегии. В лог будет записана ошибка "недостаточно привилегий".
Поэтому если мы собираемся импортировать данные на только что установленную БД,
то нужно создать пользователей и выдать им привилегии не меньше тех, что были
при экспорте - иначе некоторые объекты могут не быть импортированы по причине недостатка привилегий.
У меня была ситуация, когда приходилось восстанавливать данные после экспериментов с БД.
В этом случае я выполнял экспорт данных,
а перед восстановлением удалял пользователей и их табличные пространства:
затем создаем по-новому табличные пространства,
пользователей, и назначаем им привилегии как рассказано в начале статьи.
Использование инструмента экспорта и импорта Oracle exp / imp
1. Экспортируйте инструмент exp
1. Это следующий исполняемый файл операционной системы Каталог хранения / ORACLE_HOME / bin
Инструмент экспорта exp сжимает резервную копию данных в базе данных в двоичный системный файл и может быть перенесен между различными ОС
Имеет три режима:
A. Режим пользователя: экспортировать все объекты пользователя и данные в объекты;
B. Режим таблицы: экспортировать все или указанные таблицы пользователей;
C. Вся база данных: экспорт всех объектов в базе данных.
2. Примеры использования инструмента экспорта exp в режиме интерактивной командной строки
3. Пример инструмента экспорта exp неинтерактивной командной строки
Описание: Экспорт двух таблиц emp и dept in scott user в файл /directory/scott.dmp
Описание: Добавить условие запроса экспорта emp в exp = job = 'salesman' и sal <1600
(Но лично я редко использую его таким образом, или после генерации записей, которые удовлетворяют условиям, во временную таблицу, тогда exp будет более удобным)
$ exp parfile=username.par file=/directory1/username_1.dmp,/directory1/username_2.dmp filesize=2000M log=/directory2/username_exp.log
Файл параметров username.par content
userid=username/userpassword
buffer=8192000
compress=n
grants=y
Примечание: username.par - это файл параметров, используемый инструментом экспорта exp
Размер файла определяет максимальное количество байтов сгенерированного двоичного файла резервной копии.
(Может использоваться для устранения ограничений физических файлов 2G под определенной ОС, ускорения скорости сжатия и упрощения записи исторических данных на компакт-диск и т. Д.)
2. Импортировать инструмент imp
1. Это исполняемый файл в операционной системе. Каталог хранения / ORACLE_HOME / bin
Инструмент импорта imp импортирует двоичные системные файлы, сформированные EXP, в базу данных.
Имеет три режима:
A. Режим пользователя: экспортировать все объекты пользователя и данные в объекты;
B. Режим таблицы: экспортировать все или указанные таблицы пользователей;
C. Вся база данных: экспорт всех объектов в базе данных.
Только пользователи с разрешениями IMP_FULL_DATABASE и DBA могут импортировать всю базу данных.
Шаги беса:
(1) create table (2) insert data (3) create index (4) create triggers,constraints
2. Примеры импорта инструмента имп интерактивной командной строки
3. Пример неинтерактивной командной строки imp инструмента импорта
$ imp system/manager fromuser=jones tables=(accts)
$ imp system/manager fromuser=scott tables=(emp,dept)
$ imp system/manager fromuser=scott touser=joe tables=emp
$ imp scott/tiger file = expdat.dmp full=y
$ imp scott/tiger file = /mnt1/t1.dmp show=n buffer=2048000 ignore=n commit=y grants=y full=y log=/oracle_backup/log/imp_scott.log
$ imp system/manager parfile=params.dat
содержание params.dat
file=dba.dmp show=n ignore=n grants=y fromuser=scott tables=(dept,emp)
4. Возможные проблемы с импортным инструментом imp
(1) Объект базы данных уже существует
В общем, перед импортом данных вы должны полностью удалить таблицы, последовательности, функции / процедуры, триггеры и т. Д. Под целевыми данными;
Объект базы данных уже существует, в соответствии с параметром imp по умолчанию, импорт завершится неудачно
Если используется параметр ignore = y, содержимое данных в файле exp будет импортировано
Если таблица имеет уникальные ограничения по ключевым словам, неквалифицированные условия не будут импортированы
Если таблица не имеет ограничения уникального ключевого слова, это приведет к дублированию записей
(2) Объекты базы данных имеют ограничения первичного и внешнего ключа
Если ограничения первичного и внешнего ключей не соблюдены, данные не будут импортированы
Решение. Сначала импортируйте основную таблицу, а затем импортируйте таблицу зависимостей.
Отключите ограничения первичного и внешнего ключей целевого объекта импорта, после импорта данных включите их снова
(3) Недостаточные полномочия
Если вы хотите импортировать данные пользователя A в пользователя B, пользователь A должен иметь разрешение imp_full_database
(4) При импорте больших таблиц (более 80 МБ) распределение памяти завершается неудачно
В EXP по умолчанию, compress = Y, это означает, что все данные сжимаются в одном блоке данных.
При импорте, если нет непрерывного большого блока данных, импорт завершится неудачно.
При экспорте больших таблиц размером более 80M помните, что compress = N, это не приведет к этой ошибке.
(5) Наборы символов, используемые imp и exp, отличаются
Если набор символов отличается, импорт завершится неудачно, вы можете изменить переменную среды unix или информацию, связанную с NLS_LANG, в реестре NT.
После завершения импорта измените его обратно.
Для полноты картины напомню, что некоторые параметры утилиты импорта могут конфликтовать друг с другом. Например, если написать - FULL = Y и FROMUSER = MILLER, то получите ошибку! Так же параметр DESTROY может быть очень полезным для админов БД, которые работают с несколькими БД, на одном сервере. Поскольку в процессе полного экспорта БД, осуществляется запись всего словаря данных. А, в файл дампа экспорта, заносятся определения табличных пространств и файлов данных. При этом, если файл дампа экспорта используется для миграции в другую БД того же сервера у вас могут возникнуть проблемы. Это связано с тем что при импорте результатов полного экспорта, первой БД во вторую будут выполнены команды CREATE TABLESPACE, обнаруженные в файле дампа экспорта. Эти команды создадут такие же файлы во второй БД, в результате чего, если не указать параметр DESTROY = N файлы первой БД могут быть переписаны и ее данные будут потеряны! Избежать этого можно заранее создав табличные пространства и разделив их каталоги! Тогда ничего страшного не произойдет! А, сейчас давайте вспомним еще раз наш с вами первый импорт при создании пользователя MILLER:
Здесь хорошо видно, что файл дампа экспорта имеет имя MILLER.DAT. При этом производится импорт данных, от имени пользователя MILLER моей БД, которую я создал для работы с шагами в вашу БД тому же пользователю MILLER. В данном случае работают операторы fromuser и touser. Данную строку можно было переписать и вот так:
Так как данные пользователя БД, идут первыми в командной строке и запись USERID при этом не требуется. А, если импорт проводиться прямо на машине сервера, то можно записать еще проще:
В данном случае имя сетевой службы нет необходимости указывать, так как "ухо" сервера вашей БД и так поймет что от него хотят! Если у вас есть желание, то можете попробовать добавить в эту строку что-то еще из параметров прошлого шага и посмотреть, что будет получаться! Теперь, что касается команды COMMIT для выполнения импорта данных. Допустим в вашем дампе экспорта есть таблица на 300 Мбайт данных, это совсем не значит, что необходимо иметь сегмент отката такой же величины! Для того, чтобы уменьшить размеры элементов сегментов отката при выполнении данного импорта определите COMMIT = Y и задайте значение параметра BUFFER. Теперь команда COMMIT будет выполняться после каждого ввода информации объемом BUFFER. Например:
В данном случае COMMIT будет выполняться после ввода каждой таблицы, а в следующем примере:
При этом не забывайте о связи объектов БД! Я вам о них рассказывал ранее! Например, если вы удалили таблицу, а представление созданное от нее осталось в словаре данных, то последующий импорт так же будет неудачным в следствии того, что представлению некуда ссылаться! Не забывайте об этом! Следует быть внимательным при работе с объектами БД и их экспортом для последующего импорта в другую или в эту же БД! Теперь давайте рассмотрим еще один параметр при импорте данных, а именно INDEXES и INDEXFILE. Эти параметры позволяют "развести" при необходимости таблицы и индексы по разным табличным пространствам. При использовании INDEXFILE файл данных при импорте будет прочитан, но не импортирован. Все сценарии создания таблиц будут записаны в файл на выходе. При этом в сценарий, который будет создан, все конструкции DDL будут закомментированы и в дальнейшем на его основе изменив параметры storage и tablespace вы можете переопределить местоположение таблиц и индексов. Так же следует отметить, что использование INDEXFILE требует либо определить параметр FROMUSER, либо параметр FULL значением Y! Рассмотрим это на примере. Первое проводим экспорт пользователя MILLER вот так:
Получаем файл MILLER.DAT. Затем напишите bat файл вот с такой командой импорта данного пользователя:
На экране должно получиться, что-то вроде:
Затем отредактируйте как вам нужно файл сценария milleridx.sql изменив в нем конструкции STORAGE и TABLESPACE. Вот примерное содержимое этого файла, которое получилось у меня:
Затем запустите сценарий создания таблиц и индексов в SQL*Plus и проведите импорт данных с такими параметрами:
Но если количество индексов для отделения не большое, то можно воспользоваться опцией rebuild команды alter index. Вот собственно кратко о том, как выполняется импорт и экспорт в БД Oracle! Все остальное я надеюсь вы сможете одолеть и сами, если есть желание и время! И конечно же, если что-то не совсем ясно, можете спрашивать! Чем могу помогу!
Привет, сейчас мы с Вами рассмотрим технологию Oracle Data Pump, с помощью которой мы можем экспортировать данные в дамп и импортировать данные из дампа в СУБД Oracle. Эта технология подразумевает использование утилит expdp и impdp, которые заменяют традиционные exp и imp, и сегодня мы с Вами научимся использовать их для создания дампа базы данных и импорта данных из этого дампа.
Как Вы, наверное, уже догадались, сейчас речь пойдет о СУБД Oracle, а именно о технологии Oracle Data Pump и начнем мы, конечно же, с обзора данной технологии.
Что такое Oracle Data Pump?

Oracle Data Pump – это технология позволяющая экспортировать и импортировать данные и метаданные в СУБД Oracle Database в специальный формат файлов дампа.
Данная технология впервые появилась в версии 10g и включается во все последующие версии Oracle Database. Для экспорта и импорта данных до Oracle Data Pump, т.е. до версии 10g, использовались традиционные утилиты exp и imp, возможности которых в 10 и выше версиях сохранены в целях совместимости. Особенностью Oracle Data Pump является то, что экспорт и импорт данных происходит на стороне сервера, dmp-файл формируется на файловой системе сервера, а также главным преимуществом Oracle Data Pump перед традиционным способом экспорта и импорта данных является более быстрая выгрузка и загрузка данных.
В Oracle Data Pump для экспорта и импорта данных созданы новые серверные утилиты expdp и impdp. Формат файлов дампа (dmp) используемый в этих утилитах, несовместим с форматом, который используется в exp и imp.
Expdp – утилита для экспорта данных в СУБД Oracle Database в дамп.
Impdp – утилита для импорта данных в СУБД Oracle Database из дампа.
Утилиты expdp и impdp поддерживают несколько режимов работы:
Для того чтобы посмотреть подробную справку (описание параметров) по этим утилитам запустите их с параметром help=y, например
Примечание! Запуск утилит в операционной системе Windows запускается из командной строки. В случае если системный каталог bin СУБД Oracle не добавлен в переменную среды Path, то запускать утилиты нужно из данного каталога, т.е. предварительно перейдя в него (например, с помощью команды cd). Для демонстрации примеров ниже я использую Oracle Database Express Edition 11g Release 2 установленный на операционной системе Windows 7.
Пример создания дампа базы данных Oracle с помощью expdp
Для того чтобы создавать дампы в Oracle с помощью утилиты expdp предварительно необходимо определится с логической директорией, в которую Вы будете экспортировать дампы, т.е. где они будут храниться. Можно использовать стандартную директорию DATA_PUMP_DIR, но Вы, если хотите, можете создать новую, конкретно для Ваших целей отдельную директорию. Давайте создадим отдельный каталог для наших задач с экспортом и импортом данных, заодно и научимся создавать такие директории.
Сначала создаем каталог в файловой системе, например, я создал D:\OracleEX\ExportImport.
Затем уже создаем директорию в Oracle, для этого открываем SQL*Plus или SQLDeveloper и запускаем следующую команду (я запустил в SQL*Plus и директорию назвал ExportImport).
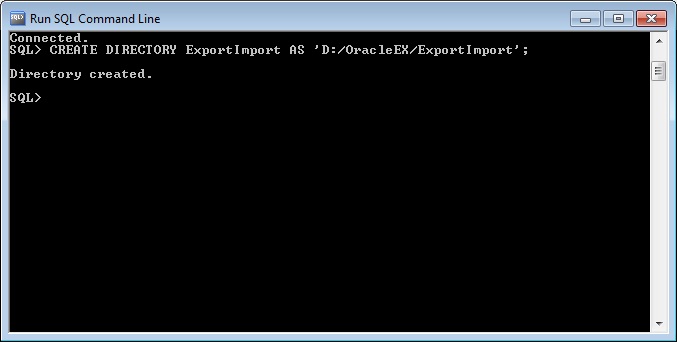
Чтобы посмотреть, какие директории уже созданы, можете использовать следующий запрос.
Теперь давайте перейдем непосредственно к экспорту. Я все действия выполнял от имени системного пользователя Oracle.
Создание дампа всей базы данных
Для того чтобы создать полный дамп базы данных выполните следующую команду в командной строке
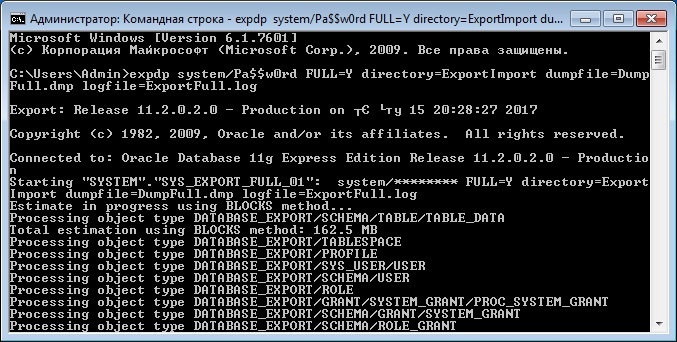
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- FULL=Y – параметр, который указывает, что мы делаем полный экспорт базы данных;
- directory=ExportImport – параметр указывает директорию, в которую мы будем выгружать дамп файл;
- dumpfile=DumpFull.dmp – параметр для указания названия дамп файла;
- logfile=ExportFull.log – параметр для указания названия лог файла экспорта данных.
Создание дампа на основе отдельной схемы базы данных
В большинстве случае все-таки, наверное, понадобится экспортировать отдельную, выбранную схему базы данных, а не всю БД. Для того чтобы выгрузить схему, указываем параметр SCHEMAS.
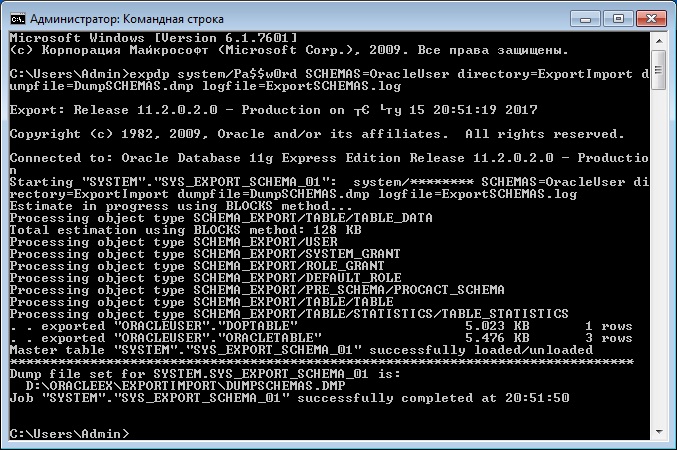
SCHEMAS=OracleUser – параметр, в котором мы указываем схему для экспорта, в нашем случае OracleUser.
Создание дампа на основе отдельных таблиц базы данных
Иногда нужно экспортировать только одну или несколько таблиц, для этого мы можем использовать параметр TABLES. В примере ниже мы экспортируем таблицу OracleTable в схеме OracleUser.
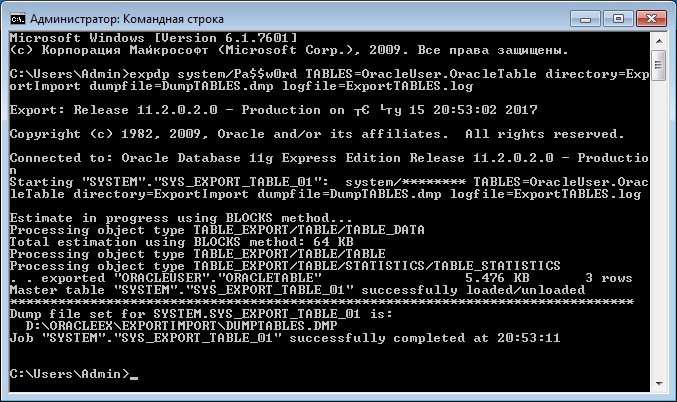
TABLES=OracleUser.OracleTable – это параметр, в котором мы указываем таблицу для экспорта (или несколько таблиц через запятую).
Пример импорта данных из дампа Oracle с помощью impdp
Сейчас давайте перейдем к импорту данных из дампа. Как Вы помните, для этих целей у нас существует утилита impdp.
Импорт схемы из дампа
Для импорта всей схемы запускаем утилиту impdp с параметром SCHEMAS. В случае если у Вас уже создана схема, которую Вы собираетесь импортировать, то ее предварительно нужно удалить. Для удаления схемы используйте следующий запрос в SQL*Plus или SQLDeveloper
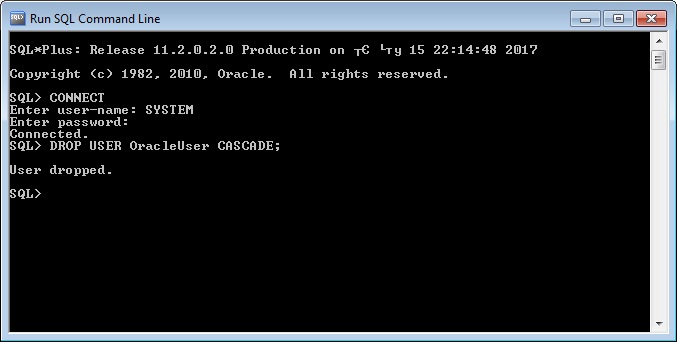
После этого, для того чтобы импортировать схему, запускаем утилиту impdp со следующими параметрами
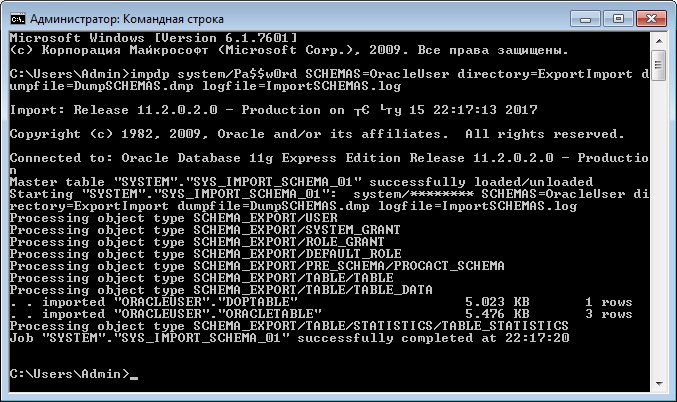
- system/Pa$$w0rd – это логин и пароль пользователя в СУБД;
- SCHEMAS=OracleUser – параметр, который указывает, что мы хотим импортировать конкретную схему (в нашем случае OracleUser);
- directory=ExportImport – параметр указывает директорию, в которой расположен файл дампа данных;
- dumpfile=DumpSCHEMAS.dmp – параметр для указания названия дамп файла;
- logfile=ImportSCHEMAS.log – параметр для указания названия лог файла импорта данных.
Импорт таблиц из дампа
Если Вы хотите импортировать одну или несколько таблиц, то можете использовать параметр TABLES, также как и при экспорте. В случае если таблица или таблицы уже созданы, т.е. существуют, то их необходимо или удалить вручную (DROP TABLE) или указать параметр TABLE_EXISTS_ACTION, который может принимать следующие значения:
Для примера давайте запустим impdp с параметром TABLE_EXISTS_ACTION=REPLACE, для того чтобы перезаписать существующую таблицу.
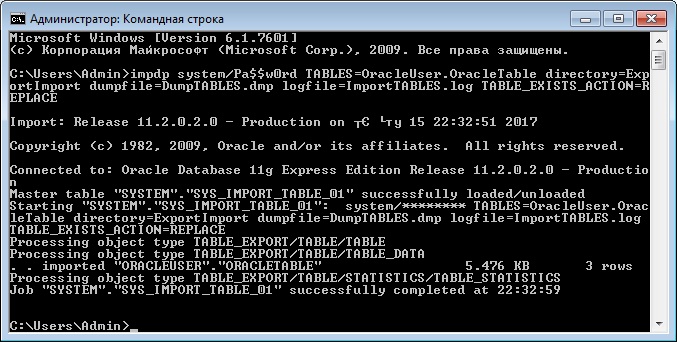
Заметка! Для изучения языка SQL как стандарта, чтобы его можно было использовать в любой СУБД, рекомендую почитать книгу «SQL код», в ней рассматриваются конструкции SQL, которые будут работать везде и не привязаны к какой-то конкретной СУБД.
Читайте также: