
Сайт закрыт для индексирования в файле robots txt как исправить
Обновлено: 03.07.2024
Перейдите в Вебмастере на страницу Индексирование → Статистика обхода и посмотрите, какой код ответа отдавала страница на запросы робота Яндекса — в столбце Стало . Если код ответа отличается от 200 OK, убедитесь в актуальности проблемы с помощью инструмента Проверка ответа сервера.
HTTP-заголовок. Например, если он содержит \"Content-length: 0\", то робот не сможет проиндексировать такую страницу.Если в результате проверки страница отвечает кодом 200 OK и проблем с доступностью содержимого нет, то предупреждение в Вебмастере пропадет в течение нескольких дней.
Не удалось подключиться к серверу из-за ошибки DNS
Раз в сутки индексирующий робот обращается к DNS-серверам, чтобы определить IP-адрес сервера, на котором находится сайт. Если на сайте некорректно настроены DNS-записи, робот не получает IP-адрес сайта. Поэтому сайт не может быть проиндексирован и добавлен в результаты поиска.
Проверьте корректность ответа сервера индексирующему роботу. Если сайт по-прежнему недоступен, обратитесь к хостинг-провайдеру для корректировки DNS-записей вашего домена. Когда доступ к сайту появится, информация в Вебмастере обновится в течение нескольких дней.
Проблема с доступом к сайту может быть кратковременной. Если при повторной проверке ответа сервера ошибок не обнаружено, дождитесь обновления информации в Вебмастере, это должно произойти в течение нескольких дней.
Сайт закрыт для индексирования в файле robots.txt
Несколько раз в сутки индексирующий робот запрашивает файл robots.txt и обновляет информацию о нем в своей базе. Если при очередном обращении робот получил запрещающую директиву, в Вебмастере появляется соответствующее предупреждение.
Проверьте содержимое файла robots.txt . Если запрет по-прежнему присутствует, удалите его из файла. Если вы не можете сделать это самостоятельно, обратитесь к хостинг-провайдеру или регистратору доменного имени. После снятия запрета данные в Вебмастере обновятся в течение нескольких дней.
Также предупреждение может появиться в Вебмастере, если:
Такая ситуация может быть в случае, когда обе версии сайта запрещены в файле robots.txt и эта информация сохранена в базе индексирующего робота.
Когда робот снова посетит сайт и узнает об изменениях, предупреждение перестанет отображаться в Вебмастере.
Обнаружены нарушения или проблемы с безопасностью
Посмотрите описание нарушения и рекомендации по его исправлению.
- Использование SEO-текстов
- Обман пользователей мобильного интернета (платные подписки)
- Малополезный контент, спам, избыток рекламы
- Использование SEO-ссылок для продвижения («Минусинск»)
- Нежелательные программы и опасные файлы
- Майнинг криптовалют
- Размещение SEO-ссылок на страницах сайта
- Дорвей
- Запросный спам
- Скрытый текст
- Кликджекинг
- Имитация действий пользователей
- Содействие имитации действий пользователей
- Партнерская программа
- Фишинг
- SMS-мошенничество
- Клоакинг
На странице Диагностика → Безопасность и нарушения выполните следующее:
Нажмите значок , чтобы узнать подробную информацию о заражении сайта. Нажмите на название вердикта, чтобы увидеть его описание и примерный вид кода, который обрабатывается в браузере. Список возможных вердиктов.Когда вы решите проблему:
Убедитесь, что проблема устранена. Если при проверке сервис повторно обнаружит угрозу, вы сможете сообщить о ее устранении только через месяц. Дальше этот период будет увеличиваться и может составить три месяца. В Вебмастере на странице Диагностика → Безопасность и нарушения нажмите кнопку Я все исправил . Это даст дополнительный сигнал алгоритмам Яндекса о том, что сайт нужно перепроверить. Если проверка завершена успешно, со временем ограничения будут сняты, а информация о нарушениях перестанет отображаться.Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Если вы следовали рекомендациям и сайт доступен для робота, но ошибка продолжает отображаться в Вебмастере, заполните форму:
Если вы следовали рекомендациям, но ошибка продолжает отображаться в Вебмастере, заполните форму:
Robots.txt - это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие - нет.
Почему robots.txt важен для SEO-продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл robots.txt поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла robots.txt :
Какие директивы используются в robots.txt
User-agent
User-agent - основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
Для поискового робота Яндекс:
Для поискового робота Google:
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow - принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* - спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
$ - знак доллара означает конец адреса и ограничивает действие знака «*», например:
Crawl-delay
Crawl-delay - директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param .
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param , не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param :
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap - это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо обходить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
В robots.txt следует указать полный путь к странице, в которой содержится файл sitemap.
Пример правильно составленного файла robots.txt :
Как найти ошибки в robots.txt с помощью Labrika?
Labrika показывает наличие 26 видов ошибок в robots.txt – это больше, чем определяет сервис Яндекса. Отчет "Ошибки robots.txt " находится в разделе "Технический аудит" левого бокового меню. В отчете приводится содержимое строк файла robots.txt . При наличии в какой-либо директиве ошибки Labrika дает её описание.

Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом ":".
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent , поскольку она указывает, для какого поискового робота предназначены инструкции.
Не указан пользовательский агент.
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: / , то есть "не запрещать ничего".
Пример ошибки в директиве Sitemap:
Не указан путь к карте сайта.
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent . Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Найдено несколько правил вида "User-agent: *"
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущены ошибки синтаксиса, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt , если его размер не превышает 500 КБ. Допустимое количество правил в файле - 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt , все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt . Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак "$" можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Правило начинается не с символа "/" и не с символа "*".
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Правильным вариантом будет:
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив Crawl-delay ;
- некорректный формат директивы Crawl-delay .
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param , например:
В именах GET-параметров встречается два или более знака амперсанд "&" подряд:
Правило должно соответствовать виду "p0[&p1&p2&..&pn] [path]". В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: ".", "-", "/", "*", "_".
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark - маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать - открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
В большинстве случаев, если вы заблокировали сканирование в своем файле robots.txt, это является очевидной проблемой. Но есть несколько дополнительных условий, которые могут вызвать эту проблему, поэтому давайте рассмотрим следующий процесс устранения неполадок, который поможет выявлять и исправлять существующие проблемы как можно более эффективно.

Как видите, первым делом нужно спросить себя, хотите ли вы, чтобы Google индексировал URL-адрес.
Если вы не хотите, чтобы URL-адрес индексировался…
Просто добавьте атрибут noindex в метатег robots и убедитесь, что сканирование разрешено, если адрес каноничный.
Если вы заблокируете сканирование страницы, Google все равно сможет проиндексировать ее, потому что сканирование и индексирование — это разные процессы. Если Google не может сканировать страницу, они не увидят атрибут noindex в метатеге и все равно смогут проиндексировать страницу, если на ней есть ссылки.
Если URL-адрес каноникализируется на другую страницу, не добавляйте атрибут noindex в метатег robots. Просто убедитесь, что настроены правильные сигналы каноникализации, включая атрибут canonical на канонической странице, и разрешите сканирование, чтобы сигналы проходили и консолидировались правильно.
Если вы хотите, чтобы URL-адрес индексировался…
Вам нужно выяснить, почему Google не может просканировать URL-адрес и снять блокировку.
Наиболее вероятная причина — блокировка сканирования в robots.txt. Но есть несколько других сценариев, которые могут вызывать предупреждение о том, что вы заблокированы. Давайте рассмотрим их в том порядке, в котором вам, вероятно, стоит их искать.
Проверьте наличие блокировки сканирования в robots.txt
Самый простой способ выявить эту проблему — использовать средство проверкиrobots.txt в GSC, которое покажет правило блокировки.
Директива может блокировать какой-то конкретный или все user-agent. Если ваш сайт новый или был запущен недавно, вы можете поискать:
Возможно, кто-то опередил вас и уже устранил блокировку robots.txt, чем и решил проблему. Это наилучший сценарий. Однако, если проблема выглядит исправленной, но появляется снова спустя какое-то время, возможно, вы испытываете проблемы из-за периодической блокировки.
Вам нужно удалить директиву disallow, вызывающую блокировку. Способ исправления проблемы зависит от используемой вами технологии.
WordPress
Если проблема затрагивает весь ваш веб-сайт, наиболее вероятная причина в том, что вы включили параметр в WordPress, отвечающий за запрет индексации. Эта ошибка часто встречается на новых веб-сайтах и после проведения миграции. Выполните следующие действия, чтобы проверить это.
- Нажмите “Настройки” (Settings)
- Нажмите “Чтение” (Reading)
- Снимите флажок “Видимость в поисковых системах” (Search Engine Visibility).
WordPress с Yoast
Если вы используете плагинYoast SEO, вы можете напрямую отредактировать файл robots.txt, чтобы удалить директиву блокировки.
- Нажмите на Yoast SEO
- Нажмите “Инструменты” (Tools)
- Нажмите “Редактор файлов” (File editor)
WordPress с Rank Math
Как и Yoast, Rank Math позволяет напрямую редактировать файл robots.txt.
- Нажмите на Rank Math
- Нажмите “Общие настройки” (General Settings)
- Нажмите “Редактировать robots.txt” (Edit robots.txt)
FTP или хостинг
Если у вас есть FTP-доступ к сайту, вы можете напрямую отредактировать файл robots.txt, чтобы удалить директиву disallow, вызывающий проблему. Ваш хостинг-провайдер также может предоставлять вам доступ к файловому менеджеру, с помощью которого вы можете напрямую обращаться к файлу robots.txt.
Проверьте наличие периодической блокировки
Периодические проблемы труднее устранить, поскольку условия, вызывающие блокировку, могут не присутствовать в момент проверки.
Я рекомендую проверить историю вашего файла robots.txt. Например, в средстве проверки robots.txt в GSC хранятся предыдущие версии файлов. Вы можете нажать на раскрывающийся список, выбрать версию и посмотреть ее содержимое.

Вы также можете воспользоваться бета-версией отчета “Изменения” (Changes), который позволяет легко просматривать изменения содержимого между двумя разными версиями файлов.
Процесс исправления периодической блокировки будет зависеть от того, что вызывает проблему. Например, одной из возможных причин может быть общий кэш между тестовой средой и действующей средой. Файл robots.txt может содержать директиву блокировки, когда кэш используется тестовой средой. А когда кэш используется действующей средой, сайт может разрешать сканирование. В таком случае вы захотите разделить кэш или, возможно, исключить из кэша файлы з разрешением .TXT в тестовой среде.
Проверьте наличие блокировки по user-agent
Блокировка по user-agent — это блокировка, при которой сайт блокирует определенный user-agent, такого как Googlebot или AhrefsBot. Другими словами, сайт определяет конкретного бота и блокирует соответствующий user-agent.
Если вы можете просматривать страницу в своем обычном браузере, но блокируетесь после смены user-agent, это означает, что используемый вами user-agent заблокирован.
Вы можете задать конкретный user-agent с помощью инструментов разработчика Chrome. Еще один вариант — использовать расширение браузера для смены user-agent, подобное этому.
Кроме того, вы можете проверить блокировку по user-agent с помощью команды cURL. Вот как это сделать в Windows.
- Нажмите клавиши Windows+R, чтобы открыть окно “Выполнить”.
- Введите “cmd” и нажмите “ОК”.
- Введите команду cURL, подобную этой:
К сожалению, это еще один случай, когда процесс исправления будет зависеть от того, где вы найдете блокировку. Бота может блокировать множество разных систем, в том числе .htaccess, конфигурация сервера, брандмауэр, CDN или даже что-то, к чему вас нет доступа. Например то, что контролирует ваш хостинг-провайдер. Лучше всего будет обратиться к вашему хостинг-провайдеру или CDN и спросить их, откуда происходит блокировка и как вы можете устранить ее.
Например, вот два разных способа блокировки по user-agent в .htaccess, которые вам, возможно, придется искать.
Проверьте наличие блокировки по IP-адресу
Если вы подтвердили, что не заблокированы файлом robots.txt, и исключили блокировку по user-agent, то, скорее всего, это блокировка по IP-адресу.
Блокировку по IP-адресу сложно отследить. Как и в случае с блокировкой по user-agent, лучше всего будет обратиться к вашему хостинг-провайдеру или CDN и спросить их, откуда происходит блокировка и как вы можете устранить ее.
В прошлой статье «Как добавить сайт в поисковые системы» мы рассказали, как сообщить поисковым роботам о новом сайте или страницах. Но после добавления сайта в поисковые системы, он все еще может не индексироваться в Google или Яндексе. Что еще хуже, поисковые роботы сканировали сайт раньше, но теперь сайт не индексируется. Единственный выход в этой ситуации ― проверить возможные причины, которые влияют на индексацию сайта. Об этих причинах расскажем в статье.

Из статьи вы узнаете:
Сайт закрыт от индексации в Robots.txt
Одна из самых распространенных причин, из-за которой сайт не индексируется ― запрет на индексацию в файле robots.txt. Часто разработчики сайта хранят тестовую версию на отдельных доменах или поддоменах. Тестовый сайт закрывают от индексации с помощью robots.txt. Когда сайт уже готов, содержимое тестовой версии вместе с файлом robots.txt попадает на рабочий домен. Файл robots.txt забывают изменить и сайт становится недоступным для поисковых роботов.
Если сайт закрыт от индексации, содержимое файла может выглядеть следующим образом:

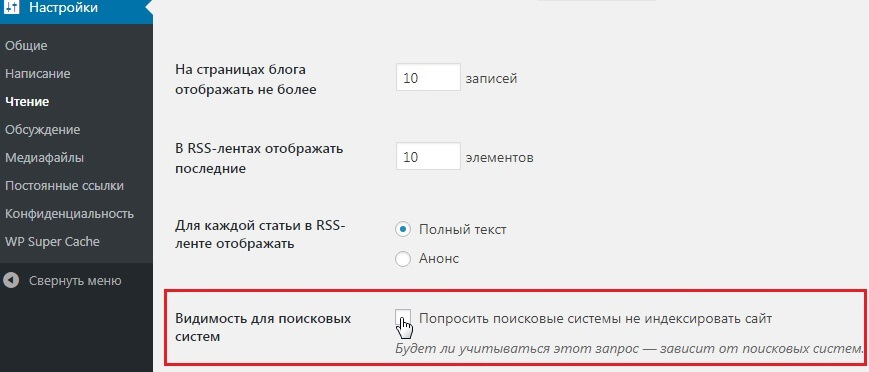
Если у вас сайт на CMS WordPress, проверьте настройки индексации в панели управления сайтом. Зайдите в раздел Настройки → Чтение. Поле Видимость для поисковых систем должно быть пустым:
Как проверить Robots.txt
При помощи следующих инструментов можно проверить не закрыт ли через robots.txt от индексации сайт или определенные страницы:
Предварительно нужно добавить сайт в панель вебмастеров Google или Яндекс, чтобы проверить robots.
Если еще не пользуетесь данными сервисами, читайте статью: Как добавить сайт в инструменты веб-мастеров
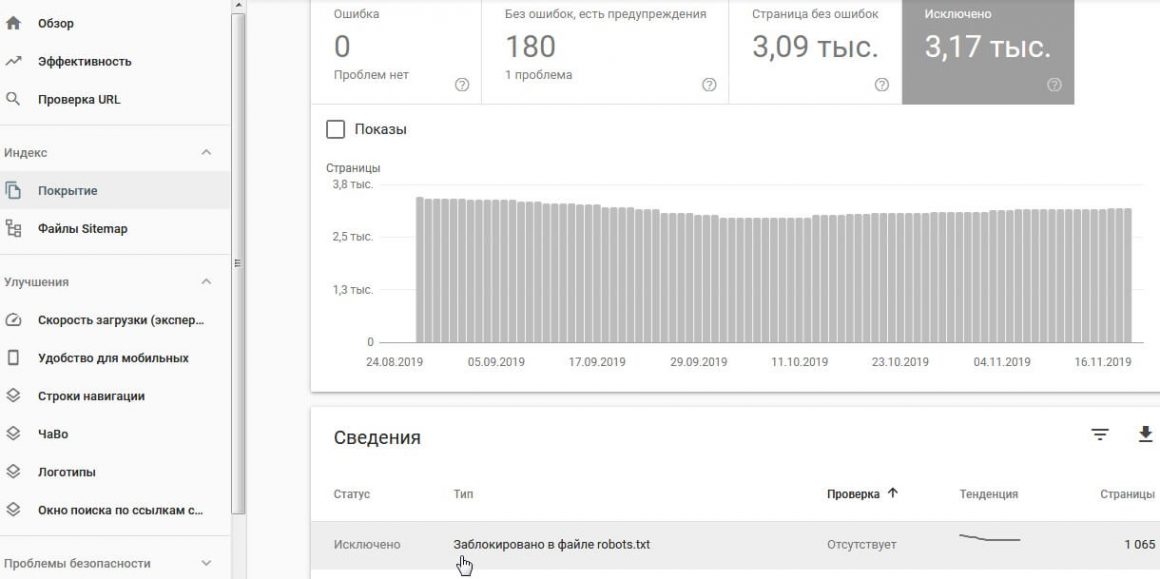
Google Search Console
Отчет Индекс → Покрытие → вкладка Исключено
Яндекс вебмастер
Отчет Диагностика → Диагностика сайта показывает наличие проблем с индексацией сайта.
После сканирования сайта или определенных страниц, в результатах отчета будут показаны страницы, которые недоступны для индексации:
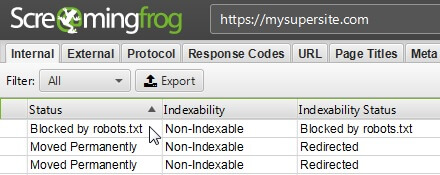
Screaming Frog SEO Spider
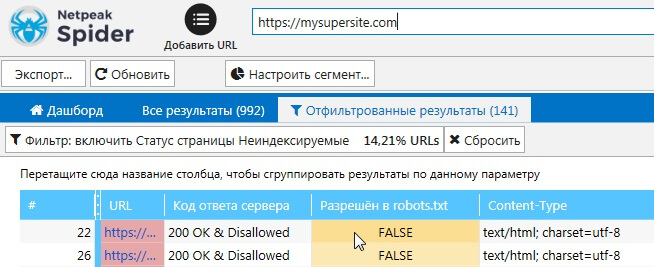
Netpeak Spider
Метатеги Robots
Проверьте наличие метатега robots в коде страницы. Его размещают между тегами <head></head>. Выглядеть этот тег может следующим образом:
Метатег robots сообщает поисковым роботам о том, что страницу индексировать не нужно.
Как проверить метатеги Robots
Google Search Console
Отчет Индекс → Покрытие → вкладка Исключено
Обнаружить страницы, которые закрыты от индексации с помощью метатегов robots, можно с помощью программ для аудита внутренней оптимизации сайта.
Screaming Frog SEO Spider
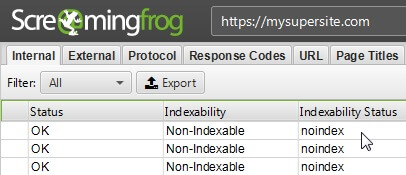
Netpeak Spider
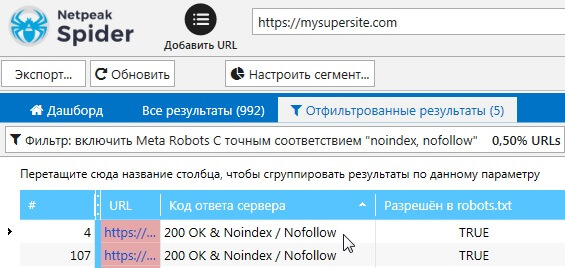
Файл .htaccess
С помощью некоторых правил в .htaccess можно закрыть сайт от индексации. Например, можно закрыть доступ для всех посетителей, кроме нужного IP адреса:
Или можно разрешить доступ всем, кроме нужного IP:
Проверьте файл .htaccess на вашем сервере, возможно в нем прописаны запрещающие правила для индексирования.
Более подробно узнать о директивах и правилах можно в нашей статье: Файл htaccess.
Rel Canonical
Рассмотрим на примере две страницы, которые имеют одинаковое содержание:


X‑Robots-Tag
Этот тег можно использовать в конфигурации сервера. На серверах Apache он добавляется в файл .htaccess, на серверах Nginx в файл conf.
Рассмотрим на примере, как выглядит запрет на индексацию файлов .doc через X-Robots-Tag:
Фрагмент кода в файле .htaccess для сервера Apache
Фрагмент кода в файле conf для сервера Nginx
Как проверить наличие X‑Robots-Tag на страницах сайта
Плагин Web Developer для браузеров:



Долгий ответ сервера
Время ответа сервера ― это время, за которое запрос клиента в браузере доходит до сервера и клиент получает ответ сервера. Время отклика измеряется в TTFB (Time To First Byte) ― время до первого байта, или сколько миллисекунд прошло между вашим запросом и ответом сервера. Google рекомендует стремиться к тому, чтобы время отклика было менее 200 миллисекунд. TTFB больше 500 мс уже является проблемой.
Если при обращении поискового робота к серверу, он получает долгий ответ, то робот может не просканировать часть страниц..
Как проверить время ответа сервера
Проверить время ответа сервера можно с помощью сервисов:
Возможные причины долгого ответа сервера
Среди возможных причин можно выделить следующие:
- недостаточный объем ресурсов сервера (слабый процессор, недостаточно памяти);
- не оптимизирована работа сервера;
- отсутствие оптимизации скорости загрузки сайта. Не минимизированы файлы CSS/JS, не сжаты изображения и т.д.
- отсутствие кэширования.
Полезные статьи по теме:
Если вы оптимизировали скорость загрузки сайта, но у вас остались проблемы с долгим ответом сервера, стоит попробовать другие хостинги. Например, мы предлагаем виртуальный хостинг с серверами в Украине, Нидерландах и США . Ваш сайт более требовательный и нужно больше мощностей? Не проблема. У нас есть VIP пакеты с большим объемом ресурсов или можно взять VPS.
Возьмите хостинг на тест и проверьте сами. 30 дней бесплатно!
Пробуйте надежный хостинг с аптаймом 99,5%!
Наша теплая поддержка на связи 24/7

Неверный ответ сервера
Проверьте код ответа сервера. Убедитесь, что нужные вам страницы отдают код 200.
Этот код означает, что страница доступна на сервере.
Как проверить ответ сервера
Проверить ответ сервера можно с помощью инструментов:
Также можно использовать различные плагины для браузеров или можно проверить в самом браузере ― F12+вкладка Network.
Некачественный контент
Если ваши страницы содержат контент, который не имеет ценности для пользователя, то поисковые роботы могут не индексировать их. В англоязычных статьях можно встретить термин thin content, который описывает данные страницы.
Примером такого контента может быть:
- дублированный контент;
- скопированный контент;
- автоматически сгенерированный контент;
- неинформативные страницы с партнерскими ссылками;
- дорвеи.
Проблемы на стороне поисковых систем
Как говорится ― и на старуху бывает проруха. На стороне поисковых систем тоже могут возникать проблемы. Например, в начале июля в Google возникли проблемы с индексацией нового контента. Об этом можно прочитать в новостях:
В Google оперативно реагируют и исправляют проблемы.
The indexing issues from yesterday have been resolved. Thank you for your patience.
— Google Search Central (@googlesearchc) June 3, 2020
Итоги
Подытожим причины, из-за которых страницы сайта могут не индексироваться:
- Сайт закрыт от индексации через
- robots.txt
- метатеги robots
- файл .htaccess
- X-robots-tag
Руслан Иванов
Работает в сфере SEO с 2007 года. Занимается продвижением HOSTiQ с 2016. Пишет статьи по SEO.
Читайте также: