
Сопроцессор что это в компьютере
Обновлено: 07.07.2024
Привет, дорогие друзья. Вы не задумывались, почему мы можем просто вставить несколько видеокарт и использовать их вместе, а вот с процессором такое проделать нельзя? Я знаю, что есть двухпроцессорные материнские платы, но если на плате всего один слот, то что же делать? Если у меня на плате один слот PCI-E, но я очень хочу две видеокарты, я все равно могу подцепить вторую через райзер. А вот процессор не могу. Или все же могу?
Сопроцессоры 101
Давайте вообще разберемся с тем, что из себя представляют сопроцессоры и почему же так мало информации о них. Вопрос это весьма и весьма сложный, хоть и кажется простым на первый взгляд. Но от того и интереснее в нем разобраться.
Я начал свои поиски, так как (каюсь) сам не был слишком знаком с сопроцессорами. При запросах в ру-сегменте интернета я получал примерно вот такие вещи:
Потому было принято идти в сегмент забугорный, так сказать ненашенский.
Согласно классическому определению, сопроцессором обозначается устройство делегирующее себе часть задач основного процессора (не равно центрального), например операций с плавающей точкой, графикой, строками, etc. В общем, помощник грубо говоря. Это было ясно с самого начала, как итог использования сопроцессора мы получаем большую производительность в каких-то конкретных задачах или широком круге задач. Ясно-понятно-хорошо.
А что дальше-то? Откуда брать? Куда это подключать? Как это выглядит? Как использовать?
Чтобы лучше в этом разобраться нужно немного окунуться в пучины истории. Первыми юзерами таких штук был конструкторы/инженеры, использующие IBM PC, и владельцы мейнфреймов. Тот же оригинальный IBM PC из бородатых годов имел отдельный сокет для установки сопроцессора для операций с плавающей точкой.
В современном мире изменилось немного. В потомках оригинальных IBM PC тоже имеется сокет для установки сопроцессора, но скорее формально — чаще всего туда ставят видеокарты, к слову, являющиеся графическими сопроцессорами. Но этим дело далеко не ограничивается, прошу обратить внимание на такую штуку как Xeon Phi.
Xeon Phi — x86 процессор, использующий в качестве интерфейса подключения PCI-E. Пожалуй, эти штуки ближе к видеокартам, чем к классическим CPU. Они имеют сумасшедшее количество ядер, используют тот же интерфейс, и не очень высокие частоты. Но работают на той же самой архитектуре, что и процессоры у большинства людей в домашних компах (не считая нюансов).
О Xeon Phi, к слову, информации уже гораздо больше. Известно, что на них не может быть запущена операционная система, и они могут выступать только в качестве помощника основному процессору. Также известно, что заведется сие чудо техники не в каждом компьютере. У этого парня например не получилось:
А вот у этого получилось:
Также известно, что данное устройство хорошо себя показывает лишь в узком спектре задач и для бытового пользования годится весьма не весьма. К сожалению, я такой вещицей не владею, но если она появится, то я обязательно найду способ тщательно её протестировать и попробовать её хоть как-то использовать. Говорят, что находятся индивиды, которые занимаются на этой штуке майнингом крипты, но мне, пожалуй, это применение не очень интересно.
Если выдумаете, что одними Xeon Phi все ограничивается, то спешу разочаровать (ну или обрадовать) — не ограничивается. Правда, речь пойдет о немного других штуках.
Есть такое понятие как кластер — это когда несколько компьютеров работают сообща. В рассматриваемом нами случае PCI/PCI-E шина используется лишь для запитки. По сути, это компьютер внутри компьютера, материнка подключенная к материнке, и чтобы суммировать мощность, нужно использовать отдельный коммутатор. Конечно, для бытовых нужд такое приспособить непросто, но все же можно, например, рендерить на таких кластерах или решать какие-то научные задачи. Очень удобно, я считаю. Так, один парень смог на кластере из нескольких PlayStation 3 заниматься расчетами активности черных дыр .
Как правило основными заказчиками таких кластеров являются серьезные промышленные предприятия.
Хотя согласитесь, было бы здорово, если бы цены на такие приспособы не были бы такими кусачими, а установка походила бы на установку второго зеона в двухпроцессорный хуанан со всеми вытекающими преимуществами в виде отвала чипсета . Поставил себе шесть Core2Duo и уже вроде как и райзен не нужен.

Специализированные процессоры ASIC для конкретных областей — один из способов «перезапустить» закон Мура и преодолеть ограничения универсальных CPU общего назначения. Сейчас это очень перспективная область развития микроэлектроники. Собственные проекты есть у Google, Amazon и других компаний. Например, Google выпускает тензорные процессоры Google TPU, а в дата-центрах Amazon работают чипы AWS Graviton на ядре ARM.
Первые представляют собой ASIC для нейронных сетей, вторые — 64-битные ARM общего назначения для оптимизации соотношения цены и производительности в рабочих нагрузках, требующих больших вычислительных ресурсов.
Еще один класс универсальных ASIC, где в последнее время идут активные эксперименты, — это специализированные сопроцессоры для обработки данных (data processing unit, DPU), разновидность умных сетевых карт (SmartNIC). Вот некоторые представители этого вида: Nvidia BlueField 2, Fungible и Pensando DSC-25.
Что они из себя представляют? Для каких задач подходят? Давайте посмотрим.

Что такое SmartNIC
Обычные сетевые карты (NIC) построены на интегральной схеме специального назначения (ASIC), которая спроектирована на работу Ethernet-контроллером. Часто эти микросхемы проектируют для выполнения вторичных функций. Например, контроллеры Mellanox ConnectX также поддерживают высокоскоростной протокол Infiniband. Это отличные специализированные чипы, но их функциональность нельзя изменить.
В отличие от простых сетевых карт, SmartNIC допускает загрузку в контроллер дополнительного программного обеспечения уже самим пользователем, то есть после покупки аппаратного обеспечения. Это расширяет или изменяет функциональность ASIC. Процедура чем-то похожа на покупку смартфона и установку на него различных приложений.
Чтобы такое стало возможным, SmartNIC требует повышенной вычислительной мощности и дополнительной памяти, по сравнению с обычными NIC. Речь идет о более мощных многоядерных ARM-процессорах, установке специализированных сетевых процессоров (flow processing cores, FPC) и программируемых пользователем вентильных матриц (FPGA).

Схема Xilinx Alveo U25
На платах SmartNIC зачастую выделяют отдельное ядро ARM для уровня управления, некоторые платы допускают загрузку модифицированного ядра Linux. Эти специализированные ядра ARM распределяют нагрузку по остальным вычислительным модулям, собирают статистику и логи, отслеживают состояние SmartNIC. Непосредственно сетевой трафик через них не проходит.
Для каких задач подходят DPU
Сопроцессоры для обработки данных (DPU) — типичное расширение сетевых плат SmartNIC, к которым добавляют функциональность NVMe или NVMe over Fabrics (NVMe-oF). Такая плата позволяет разгрузить центральный процессор, забрав себе все задачи ввода-вывода.
Для примера можно рассмотреть устройство SmartNIC микроконтроллера Broadcom NetXtreme-S BCM58800. Он работает как программируемая сетевая карта и поддерживает (NVMe-oF).

Архитектура карты Broadcom Stingray на базе микроконтроллера BCM58800
В Broadcom Stingray установлено восемь ядер ARM v8 A72 на частоте 3 ГГц, и это, возможно, самая высокая тактовая частота среди ARM на любых SmartNIC. Сетевая карта комплектуется до 16 ГБ памяти DDR4. На аппаратном уровне поддерживается шифрование на скорости до 90 Гбит/с и некоторые функции по обработке данных: дедупликация, удаляющее кодирование RAID 5 и RAID 6.
На схеме также отмечен ускоритель TruFlow. Это патентованная технология Broadcom для аппаратного ускорения сетевых операций, в том числе операций программного коммутатора Open vSwitch (OvS) и др.
Nvidia BlueField 2
Nvidia традиционно специализируется на производстве графических ускорителей, но в этом году она завершила покупку разработчика специализированных микросхем Mellanox за $7 млрд, так что теперь всерьез нацеливается на новую для себя сферу — рынок высокопроизводительных вычислений в ЦОД.
Mellanox — один из первопроходцев в разработке умных сетевых карт, и ведущим продуктом сейчас считается плата BlueField 2, которая позиционируется как Data Processing Unit (DPU).
Архитектура Nvidia/Mellanox BlueField 2
Ключевые приложения DPU:
- Виртуальные и аппаратные облачные среды.
- Хранилища NVMe в виртуальных машинах.
- Приложения Network Function Virtualization (NFV).
- Приложения ИБ, такие как Deep Packet Inspection (DPI).
- Микросерверы для граничных вычислений
Здесь реализован массив из восьми ядер ARM v8 A72, контроллер памяти DDR4 и двухпортовый сетевой адаптер Ethernet или InfiniBand (два на 100 Гбит/с или один 200 Гбит/с), плюс специализированные ASIC-блоки для ускорения различных функций: регулярных выражений, хэширования SHA-2 и др.
Pensando

Один из новых стартапов в области SmartNIC — компания Pensando, которая предлагает на рынке так называемые Distributed Services Card, это Pensando DSC-25 (для корпоративных серверов) и Pensando DSC-100 (для облачных провайдеров).
Pensando DSC-25 и Pensando DSC-100
Основным продуктом считается Pensando DSC-25. Это карта с одним DPU-процессором P4 (Capri) для обработки данных, дополнительными ARM-ядрами и аппаратными ускорителями отдельных функций.

Схема Pensando DSC-25
Основной процессор DPU и ARM-ядра через общую шину межсоединения подключены к контроллеру PCIe и массиву оперативной памяти (до 4 ГБ).
Отдельные аппаратные ускорители здесь называются Service Processing Offloads. Как и в карте Mellanox, они берут на себя шифрование, обработку дисковых операций и другие задачи.
Fungible

Высокоуровневая архитектура Fungible
Еще один многообещающий стартап Fungible утверждает, что это именно он изобрел термин DPU в 2016 году. Компания заявляет о выпуске процессоров под названием F1 DPU, но фактическая архитектура этих чипов неизвестна. Fungible пока может продемонстрировать только общие схемы, как на иллюстрации выше. Некоторые специалисты высказывают подозрение, что Fungible просто использует хайповый термин DPU для привлечения венчурных инвестиций. Кстати, на различных раундах в нее уже вложено $500 млн.
Что дальше?
Вокруг концепции DPU в последнее время много хайпа. В этом обзоре упомянуты не все компании, которые пытаются выйти на этот рынок (Intel, Xilinx и другие).
Факт в том, что концепция SmartNIC появилась уже давно, а крупные компании вроде Google и Amazon разработали и внедрили собственные внутренние решения. В то же время был сформирован рынок, который заполнили сторонние игроки.
Сейчас появляется второе поколение SmartNIC на основе FPGA. Технология программируемых пользователем вентильных матриц созрела до такой степени, что теперь может стать основополагающей технологией для SmartNIC. Десять лет назад рынок буквально наводнили графические ускорители — это была первая значительная волна в технологиях аппаратного ускорения. Теперь, когда FPGA преодолели рубеж в три миллиона логических блоков, эти микросхемы тесно интегрируются с другими составными блоками для обработки сетевого трафика, памятью, системой хранения и вычислительными ядрами. Технологии SmartNIC и FPGA отлично дополняют друг друга.
На этом фоне можно ожидать вторую волну аппаратных ускорителей. И тогда к комплекту CPU + GPU добавится третий элемент — DPU. Сопроцессор для обработки данных освободит серверные процессоры от инфраструктурных задач. Исследования показывают, что в сильно виртуализированных средах сетевые процессы, такие как транзакции OvS, могут занимать более 30% процессорного времени на хосте. Представьте, что дисковые операции, шифрование, DPI и сложная маршрутизация выполняются отдельным модулем. Это потенциально снимет значительную часть нагрузки с CPU.
Стартапы вроде Pensando и Fungible со своими инновациями столкнулись на рынке с технологическими лидерами, такими как Xilinx, Intel, Broadcom и Nvidia. Это технологическое соревнование, за которым всегда интересно наблюдать.
Сегодня любой процессор представляет собой сложную смесь ядер различных типов, которые либо выполняют основную часть работы, выполняют специализированные задачи, либо взаимодействуют друг с другом для достижения наилучшего возможного результата при выполнении различных процессов. В любом случае, есть различия между ускорителем и сопроцессором в качестве поддерживающих ядер. Читайте дальше, чтобы понять, что они из себя представляют.

Совершенно очевидно, что ЦП не может выполнять работу сам по себе, существуют обычные операции, которые компьютер выполняет постоянно, в которых универсальный процессор неэффективен, но прежде всего мы должны понять, что это означает и почему они необходимы. поддержка чипов.
При разработке новой архитектуры существует ряд параметров, которые обозначают пределы, которые инженеры не должны превышать, включая такие вещи, как тип библиотек, используемых для проектирования, сколько будет потреблять чип, что это будет? его размер, но особенно то, какие типичные проблемы он пытается решить с помощью нового процессора. Именно здесь определяются не только основные блоки, но также сопроцессоры и ускорители, которые будут его частью.
Первые процессоры поддержки, которые размещаются в архитектуре, легко определить, обычно это те, которые были разработаны для предыдущих архитектур той же марки или, в противном случае, те, которые были лицензированы третьими сторонами. Последние, с другой стороны, рождаются во время разработки, в результате запросов клиентов или из-за типа решаемой проблемы, требующей нового типа аппаратного модуля.
Что такое сопроцессор?

Хотя означающее самоочевидно, важно помнить, что если у нас есть несколько ядер, работающих вместе для решения одной и той же проблемы, общей для распределенных частей, то мы говорим о каждой из единиц процесса, действующих совместно с другими. . И да, мы знаем, что пришло вам в голову, но когда у нас есть несколько ядер ЦП, решающих конкретную проблему, мы говорим о тех, которые не выполняют основной процесс, действуют как сопроцессоры других.
Поддерживающие микросхемы традиционно назывались сопроцессорами, хотя самым известным сопроцессором в истории ПК является математический сопроцессор, который был не чем иным, как тем, что позже стало блоком с плавающей запятой или FPU, который был полностью отделен от основного процессора. Таким образом, в сопроцессоре обычно отсутствует процесс для захвата инструкций из памяти, а скорее требуется другой процессор для отправки инструкций и данных для обработки. Работа сопроцессора? Решите эту часть программы и как можно быстрее верните результат главному процессору.
Пока сопроцессор выполняет свою работу, основное ядро может использовать полученную мощность для выполнения других задач, но, поскольку процесс выполняется вместе, будет достигнута точка, в которой оно не сможет для продолжения, пока сопроцессор или сопроцессоры не выполнят возложенную на них задачу.
Что такое ускоритель?
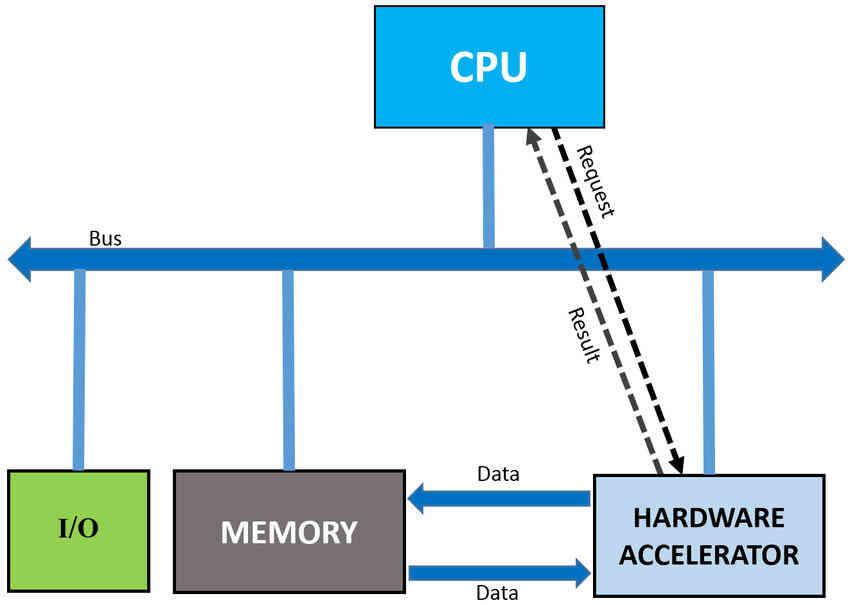
Технически ускоритель - это сопроцессор, но с большей независимостью, чем они, поскольку они не отвечают за выполнение процесса в целом, а им назначают весь процесс, который полностью игнорируется ЦП, кроме как для получения конечного результата или для того, чтобы знать что задача выполнена.
Поскольку ускоритель полностью отделен от процессора, он полностью асинхронен с ним. Что мы имеем в виду? Дело в том, что ускоритель в отличие от сопроцессора не работает в сочетании с основным процессором системы. Это позволяет ускорить выполнение вашей части кода, что означает выполнение его с гораздо большей скоростью и, следовательно, за меньшее время. Конечно, это требует серьезных изменений в архитектуре.
Прежде всего, сопроцессор может совместно использовать части блока управления и даже регистры или доступ к общей памяти с ЦП. Когда все эти элементы являются общими, они могут создавать перегрузку при доступе к ним, в результате чего тот или иной блок будет остановлен в ожидании использования этих ресурсов. Как вы понимаете, этого не может произойти в ускорителе, поэтому его данные и инструкции, несмотря на то, что они предоставляются процессором, предназначены для того, чтобы быть доступными вам в 100% случаев, поэтому многие ускорители представляют собой законченные процессоры, у которых есть свои собственные локальные Оперативная память внутри.
Если ускоритель лучше, зачем сопроцессор?

Во вступлении к этой статье мы говорили, что все связано с бюджетом, который у архитекторов есть при реализации решения проблемы, и одна вещь, которая обычно не принимается во внимание, - это коммуникационные инфраструктуры между различными элементами, а также блоки, которые являются частью цикла команд каждого процессора, но не отвечают за обработку чисел на высокой скорости.
На уровне маркетинга очень легко продать мощность процессора в цифрах, это легко понять людям, которые могут провести порядковое или кардинальное сравнение на основе указанных данных. Реальность такова, что в настоящее время инфраструктуры в любом процессоре - это то, что занимает больше всего места, и поэтому решение о реализации чего-либо в виде сопроцессора или ускорителя принимается только из-за этих ограничений.
Примером являются тензорные ядра и NVIDIAоба блока NVDLA служат одной и той же цели, но в то время как первый является сопроцессором в блоке шейдера, который разделяет регистры и блок управления с остальной частью GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР шейдерный блок, в случае второго - это сам процессор. Неудивительно, что аббревиатура DLA означает Deep Learning Accelerator.

Сопроцессора представляет собой компьютер процессор , используемый в дополнение к функции основного процессора (далее ЦП ). Операции , выполняемые с помощью сопроцессора может быть плавающей точкой арифметики, графики , обработки сигналов , обработки строк , криптографию или ввода / вывода интерфейса с периферийными устройствами. Выгружая задачи, интенсивно использующие процессор , с главного процессора , сопроцессоры могут повысить производительность системы. Сопроцессоры позволяют настраивать линейку компьютеров, так что клиентам, которым не нужна дополнительная производительность, не нужно за нее платить.
Содержание
Сопроцессоры различаются по степени автономности. Некоторые (например, FPU ) полагаются на прямое управление с помощью инструкций сопроцессора , встроенных в поток инструкций CPU . Другие - самостоятельные процессоры, способные работать асинхронно; они все еще не оптимизированы для кода общего назначения или неспособны к этому из-за ограниченного набора инструкций, ориентированных на ускорение конкретных задач . Обычно они управляются прямым доступом к памяти (DMA), когда хост-процессор создает список команд . PlayStation 2 «ы эмоции двигателясодержал необычный DSP- подобный векторный блок SIMD, способный работать в обоих режимах.
Чтобы максимально эффективно использовать процессорное время мэйнфрейма , задачи ввода / вывода были делегированы отдельным системам, называемым канальным вводом / выводом . Мэйнфрейм вообще не потребовал бы никакой обработки ввода-вывода, вместо этого просто установил бы параметры для операции ввода или вывода, а затем подал бы сигнал канальному процессору на выполнение всей операции. Выделив относительно простые подпроцессоры для обработки трудоемких операций форматирования и обработки ввода-вывода, общая производительность системы была улучшена.
По мере развития микропроцессоров стоимость интеграции арифметических функций с плавающей запятой в процессор снижалась. Высокая скорость процессора также затрудняла реализацию тесно интегрированного сопроцессора. Отдельно упакованные математические сопроцессоры сейчас редко встречаются в настольных компьютерах . Однако спрос на специальный графический сопроцессор вырос, в частности, из-за растущего спроса на реалистичную трехмерную графику в компьютерных играх .
Оригинальный IBM PC включал в себя разъем для сопроцессора Intel 8087 с плавающей запятой (он же FPU ), который был популярным вариантом для людей, использующих ПК для автоматизированного проектирования или сложных математических вычислений. В этой архитектуре сопроцессор ускоряет арифметические операции с плавающей запятой в 50 раз. Например, пользователи, которые использовали ПК только для обработки текстов, сэкономили на высокой стоимости сопроцессора, который не увеличил бы производительность операций обработки текста.
8087 был тесно интегрирован с 8086 /8088 и ответил на плавающую точку машинного кода коды операций , вставленных в потоке в 8088 команд. Процессор 8088 без 8087 не мог бы интерпретировать эти инструкции, требуя отдельных версий программ для систем с FPU и не-FPU или, по крайней мере, теста во время выполнения для обнаружения FPU и выбора соответствующих функций математической библиотеки.

Другим сопроцессором для центрального процессора 8086/8088 был сопроцессор ввода / вывода 8089 . Он использовал ту же технику программирования, что и 8087, для операций ввода / вывода, таких как передача данных из памяти на периферийное устройство, и тем самым снижая нагрузку на ЦП. Но IBM не использовала его при разработке IBM PC, и Intel прекратила разработку сопроцессоров этого типа.
Intel 80386 микропроцессор используется дополнительный «математический сопроцессор» (The 80387 ) для выполнения операций с плавающей точкой непосредственно в аппаратных средствах . Процессор Intel 80486DX включал в себя оборудование с плавающей запятой. Intel выпустила недорогой процессор 80486SX, в котором не было оборудования с плавающей запятой, а также продала сопроцессор 80487SX, который отключал основной процессор при установке, поскольку 80487SX был полным 80486DX с другим набором контактов. [1]
Процессоры Intel более поздней версии, чем 80486, интегрировали оборудование с плавающей запятой в чип основного процессора; прогресс в интеграции устранил ценовое преимущество продажи процессора с плавающей запятой в качестве дополнительного элемента. Было бы очень трудно адаптировать методы печатной платы, подходящие для тактовой частоты процессора 75 МГц, для соответствия стандартам временной задержки, энергопотребления и радиочастотных помех, требуемых при тактовых частотах в диапазоне гигагерц. Эти встроенные в кристалл процессоры с плавающей запятой по-прежнему называются сопроцессорами, поскольку они работают параллельно с основным ЦП.
В семействе Motorola 68000 были сопроцессоры 68881/68882, которые обеспечивали такое же ускорение с плавающей запятой, что и процессоры Intel. Компьютеры, использующие семейство 68000, но не оборудованные аппаратным процессором с плавающей запятой, могли улавливать и эмулировать инструкции с плавающей запятой в программном обеспечении, что, хотя и работало медленнее, позволяло распространять одну двоичную версию программы для обоих случаев. Сопроцессор управления памятью 68451 был разработан для работы с процессором 68020. [3]
С 2001 [Обновить] года специальные графические процессоры ( GPU ) в виде видеокарт стали обычным явлением. Некоторые модели звуковых карт были оснащены специальными процессорами, обеспечивающими цифровое многоканальное микширование и эффекты DSP в реальном времени еще с 1990 по 1994 год ( типичными примерами являются Gravis Ultrasound и Sound Blaster AWE32 ), а Sound Blaster Audigy и Sound Blaster X -Fi - более свежие примеры.
В 2006 году AGEIA анонсировала дополнительную плату для компьютеров, которую назвала PhysX PPU . PhysX был разработан для выполнения сложных физических вычислений, чтобы центральному и графическому процессорам не приходилось выполнять эти трудоемкие вычисления. Он был разработан для видеоигр, хотя теоретически для него могут быть разработаны другие математические применения. В 2008 году Nvidia приобрела компанию и отказалась от линейки карт PhysX; функциональность была добавлена через программное обеспечение, позволяющее их графическим процессорам отображать PhysX на ядрах, обычно используемых для обработки графики, с использованием программного обеспечения движка Nvidia PhysX.
В 2006 году BigFoot Systems представила карту расширения PCI, которую они назвали KillerNIC, которая запускала собственное специальное ядро Linux на FreeScale PowerQUICC, работающем на частоте 400 МГц, называя чип FreeScale Network Processing Unit или NPU.
SpursEngine является медиа-ориентированные карты расширения с сопроцессором на основе Cell микроархитектуры. В SPU , сами по себе являются векторные сопроцессоры.
В 2008 году Khronos Group выпустила OpenCL с целью поддержки процессоров общего назначения, графических процессоров ATI / AMD и Nvidia (и других ускорителей) с помощью единого общего языка для вычислительных ядер .
В 2010-х годах в некоторых мобильных вычислительных устройствах концентратор датчиков был реализован в качестве сопроцессора. Примеры сопроцессоров, используемых для интеграции сенсоров в мобильные устройства, включают сопроцессоры движения Apple M7 и M8 , ядро сенсора Qualcomm Snapdragon и Qualcomm Hexagon , а также блок голографической обработки для Microsoft HoloLens .
В 2012 году Intel анонсировала сопроцессор Intel Xeon Phi . [4]
С 2016 [Обновить] года различные компании разрабатывают сопроцессоры, нацеленные на ускорение искусственных нейронных сетей для зрения и других когнитивных задач (например, устройства обработки зрения , TrueNorth и Zeroth ), а с 2018 года такие чипы AI есть в смартфонах, таких как Apple, и несколько производителей телефонов Android.
Со временем процессоры имеют тенденцию к росту, чтобы вбирать в себя функции наиболее популярных сопроцессоров. FPU теперь считаются неотъемлемой частью основного конвейера процессоров; Блоки SIMD дали мультимедиа ускорение, взяв на себя роль различных карт ускорителей DSP ; и даже графические процессоры интегрированы в кристаллы ЦП. Тем не менее, специализированные блоки остаются популярными вдали от настольных компьютеров, из-за дополнительной мощности и позволяют продолжать развитие независимо от линейки продуктов с основными процессорами.
Читайте также: