
Распределительный способ обработки данных предполагает локальные компьютеры
Обновлено: 07.07.2024
Организация ЛВС на предприятии дает возможность распределить ресурсы ПК по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации.
Распределенная обработка данных имеет следующие преимущества:
возможность увеличения числа удаленных взаимодействующих пользователей, выполняющих функции сбора, обработки, хранения и передачи информации;
снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз на разных персональных компьютерах;
обеспечение доступа пользователей к вычислительным ресурсам ЛВС;
обеспечение обмена данными между удаленными пользователями.
При распределенной обработке производится работа с базой данных, т. е. представление данных, их обработка. При этом работа с базой на логическом уровне осуществляется на компьютере клиента, а поддержание базы в актуальном состоянии -- на сервере.
Выделяют локальные и распределенные базы данных:
Локальная база данных - это база данных, которая полностью располагается на одном ПК. Это может быть компьютер пользователя или сервер.
Распределенная база данных характеризуется тем, что может размещаться на нескольких ПК, чаще всего в роли таких QK выступают серверы
В настоящее время созданы базы данных по всем направлениям человеческой деятельности: экономической, финансовой, кредитной, статистической, научно-технической, маркетинга, патентной информации, электронной документации и т. д.
Создание распределенных баз данных было вызвано двумя тенденциями обработки данных, с одной стороны -- интеграцией, а с другой -- децентрализацией.
Интеграция обработки информации подразумевает централизованное управление и ведение баз данных.
Децентрализация обработки информации обеспечивает хранение данных в местах их возникновения или обработки, при этом скорость обработки повышается, стоимость снижается, увеличивается степень надежности системы.
Доступ пользователей к распределенной базе данных (РБД) и администрирование осуществляется с помощью системы управления распределенной базой данных, которая обеспечивает выполнение следующих функций:
автоматическое определение компьютера, хранящего требуемые в запросе данные;
декомпозицию распределенных запросов на частные подзапросы к базе данных отдельных ПК;
планирование обработки запросов;
передачу частных подзапросов и их исполнение на удаленных персональных компьютерах;
прием результатов выполнения частных подзапросов;
поддержание в согласованном состоянии копий дублированных данных на различных ПК сети;
управление параллельным доступом пользователей к РБД;
*обеспечение целостности РБД.
Распределенная обработка данных
реализуется с помощью технологии «клиент-сервер».
Эта технология предполагает, что каждый из компьютеров сети имеет свое назначение и выполняет свою определенную роль. Одни компьютеры в сети владеют и распоряжаются информационно-вычислительными ресурсами (процессоры, файловая система, почтовая служба, служба печати, база данных), другие имеют возможность обращаться к этим службам, пользуясь их услугами.
Рассматриваемая технология определяет два типа компонентов: серверы и клиенты.
Сервер -- это объект, предоставляющий сервис другим объектам сети по их запросам. Сервис -- это процесс-обслуживания клиентов.
Сервер работает по заданиям клиентов и управляет выполнением их заданий. После выполнения каждого задания сервер посылает полученные результаты клиенту, пославшему это задание.
Сервисная функция в архитектуре «клиент-сервер» описывается комплексом прикладных программ, в соответствии с которым выполняются разнообразные прикладные процессы.
Клиенты -- это рабочие станции, которые используют ресурсы сервера и предоставляют удобные интерфейсы пользователя. Интерфейсы пользователя -- это процедуры взаимодействия пользователя с системой или сетью.
Клиент является инициатором и использует электронную почту или другие сервисы сервера. В этом процессе клиент запрашивает вид обслуживания, устанавливает сеанс, получает нужные ему результаты и сообщает об окончании работы.
Один из основных принципов технологии «клиент-сервер» заключается в разделении функций стандартного интерактивного приложения на три группы, имеющие различную природу:
Это функции ввода и отображения данных
Это прикладные операции обработки данных, характерные для решения задач данной предметной области (например, для банковской системы - открытие счета, перевод денег с одного счета на другой и т. д.)
Это операции хранения и управления информационно-вычислительными ресурсами (базами данных, файловыми системами и т. д.)
В соответствии с этой классификацией в любом приложении выделяются следующие логические компоненты:
компонент представления, реализующий функции первой группы;
прикладной компонент, поддерживающий функции второй группы;
компонент доступа к информационным ресурсам, поддерживающий функции третьей группы.
Выделяют четыре модели реализации технологии «клиент-сервер»:
ь Модель файлового сервера
ь Модель доступа к удаленным данным
ь Модель сервера баз данных
ь Модель сервера приложений
Модель файлового сервера представляет наиболее простой случай распределенной обработки данных. Один из компьютеров в сети считается файловым сервером и предоставляет другим компьютерам услуги по обработке файлов. Файловый сервер играет роль компонента доступа к информационным ресурсам (т. е. к файлам). На других ПК в сети функционирует приложения, в которых совмещены компонент представления и прикладной компонент. Использование файловых серверов предполагает, что вся обработка данных выполняется на рабочей станции, а сервер лишь выполняет функции накопителя данных и средств доступа (рис. 12).
Рис. 12. Модель файлового сервера
К недостаткам технологии данной модели относят низкий сетевой трафик (передача множества файлов, необходимых приложению), небольшое количество операций манипуляции с данными (файлами), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т. д.
Модель доступа к удаленным данным существенно отличается от модели файлового сервера методом доступа к информационным ресурсам. В этой модели компонент представления и прикладной компонент также совмещены и выполняются на компьютере-клиенте. Доступ к информационным ресурсам обеспечивается операторами специального языка (SQL, если речь идет о базах данных) или вызовами функций специальной библиотеки.
Запросы к информационным ресурсам направляются по сети серверу базы данных, который обрабатывает и выполняет их, возвращая клиенту не файлы, а необходимые для обработки блоки данных, которые удовлетворяют запросу клиента (рис. 13).
Рис. 13. Модель доступа к удаленным данным
Основное достоинство модели доступа к удаленным данным заключается в унификации интерфейса «клиент-сервер» в виде языка и широком выборе средств разработки приложений. К недостаткам можно отнести существенную загрузку сети при взаимодействии клиента и сервера посредством SQL-запросов и невозможность администрирования приложений, т.к. в одной программе совмещаются различные по своей природе функции (представления данных и прикладного компонента).
Модель сервера баз данных основана на механизме хранимых процедур. Процедуры хранятся в словаре баз данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. В этой модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере базы данных. Там же выполняется компонент доступа к данным, т. е. ядро СУБД (рис. 14).
14. Модель сервера баз данных
Достоинства модели сервера баз данных:
возможность централизованного администрирования прикладных функций;
снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур);
экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры.
Основной недостаток модели сервера баз данных является ограниченность средств написания хранимых процедур, представляющих собой разнообразные процедурные расширения SQL. Сфера их использования ограничена конкретной СУБД из-за отсутствия возможности отладки и тестирования разнообразных хранимых процедур.
Модель сервера приложений позволяет помещать прикладные программы на отдельные серверы приложений. Программа, выполняемая на компьютере-клиенте, решает задачу ввода и отображения данных, т. е. реализует операции первой группы. Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения. Доступ к информационным ресурсам, необходимым для решения прикладных задач, обеспечивается так же, как в модели доступа к удаленным данным, т. е. прикладные программы обращаются к серверу базы данных с помощью SQL-запросов (рис. 15).
Рис. 15. Модель сервера приложений
Технологии «клиент-сервер» имеют следующие преимущества:
позволяют организовывать сети с большим количеством рабочих станций;
обеспечивают централизованное управление учетными записями пользователей, безопасностью и доступом, что упрощает сетевое администрирование;
* предоставляют эффективный доступ к сетевым ресурсам.
Наряду с преимуществами технология «клиент-сервер» имеет и ряд недостатков:
неисправность сервера может сделать сеть неработоспособной, что влечет как минимум потерю сетевых ресурсов;
Концепция построения сети
До появления компьютерных сетей каждый пользователь должен был иметь свой принтер, плоттер и другие периферийные устройства. Чтобы совместно использовать принтер, существовал единственный способ - пересесть за компьютер, подключенный к этому принтеру. Сети позволяют целому ряду пользователей одновременно «владеть» данными на носителях прямого доступа и периферийными устройствами. Если нескольким пользователям надо распечатать документ, все они могут обратиться к сетевому принтеру.
Самая простая сеть состоит как минимум из двух компьютеров, соединенных друг с другом кабелем. Это позволяет им использовать данные совместно. Все сети (независимо от сложности) основываются именно на этом простом принципе. Рождение компьютерных сетей было вызвано практической потребностью - иметь возможность для совместного использования данных. Персональный компьютер - прекрасный инструмент для создания документа, подготовки таблиц, графических данных и других видов информации, но при этом Вы не можете быстро поделиться своей информацией с другими. Когда не было сетей, приходилось распечатывать каждый документ, чтобы другие пользователи могли работать с ним, или в лучшем случае - копировать информацию на дискеты. Одновременная обработка документа несколькими пользователями исключалась. Подобная схема работы называется работой в автономной среде.
Сетью называется группа соединенных компьютеров и других устройств. А концепция соединенных и совместно использующих ресурсы компьютеров носит название сетевого взаимодействия. Компьютеры, входящие в сеть, могут совместно использовать:
Данный список постоянно пополняется, так как возникают новые способы совместного использования ресурсов.
Первоначально компьютерные сети были небольшими и объединяли до десяти компьютеров и один принтер. Технология передачи данных ограничивала размеры сети, в том числе количество компьютеров в сети и ее физическую длину. Например, в начале 1980-х годов наиболее популярный тип сетей состоял не более чем из 30 компьютеров, а длина кабеля не превышала 185 м (600 футов). Такие сети легко располагались в пределах одного этажа здания или небольшой организации. Для маленьких фирм подобная конфигурация подходит и сегодня. Эти сети называются локальными вычислительными сетями [ЛВС (LAN)].
Локальные сети не совсем соответствуют потребностям крупных предприятий, офисы которых обычно территориально расположены в различных местах. Этот факт поставил задачу расширения сетей. Так на основе небольших локальных сетей возникли более крупные системы. В настоящее время миллионы ЛВС объединены в глобальную вычислительную сеть ГВС (WAN), а количество компьютеров в сети достигает нескольких тысяч.
В настоящее время большинство организаций хранит и совместно использует в сетевой среде огромные объемы жизненно важных данных. Вот почему сети сейчас так же необходимы, как еще совсем недавно были необходимы пишущие машинки и картотеки.
Два типа ЛВС - одноранговые сети и сети с выделенным сервером
Все сети имеют некоторые общие компоненты, функции и характеристики:
· серверы (server) - компьютеры, предоставляющие свои ресурсы сетевым пользователям;
· клиенты (client) - компьютеры, осуществляющие доступ к сетевым ресурсам, предоставляемым сервером;
· среда (media) - способ соединения компьютеров;
· совместно используемые данные - файлы, предоставляемые серверами по сети;
· совместно используемые периферийные устройства, например принтеры, библиотек CD-ROM и т.д.,
· ресурсы, предоставляемые серверами;
· ресурсы - файлы, принтеры и другие элементы, используемые в сети.
· Несмотря на определенные сходства, сети разделяются на два типа:
· на основе сервера (server based).
Различия между одноранговыми сетями и сетями на основе сервера имеют принципиальное значение, поскольку определяют разные возможности этих сетей. Выбор типа сети зависит от многих факторов:
· необходимого уровня безопасности;
· уровня доступности административной поддержки;
· объема сетевого трафика;
· потребностей сетевых пользователей;
Распределенная обработка данных
Распределенная обработка данных - методика выполнения прикладных программ группой систем. При этом пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах.
В современном бизнесе очень часто возникает необходимость предоставить доступ к одним и тем же данным группам пользователей, территориально удаленным друг от друга. В качестве примера можно привести банк, имеющий несколько отделений. Эти отделения могут находиться в разных городах, странах или даже на разных континентах, тем не менее необходимо организовать обработку финансовых транзакций (перемещение денег по счетам) между отделениями. Результаты финансовых операций должны быть видны одновременно во всех отделениях.
Существуют два подхода к организации обработки распределенных данных.
1. технология распределенной базы данных. Такая база включает фрагменты данных, расположенные на различных узлах сети. С точки зрения пользователей она выглядит так, как будто все данные хранятся в одном месте. Естественно, такая схема предъявляет жесткие требования к производительности и надежности каналов связи.
2. технология тиражирования. В этом случае в каждом узле сети дублируются данные всех компьютеров. При этом:
o передаются только операции изменения данных, а не сами данные
o передача может быть асинхронной (неодновременной для разных узлов)
o данные располагаются там, где обрабатываются.
Это позволяет снизить требования к пропускной способности каналов связи, более того при выходе из строя линии связи какого-либо компьютера, пользователи других узлов могут продолжать работу. Однако при этом допускается неодинаковое состояние базы данных для различных пользователей в один и тот же момент времени. Следовательно, невозможно исключить конфликты между двумя копиями одной и той же записи.
Достоинствами распределенной обработки информации является:
o большое число взаимодействующих между собой пользователей;
o устранение пиковых нагрузок с централизованной базы данных за счет распределения обработки и хранения локальных баз данных на разных ЭВМ;
o возможность доступа пользователя к вычислительным ресурсам сети ЭВМ;
o обеспечение обмена данными между удаленными пользователями.
При распределенной обработке производится работа с базой, т.е. представление данных, их обработка, работа с базой на логическом уровне осуществляется на компьютере клиента, а поддержание базы в актуальном состоянии - на сервере. При наличии распределенной базы данных база размещается на нескольких серверах. В настоящее время созданы базы данных по всем направлениям человеческой деятельности: экономической, финансовой, кредитной, статистической, научно-технической, маркетинга, патентной информации, электронной документации и т.д.
При размещении БД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если БД используют несколько пользователей, они могут работать с ней только последовательно, и поэтому вопросов о поддержании корректной модификации БД в этом случае здесь не стоит, они решаются организационными мерами — то есть определением требуемой последовательности работы конкретных пользователей с соответствующей БД . Однако даже в некоторых настольных БД требуется учитывать последовательность изменения данных при обработке, чтобы получить корректный результат: так, например, при запуске программы балансного бухгалтерского отчета все бухгалтерские проводки — финансовые операции должны быть решены заранее до запуска конечного приложения.
Однако работа на изолированном компьютере с небольшой базой данных в настоящий момент становится уже нехарактерной для большинства приложений. БД отражает информационную модель реальной предметной области , она растет по объему и резко увеличивается количество задач, решаемых с ее использованием, и в соответствии с этим увеличивается количество приложений, работающих с единой базой данных. Компьютеры объединяются в локальные сети , и необходимость распределения приложений, работающих с единой базой данных по сети, является несомненной.
Действительно, даже когда вы строите БД для небольшой торговой фирмы, у вас появляется ряд специфических пользователей БД , которые имеют свои бизнес-функции и территориально могут находиться в разных помещениях, но все они должны работать с единой информационной моделью организации, то есть с единой базой данных.
Параллельный доступ к одной БД нескольких пользователей, в том случае если БД расположена на одной машине, соответствует режиму распределенного доступа к централизованной БД . (Такие системы называются системами распределенной обработки данных.)
Если же БД распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной БД . Подобные системы называются системами распределенных баз данных. В общем случае режимы использования БД можно представить в следующем виде (см. рис. 10.1).
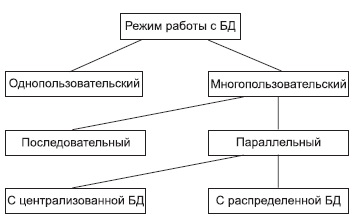
Определим терминологию, которая нам потребуется для дальнейшей работы. Часть терминов нам уже известна, но повторим здесь их дополнительно.
Терминология
Пользователь БД — программа или человек, обращающийся к БД на ЯМД.
Запрос — процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД .
Транзакция — последовательность операций модификации данных в БД , переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД — определение БД на физически независимом уровне, ближе всего соответствует концептуальной модели БД .
Топология БД = Структура распределенной БД - схема распределения физической БД по сети.
Локальная автономность — означает, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
Удаленный запрос — запрос , который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции обработка одной транзакции, состоящей из множества SQL -запросов на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL , которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле, то есть запросы не являются распределенными. При обработке одной распределенной транзакции разные локальные запросы могут обрабатываться в разных узлах сети.
Распределенный запрос — запрос , при обработке которого используются данные из БД , расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД , которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. При этом пользовательские терминалы не имели собственных ресурсов — то есть процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R, разработанная фирмой IBM , именно в ней были реализованы как язык манипулирования данными SQL , так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД .
Общая тенденция движения от отдельных mainframe -систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название DownSizing . Этот процесс оказал огромное влияние на развитие архитектур СУБД и поставил перед их разработчиками ряд сложных задач. Главная проблема состояла в технологической сложности перехода от централизованного управления данными на одном компьютере и СУБД , использовавшей собственные модели, форматы представления данных и языки доступа к данным и т. д., к распределенной обработке данных в неоднородной вычислительной среде, состоящей из соединенных в глобальную сеть компьютеров различных моделей и производителей.
В то же время происходил встречный процесс — UpSizing . Бурное развитие персональных компьютеров, появление локальных сетей также оказали серьезное влияние на эволюцию СУБД . Высокие темпы роста производительности и функциональных возможностей PC привлекли внимание разработчиков профессиональных СУБД , что привело к их активному распространению на платформе настольных систем.
Сегодня возобладала тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам. Она получила название RightSizing (помещение ровно в тот размер, который необходим).
Однако и в настоящее время большие ЭВМ сохраняются и сосуществуют с современными открытыми системами. Причина этого проста — в свое время в аппаратное и программное обеспечение больших ЭВМ были вложены огромные средства: в результате многие продолжают их использовать, несмотря на морально устаревшую архитектуру. В то же время перенос данных и программ с больших ЭВМ на компьютеры нового поколения сам по себе представляет сложную техническую проблему и требует значительных затрат.
Модели "клиент-сервер" в технологии баз данных
Вычислительная модель "клиент— сервер " исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро эволюционировала. Сам термин "клиент- сервер " исходно применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели назывался "клиентом", а другой — "сервером". Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов.
Ранее приложение (пользовательская программа ) не разделялась на части, оно выполнялось некоторым монолитным блоком. Но возникла идея более рационального использования ресурсов сети. Действительно, при монолитном исполнении используются ресурсы только одного компьютера, а остальные компьютеры в сети рассматриваются как терминалы. Но теперь, в отличие от эпохи main-фреймов, все компьютеры в сети обладают собственными ресурсами, и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы.
И как в промышленности, здесь возникает древняя как мир идея распределения обязанностей , разделения труда. Конвейеры Форда сделали в свое время прорыв в автомобильной промышленности, показав наивысшую производительность труда именно из-за того, что весь процесс сборки был разбит на мелкие и максимально простые операции и каждый рабочий специализировался на выполнении только одной операции , но эту операцию он выполнял максимально быстро и качественно.
Конечно, в вычислительной технике нельзя было напрямую использовать технологию автомобильного или любого другого механического производства, но идею использовать было можно. Однако для воплощения идеи необходимо было разработать модель разбиения единого монолитного приложения на отдельные части и определить принципы взаимосвязи между этими частями.
Основной принцип технологии "клиент— сервер " применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
- функции ввода и отображения данных (Presentation Logic);
- прикладные функции, определяющие основные алгоритмы решения задач приложения ( Business Logic );
- функции обработки данных внутри приложения (Database Logic);
- функции управления информационными ресурсами ( Database Manager System);
- служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных приведена на рис. 10.2.
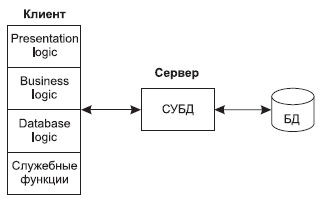
Рис. 10.2. Структура типового интерактивного приложения, работающего с базой данных
Презентационная логика ( Presentation Logic ) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение . Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация . Поэтому основными задачами презентационной логики являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатие клавиш клавиатуры.
Некоторые возможности для организации презентационной логики приложений предоставляет знако-ориентированный пользовательский интерфейс , задаваемый моделями CCIS ( Customer Control Information System ) и IMS /DC фирмы IBM и моделью TSO ( Time Sharing Option ) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса, поддерживается в операционных средах Microsoft's Windows , Windows NT, в OS/2 Presentation Manager , X- Windows и OSF / Motif .
Бизнес-логика, или логика собственно приложений (Business processing Logic ), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как C, C++, Cobol, SmallTalk, Visual-Basic.
Логика обработки данных ( Data manipulation Logic ) — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД ( DBMS ). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL .
Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения ( 3GL , 4GL ), которые используются для написания кода приложения.
Процессор управления данными ( Database Manager System Processing ) — это собственно СУБД , которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing ) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений (см. рис. 10.3):
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP );
- распределенная бизнес-логика (Distributed Business Logic, DBL);
- распределенное управление данными (Distributed data management , DDM );
- удаленное управление данными (Remote data management , RDM ).
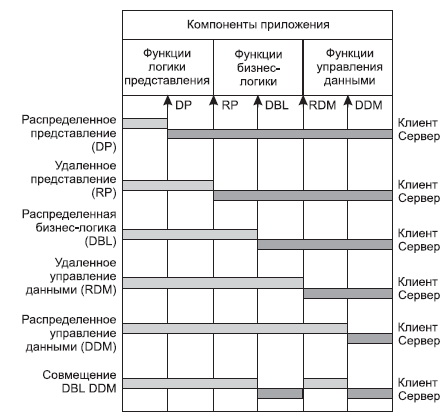
Рис. 10.3. Распределение функций приложения в моделях "клиент—сервер"
Эта условная классификация показывет, как могут быть распределены отдельные задачи между серверным и клиенскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Действительно, считается, что она не может быть удалена сама по себе полностью. Считается, что она может быть распределена между разными процессами, которые в общем-то могут выполняться на разных платформах, но должны корректно кооперироваться (взаимодействовать) друг с другом.
Одной из важнейших и динамично развивающихся сетевых технологий являются технологии распределенной обработки данных. Использование этих технологий позволяет существенно улучшить информационное обеспечение территориально распределенного производства. При этом для администрации фирмы безразлично, где именно находится производство: в этом же здании, за 100 м или за 10 000 км. Появляются совсем другие проблемы, такие как межконтинентальное снабжение, поясное время и т.д.
Персональные компьютеры стоят на рабочих местах, т.е. в местах возникновения и использования информации (например, в иногороднем филиале фирмы, в пункте обмена валют коммерческого банка и т.д.). Они соединены каналами связи. Использование технологии распределенной обработки данных дает возможность распределить ресурсы всех компьютеров такой корпоративной (региональной) компьютерной сети по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации.
Преимущества распределенной обработки данных:
- большое число взаимодействующих между собой пользователей, выполняющих функции сбора, регистрации, хранения, передачи и выдачи информации;
- снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ;
- обеспечение доступа каждого работника к вычислительным ресурсам сети ЭВМ;
- обеспечение симметричного обмена данными между удаленными пользователями.
Распределенная обработка и распределенная база данных не синонимы. Если при распределенной обработке производится работа с базой, то подразумевается, что представление данных, их содержательная обработка, работа с базой на логическом уровне выполняются на персональном компьютере клиента, а поддержание базы в актуальном состоянии (состоянии, соответствующем состоянию реальной системы) — на сервере. В случае использования распределенной базы данных последняя размещается на нескольких серверах. Работа с ней осуществляется на тех же персональных компьютерах либо на других, и для доступа к удаленным данным надо использовать сетевую СУБД.
В системе распределенной обработки клиент может послать запрос как к собственной локальной базе данных, так и к удаленной. Удаленный запрос — единичный запрос к одному серверу. Несколько удаленных запросов к одному серверу объединяются в удаленную транзакцию. Если отдельные запросы транзакции обрабатываются различными серверами, то транзакция называется распределенной. При этом один запрос транзакции обрабатывается одним сервером. Распределенная же СУБД позволяет обрабатывать один запрос несколькими серверами. Такой запрос называется распределенным. Только обработка распределенного запроса поддерживает концепцию распределенной базы данных.
Организация обработки данных зависит от способа их распределения. Существуют централизованный, децентрализованный и смешанный способы распределения данных
Централизованная организация данных является самой простой для реализации (рис. 3.2.). На одном сервере находится единственная копия базы данных. Все операции с базой данных обеспечиваются этим сервером. Отсюда — ограничение на параллельную обработку. Доступ к данным выполняется с помощью удаленного запроса или удаленной транзакции. Достоинством такого способа являлся легкая поддержка базы данных в актуальном состояние а недостатками — то, что размер базы ограничен размером внешней памяти сервера; все запросы направляются к единственному серверу с соответствующими затратами на стоимость связи и временную задержку. Кроме того, база может стать полностью недоступной для удаленных пользователей при появлении ошибок связи или при отказе центрального сервера.
Децентрализованная организация данных предполагает разбиение информационной базы на несколько физически распределенных. Каждый клиент пользуется своей базой данных, которая может быть либо частью общей информационной базы (рис. 3.3), либо копией информационной базы в целом (рис. 3.4), что приводит к ее дублированию для каждого клиента.
При распределении данных на основе разбиения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо. Достоинства этого метода: большинство запросов удовлетворяются локальными серверами, что сокращает время получения ответа и снижает стоимость обработки запроса; система остается частично работоспособной при выходе из строя одного из серверов. Имеются и недостатки: часть удаленных запросов или транзакций может потребовать доступ к нескольким или даже всем серверам, что увеличит время ожидания; постоянно необходимо иметь сведения о размещении данных в различных БД. Расчленение базы данных наиболее подходит в случае совместного использования локальных и глобальных сетевых коммуникаций, поскольку обеспечивает безопасное использование внутрикорпоративных данных.

Способ дублирования заключается в том, что на каждом сервере сети размещается полная база данных (рис. 3.4). Это обеспечивает наибольшую надежность хранения данных. Недостатки способа: повышенные требования к объему внешней памяти клиентских компьютеров; усложнение корректировки баз, так как требуется синхронизация в целях согласования копий. Достоинства — все запросы выполняются локально, что обеспечивает быстрый доступ. Данный способ используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика.
Возможна и смешанная организация хранения данных, которая объединяет два способа распределения: разбиение и дублирование (рис. 3.5), приобретая при этом и преимущества, и недостатки обоих способов.
Появляется необходимость хранить информацию о том, где находятся данные в сети. При этом достигается компромисс между объемом памяти под базу в целом и под базу на каждом сервере, чтобы обеспечить надежность и эффективность работы сети; легко реализуется параллельная обработка. Смешанный способ организации данных можно использовать лишь при наличии сетевой СУБД.
В базах данных коллективного пользования центральным технологическим звеном становятся серверы баз данных. Программные средства серверов баз данных обеспечивают реализацию многопользовательских приложений, централизованное хранение, целостность и безопасность данных. Производительность серверов баз данных на порядок выше по сравнению с файл-серверами, которые используются в локальных сетях.
Серверы баз данных рассчитаны на поддержку большого числа различных типов приложений. Для реализации интерфейса с сервером базы данных можно использовать объектно-ориентированные средства, электронные таблицы, текстовые процессоры, графические пакеты, настольные издательские системы и другие информационные технологии.
Недостаток технологии клиент-сервер заключается в повышении требований к производительности ЭВМ-сервера, в усложнении управления вычислительной сетью, а при отсутствии сетевой СУБД — в сложности организации распределенной обработки.
Читайте также: