
Транзакционные файлы что это
Обновлено: 03.07.2024
Производители СУБД и корпоративных платформ активно соревнуются в разработке новых функциональных возможностей своих продуктов. Однако многие проблемы, такие как совместная обработка данных или управление их жизненным циклом, могут быть решены проще и эффективнее посредством технологий управления данными.
Увеличение объема информации и развитие информационных систем – два взаимосвязанных процесса: рост объемов данных требует развития средств их обработки, совершенствование которых стимулирует обработку все больших массивов данных. Сегодня практически в каждой более-менее крупной организации деятельность строится вокруг корпоративной информационной системы (а зачастую и нескольких систем), большинство из которых построены на основе реляционных систем управления базами данных по трехзвенной архитектуре: клиентские приложения – серверы приложений – серверы баз данных. При разработке каждой такой системы приходится решать ряд проблем, связанных с управлением данными.
Проблема отслеживания изменений
Одной из наиболее сложных сегодня остается задача управления конкурентным доступом к данным. Обычно под решением данной задачи подразумевают защиту от проблем «грязного» чтения (dirty read), неповторяющегося чтения (non-repeatable read) и потерянного обновления (lost update). Для решения проблемы «грязного» чтения, которая заключается в чтении данных, записанных отмененной операцией, вполне может быть достаточно средств сервера баз данных, реализующих стандартные транзакции.Решение же проблемы неповторяющегося чтения (состоящей в отличии результатов первичного и последующего чтения данных одним клиентом, не изменявшим их), а также проблемы потерянного обновления (возникающей при одновременном изменении различными клиентами одного и того же значения элемента, при котором более раннее изменение теряется) средствами транзакций на уровне только сервера баз данных и/или сервера приложений эффективно лишь в отношении серверных задач обработки данных, которые выполняются на сервере приложений или сервере баз данных в фоновом режиме по заранее заданному алгоритму и без активного участия пользователя.
Однако защиту от аналогичных проблем требуется обеспечивать и при ручной обработке данных пользователями с использованием их клиентских приложений. Основное отличие здесь заключается в том, что каждый пользователь работает не напрямую с данными, содержащимися в СУБД, а с некоторой их локальной копией, загруженной в клиентское приложение. Зачастую это приводит к тому, что когда два пользователя сохраняют изменения в одном и том же элементе данных (причем их исправления могли касаться разных его свойств), более раннее изменение теряется, причем клиент, чье изменение потеряно, может некоторое время этого даже не видеть.
Считается, что защита от подобного рода проблем должна обеспечиваться логикой приложения за счет более активного использования транзакций. Но не все проблемы конкурентного доступа можно обойти программно за счет дополнительных проверок и транзакций. И ключевой фактор здесь – человек. Невозможно выделить программным образом последовательность чтений и записей пользователем данных, составляющих атомарную операцию. Следовательно, нельзя и откатить такую транзакцию при изменении данных чтения – система просто не в состоянии определить, какое количество последних действий пользователя образуют единое целое, да и какие из прочитанных им данных учел пользователь при принятии решения. Что же остается делать?
Как и во всех случаях, когда предотвратить проблему невозможно, все усилия должны быть сконцентрированы на ее отслеживании. Причем в корпоративных системах управление конкурентным доступом – далеко не единственное направление, где требуется решение задачи отслеживания изменений. Другой очень важной проблемой является сложность выявления данных, на основе которых сформированы другие, как правило, обобщенные данные. В качестве характерного примера можно привести различного рода отчеты, формируемые на основании данных из системы и не сохраняющиеся в ней. Определить в будущем источники формирования каждого сводного показателя отчета можно лишь при условии неизменности исходных данных.
В качестве одного из решений здесь возможно введение административного запрета редактирования данных, по которым сформированы отчеты, однако это далеко не всегда возможно, да и не слишком удобно. А с другой стороны, вполне обычным является процесс, когда после сдачи первичного отчета в последующем, при выявлении неточностей, эти неточности исправляются, а на основании исправленных данных формируется уточненный отчет (таков, к примеру, порядок в отношении налоговой отчетности).
В общем виде целью отслеживания изменений является возможность получения данных, существовавших в системе (локальной копии данных) на момент принятия пользователем решения об изменении данных, формирования отчета и т.п. Кроме того, зачастую также требуется наличие информации об авторстве изменений и исправлений. Причем сведения нужны относительно всех модификаций, а не только последних, так как ошибки в данных (умышленные или неумышленные) могли быть внесены ранее, а другие пользователи в дальнейшем основывались на них.
Особенно актуальной данная задача выглядит в свете повсеместного перехода от бумажных информационных ресурсов к электронным ресурсам, в которых требуется придание данным юридической значимости (посредством ЭЦП). Отдельно следует отметить, что речь здесь идет не о придании юридической значимости отдельным документам, передаваемым между организациями, а о формировании полностью юридически значимого массива данных, любая выборка из которого также имеет официальный статус. Естественно, что при этом должна обеспечиваться персональная ответственность лиц, формирующих данный информационный массив. Особенно это важно для государственных систем, где каждый служащий имеет свои полномочия и несет соответствующую ответственность.
Задача отслеживания модификаций данных также крайне важна для обеспечения их синхронизации при совместной обработке данных в нескольких информационных системах. Если системы работают последовательно (то есть данные из первой системы служат сырьем для второй), то все относительно просто. Сложнее дело обстоит с организацией параллельной обработки данных, например, при управлении мастер-данными. Здесь широко применяется централизованная модель, при которой все мастер-данные хранятся в выделенной системе, однако это не всегда удобно и возможно, особенно при взаимодействии информационных систем различных организаций. Кроме того, такая модель не основана на технологии управления данными, а представляет собой лишь архитектурное решение.
Если вернуться к государственным информационным системам, то организация параллельной обработки данных в электронных информационных ресурсах, каждый из которых содержит юридически значимую информацию, является одним из основных инфраструктурных элементов подхода к построению электронного правительства.
Транзакционные и нетранзакционные данные
Для решения задачи отслеживания всех производимых модификаций разумно использовать технологии темпоральных баз данных. Но на сегодняшний день полноценные промышленные реализации темпоральных баз данных, по сути, отсутствуют. Что любопытно, они вполне могли появиться лет пять-десять назад, но в силу модных тенденций в сфере управления данными, сместивших акценты в сторону поддержки XML и решения задач интеграции, темпоральные технологии остались в стороне. Некоторые современные СУБД содержат специализированные механизмы, которые позволяют использовать фоновую версионность значений атрибутов. Однако ее далеко не всегда удобно использовать.Но важнее другое – реляционная модель данных предоставляет весьма широкие средства, которые вполне могут быть использованы для решения перечисленных выше проблем. Может быть, и не стоит искусственно расширять эту модель дополнительной временной размерностью?
Данные, обрабатываемые в каждой информационной системе, можно разделить на транзакционные и нетранзакционные. Транзакционные данные – это данные, каждая запись которых относится к фиксированному моменту времени и содержит сведения, фиксированные на данный момент времени, не изменяющиеся в будущем. Соответственно, нетранзакционными являются все остальные данные.
Транзакционные данные обычно представляют собой повторяющиеся примеры событий, явлений, происшествий одного и того же типа. Сюда относятся все заявки, счета, накладные – да и вообще все документы (как сущности), так как все они зафиксированы (это уже оформленные документы) и привязаны к некоторому моменту времени (времени их составления или регистрации).
Нетранзакционные данные, которые часто называют справочными или базовыми данными, представляют собой списки однотипных объектов: сущностей, предметов и абстрактных категорий. Как правило, это разнообразного рода справочники и классификаторы, другими словами – мастер-данные или, как частный случай, нормативно-справочная информация.
Нетрудно заметить, что связь между этими двумя категориями данных, как правило, односторонняя: при описании транзакционных схем могут использоваться как транзакционные, так и нетранзакционные данные, а при описании же нетранзакционных данных, как правило, используются только нетранзакционные данные. Например, при составлении накладной используются несколько справочников (контрагентов, номенклатуры), а основанием для накладной может служить, например, счет.
С другой стороны, если не принимать во внимание конкретное информационное представление данных и процедуры их архивации и утилизации, то можно утверждать, что количество информационных объектов транзакционных данных постоянно увеличивается, так как регистрация каждого нового события вызывает появление новой записи. В то же время, количество информационных объектов нетранзакционных данных является относительно постоянным.
Значение каждой записи транзакционных данных, как правило, остается неизменным с момента ее фиксации. Исключения составляют случаи коррекции записи по причине неточностей или ошибок, что, кстати, в информационной системе обычно рассматривается как не совсем корректное действие – коррекция должна проводится отдельной операцией. Нетранзакционные данные не привязаны к конкретному моменту времени, но в течение своего жизненного цикла они могут определяться, а значения атрибутов каждого элемента таких данных могут изменяться.
Таким образом, проблема отслеживания модификаций, в основном, актуальна для нетранзакционных данных. Для транзакционных данных она имеет смысл лишь в части отслеживания исправлений.
Одной из основных причин появления проблем, связанных с представлением нетранзакционных данных, является то, что нетранзакционные данные часто воспринимаются как условно-постоянные и, как следствие, имеющие статичное представление в базах данных. Для записи данных в SQL используются операторы вставки (insert), изменения (update) и удаления (delete). Как правило, эти операторы используются весьма прямолинейно: появился новый объект – вставили новую запись, изменились его характеристики – обновили их, исчез объект – удалили запись. Справедливости ради, следует отметить, что для повышения ссылочной целостности вместо операции удаления в настоящее время все больше используется обновление дополнительного атрибута (статуса) записи.
Однако операция обновления тоже не безобидна. Прекращение существования объекта – это новая информация, и результатом должно быть не общее сокращение информации в базе данных, а наоборот, ее увеличение. Аналогично, при изменении характеристик одного из объектов поступает новая информация, и общий объем информации в базе данных также должен увеличиваться. То же самое можно сказать и про исправления. Другими словами, информационные элементы должны хранить информацию о жизненном цикле реальных объектов, а не повторять его.
Используя термины SQL, можно говорить, что для прекращения существования объектов и изменения их характеристик недопустимо использование операторов delete и update. Эти операторы являются служебными и должны использоваться исключительно в служебных целях: для перемещения, архивации и утилизации массивов данных. Таким образом, можно сделать вывод, что все данные, циркулирующие в базе данных, должны быть транзакционными; нетранзакционные данные должны представляться в виде цепочки транзакционных данных.
Темпоральность в реляционной СУБД
Транзакционные данные, как правило, ассоциированы только с одним значением времени. Для обеспечения же управления конкурентным доступом и реализации раздельного отражения в состоянии базы данных операций исправления требуется использование битемпоральной модели, включающей действительное и транзакционное время. Действительное время – это время, указывающее на время актуальности существования и значений атрибутов реальных объектов. Транзакционное время – время внесения новых сведений об объекте в информационную систему.Двойная темпоральность позволяет не просто более точно описать модель системы, но и определить операцию исправления. Для этого в дополнение к существующей записи с неправильным значением вносится корректирующая запись с тем же действительным временем, текущим транзакционным временем и исправленными значениями.
Кроме расширения возможностей представления данных в информационной системе, использование битемпоральной модели позволяет обеспечить управление конкурентным доступом в части защиты от проблем неповторяющегося чтения. Это достигается за счет того, что в рамках одной операции (транзакции) при обработке данных используется ограничение на выборку данных: используются только записи, внесенные в информационную систему до начала транзакции.
Двойная темпоральность данных в сочетании с управлением данных в режиме «только вставка» позволяет обеспечивать хранение вместе с данными сведений о пользователе, внесшем изменения, а также его электронную цифровую подпись, рассчитанную на основании внесенных данных. Это позволяет организовать юридически значимое хранилище данных с разделением персональной ответственности за их содержание.
Кроме того, данная технология позволяет обеспечить возможность отслеживания данных, которые существовали в системе до внесения пользователем изменений. Аналогичным же образом можно отследить первичные данные, находившиеся в системе при формировании вторичных данных, при условии сохранения вместе с вторичными данными штампа времени, по состоянию на которое они сформированы.
При этом следует отметить, что в трехзвенной архитектуре здесь возможны конфликтные ситуации, связанные с тем, что между временем чтения данных и моментом внесения изменений в данные могут быть внесены изменения другим пользователем. Чтобы защититься от этого, имеет смысл использовать два транзакционных времени: основное транзакционное время – транзакционное время внесения изменений; и транзакционное время чтения данных – для отслеживания основного транзакционного времени данных, на основе которых производилась обработка.
В данной модели в чистом виде невозможно отобразить исчезновение (удаление) объекта. Однако, кроме появления, исчезновения элементов данных и изменения их атрибутов, с ними могут происходить также такие события, как объединение, присоединение, разделение, выделение, реорганизация. Для реализации требуемых операций необходимо использовать дополнительную таблицу, причем соответствующее событие должно отображаться в ней в виде перехода (вектора) с указанием предшествующего идентификатора (null при появлении элемента) и нового идентификатора (null при исчезновении элемента). Используя подобный подход, несколькими взаимосвязанными записями можно отразить в состоянии базы данных любую из перечисленных выше операций.
Существенной проблемой является обеспечение мягкой модернизации информационных систем вместе с соответствующими взаимосвязями между ними. В первую очередь, сложность составляет необходимость модернизации метаданных и обеспечение работы с данными прошлых периодов в соответствующей схеме данных. Важное значение имеет также сохранение связанности систем при изменении структур данных без дополнительной разработки, а лишь за счет соответствующей перенастройки связей.
По сути, кроме жизненного цикла элемента данных и жизненного цикла его атрибутов, имеет смысл рассматривать еще два жизненных цикла метаданных: жизненный цикл классов (таблиц) и жизненный цикл атрибутов классов (столбцов таблиц). Для их описания требуются дополнительные таблицы, в которых так же, как и для отражения в состоянии базы данных операций над элементами данных, используются переходы.

На рисунке изображена структура для представления данных по описанной технологии. Для связи записей выделена дополнительная таблица транзакций, в которой хранятся транзакционное время чтения, транзакционное время записи, сведения об авторе и его электронная цифровая подпись. Это дополнительно позволяет осуществлять ручной откат транзакций, а также в некоторой степени сократить объем памяти, требуемой для хранения информации о пользователях и ЭЦП. Все таблицы элементов объединены в единую таблицу, которая содержит поле, указывающее на класс элемента. Также в одну таблицу объединены и все таблицы значений, и эта таблица содержит поля ссылок на таблицу элементов и таблицу атрибутов.
Заключение
К преимуществам данной модели можно отнести значительное повышение уровня ссылочной целостности, раздельное отражениев состоянии базы данных операций изменения и исправления данных, возможность организации частичной защиты от проблем конкурентного доступа к данным, решение проблемы отслеживания источников вторичных данных, обеспечение отслеживания авторства и возможность формирования юридически значимого массива данных.Темпоральная организация данных позволяет значительно упростить их совместное редактирование в нескольких информационных системах, а темпоральная организация метаданных – предоставить возможность мягкой модернизации структур данных и обеспечение работы с данными прошлых периодов в соответствующей схеме данных.
Описанный подход может быть применим при построении систем самого различного назначения, в первую очередь, систем (подсистем) управления мастер-данными или нормативно-справочной информацией. В частности, использование описанной технологии может решить множество проблем при построении одного из основных компонентов электронного правительства – Системы реестров государственных услуг.
Описание различных аспектов программирования транзакционной NTFS см. в следующих разделах:
Какие изменения в файлах являются транзакционными
Большинство изменений файлов, таких как изменения в содержимом файлов, потоках, точках повторного анализа, атрибутах и пространстве имен файловой системы, являются транзакционными. При выполнении одного из этих изменений в транзакционном файле обрабатывается изменение, изолированное от других транзакций, и изменение отменяется, если откат транзакции выполнен.
Изменения, которые не влияют на содержимое файла, метаданные или пространство имен файловой системы, такие как изменения в сжатии или дефрагментации, не являются транзакционными. Эти изменения не изолированы от других транзакций и не отменяются, если откат транзакции выполнен.
Сжатие
Не удается изменить состояние сжатия файла, открытого в транзакции.
Создание файла или каталога
Файл или каталог, созданный в транзакции, невидим для всех элементов за пределами текущей транзакции. За пределами этой транзакции любая попытка создать файл с тем же именем завершается ошибкой с _ _ конфликтом транзакций, что позволяет эффективно передать имя файла при фиксации или откате транзакции.
Удаление файла
Файл или каталог, который удаляется путем вызова функции делетефилетрансактед , остается видимым для всех внешних читателей.
Все дескрипторы транзакций файла должны быть закрыты до завершения транзакции. Если дескрипторы не закрыты должным образом, удаление не выполняется. Все открытые дескрипторы файла должны быть закрыты перед выполнением фиксации, чтобы считаться частью транзакции. это обусловлено тем, что система фактически не удаляет файл до тех пор, пока не будет закрыт последний обработчик, даже если операция не является транзакционной, как часть подсистемы Windows файлового ввода-вывода.
Удаление каталога
Каталог, который удаляется путем вызова функции ремоведиректоритрансактед , остается видимым для всех внешних читателей.
Те же ограничения существуют для открытых дескрипторов операций с каталогами транзакций, как и в файлах. Дополнительные сведения см. в разделе Удаление файла.
Проблемы с блокировкой каталога
Если файл изменяется в транзакции, все компоненты каталога пути к файлу называются закрепленными по переименованию до завершения транзакции. Это значит, что система не позволяет переименование, пока транзакция не будет зафиксирована или отменена. Попытка переименования каталога, который является предком файла, который был изменен в текущей транзакции, завершится ошибкой, и ошибка не сможет _ _ прервать _ транзакционную _ зависимость.
Перечисление каталогов
Содержимое каталога может быть изменено, когда перечисление выполняется в результате использования интерфейсов API для перечисления, например функций финдфирстфилетрансактед и FindNextFile .
Изменения в каталоге за пределами транзакции не изолируются от транзакции и сразу же отображаются в пределах транзакции. Например, если модуль записи, не поддерживающей транзакции, добавляет файл в каталог, новый файл сразу же становится видимым внутри транзакции таким образом, что вызов функции финдфирстфилетрансактед или FindNextFile вернет новый файл.
Изменения, вносимые в каталог внутри транзакции, изолируются до тех пор, пока не будет выполнена фиксация транзакции. Например, файл, созданный в каталоге как часть транзакции. Нетранзакционный модуль чтения, вызывающий функцию FindFirstFile или FindNextFile , не увидит созданный файл до тех пор, пока не будет выполнена фиксация транзакции.
Сопоставленные в памяти файлы
Клиент должен вызвать функцию флушвиевоффиле , закрыть объект сопоставления файлов и закрыть этот файл перед фиксацией связанной транзакции в размещенном в памяти файле.
Именованные потоки
Вторичный поток нельзя переименовать в транзакции.
Переименование файла или каталога
Чтобы переименовать файл как транзакционную операцию, вызовите мовефилетрансактед , чтобы переместить файл.
Точки повторного синтаксического анализа
Изменения точек повторного анализа являются транзакционными. Это означает, что если новая точка повторного анализа назначена файлу в транзакции, она не будет видна другим транзакциям. Аналогично, изменения или удаление существующей точки повторного анализа не видны до фиксации.
Коды ошибок
Диспетчер транзакций ядра (KTM) использует коды системных ошибок в диапазоне от 6700 до 6799. транзакционная NTFS (TxF) использует Windows коды ошибок в диапазоне от 6800 до 6899. Дополнительные сведения см. в разделе WinError. h и коды системных ошибок (6000-8199).
Зашифрованная файловая система
TxF не поддерживает операции с файлами EFS. Для транзакций нельзя открыть зашифрованный с помощью EFS файл. Вызов функции креатефилетрансактед для файла EFS завершится ошибкой, если _ _ _ _ в _ транзакции не разрешена ошибка EFS. Аналогично, вызов функции енкриптфиле для файла в транзакции завершится ошибкой, если _ _ _ _ в _ транзакции не разрешена ошибка EFS.
Функции файлового ввода-вывода и транзакционная NTFS
TxF предоставляет новые транзакционные функции, которые принимают имя файла и изменяет поведение существующих функций API файлового ввода-вывода, которые принимают маркер файла.
Транзакционные функции
Если не выполняется вызов одной из следующих транзакционных функций вместо ее версии, не поддерживающей транзакции, операция не будет транзакционной:
Функции файлового ввода-вывода, измененные системой TxF
В следующей таблице перечислены функции, поведение которых зависит от транзакционной NTFS. Например, поведение функции ReadFile будет зависеть от того, был ли параметр HFile создан функцией CreateFile или функцией креатефилетрансактед .

Заметка! T-SQL – это расширение языка SQL, реализованное в Microsoft SQL Server. Более подробно об этом можете почитать в статье – Что такое T-SQL. Подробное описание для начинающих.
Транзакции в T-SQL
Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе, или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены. Другими словами, если одна команда или инструкция внутри транзакции завершилась с ошибкой, то все, что было отработано перед ней, также отменяется, даже если предыдущие команды завершились успешно.
Транзакции очень полезны и просто незаменимы в тех случаях, когда Вам необходимо реализовывать бизнес логику в базе данных Microsoft SQL Server, которая предполагает многошаговые операции, где каждый шаг логически связан с другими шагами.
По сути каждая отдельная инструкция языка T-SQL является транзакцией, это называется «Автоматическое принятие транзакций» или «Неявные транзакции», но также есть и явные транзакции, это когда мы сами явно начинаем транзакцию и также явно заканчиваем ее, т.е. делаем все это с помощью специальных команд.
Чтобы понять, как работают транзакции и для чего они нужны, давайте рассмотрим классический пример, который наглядно показывает необходимость использования транзакций.
Допустим, у Вас есть хранимая процедура, которая осуществляет перевод средств с одного счета на другой, соответственно, как минимум у Вас будет две операции в этой процедуре, снятие средств, и зачисление средств, например, две инструкции UPDATE.
Но в каждой из этих операций может возникнуть ошибка и инструкция не выполнится. А теперь представьте, что первая инструкция снимает деньги, она выполнилась успешно, вторая инструкция зачисляет деньги и в ней возникла ошибка, без транзакции снятые деньги просто потеряются, так как они никуда не будут зачислены.
Чтобы этого не допустить, все SQL инструкции, которые логически что-то объединяет, в данном случае все операции, связанные с переводом средств, пишут внутри транзакции, и тогда, если наступит подобная ситуация, все изменения будут отменены, т.е. деньги вернутся обратно на счет.
Транзакции – это отличный механизм обеспечения целостности данных.
Свойства транзакции
У транзакции есть 4 очень важных свойства:
- Атомарность – все команды в транзакции либо полностью выполняются, и соответственно, фиксируются все изменения данных, либо ничего не выполняется и ничего не фиксируется;
- Согласованность – данные, в случае успешного выполнения транзакции, должны соблюдать все установленные правила в части различных ограничений, первичных и внешних ключей, определенных в базе данных;
- Изоляция – механизм предоставления доступа к данным. Транзакция изолирует данные, с которыми она работает, для того чтобы другие транзакции получали только согласованные данные;
- Надежность – все внесенные изменения фиксируются в журнале транзакций и данные считаются надежными, если транзакция была успешно завершена. В случае сбоя SQL Server сверяет данные, записанные в базе данных, с журналом транзакций, если есть успешно завершенные транзакции, которые не закончили процесс записи всех изменений в базу данных, они будут выполнены повторно. Все действия, выполненные не подтвержденными транзакциями, отменяются.
Команды управления транзакциями в T-SQL
В T-SQL для управления транзакциями существуют следующие основные команды:
- BEGIN TRANSACTION (можно использовать сокращённую запись BEGIN TRAN) – команда служит для определения начала транзакции. В качестве параметра этой команде можно передать и название транзакции, полезно, если у Вас есть вложенные транзакции;
- COMMIT TRANSACTION (можно использовать сокращённую запись COMMIT TRAN) – с помощью данной команды мы сообщаем SQL серверу об успешном завершении транзакции, и о том, что все изменения, которые были выполнены, необходимо сохранить на постоянной основе;
- ROLLBACK TRANSACTION (можно использовать сокращённую запись ROLLBACK TRAN) – служит для отмены всех изменений, которые были внесены в процессе выполнения транзакции, например, в случае ошибки, мы откатываем все назад;
- SAVE TRANSACTION (можно использовать сокращённую запись SAVE TRAN) – данная команда устанавливает промежуточную точку сохранения внутри транзакции, к которой можно откатиться, в случае возникновения необходимости.
Примеры транзакций в T-SQL
Давайте рассмотрим примеры транзакций, реализованные на языке T-SQL.
Исходные данные для примеров
Но сначала нам необходимо создать тестовые данные для нашего примера.
Для этого выполните следующую инструкцию.
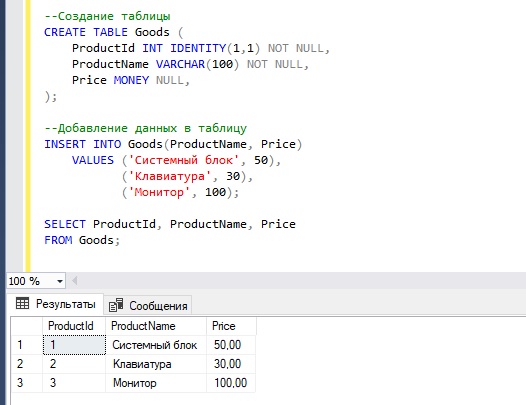
Простой пример транзакции в T-SQL
В данном примере у нас всего две инструкции, которые изменяют данные, но допустим, что они взаимосвязаны, т.е. они обе обязательно должны выполниться вместе или не выполниться также вместе.
Поэтому мы решили эти инструкции объединить в одну транзакцию.
Сначала мы открываем транзакцию командой BEGIN TRANSACTION, далее пишем все необходимые инструкции, которые мы хотим объединить в транзакцию.
После этого командой COMMIT TRANSACTION мы сохраняем все внесенные изменения.
В данном случае у нас нет никаких ошибок, все инструкции выполнились успешно. Как результат, транзакция завершена также успешно и все изменения сохранены на постоянной основе командой COMMIT TRANSACTION.
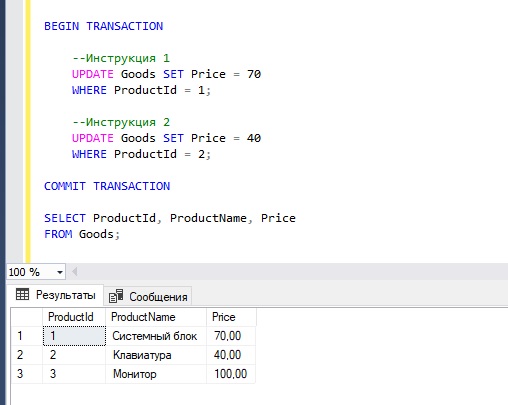
Однако, если в любой из инструкций возникнет ошибка, транзакция не завершится, и все изменения не сохранятся.
При этом, стоит помнить о том, что ошибки с определённым уровнем серьезности, например, ошибки, связанные с нарушением ограничений, не влекут за собой автоматический откат всех изменений внесенных текущей транзакцией, поэтому всегда необходимо использовать или инструкцию SET XACT_ABORT ON, или обработку ошибок (допускается и совместное использование).
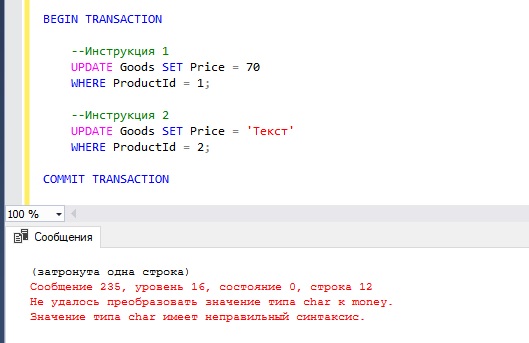
Например, если во второй инструкции мы попытаемся записать в столбец Price какое-нибудь текстовое значение, то у нас возникнет ошибка, и изменения, внесённые первой инструкцией, не зафиксируются на постоянной основе.
Пример транзакции в T-SQL с обработкой ошибок
В языке T-SQL существует механизм перехвата и обработки ошибок – конструкция TRY… CATCH.
Эту конструкцию можно использовать для отслеживания появления возможных ошибок внутри транзакции и в случае появления таких ошибок предпринять определенные действия.
Сначала мы открываем блок для обработки ошибок, затем открываем транзакцию командой BEGIN TRANSACTION, далее пишем наши инструкции, например, те же самые две инструкции UPDATE.
После этого закрываем блок TRY, открываем блок CATCH, в котором в случае возникновения ошибки мы откатываем все изменения командой ROLLBACK TRANSACTION. Также мы принудительно завершаем нашу инструкцию командой RETURN.
Если ошибок нет, то в блок CATCH мы, соответственно, не попадаем и у нас выполнится команда COMMIT TRANSACTION, которая сохранит все изменения.
В этом примере нет ошибок, поэтому транзакция завершена успешно.
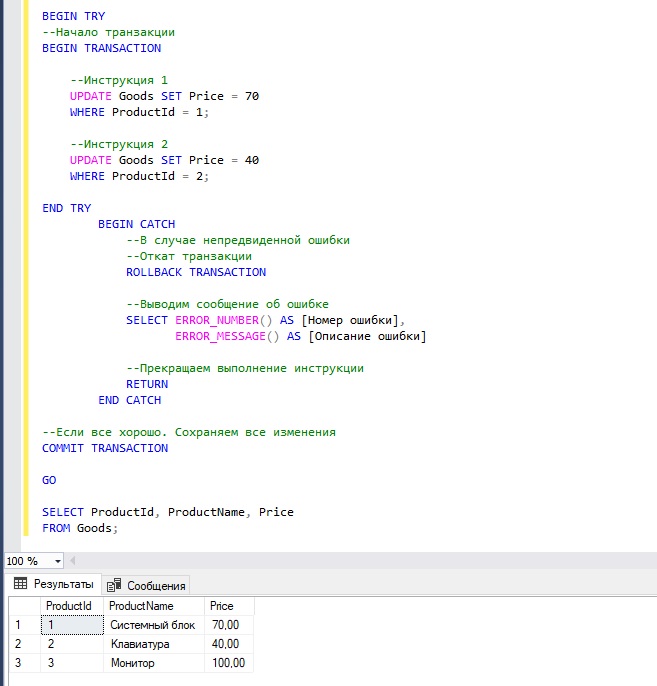
А в этом примере мы намерено допускаем ошибку во второй инструкции. Поэтому управление передается в блок CATCH, где мы откатываем все изменения, возвращаем номер и описание ошибки и принудительно завершаем всю инструкцию командой RETURN.
Первая инструкция отработала нормально, но ее изменения не были сохранены, так как вторая инструкция выполнена с ошибкой.
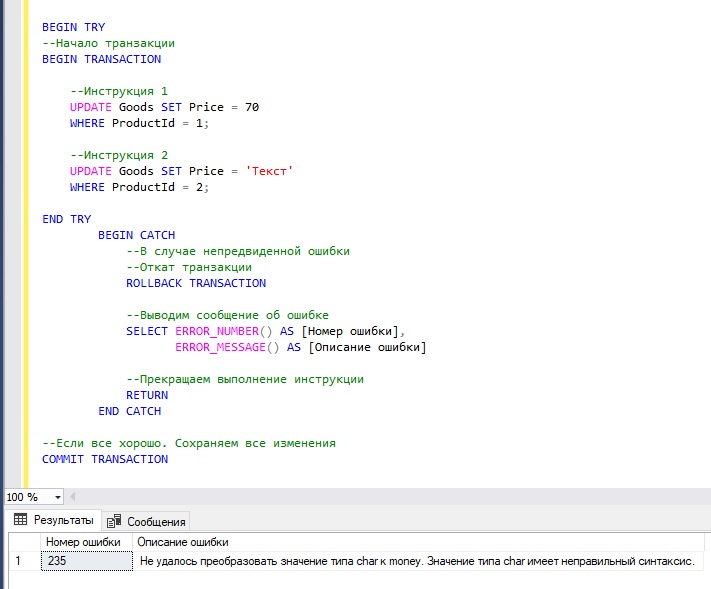
Уровни изоляции транзакций в T-SQL
Во время выполнения транзакции все данные, над которыми производятся изменения, блокируются, до завершения транзакции, так как, когда один процесс изменяет данные, другой процесс не может одновременно изменять их. В SQL сервере существует механизм, который блокирует (изолирует) данные во время выполнения транзакции. У данного механизма есть несколько уровней изоляции, каждый из которых определяет степень блокировки данных.
Давайте подробней рассмотрим уровни изоляции.
READ UNCOMMITTED
Самый низкий уровень, при котором SQL сервер разрешает так называемое «грязное чтение». Грязным чтением называют считывание неподтвержденных данных, иными словами, если транзакция, которая изменяет данные, не завершена, другая транзакция может получить уже измененные данные, хотя они еще не зафиксированы и могут отмениться.
READ COMMITTED
Этот уровень уже запрещает грязное чтение, в данном случае все процессы, запросившие данные, которые изменяются в тот же момент в другой транзакции, будут ждать завершения этой транзакции и подтверждения фиксации данных. Данный уровень по умолчанию используется SQL сервером.
REPEATABLE READ
На данном уровне изоляции запрещается изменение данных между двумя операциями чтения в одной транзакции. Здесь происходит запрет на так называемое «неповторяющееся чтение» или «несогласованный анализ». Другими словами, если в одной транзакции есть несколько операций чтения, данные будут блокированы и их нельзя будет изменить в другой транзакции. Таким образом, Вы избежите ситуации, когда вначале транзакции Вы запросили данные, провели их анализ (некое вычисление), в конце транзакции запросили те же самые данные, а они уже отличаются от первоначальных, так как они были изменены другой транзакцией.
Также уровень REPEATABLE READ, как и остальные, запрещает «Потерянное обновление» – это когда две транзакции сначала считывают одни и те же данные, а затем изменяют их на основе неких вычислений, в результате обе транзакции выполнятся, но данные будут те, которая зафиксировала последняя операция обновления. Это происходит потому, что данные в операциях чтения в начале этих транзакций не были заблокированы.
SERIALIZABLE
Данный уровень исключает чтение «фантомных» записей. Фантомные записи – это те записи, которые появились между началом и завершением транзакции. Иными словами, в начале транзакции Вы запросили определенные данные, в конце транзакции Вы запрашиваете их снова с тем же фильтром, но там уже есть и новые данные, которые добавлены другой транзакцией. Более низкие уровни изоляции не блокировали строки, которых еще нет в таблице, данный уровень блокирует все строки, соответствующие фильтру запроса, с которыми будет работать транзакция, как существующие, так и те, что могут быть добавлены.
SNAPSHOT и READ COMMITTED SNAPSHOT
Также существуют уровни изоляции, алгоритм которых основан на версиях строк, это
Иными словами, SQL Server делает снимок и хранит последние версии подтвержденных строк. В данном случае, клиенту не нужно ждать снятия блокировок, пока одна транзакция изменит данные, он сразу получает последнюю версию подтвержденных строк. Следует отметить, что уровни изоляции, основанные на версиях строк, замедляют операции обновления и удаления, так как перед этими операциями сервер делает и копирует снимок строк во временную базу данных.
SNAPSHOT – уровень хранит строки, подтверждённые на момент начала транзакции, соответственно, именно эти строки будут считаны в случае обращения к ним из другой транзакции. Данный уровень исключает повторяющееся и фантомное чтение примерно так же, как уровень SERIALIZABLE.
READ COMMITTED SNAPSHOT – этот уровень изоляции работает практически так же, как уровень SNAPSHOT, с одним отличием, он хранит снимок строк, которые подтверждены на момент запуска команды, а не транзакции, как в SNAPSHOT.
Побочные эффекты параллелизма
На основе вышеизложенного мы можем выделить несколько побочных эффектов, которые могут возникнуть в результате параллельного использования данных:
- Потерянное обновление (LostUpdate) – при одновременном изменении данных разными транзакциями одно из изменений будет потеряно;
- Грязное чтение (DirtyRead) – чтение неподтвержденных данных;
- Неповторяющееся чтение (Non-Repeatable Read) – чтение измененных данных в рамках одной транзакции;
- Фантомное чтение (Phantom Reads) – чтение записей, которые появились между началом и завершением транзакции.
Каждый из уровней изоляции устраняет определенные побочные эффекты. В таблице ниже приведены сводные данные.
| Побочный эффект / Уровень изоляции | Потерянное обновление | Грязное чтение | Неповторяющееся чтение | Фантомные записи |
| READ UNCOMMITTED | Устраняет | Не устраняет | Не устраняет | Не устраняет |
| READ COMMITTED | Устраняет | Устраняет | Не устраняет | Не устраняет |
| REPEATABLE READ | Устраняет | Устраняет | Устраняет | Не устраняет |
| SERIALIZABLE | Устраняет | Устраняет | Устраняет | Устраняет |
| SNAPSHOT | Устраняет | Устраняет | Устраняет | Устраняет |
| READ COMMITTED SNAPSHOT | Устраняет | Устраняет | Устраняет | Устраняет |
Включение уровня изоляции в T-SQL
Для того чтобы включить тот или иной уровень изоляции для всей сессии, необходимо выполнить команду SET TRANSACTION ISOLATION LEVEL и указать название уровня изоляции.
Также для уровней SNAPSHOT и READ COMMITTED SNAPSHOT предварительно необходимо включить параметр базы данных ALLOW_SNAPSHOT_ISOLATION для уровня изоляции SNAPSHOT и READ_COMMITTED_SNAPSHOT для уровня READ COMMITTED SNAPSHOT.
Заметка! Если Вас интересует язык SQL, то рекомендую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных.
Подобные вопросы должны возникать в голове пользователя, которому было сказано проверить свои файлы, и который не понимает важности этих файлов. Здесь вы узнаете, почему создаются эти файлы и какие есть причины для анализа журналов.
Поскольку существует огромное количество организаций, использующих базу данных SQL-сервера, существуют различные типы рисков, которым подвергаются данные, хранящиеся на сервере. Файл транзакции содержит все транзакции, которые происходят в базе данных для ведения записи.
Теперь вопрос, зачем нам проверять журнал транзакций SQL-сервера? Что ж, мы должны проанализировать эти файлы, чтобы мы знали о каждой транзакции, которая происходит. Поскольку количество киберпреступлений растет с каждым днем, каждому пользователю рекомендуется регулярно проверять свои журналы.
Методы, чтобы узнать, как проверить журнал транзакций SQL Server
Как мы узнали, чтение файла журнала имеет огромное значение, отсутствие его анализа может привести к потере или повреждению данных в базе данных. Это не может быть подходящей ситуацией для любого пользователя как такового. Чтобы помочь тем, кто не знает, как открыть эти файлы, у нас есть 3 решения.
В третьем решении вы должны использовать SQL Server Management Studio, который может решить ту же проблему за вас. Пока это бесплатный метод, он сложен и может занять некоторое время, чтобы выполнить это упражнение.
Давайте перейдем ко всем этим методам и узнаем, как работают для каждого.
Как проверить журнал транзакций SQL Server с помощью интеллектуального решения?
Для эффективного открытия файла журнала и анализа всех транзакций, таких как вставка, обновление и удаление. Для этого загрузите Анализатор журналов SQL что позволяет пользователям восстанавливать измененную базу данных.
Приступим к работе с этим инструментом.
Как инструмент помогает проверить журнал транзакций SQL Server?
1. Запустите инструмент и щелкните значок Открыть кнопку, чтобы вставить файлы в панель программного обеспечения.

2. Выберите Онлайн БД вариант и выберите Имя сервера из списка или введите его. Выберите Тип аутентификации и ударил ОК.

3. Отметьте таблицы, которые вы хотите проанализировать, и нажмите на Экспорт кнопка.

4. Выберите Вставлять, Обновлять, и / или Удалить варианты и применить Дата-фильтры.

5. Перейти к База данных SQL Server в Экспорт в / как поле. Введите необходимую информацию в Учетные данные базы данных вариант.

6. Задайте место назначения или Создать новую базу данных и ударил Экспорт чтобы узнать, как проверить журнал транзакций SQL Server.

В Дата-фильтр опция позволяет пользователям выбрать определенный период времени, указав даты от и до. Программа принимает данные из указанного часового пояса и экспортирует только выборочные данные.
Это самый простой способ открытия файлов журналов среди всех остальных. Если пользователи хотят проверить бесплатные методы, перейдите к следующему способу.
Ручной метод открытия файлов журнала с помощью fn_dblog ()
Эта функция может использоваться в целях криминалистики для извлечения данных из файлов транзакций для их тщательного анализа. Пользователи могут применять эту функцию в версиях SQL 2005, 2008 R2 до 2017 для проверки журнала транзакций SQL Server. Ниже приведены шаги для этой функции:
1. Здесь вы должны просмотреть записи, используя T-SQL и использовать Обновлять команда.
2. Выберите Выбирать запрос для просмотра значений таблицы.
3. После этого вы можете увидеть измененные данные.
4. Затем запустите fn_dblog () функционировать согласно вашим требованиям.
5. Теперь вы можете просмотреть все детали внесенных изменений в журнал на вашем дисплее.
Несмотря на то, что этот метод выполняется всего за несколько шагов, он может отображать только время внесенных изменений и может стать сложным и длительным процессом.
Как проверить журнал транзакций службы SQL с помощью альтернативного ручного метода?
С помощью этого подхода пользователи могут сделать видимыми только некоторые детали из файла журнала. К ним относятся сбор аудита, история заданий, SQL Server, почта базы данных, сбор данных, события Windows и агент SQL Server.
Теперь перейдем к рабочим этапам этой техники:
1. Прежде всего откройте приложение SQL Server Management Studio, чтобы запустить этот процесс.
2. После этого перейдите в Подключиться к серверу окно и заполните детали в Имя сервера а также Аутентификация поля.
3. Нажмите Соединять после заполнения данных и переходите к проверке журнала транзакций SQL Server.

4. На этом шаге перейдите к Обозреватель объектов окно и выберите Управление вариант.

5. Там выберите Журналы SQL Server вариант из расширенного меню.

6. Теперь щелкните правой кнопкой мыши Журналы SQL Server возможность открыть другой расширенный список и нажать Вид.
7. Здесь выберите Журнал SQL Server кнопку из меню.

8. Наконец, вы сможете увидеть журналы на Окно просмотра файлов журнала.

Время и личность пользователя, который внес изменения, с помощью этого метода не раскрываются.
Это должно быть все
Важно знать, как проверять журнал транзакций SQL Server, поскольку данные, хранящиеся в файлах, могут сказать вам, была ли какая-либо операция, не связанная с информацией. Непросто проанализировать файлы, если у вас нет необходимых технических знаний для применения ручных методов.
Тем не менее, вы можете использовать описанное здесь программное обеспечение, чтобы выполнить ту же задачу без каких-либо технических знаний и завершить процесс за считанные минуты.
Читайте также: