
Простейший способ организации данных в компьютере состоящий из кодов таблицы символьной кодировки
Обновлено: 07.07.2024
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
В 7:34 поступил вопрос в раздел ЕГЭ (школьный), который вызвал затруднения у обучающегося.
Вопрос вызвавший трудности
Что такое гипертекст? А) простейший способ организации данных в компьютере, состоящий из кодов таблицы символьной кодировки Б) способ организации текстовой информации, внутри которой установлены смысловые связи между различными её фрагментами В) прикладная программа, позволяющая создавать текстовые документыДля того чтобы дать полноценный ответ, был привлечен специалист, который хорошо разбирается требуемой тематике "ЕГЭ (школьный)". Ваш вопрос звучал следующим образом: Что такое гипертекст? А) простейший способ организации данных в компьютере, состоящий из кодов таблицы символьной кодировки Б) способ организации текстовой информации, внутри которой установлены смысловые связи между различными её фрагментами В) прикладная программа, позволяющая создавать текстовые документы
После проведенного совещания с другими специалистами нашего сервиса, мы склонны полагать, что правильный ответ на заданный вами вопрос будет звучать следующим образом:
Б) способ организации текстовой информации, внутри которой установлены смысловые связи между различными её фрагментамиНЕСКОЛЬКО СЛОВ ОБ АВТОРЕ ЭТОГО ОТВЕТА:

Работы, которые я готовлю для студентов, преподаватели всегда оценивают на отлично. Я занимаюсь написанием студенческих работ уже более 4-х лет. За это время, мне еще ни разу не возвращали выполненную работу на доработку! Если вы желаете заказать у меня помощь оставьте заявку на этом сайте. Ознакомиться с отзывами моих клиентов можно на этой странице.
Карпова Капитолина Мэлоровна - автор студенческих работ, заработанная сумма за прошлый месяц 68 700 рублей. Её работа началась с того, что она просто откликнулась на эту вакансию
ПОМОГАЕМ УЧИТЬСЯ НА ОТЛИЧНО!
Выполняем ученические работы любой сложности на заказ. Гарантируем низкие цены и высокое качество.
Деятельность компании в цифрах:
Зачтено оказывает услуги помощи студентам с 1999 года. За все время деятельности мы выполнили более 400 тысяч работ. Написанные нами работы все были успешно защищены и сданы. К настоящему моменту наши офисы работают в 40 городах.
Ответы на вопросы - в этот раздел попадают вопросы, которые задают нам посетители нашего сайта. Рубрику ведут эксперты различных научных отраслей.
Полезные статьи - раздел наполняется студенческой информацией, которая может помочь в сдаче экзаменов и сессий, а так же при написании различных учебных работ.
Красивые высказывания - цитаты, афоризмы, статусы для социальных сетей. Мы собрали полный сборник высказываний всех народов мира и отсортировали его по соответствующим рубрикам. Вы можете свободно поделиться любой цитатой с нашего сайта в социальных сетях без предварительного уведомления администрации.
Процессор берёт команды программ и данные для обработки из памяти. Память является электронным устройством и состоит из микросхем, которые, в свою очередь, состоят из тысяч более мелких электронных компонентов. Подобные электронные компоненты могут находиться только в двух состояниях — «включено» или «выключено», что соответствует двум цифрам двоичной системы счисления 1 или 0 или одному биту.
Таким образом, любая информация в памяти компьютера представляется в виде последовательности битов, каждый из которых находится в одном из допустимых состояний.
При использовании одного бита можно представить в памяти компьютера только два различных символа. Одному из них будет сопоставлен двоичный код — ноль, а второму — единица.
Если мы увеличим длину кодовой комбинации символа до двух цифр, то получим следующие коды: 00, 01, 10, 11. Таким образом, в памяти компьютера можно будет представить четыре различных символа. При последовательном наращивании длины двоичной кодовой комбинации увеличивается количество символов, которые могут быть закодированы. Кодом длиной в три символа представляются 8 различных символов (000, 001, 010, 011, 100, 101, 110, 111) и т. д.
При длине кодовой комбинации L количество кодовых комбинаций K определяется по формуле:
K = 2 L ,
Текстовая информация состоит из букв, цифр, знаков препинания, специальных символов, таких, как пробел, символ перевода строки и др. Для кодирования текстовой информации в компьютере используются равномерные коды. В случае, когда код каждого символа занимает в памяти компьютера 1 байт, или 8 бит, общее количество символов, которые можно закодировать, равно 2 8 = 256. Если кодовое слово состоит из двух байтов, можно закодировать 2 16 = 65 536 символов.
Существуют стандартные таблицы кодов. Они могут использовать один или два байта для кодирования одного символа.
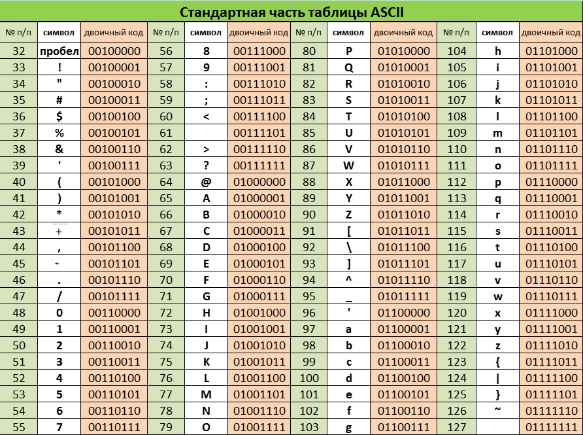
Широко используется таблица кодов, известная как стандарт ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией), использующая один байт для кодирования одного символа. ASCII представляет собой кодировку для представления десятичных цифр, символов латинского и национального алфавитов, знаков препинания, символов арифметических операций и управляющих символов. Управляющие символы называют непечатаемыми символами, к ним относятся такие, как «перевод строки» (код символа 10), «возврат каретки» (код 13) и др.
Первая половина кодовой таблицы содержит стандартные символы ASCII (символы с кодами 0 — 127), они одинаковые во всех странах.
Коды в таблице записаны в шестнадцатеричной системе счисления, как принято в информатике. Код символа А, например, 4116 = 6510. Таблицу кодов не надо запоминать, но следует помнить последовательность символов:
- знаки препинания и арифметических операций;
- цифры от 0 до 9;
- прописные символы латинского алфавита;
- строчные символы латинского алфавита.
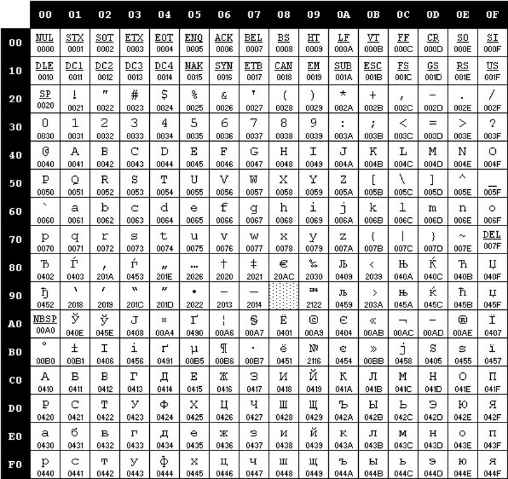
Вторая часть кодовой таблицы (символы с кодами 128 — 255) называют расширенными кодами ASCII. В расширенные коды ASCII включают символы национальных алфавитов, например символы кириллицы. Но даже с учётом этих дополнительных знаков алфавиты многих языков не удаётся охватить при помощи 256 знаков. По этой причине существуют различные варианты кодировки ASCII, включающие символы разных языков.
Отсутствие согласованных стандартов привело к появлению различных кодовых таблиц (вернее, различных вторых частей кодовых таблиц) для кодирования символов кириллицы, среди которых
- международный стандарт ISO 8859;
- кодовая таблица фирмы Microsoft CP-1251 (кодировка Windows);
- кодовая таблица, применяемая в ОС Unix KOI8R и др.
По этой причине тексты на русском языке, набранные с использованием одной кодовой таблицы, невозможно прочитать при использовании другой кодовой таблицы.
В настоящее время в компьютерах широко применяется стандарт кодирования Unicode (Юникод), в котором для кодирования одного символа отводятся один байт, два байта или четыре байта. Первые 128 символов Юникода совпадают с символами ASCII. Остальная часть кодовой таблицы включает символы, используемые в основных языках мира.
Изображение на экране монитора формируется набором экранных точек —пикселей. Каждая экранная точка имеет свой цвет. Картинка на экране — это отображение информации из памяти компьютера.
Первые мониторы были монохромными. Точка на экране монохромного монитора может быть только светлой (белой) или тёмной (чёрной). Для кодирования цвета пикселя используется один бит памяти, значение 1 соответствует белому цвету, 0 — чёрному. Подобные экраны используются в недорогих сотовых телефонах, системах видеонаблюдения и других устройствах.
Каждый пиксель современного дисплея определяется компонентами трёх основных цветов: красного (Red, R), зелёного (Green, G) и синего (Blue, B). В памяти необходимо сохранять информацию о состоянии каждой точки изображения, т. е. о состоянии каждой из её трёх составляющих. Управление яркостью каждой составляющей позволяет влиять на цвет экранной точки.
Цветовой моделью называется правило представления цвета в виде наборов чисел (обычно трёх-четырёх). В компьютерной графике используется несколько видов цветовых моделей.
Рассмотрим цветовую модель, связанную с представлением пикселя составляющими красного, зелёного и синего цветов. Она называется RGB(Red-Green-Blue)-моделью.
В RGB-модели происходит сложение цветов и добавление их к чёрному цвету экрана, поэтому она называется аддитивной (additive). Разные цвета образуются смешиванием трёх основных цветов в разных пропорциях, т. е. с разными яркостями.
Глубина цвета (color depth) — это число бит, используемых для представления каждого пикселя изображения.
В модели RGB каждый цвет может кодироваться тремя байтами (режимTrueColor). Каждый байт отвечает за яркость красной, зеленой и синей составляющей пикселя соответственно. Таким образом, глубина цвета в режиме TrueColor составляет 24 бита. Изображения, пиксели которых закодированы таким способом, называются 24-битными изображениями.
Чтобы указать цвет пикселя в модели RGB, достаточно перечислить разделённые точками яркости каждой составляющей, например: 255.255.0 — код жёлтой точки, записанный при помощи десятичных кодов яркостей. Значения яркости варьируются от 0 («выключено») до 255 («включено на максимум»). Если значения яркостей всех трёх составляющих равны, получим оттенки серого цвета.
Если изменять интенсивность каждого цвета для смешанных цветов, например задать цвет 127.127.0, то мы получим на экране болотный цвет, а не более тёмный оттенок жёлтого цвета, как можно было ожидать. Это связано с тем, что человеческий глаз более чувствителен к зелёному цвету. Чем ниже интенсивности составляющих, тем темнее цвет на экране. И наоборот — чем выше интенсивности цветов, тем светлее оттенки.
Модель CMY использует также три основных цвета: голубой (Cyan), фуксин (Magenta, иногда его называют «пурпурный» или «малиновый») и жёлтый (Yellow). Эти цвета описывают отражённый от белой бумаги свет трёх основных цветов RGB-модели.
Модель CMY является субтрактивной (основанной на вычитании) цветовой моделью. Краситель, нанесённый на белую бумагу, вычитает часть спектра из падающего белого света. Например, на поверхность бумаги нанесли жёлтый (Yellow) краситель. Теперь синий свет, падающий на бумагу, полностью поглощается. Таким образом, жёлтый носитель вычитает синий свет из падающего белого.
При смешении двух субтрактивных составляющих результирующий цвет затемняется, а при смешении всех трёх должен получиться чёрный цвет. Но при использовании реальных полиграфических красок получается не чёрный, а неопределённый тёмный цвет. Поэтому к трём основным цветам CMY-модели добавляют чёрный (Black) и получают новую цветовую модель CMYK.
Цветовая модель CMYK используется в основном в полиграфии при выводе изображения на печать.
Количество различных цветов K и количество битов для их кодирования (глубина цвета) L связаны формулой K = 2 L . При L = 24 бита можно закодировать 2 24 = 16 777 216 различных цветов.
Если известно разрешение экрана (количество точек по горизонтали и вертикали) и глубина цвета, можно определить объём видеопамяти для хранения одного кадра (одной страницы) изображения. Например, при разрешении экрана 640 × 480 и использовании 24 бит на точку объём видеопамяти равен 640 ∙ 480 ∙ 24 = 7 372 800 бит = 900 Кбайт.
Все компьютерные изображения делятся на два больших класса — растровые и векторные. Различие между ними определяет способ хранения изображений в памяти компьютера.
Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда сигнала, тем громче звук; чем больше частота сигнала (число колебаний в секунду), тем выше тон.
В настоящее время существует два основных способа записи звука —аналоговый (непрерывный) и цифровой (дискретный). Виниловая пластинка является примером аналогового хранения звуковой информации, так как звуковая дорожка изменяет свою форму непрерывно. Компакт-диски являются примером цифрового хранения звуковой информации, так как звуковая дорожка компакт-диска содержит участки с различной отражающей способностью.
Для того чтобы записать звук на какой-нибудь носитель, его нужно преобразовать в электрический сигнал. Это делается с помощью микрофона. Микрофоны имеют мембрану, которая колеблется под воздействием звуковых волн. К мембране присоединена катушка, перемещающаяся синхронно с мембраной в магнитном поле. В катушке возникает переменный электрический ток. Так звуковые волны преобразуются микрофоном в электрический ток переменного напряжения, который представляет собой аналоговый сигнал. Применительно к электрическому сигналу термин «аналоговый» обозначает, что этот сигнал непрерывен по времени и амплитуде (см. рис. 11а).
Для того чтобы компьютер мог обрабатывать звук, непрерывный сигнал должен быть превращён в последовательность электрических импульсов (двоичных нулей и единиц). В процессе кодирования непрерывного звукового сигнала производится его дискретизация по времени. Дискретизация — это преобразование непрерывных сигналов в набор дискретных значений, каждому из которых присваивается число — кодовое слово.
Для дискретизации надо несколько раз в секунду измерять величину аналогового сигнала и кодировать её, например, с помощью 256 значений.
Фактически плоскость, на которой изображён непрерывный сигнал, разбивается вертикальными и горизонтальными линиями (см. рис. 11б), и считается, что график проходит строго через узлы полученной сетки, непрерывная плавная линия заменяется ломаной.

Дискретизация по времени соответствует разбиению вертикальными линиями. Она характеризуется частотой дискретизации. Частота дискретизации звукового компакт-диска 44,1 кГц, DVD — примерно 96 кГц. Это значит, что величина аналогового сигнала измеряется 44 100 и 96 000 раз в секунду соответственно. Если кодируется стереозвук, отдельно кодируются два канала.
Горизонтальное разбиение также важно: чем меньше расстояние между горизонтальными линиями сетки, тем качественнее будет цифровой звук. Количество линий сетки определяет количество уровней звука, поэтому горизонтальное разбиение называется квантованием по уровню. Для кодирования полученных значений уровней используют двоичные числа. Количество используемых для кодирования бит называется глубиной звука. Если глубина звука 8 бит или 16 бит, можно закодировать соответственно 2 8 = 256 уровней или 2 16 = 65 536 уровней сигналов. Это значит, что интервал от нулевого до максимального напряжения аналогового сигнала разбивается на 256 или 65 536 уровней, что соответствует количеству высот звука (тонов).
Преобразование непрерывной звуковой волны в последовательность звуковых импульсов различной амплитуды производится с помощью аналого-цифрового преобразователя (АЦП), размещённого на звуковой плате.
С помощью специальных программных средств (редакторов звукозаписей) открываются широкие возможности по созданию, редактированию и прослушиванию звуковых файлов. Но, как видно из примера, звуковые файлы занимают очень много места в памяти. Поэтому используются методы сжатия звуковых файлов. Качество музыки после сжатия несколько ухудшается, но это практически незаметно, так как при разработке алгоритмов сжатия учитываются законы восприятия музыки человеком.
Урок 13. Представление текстовой информации в компьютере. Кодовые таблицы.
Практическая работа № 4. Представление текстов. Сжатие текстов

В этом параграфе обсудим способы компьютерного кодирования текстовой, графической и звуковой информации. С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
Что принципиально нового появлялось в устройстве компьютеров с освоением ими новых видов информации? Главным образом, это периферийные устройства для ввода и вывода текстов, графики, видео, звука. Процессор же и оперативная память по своим функциям изменились мало. Существенно возросло их быстродействие, объем памяти. Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
О том, как текст, графика и звук сводятся к целым числам, будет рассказано дальше. Предварительно отметим, что здесь мы снова встретимся с главной формулой информатики:
Смысл входящих в нее величин здесь следующий: i — разрядность ячейки памяти (в битах), N — количество различных целых положительных чисел, которые можно записать в эту ячейку.
Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).

Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 2 16 = 65 536 различных символов.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Практикум
Практическая работа № 1.4 "Представление текстов. Сжатие текстов"
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
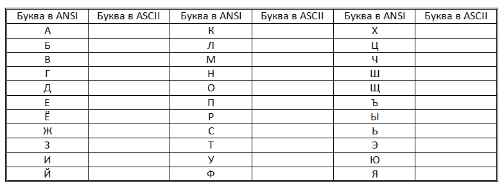
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Задание 6
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмена. Сжатием информации в памяти компьютера называют такое её преобразование, которое ведёт к сокращению объёма ханимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации - алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
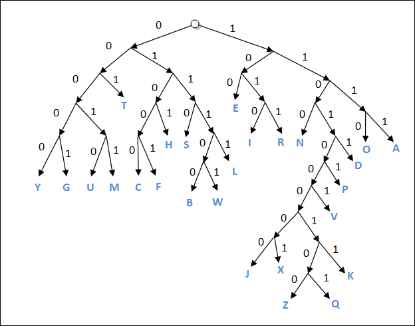
Закодируем с помощью данного дерева слово "hello":
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000
Читайте также: