Proxmox ограничить потребление памяти zfs
Обновлено: 06.07.2024
ZFS (Zettabyte File System) — файловая система, изначально созданная в Sun Microsystems для операционной системы Solaris. Эта файловая система поддерживает большие объёмы данных, объединяет концепции файловой системы и менеджера логических дисков (томов) и физических носителей, новаторскую структуру данных на дисках, легковесные файловые системы (англ. lightweight filesystems), а также простое управление томами хранения данных. ZFS является проектом с открытым исходным кодом и лицензируется под CDDL (Common Development and Distribution License).
Основное преимущество ZFS — это её полный контроль над физическими и логическими носителями. Зная, как именно расположены данные на дисках, ZFS способна обеспечить высокую скорость доступа к ним, контроль их целостности, а также минимизацию фрагментации данных. Это позволяет динамически выделять или освобождать дисковое пространство на одном или более носителях для логической файловой системы. Кроме того, имеет место переменный размер блока, что лучшим образом влияет на производительность, параллельность выполнения операций чтения-записи, а также 64-разрядный механизм использования контрольных сумм, сводящий к минимуму вероятность незаметного разрушения данных.
В Proxmox VE с помощью ZFS можно позволить себе репликацию данных на другой гипервизор, миграцию виртуальной машины/LXC контейнера, доступ к LXC контейнеру с хост-системы и так далее.
1.2. Пулы хранения.
В отличие от традиционных файловых систем, которые располагаются на одном устройстве и, следовательно, при использовании более чем на одном устройстве для них требуется менеджер томов, ZFS строится поверх виртуальных пулов хранения данных, называемых zpool. Пул построен из виртуальных устройств (vdevs), каждое из которых является либо физическим устройством, либо зеркалом (RAID 1) одного или нескольких устройств, либо (RAID Z) — группой из двух или более устройств. Ёмкость всех vdevs затем доступна для всех файловых систем в zpool.
Для ограничения пространства, доступного конкретной файловой системе или тому, может быть установлена квота. Кроме того, возможно использование дискового резервирования (лимита) — это гарантирует, что всегда будет оставаться некоторый доступный объём для конкретной файловой системы или тома.
Каждый пул хранения состоит из одного или нескольких виртуальных устройств (virtual device, vdev). В свою очередь, каждый vdev включает одно или несколько реальных устройств. Большинство виртуальных устройств используются для простого хранения данных, но существует несколько вспомогательных классов vdev, включая CACHE, LOG и SPECIAL. Каждый из этих типов vdev может иметь одну из пяти топологий: единое устройство (single-device), RAIDz1, RAIDz2, RAIDz3 или зеркало (mirror).
RAIDz1, RAIDz2 и RAIDz3 — это особые разновидности того, что назовут RAID двойной (диагональной) чётности. 1, 2 и 3 относятся к тому, сколько блоков чётности выделено для каждой полосы данных. Вместо отдельных дисков для обеспечения чётности виртуальные устройства RAIDz полуравномерно распределяют эту чётность по дискам. Массив RAIDz может потерять столько дисков, сколько у него блоков чётности; если он потеряет ещё один, то выйдет из строя и заберет с собой пул хранения.
В зеркальных виртуальных устройствах (mirror vdev) каждый блок хранится на каждом устройстве в vdev. Хотя наиболее распространённые двойные зеркала (two-wide), в зеркале может быть любое произвольное количество устройств — в больших установках для повышения производительности чтения и отказоустойчивости часто используются тройные. Зеркало vdev может пережить любой сбой, пока продолжает работать хотя бы одно устройство в vdev.
Одиночные vdev по своей сути опасны. Такое виртуальное устройство не переживёт ни одного сбоя — и если используется в качестве хранилища или специального vdev, то его сбой приведёт к уничтожению всего пула. Будьте здесь очень, очень осторожны.
Виртуальные устройства CACHE, LOG и SPECIAL могут быть созданы по любой из вышеперечисленных топологий — но помните, что потеря виртуального устройства SPECIAL означает потерю пула, поэтому настоятельно рекомендуется избыточная топология.
1.3. Встроенное сжатие.
Механизм копирования при записи также упрощает систему встроенного сжатия. В традиционной файловой системы сжатие проблематично — как старая версия, так и новая версия изменённых данных находятся в одном и том же пространстве.
Если рассмотреть фрагмент данных в середине файла, который начинает свою жизнь как мегабайт нулей от 0x00000000 и так далее — его очень легко сжать до одного сектора на диске. Но что произойдёт, если мы заменим этот мегабайт нулей на мегабайт несжимаемых данных, таких как JPEG или псевдослучайный шум? Неожиданно этому мегабайту данных потребуется не один, а 256 секторов по 4 КиБ, а в этом месте на диске зарезервирован только один сектор.
У ZFS нет такой проблемы, так как изменённые записи всегда записываются в неиспользуемое пространство — исходный блок занимает только один сектор 4 КиБ, а новая запись займёт 256, но это не проблема — недавно изменённый фрагмент из «середины» файла был бы записан в неиспользуемое пространство независимо от того, изменился его размер или нет, поэтому для ZFS это вполне штатная ситуация.
Встроенное сжатие ZFS отключено по умолчанию, и система предлагает подключаемые алгоритмы — сейчас среди них LZ4, gzip (1-9), LZJB и ZLE.
- LZ4 — это потоковый алгоритм, предлагающий чрезвычайно быстрое сжатие и декомпрессию и выигрыш в производительности для большинства случаев использования — даже на довольно медленных CPU.
- GZIP — почтенный алгоритм, который знают и любят все пользователи Linux-систем. Он может быть реализован с уровнями сжатия 1-9, с увеличением степени сжатия и использования CPU по мере приближения к уровню 9. Алгоритм хорошо подходит для всех текстовых (или других чрезвычайно сжимаемых) вариантов использования, но в противном случае часто вызывает проблемы c CPU — используйте его с осторожностью, особенно на более высоких уровнях.
- LZJB — оригинальный алгоритм в ZFS. Он устарел и больше не должен использоваться, LZ4 превосходит его по всем показателям.
- ZLE — кодировка нулевого уровня, Zero Level Encoding. Она вообще не трогает нормальные данные, но сжимает большие последовательности нулей. Полезно для полностью несжимаемых наборов данных (например, JPEG, MP4 или других уже сжатых форматов), так как он игнорирует несжимаемые данные, но сжимает неиспользуемое пространство в итоговых записях.
Рекомендуется сжатие LZ4 практически для всех вариантов использования. Штраф за производительность при встрече с несжимаемыми данными очень мал, а прирост производительности для типичных данных значителен. Копирование образа виртуальной машины для новой инсталляции операционной системы Windows (свежеустановленная операционная система, никаких данных внутри ещё нет) с compression=lz4 прошло на 27% быстрее, чем с compression=none .
1.4. Секторы.
Последний, самый базовый строительный блок — сектор. Это наименьшая физическая единица, которая может быть записана или считана с базового устройства. В течение нескольких десятилетий в большинстве дисков использовались секторы по 512 байт. В последнее время большинство дисков настроено на сектора 4 КиБ, а в некоторых — особенно SSD — сектора 8 КиБ или даже больше.
В системе ZFS есть свойство, которое позволяет вручную установить размер сектора. Это свойство ashift. Несколько запутанно, что ashift является степенью двойки. Например, ashift=9 означает размер сектора 2^9, или 512 байт.
ZFS запрашивает у операционной системы подробную информацию о каждом блочном устройстве, когда оно добавляется в новый vdev, и теоретически автоматически устанавливает ashift должным образом на основе этой информации. К сожалению, многие диски лгут о своём размере сектора, чтобы сохранить совместимость с Windows XP (которая была неспособна понять диски с другими размерами секторов).
Это означает, что администратору ZFS настоятельно рекомендуется знать фактический размер сектора своих устройств и вручную устанавливать ashift. Если установлен слишком маленький ashift, то астрономически увеличивается количество операций чтения/записи. Так, запись 512-байтовых «секторов» в реальный сектор 4 КиБ означает необходимость записать первый «сектор», затем прочитать сектор 4 КиБ, изменить его со вторым 512-байтовым «сектором», записать его обратно в новый сектор 4 КиБ и так далее для каждой записи.
В реальном мире такой штраф бьёт по твёрдотельным накопителям Samsung EVO, для которых должен действовать ashift=13 , но эти SSD врут о своём размере сектора, и поэтому по умолчанию устанавливается ashift=9 . Если опытный системный администратор не изменит этот параметр, то этот SSD работает медленнее обычного магнитного HDD.
Для сравнения, за слишком большой размер ashift нет практически никакого штрафа. Реального снижения производительности нет, а увеличение неиспользуемого пространства бесконечно мало (или равно нулю при включённом сжатии). Поэтому мы настоятельно рекомендуем даже тем дискам, которые действительно используют 512-байтовые секторы, установить ashift=12 или даже ashift=13 , чтобы уверенно смотреть в будущее.
Внимание! Свойство ashift устанавливается для каждого виртуального устройства vdev, а не для пула, как многие ошибочно думают — и не изменяется после установки. Если вы случайно сбили ashift при добавлении нового vdev в пул, то вы безвозвратно загрязнили этот пул устройством с низкой производительностью и, как правило, нет другого выхода, кроме как уничтожить пул и начать всё сначала. Даже удаление vdev не спасёт от сбитой настройки ashift!
2. Подключаем диск в системе.
Подключаем физический диск к серверу и смотрим появился ли он в системе. Просто выполните действия в web-интерфейсе гипервизора Proxmox VE.
Инициализируем диск в GPT разметке диска.

Если всё хорошо, то преобразование может начаться сразу:

А может не начаться и выдать выдать ошибку:


Затем снова переходим в меню преобразования диска в GPT и операция завершается успешно.

3. Добавление нового хранилища.
Добавляем новое хранилище в web-панели управления Proxmox VE.
Переходим в web-интерфейс панели управления Proxmox VE, Выбираем сервер виртуальных машин и раздел «Диски» — «ZFS»:

Готово! ZFS в строю.

Теперь мы можем использовать хранилище для размещения виртуальных машин и контейнеров.
4. Удаление хранилища.
Удаление производится простым способом. Паркуем все виртуальные машины, которые используют данное хранилище, размонтируем хранилище и удалим его.
Внимание! Удаление не предусматривает запроса на подтверждение. Имейте в виду. Удаляется сразу.
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Loading
Copy raw contents
Copy raw contents
Внимание! Данная тема регулярно служит источником холиваров и граблей! Рекомендуется читать до конца перед применением!
Зачем вот это вот все
Postgres (ванильный), в отличие от MS SQL, не умеет сжатие данных.
Зато сжатие отлично умеет zfs, файловая система и по совместительству менеджер хранилищ.
TODO: COW - кратко плюсы и минусы
Аналоги: btrfs, почему все же не она.
Большое сравнение файловых систем смотрим здесь.
Что не так с zfs
Как считают многие linux-разработчики и ментейнеры дистрибутивов, "проект мог бы быть прекрасен и мог бы претендовать на роль лучшей ФС будущего", но имеет несовместимую с ядром linux лицензиюю. В общем, лицензионные перипетии ужасно изговняли всю эту историю, и это очень-очень печально (за подробностями - в google). Несмотря на это, debian, ubuntu, arch, suse и другие дистрибутивы не только поддерживают zfs, но и имеют воможность установки системы на zfs. Если хочется zfs прям из коробки, например для создания обособленного хранилища, имеет смысл посмотреть в сторону freebsd. Небольшой курьез - в виду очень бодрого развития проекта zfs-on-linux freebsd планирует пересесть на него (upd: пересел)
Важно! Неоптимальная конфигурация пула zfs может снизить быстродействие на порядок!
Чтобы понять, насколько велика может быть разница, имеет смысл сделать хотя бы сферические замеры на ext4, а затем повторить их на zfs. Самый простой, хоть и не самый лучший, способ - создать раздел ext4 и выполнить dd с разным размером блока. Предположим у нас есть диск /dev/sdb, на который мы планируем положить zfs.
Для начала форматируем его в ext4:
TODO: такой замер оказался ни о чем, сделать отсюда
Результаты записываем и после создания тома zfs тесты повторяем. Практически все параметры томов zfs можно менять на лету: очень рекомендую попробовать поставить recordsize равным 4, 8, 16, 32, 64, 128k и сравнить результаты замеров. Так, при блоке 128k скорость записи примерно уравнивается с показателями ext4. Задрежки, конечно, при таких условиях будут несколько больше.
Также можно сравнить производительность без сжатия, ну и сдругими параметрами поиграть.
Кратко общие рекомендации в интернетах: если надо писать большие файлы, либо писать много потоком - ставим 128k, много мелких файлов или сильно непоследовательно - в районе 4-16k. Оптимальное значение подбираем опытным путем.
Рекомендации в интернетах для postgresql: имеет смысл ставить размер записи равным (или большим) размеру блока, записываемого СУБД, в случае postgresql это 8k.
Рекомендации от сердца, выстраданные в результате долгих экспериментов и последующих наблюдений в проде:
- Ставить 128k и не париться. Оно так по-умолчанию и стоит, к слову ;)
- Сжатие lz4 обязательно, ибо по факту одни плюсы в выхлопе, минусов ни одного найти не удалось
- Использовать zfs на гипервизоре для размещения виртуалок, в виртуалках использовать ext4
- Избегать "вложенности" в случае виртуальных машин, когда zfs на гипервизоре и zfs в виртуалке
- Для БД идеальной получилась схема с размещением на гипервизоре proxmox в lxc-контейнере, контейнер размещен на zfs - быстродействие сопоставимо с работой на хосте в пределах погрешностей
sync: Про sync настоятельно рекомендую все изучить и взвесить самостоятельно. Если кратко, то в случае внезапно краха системы ФС останется абсолютно живой и здоровой (хвала COW), но будет потеряно до 30 секунд работы (как правило 2-5, получено путем примерно 100 экспериментов с жестким отключением питания на обычном ПК). В случае БД теоретически можно получить несогласованные записи (например документ есть, а движений нет), но на практике еще я лично не сталкивался. Лично я для себя принял решение ставить sync=disabled.
Ну и напоследок про бэкапы. Ну их ведь все и всегда регулярно делают и проверяют, да? Мы вот еще и реплики всех виртуалок и контейнеров держим, для особо важных данных - еще и не по одной, благо дисковое пространство сегодня дешево.
Установка и создание пула
Создание пула для postgresql:
"/dev/" - здесь может быть диск или раздел диска (посмотреть, что есть: ls /dev/sd*), или просто каталог в случае тестов, например
/zfstst.
Если пул создется на hdd, и есть немного места на ssd, можно на ssd создать раздел и включить его в пул в качестве кэша:
Устанавливаем и сразу проверяем параметры:
Ограничение потребления памяти
Создаем /etc/modprobe.d/zfs.conf, в него записываем:
Отключение "умного" кэширования (только при необходимости, например на хосте proxmox):
Затем обновляем initramfs:
Чтобы не ждать перезагрузку, можно менять параметры на лету. Например:
Параметры: cat /sys/module/zfs/parameters/PARAMETER
Статистика ARC: cat /proc/spl/kstat/zfs/arcstats
iostat: zpool iostat -v
Создание тонких копий
Предположим нужна копия сервера БД для разработчика.
Создаем новый контейнер с диском минимального размера, затем удаляем диск и вместо него создаем клон с продуктивного сервера БД.
Чтобы не размещать копии на продуктивном сервере, имеет смысл настроить реплику датасета на сервер разработки и делать клоны с нее.
Предположим, что продуктивный сервер БД размещен в контейнере (или виртуалке) с id 103, нужно сделать клон в контейнер с id 108:
Я хочу построить небольшой домашний сервер виртуализации на базе ProxMox. Требования к подсистеме хранения такие:
дедупликация при небольшом потреблении памяти. не обязательно inline, можно просто по расписанию. ZFS - все круто (“искаропки” есть кеширование, дедупликация и сжатие). Однако, дедупликация требует очень много памяти (>5GB на 1Tb данных). А также на производительность влияет неотключаемый Copy-On-Write. ext3/4 over LVM - быстрая и стабильная. можно сделать кеширование на SSD. Нет дедупликации. Нет сжатия. BTRFS over LVM - можно сделать кеширование на SSD. Есть дедупликация по запросу. Есть сжатие. Можно отключить Copy-On-Write (но тогда отключится сжатие). Virtual Data Optimizer - VDO суперштука. Модуль ядра, который реализует inline-дедупликацию и сжатие для томов LVM. Пока что доступен только в RedHat и непонятно что со стабильностью/производительностью/ресурсами.Выбор пал на связку BTRFS over LVM. Она позволяет дедуплицировать данные по расписанию (с помощью duperemove), кешировать данные на SSD с помощью lvmcache.
Файлы образов дисков должны быть в формате qcow2, что позволит делать снепшоты.
Файловые системы контейнеров LXC можно хранить как в виде образов, так и просто в папках на BTRFS. Последний вариант будет скорее всего быстрее (вследствие отсутствия loop-устройства), позволит дедуплицировать и\или сжимать файлы контейнеров средствами BTRFS.
Забегая вперед, скажу, что SSD кеш делает виртуальные машины ГОРАЗДО отзывчивее. Даже в условиях нехватки оперативной памяти.
ВНИМАНИЕ.
Всем, кто решит использовать BTRFS + lvmcache на хосте ProxMox нужно помнить следующее:
lvmcache НЕ совместим с различными вариантами hibernate. Если вы попытаетесь выполнить pm-hibernate на хосте кешированными томами, то никакого hibernate не произойдет. Система просто перезагрузится, а данные на дисках будут повреждены. Я пробывал. использование BTRFS с флагом nodatacow (то есть отключение Copy-On-Write) наверное, немного поднимет производительность, но взамен сделает и без того не самую надежную файловую систему абсолютно неремонтопригодной. Отключится весь функционал, обеспечивающий надежность хранения (CoW и контрольные суммы). В результате, при повреждения файловой системы даже btrfs check использовать не получится (по причине отсутствия ctree).Создание кешированного тома LVM
Пример конфигурации такой. два диска - /dev/vdb (SSD) и /dev/vdc (HDD). Создаем физичесике тома и группу томов test:
Создаем том с кешем на SSD:
Создаем том с данными:
И теперь собираем конструкцию:
Отсоединить кеш от тома можно командой:
Состояние тома можно поглядеть командой:
Тип кеша можно поменять командами:
Создание хранилища Proxmox
Для начала надо смонтировать том с параметрами noatime,nodiratime
Тестирование FIO
То есть тест блоками по 4k, случайные чтение и запись, глубина очереди 32, размер тестового файла - 1Gb, без кеширования на уровне Windows (direct=1).
Тесты запускались по три раза, чтобы тестовый файл попал в SSD-кеш.
| LVM Cache/PM Cache/Format | Read, MiB/s | Write MiB/s | Read IOPS avg, k | Write IOPS avg, k | CPU Read, % | CPU Write, % |
|---|---|---|---|---|---|---|
| WB/NC/qcow2 | 133 | 100 | 34.0 | 25.6 | 26 | 0 |
| WB/NC/raw | 127 | 104 | 32.5 | 26,6 | 25 | 0 |
| WB/WB/qcow2 | 158 | 107 | 40.5 | 27,4 | 0 | 0 |
| WB/WT/qcow2 | 166 | 5.3 | 42.6 | 1.324 | 0 | 4 |
| WB/WT/raw | 154 | 5.47 | 39.5 | 1.335 | 0 | 3.5 |
| WB/WB/raw | 150 | 118 | 38.3 | 30.1 | 0 | 23 |
| WT/WT/qcow2 | 213 | 0.046 | 54.5 | 0.011 | 21 | 0 |
| WT/WB/qcow2 | 159 | 9.5 | 40.8 | 2.37 | 0 | 0.9 |
| WT/NC/qcow2 | 128 | 0.612 | 32.8 | 0.152 | 12.5 | 0 |
| WT/NC/raw | 121 | 0.832 | 30.9 | 0.208 | 0 | 0 |
| WT/WT/raw | 288 | 0.041 | 73.7 | 0.010 | 56 | 0 |
| WT/WB/raw | 137 | 16.8 | 35.1 | 4.303 | 0 | 3.3 |
| NC/WB/raw | 146 | 4.4 | 37.3 | 1.099 | 0 | 0.4 |
| NC/WT/raw | 148 | 0.0476 | 37.8 | 0.011 | 0 | 0 |
| NC/NC/raw | 1.766 | 0.694 | 0.441 | 0.173 | 0 | 0.33 |
| NC/NC/qcow2 | 1.830 | 0.244 | 0.457 | 0.061 | 0.86 | 0 |
| NC/WT/qcow2 | 1.7 | 0.0465 | 0.449 | 0.011 | 0 | 0 |
| NC/WB/qcow2 | 3.578 | 4.889 | 0.894 | 1.222 | 0 | 0.47 |
Результаты тестирования fio
Предсказуемо, стабильно высокие результаты при минимальной загрузке VCPU показал вариант, когда включено кеширование на LVM и Proxmox в режимах WriteBack. Его недостатком можно считать вероятность потери данных при выходе из строя SSD или отключении питания. Не сильно отстает конфигурация с кешированием только на SSD в режиме WriteBack. От выхода из строя SSD можно защититься, использовав два накопителя в зеркальном массиве. Разница между форматами qcow2 и raw несущественна, при большей функциональности qcow2. В режимах Writeback на уровне proxmox без кеширования на SSD на уровне lvm, скорость записи очень нестабильна. Она может быть как довольно высокой (3000-4000 IOPS), так и довольно низкой (500-1000 IOPS) и меняется произвольным образом. Режимы кеширования ProxMox WriteThrough - существенно ускоряют чтение (в 100 раз), но замедляют запись (в 5-20 раз) по сравнению с режимами без кеширования и writeback.Тестирование с помощью CrystalDiskMark 6.0.2 x64
Тестирование производилось на VM - Windows Server 2008 R2, 4GB mem, 2 cores. Для тестирования виртуальной машине добавлен отдельный пустой диск 32Gb.
В качестве SSD cache выступал том LVM на SATA диске OCZ Vertex V2 EX.
Тест в Crystal Mark запускался по 3 раза, чтобы данные успевали закешироваться. В таблице приведены данные после третьего замера.
Параметры CrystalMark - 5, 1GiB.
Boot Time - время загрузки ОС от включения до появления приглашения Press Ctrl+Alt+Del.
1 - lvm cache - On WriteBack, proxmox cache - no cache, qcow2
2 - lvm cache - On WriteBack, proxmox cache - no cache, raw
3 - lvm cache - On WriteBack, proxmox cache - WriteBack, qcow2 . WARNING - Very High CPU Load while tests. Very Long test.
4 - lvm cache - On WriteBack, proxmox cache - WriteThrough, qcow2 WARNING - Very High CPU Load while tests. Very Long test.
5 - lvm cache - On WriteBack, proxmox cache - WriteThrough, raw WARNING - Very High CPU Load while tests. Very Long test.
6 - lvm cache - On WriteBack, proxmox cache - WriteBack, raw . WARNING - Very High CPU Load while tests. Very Long test.
Не вполне стандартные задачи, с которыми мне приходится сталкиваться по работе и способы их решения.
вторник, 5 ноября 2019 г.
Руководство администратора Proxmox VE R 6.0 Глава 4.
Гиперконвергентная инфраструктура
Преимущества гиперконвергентной инфраструктуры (HCI) с Proxmox VE
Управление службами Ceph на узлах Proxmox VE

Proxmox VE объединяет ваши вычислительные системы и системы хранения, т.е. вы можете использовать одни и те же физические узлы в кластере как для вычислений (обработка виртуальных машин и контейнеров), так и для реплицированного хранилища. Традиционные хранилища вычислительных и запоминающих ресурсов могут быть объединены в одно гиперконвергентное устройство. Отдельные сети хранения (SANs) и подключения через сетевые хранилища (NAS) исчезают. Благодаря интеграции Ceph, программной платформы хранения с открытым исходным кодом, Proxmox VE имеет возможность запускать и управлять хранилищем Ceph непосредственно на узлах гипервизора.
Ceph - это распределенное хранилище объектов и файловая система, предназначенная для обеспечения отличной производительности, надежности и масштабируемости.
- Простая настройка и управление с поддержкой CLI и GUI
- Тонкая настройка
- Поддержка снапшотов
- Самовосстановление
- Масштабируемость до уровня эксабайт
- Настройка пулов с различными характеристиками производительности и резервирования
- Данные реплицируются, что делает их отказоустойчивыми
- Работает на бюджетном оборудовании
- Нет необходимости в аппаратных RAID контроллерах
- Открытый исходный код
- Ceph Monitor (ceph-mon)
- Ceph Manager (ceph-mgr)
- Ceph OSD (ceph-osd; Object Storage Daemon)
Предварительное условие
Для построения гиперконвергентного кластера Proxmox + Ceph должно быть как минимум три (желательно) одинаковых сервера для установки.
Проверьте также рекомендации с веб-сайта Ceph.
CPU
Более высокая частота ядра процессора уменьшает задержки и является предпочтительной. В качестве простого практического правила вы должны назначить ядро (или поток) процессора каждому сервису Ceph, чтобы обеспечить достаточно ресурсов для стабильной и надежной работы Ceph.
Память
Особенно в гиперконвергентной установке, потребление памяти необходимо тщательно контролировать. В дополнение к предполагаемой рабочей нагрузке от виртуальных машин и контейнера, Ceph требуется достаточно памяти, чтобы обеспечить хорошую и стабильную производительность. Как правило, для примерно 1 TiB данных, 1 GiB памяти будет использоваться OSD. Кэширование OSD будет использовать дополнительную память.
Сеть
Мы рекомендуем пропускную способность сети, которая используется исключительно для Ceph не менее 10 GbE или более. Ячеистая топология сети 2 также является выходом, если нет доступных коммутаторов 10 GbE. Объем трафика, особенно во время восстановления, будет мешать другим службам в той же сети и может даже разрушить стек кластера Proxmox VE. Кроме того, оцените свои потребности в пропускной способности. В то время как один жесткий диск может не насыщать канал 1 Гб, несколько жестких дисков на узле могут, а современные накопители SSD NVMe даже быстро насыщают пропускную способность 10 Gbps. Развертывание сети, способной к еще большей пропускной способности, гарантирует, что это не ваше узкое место и не будет в ближайшее время, возможно 25, 40 или даже 100 Gbps.
Диски
При планировании размера кластера Ceph важно учитывать время восстановления. Особенно с небольшими кластерами, восстановление может занять много времени. Рекомендуется использовать твердотельные накопители вместо жестких дисков в небольших установках, чтобы сократить время восстановления, минимизируя вероятность последующего сбоя во время восстановления.
В целом SSD накопители обеспечивают больше операций ввода-вывода, чем вращающиеся диски. Этот факт и более высокая стоимость могут сделать привлекательным разделение пулов на основе классов устройств (см раздел 4.2.9). Другая возможность ускорить OSD - использовать более быстрый диск для журнала или DB/Write-Ahead-Log устройства (см. раздел Ceph OSD.) Если для нескольких операционных систем используется более быстрый диск, необходимо выбрать правильный баланс между OSD и Wal/DB (или журнальным) диском, в противном случае более быстрый диск становится узким местом для всех связанных операционных систем. Помимо типа диска, Ceph лучше всего работает с равномерным распределением размеров и количества дисков на узел. Например, 4 х 500 ГБ дисков с в каждом узле лучше, чем смешанная установка с одним 1 ТБ и три 250 ГБ диска.
Также необходимо сбалансировать количество OSD и емкость одного OSD. Большая емкость позволяет увеличить плотность хранения, но это также означает, что сбой одного OSD сразу заставляет ceph восстанавливать большее количество данных.
Отказ от RAID
Поскольку Ceph самостоятельно обрабатывает избыточность объектов данных и распаралеливание операций записи на диски (OSD) , использование RAID - контроллера обычно не улучшает производительность или доступность. Напротив, Ceph предназначен для работы напрямую с дисками самостоятельно, без какой-либо абстракции между ними. RAID - контроллеры не предназначены для использования Ceph и могут усложнять ситуацию, а иногда даже снижать производительность, так как их алгоритмы записи и кэширования могут мешать работе Ceph.
Начальная установка и настройка Ceph

С Proxmox VE вы можете воспользоваться простым в использовании мастером установки Ceph. Щелкните на одном из узлов кластера и перейдите к разделу Ceph в дереве меню. Если пакет еще не установлен, вам будет предложено сделать это сейчас.
Мастер разделен на различные разделы, каждый из них должен быть успешно завершен, чтобы использовать Ceph. После запуска установки мастер загрузит и установит все необходимые пакеты из репозитория Ceph Proxmox VE.
После завершения первого шага, вам нужно будет создать конфигурацию. Этот шаг необходим только один раз для каждого кластера, поскольку эта конфигурация автоматически распространяется среди всех остальных узлов кластера через файловую систему конфигурации кластера Proxmox VE (pmxcfs), глава 7.
- Публичная сеть: Вы должны настроить выделенную сеть для Ceph, этот параметр является обязательным. Отделение вашего трафика Ceph настоятельно рекомендуется, потому что это может привести к проблемам с другими зависимыми от задержки службами, например, взаимодействие узлов кластера может снизить производительность Ceph, если этого не сделано.
- Сеть кластера: В качестве дополнительного шага вы можете пойти еще дальше и отделить трафик репликации разделов OSD (см. 4.2.7) и heartbeat трафик. Это облегчит работу общедоступной сети и может привести к значительному повышению производительности, особенно в больших кластерах.
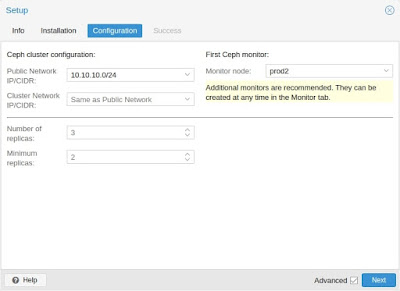
У вас есть еще два варианта, которые считаются расширенными и поэтому должны изменяться только в том случае, если вы являетесь экспертом.
- Количество реплик: Определяет частоту репликации объекта.
- Минимальное количество реплик: Определяет минимальное количество требуемых реплик для I/O, помеченных как завершенные.
Установка пакетов Ceph
Создание начальной конфигурации Ceph

Создание Ceph мониторов
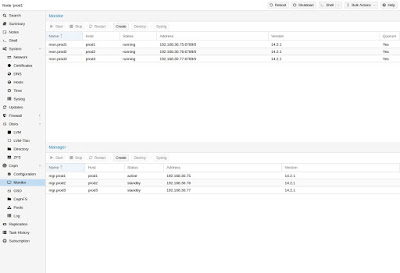
Ceph Monitor (MON) 3 поддерживает главную копию карты кластера. Для высокой доступности необходимо иметь не менее 3 мониторов. Один монитор уже был установлен, если вы использовали мастер установки. Вам не понадобится более 3 мониторов, пока ваш кластер мал до среднего размера, только действительно большие кластеры требуют большего количества.
Создание Ceph Manager
Создание Ceph OSD
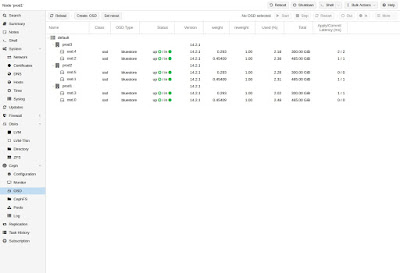
Используя GUI или с помощью коммандной строки следующим образом: Совет Мы рекомендуем размер кластера Ceph, начиная с 12 OSD, равномерно распределенных между вашими, по крайней мере, тремя узлами (4 OSD на каждом узле). Если диск использовался ранее (например, ZFS/RAID/OSD), для удаления таблицы разделов, загрузочного сектора и всех оставшихся OSD должна быть достаточно следующей команды. Внимание! Приведенная выше команда уничтожит данные на диске! Ceph Bluestore
Начиная с выпуска Ceph Kraken, был представлен новый тип хранилища ceph OSD, так называемый Bluestore 5 . Это значение по умолчанию при создании OSD начиная с Ceph Luminous.
Block.db и block.wal
- bluestore_block__size from ceph configuration.
- . database, section osd
- . database, section global
- . file, section osd
- . file, section global
Создание Ceph Пулов
![]()
Пул-это логическая группа для хранения объектов. Он содержит группы размещения (PG, pg_num), набор объектов.
Если параметры не заданы, используется значение по умолчанию 128PG, size 3 реплики и min_size 2 реплики для обслуживания объектов в случае деградации пула. Примечание Количество PG по умолчанию подходит для 2-5 дисков. Ceph выдает предупреждение HEALTH_WARNING, если у вас слишком мало или слишком много PG в вашем кластере. Рекомендуется рассчитать число PG в зависимости от ваших настроек, в интернете вы можете найти формулу и онлайн PG калькулятор 6 . Количество PG может быть увеличено позже, но оно никогда не может быть уменьшено.
Ceph CRUSH и классы устройств
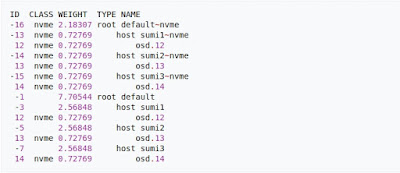
Фундамент Ceph - это его алгоритм "Controlled Replication Under Scalable Hashing" (CRUSH 8 ).
Классы устройств можно увидеть в выходных данных ceph osd tree. Эти классы представляют свои собственные корневые сегменты, которые можно увидеть с помощью приведенной ниже команды. Пример вывода формы приведенной выше команды:
![]()
Ceph Client
![]()
Затем можно настроить Proxmox VE для использования таких пулов для хранения образов виртуальных машин или контейнеров. Просто используйте графический интерфейс, чтобы добавить новое хранилище RBD (см. раздел Ceph RADOS Block Devices (RBD) раздел 8.14).
CephFS
Ceph также предоставляет файловую систему, работающую поверх того же хранилища объектов, что и блочные устройства RADOS. Сервер метаданных (MDS) используется для сопоставления объектов, поддерживаемых RADOS, с файлами и каталогами, что позволяет обеспечить реплицированную файловую систему, совместимую с POSIX. Это позволяет иметь кластерную высокодоступную общую файловую систему простым способом (если ceph уже настроен). Его серверы метаданных гарантируют, что файлы будут равномерно распределены по всему кластеру Ceph, таким образом, что даже высокая нагрузка не будет перегружать один хост, что может быть проблемой при использовании общих файловых систем с традиционным подходом, например таких, как NFS.![]()
Proxmox VE поддерживает оба варианта, используя существующую CephFS в качестве хранилища (см. раздел 8.15) для сохранения резервных копий, ISO-файлов или шаблонов контейнеров и создавая гиперконвергентную CephFS.
Сервер метаданных (MDS)
Для функционирования CephFS необходим как минимум один сервер метаданных, который должен быть настроен и запущен. Можно просто создать его через узел Proxmox VE web GUI -> панель CephFS или в командной строке с помощью: В кластере можно создать несколько серверов метаданных. Но с настройками по умолчанию только один единовременно может быть активным. Если MDS или его узел перестает отвечать на запросы (или аварийно завершает работу), другой резервный MDS будет активирован. Можно ускорить передачу обслуживания между активным и резервным MDS помощью опции hotstandby при создании MDS, или если вы его уже создали его, вы можете установить/добавить: в соответствующем разделе MDS файла ceph.conf . Если этот параметр включен, этот конкретный MDS всегда будет опрашивать активный, так что он сможет приступить к обслуживанию быстрее, поскольку он находится в готовом к обслуживанию состоянии. Но, естественно, регулярный опрос вызовет некоторую дополнительную нагрузку на вашу систему и активный MDS.
Несколько активных MDS
Начиная с Ceph Luminous (12.2.x), вы также можете использовать несколько активных серверов метаданных, но это обычно полезно только для большого количества параллельных клиентов, так как в противном случае MDS редко является узким местом. Если вы все же хотите настроить их, пожалуйста, обратитесь к документации ceph 9 .
CephFS интегрирована в Proxmox VE и вы можете легко создавать CephFS через веб-интерфейс, интерфейс командной строки или внешний API. Для этого требуются некоторые предварительные условия:
- Установка пакетов Ceph (см. раздел 4.2.3), если это уже было сделано некоторое время назад, вы можете повторно запустить его в обновленной системе, чтобы убедиться, что также установлены все пакеты, связанные с CephFS.
- Установлены Мониторы. (см. Раздел 4.2.5)
- Настроены ваши OSD. (см. Раздел 4.2.7)
- Настроен хотябы один MDS. (см. Раздел 4.2.11)
Внимание! Уничтожение CephFS сделает все его данные непригодными для использования, и может быть отменено! Если вы действительно хотите уничтожить существующий CephFS, вам сначала нужно остановить или уничтожить все сервера метаданных (MDS). Вы можете уничтожить их либо через веб-интерфейс или интерфейс командной строки, с помощью: на каждом узле Proxmox VE, где размещается демон MDS.
Ceph Мониторинг и устранение неполадок
Хорошей практикой является непрерывный мониторинг работоспособности ceph с самого начала развертывания. Как через набор инструментов самого ceph, так и путем доступа к его статусу через API Proxmox VE.
Нижеследующие команды ceph могут использоваться, чтобы увидеть, является ли кластер исправным (HEALTH_OK), есть ли предупреждения (HEALTH_WARN), или ошибки (HEALTH_ERR). Если кластер находится в нерабочем состоянии, нижеприведенные команды состояния также дадут вам обзор текущих событий и действий.
Cluster
SR-IOV
P.s. Можно загрузиться в ILO с Live CD того же Linux Mint 19.x , запустить терминал, перейти в учетку root (sudo passwd root -> два раза пароль -> su - -> пароль root) и проделать рабочую процедуру, к-ая описана выше (заменить xenial на bionic в настройках репозитория, ес-но).
![0_1549192679088_sr-iov_scheme.jpg]()
P.s. Напр., Asrock AB350 Pro4 при своей достачно скромной цене (в кач-ве мат. платы для сервера) умеет и amd_iommu и sr-iov - осталось только сетевую прикупить. Более того, совсем бюджетные Biostar A320MD PRO\A320MH PRO также умееют и amd_iommu и sr-iov.
Zettabyte File System (ZFS)
- Создать новую VM с размером hdd равным размеру клонируемой. Не запускать VM.
- Выполнить:
![3_1527667444052_ZFS.jpg]()
![0_1527667444051_Data integrity on ZFS.jpg]()
SCT Error Recovery Control
andy/blog/2015/11/09/linux-software-raid-and-drive-timeouts/
Т.е. если вы собираете zfs raid-z1*2**3* массив, то вкл. вышеописанного поможет сократить время для восстановления,
если же собираетесь использовать zfs raid-0*1**10*, то вкл. не нужно.Open vSwitch (OVS)
Open vSwitch — программный многоуровневый коммутатор с открытым исходным текстом, предназначенный для работы в гипервизорах и на компьютерах с виртуальными машинами.
Основные возможности коммутатора:
Учёт трафика, в том числе проходящего между виртуальными машинами с использованием SPAN/RSPAN, sFlow[en] и Netflow.
Поддержка VLAN (IEEE 802.1q).
Привязка к конкретным физическим интерфейсам и балансировка нагрузки по исходящим MAC-адресам.
Работа на уровне ядра, поддержка существующих возможностей Linux по работе в качестве моста.
Поддерживает Openflow для управления логикой коммутации.
Помимо режима на уровне ядра, с меньшей производительностью open vSwitch может работать и с правами пользователя (вне ядра).Основные области применения:
Замена обычных bridgetools.
Использование в составе Xen Server, Xen Cloud Platform, KVM, VirtualBox, QEMU, ProxMox (начиная с 2.3)
QoS, GRE-туннелирование, индивидуальные политики для виртуальных машин, а также возможность агрегации портов с распределением нагрузки.--> Использование Open vSwitch в Proxmox:
Pfsense
Нюансы работы pfsense в Proxmox:
I've got a fresh install of 2.3.3-RELEASE-p1 (amd64), running on ovirt (kvm). My guests (only have linux guests) could ping out, but no udp or tcp.
Just selecting the "Disable hardware checksum offload" and rebooting (though I didn't check without rebooting) the pfsense instance did the trick.
I didn't need to change anything on the ovirt/kvm hypervisor - the default offload settings are in place. All guests (pfsense and the linux ones) are using virtio network drivers.
Microsoft Windows OS
->zswap
Вкратце, это технология, позволяющая оптимизировать работу ядра со swap - хранилищем избыточных страниц памяти.
Включение и использование ZSWAP в Proxmox VE и любом современном дистр-ве Linux с ядром >= 3.11
Обновляемся:
apt-get clean; apt-get update; apt-get full-upgrade -y; apt-get autoremove --purge -y; apt-get autocleanПроверяем включено ли в ядре:
cat /boot/config-$(uname) | grep -i zswapЕсли все ОК:
CONFIG_ZSWAP=yПравим GRUB :
mkdir -vp /etc/default/grub.dНа выбор:
LZ4:
echo 'GRUB_CMDLINE_LINUX_DEFAULT="$GRUB_CMDLINE_LINUX_DEFAULT zswap.enabled=1 zswap.compressor=lz4 zswap.zpool=z3fold zswap.max_pool_percent=25"' > /etc/default/grub.d/zswap.cfg
или
ZSTD:
echo 'GRUB_CMDLINE_LINUX_DEFAULT="$GRUB_CMDLINE_LINUX_DEFAULT zswap.enabled=1 zswap.compressor=zstd zswap.zpool=z3fold zswap.max_pool_percent=25"' > /etc/default/grub.d/zswap.cfg
update-grub
Вкл. модули:
cp -fv /etc/initramfs-tools/modules
for module in lz4 lz4_compress zstd zstd_compress z3fold
do grep -qx "$" /etc/initramfs-tools/modules || echo "$" >> /etc/initramfs-tools/modules
done
update-initramfs -u -k all
Перезагрузка:
reboot
Проверяем:
dmesg | grep -i zswap
Должно быть:
Если выбран LZ4:
.
zswap: loaded using pool lz4/z3fold
.
Для ZSTD:
.
zswap: loaded using pool zstd/z3fold
.
Получаем статистику по ZSWAP:
Статистика:
watch -n1 grep -R . /sys/kernel/debug/zswap/
Сжатие:
cd /sys/kernel/debug/zswap
watch -n1 -x perl -E "say $(cat stored_pages) * 4096 / $(cat pool_total_size)"
Текущие настройки:
grep -R . /sys/module/zswap
Прим. Касаемо строки zswap.zpool=z3fold. По умолчанию на данный момент в linux испол-ся zbud в кач-ве memory allocator. Он обкатан и надежен и работает на любом "железе", но появился более эффективный z3fold:The zpool parameter controls the management of the compressed memory pool, it is by default set to zbud. With the zbud data allocator, 2 compressed objects are stored into 1 page which limits the compression ratio to 2 or less. The superior z3fold allocator allows up to 3 compressed objects by page. The compression ratio with z3fold typically averages 2.7 while it is 1.7 for zbud.
Однако, следует помнить, что компрессия требует вычислительных мощностей. И чем сильнее сжатие, тем выше требования к "железу".->FOG Project
FOG можно использовать:
Спасибо за популяризацию Proxmox.
Из мануала по вашим ссылкам:
Proxmox VE сам по себе свободен для применения. Не существует абсолютно никаких платежей включенных в загрузку простого образа ISO и установки полнофункционального кластера Proxmox без оплаты лицензий или подписок.
С официального сайта:
Starting out
€ 5,83/month (per CPU)Отказ от подписки с точки зрения разработчиков допустим?
Отказ от подписки с точки зрения разработчиков допустим?
Все строго добровольно. Хотите платную поддержку и сверх быструю реакцию на баги - платите. Нет? Пользуйте просто так.
P.s. Вот "увидивили". Был на 146% уверен, что уж вы-то, ув. pigbrother, точно KVM "тискали" :'(
Первый тестовый виртуальный домен поднимал в далеком 2001 году на PIII (Vmware Workstation). ;),
Winows NT DC, рабочие станции Windows NT и 98, выход в интернет через RRAS с диалапом…Сейчас в продакшн используется ESXi - выбор руководства. Мы посовещались и оно решило ;).
С KVM за довольно долгую карьеру столкнуться, как ни странно, так и не пришлось. Сейчас же хочу покрутить для собственного интереса.Что порекомендуете - сразу 5.0 или начать с 4.4?
5-ку, ес-но. После установки - сразу обновить.
Если в будущем в продакшн соберетесь, то использовать ZFS raid от 2-ух (raid1), а лучше - 4 диска (raid10). Zfs raid идет из коробки и в самом начале установки конфигурируется.
Proxmox поддерживает nested virtualization? Хочу попробовать в ESXi. Нет под рукой свободного полноценного железа.
Все это исключительно для тестов, нормальной работы от такого мутанта никто не ждет.
Nested virtualization (вложенная виртуализация, т.е. возможность запускать гипервизор в гипервизоре) на Proxmox:
Миграция с других гипервизоров (локально).
Внимание! Формат raw - это т.н. "сырой" формат образов дисков. Перед дальнейшими операциями убедиться в наличие
свободного места.Подключаемся по SFTP к Proxmox. В Win это можно сделать с пом. WinSCP или FAR.
Забрасываем образ(ы) диска(ов), к-ые мы хотим подкинуть к ВМ в предварительно созданную временную папку.
Прим. Если у вас ova-образ - сперва распаковываем
tar -xvf disk.ovaКонвертируем (на примере vmware .vmdk)
qemu-img convert -p -O raw disk.vmdk disk.rawСмотрим размер получившегося
ls -ahlCоздаем через gui ВМ с диском(-ми) не меньшего размера. ВМ не запускать!
Смотрим что у нас получилось (у вас путь к образам дисков может быть другой)
ls -al /dev/zvol/rpool/data/Разворачиваем образ диска в диск ВМ
dd if=/path/to/file/disk.raw of=/dev/zvol/ZFS-Pool-Name/vm-XYZ-disk-X
ZFS-Pool-Name и vm-XYZ-disk-X изменить на своиПосле
qm rescanUpd2.
Короткий вариант. Проверил - работает.
qemu-img convert -p -O raw disk.vmdk /dev/zvol/ZFS-Pool-Name/vm-XYZ-disk-X
ZFS-Pool-Name и vm-XYZ-disk-X изменить на свои
qm rescanЗапускаем ВМ. Проверяем.
Upd3.
Специально для тех, кто переходит с MS Hyper-V на Proxmox (KVM):Подкидываем **vhdx-**образ по SFTP во временную папку на Proxmox.
Далее повторяем ранее описанное (т.е., создаем через gui ВМ с диском необх. размера, но не вкл. её! )
Команда для конвертации:
qemu-img convert -p -O raw disk.vhdx /dev/zvol/ZFS-Pool-Name/vm-XYZ-disk-X
ZFS-Pool-Name и vm-XYZ-disk-X изменить на свои
qm rescanЗапускаем ВМ. Проверяем.
Upd4.
И для догадливых (типа меня, ага 8))
Аналогично описанному выше (только наоборот ;)) можно конвертировать zfs-диски Proxmox-а во все самые распространненные форматы:Сперва выкл. ВМ, конечно.
VHD\VHDX (Hyper-V)
qemu-img convert -p -O vhdx /dev/zvol/ZFS-Pool-Name/vm-XYZ-disk-X /path/to/file/disk.vhdx
ZFS-Pool-Name , vm-XYZ-disk-X и /path/to/file/ изменить на своиТак что, добро пожаловать в мир открытого ПО. Для тех кто еще не решился )
Миграция Windows 2000 с динамическими дисками dynamic disc
Дано:
Старый сервер с Windows 2000 Server на программном raid1 из 2-ух дисков. На сервере живет оч. важное для клиента ПО.Задача:
(Бережно) перенести в Proxmox VE (KVM)- Linux ничего "не знает" о динамических дисках Windows, что не дает возможность использовать "в лоб" Clonezilla и Partclone для миграции локально или по сети.
- Windows 2000 не имеет в своем составе службу Volume Shadow Copy, что не позволяет использовать, напр., Disk2vhd для промежуточной миграции в vhd(x) и дальнейшего переноса на PVE.
Решение:
Нам понадобятся Clonezilla Live, Gparted Live, драйверы на сетевой адаптер Intel e1000.Мигрируем удаленно.
Предупреждение. Все ниже описанное вы делаете на свой страх и риск. Внимательно проверяйте какие диски копируете и куда принимаете. Крайне желательно иметь резервные копии данных.
И так. Как сказал один оч. известный и достойный Человек: "Поехали!"
Принимающая сторона:
На Proxmox создаем ВМ с размером диска как у отдающей стороны.
Загружаемся с SystemRescueCD в эту ВМ.
Настраиваем сет. параметры (net-setup имя-интерфейса) или получаем их по dhcp. Проверить полученные\настроенные сет. параметры - ip a sНа отдающей стороне:
Загружаемся с SystemRescueCD.
Настраиваем сет. параметры (net-setup имя-интерфейса) или получаем их по dhcp. Проверить полученные\настроенные сет. параметры - ip a sЗапускаем на принимающей стороне:
nc -w10 -vvnlp 19000 | pigz -5 -dfc | cat > /dev/disk-name, где :-w10 - время ожидания данных в сек. на приним. стороне (меняется на ваше усмотрение).
19000 - номер порта, к-ый слушает netcat и принимает на него данные от отдающей стороны (меняется на ваше усмотрение)
pigz -5 - степень сжатия (меняется на ваше усмотрение)
disk-name - имя диска внутри ВМ (меняете на свое)Считаем до трех и запускаем на отдающей стороне:
pv /dev/disk-name | pigz -5 -fc | nc -vvn remote-server-ip 19000, где:disk-name - имя диска, к-ый вы хотите передать (узнается по fdisk -l)
pigz -5 - степень сжатия (меняется на ваше усмотрение)
remote-server-ip - ip-адрес\имя удаленного сервера-приемника
19000 - номер порта удаленного сервера-приемникаВсё. Скрещиваем пальцы, чтобы линк между отдающей и принимающей сторонами не упал и ждем окончания процесса.
После удачного окончания выкл. ВМ на принимающей стороне. Извлекаем в gui из вирт. привода SystemRescueCD и пробуем загрузиться.Пример с SSH (кому необходима секьюрность):
Принимающая сторона:
Создаем ВМ с размером диска как у отдающей стороны.
Загружаемся с SystemRescueCD в эту ВМ.
Настраиваем сет. параметры (net-setup имя-интерфейса) или получаем их по dhcp. Проверить полученные\настроенные сет. параметры - ip a s
Смотрим какие диски у нас есть - fdisk -l. Запоминаем\записываем имя нужного нам диска.
Более ничего на принимающей стороне делать\запускать не надо.На отдающей стороне:
Загружаемся с SystemRescueCD.
Настраиваем сет. параметры (net-setup имя-интерфейса) или получаем их по dhcp. Проверить полученные\настроенные сет. параметры - ip a s
Запускаем команду:
pv /dev/disk-name | pigz -5 -fc | ssh remote-server-ip "cat > /dev/disk-name", где :disk-name - имя диска на принимающей стороне, к-ое мы внимательно выбрали и запомнили ранее
remote-server-ip - ip\имя примающей стороныОжидаем удачного окончания процесса передачи. После выкл. ВМ на принимающей стороне. Извлекаем в gui из вирт. привода SystemRescueCD и пробуем загрузиться.
Читайте также: