
Provisioned space vmware что это
Обновлено: 04.07.2024
При создании новой виртуальной машины в гипервизоре VMware ESXi можно выбрать следующие варианты организации жесткого диска:
Thin Provision -"тонкий" диск, изначально не занимает на файловой системе VMFS места, разрастается до максимального размера по мере накопления информации.
Thick Provision Lazy Zeroed - "толстый" диск, резервирует свое максимальное пространство на VMFS сразу же при создании.
Thick Provision Eager Zeroed - тоже самое что и Thick Provision Lazy Zeroed, только в момент создания все пространство заполняется нулями, это замедляет процесс инсталляции но повышает производительность диска в эксплуатации.
Способы конвертации диска через GUI vSphere Client:
1. Толстый в тонкий(THICK to THIN) - при наличии "Storage VMotion", во время миграции на другой datastore можно в окне мастера поменять формат виртуального диска. Т.е. мигрируем туда и обратно. Либо, при отсутствии "Storage VMotion", клонируем виртуальную машину под другим именем и с изменением формата диска.


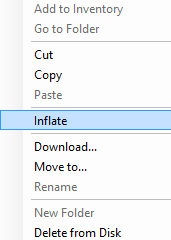
2. Тонкий в толстый(THIN to THICK) - также подойдет первый способ, но кроме него можно кликнуть правой кнопкой в окне "Datastore Browser" на соответствующем файле формата ".vmdk", и выбрать в контекстном меню команду "Inflate".
Способы конвертации диска используя консоль ESXi сервера или подключение по SSH:
1. Толстый в тонкий(THICK to THIN) - используя консоль, переходим в каталог с файлами виртуальной машины и выполняем команду:
В этом случае файл виртуального диска называется vm1.vmdk. Чтобы не ошибиться с выбором файла, его имя нужно уточнить в свойствах виртуальной машины("Edit Settings"), закладка "Hardware". Кликните на жесткий диск, и в поле "Disk File" будет указан путь к необходимому файлу ".vmdk".
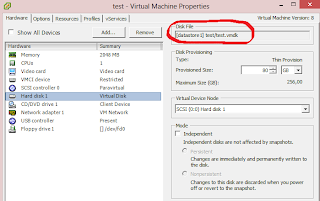
2. Тонкий в толстый(THIN to THICK) - также как и в первом пункте, только используя другой параметр:
VASA это набор API, предоставляемый VMware и предназначенный для разработки провайдеров хранилищ (storage providers) для инфраструктуры vSphere. Storage provider-ы это программные компоненты, предоставляемые vSphere или разрабатываемые 3-ей стороной, предназначенные для интеграции (отслеживания) хранилищ (программных и аппаратных СХД) и фильтров ввода-вывода (VAIO) с инфраструктурой vSphere.
Storage provider (VASA-провайдер) нужен для того, чтобы виртуальная инфраструктура:
- получала информацию о статусе, характеристиках и возможностях СХД;
- могла работать с такими сущностями как Virtual SAN and Virtual Volumes;
- могла взаимодействовать с фильтры ввода-вывода (VAIO).
VASA-провайдеры сторонних разработчиков используются как сервисы отслеживания информации о данном хранилище для vSphere. Такие провайдеры требуют отдельной регистрации и установки соответствующих плагинов.
Встроенные storage provider-ы являются компонентами vSphere и не требуют регистрации. Так, например, провайдер для Virtual SAN автоматически регистрируется при её развертывании.
vSphere посредством storage provider собирает информацию о хранилищах (характеристики, статус, возможности) и сервисах данных (фильтрах VAIO) во всей инфраструктуре, данная информация становится доступной для мониторинга и принятия решений через vSphere Web Client.
Информацию, собираемую VASA-провайдерами, можно разделить на 3 категории:
- Возможности и сервисы хранилища. Это как раз то, на основе чего формируются правила Common rules и Rules Based on Storage-Specific Data Services в SPBM – возможности и сервисы, предоставляемые Virtual SAN, vVol и фильтрами ввода-вывода.
- Состояние хранилища. Информация о состоянии и событиях на стороне хранилищ, в т.ч. тревожные события, изменения конфигурации.
- Информация Storage DRS. Данная информация позволяет учитывать внутренние процессы управления хранилищами в работе механизма Storage DRS.
К одному storage provider-у могут одновременно обращаться несколько серверов vCenter. Один vCenter может одновременно взаимодействовать с множеством storage provider-ов (несколько массивов и фильтров ввода-вывода).
VAAI — vSphere API for Array Integration / Набор API для интеграции массива
API данного типа можно разделить на 2 категории:
- Hardware Acceleration APIs. Предназначены для прозрачного переноса нагрузок по выполнению отдельных операций связанных с хранением с гипервизоров на СХД.
- Array Thin Provisioning APIs. Предназначены для мониторинга пространства на «тонких» разделах массивов для предотвращения ситуаций с нехваткой места и выполнения отзыва (неиспользуемого) пространства.
Storage Hardware Acceleration (VAAI для Hardware Acceleration)
Данный функционал обеспечивает интеграцию хостов ESXi и совместимых СХД, позволяет перенести выполнение отдельных операций по сопровождению ВМ и хранилища с гипервизора (хоста ESXi) на массив (СХД), благодаря чему увеличивается скорость выполнения данных операций, при этом снижается нагрузка на процессор и память хоста, а также на сеть хранения данных.
Storage Hardware Acceleration поддерживается для блочных (FC, iSCSI) и файловых (NAS) СХД. Для работы технологии необходимо, чтобы блочное устройство поддерживало стандарт T10 SCSI либо имело VAAI-плагин. Если блочный массив поддерживает стандарт T10 SCSI, то VAAI-плагин для поддержки Hardware Acceleration не нужен, все заработает напрямую. Файловые хранилища требуют наличия отдельного VAAI-плагина. Разработка VAAI-плагинов ложится на плечи производителя СХД.
В целом VAAI для Hardware Acceleration позволяют оптимизировать и переложить на массив следующие процессы:
- Миграция ВМ посредством Storage vMotion.
- Развертывание ВМ из шаблона.
- Клонирование ВМ или шаблонов ВМ.
- Блокировки VMFS и операции с метаданными для ВМ.
- Работа с «толстыми» дисками (блочный и файловый доступ, eager-zero диски).
- Full copy (clone blocks или copy offload). Позволяет массиву делать полную копию данных, избегая операций чтения-записи хостом. Данная операция сокращает время и сетевую нагрузку при клонировании, развертывании из шаблона или миграции (перемещении диска) ВМ.
- Block zeroing (write same). Позволяет массиву обнулять большое количество блоков, что значительно оптимизирует создание дисков типа «eager zero thick» для ВМ.
- Hardware assisted locking (atomic test and set — ATS). Позволяет избежать блокировки LUN-а с VMFS целиком (нет необходимости использовать команду SCSI reservation) благодаря поддержке выборочной блокировки отдельных блоков. Исключается потеря (снижается вероятность потери) производительности хранилища при внесении гипервизором изменений в метаданные на LUN с VMFS.
Пояснение
VMFS является кластерной ФС (файловая система) и поддерживает параллельную работу нескольких хостов ESXi (гипервизоров) с одним LUN-ом (который под неё отформатирован). На LUN-е с VMFS может размешаться множество файлов ВМ, а также метаданные. В обычном режиме, пока не вносятся изменения в метаданные, все работает параллельно, множество хостов обращается в VMFS, никто никому не мешает, нет никаких блокировок.
Если Hardware Acceleration (VAAI) не поддерживаются блочным устройством, то для внесения изменений в метаданные на VMFS каким-либо хостом приходится использовать команду SCSI reservation, LUN при этом передается в монопольное использование данному хосту, для остальных хостов на момент внесения изменений в метаданные этот LUN становится недоступен, что может вызвать ощутимую потерю производительности.
Метаданные содержат информацию о самом разделе VMFS и о файлах ВМ. Изменения метаданных происходят в случае: включения/выключения ВМ, создания фалов ВМ (создание ВМ, клонирование, миграция, добавление диска, создание снапшота), удаление файлов (удаление ВМ или дисков ВМ), смена владельца файла ВМ, увеличение раздела VMFS, изменение размера файлов ВМ (если у ВМ «тонкие» диски или используются снапшоты – это происходит постоянно).
Hardware Acceleration для VMFS не отработает и нагрузка ляжет на хост если:
- VMFS разделы источника и назначения имеют разные размеры блока
- Файл источник имеет формат RDM, файл назначения не-RDM
- Исходный файл «eager-zeroed-thick», файл назначения «тонкий»
- ВМ имеет снапшоты
- VMFS растянута на несколько массивов
- Full File Clone. Позволяет клонировать файлы ВМ на уровне устройства NAS.
- Reserve Space. Позволяет резервировать пространство для ВМ с «толстыми» дисками (по умолчанию NFS не резервирует пространство и не позволяет делать «толстые» диски).
- Native Snapshot Support. Поддержка создания снапшотов ВМ на уровне массива.
- Extended Statistics. Даёт возможность увидеть использование пространства на массиве.
Multipathing Storage APIs — Pluggable Storage Architecture (PSA) / Набор API для мультипафинга
Для управления мультипафингом гипервизор ESXi использует отдельный набор Storage APIs называемый Pluggable Storage Architecture (PSA). PSA – открытый модульный каркас (framework), координирующий одновременную работу множества плагинов мультипафинга (multipathing plug-ins – MPPs). PSA позволяет производителям разрабатывать (интегрировать) собственные технологии мультипафинга (балансировки нагрузки и восстановления после сбоя) для подключения своих СХД к vSphere.
PSA выполняет следующие задачи:
- Загружает и выгружает плагины мультипафинга
- Скрывает от ВМ специфику работы плагинов мультипафинга
- Направляет запросы ввода-вывода MPP
- Обрабатывает очереди ввода-вывода
- Распределяет полосу пропускания между ВМ
- Выполняет обнаружение и удаление физических путей
- Собирает статистику ввода-вывода
NMP в свою очередь также является расширяемым модулем, управляющим двумя наборами плагинов: Storage Array Type Plug-Ins (SATPs), and Path Selection Plug-Ins (PSPs). SATPs и PSPs могут быть встроенными плагинами VMware или разработками сторонних производителей. При необходимости разработчик СХД может создать собственный MPP для использования в дополнение или вместо NMP.
SATP отвечает за восстановление пути посте сбоя (failover): мониторинг состояния физических путей, информирование об изменении их состояния, переключение со сбойного пути на рабочий. NMP предоставляет SATPs для всех возможных моделей массивов, поддерживаемых vSphere, и осуществляет выбор подходящего SATP.
PSP отвечает за выбор физического пути передачи данных. NMP предлагает 3 встроенных варианта PSP: Most Recently Used, Fixed, Round Robin. Основываясь на выбранном для массива SATP, модуль NMP делает выбор варианта PSP по умолчанию. При этом vSphere Web Client дает возможность выбрать вариант PSP вручную.
Принцип работы вариантов PSP:
-
Most Recently Used (MRU) – хост выбирает путь который использовался последним (недавно). Если этот путь становится недоступен, то хост переходит на альтернативный путь. Возврат к первоначальному пути после его восстановления не происходит. Возможность задания предпочитаемого пути отсутствует. MRU – вариант по умолчанию для большинства active-passive массивов.
Delphi site: daily Delphi-news, documentation, articles, review, interview, computer humor.
Выделите виртуальную машину с тонким диском и посмотрите на закладку Summary. Там в разделе Resources вы увидите данные по занимаемому месту (рис. 5.17).
- Provisioned Storage - это максимальный объем, который могут занять файлы виртуальной машины. То есть это номинальный объем ее диска плюс объем всех прочих файлов. Из «прочих файлов» заслуживают упоминаний два. Это файл подкачки (*.vswp), который гипервизор создает для этой ВМ, и файлы vmdk снимков состояния. Так как каждый снимок состояния (snapshot) может занять место, равное номинальному размеру диска, то при каждом снимке состояния величина Provisioned Storage увеличивается на размер диска/дисков;
- Not-shared Storage - сколько места эта виртуальная машина занимает именно под свои файлы, не разделяя их с другими ВМ;
- Used Storage - сколько места реально занимают на хранилище файлы-диски этой ВМ.

Рис. 5.17. Данные по размеру тонкого диска
Not-shared Storage всегда равняется Used Storage, за исключением двух вариантов:
- когда используется функция Linked Clone. Она доступна при использовании поверх vSphere таких продуктов, как VMware Lab Manager или VMware View;
- когда диском ВМ является RDM и у вас кластер между ВМ (например, MSCS/MFC). В таком случае RDM выступает в роли общего хранилища, принадлежит сразу двум ВМ. Not-shared Storage будет показывать остальное место, что ВМ занимает на хранилище, кроме RDM.
Обратите внимание. Provisioned Storage - это ограничение размера файла vmdk. То есть это гипервизор не даст файлу вырасти больше. Однако если на хранилище закончится место, то гипервизор не сможет увеличить thin-диск (или файл снимка состояния), даже если тот не достиг своего максимума. Это приведет к неработоспособности ВМ.

Всем привет сегодня рассмотрим, в чем разница виртуальных дисков у Vmware ESXi 5.5, разберем каждый тип диска и где его лучше применять. Виртуальные машины на платформе VMware vSphere размещаются на хранилищах Fibre Channel, iSCSI, NAS/NFS или локальных дисках серверов ESX. Диски виртуальных машин могут располагаться на томах в файловой системе VMFS (Virtual Machine File System), NFS (Network File System) или на томах RDM (Raw Device Mapping). При этом на томах VMFS и NFS виртуальные диски машин хранятся в формате vmdk, а на томах RDM виртуальная машина хранит свои данные напрямую на LUN. Сегодня мы поговорим о том, в каких форматах могут быть виртуальные диски машин в VMware vSphere, к которым обращаются серверы VMware ESXI 5.x.x
Диски типа Raw
Файловая система VMFS поддерживает схему Raw Device Mapping (RDM), которая представляет собой механизм для прямого доступа виртуальной машины к дисковой подсистеме (конкретному LUN) устройств хранения Fibre Channel или iSCSI. Этот тип виртуального диска доступен для создания из vSphere Client.
Если в сети хранения данных используется ПО для создания мгновенных снимков системами резервного копирования, которые запущены в виртуальных машинах, требуется прямой доступ к дисковой подсистеме устройств хранения. Кроме того Raw-диски используются для кластеров Microsoft Clustering Services (MSCS), включая кластеры типа «виртуальный-виртуальный» и «виртуальный-физический».
Но RDM не используется для повышения производительности - его производительность аналогична дискам vmdk в файловой системе VMFS.
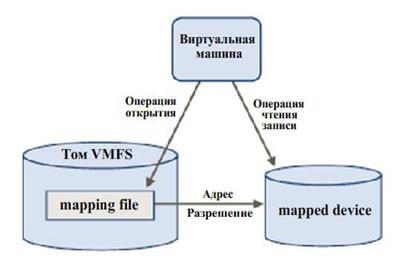
RDM может обеспечиваться путем предоставления символьной ссылки в томе VMFS к разделу Raw (режим виртуальной совместимости). В этом случае файлы маппирования, относящиеся к конфигурации виртуальных машин, отображаются как файлы в томе VMFS в рабочей директории виртуальной машины. Когда том Raw открывается для записи, файловая система VMFS предоставляет доступ к файлу RDM на физическом устройстве и реализует через него механизм блокирования и контроля доступа. После этого операции чтения и записи идут напрямую к тому Raw, минуя файл маппирования.
Файлы RDM содержат метаданные, используемые для управления и перенаправления доступа к физическому устройству. RDM предоставляет возможности прямого доступа к дискам, при этом сохраняются некоторые возможности, присущие файловой системе VMFS. Схема взаимодействия виртуальной машины с устройством хранения посредством механизма RDM изображена на рисунке:
Описание типов виртуальных дисков vmdk виртуальных машин на VMware vSphere ESXI 5.x.x-01
Перед началом операций ввода-вывода виртуальная машина vmware посредством файла маппирования инициирует открытие тома Raw. Далее файловая система VMFS осуществляет разрешение адресов секторов физического устройства, а виртуальная машина начинает производить операции чтения-записи на физическое устройство.
Используя RDM возможно производить следующие операции:
- «горячая» миграция виртуальных машин посредством VMotion на томах Raw;
- добавлять новые тома Raw с помощью VI Client;
- использовать возможности файловых систем, такие как распределенное блокирование файлов, установка разрешений и именование;
Для RDM используются два режима совместимости:
- Режим виртуальной совместимости, который позволяет производить маппирование файлов виртуальных дисков, включая возможности создания мгновенных снимков системы хранения. При таком режиме выбирается том VMFS, на котором будет храниться файл маппирования и том, где находится файл конфигурации виртуальной машины.
- Режим физической совместимости, позволяющий приложениям получать низкоуровневый доступ к SCSI-устройствам, при этом наличие файла маппирования не требуется.
Использование функций VMotion, DRS и HA поддерживаются в обоих режимах совместимости.
Диски типа Thick (толстые диски)
Это тип дисков vmdk на томах VMFS или NFS, размер которых предопределяется заранее (при создании) и не изменяется в процессе наполнения его данными. Давайте добавим для примера новый виртуальный диск.
Никогда без веской необходимости не создавайте IDE диски, так как они не расширяются на лету и без геморроя и медленнее SCSI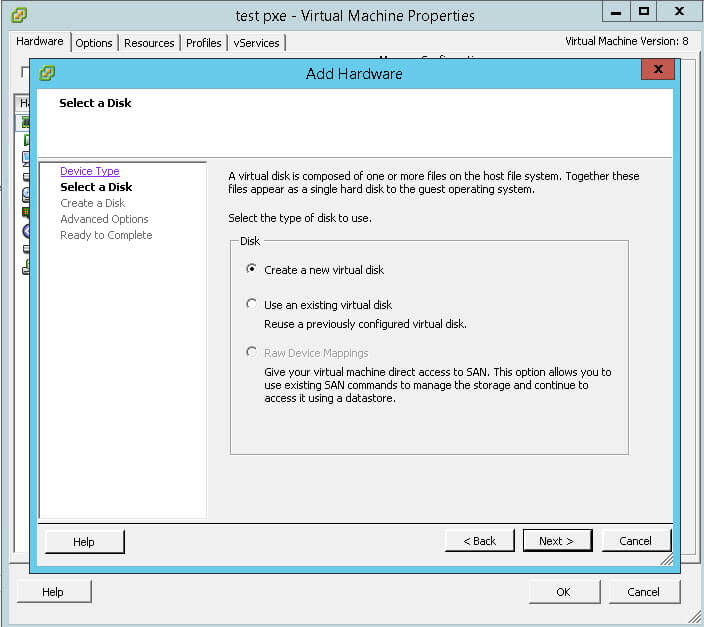
Существует три типа дисков thick:
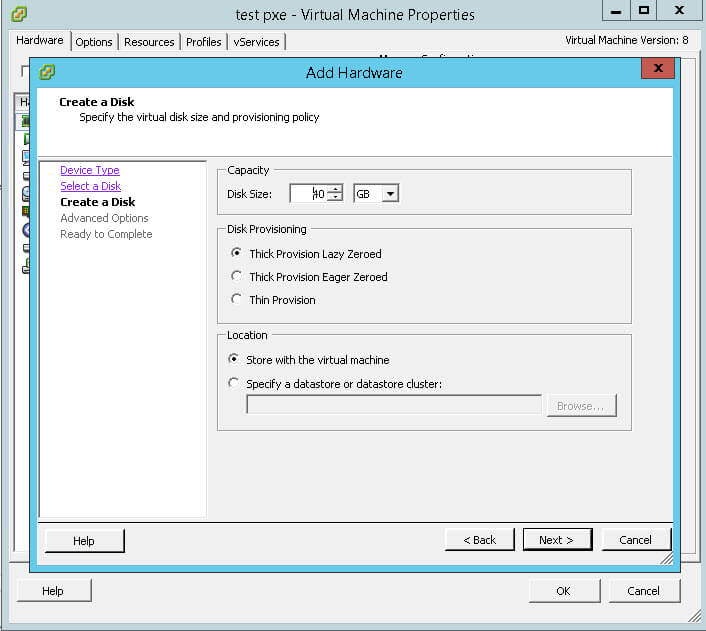
Thick disks
Все пространство диска выделяется в момент создания, при этом блоки не очищаются от данных, которые находились там ранее. Это может создавать потенциальные угрозы безопасности, поскольку виртуальная машина может получить доступ к данным на хранилище VMFS, которые ей не принадлежат. При обращении к блокам такого диска их содержимое предварительно не очищается со стороны ESX. Преимущество дисков типа thick - производительность и быстрота создания, недостаток - безопасность
Zeroed thick disks (lazy zeroed thick disks)
Все пространство такого диска выделяется в момент создания, при этом блоки не очищаются от данных, которые находились там ранее. При первом обращении виртуальной машины к новому блоку происходит его очистка. Таким образом, эти диски более безопасны, однако при первом обращении к блоку - теряется производительность системы ввода-вывода на операцию очистки. При последующих обращениях - производительность идентична дискам типаEager zeroed thick. Этот тип диска создается по умолчанию через VMware vSphere Client для виртуальных машин. Преимущество дисков Zeroed thick disks - безопасность и быстрота создания, недостаток - производительность при первом обращении к блоку.
Eager zeroed thick disks
Все пространство такого диска выделяется в момент создания, при этом блоки очищаются от данных, которые находились там ранее. Далее происходит обычная работа с блоками без очистки. Преимущество такого диска - производительность и безопасность, недостаток - долгое время создания.
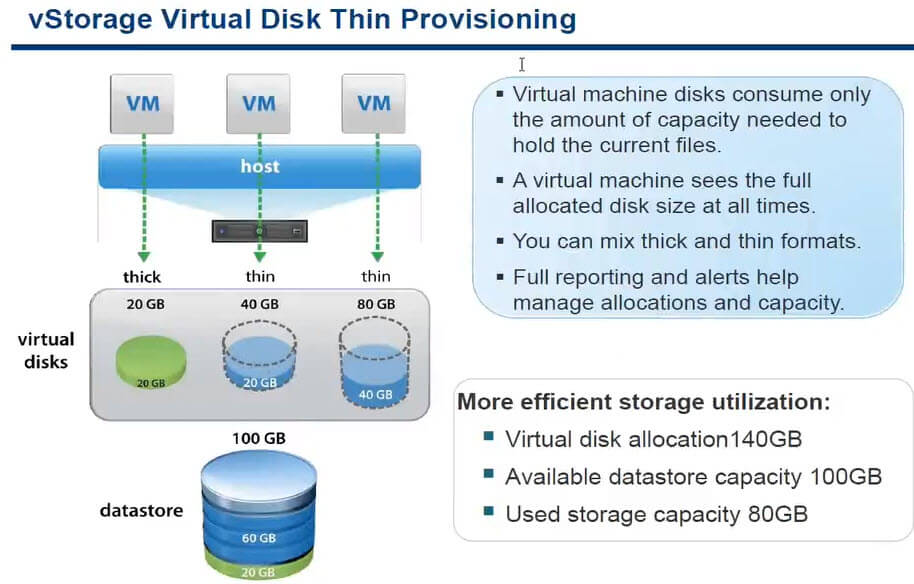
Диски типа Thin (тонкие диски)
Эти диски создаются минимального размера и растут по мере их наполнения данными до выделенного объема. При выделении нового блока - он предварительно очищается. Эти диски наименее производительны (выделение нового блока и его очистка), однако наиболее оптимальны для экономии дискового пространства на системе хранения данных. Чаще всего их используют в тестовых средах и стендах, где нужно по экономить дисковое пространство или же для разработки.
На слайде пример виртуальной машины с тремя дисками общего объема 140 ГБ, а по фату на датасторе используется 80 гб.
Independent, Persistent, Non-Persistent диски
И так теперь у вас есть виртуальная машина, если вы зайдете в ее свойства то сможете обнаружить, что для каждого виртуального диска есть еще дополнительные опции
- Independent
- Persistent
- Non-Persistent
давайте смотреть, что каждый из них означает. Вот такая картинка идет по умолчанию для виртуального диска. Что это подразумевает, а то, что у вас в конфигурации стандартный виртуальный диск, на нем можно делать снапшоты ESXI, это дает возможность делаться дельте диска и данные уже писать в него. Если откатывать снапшот, то вы получите диск на момент снятия.

Independent, Persistent, Non-Persistent диски-01
Если у нас стоит Independent и Persistent. В такой конфигурации это означает, что вы не сможете создать снапшот, так как все изменения сразу пишутся на диск. При попытке его создать вас пошлют с ошибкой Cannot take a memory snapshot, since the virtual machine is configured with independent disks. Некий такой механизм защиты от снапшота,

Independent, Persistent, Non-Persistent диски-02
И последний вариант это Independent > Non-Persistent. Тут тоже не работают снапшоты. Диск необходим вот для чего. Предположим у вас есть какой, то публичный или тестовый стенд, где все что то могут поставить, до этого вы его подготовили в эталонный вид и поставили тип диска Non-Persistent, далее все начинаю херачить и ломать эту машинку, ставить там свой софт и тестить его, в итоге, у вас же нет снапшота, а откатиться хочется, этот тип диска и позволяет это сделать путем обычной перезагрузки. Хороших примеров его использования полно, главный принцип один раз настроили, что то пошло не так ребутнули и все счастливы.



В этой статье мы рассмотрим, как увеличить размер VMFS хранилища с помощью веб интерфейса vSphere Client и из командной строки VMWare ESXi.
При проверке свободного места на VMFS датасторах, вы обнаружили что на одном из них заканчивается свободное место. Вам нужно увеличить размер VMFS хранилища, добавив дополнительное место на СХД.
Сначала нужно увеличить размер LUN на СХД. Как это сделать – зависит от вендора вашей хранилки (если вы используете Microsoft iSCSI, то увеличить размер диска можно через Server Manager -> File and Storage Services -> iSCSI -> выберите диск -> Extend iSCSI Virtual Disk). В нашем примере мы увеличили размер LUN со 100 до 105 Гб.
VMWare ESXi поддерживает два способа расширения VMFS хранилищ – за счет неиспользуемого места на этом же LUN (этот способ мы рассматриваем в статье) или за счет добавление дополнительного LUN-а (способ называется extent). VMFS extent – своеобразный span раздела на несколько LUN. Запись на второй LUN начнется после того, как заполнится первый и т.д.Как увеличить VMFS хранилище из веб-интерфейса VMWare vSphere Client?

- В интерфейсе vSphere Client выберите раздел Storage;
- Щелкните правой кнопкой мыши по датастору и выберите Increase Datastore Capacity;
- Выберите диск (LUN), который надо расширить. Обратите внимание на значение поля Expandable. В нем должно быть указано Yes. Это значит, что данное VMFS хранилище можно расширить;
В некоторых случая расширить VMFS хранилище из графического интерфейса vSphere Client нельзя. Чаще всего проблема связана с невозможностью расширить VMFS хранилище на загрузочном диске. При этом появляется ошибка:

В этом случае придется расширить хранилище из командной строки хоста ESXi.
Расширить VMFS хранилище из командной строки VMWare ESXi

- Подключитесь к хосту ESXi через SSH (можно использовать встроенный SSH клиент Windows)
- Пересканируйте адаптеры хранения: esxcli storage core adapter rescan --all
- Затем нужно определить диск, соответствующий вашему VMFS хранилищу: vmkfstools -P /vmfs/volumes/DCx2VMFS1 . В нашем случае диск выглядит так /vmfs/devices/disks/naa.60003ff44dc75adca68b263bd62e4d1f.:1 означает, что VMFS хранилище расположено на первом разделе диска;
- Проверим таблицу разделов диска: partedUtil get /vmfs/devices/disks/naa.60003ff44dc75adca68b263bd62e4d1f
Как вы видите, вы успешно расширили VMFS хранилище на 5 Гб. Операция выполнялась онлайн без отмонтирования хранилища и без остановки ВМ.
Читайте также: