
Pl sql расширение файла
Обновлено: 01.07.2024
В конце, я написал один PL/SQL пакет, который находится в database и может быть вызван из любой аппликации. В ходе написания я столкнулся со многими ограничениями и хочу рассказать о том, как их поборол.
Для тех — кто сомневается, я этого, конечно не мог знать заранее, но за несколько лет, что пакет работает в большой компании, у меня не было проблем свести RDF любой сложности, с многими триггерами/формулами, в один селект, хвала Ораклу. Наоборот, так как селект — стринговый параметр и его можно построить динамически, это дает большую гибкость. В параметрах можно задать даже имя таблицы.
Прежде всего не судите строго за обилие англицизмов(так, по-моему, это называется), я просто давно вне русского программного сообщества и не знаю, чем заменяют эти слова.
Очень часто в аппликациях, написанных в Oracle Forms/Reports для создания файла Excel используют Oracle*Reports, потому что там есть возможность использовать параметры и видоизменять селект до его выполнения. Потом в триггер на уровне строки вывода пишут вывод в файл. Получается csv файл. Ну что же, можно и так, конечно.
Если вместе с Excel нужно создать pdf, то никуда не денешься, пользуйся Reports и не жалуйся как тебя достала эта программа. Но ведь часто нужен только Excel и городить для этого RDF как-то не хочется.
Примерно такой набор. Думаю, тут все понятно. Несколько слов:
LIMIT_ROWS, LIMIT_LEN позволяют делить результирующий файл в процессе создания по мере достижения предельных значений на несколько Excel корректных.
LITERAL_PARAMS говорит о том, как использовать параметры выполнения — вставлять значения или выполнять селект в dbms_sql с dbms_sql.bind_variable.
OUT_TYPE задает формат: Excel Workbook,CSV,HTML,XML
Как обеспечить динамичность селекта с параметрами, получаемыми в runtime
Параметры передаем так:
Язык предвыполнения
- Получаем параметры выполнения.
- Компилируем текст селекта.
- Подаем его для выполнения следующему шагу.
Вот язык, который в конце покрывал все мои потребности
В тексте селекта это выглядит как комментарий(hint)
Шаг компиляции заключается в том, что я нахожу в тексте команду, если один из операндов требует выполнения — выполняю это как select (expression) from dual или как PL/SQL блок в execute immediate и заменяю всю команду на результат выполнения.
или
ну и так далее…
Я это описал для того, чтобы вы поверили, что эти приемы позволяют писать действительно эффективные селекты.
Никаких " and (:param1 is null or table_field=:param1)"
Парсинг и выполнение
Ради этого раздела я затеялся писать эту статью. Здесь я напишу об опыте, который приобрел, и который наверняка не нужен тому, кто не ходил на границах допустимого в Оракле. Например, все знают, что максимальная длина текстового поля в таблице — 4000, но многие ли знают, что предел для конкатенации строкового поля в селекте в оракле тоже 4000 байтов.
Получили селект после предкомпиляции с параметрами выполнения. Он у нас в переменной l_Stmt.
К сожалению, в PL/SQL нет легкой возможности организовать цикл по полям селекта, как это можно было бы сделать в Java. Будем пользоваться процедурой dbms_sql.parse, которая возвращает поля селекта как таблицу, по которой сделаем цикл в дальнейшем.
Что мы хотим сделать?
Выполнить парсинг и получить список полей с datatype.
Для этого применяем
Мы получили самое главное — список полей селекта в PL/SQL таблице l_LogColumnTblInit.
Это для нас выполнил великий пакет DBMS_SQL. Теперь мы можем организовать цикл по полям селекта.
Тот, кто пишет на Java(в том числе и я теперешний) посмеется над такой победой, там это всегда было — перебор полей в PreparedStatement.
Сейчас, зная Java, я бы написал бы, может, по другому, но принципиальные вещи не изменились бы.
Кстати, здесь я встретил ограничение на размер селекта 32К, не сразу, в ходе эксплуатации, когда начали писать серьезные селекты. И тут меня снова порадовал Оракл. Оказывается, длинный селект можно разбить на порции 256 байт, зарузить в PL/SQL таблицу l_LongSelectStmt dbms_sql.varchar2s и передать в overload версию dbms_sql.parse.
Теперь пришло время подумать о форматах вывода.
Допустим, наш селект выглядит так:
Для вывода в формате CSV нужно написать
Для вывода в формате HTML нужно написать
Для создания самого красивого, но и самого сложного формата Excel Workbook, мне пришлось поэкспериментировать с Excel. Excel Workbook — это не бинарный, а текстовый файл, его можно посмотреть и понять, как там все устроено.
Там есть CSS, определения Workbook,Worksheet, заголовков таблиц. Не буду углубляться, это не очень сложно понять, если вы встречали раньше HTML.
В Excel Workbook строка вывода будет выглядеть примерно так
Здесь, как вы видите, нам может пригодиться знание типов данных из виртуальной таблицы, полученной в dbms_sql.describe_columns.
Если сравнивать типы вывода, то можно сказать следующее:
CSV — маленький по размеру(это плюс), некрасивый, нет возможности нескольких таблиц(spreadshhets)
HTML — средний по размеру, достаточно сексуальный, нет возможности нескольких таблиц
Excel Workbook — большой файл, красивый, есть возможность создания нескольких таблиц
Алгоритм работы
Цикл по полям
Двигаясь по таблице выходных полей, заворачиваем очередное поле в соответствующие формату тэги или просто добавляем табуляцию(CSV). Теперь вы поняли, как я ударился об эти 4000 байтов. Мне пришлось проверять перед слиянием строк длину результата и, если она была больше 4000, то начинал новое поле вывода, примерно так:
Когда селект построен, выполняем его. Если селект большой, то его надо загрузить в dbms_sql.varchar2s таблицу и выполнить в dbms_sql. Если ваш DBA сказал, что он не потерпит литералы и требует, чтобы параметры были bind variable, то тоже нужно использовать dbms_sql с dbms_sql.bind_variable.
Иначе, если ваш селект поместился в 32К вашей varchar2 переменной l_Stmt можете открыть ref cursor:
Цикл по курсору
Делаем fetch и пишем в utl_file. Следим за количеством строк и за величиной выводимого файла, если нужно, завершаем его(красиво, Excel корректно) и начинаем следующий.
В конце, или, если это Excel Workbook в отдельном sheet, выводим параметры, с которыми выполнен отчет.
Ну вот, наверно и все по большому счету.
Наверное теперь можно показать результат:
Если кому интересно, я могу рассказать, как я завернул этот пакет в другой, который зиповал файл, если он был большой, посылал его по мейлу как ссылку или как attachment, но главное, это определения параметров и типовой экран ввода.
Доброго дня. Третья часть разговора про формат XLSX подоспела. Я не случайно начал со внутреннего устройства файла. Не понимая где что находится и как выглядит, сложно понять, для чего я сделал то-то и то-то. К тому же, теперь я могу сделать несколько замечаний:
Первое. Если я не упомянул какой-то элемент, который нужен именно вам, — создайте пустой файл XLSX, сделайте нужный элемент и сохраните. Теперь вы знаете, где искать код, определяющий этот элемент.
Второе. OpenXML допускает наличие в разметке произвольного текста, если он не нарушает структуру тегов (этим мы будем очень активно пользоваться). Сейчас проиллюстрирую. Вот так делать можно:
А вот так — нельзя:
Но к делу. Строго говоря, есть два возможных случая. Либо мы имеем некий шаблон, который нам необходимо заполнить данными, либо сами вынуждены составлять файл, что называется, с нуля. Первый случай проще, второй — интереснее. Но при этом оба случая требуют от нас наличия файла-заготовки: поскольку файл .XLSX состоит не только из .XML-файлов, создать его «руками», увы, не выйдет.
Вообще методика, которой я пользуюсь, в значительной степени основывается на библиотеке Alexandria PL/SQL. Сама библиотека огромна, и если кроме как для целей, описанных ниже, она вам не нужна, то лучше имплантировать ее выборочно.
Для простой подстановки в бланк квитанции ФИО абонента средств, представленных в этой библиотеке, должно вполне хватить. Мне же, с учетом моей специфики, пришлось делать над ней надстройку. Поэтому если вы начали читать, рекомендую дочитать до конца: как знать, быть может, мое решение покажется вам более удобным или эффективным. Общий же алгоритм действий таков:
- Трансформируем файл-заготовку в BLOB;
- Заменяем условные метки в XML-файлах внутри него на наши данные;
- Сохраняем измененный BLOB как новый файл;
- Возвращаем измененный файл пользователю.
Трансформация файла-заготовки в BLOB
Если у нас есть в наличии некий бланк, к примеру, квитанция, в которую надо вставить ФИО абонента и сумму к оплате, то все проще некуда: берем готовую квитанцию и меняем содержимое переменных полей на специальные метки-маячки. По поводу текста этих маячков есть два основных правила — они не должны имитировать теги и вероятность совпадения в исходном тексте документа или в заменяющем тексте должна быть исчезающе малой. В остальном все зависит от вашей фантазии или привычек. Я использую что-то типа %name%. Объясню почему. Знак "%" не имитирует разметку, и вероятность того, что где-то будет слово, с двух сторон обособленное этим знаком, — мизерна.
А вот в случае, когда мы заранее не знаем, что может быть в файле на выходе, работы будет больше.
Перво-наперво рекомендую поэксплуатировать Excel и обозначить все стили ячеек, которые нам могут понадобиться (если не понадобятся — ничего страшного, это лучше, чем если чего-то не хватит). После этого лезем блокнотом в стили и записываем индексы конкретных стилей. Так, я сделал себе отдельный стиль для заголовка (серая заливка, полужирное написание и тонкие границы) и отдельный стиль для рядовой строки (без заливки, обычное написание и тонкие границы).
Далее работать придется не через Excel, а руками.
Файл sharedStrings.xml должен выглядеть примерно так:
Файл sheet1.xml (предполагая, что основным листом у нас будет первый) должен содержать следующее:
Метка %attach% расположена там, где должен находиться тег закрепления области. Метка %colsize% — там, где находится тег, указывающий ширину занятых столбцов. Это сделано для того, чтобы, допустим, в столбце ФИО ширина была соответствующей. Метка %data% будет заменена сгенерированной разметкой ячеек. Метка %filter% — на случай, если понадобится встраивать автофильтр.
Сохраняем, закрываем — болванка готова. Далее нам надо трансформировать ее в BLOB. Для этого нам понадобится библиотечная функция lib_utils.get_blob_from_file (на всякий случай напомню, что lib_utils — это функции из библиотеки по ссылке в начале поста). Функция принимает два параметра: директорию и имя файла. Поскольку это слегка неочевидно, поясню, что под директорией подразумевается оракловый объект DIRECTORY. В нашем примере назовем директорию FILE_DIR. То есть вызов будет выглядеть примерно так:
Замена меток на кастомные данные
В более простом случае с бланком квитанции (или аналогичном случае), просто используем функцию lib_utils.multi_replace. Библиотека все сделает за вас.
Для сложного случая я построил свою конструкцию. В основе ее лежит составной рукописный тип данных, являющий собой комплексное описание содержимого листа Excel. Поскольку тип составной, пойдем снизу вверх:
Последний тип напрямую не задействован в построении tp_table, но все равно далее будет нужен. Поясню элементы типа tp_cell.
- address — фактический адрес ячейки. Тут надо пояснить кое-что. В комментариях к предыдущему посту выложены результаты экспериментов, показывающие, что при описании ячейки адрес вписывать необязательно. Это так. Однако, на мой взгляд, явное, как правило, лучше неявного.
- style — ссылка на индекс стиля описываемой ячейки. Я для себя решил, что все описанные мной стили будут храниться в виде глобальных констант пакета custom_utils.
- val — содержимое ячейки.
- lines — флажок многострочности. Установка его значения на 2 или выше будет означать, что в содержимом ячейки подразумевается перенос, а как мы помним, для его отображения следует увеличивать высоту ячейки.
Процедура принимает следующие параметры:
- i_content — содержимое будущего файла.
- i_filename — имя будущего файла.
- i_filter — флажок необходимости автофильтра.
- i_attach — флажок необходимости закрепления области. Поскольку в моем случае требуется закрепление только первой строки, у меня генерируемый из-за этого флага код всегда будет одинаковым.
Сразу хочу кое-что пояснить. Поскольку данных в файле может быть много, работать с varchar-ообразными типами нельзя, их просто не хватит. Поэтому приходится затачивать свое решение под CLOB. В целом же, пока что ничего сверхъестественного. Но — к делу.
Во-первых, давайте сначала поговорим о среде (другие версии похожи):
- Операционная система: Windows 10
- База данных Oracle 11g r2
- PL/SQL Developer 12
Во-вторых, файл CSV
Csv, который называется значениями, разделенными запятыми, обычно переводится как значения, разделенные запятыми, а файлы csv хранят данные таблиц в виде простого текста. В системе Windows, если вы устанавливаете Excel, открытие csv по умолчанию, как правило, происходит в Excel, но, как упоминалось ранее, CSV хранит данные в виде простого текста, а затем мы пытаемся открыть его в текстовом редакторе. Вы найдете, о! Оказалось, что соус фиолетовый, посмотрите на картинку. Рисунок 1 открывается Office Excel, а Рисунок 2 - Блокнот.


3. Импорт через PL / SQL Developer
Ну, не бред. Мы будем использовать приведенные выше данные таблицы ученика, чтобы импортировать ее один раз.
1. Подготовка
(1) Сначала измените заголовочную часть файла csv, которая является первой строкой, и измените ее на соответствующее имя поля базы данных.
(2) Создайте таблицу, соответствующую данным таблицы в базе данных, код выглядит следующим образом:
(3) Затем мы открываем импортер текста PL / SQL Developer, я возьму здесь фотографию plsql 12 и поищу другие версии.

(4) После открытия средства импорта текста, мы нажимаем значок открытия в верхнем левом углу, находим файл CSV, который вы хотите импортировать, дважды щелкните, чтобы открыть

(5) После загрузки файла эффект будет следующим: в средней конфигурации, если мы проверим имя заголовка, первая строка будет автоматически использоваться в качестве заголовка таблицы, то есть имени поля. Затем мы нажимаем на вкладку: данные в Oracle, чтобы выбрать таблицу для импорта в базу данных.

(6) На вкладке данных в Oracle выберите пользователя и имя таблицы импортируемой таблицы, как показано на рисунке ниже LHY.TMP_STUDENT
После выбора имени пользователя и указания область поля в середине интерфейса будет автоматически соответствовать полю таблицы, а формат даты также будет автоматически преобразован в соответствующий формат. В то же время вы также можете выбрать соответствующее импортируемое поле.
После подтверждения, если после подтверждения проблем нет, нажмите кнопку импорта в левом нижнем углу, чтобы завершить импорт.
Эмм . Каждое количество представлений на картинке, импорт больших данных может быть соответственно увеличен.

(7) После нажатия кнопки «Импорт» (xxx записи импортируются, это занимает 0,00000001 секунды).
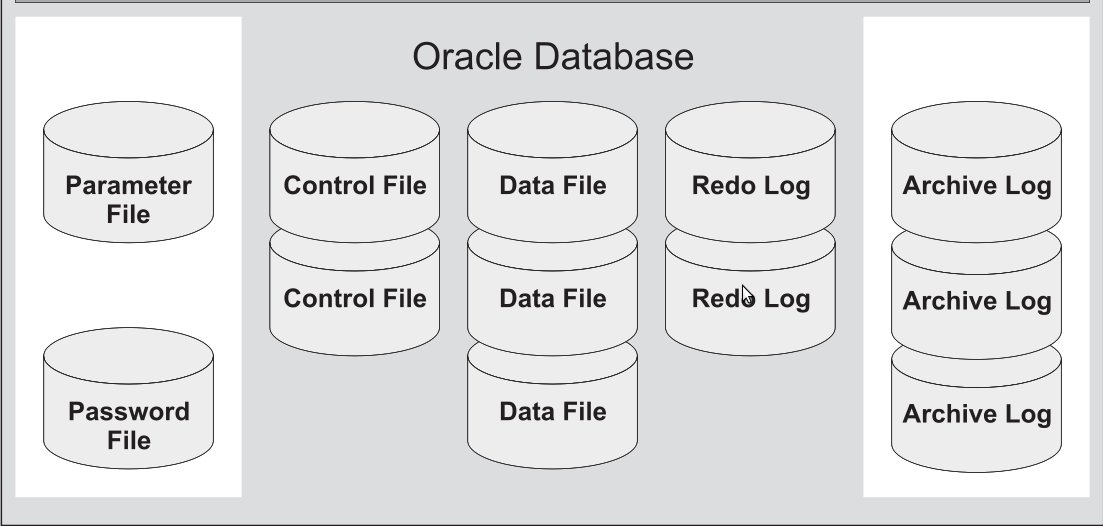
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Читайте также: