Посмотреть текущий scn oracle
Обновлено: 07.07.2024
Возможности Oracle Flashback (база данных FLASHBACK)
Технология флэшбека обычно используется для быстрого и простого восстановления логических ошибок, таких как неправильные операции в базе данных. Методы флэшбека можно разделить на флэшбэк на уровне базы данных, флэшбэк на уровне таблицы и транзакцию.
Уровень обратного воспоминания можно разделить на восстановление воспоминаний и запрос воспоминаний в зависимости от воздействия воспоминаний на данные. Восстановление флэшбека изменит данные, и все данные после точки возврата будут потеряны. Флэшбэк запрос доступен
Чтобы запросить различные версии данных DML, вы также можете определить, следует ли восстанавливать на основе этого
1. Особенности базы данных Flashback
флэшбэк data1base флэш назад к определенному моменту в прошлом
Вся работа после того, как точка воспоминания потеряна
Используйте resetlogs, чтобы создать новую сцену и открыть базу данных (после сброса, вы больше не можете вспомнить время до сброса)
Распространенные сценарии: усеченная таблица, непредвиденные ошибки в нескольких таблицах и т. Д.
Использовать журнал ретроспективных данных, чтобы достичь обратной памяти базы данных, данные после точки обратной памяти будут потеряны
Во-вторых, состав базы воспоминаний
Буфер обратной памяти: если включена база данных обратной памяти, в sga будет открыта новая область в качестве буфера обратной памяти, размер которой выделяется системой
Включите новый процесс rvwr: процесс rvwr записывает содержимое буфера флэшбэка в журнал флэшбека. Обратите внимание, что журнал флэшбека отличается от оперативного журнала повторов. Журнал воспоминаний основан на оперативном журнале повторов.
Сгенерированный выше - журнал полного изображения блока данных. Онлайн журнал - это журнал изменений. Журналы воспоминаний не могут быть повторно использованы или заархивированы. Журналы воспоминаний используют режим циклической записи.
Три, конфигурация базы данных флэшбека
База данных Flashback требует, чтобы база данных находилась в режиме архива, а для открытия базы данных после флэшбэка необходимо использовать resetlogs
А. Проверьте, включены ли режим архивации базы данных и флэшбэк
б. Просмотрите и установите каталог флэшбэка, размер пространства каталога флэшбэка и т. д.
- Смотрите ниже, чтобы посмотреть каталог восстановления и размер места назначения восстановления
- Вы можете использовать alter system set db_recovery_file_dest, чтобы установить новый путь
- Вы можете использовать alter system set db_recovery_file_dest_size, чтобы установить новый размер
c. Установите целевое время сохранения флэшбэка
В-четвертых, использовать базу данных флэшбека, чтобы вернуться в базу данных
Процедура
Закройте базу данных
Запустите базу данных в состояние монтирования (эксклюзивный режим)
Воспоминание на определенный момент времени, номер SCN или номер журнала
Используйте resetlogs, чтобы открыть базу данных
1. Используйте sqlplus, чтобы добиться воспоминания
Может принимать метку времени или аргумент номера системного изменения
Несколько распространенных методов обратной базы данных sqlplus
FLASHBACK [STANDBY] БАЗА ДАННЫХ [<database_name>] ДО [BEFORE] SCN <system_change_number> - на основе флэш-памяти SCN
FLASHBACK [STANDBY] БАЗА ДАННЫХ [<имя_базы_данных>] до [BEFORE] TIMESTMP <system_timestamp_value> - Воспроизведение на основе отметки времени
FLASHBACK [STANDBY] БАЗА ДАННЫХ [<database_name>] ДО [BEFORE] ВОССТАНОВИТЬ ТОЧКУ <restore_point_name> - на основе обратного отсчета времени
В следующем примере:
SQL> flashback database to timestamp('2010-10-24 13:04:30','yyyy-mm-dd hh24:mi:ss');
SQL> flashback database to scn 918987;
SQL> flashback database ro restore point b1_load;
Воспоминание на основе метки времени
б) Воспоминание на основе номера SCN
C. Воспоминание, основанное на времени
2. Используйте RMAN для базы данных flashback
Несколько распространенных методов использования RMAN для возврата к базе данных
RMAN> flashback database to scn=918987;
RMAN> flashback database to sequence=85 thread=1;
Представление запроса: v $ recovery_file_dest покажет использование области воспоминания
Некоторые табличные пространства могут быть исключены из воспоминаний
Если вам нужно включить функцию обратного отсчета для указанного выше табличного пространства, вам нужно включить функцию для табличного пространства в режиме монтирования.
V. Резюме
Стратегия флешбэка является усовершенствованием функции отмены Oracle, которая обеспечивает больше удобства для быстрого восстановления базы данных. Скорость восстановления с обратной памятью базы данных выше, чем у RMAN и пользовательского резервного копирования и восстановления. Основная причина заключается в том, что флэш-память базы данных использует журнал воспоминаний, а журнал воспоминаний хранит полный образ блока данных. Во-вторых, степень восстановления флешбека зависит от размера пространства флешбека и стратегии хранения флешбека, размер пространства флешбека будет использован повторно, а стратегия хранения флешбека определяет продолжительность хранения журнала флешбека. Короче говоря, разумный баланс между скоростью восстановления и доступным пространством зависит от конкретных требований к обслуживанию.
Продолжение статьи про Real Application Cluster (RAC). Окончание.
Считаем, что кластер поднялся и все закрутилось.
Взаимодействие узлов. Cache-fusion.
Много экземпляров БД, много дисков. Хлынули пользовательские запросы… вот они, клиенты, которых мы так ждали. =)
Самым узким местом любой БД являются дисковый ввод-вывод. Поэтому все базы данных стараются как можно реже обращаться к дискам, используя отложенную запись. В RAC все так же, как и для single-instance БД: у каждого узла в RAM располагается область SGA (System Global Area), внутри нее находится буферный кэш (database buffer cache). Все блоки, некогда прочитанные с диска, попадают в этот буфер, и хранятся там как можно дольше. Но кэш не бесконечен, поэтому, чтобы оценить важность хранимого блока, используется TCA (Touch Count Algorithm), считающий количество обращений к блокам. При первом попадании в кэш, блок размещается в его cold-end. Чем чаще к блоку обращаются, тем ближе он к hot-end. Если же блок «залежался», он постепенно утрачивает свои позиции в кэше и рискует быть замещенным другой записью. Перезапись блоков начинается с наименее используемых. Кэш узла – крайне важен для производительности узлов, поэтому для поддержания высокой производительности в кластере кэшем нужно делиться (как завещал сами-знаете-кто). Блоки, хранимые в кэше узла кластера, могут иметь роль локальных, т.е. для его собственного пользования, но некоторые уже будут иметь пометку глобальные, которыми он, поскрипев зубами дисками, будет делится с другими узлами кластера.
Технология общего кэша в кластере называется Cache-fusion (синтез кэша). CRS на каждом узле порождает синхронные процессы LMSn, общее их название как сервиса — GCS (Global Cache Service). Эти процессы копируют прочитанные на этом экземпляре блоки (глобальные) из буферного кэша к экземпляру, который за ними обратился по сети, и также отвечают за откат неподтвержденных транзакций. На одном экземпляре их может быть до 36 штук (GCS_SERVER_PROCESSES). Обычно рекомендуется по одному LMSn на два ядра, иначе они слишком сильно расходуют ресурсы. За их координацию отвечает сервис GES (Global Enqueue Service), представленный на каждом узле процессами LMON и LMD. LMON отслеживает глобальные ресурсы всего кластера, обращается за блоками к соседним узлам, управляет восстановлением GCS. Когда узел добавляется или покидает кластер, он инициирует реконфигурацию блокировок и ресурсов. LMD управляет ресурсами узла, контролирует доступ к общим блоками и очередям, отвечает за блокировки запросов к GCS и управляет обслуживанием очереди запросов LMSn. В обязанности LMD также входит устранение глобальных взаимоблокировок в рамках нескольких узлов кластера.

Таблица GRD распределена между узлами кластера. Каждый узел принимает участие в распределении ресурсов кластера, обновляя свою часть GRD. Часть таблицы GRD относится к ресурсам – объектам: таблицы, индексы и.т.п. Она постоянно синхронизируется (обновляется) между узлами.
Когда узел прочел блок данных с диска, он становится master-ом этого ресурса и делает соответствующую отметку в своей части таблицы GRD. Блок помечается как локальный, т.к. узел пока использует его в одиночку. Если же этот блок потребовался другому узлу, то процесс GCS пометит этот блок в таблице как глобальный («опубликован» для кластера) и передаст затребовавшему узлу.
| DBA | location | mode | role | SCN | PI/XI |
| 500 | узел №3 | shared | local | 9996 | 0 |
- Data Block Address (DBA): физический адрес блока
- Location: узел на котором доступен этот блок
- Resource mode: определяется тем, кто на текущий момент является владельцем блока и какая операция к нему будет применяться
- null: узел не претендует на изменение этого блока (только select)
- shared: к блоку осуществляется защищенный множественный доступ только для чтения на нескольких узлах.
- exclusive: узел собирается изменить (или уже изменил) этот блок. Хотя одновременно в кластере могут содержаться прежние (согласованные) версии этого же блока, менять их нельзя.
- local: когда узел только прочитал блок с диска, и ни с кем им еще не делился.
- global: когда узел был изначально считан этим блоком, но после был передан запросившему его узлу в некотором режиме (mode). Теперь этот же блок может присутствовать на других узлах.
- Past Image (PI): глобальный грязный блок (старая версия, после изменения), хранящийся в кэше узла после того, как узел передал его по сети другому. Блок держится в памяти пока он или более поздняя версия не будет записана на диск, о чем оповестит GCS, когда блок будет больше не нужен.
- Current Image (XI): текущая последняя копия блока, содержащаяся в последнем узле кластера в цепочке запросов этого блока.
- как можно реже обращаться к диску, за счет активной работы с кэшем
- обеспечить consistency read (CR), согласованность по чтению, т.е. данные неподтвержденной транзакции никто никогда не увидит ни в какой (параллельной) сессии
- Read/read behavior (no transfer).
Пусть данные таблицы A первым считал узел №4. Он является master этой таблицы и отвечает за соответствующую часть в GRD. - На узел №3 пришел запрос на чтение из таблицы A. У узла №3 в кэше нет необходимого блока. Из GRD он узнает, что master таблицы A – это узел №4, и обращается к нему.
- Узел №4 просматривает GRD на наличие запрашиваемого блока. Если бы он был у него в кэше, то он просто бы передал его. Но допустим, что нужного блока не оказалось. Узел №4 отправит узлы №3 самостоятельно считать этот блок с диска.
- Узел №3 сам считывает его с диска, пока только для себя и ни с кем блоком не делится (local), но впоследствии может предоставлять к нему доступ другим узлам через посредника — master-а этой таблицы (shared).
- Узел №3 отчитывается перед master таблицы A узлом №4, и тот вносит соответствующую запись в GRD (на узле №4):
Без необходимости никаких записей на диск не происходит. Всегда копия блока хранится на узле, на котором он чаще используется. Если определенного блока пока еще нет в глобальном кэше, то при запросе master попросит соответствующий узел прочитать блок с диска и поделиться им с остальными узлами (по мере надобности).
- Участвует 2 узла: когда целевому узлу потребовался блок, который хранился в кэше master.
- Участвует 3 узла: когда master отправляет запрос промежуточному узлу, и тот передает блок востребованному в нем узлу.
Taking fire, need assistance! Workload distribution.
Описанное устройство Cache-fusion, предоставляет кластеру возможность самому (автоматически) реагировать на загрузку узлов. Вот как происходит workload distribution или resource remastering (перераспределение вычислительных ресурсов):
Если, скажем, через узел №1 1500 пользователей обращается к ресурсу A, и примерно в это же время 100 пользователей обращается к тому же ресурсу A через узел №2, то очевидно, что первый узел имеет большее количество запросов, и чаще будет читать с диска. Таким образом узел №1 будет определен как master для запросов к ресурсу A, и GRD будет создано и координироваться начиная с узла №1. Если узлу №2 потребуются те же самые ресурсы, то для получения доступа к ним он должен будет согласовать свои действия с GCS и GRD узла №1, для получения ресурсов через interconnect.
Если же распределение ресурсов поменяется в пользу узла №2, то процессы №2 и №1 скоординируются свои действия через interconnect, и master-ом ресурса A станет узел №2, т.к. теперь он будет чаще обращаться к диску.
Это называется родственность (affinity) ресурсов, т.е. ресурсы будут выделяться тому узлу, на котором происходит больше действий по получению и их блокированию. Политика родственности ресурсов скоординирует деятельность узлов, чтобы ресурсы более доступны были там, где это более необходимо. Вот, кратко, и весь workload distribution.Перераспределение (remastering) также происходит, когда какой-то узел добавляется или покидает кластер. Oracle перераспределяет ресурсы по алгоритму называемому «ленивое перераспределение» (lazy remastering), т.к. Oracle почти не принимает активных действий по перераспределению ресурсов. Если какой-то узел упал, то все, что предпримет Oracle – это перекинет ресурсы, принадлежавшие обвалившемуся узлу, на какой-то один из оставшихся (менее загруженный). После стабилизации нагрузки GCS и GES заново (автоматически) перераспределят ресурсы (workload distribution) по тем позициям, где они более востребованы. Аналогичное действие происходит при добавлении узла: примерно равное количество ресурсов отделяется от действующих узлов и назначается вновь прибывшему. Потом опять произойдет workload distribution.
Как правило, для инициализации динамического перераспределения, загруженность на определенном узле должна превышать загруженность остальных в течение более 10 минут.Вот пуля пролетела, и… ага? Recovery.
- Часть GRD таблицы с ресурсами упавшего узла «замораживается».
- Не вышедший на связь узел помечается как «пропавший», чтобы оставшиеся узлы к нему не обращались зря по interconnect.
- Узел, который первым обнаружил пропажу, начинает восстановление информации, которая обрабатывалась на исчезнувшем узле:
- Понижает темпы обслуживания собственных транзакций, бросая вычислительные ресурсы на восстановление
- Обращается к общему файловому хранилищу (datastorage), и на себе начинает применять online redo logs, принадлежавшие пропавшему узлу. С учетом порядкового номера SCN блоков, merge их с тем, что хранится в буфере, и «накатывает» (roll-forward) в своем кэше. При этом узел пропускает те устаревшие записи блоков (PI), более поздние версии которых, уже были сброшены на диск. Если у считанных блоков в кластере присутствует master соответствующего ресурса, то узел сообщает список считанных блоков, и master на этих ресурсах выставляет блокировку, чтобы узлы к ним не обращались (пока они восстанавливаются).
- После чего, вторым прочтением по redo log, учитывая уже undo записи, откатывает (roll-back) незафиксированные транзакции. Происходит это по технологии fast-recovery, т.е. откат транзакций будет производиться отдельным background процессом. Oracle вернет заблокированные незавершенными транзакциями (uncommitted) блоки в согласованное состояние (consistent), к прежним значениям, как только придет запрос на эти блоки. Либо они уже к тому времени будут восстановлены этим самым параллельным background процессом. Таким образом, уже в кластере снимаются блокировки и могут выполняться новые запросы пользователей.
- Часть таблицы GRD, принадлежавшая упавшему узлу, размораживается на восстанавливающем узле (теперь он master ресурса). Таким образом, в кластере восстанавливается состояние обрабатываемых транзакций на пропавшем узле на момент «падения».
Но пока все эти процессы происходят, нетерпеливому клиенту есть что предложить.
Пока узлы спасают друг друга… Failover.
Virtual IP (VIP) – логический сетевой адрес, назначаемый узлу на внешнем сетевом интерфейсе. Он предоставляет возможность CRS спокойно запускать, останавливать и переносить работу с этим VIP на другой узел. Listener (процесс, принимающий соединения) на каждом узле будет прослушивать свой VIP. Как только какой-то узел становится недоступным, его VIP подхватывает на себя другой узел в кластере, таким образом, временно обслуживая свои и запросы упавшего узла.
- Database VIPs: Клиент подсоединится по VIP, но уже подключится к другому узлу. Временно замещающий узел ответит “logon failed”, несмотря на то, что VIP будет active, нужный экземпляр БД за ним будет отсутствовать. И клиент тут же повторит попытку, но уже к другому экземпляру/узлу кластера из своего списка в конфигурации.
- Application VIP: то же, что и прежде. Но только теперь по этому VIP можно будет обратиться к приложению, на каком бы узле оно ни крутилось.
Если узел восстановится и выйдет в online, CRS опознает это и попросит сбросить в offline на подменяющем его узле и вернет VIP адрес обратно владельцу. VIP относится к CRS, и может не перебросится если выйдет из строя именно экземпляр БД.
Важно отметить, что при failover переносятся только запросы select, вместе и открытыми курсорами (возвращающими результат). Транзакции не переносятся (PL/SQL, temp tables, insert, update, delete), их всегда нужно будет запускать заново.
- Connect-time failover and client load-balancing
В этом случае клиент всегда случайно выбирает к какому узлу кластера подключиться из своего списка конфигурации сетевого подключения. Если узел, выполняющий запрос, выходит из строя, то по TAF клиент выбирает другой узел кластера и переподключается. - Preconnect
В этом случае, клиент всегда при установлении соединения с кластером подключается ко всем узлам, хотя запрос будет запускать только на одном экземпляре. Если же узел выходит из строя, то просто переводит запрос на другой узел. Failover происходит быстрее, но расходует ресурсы на подключение на всех узлах кластера.
Туда не ходи, сюда ходи… Load-balancing.
При выполнении любых операций, информацию, относящуюся к производительности запросов (наподобие «отладочной»), Oracle собирает в AWR (Automatic Workload Repository). Она хранится в tablespace SYSAUX. Сбор статистики запускается каждые 60 минут (default): I/O waits, wait events, CPU used per session, I/O rates on datafiles (к какому файлу чаще всего происходит обращение).
Необходимость в Load-balancing (распределении нагрузки) по узлам в кластере определяется по набору критериев: по числу физических подключений к узлу, по загрузке процессора (CPU), по трафику. Жаль что нельзя load-balance по среднему времени выполнения запроса на узлах, но, как правило, это некоторым образом связано с задействованными ресурсами на узлах, а следовательно оставшимися свободными ресурсам.
О Client load-balancing было немного сказано выше. Он просто позволяет клиенту подключаться к случайно выбранному узлу кластера из списка в конфигурации. Для осуществления же Server-side load-balancing отдельный процесс PMON (process monitor) собирает информацию о загрузке узлов кластера. Частота обновления этой информации зависит от загруженности кластера и может колебаться в пределе от приблизительно 1 минуты до 10 минут. На основании этой информации Listener на узле, к которому подключился клиент, будет перенаправлять его на наименее загруженный узел.
- Based on elapsed-time (CLB_GOAL_SHORT): по среднему времени выполнения запроса на узле
- Based on number of sessions (CLB_GOAL_LONG): по количеству подключений к узлу
До сих пор вы знакомились с компонентами системы базы данных Oracle: необходимыми файлами и распределением памяти, а также способами их настройки. Теперь пришло время посмотреть, как Oracle обрабатывает пользовательские запросы и как проводит изменение в данных. Важно понимать механизм обработки транзакций SQL, потому что все взаимодействие с базой данных Oracle происходит либо в форме запросов SQL, которые читают данные, либо операций SQL (или PL/SQL), которые модифицируют, вставляют или удаляют данные.
Транзакция – это логическая единица работы в базе данных Oracle, состоящая из одного или более операторов SQL. Транзакция начинается с первого исполняемого опертартора SQL и завершается, когда вы фиксируетет или отказываете транзакцию. Фиксация (commiting) транзакции закрепляет проведенные вами изменения, а откат (roll back) – конечно же, отменяет их. Как только вы зафиксировали транзакцию, все прочие транзакции других пользователей, которые начались после нее, смогут видеть изменения, проведенные вашими транзакциями.
Когда транзакция вообще не может выполниться (скажем, из-за отключения электропитания), то она вся целиком должна быть отменена. Oracle откатывает все изменения, проведенные предшествующими операторами SQL, возвращая данные в исходное состояние (которое они имели перед началом транзакции). Весь процесс построен так, чтобы поддерживать целостность данных – т.е. концепцию «все или ничего».
Следующий простой пример вставки строки описывает то, как Oracle обрабатывает транзакцию.
Фиксация и откат
Вы должны четно понимать два фундаментальных термина, касающихся транзакций: фиксаций (commiting) и откат (rolling back) транзакций. Ниже кратко объясняются оба термина.
Фиксация транзакцииКогда вы фиксируете транзакцию, скажем, посредством оператора COMMIT, Oracle делает все имзееения, выполненные всеми операторами SQL, в рамках этой транзакции, постоянной частью базы данных. Прежде, чем Oracle зафиксирует результаты транзакции, он делает следующее.
- Генерирует информацию отмены (undo), которая состоит из значений данных, подлежащих модификации, до изменений. Эти данные сохранятся в сегменте undo, расположенном в табличном пространстве undo.
- Он также генерирует данные повторного выполнения (redo), содержащие изменения в блоках данных и в блоках отката, в буфер журнала повторного выполнения. База данных может писать на диск содержимое буферов журнала повторного выполнения перед фиксацией транзакций.
- Проводит изменения в буферах базы данных, находящихся в SGA. База данных может писать модифицированные буферы на диск перед фиксацией транзакции.
База данных может писать изменения транзакции, которые были выполнены первыми, из буферов базы данных в SGA в файлы данных немедленно или же спустя какое-то время после фиксации транзакции, либо даже перед ее фиксацией. Когда баз данных фиксирует транзакцию, она выполняет следующее.
- База данных назначает и записывает SCN для фиксируемой транзакции.
- Писатель журналов пишет элементы журнала повторного выполнения в файл журнала повторного выполнеяия на диске из буфера журнала повторного выполнения в SGA: он также записывает SCN транзакции в файл журнала повторного выполнения, помечая тем официальную фиксацию транзакции.
- База данных освобождает все блокировки таблиц и строк.
- База данных помечает транзакцию как завершенную.
Откат транзакцииОтменить изменения, выполненные транзакцией, которые еще не были зафиксированы можно с помощью команды ROLLBACK. В то время как журнал повторного выполнения содержит все изменения, проведенные в транзакции, сегмент отмены (undo) содержит все старые значения, которые существовали до момента проведения изменений. Вы можете либо откатить изменения, проведенные всей транзакцией, либо просто вернуться к маркеру, который поместили ранее внутри транзакции, называемому точкой сохранения (savepoint). Существует несколько типов отката, среди которых перечислены ниже:
- Откат , запрошенный пользователем.
- Откат, произошедший из-за ненормального прерывания работы процесса или экземпляра.
- Откат незафиксированных транзакций во время восстановления.
- Откат уровня оператора, произошедший из-за ошибки выполнения этого оператора.
Независимо от причины отката, процедура всегда одна и та же.
- База данных использует данные в виде, который они имели до изменения в табличном пространстве undo, чтобы отменить все изменения, проведенные во время транзакции.
- База данных освобождает все блокировки транзакции и таблицы.
- База данных завершает транзакцию
Целостность данных и параллелизм данных
База данных была бы не слишком полезной, если бы множество пользователей не могли обращаться к данным и модифицировать их одновременно. Под параллелизмом данных (a concurrency) понимают способность базы данных обеспечивать параллельный доступ для множества пользователей. Чтобы обеспечить согласованные результаты, база данных нуждается в механизме, который гарантирует, что пользователи не будут натыкаться на изменения, проводимые друг другом. Целостность данных (data consistence) - это возможность для пользователя получать согласованное представление данных, включая все изменения, проведенные в них другими пользователями.
Для обеспечения целостности данных, Oracle использует специальные структуры, именуемые сегментами отмены (undo segments). Например, когда вы читаете набор данных для транзакции, Oracle обеспечивает, чтобы прочитанные данные были согласованы по набору транзакций т.е. гарантирует, что данные, которые вы видите, отражают один набор зафиксированных транзакций. Oracle также обеспечивает согласованность данных по чтению, что означает, что все данные, выбранные вашими запросами, относятся к одному моменту времени. Сегменты отмены Oracle – это часть табличного пространства undo, упомянутого ранее в этой главе.
Oracle использует механизм блокировок для обеспечения параллелизма данных. Позволяя одному пользователю блокировать индивидуальные строки или целые таблицы, он гарантирует ему исключительное использование таблицы в целях обновления. Важной характеристикой механизмов блокировки Oracle является то, что они по большей части происходят автоматически. Вам не нужно беспокоиться о деталях блокировки объектов, которые вы хотите модифицировать – Oracle «за кулисами» позаботится об этом.
Oracle использует две базовые модели блокировок. Модель исключительной блокировки применяется для обновлений, а модель разделяемой блокировки используется для операции SELECT на таблицах. Модель разделяемой блокировки позволяет нескольким пользователям одновременно читать один и те же строки таблицы. Модель исключительной блокировки, поскольку включает обновление таблицы, может использоваться только одним пользователем в любой заданный момент времени. Исключительные блокировки почти всегда применяются к определенным строкам, подлежащим обновлению, позволяя одновременно использовать базы данных множеству пользователей. После выполнения команды COMMIT или ROLLBACK Oracle автоматически освобождает блокировки на таблицах и прочие важные ресурсы.
Блокировки Oracle сложны, и вы детально познакомитесь с ними в главе 8, вместе с тем, как Oracle обеспечивает согласованность и параллелизм данных.
Писатель базы данных и протокол опережающей записи
Писатель базы данных, как вы видели ранее, отвечает за запись в файлы данных всех модифицированных буферов из буферного кэша базы данных. Кроме того, он следует за наличием свободного пространства в буферном кэше, чтобы серверный процесс мог читать новые данные из файлов данных при необходимости. Протокол опережающей записи (журнала) также требует, чтобы записи повторного выполнения в буфере журнала повторного выполнения, ассоциированные с измененной информацией в буферном кэше, были записаны в буфер журнала повторного выполнения перед тем, как они отразятся в файлах данных. Важность содержимого журнала повторного выполнения диктует Oracle обязательность записи содержимого файла журнала повторного выполнения в постоянное хранилище перед тем, как изменения данных будут проведены в фалах данных на диске.
Когда пользователь фиксирует транзакцию, процесс-писатель журнала немедленно вносит в файлы журналов повторного выполнения запись о фиксации. Полный набор записей, затронутых зафиксированной транзакцией, может и не записываться одновременно в в файлы данных. Механизм быстрой фиксации, наряду с журналом опережающей записи, гарантирует, что базада нных не будет ждать завершения всех физических операций записи после каждой транзакции. Как вы можете себе представить, огромные базы данных OLTP с многочисленными изменениями на протяжении всего дня не могли бы функционировать оптимально, если бы им пришлось выполнять запись на диск после каждого зафиксированного изменения данных.
При наличии огромного числа транзакций и, как следствие, огромного количества запросов на фиксацию, процесс-писатель журнала может и не вносить немедленно запись о каждой зафиксированной транзакции в журнал повторного выполнения. Он может накапливать по нескольку запросов на фиксацию, если очень занят в данный момент. Такая пакетированная запись информации о множестве зафиксированных транзакций называется групповой фиксацией.
Системный номер изменения
Системный номер изменения, или SCN (system change number) – важный оценочный фактор, используемый базой данных Oracle для отслеживания состояния в каждый данный момент времени. Когда вы читаете (SELECT) данные в таблицах, то не затрагиваете состояния базы данных, но когда модифицируете, вставляете или удаляете строку, то состояние базы данных по отношению к тому, каким оно было до операции. Oracle использует SCN для слежения за всеми изменениями, проведенными в базе данных со временем. SCN – это логическая временная метка, используемая Oracle для упорядочивания событий, происходящих с базой данных. SCN очень важен по нескольким причинам, не последняя из которых – восстановление базы данных после сбоя.
SCN подобны возрастающим номерам последовательности, и Oracle сначала увеличивает их в SGA. Когда транзакция модифицирует или вставляет данные, Oracle сначала пишет новый SCN в сегмент отката. Процесс-писатель журналов затем немедленно вносит запись о фиксации транзакции в журнал повторного выполнения, и эта запись получает уникальный SCN в сегмент отката. Процесс-писатель журналов, затем немедленно вносит запись о фиксации транзакции в журнал повторного выполнения, и эта запись получает уникальный SCN новой транзакции. Фактически запись этого SCN в журнал повторного выполнения отмечает зафиксированную транзакцию в базе данных Oracle.
SCN помогает Oracle определять необходимость восстановления после сбоя, после внезапного прерывания работы экземпляра базы данных или после издания команды SHUTDONW ABORT. Всякий раз, когда база данных выполняет операцию контрольной точки, Oracle пишет команду START SCN в заголовки файлов данных. Управляющий файл поддерживает значение SCN для каждого файла данных, называемый STOP SCN, который обычно устанавливается в бесконечность, и всякий раз, когда экземпляр останавливается нормально (командой SHUTDOWN NORMAL или SHUTDOWN IMMEDIATE). Oracle копирует номер START SCN в заголовках файлов данных в номера STOP SCN ля файлов данных в управляющем файле. Когда вы перезапускаете базу данных после успешного останова, нет необходимости ни в каком восстановлении, потому что номера SCN в файлах данных и управляющих файлах соответствуют. С другой стороны, внезапное прерывание работы экземпляра не оставляет времени на приведение в соответствие номеров SCN, и Oracle обнаруживает необходимость восстановления экземпляра, потому что отличаются номера SCN в файлах данных с одной стороны, и управляющем файле - с другой. Они играют ключевую роль в восстановлении базы данных. Oracle определяет, на сколько нужно вернуться, применяя архивные журналы повторного выполнения во время восстановления на основе SCN.
Управление отменой
Когда вы проводите изменения в базе данных, вы должны иметь возможность отменить или откатить это изменение при необходимости. Информация, необходимая для отмены или отката изменений транзакции, которая в основном состоит из информации таблицы, предшествующей изменению, называется данными отмены (векторами изменений) и хранится в записях отмены (undo records). При выдаче команды ROLLBACK Oracle использует эти записи отмены для замены измененных данных их исходными версиями. Записи отмены жизненно важны для восстановления базы данных, когда незавершенные или незафиксированные транзакции должны быть отменены, чтобы оставить базу в согласованном состоянии.
Oracle настоятельно рекомендует использовать средство автоматического управления изменениями (Automatic Undo Management - AUM), при котором сам сервер oracle будет поддерживать и управлять сегментами отмены (отката). Все, что вам нужно сделать – это предоставить выделенное табличное пространство undo и установить параметр инициализации UNDO_MANAGEMENT в auto. Oracle создаст необходимое количество сегментов отмены, которые структурно подобны традиционным сегментам отката, и будет расширять их по мере необходимости. Нет ничего необычного в том, что будут создаваться новые сегменты отмен, а старые – деативизироваться в зависимости от количества транзакций, проводимых в базе данных.
Поскольку Oracle самостоятельно управляет размерами индивидуальных сегментов отмены, два решения, которые вы должны принять, касаются размера табличного пространства undo и установки инициализационного параметра UNDO_RETINTION (который определяет, насколько долго Oracle будет стараться хранить для вас записи об отмене в табличном пространстве undo). Помните, что ваше табличное пространство undo должно не только вместить все долговременные транзакции, но так же быть достаточно большим, чтобы позволить работать всем средства ретроспективы (flashback), которые вы можете реализовать в вашей базе данных; средства ретроспективы Oracle позволяют отменять изменение данных на различных уровнях. Некоторые из них, такие как Flashback Query, Flashback Versions Query и Flashback Table используют данные отмены.
Вы можете использовать Undo Advisor Oracle через OEM для нахождения идеального размера табличных пространств undo и идеальной длительности, чтобы специфицировать параметр UNDO_RETENTION. Посредством статистики текущего использования пространства отмены можно оценить оптимальные параметры генерации данных отмены для вашего экземпляра.
![oracle]()
Всем привет, в данном посте речь пойдет о том Как использовать FLASHBACK TABLE для восстановления данных в Oracle. Ситуация такая, что с таблицей что-то сделали не то и выполнили COMMIT? Поговорим, что вообще из себя представляет таблица воспроизведения, я сам пока учусь данной технологии, так что шпаргалка больше для себя.
В случае с Oracle нет ничего проще - достаточно просто откатить таблицу к нужному моменту времени с помощью команды FLASHBACK TABLE.
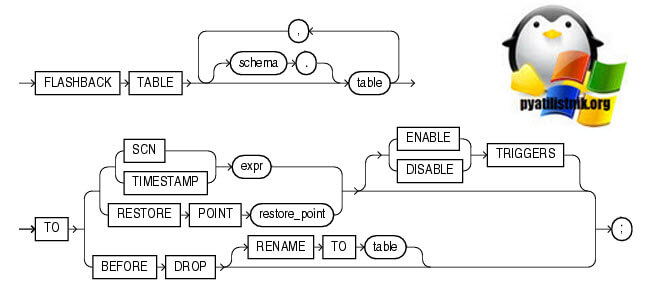
Что такое FLASHBACK TABLE?
Используя инструкцию FLASHBACK TABLE для восстановления более раннего состояния таблицы в случае ошибки человека или приложения. Время отката до которого таблица может быть восстановлена, зависит от количества данных отмены в системе. Кроме того, Oracle Database не может восстановить таблицу до более раннего состояния с помощью любых операций DDL, которые изменяют структуру таблицы.
Oracle настоятельно рекомендует запускать базу данных в автоматическом режиме отмены, оставив для " UNDO_MANAGEMENT" параметра инициализации значение по умолчанию " AUTO ". Кроме того, установите параметр инициализации " UNDO_RETENTION " на достаточно большой интервал, чтобы включить самые старые данные, которые, по вашему мнению, могут потребоваться. Дополнительные сведения в документации по параметрам инициализации UNDO_MANAGEMENT и UNDO_RETENTION . Рекомендуется записать текущий SCN перед выдачей FLASHBACK TABLE пункта.![flashback_table]()
Во время операции Oracle Flashback Table Oracle Database устанавливает эксклюзивные блокировки DML для всех таблиц, указанных в списке Flashback. Эти блокировки предотвращают любые операции с таблицами, пока они возвращаются в свое предыдущее состояние.
Операция Flashback Table выполняется за одну транзакцию, независимо от количества таблиц, указанных в списке Flashback. Либо все таблицы вернутся к предыдущему состоянию, либо ни одна из них не вернется. Если операция Flashback Table завершается неудачно для какой-либо таблицы, то весь оператор терпит неудачу.
По завершении операции Flashback Table данные table соответствуют предыдущим из table. Однако FLASHBACK TABLE TO SCN или TIMESTAMP не сохраняет идентификаторы строк и FLASHBACK TABLE TO BEFORE DROP не восстанавливает ссылочные ограничения.
Oracle Database не возвращает статистику, связанную с table в ее более ранней версии. Индексы table, существующие в настоящее время, восстанавливаются и отражают состояние таблицы в точке Flashback. Если индекс существует сейчас, но еще не существовал в точке Flashback, то база данных обновляет индекс, чтобы отразить состояние таблицы в точке Flashback. Однако индексы, которые были отброшены в течение интервала между точкой Flashback и текущим временем, не восстанавливаются.
- Укажите схему, содержащую таблицу. Если вы не укажете schema , то база данных предполагает, что таблица находится в вашей собственной схеме.
- Укажите имя одной или нескольких таблиц, содержащих данные, которые вы хотите вернуть к более ранней версии.
- Укажите номер изменения системы (SCN), соответствующий моменту времени, в который вы хотите вернуть таблицу. expr Должен вычисляться число, представляющее действительное SCN.
- Укажите значение отметки времени, соответствующее моменту времени, в который вы хотите вернуть таблицу. expr Должны вычисляться действительной метку времени в прошлом. Таблица будет возвращена на время в пределах примерно 3 секунд от указанной временной метки.
Ограничения
- Операции Flashback Table недействительны для следующих типов объектов: таблицы, которые являются частью кластера, материализованные представления, таблицы Advanced Queuing (AQ), таблицы словаря статических данных, системные таблицы, удаленные таблицы, таблицы объектов, вложенные таблицы или отдельные разделы или подразделения.
- Следующие операции DDL изменяют структуру таблицы, так что вы не можете впоследствии использовать предложение TO SCN или TO TIMESTAMP для возврата таблицы к моменту, предшествующему операции: обновление, перемещение или усечение таблицы; добавление ограничения в таблицу, добавление таблицы в кластер; изменение или удаление столбца; изменение ключа шифрования столбца; добавление, удаление, объединение, разделение, объединение или усечение раздела или подраздела (за исключением добавления раздела диапазона).
Рассмотрим откат на примере таблицы TEST_1
- Проверяем есть ли право ROW MOVEMENT на нашу таблицу:
- Если запрос выдает DISABLE - даем право командой:
Если этого не сделать, то при выполнении команды FLASHBACK TABLE будем выходить на ошибку:
ORA-08189: cannot flashback row movement is not enabledЧитайте также: