
Sap индекс не существует в системе бд oracle
Обновлено: 30.06.2024
Оптимайзер использует индекс LOT со следующими полями:
MANDT
LOT_ID
ACCOUNTING_CODE
VALUATION_AREA
VALUATION_CLASS
Я считаю, что он должен использовать другой индекс, SEC с полями:
MANDT
CONTEXT
ACCOUNTING_CODE
VALUATION_AREA
VALUATION_CLASS
PORTFOLIO
ACCOUNT_GROUP
SECURITY_ACCOUNT
SECURITY_ID
А index adviser говорит вообще о третьем индексе FUT с полями:
MANDT
CONTEXT
ACCOUNTING_CODE
VALUATION_AREA
VALUATION_CLASS
POSITION_ACCOUNT
SECURITY_ID
FLAG_LONG_SHORT
Я решил попробовать прописать в коде хинты на использование нужного мне индекса. Прочитал САПовские ноты
724614 - DB2-z/OS: Database hints in Open SQL as of Kernel Rel 6.20
150037 - Database hints in Open SQL for DB6 (DB2 for LUW)
868888 - DB6: Optimization Guidelines
так же еще нашел ноты, где прямо в коде указывался хинт для db2. Честно говоря, как я не пробовал и не менял синтаксис, все равно хинт не работает и берет старый индекс.
Исходный запрос в АБАПе выглядит так:
сейчас у меня такой синтаксис у хинта:
пробовал менять DB2 на DB6, INDEX на SAP_INDEX, так же пробовал вот такой синтаксис (это в саповских нотах встречал)
ничего не помогло.
Так же встретил упоминание, что должен быть включен какой-то параметр:
| автор |
|---|
| DB2 ZPARM OPTHINTS must be set to YES |
но как там же написано, это до 9-й версии, выше 9-ки он включен по умолчанию
Я не SAP специалист, но если у вас DB2 for Linux, Unix and Windows, а не DB2 for Z/OS, то вам везде надо использовать DB6, а не DB2.
Судя по нотам, в ктороых описывается синтакис хинтов для DB2 for LUW в SAP, у вас должно быть:
%_HINTS DB6 '<IXSCAN TABLE=''DIFT_POS_IDENT'' INDEX=''"DIFT_POS_IDENT
Марк огромнейшее вам спасибо, с алиасом 'T_00' все заработало, теперь запрос летает!

На план запроса, конечно, много чего влияет, но вкратце так.
Статистику по индексам можно посмотреть в:
там кардинальность (кол-во разных значений) как всего индекса, так и первых одного, двух, трех и четырех полей.
В вашем случае эти индексы отличаются по большому счету 2-мя первыми полями, поэтому посмотрите, какие для них будут
FIRSTKEYCARD, FIRST2KEYCARD, FULLKEYCARD.
Кроме того, оно может смотреть на статистику распределения данных в этих полях
Большего, наверное, оно не может использовать (ну, еще может цену i/o исходя из размеров индексов), т.к. у вас параметры используются, т.е. на момент компиляции запроса непонятно, какие там актуальные значения будут.
Индексы Oracle обеспечивают быстрый доступ к строкам таблиц, сохраняя отсортированные значения указанных столбцов и используя эти отсортированные значения для быстрого нахождения ассоциированных строк таблицы . Индексы позволяют находить строку с определенным значением столбца, просматривая при этом лишь небольшую часть общего объема строк таблицы. Таким образом правильное использование индексов сокращает до минимума количество дорогостоящих операций ввода-вывода.
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса – ускорение запросов – довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблиц, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже.
Вообще говоря, если таблицы в основном используются для чтения (выборки) информации, как в хранилищах данных, то лучше иметь много индексов. Если база данных относится к типу OLTP, с большим количеством вставок, обновлений и удалений, то лучше обойтись меньшим числом индексов.
Если только вам не нужно обращаться к большинству сток таблицы, индексированные запросы обеспечивают более быстрое получение результатов, чем запросы, не использующие индексы. Не существует ограничений на количество индексов, которые могут относиться к одной таблице Oracle, но, как упоминалось ранее, от их количества зависит производительность. Индекс полностью прозрачен для пользователя – т.е. оператор SQL пользователя не должен изменяться в результате создания индексов. Однако разработчикам приложений для построения эффективных запросов следует хорошо представлять себе , что такое индексы и как они работают.
Индексы могут относиться к нескольким типам, наиболее важные из которых перечислены ниже:
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце – обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы – это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы – это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы – индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных, следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индекс имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4-5% данных таблицы. Альтернативной использования индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного колюча Oracle автоматически создаст индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, стоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец в котором количество строк с одинаковым значением минимально.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса: например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Схемы индексации Oracle
Oracle предлагает несколько схем индексации, соответствующих требованиям различных типов приложений. На фазе проектирования после тщательного анализа конкретных требований приложения, необходимо выбрать правильный тип индекса.
(B*tree)
В реализации индексов на основе B-деревьев используется концепция сбалансированного (на что указывает буква ‘B’ (balanced)) дерева поиска в качестве основы структуры индекса. В Oracle имеется собственный вариант B-дерева. Это обычные индексы, создаваемые по умолчанию, когда вы применяете оператора CREATE INDEX.
Индексы на основе B-деревьев структурированы в форме обратного дерева, где блоки верхнего уровня называются блоками ветвей (branch blocks), а блоки нижнего уровня – листовыми блоками (leaf blocks). В иерархии узлов все узлы кроме вершины, или корневого узла, имеют родительский узел и могут иметь ноль или более дочерних узлов. Если глубина древовидной структуры , т.е. количество уровней, одинакова от каждого листового блока до корневого узла, то такое дерево называется сбалансированным, или B-деревом.
B-деревья автоматически поддерживают необходимый уровень индекса по размеру таблицы. B-деревья также гарантируют, что индексные блоки всегда будут заполнены не меньше, чем наполовину, и менее, чем на 100%. B-деревья допускают операции выборки, вставки и удаления с очень небольшим количеством операций ввода-вывода на один оператор. Большинство B-деревьев имеет всего три и менее уровней. При использовании B-дерева нужно читать только блоки B-дерева, так что количество операций ввода-вывода будет ограничено числом уровней B-дерева (скажем, тремя) плюс две операции ввода-вывода на выполнение обновления или удаления (одна для чтения и одна для записи). Для выполнения поиска по B-дереву понадоисят всего три или менее обращений к диску.
Реализация B-дерева от Oracle – всегда сохраняет дерево сбалансированным. Листовые блоки содержат по два элемента: индексированные значения столбца и соответствующий идентификатор ROWID для строки, которая содержит это значение столбца. ROWID – уникальный указатель Oracle, идентифицирующий физическое местоположение строки и обеспечивающий самый быстрый способ доступа к строке в базе данных Oracle. Сканирование индекса быстро дает ROWID строки, и отсюда можно быстро получить к ней доступ непосредственно. Если запрос нуждается лишь в значении индексированного столбца, то конечно, последний шаг исключается, поскольку извлекать дополнительные данные, кроме прочитанных из индекса, не потребуется.
Оценка размера индекса
Для оценки размера нового индекса можно использовать пакет DBMS_SPACE. Процедуре CREATE_INDEX_COST этого пакета потребуется передать оператор DDL, создающий индекс, в качестве атрибута.
Обратите внимание на отличие между атрибутами, касающимися размера, в процедуре CREATE_INDEX_COST:
- Used_bytes показывает количество байт, которыми представлены данные индекса;
- Alloc_bytes показывает количество байт, которое займет индекс в табличном пространстве после его создания.
Создание индекса
Индекс создается с помощью оператора CREATE INDEX
По умолчанию Oracle допускает дублирование значения в столбцах индекса, которые также называются ключевыми столбцами. Однако можно специфицировать уникальный индекс, что исключит дублирование значений столбца в нескольких строках.
Для создания уникального индекса служит оператор CREATE UNIQUE INDEX.
Специальные типы индексов
Нормальный или типовой индекс, который создается в базе данных, называется индексом кучи (heap index), или неупорядоченным индексом. Oracle также предоставляет несколько специальных типов индексов для специфических нужд.
Битовые индексы (bitmap indexes)
Битовые индексы используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью (число уникальных записей в таблице мало) при при большом размере таблицы. Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных.
Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев.
| Индексы B-деревьев | Битовые индексы |
| Хороши для данных с высокой кардинальностью | Хороши для данных с низкой кардинальностью |
| Хороши для баз данных OLTP | Хороши для приложений хранилищ данных OLAP |
| Занимают много места | Используют, относительно мало места |
| Легко обновляются | Трудно обновляются |
Для создания битового индекса используется оператор
Иногда можно наблюдать значительное повышение производительности при замене обычных индексов B-дерева на битовые в некоторых очень крупных таблицах. Однако каждый элемент битового индекса открывает огромное количество строк в таблице, так что когда данные обновляются,вставляются или удаляются из таблицы, то необходимые обновления битового индекса очень велики., и сам индекс может существенно увеличиться в размере. Единственный способ обойти это увеличение размера индекса с последующим падением производительности заключается в регулярной его перестройке. Битовый индекс – не слишком разумная альтернатива для таблиц, подвергающихся большому количеству вставок, удалений и обновлений.
Индексы с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет создания индекса со сжатым ключом. Всякий раз, когда индексируемый ключ имеет повторяющийся компонент, или же создается уникальный многостолбцовый индекс, получается выигрыш от использования сжатия ключа. Вот пример:
Приведенный выше оператор сжимает все дублированные вхождения индексированного ключа в листовом блоке индекса (на уровне 1).
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы и сохраняют результат в индексе. Когда конструкция WHERE содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER
Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции, поскольку база данных создаст его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Секционированные индексы
Секционированные индексы используются для индексации секционированных таблиц. Oracle предлагает два типа индексов для таких таблиц: локальные и глобальные.
Существенное различие между ними заключается в том, что локальные индексы основаны на разделах таблицы, по которой они созданы. Если таблица секционирована на 12 разделов по диапазонам дат, то индексы также будут распределены по тем же 12 разделам. Другими словами, между разделами индексов и разделами таблиц существует соответствие «один к одному». Такого соответствия нет между глобальными индексами и разделами таблицы, потому что глобальные индексы секционируются независимо от базовых таблиц.
В следующих разделах будут раскрыт важные различия между управлением глобального секционированными индексами и локально секционированными индексами.
Глобальные индексы
Глобальные индексы на секционированных таблицах могут быть как секционированными, так и несекционированными. Глобальные несекционированные индексы подобны обычным индексам Oracle для несекционированных таблиц. Для создания таких индексов применяется обычный синтаксис CREATE INDEX.
Ниже приведен пример глобального индекса на таблице ticket_sales:
Обратите внимание, что управление глобально секционированными индексами требует серьезных усилий. Всякий раз, когда происходит какое-т о действие DDL над секционированной таблицей, ее глобальные индексы требуют перестройки. Действия DDL над лежащей в основе таблице помечают глобальные индексы как недействительные. По умолчанию любая операция обслуживания секционированной таблицы делает недействительными глобальные индексы.
Давайте в качестве примера воспользуемся таблицей ticket_sales, чтобы разобраться, почему это так. Предположим, что вы ежеквартально уничтожаете самый старый раздел, чтобы освободить место для нового раздела, в который поступят данные за новый квартал. Когда уничтожается раздел, относящийся к таблице ticket_sales, глобальные индексы могут стать недействительными, потому что часть данных, на которые они указывают, перестают существовать. Чтобы предотвратить такое объявление недействительным индекса из-за уничтожения раздела, необходимо использовать опцию UPDATE GLOBAL INDEXES вместе с оператором DROP PARTITION:
Если не включить оператор UPDATE GLOBAL INDEXES, то все глобальные индексы станут недействительными. Опцию UPDATE GLOBAL INDEXES можно также использовать при добавлении, объединении, обмене, слиянии, перемещении, разделении или усечении секционированных таблиц. Разумеется, с помощью ALTER INDEX..REBUILD можно перестраивать любой индекс, который становится недействительным, но эта опция также требует дополнительных затрат времени и обслуживания.
При небольшом количестве листовых блоков индекса, что приводит к высокой конкуренции Oracle рекомендует использовать глобальные индексы с хэш-секционированием. Синтаксис для создания хэш-секционированного глобального индекса подобен тому, что применяется для хэш-секционированной таблицы. Например, следующий оператор создает хэш-секционированный глобальный индекс:
Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имею отношение «один к одному» с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же, как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов – Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
Невидимые индексы
По умолчанию оптимизатор «видит» все индексы. Тем не менее, можно создать невидимый индекс, который оптимизатор не обнаруживает и не принимает во внимание при создании плана выполнения оператора. Невидимый индекс можно применять в качестве временного индекса для определенных операций или его тестирования перед тем, как сделать его «официальным». Вдобавок, иногда объявления индекса невидимым можно использовать в качестве альтернативы уничтожению индекса или объявлению его недоступным. Сделать индекс невидимым можно временно, чтобы протестировать эффект от его уничтожения.
База данных поддерживает невидимый индекс точно так же, как и нормальный (видимый) индекс. После объявления индекса невидимым, его и все прочие невидимые индексы можно сделать вновь видимым для оптимизатора, установив значение параметра optimizer_use_invisible_index равным TRUE на уровне сеанса или всей системы. Значением этого параметра по умолчанию является FALSE, а это означает, что оптимизатор по умолчанию не может использовать невидимые индексы.
Создание невидимого индекса.
Чтобы сделать индекс невидимым, к оператору CRETE INDEX нужно добавить конструкцию INVISIBLE.
С помощью команды ALTER INDEX можно превратить существующий индекс в невидимый.
Создадим индекс для таблицы ZKRE_PRODUCTS. С помощью транзакции SE11 заходим в режим редактирования таблицы и нажимаем кнопку изменить. Затем Goto-->Indexes. Учтем, что для ключевых полей индексы создаваться не могут.

Индекс— объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Появилось окно, где отображаются индексы для данной таблицы. Сейчас индексов нет. Нажимаем кнопку создать.

Появилось еще одно модальное окно где необходимо ввести имя нашего индекса.

Нажимаем Ввод и появляется следующий экран где задаются атрибуты индекса. Вводим краткое описание и нажимаем кнопку TablesFields.

Появилась форма в которой выбираем нужное нам поле для индексации


Теги : Index
Обсуждения : 1 комментарий
Комментарии
Tomatos
Для ключевых полей создается автоматически индекс первичного ключа с именем "0", который содержит все ключевые поля, в указанном порядке
Задача настоящей статьи - восполнить отсутствующую в других статьях информацию, необходимую для практической реализации доступа к внешним базам данных с помощью EXEC SQL. Вы узнаете, как настраивать соединение с базой данных Oracle, открывать и закрывать соединение, форматировать данные с учетом нужной кодировки. Также будут рассмотрены некоторые операторы EXEC SQL.
Зачастую бывает необходимо обратиться к таблицам во внешних базах данных таких как DB2, Microsoft SQL Server, Oracle и т.д. SAP NetWeaver AS ABAP предлагает три модели программирования на SQL: Open SQL, ADBC, EXEC SQL.В настоящей статье рассматривается практическая работа с EXEC SQL. Типичной сферой применения SQL - команд EXEC являются статические SQL-операторы, выполняемые в отношении объектов базы данных, которые не определены в ABAP-словаре, а также SQL-операторы, использующие специальные функции БД, которые не могут быть реализованы посредством Open SQL. Следует помнить, что таблицы базы данных/ракурсы, к которым осуществляется доступ, в ABAP словаре не описывают.
Более подробно теоретическая часть, посвященная EXEC SQL, изложена в статье Юргена Кисснера (Juergen Kissner) “Организация доступа к удаленной БД и параллельная обработка транзакций в ABAP”. По ADBC есть статья “Вся SQL-функциональность базы данных ABAP Database Connectivity (ADBC)». Авторы Тобиас Веннер и Томас Ропп.
Задача настоящей статьи - восполнить отсутствующую в вышеуказанных статьях информацию, необходимую для практической реализации доступа к внешним базам данных с помощью EXEC SQL. Вы узнаете, как настраивать соединение с базой данных Oracle, открывать и закрывать соединение, форматировать данные с учетом нужной кодировки. Также будут рассмотрены некоторые операторы EXEC SQL.
1.Настройка соединения с Oracle.
Записи соединений с внешними базами ведутся в таблице DBCON: транзакция DBCO или DBACOCKPIT (Рис.1).
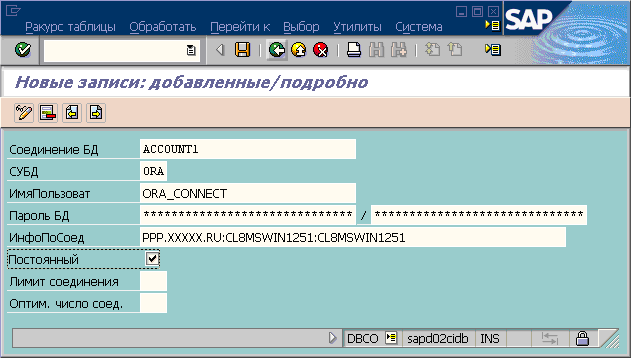
Рис.1 Записи соединений
DBCON-CON_NAME(Соединение БД) – логическое имя соединения с базой данных. Здесь указывается имя соединения, использующееся для вторичных соединений. Например, можно создать соединение с именем ‘ACCOUNT2’ для тестовой системы и соединение ‘ACCOUNT1’ для продуктивной системы.
Читайте также: