
Rmngr 1c что это
Обновлено: 06.07.2024
Кластер — это разновидность параллельной
или распределённой системы, которая:
1. состоит из нескольких связанных
между собой компьютеров;
2. используется как единый,
унифицированный компьютерный ресурс
Дано: есть бизнес-приложение (например, ERP-система), с которым работают одновременно тысячи (возможно, десятки тысяч) пользователей.
- Сделать приложение масштабируемым, чтобы при увеличении количества пользователей можно было за счёт наращивания аппаратных ресурсов обеспечить необходимую производительность приложения.
- Сделать приложение устойчивым к выходу из строя компонентов системы (как программных, так и аппаратных), потере связи между компонентами и другим возможным проблемам.
- Максимально эффективно задействовать системные ресурсы и обеспечить нужную производительность приложения.
- Сделать систему простой в развертывании и администрировании.
К желаемому результату мы пришли не сразу.
В этой статье расскажем о том, какие бывают кластеры, как мы выбирали подходящий нам вид кластера и о том, как эволюционировал наш кластер от версии к версии, и какие подходы позволили нам в итоге создать систему, обслуживающую десятки тысяч одновременных пользователей.

Как писал автор эпиграфа к этой статье Грегори Пфистер в своей книге «In search of clusters», кластер был придуман не каким-либо конкретным производителем железа или софта, а клиентами, которым не хватало для работы мощностей одного компьютера или требовалось резервирование. Случилось это, по мнению Пфистера, ещё в 60-х годах прошлого века.
Традиционно различают следующие основные виды кластеров:
- Отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
- Кластеры с балансировкой нагрузки (Load balancing clusters, LBC)
- Вычислительные кластеры (High performance computing clusters, HPC)
- Системы распределенных вычислений (grid) иногда относят к отдельному типу кластеров, который может состоять из территориально разнесенных серверов с отличающимися операционными системами и аппаратной конфигурацией. В случае grid-вычислений взаимодействия между узлами происходят значительно реже, чем в вычислительных кластерах. В grid-системах могут быть объединены HPC-кластеры, обычные рабочие станции и другие устройства.
Для тех, кто не в курсе, коротко расскажу, как устроены бизнес-приложения 1С. Это приложения, написанные на предметно-ориентированном языке, «заточенном» под автоматизацию учётных бизнес-задач. Для выполнения приложений, написанных на этом языке, на компьютере должен быть установлен рантайм платформы 1С:Предприятия.
1С:Предприятие 8.0
Первая версия сервера приложений 1С (еще не кластер) появилась в версии платформы 8.0. До этого 1С работала в клиент-серверном варианте, данные хранились в файловой СУБД или MS SQL, а бизнес-логика работала исключительно на клиенте. В версии же 8.0 был сделан переход на трехзвенную архитектуру «клиент – сервер приложений – СУБД».

Сервер 1С в платформе 8.0 представлял собой СОМ+ сервер, умеющий исполнять прикладной код на языке 1С. Использование СОМ+ обеспечивало нам готовый транспорт, позволяющий клиентским приложениям общаться с сервером по сети. Очень многое в архитектуре и клиент-серверного взаимодействия, и прикладных объектов, доступных разработчику 1С, проектировалось с учетом использования СОМ+. В то время в архитектуру не было заложено отказоустойчивости, и падение сервера вызывало отключение всех клиентов. При падении серверного приложения СОМ+ поднимал его при обращении к нему первого клиента, и клиенты начинали свою работу с начала – с коннекта к серверу. В то время всех клиентов обслуживал один процесс.
1С:Предприятие 8.1
В следующей версии мы захотели:
- Обеспечить нашим клиентам отказоустойчивость, чтобы аварии и ошибки у одних пользователей не приводили авариям и ошибкам у других пользователей.
- Избавиться от технологии СОМ+. СОМ+ работала только на Windows, а в то время уже начала становиться актуальной возможность работы под Linux.
Так в версии 8.1 появился первый кластер. Мы реализовали свой протокол удаленного вызова процедур (поверх ТСР), который по внешнему виду выглядел для конечного потребителя-клиента практически как СОМ+ (т.е. нам практически не пришлось переписывать код, отвечающий за клиент-серверные вызовы). При этом сервер, реализованный нами на С++, мы сделали платформенно-независимым, способным работать и на Windows, и на Linux.
На смену монолитному серверу версии 8.0 пришло 3 вида процессов – рабочий процесс, обслуживающий клиентов, и 2 служебных процесса, поддерживающих работу кластера:
- rphost – рабочий процесс, обслуживающий клиентов и исполняющий прикладной код. В составе кластера может быть больше одного рабочего процесса, разные рабочие процессы могут исполняться на разных физических серверах – за счёт этого достигается масштабируемость.
- ragent – процесс агента сервера, запускающий все другие виды процессов, а также ведущий список кластеров, расположенных на данном сервере.
- rmngr – менеджер кластера, управляющий функционированием всего кластера (но при этом на нем не работает прикладной код).


Клиент на протяжении сессии работал с одним рабочим процессом, падение рабочего процесса означало для всех клиентов, которых этот процесс обслуживал, аварийное завершение сессии. Остальные клиенты продолжали работу.
1С:Предприятие 8.2
В версии 8.2 мы захотели, чтобы приложения 1С могли запускаться не только в нативном (исполняемом) клиенте, а ещё и в браузере (без модификации кода приложения). В связи с этим, в частности, встала задача отвязать текущее состояние приложения от текущего соединения с рабочим процессом rphost, сделать его stateless. Как следствие возникло понятие сеанса и сеансовых данных, которые нужно было хранить вне рабочего процесса (потому что stateless). Был разработан сервис сеансовых данных, хранящий и кэширующий сеансовую информацию. Появились и другие сервисы — сервис управляемых транзакционных блокировок, сервис полнотекстового поиска и т.д.
В этой версии также появились несколько важных нововведений – улучшенная отказоустойчивость, балансировка нагрузки и механизм резервирования кластеров.
Отказоустойчивость
Поскольку процесс работы стал stateless и все необходимые для работы данные хранились вне текущего соединения «клиент – рабочий процесс», в случае падения рабочего процесса клиент при следующем обращении к серверу переключался на другой, «живой» рабочий процесс. В большинстве случаев такое переключение происходило незаметно для клиента.
Балансировка нагрузки
Это стандартная задача для кластера с балансировкой нагрузки. Есть несколько типовых алгоритмов её решения, например:
-
– серверам присваиваются порядковые номера, первый запрос отправляется на первый сервер, второй запрос – на второй и т. д. до достижения последнего сервера. Следующий запрос направляется на первый сервер и всё начинается с начала. Алгоритм прост в реализации, не требует связи между серверами и неплохо подходит для «легковесных» запросов. Но при балансировке по этому алгоритму не учитывается производительность серверов (которая может быть разной) и текущая загруженность серверов. – усовершенствованный Round-Robin: каждому серверу присваивается весовой коэффициент в соответствии с его производительностью, и сервера с бо́льшим весом обрабатывают больше запросов.
- Least Connections: новый запрос передается на сервер, обрабатывающий в данный момент наименьшее количество запросов.
- Least Response Time: сервер выбирается на основе времени его ответа: новый запрос отдаётся серверу, ответившему быстрее других серверов.
Запрос от нового клиента адресуется на наиболее производительный на данный момент сервер.
Запрос от существующего клиента в большинстве случаев адресуется на тот сервер и в тот рабочий процесс, в который адресовался его предыдущий запрос. С работающим клиентом связан обширный набор данных на сервере, передавать его между процессами (а тем более между серверами) – довольно накладно (хотя мы умеем делать и это).
Запрос от существующего клиента передается в другой рабочий процесс в двух случаях:
- Процесса больше нет: рабочий процесс, с которым ранее взаимодействовал клиент, более недоступен (упал процесс, стал недоступен сервер и т.п.).
- Есть более производительный сервер: если в кластере есть сервер, отличающийся по производительности в два и более раза по сравнению с сервером, где запушен текущий рабочий процесс, то платформа считает, что даже ценой миграции клиентского контекста нам выгоднее выполнять запросы на более производительном сервере. Переноситься клиенты с одного сервера на другой будут постепенно, по одному, с периодической оценкой результата – что в плане производительности стало с серверами после переноса каждого из клиентских процессов. Цель этой процедуры – выравнивание производительности серверов в кластере (т.е. равномерная загрузка серверов).
Резервирование кластеров
Мы решили повысить отказоустойчивость кластера, прибегнув к схеме Active / passive. Появилась возможность конфигурировать два кластера – рабочий и резервный. В случае недоступности основного кластера (сетевые неполадки или, например, плановое техобслуживание) клиентские вызовы перенаправлялись на резервный кластер.

Однако эта конструкция была довольно сложна в настройке. Администратору приходилось вручную собирать две группы серверов в кластеры и конфигурировать их. Иногда администраторы допускали ошибки, устанавливая противоречащие друг другу настройки, т.к. не было централизованного механизма проверки настроек. Но, тем не менее, этот подход повышал отказоустойчивость системы.
1С:Предприятие 8.3
В версии 8.3 мы существенно переписали код серверной части, отвечающий за отказоустойчивость. Мы решили отказаться от схемы Active / passive кластеров ввиду сложности её конфигурирования. В системе остался только один отказоустойчивый кластер, состоящий из любого количества серверов – это ближе к схеме на Active / active, в которой запросы на отказавший узел распределяются между оставшимися рабочими узлами. За счет этого кластер стал проще в настройке. Ряд операций, повышающих отказоустойчивость и улучшающих балансировку нагрузки, стали автоматизированными. Из важных нововведений:
- Новая настройка кластера «Уровень отказоустойчивости»: число, указывающее, сколько серверов может выйти из строя без последствий в виде аварийного завершения сеансов подключенных пользователей. Исходя из этой настройки кластер будет тратить определённый объём ресурсов на синхронизацию данных между рабочими серверами, чтобы иметь всю необходимую для продолжения работы клиентов информацию на «живых» серверах в случае выхода из строя одного или нескольких серверов.
- Количество рабочих процессов не задается вручную, как раньше, а автоматически рассчитывается исходя из описаний требований задач по отказоустойчивости и надежности.
- Появился ряд настроек, связанных с максимальными объемами памяти, которые разрешается потреблять рабочим процессам, а также настройки, определяющие что делать, если эти объемы превышены:

Главная идея этих наработок – упростить работу администратора, позволяя ему настраивать кластер в привычных ему терминах, на уровне оперирования серверами, не опускаясь ниже, а также минимизировать уровень «ручного управления» работой кластера, дав кластеру механизмы для решения большинства рабочих задач и возможных проблем «на автопилоте».

Три звена отказоустойчивости
Как известно, даже если компоненты системы по отдельности надёжны, проблемы могут возникнуть там, где компоненты системы вызывают друг друга. Мы хотели свести количество мест, критичных для работоспособности системы, к минимуму. Важным дополнительным соображением была минимизация переделок прикладных механизмов в платформе и исключение изменений в прикладных решениях. В версии 8.3 появилось 3 звена обеспечения отказоустойчивости «на стыках»:
В заключение
Благодаря механизму отказоустойчивости приложения, созданные на платформе 1С:Предприятие, благополучно переживают разные виды отказов рабочих серверов в кластере, при этом бо́льшая часть клиентов продолжают работать без перезапуска.
Бывают ситуации, когда мы не можем повторить вызов, или падение сервера застает платформу в очень неудачный момент времени, например, в середине транзакции и не очень понятно, что с ними делать. Мы стараемся обеспечить статистически хорошую выживаемость клиентов при падении серверов в кластере. Как правило, средние потери клиентов за отказ сервера – единицы процентов. При этом все «потерянные» клиенты могут продолжить работу в кластере после перезапуска клиентского приложения.
Надежность кластера серверов 1С в версии 8.3 существенно повысилась. Уже давно не редкость внедрения продуктов 1С, где количество одновременно работающих пользователей достигает нескольких тысяч. Есть и внедрения, где одновременно работают и 5 000, и 10 000 пользователей — например, внедрение в «Билайне», где приложение «1С: Управление Торговлей» обслуживает все салоны продаж «Билайн» в России, или внедрение в грузоперевозчике «Деловые Линии», где приложение, самостоятельно созданное разработчиками ИТ-отдела «Деловых Линий» на платформе 1С:Предприятие, обслуживает полный цикл грузоперевозок. Наши внутренние нагрузочные тесты кластера эмулируют одновременную работу до 20 000 пользователей.
В заключение хочется кратко перечислить что ещё полезного есть в нашем кластере (список неполный):
В клиент-серверном варианте работы клиентское приложение взаимодействует с кластером серверов, который, в свою очередь, осуществляет взаимодействие с сервером баз данных.
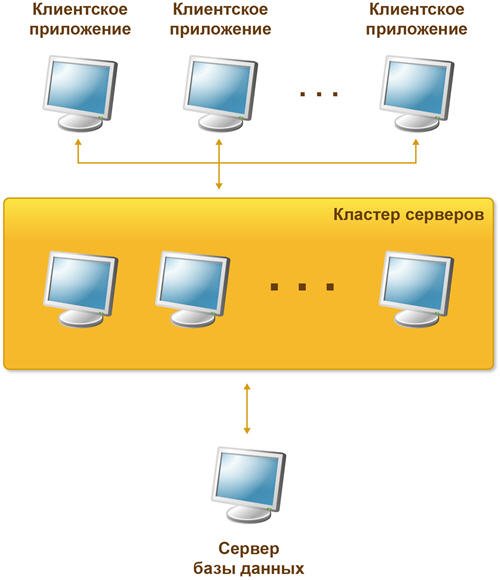
Один из компьютеров, входящих в состав кластера серверов, является центральным сервером кластера. Центральный сервер, помимо обслуживания клиентских соединений, управляет работой всего кластера и хранит реестр кластера.
Для клиентского соединения кластер адресуется по имени центрального сервера и номеру сетевого порта. Если используется стандартный сетевой порт, то достаточно указания одного имени центрального сервера.
При установке соединения клиентское приложение обращается к центральному серверу кластера. Центральный сервер, на основе анализа статистики загруженности рабочих процессов, направляет клиентское приложение к конкретному рабочему процессу, который будет его обслуживать. Этот процесс может находиться как на центральном сервере, так и на любом рабочем сервере кластера.
Рабочий процесс выполняет аутентификацию пользователя и обслуживает соединение до окончания сеанса работы клиента с данной информационной базой.
Состав простейшего кластера серверов
Простейший кластер серверов может располагаться на одном компьютере и содержать один рабочий процесс:
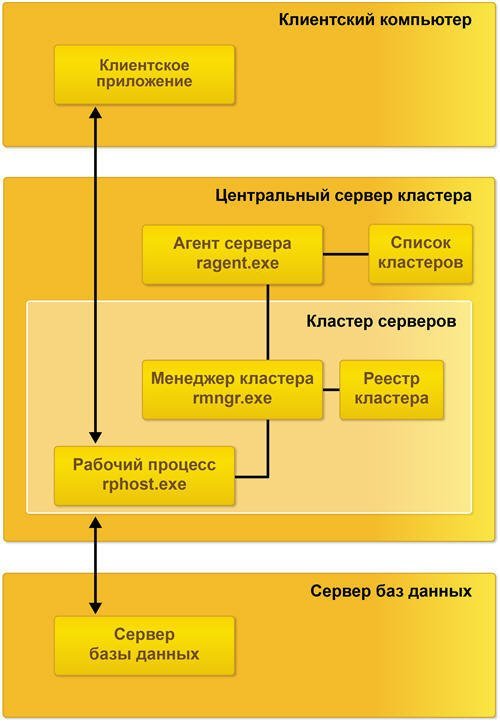
- процессы кластера серверов:
- ragent.exe;
- rmngr.exe;
- rphost.exe;
- список кластеров;
- реестр кластера.
Функционирование компьютера в составе кластера обеспечивается процессом ragent.exe, который называется агентом сервера. Соответственно компьютер, на котором запущен агент сервера, называется рабочим сервером. Одной из функций агента сервера является ведение списка кластеров, расположенных на данном рабочем сервере.
Агент сервера и список кластеров не входят в состав кластера серверов, а лишь обеспечивают работу сервера и кластеров, которые расположены на нем.
![На клиенте на сервере]()
Немного теории о стороне выполнения кода. При работе 1С в режиме клиент-сервера, запускается несколько процессов. На компьютере пользователя запускается 1cv8.exe, на сервере 1С запускается rphost.exe, rmngr.exe и ragent.exe.
ragent.exe
Приложение ragent.exe это по сути и есть наша служба агента 1С, которую мы можем посмотреть в списке служб Windows. Данное приложение отвечает за запуск всех остальных приложений и за распределение нагрузки между рабочими rphost.
rphost.exe
Рабочих процессов может быть несколько. В версии платформы 8.2 их можно было создавать вручную. В версии 8.3 на их количество можно повлиять косвенно, увеличив количество сеансов или информационных баз на один рабочий процесс в свойствах рабочего сервера.
![Количество ИБ на процесс rphost]()
rmngr.exe
В общем случае данное приложение отвечает за выполнение регламентных заданий.
Сторона выполнения кода
После того, как мы в общих чертах описали приложения, выполняющиеся на сервере, перейдем к описанию директив препроцессора, т.е. тех самых &НаКлиенте, &НаСервере. В зависимости от того, на какой стороне выполняется код, мы имеем доступ к файлам либо пользовательского компьютера, либо к файлам на сервере. При этом очень важно понимать, что код &НаКлиенте выполняется с правами пользователя, запустившего 1С. Код &НаСервере выполняется с правами пользователя, под которым запущена служба агента 1С. Как правило, это пользователь USR1CV8, если никто этого не поменял.
&НаКлиенте
Код выполняется на том компьютере, за которым сидит пользователь и под теми правами, которые есть у пользователя. Файлы, созданные в процедурах &НаКлиенте будут созданы на пользовательском компьютере. Есть множество ограничений выполнения кода &НаКлиенте, например, здесь нельзя обращаться к СУБД. Это значит нельзя использовать как прямое создание запроса, так и косвенный запрос при обращении к ссылке через точку. Компьютер клиента может быть медленнее сервера, это следует учитывать при написании кода.
&НаСервере
Код выполняется на сервере 1С, в процессе rphost. Файлы, созданные в процедурах &НаСервере, будут сохранены на сервере и смогут быть записаны только в те папки, на которые у пользователя службы агента 1С есть доступ на запись. &НаСервере уже можно свободно писать запросы, обращаться к предопределенным данным и к реквизитам ссылки через точку.
&НаСервереБезКонтекста
Это самый интересный вариант, разберемся для начала, что такое контекст формы. Управляемая форма представляется на уровне платформы в виде XML файла описания расположения элементов и значения реквизитов формы. Соответственно, чем больше элементов на форме и чем больше данных хранится в реквизитах формы, тем больше будет контекст.
При вызове процедуры без контекста, процедура не видит реквизитов формы и не может к ним обращаться ни для чтения, ни для изменения.
И вот здесь нам как раз может помочь директива &НаСервереБезКонтекста.
В данном примере произойдет следующее: описание формы, таблица значений с 100000 строк и реквизит1 будут преобразованы в XML, отправлены на сервер. На сервере будет выполнен небольшой неявный запрос к СУБД, в значение реквизит1 будет записан результат этого запроса, все данные опять преобразуются в XML и отправятся на сервер. Учитывая, что таблица значений очень большая, то получится, что мы большой объем данных дважды в холостую передали между клиентом и сервером. Это не оптимально.
Во втором примере мы не стали передавать контекст формы, в итоге произошла только передача ссылки на элемент перечисления с сервера на клиент.
Важно понимать, сколько данных будет передано в холостую, а сколько полезно. Например, если нам нужно заполнить нашу таблицу значения, то есть самый тяжелый элемент формы, то целесообразней будет не усложнять код обходом передачи контекста, а просто передать контекст через &НаСервере.
Пример 3, предположим, у нас есть название для перечисления, которое хранится в реквизите Реквизит2, мы можем его передать в качестве параметра функции:
Ну и напоследок еще один пример, как делать не надо:
Если мы в качестве параметра передаем ЭтаФорма, то по факту мы внеконтекстный вызов превращаем в контекстный. Если без этого не обойтись, то стоит делать контекстный вызов.
PHP, Java, Delphi, 3D
![]()
![]()
Введение
На сервере размещались примерно 30-35 баз, в которых работали по 1-2 человека и пару баз были, где работали по 3-5 человек одновременно. Все это крутилось вместе с MSSQL сервером на отдельном железном сервере с одним стареньким ксеоном и 32 гб оперативы. В принципе, для этих задач железо было более чем.
Первое, на что я обратил внимание, это то, что процессор был загружен даже ночью, когда на сервере никто не работал. Полез в консоль администратора смотреть, что нагружает процессор. Оказалось, что это фоновые задачи. Для большинства баз они были не нужны и все лишнее отключил. Нагрузка процессора сразу упала до приемлемого уровня в 60-70%, а диски вообще полностью разгрузились. Я про сервер забыл на какое-то время.
Разбираемся что конкретно в rmngr.exe грузит процессор
Загрузку процессора в равной степени давал процесс rmngr.exe и rphost.exe. Rphost уже ранее был настроен и оптимизирован. Вот такие настройки дали стабильную работу без необходимости перезапускать сервер месяцами:
![Борьба с торможением]()
Нагрузку rphost давал за счет оставшихся фоновых задач и что с ним еще сделать, я не знал. А с rmngr хотелось разобраться и узнать, что конкретно пожирает процессорное время. В этом процессе собраны все процессы менеджера кластера:
![Борьба с торможением 1С]()
Есть возможность разделить сервисы менеджера кластера по разным системным процессам rmngr.exe и по pid определить, какая именно служба нагружает процессор. Включить такое разделение можно в свойствах рабочего сервера:
![Борьба с торможением 1С]()
![Борьба с торможением 1С]()
![Борьба с торможением 1С]()
В моем случае это был сервис журнала регистраций. Чтобы это узнать, дважды щелкните мышкой по процессу с необходимым pid:
![Блокирование торможения 1С]()
Пол дела сделали, нашли виновника тормозов. Я скрины делал, когда уже решил проблему, так что у меня нагрузки нет.
Я выяснил, что конкретно дает чрезмерную нагрузку на сервер. Посмотрел на объем журналов регистраций. У некоторых баз он достигал размера в 10-15 гигов. После чистки серверу стало заметно легче, нагрузка снова опустилась, но где-то до 80-90% и я на несколько месяцев забыл про сервер.
Он напомнил о себе тормозами и загрузкой процессора в 100%. Проделанные выше операции уже не давали результата. Баз стало немного больше и нужно было думать, как разгрузить сервер. Он работал на все 100% даже в нерабочее время, когда на нем не было ни одного реального пользователя. Сервис журнала регистраций потреблял 30-40% процессорного времени.
Я стал внимательно шерстить интернет на заданную тему и нашел несколько заметок. Находились люди, которые обратили внимание на чрезмерную нагрузку сервиса журнала регистраций. Как вариант решения проблемы они предлагали откатиться на старую версию ведения логов lgf вместо новой lgd. Я не знаю, что принципиально изменилось в формате ведения лога журнала регистраций, но по отзывам попробовавших, нагрузка на процессор падала. Забегая вперед скажу, что мне этот совет помог.
Переводим сервер на старый вариант ведения логов журнала регистраций
![Оптимизация работы 1С]()
В каждой папке с базой есть каталог 1Cv8Log, а в нем 2 файла: 1Cv8.lgd и 1Cv8.lgd-journal. Их надо удалить и вместо них в этой папке создать пустой файл 1Cv8.lgf. Проделать такую операцию нужно со всеми базами, где будете менять формат лога. Старый не обязательно удалять, лучше его перенести куда-нибудь, вдруг пригодятся записи из него.
После этого можно запускать службу Агента Сервера 1С:Предприятия. После перехода на старый формат журнала регистрации, нагрузка процесса rmngr.exe упала практически до 0, а сервера в целом до приемлемых 40-60%.
Заключение
Читайте также:










