
При записи в файл слетает кодировка python
Обновлено: 05.07.2024
Эта статья посвящена работе с файлами (вводу/выводу) в Python: открытие, чтение, запись, закрытие и другие операции.
Файлы Python
Файл — это всего лишь набор данных, сохраненный в виде последовательности битов на компьютере. Информация хранится в куче данных (структура данных) и имеет название «имя файла» (filename).
В Python существует два типа файлов:
Текстовые файлы
Это файлы с человекочитаемым содержимым. В них хранятся последовательности символов, которые понимает человек. Блокнот и другие стандартные редакторы умеют читать и редактировать этот тип файлов.
Текст может храниться в двух форматах: ( .txt ) — простой текст и ( .rtf ) — «формат обогащенного текста».
Бинарные файлы
В бинарных файлах данные отображаются в закодированной форме (с использованием только нулей (0) и единиц (1) вместо простых символов). В большинстве случаев это просто последовательности битов.
Они хранятся в формате .bin .
Любую операцию с файлом можно разбить на три крупных этапа:
- Открытие файла
- Выполнение операции (запись, чтение)
- Закрытие файла
Открытие файла
Метод open()
В Python есть встроенная функция open() . С ее помощью можно открыть любой файл на компьютере. Технически Python создает на его основе объект.
- file_name = имя открываемого файла
- access_mode = режим открытия файла. Он может быть: для чтения, записи и т. д. По умолчанию используется режим чтения ( r ), если другое не указано. Далее полный список режимов открытия файла
Пример
Создадим текстовый файл example.txt и сохраним его в рабочей директории.
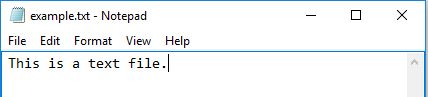
Следующий код используется для его открытия.
В этом примере f — переменная-указатель на файл example.txt .
Следующий код используется для вывода содержимого файла и информации о нем.
Стоит обратить внимание, что в Windows стандартной кодировкой является cp1252 , а в Linux — utf-08 .
Закрытие файла
Метод close()
После открытия файла в Python его нужно закрыть. Таким образом освобождаются ресурсы и убирается мусор. Python автоматически закрывает файл, когда объект присваивается другому файлу.
Существуют следующие способы:
Способ №1
Проще всего после открытия файла закрыть его, используя метод close() .
После закрытия этот файл нельзя будет использовать до тех пор, пока заново его не открыть.
Способ №2
Также можно написать try/finally , которое гарантирует, что если после открытия файла операции с ним приводят к исключениям, он закроется автоматически.
Без него программа завершается некорректно.
Вот как сделать это исключение:
Файл нужно открыть до инструкции try , потому что если инструкция open сама по себе вызовет ошибку, то файл не будет открываться для последующего закрытия.
Этот метод гарантирует, что если операции над файлом вызовут исключения, то он закроется до того как программа остановится.
Способ №3
Инструкция with
Еще один подход — использовать инструкцию with , которая упрощает обработку исключений с помощью инкапсуляции начальных операций, а также задач по закрытию и очистке.
В таком случае инструкция close не нужна, потому что with автоматически закроет файл.
Вот как это реализовать в коде.
Чтение и запись файлов в Python
В Python файлы можно читать или записывать информацию в них с помощью соответствующих режимов.
Функция read()
Функция read() используется для чтения содержимого файла после открытия его в режиме чтения ( r ).
Синтаксис
- file = объект файла
- size = количество символов, которые нужно прочитать. Если не указать, то файл прочитается целиком.
Пример
Функция readline()
Функция readline() используется для построчного чтения содержимого файла. Она используется для крупных файлов. С ее помощью можно получать доступ к любой строке в любой момент.
Пример
Создадим файл test.txt с нескольким строками:
Посмотрим, как функция readline() работает в test.txt .
Обратите внимание, как в последнем случае строки отделены друг от друга.
Функция write()
Функция write() используется для записи в файлы Python, открытые в режиме записи.
Если пытаться открыть файл, которого не существует, в этом режиме, тогда будет создан новый.
Синтаксис
Пример
Предположим, файла xyz.txt не существует. Он будет создан при попытке открыть его в режиме чтения.
Переименование файлов в Python
Функция rename()
Функция rename() используется для переименовывания файлов в Python. Для ее использования сперва нужно импортировать модуль os.
- src = файл, который нужно переименовать
- dest = новое имя файла
Пример
Текущая позиция в файлах Python
В Python возможно узнать текущую позицию в файле с помощью функции tell() . Таким же образом можно изменить текущую позицию командой seek() .
Резюме: UnicodeeCodeError обычно происходит при кодировании строки Unicode в определенное кодирование. Только ограниченное количество символов Unicode отображается на строки. Таким образом, любой символ, который не представляется/сопоставлен/сопоставлен, приведет к провалинию кодирования и повышать UnicodeEcodeEnror. Чтобы избежать этого Ошибка . Используйте кодирование ( UTF-8 ) и декодировать ( utf-8 ), соответствующим образом в вашем коде.
Вы можете использовать обработку кода приложений, который необходимо иметь дело с многоязычными данными или веб-контентом, который имеет много эмохий и специальных символов. В таких ситуациях вы, возможно, посмотрим многочисленные проблемы, связанные с данными Unicode. Но Python имеет четко определенные варианты, чтобы иметь дело с персонажами Unicode, и мы обсуждаем их в этой статье.
💡 Что такое Unicode?
🐞 Что такое UnicodeEcodeError?
В приведенном выше коде, когда мы пытались кодировать персонажа é к Его значение Unicode мы получили выход, но при попытке преобразовать его в эквивалент ASCII, мы столкнулись с ошибкой. Произошла ошибка, поскольку ASCII позволяет только 7-битное кодирование, и она не может представлять символы за пределами диапазона [0..128].
Теперь у вас есть сущность того, что UnicodeEcodeError похоже. Перед обсуждением того, как мы можем избежать таких ошибок, я чувствую, что есть ужасную необходимость обсудить следующие концепции:
💡 Кодирование и декодирование
- кодировать () это встроенный метод, используемый для кодирования. В случае не указана кодировка, UTF-8 используется в качестве по умолчанию.
- декодировать () это встроенный метод, используемый для декодирования.
Следующая диаграмма должна сделать вещи немного легче:
💡 CodePoint
Unicode отображает CodePoint к своим соответствующим персонажам. Итак, что мы подразумеваем под кодом?
- CodePoints являются числовыми значениями или целые числа, используемые для представления символа.
- Кодовая точка Unicode для ES U + 00E9 который является целым числом 233. Когда вы кодируете символ и распечатаете его, вы, как правило, получаете его шестнадцатеричное представление в качестве вывода вместо его двоичного эквивалента (как видно в приведенных выше примерах).
- Последовательность байтов кодовой точки отличается в разных схем кодирования. Например: последовательность байтов для É в UTF-8 это \ xc3 \ xa9 в то время как в UTF-16 это \ xff \ xfe \ xe9 \ x00.
Пожалуйста, посмотрите на следующую программу, чтобы получить лучшее сцепление на эту концепцию:
➥ Проблема: Учитывая строку/текст, который будет написан в текстовом файле; Как избежать UnicodeEcodeError и напишите данный текст в текстовом файле.
Выход :
Желаемый вывод :
✨ Решение 1: кодировать строку перед записью в файл и декодировать во время чтения
Вы не можете писать Unicode в файл напрямую. Это поднимет UnicodeEcodeError Отказ Чтобы избежать этого, вы должны кодировать Unicode строка используя кодировать () Функция, а затем запишите ее в файл, как показано в программе ниже:
✨ Решение 2: Открытый файл в UTF-8
Если вы используете Python 3 или выше, все, что вам нужно сделать, это открыть файл в UTF-8 , поскольку обработка строки Unicode уже стандартизирована в Python 3.
✨ Решение 3: Использование модуля кодеков
Еще один подход к борьбе с UnicodeEcodeError использует кодеки модуль.
Давайте посмотрим на следующий код, чтобы понять, как мы можем использовать модуль кодеков:
✨ Решение 4: Использование модуля Unicodecsv Python
Так как Unicodecsv Модуль не является частью стандартной библиотеки Python, вы должны установить его перед использованием. Используйте следующую команду для установки этого модуля:
Давайте посмотрим на следующий пример, чтобы получить лучшее сцепление на Unicodecsv Модуль:
Вывод
В этой статье мы обсудили некоторые важные концепции, касающиеся персонажа Unicode, а затем продолжали узнать о UnicodeEcodeError и, наконец, обсудили методы, которые мы можем использовать, чтобы избежать его. Я надеюсь, что к концу этой статьи вы можете с легкостью обрабатывать символы Unicode в вашем Python.
Пожалуйста, подпишитесь и оставайтесь настроенными для более интересных статей!
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Я профессиональный Python Blogger и Content Creator. Я опубликовал многочисленные статьи и создал курсы в течение определенного периода времени. В настоящее время я работаю полный рабочий день, и у меня есть опыт в областях, таких как Python, AWS, DevOps и Networking.
У меня есть этот скрипт Python, который берет информацию о веб-странице, а затем сохраняет эту информацию в текстовом файле. Но имя этого текстового файла время от времени меняется, и иногда оно может меняться на кириллицу, а иногда и на корейские буквы.
Проблема в том, что, скажем, я пытаюсь сохранить файл с именем «бореиская», тогда это имя будет выглядеть очень странно, когда я просматриваю его в Windows.
Я думаю, мне нужно изменить кодировку в некоторых местах. Но имя отправляется в функцию open() :
Ранее я брал переменную сервера из массива, в котором уже есть все имена.
Но, как уже упоминалось ранее, в Windows имена появляются с некоторыми очень странными символами.
3 ответа
ТЛ ; др
Всегда используйте строки Unicode для имен файлов и путей. Например.:
Я предполагаю, что server придет из другого места, поэтому вам нужно убедиться, что он правильно декодирован в строку Unicode. Смотрите io.open() .
Объяснение
Windows
Linux
Имена файлов могут быть сделаны из любой байтовой строки в любой кодировке, если только это не ASCII "." или "..". Поскольку у каждого пользователя системы может быть своя собственная кодировка, вы действительно не можете гарантировать, что кодировка, используемая одним пользователем, совпадает с другой. locale используется для настройки среды каждого пользователя. Кодировка терминала пользователя также должна соответствовать кодировке для согласованности.
Лучшее, на что можно надеяться, это то, что пользователь не изменил свою локаль, и все приложения используют одну и ту же локаль. Например, языковой стандарт по умолчанию может быть: en_GB.UTF-8 , что означает, что кодировка файлов и имен файлов должна быть UTF-8.
Когда Python встречает имя файла Unicode, он будет использовать локаль пользователя для декодирования / кодирования имен файлов. Закодированная строка будет передана непосредственно в ядро, что означает, что вам может повезти с использованием имен файлов «UTF-8».
Имена файлов OS X всегда в кодировке UTF-8, независимо от локали пользователя. Следовательно, имя файла должно быть строкой Unicode, но может быть закодировано в локали пользователя и будет переведено. Поскольку большинство пользовательских локалей - *.UTF-8 , это означает, что вы можете фактически передать строку в кодировке UTF-8 или строку Unicode.
Округлять
Для лучшей кросс-платформенной совместимости всегда используйте строки Unicode, так как в большинстве случаев они будут переведены в правильную кодировку. Это действительно просто Linux, который имеет наибольшую двусмысленность, поскольку некоторые приложения могут игнорировать локаль по умолчанию или пользователь мог изменить свою локаль на версию не-UTF-8.
В Windows вы должны закодировать имя файла, вероятно, в одну из cp125x кодировок, но я не знаю, какая именно - вероятно cp1251 .
В Linux вы должны использовать utf-8
Я просматриваю это в Windows. . Использование Python 2.7
Используйте имена файлов Unicode в Windows. Python может использовать Unicode API там.
Не используйте символы не ascii в литералах байтовых строк (это явно запрещено в Python 3).
На этом занятии мы поговорим, как в Python можно считывать информацию из файлов и записывать ее в файлы. Что такое файлы и зачем они нужны, думаю объяснять не надо, т.к. если вы дошли до этого занятия, значит, проблем с пониманием таких базовых вещей у вас нет. Поэтому сразу перейдем к функции
open(file [, mode=’r’, encoding=None, …])
- file – это путь к файлу вместе с его именем;
- mode – режим доступа к файлу;
- encoding – кодировка файла.
Для начала определимся с понятием «путь к файлу». Представим, что наш файл ex1.py находится в каталоге app:

Тогда, чтобы обратиться к файлу my_file.txt путь можно записать так:
Последние два варианта представляют собой абсолютный путь к файлу, то есть, полный путь, начиная с указания диска. Причем, обычно используют обратный слеш в качестве разделителя: так короче писать и такой путь будет корректно восприниматься как под ОС Windows, так и Linux. Первый же вариант – это относительный путь, относительно рабочего каталога.
Теперь, предположим, мы хотим обратиться к файлу img.txt. Это можно сделать так:
Для доступа к out.txt пути будут записаны так:
Обратите внимание, здесь две точки означают переход к родительскому каталогу, то есть, выход из каталога app на один уровень вверх.
И, наконец, для доступа к файлу prt.dat пути запишутся так:
Вот так следует прописывать пути к файлам. В нашем случае мы имеем текстовый файл «myfile.txt», который находится в том же каталоге, что и программа ex1.py, поэтому путь можно записать просто указав имя файла:
В результате переменная file будет ссылаться на файловый объект, через который и происходит работа с файлами. Если указать неверный путь, например, так:
то возникнет ошибка FileNotFoundError. Это стандартное исключение и как их обрабатывать мы с вами говорили на предыдущем занятии. Поэтому, запишем этот критический код в блоке try:
Изменим имя файла на верное и посмотрим, как далее можно с ним работать. По умолчанию функция open открывает файл в текстовом режиме на чтение. Это режим
Если нам нужно поменять режим доступа к файлу, например, открыть его на запись, то это явно указывается вторым параметром функции open:
- 'rt' – чтение в текстовом режиме;
- 'wb' – запись в бинарном режиме;
- 'a+' – дозапись или чтение данных из файла.
Чтение информации из файла
В чем отличие текстового режима от бинарного мы поговорим позже, а сейчас откроем файл на чтение в текстовом режиме:
и прочитаем его содержимое с помощью метода read:
Теперь все будет работать корректно. Далее, в методе read мы можем указать некий числовой аргумент, например,
Тогда из файла будут считаны первые два символа. И смотрите, если мы запишем два таких вызова подряд:
то увидим, что при следующем вызове метод read продолжил читать следующие два символа. Почему так произошло? Дело в том, что у файлового объекта, на который ссылается переменная file, имеется внутренний указатель позиции (file position), который показывает с какого места производить считывание информации.

Когда мы вызываем метод read(2) эта позиция автоматически сдвигается от начала файла на два символа, т.к. мы именно столько считываем. И при повторном вызове read(2) считывание продолжается, т.е. берутся следующие два символа. Соответственно, позиция файла сдвигается дальше. И так, пока не дойдем до конца.
Но мы в Python можем управлять этой файловой позицией с помощью метода
Например, вот такая запись:
будет означать, что мы устанавливаем позицию в начало и тогда такие строчки:
будут считывать одни и те же первые символы. Если же мы хотим узнать текущую позицию в файле, то следует вызвать метод tell:
Следующий полезный метод – это readline позволяет построчно считывать информацию из текстового файла:
Здесь концом строки считается символ переноса ‘\n’, либо конец файла. Причем, этот символ переноса строки будет также присутствовать в строке. Мы в этом можем убедиться, вызвав дважды эту функцию:
Здесь в консоли строчки будут разделены пустой строкой. Это как раз из-за того, что один перенос идет из прочитанной строки, а второй добавляется самой функцией print. Поэтому, если их записать вот так:
то вывод будет построчным с одним переносом.
Если нам нужно последовательно прочитать все строчки из файла, то для этого обычно используют цикл for следующим образом:
Этот пример показывает, что объект файл является итерируемым и на каждой итерации возвращает очередную строку.
Или же, все строчки можно прочитать методом
и тогда переменная s будет ссылаться на упорядоченный список с этими строками:
Однако этот метод следует использовать с осторожностью, т.к. для больших файлов может возникнуть ошибка нехватки памяти для хранения полученного списка.
По сути это все методы для считывания информации из файла. И, смотрите, как только мы завершили работу с файлом, его следует закрыть. Для этого используется метод close:
Конечно, прописывая эту строчку, мы не увидим никакой разницы в работе программы. Но, во-первых, закрывая файл, мы освобождаем память, связанную с этим файлом и, во-вторых, у нас не будет проблем в потере данных при их записи в файл. А, вообще, лучше просто запомнить: после завершения работы с файлом, его нужно закрыть. Причем, организовать программу лучше так:
Мы здесь создаем вложенный блок try, в который помещаем критический текст программы при работе с файлом и далее блок finally, который будет выполнен при любом стечении обстоятельств, а значит, файл гарантированно будет закрыт.
Или же, забегая немного вперед, отмечу, что часто для открытия файла пользуются так называемым менеджером контекста, когда файл открывают при помощи оператора with:
При таком подходе файл закрывается автоматически после выполнения всех инструкций внутри этого менеджера. В этом можно убедиться, выведем в консоль флаг, сигнализирующий закрытие файла:
Запустим программу, видите, все работает также и при этом файл автоматически закрывается. Даже если произойдет критическая ошибка, например, пропишем такую конструкцию:
то, как видим, файл все равно закрывается. Вот в этом удобство такого подхода при работе с файлами.
Запись информации в файл
Теперь давайте посмотрим, как происходит запись информации в файл. Во-первых, нам нужно открыть файл на запись, например, так:
и далее вызвать метод write:
В результате у нас будет создан файл out.txt со строкой «Hello World!». Причем, этот файл будет располагаться в том же каталоге, что и файл с текстом программы на Python.
Далее сделаем такую операцию: запишем метод write следующим образом:
И снова выполним эту программу. Смотрите, в нашем файле out.txt прежнее содержимое исчезло и появилось новое – строка «Hello». То есть, когда мы открываем файл на запись в режимах
то прежнее содержимое файла удаляется. Вот этот момент следует всегда помнить.
Теперь посмотрим, что будет, если вызвать метод write несколько раз подряд:
Смотрите, у нас в файле появились эти строчки друг за другом. То есть, здесь как и со считыванием: объект file записывает информацию, начиная с текущей файловой позиции, и автоматически перемещает ее при выполнении метода write.
Если мы хотим записать эти строчки в файл каждую с новой строки, то в конце каждой пропишем символ переноса строки:
Далее, для дозаписи информации в файл, то есть, записи с сохранением предыдущего содержимого, файл следует открыть в режиме ‘a’:
Тогда, выполняя эту программу, мы в файле увидим уже шесть строчек. И смотрите, в зависимости от режима доступа к файлу, мы должны использовать или методы для записи, или методы для чтения. Например, если вот здесь попытаться прочитать информацию с помощью метода read:
то возникнет ошибка доступа. Если же мы хотим и записывать и считывать информацию, то можно воспользоваться режимом a+:
Так как здесь файловый указатель стоит на последней позиции, то для считывания информации, поставим его в самое начало:
А вот запись данных всегда осуществляется в конец файла.
Следующий полезный метод для записи информации – это writelines:
Он записывает несколько строк, указанных в коллекции. Иногда это бывает удобно, если в процессе обработки текста мы имеем список и его требуется целиком поместить в файл.
Чтение и запись в бинарном режиме доступа
Что такое бинарный режим доступа? Это когда данные из файла считываются один в один без какой-либо обработки. Обычно это используется для сохранения и считывания объектов. Давайте предположим, что нужно сохранить в файл вот такой список:
Откроем файл на запись в бинарном режиме:
Далее, для работы с бинарными данными подключим специальный встроенный модуль pickle:
И вызовем него метод dump:
Все, мы сохранили этот объект в файл. Теперь прочитаем эти данные. Откроем файл на чтение в бинарном режиме:
и далее вызовем метод load модуля pickle:
Все, теперь переменная bs ссылается на эквивалентный список:
Аналогичным образом можно записывать и считывать сразу несколько объектов. Например, так:
А, затем, считывание в том же порядке:
Вот так в Python выполняется запись и считывание данных из файла.
Задания для самоподготовки
1. Выполните считывание данных из текстового файла через символ и записи прочитанных данных в другой текстовый файл. Прочитывайте так не более 100 символов.
2. Пользователь вводит предложение с клавиатуры. Разбейте это предложение по словам (считать, что слова разделены пробелом) и сохраните их в столбец в файл.
3. Пусть имеется словарь:
Необходимо каждый элемент этого словаря сохранить в бинарном файле как объект. Затем, прочитать этот файл и вывести считанные объекты в консоль.
Видео по теме



























































© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Читайте также: