
Установка zfs на raid
Обновлено: 06.07.2024
Если у вас есть какое-то аппаратное обеспечение для серверного уровня, в любом случае целесообразно запускать ZFS поверх аппаратного RAID1 или некоторых таких? Если нужно отключить аппаратный RAID и запустить ZFS на mirror или raidz zpool вместо?
Если аппаратная функциональность RAID отключена, аппаратные RAID-контроллеры SATA2 и SAS более или менее склонны скрывать ошибки чтения и записи, чем не-аппаратные RAID-контроллеры?
В терминах не настраиваемых серверов, если у вас есть ситуация, когда аппаратный RAID-контроллер эффективно нейтрален с точки зрения затрат (или даже снижает стоимость предварительно построенного серверного предложения, поскольку его присутствие повышает вероятность того, что хостинговая компания обеспечивая дополнительный доступ IPMI), если его вообще следует избегать? Но следует ли его искать?
Идея с ZFS заключается в том, чтобы сообщить ей как можно больше о том, как ведут себя диски. Затем, от худшего к лучшему:
- Аппаратный рейд (ZFS не имеет понятия о реальном оборудовании),
- Режим JBOD (проблема связана с любым потенциальным расширителем: меньшая пропускная способность),
- Режим HBA является идеальным (ZFS знает все о дисках)
О выпуске стандартизованного оборудования с некоторым аппаратным RAID-контроллером в нем, просто будьте осторожны, чтобы аппаратный контроллер имел реальный проходной или JBOD-режим.
Q. Если у вас есть какое-то аппаратное обеспечение для серверного оборудования в любой момент, целесообразно ли запускать ZFS поверх аппаратного RAID1 или некоторых таких?
а. Очень желательно запускать ZFS прямо на диск и не использовать любую форму RAID между ними. Независимо от того, действительно ли система, которая эффективно требует использования RAID-карты, исключает использование ZFS, больше связана с ДРУГИМИ преимуществами ZFS, чем с отказоустойчивостью данных. Если вы используете базовую RAID-карту, отвечающую за предоставление одного LUN для ZFS, ZFS не улучшит отказоустойчивость данных. Если единственная причина для перехода с ZFS в первую очередь - это улучшение отказоустойчивости данных, тогда вы просто потеряли все основания для ее использования. Тем не менее, ZFS также предоставляет ARC /L2ARC, сжатие, моментальные снимки, клоны и другие другие улучшения, которые вам также могут понадобиться, и в этом случае, возможно, это все еще ваша файловая система выбора.
Q. Следует ли отключить аппаратный RAID и запустить ZFS на зеркале или raidz zpool вместо этого?
а. Да, если вообще возможно. Некоторые RAID-карты позволяют осуществлять сквозной режим. Если это так, это предпочтительнее.
Q. Когда аппаратные функции RAID отключены, аппаратные RAID-контроллеры SATA2 и SAS более или менее склонны скрывать ошибки чтения и записи, чем не-аппаратные RAID-контроллеры?
а. Это полностью зависит от рассматриваемой RAID-карты. Вам нужно будет поработать над руководством или связаться с производителем /поставщиком RAID-карты, чтобы узнать. Некоторые очень многое делают, да, особенно если «отключить» функциональность RAID фактически не полностью отключает ее.
Q. С точки зрения не настраиваемых серверов, если у вас есть ситуация, когда аппаратный RAID-контроллер эффективно нейтрален с точки зрения затрат (или даже снижает стоимость предварительно встроенного серверного предложения, поскольку его присутствие повышает вероятность того, что хостинговая компания, предоставляющая дополнительные IPMI доступ), если его вообще избежать? Но следует ли его искать?
а. Это тот же вопрос, что и ваш первый. Опять же - если ваше единственное желание использовать ZFS - это улучшение отказоустойчивости данных, а на выбранной вами аппаратной платформе требуется, чтобы RAID-карта предоставляла один LUN для ZFS (или несколько LUN, но у вас есть полоса ZFS через них), то вы делаете ничто не улучшает отказоустойчивость данных, и поэтому ваш выбор ZFS может оказаться неприемлемым. Если, однако, вы обнаружите, что какая-либо из других функций ZFS полезна, она все равно может быть.
Я хочу добавить дополнительную проблему - вышеупомянутые ответы основываются на идее, что использование аппаратной RAID-карты под ZFS ничего не вредит ZFS, не удаляя ее способности улучшать отказоустойчивость данных. Правда в том, что это большая часть серой области. В ZFS существуют различные настройки и допущения, которые не обязательно работают, когда передаются многодисковые LUN вместо необработанных дисков. Большинство из них могут быть сведены на нет при правильной настройке, но из коробки вы не будете столь же эффективны в ZFS поверх большого RAID LUN, поскольку вы были бы на вершине отдельных шпинделей.
Кроме того, есть некоторые свидетельства того, что очень разные способы, с которыми ZFS разговаривает с LUN, а не с более традиционными файловыми системами, часто вызывают пути кода в RAID-контроллере и рабочие нагрузки, к которым они не привыкли, что может привести к странности. Прежде всего, вы, вероятно, окажете себе одолжение, полностью отключив функциональность ZIL на любом пуле, который вы размещаете поверх одного LUN, если вы также не предоставляете отдельное устройство регистрации, хотя, конечно, я настоятельно рекомендую вам Предоставьте пулу отдельное необработанное лог-устройство (это не LUN с RAID-карты, если это вообще возможно).
Я часто запускаю ZFS поверх конфигураций RAID HP ProLiant Smart Array.
- Потому что мне нравится ZFS для разделов данных, а не для загрузки разделов.
- Поскольку загрузка Linux и ZFS, вероятно, для меня не является достаточно надежной.
- Поскольку контроллеры HP RAID не разрешают перенос устройства RAW . Настройка нескольких томов RAID 0 не совпадает с дисками RAW.
- Поскольку серверные объединительные платы обычно не являются достаточно гибкими, чтобы выделять отсеки для дисков конкретному контроллеру или разделять обязанности между двумя контроллерами. В эти дни вы чаще всего видите настройки 8 и 16 отсеков. Не всегда достаточно, чтобы сегментировать то, как должно быть.
- Но мне все еще нравятся возможности управления томами ZFS. Zpool позволяет мне динамизировать работу и максимально использовать доступное дисковое пространство.
- Сжатие, ARC и L2ARC являются функциями убийцы!
- Правильно спроектированная ZFS-настройка на аппаратном RAID-массиве по-прежнему дает хорошее предупреждение и предупреждение о сбоях, но превосходит аппаратное решение.
список блокирующих устройств
Список файловой системы zfs
Вкратце: использование RAID ниже ZFS просто убивает идею использования ZFS. Зачем? - Потому что он предназначен для работы на чистых дисках, а не в RAID-массивах.
Для всех вас . ZFS над любым рейдом - это полная БОЛИ и выполняется только людьми MAD! . как использование ZFS с памятью не ECC.
С образцами вы поймете лучше:
- ZFS поверх Raid1, один диск немного изменился, когда не было выключено . pry все, что вы знаете, ZFS увидит некоторый урон или не зависит от того, какой диск читается (контроллер рейда не видел, что бит изменился, и подумайте, как диски в порядке) . если сбой в части VDEV . весь ZPOOL навсегда потеряет все свои данные.
- ZFS поверх Raid0, один диск немного изменился, когда не было выключено . pry все, что вы знаете (контроллер рейда не видел, что бит изменился и думаю, что оба диска в порядке) . ZFS увидит, что повреждение но если сбой в части VDEV . весь ZPOOL навсегда потеряет все свои данные.
Где хорошо работает ZFS - это обнаружение битов, которые изменились на диске, где без питания (RAID-контроллеры не могут этого сделать), также когда что-то меняется без запроса и т. д.
Это та же проблема, что и когда бит в RAM-модуле спонтанно изменяется без запроса . если память ECC, память исправляет ее самостоятельно; если нет, эти данные изменились, так что данные будут отправлены на модифицированные диски; что изменение не относится к части UDEV, если сбой находится в части VDEV . весь ZPOOL навсегда потеряет все свои данные.
Это слабость к ZFS . Сбой VDEVs означает, что все данные теряются навсегда.
Hardware Raid и Software Raid не могут обнаружить спонтанные битовые изменения, у них нет контрольных сумм, худших на уровнях Raid1 (mirros), они читают не все части и сравнивают их, они полагают, что все части будут иметь одинаковые данные ALLWAYS (я говорю это громко) Рейд судит о том, что данные не изменились никакими другими вещами /способами . но диски (как память) склонны к спонтанным изменениям бит.
Никогда не используйте ZFS в RAM без ECC и никогда не используйте ZFS на рейдовых дисках, пусть ZFS видит все диски, не добавляйте слой, который может испортить ваш VDEV и POOL.
Как имитировать такой сбой . выключение ПК, вынул один диск этого Raid1 и изменил только один бит . переконфигурируйте и посмотрите, как контроллер рейда не может знать, что изменилось . ZFS может, потому что все reads проверяются с контрольной суммой, а если не совпадают, читайте форму другой части . Рейд никогда не читает снова, потому что сбой (за исключением невозможного чтения файла) . если Рейд может читать, он считает, что данные в порядке (но это не так в таких случаях) . Рейд только пытается читать с другого диска, если там, где он читает, говорит: «Эй, я не могу читать оттуда, аппаратные сбои» . ZFS читает с другого диска, если контрольная сумма не совпадает так же, как если бы где он читает, говорит: «Эй, я не могу читать оттуда, аппаратные сбои».
Надеюсь, я даю ему понять . ZFS на любом уровне рейда - это боль в области боли и общий риск для ваших данных! а также ZFS для памяти, отличной от ECC.
Но никто не говорит (кроме меня):
- Не используйте диски с внутренним кешем (не только те, что SHDD, а также некоторые из них с кешем от 8Mib до 32MiB и т. д.) . некоторые из них используют не-ECC-память для такого кеша
- Не используйте SATA NCQ (способ записи в очередь), потому что он может испортить ZFS, если сила потеряна.
Итак, какие диски использовать?
- Любой диск с внутренним аккумулятором, который гарантирует, что все очереди будут наложены на диск в случаях сбоя питания, и использует в нем память ECC (извините, есть очень маленькие со всем этим и стоят дорого).
Но, эй, большинство людей не знают все это и никогда не сталкивались с проблемой . я говорю им: ничего себе, как вам повезло, купите несколько лотерейных билетов, прежде чем повезет, уйдет.
Риски есть . такие неудачи могут возникнуть . поэтому лучший ответ:
- Попытайтесь не помещать ни один слой между ZFS и где данные действительно хранятся (RAM, Raid, NCQ, внутренний кеш диска и т. д.) . насколько вы можете себе позволить.
Что я лично делаю?
- Поместите несколько слоев больше . Я использую каждый 2,5-дюймовый диск SATA III 7200 об /мин на корпусе USB 3.1 Gen2 типа C, я подключаю некоторые корпуса к USB 3.1 Gen 2 Type A Hubчто я подключаюсь к ПК; другой для другого концентратора, который я подключаю к другому корневому порту на ПК и т. д.
- Для системы я использую внутренние соединители sata на уровне ZFS (уровень Raid0), потому что я использую inmutable (как LiveCD) систему Linux, каждый загружает идентичный контент на внутренние диски . и у меня есть изображение Clone системы я могу восстановить (менее 1GiB системы) . также я использую трюк, чтобы иметь систему, содержащуюся в файле, и использовать диск с отображением RAM, где я клонирую его при загрузке, поэтому после загрузки вся система запускается в ОЗУ . такой файл на DVD я также могу загружать таким же образом, поэтому в случае сбоя внутренних дисков я просто загружаюсь с DVD, а система снова подключается к сети . подобный трюк для SystemRescueCD, но немного более сложный beacuse файл ISO может быть на внутренней ZFS или просто быть настоящим DVD, и я не хочу двух разных версий.
Надеюсь, я мог бы немного рассказать о ZFS против рейда, это действительно боль, когда все идет не так!
Я считаю что читатель данной заметки может самостоятельно установить Proxmox на ноду и не буду рассматривать установку и настройку самого гипервизора. Рассмотрим только настройки касающиеся ZFS RAID1 и тестирование ситуации сбоя одного из дисков.
Железо на котором предстояло развернуть проект представляло из себя ноду Supermicro, видимо в исполнении 2 node in 1U с псевдо-рейдом интегрированном в чипсет от Intel который не поддерживается в Proxmox. В связи с этим попробуем испытать решение предлагаемое «из коробки» в версии 4.0. Хоть убейте — я не помню был-ли такой вариант установки в Proxmox 3.6, может и был, но не отложилось в памяти из-за невостребованности такой конфигурации. В тестовой стойке у нас отыскался аналогичный сервер и я принялся за проверку решения, предоставляемого ребятами из Proxmox Server Solutions.
Установка
Как и предупреждал — не буду показывать установку полностью, заострю внимание только на важных моментах.
Выбираем zfs RAID1:
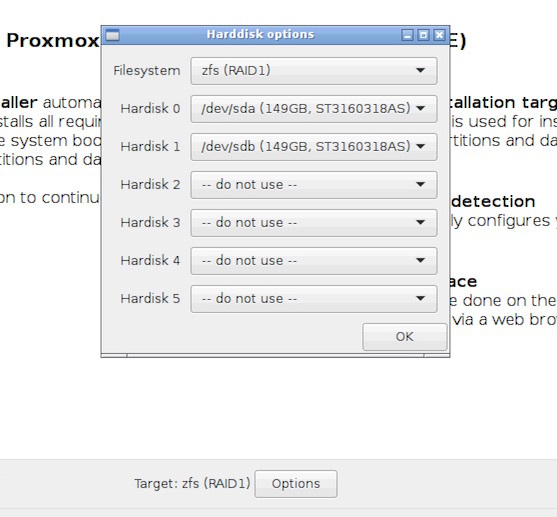
Сервер тестовый и нет подписки на коммерческий репозиторий. В /etc/apt/sources.list подключаем бесплатный:
В /etc/apt/sources.list.d/pve-enterprise.list закомментируем коммерческий.
Ну и вдруг забудете:
Смотрим что нам нарезал инсталлятор на дисках (привожу только часть вывода):
Глянем на наш массив:
По умолчанию инсталлятор Proxmox установил загрузчик на оба раздела — отлично!
Тестирование
Имитируем отказ жесткого диска следующим образом:
— выключаем сервер;
— выдергиваем одну из корзин;
— включаем сервер.
Сервер прекрасно грузится на любом из оставшихся дисков, массив работает в режиме DEGRADED и любезно подсказывает какой диск нам надо сменить и как это сделать:
Если вернуть извлеченный диск на место — он прекрасно «встает» обратно в зеркало:
Инсценируем замену диска на новый. Я просто взял другую корзину с таким-же диском из старого сервера. Ставим корзину на горячую для большей правдоподобности:
Условно неисправный диск у нас /dev/sdb и учитывая одинаковую емкость и геометрию копируем таблицу разделов 1:1 с исправного диска /dev/sda
Генерируем уникальные UUID для /dev/sdb
Ставим загрузчик на замененный диск и обновляем GRUB:
Осталось только заменить сбойный диск в массиве на свежеустановленный, но тут всплывает одна проблема, порожденная методом адресации дисков в массиве примененной в инсталляторе. А именно — диски включены в массив по физическому адресу и команда zpool replace rpool /dev/sdb2 покажет нам вот такую фигу:
Что совершенно логично, нельзя сменить сбойный диск на /dev/sdb2 так как сбойный диск и есть /dev/sdb2, а зачем нам повторять недоработку инсталлятора? Привяжем диск по UUID, я вообще уже забыл то время когда диски прибивались гвоздями вида /dev/sdХХ — UUID наше все:
Нас предупредили о необходимости дождаться окончания синхронизации прежде чем перезагружаться. Проверим статус массива:
Для общего порядку включим и sda2 в массив используя UUID:
Пока я копипастил предыдущие 2 команды из консоли в редактор массив уже синхронизировался:
Вывод
Когда нет аппаратного Raid-контроллера вполне удобно применить размещение корневого раздела на доступном в Proxmox 4.0 «из коробки» zfs RAID1. Конечно-же всегда остается вариант переноса /boot и корня на зеркала созданные средствами mdadm, что тоже неоднократно было использовано мной и до сих пор работает не нескольких серверах, но рассмотренный вариант проще и предлагается разработчиками продукта «из коробки».
Дополнение
Было несколько вопросов, пока руки дошли только до проверки работоспособности autoexpand. Тестовые диски на 160Gb были заменены на 500Gb.
После замены первого диска:
После замены второго:
Все манипуляции происходят онлайн, без перезагрузки сервера и остановки виртуальных машин.
Сделал инструкцию по классической установке Proxmox на soft raid1, таких инструкций много, но в 4-й версии есть свои мелкие детали. Кому интересно — читаем
В наши дни все большей и большей популярности набирают файловые системы следующего поколения, которые имеют более широкую функциональность, чем в обычных файловых системах. Одни из таких файловых систем - это Btrfs и ZFS, Обе они уже стали достаточно стабильными и активно применяются пользователями. Для многих пользователей очень важна сохранность данных, и такие файловые системы могут обеспечить ее наилучшим образом.
В одной из предыдущих статей мы рассматривали файловую систему Btrfs. В нашей сегодняшней статье мы остановимся на ZFS, эти файловые системы похожи по своему применению и назначению, но имеют некоторые отличия. Мы рассмотрим как установить эту файловую систему в вашем дистрибутиве, настроить ее и использовать для решения повседневных задач.
Что такое ZFS?
Файловая система ZFS имеет обычные для таких файловых систем возможности. Это просто огромный размер одного раздела, и размер файла, поддерживается возможность хранения файлов на нескольких устройствах, проверка контрольных сумм для данных и шифрование на лету, а также запись новых данных в режиме COW, когда данные не переписываются, а пишутся в новое место, что позволяет делать мгновенные снапшоты.
Возможности очень похожи на Btrfs, но есть кое-какие отличия. В Btrfs можно посмотреть все файлы, измененные с момента последнего снапшота. Второе отличие, это отсутствие в Btrfs логических блоков zvol.
Установка ZFS
В последних версиях Ubuntu файловая система ZFS была добавлена в официальный репозиторий и в установочный диск. Поэтому для того, чтобы ее установить будет достаточно выполнить несколько команд:
sudo apt install -y zfs
В других дистрибутивах. например, CentOS или Fedora ситуация немного сложнее, сначала вам придется добавить официальный репозиторий, а затем установка zfs и самого набора утилит и модулей ядра:

Затем осталось включить загрузить модуль ядра с поддержкой этой файловой системы:
sudo modprobe zfs
Теперь файловая система установлена и готова к использованию. Дальше нам нужно выбрать разделы и создать на них файловые системы. Для настройки zfs используется утилита zpool, но для начала давайте рассмотрим ее синтаксис и возможности. Файловая система может быть расположена на нескольких разделах или жестких дисках, поэтому на уровне ядра формируется общий пул (куча), а к нему уже подключаются разделы. Тут можно провести аналогию с группой томов LVM.
Команда zpool
Это основной инструмент управления разделами и функциональными возможностями ZFS, поэтому вам важно его освоить. Общий синтаксис команды достаточно прост, но у нее есть множество подкоманд, которые имеют свой синтаксис и параметры:
$ zpool команда параметры опции устройства
Как я уже сказал, параметры и опции для каждой команды свои, а в качестве устройства может указываться пул или физический раздел на жестком диске. Теперь рассмотрим основные команды и их предназначение, чтобы вы могли немного ориентироваться, а более детальные параметры разберем уже на примерах:
Это были все основные опции команды, которые мы будем использовать. Теперь рассмотрим примеры настройки zfs и управления разделами.
Как пользоваться ZFS
Настройка ZFS не очень сильно отличается от Btrfs, все базовые действия выполняются очень просто, вы сами в этом убедитесь.
Создание файловой системы
Сначала посмотрим есть ли уже созданные пулы ZFS. Для этого выполните такую команду:
sudo zpool list

Если вы устанавливаете эту файловую систему в первый раз, то здесь будет пустой список. Теперь создадим пул на основе существующего раздела, мы будем использовать раздел /dev/sda6
sudo zpool create -f pool0 /dev/sda6

Хотя вы можете использовать не только раздел, а целый диск. Теперь смотрим еще раз список пулов:
sudo zpool list

Затем смотрим состояние нашего пула с помощью команды status, здесь выводится больше подробной информации. Если у вас есть несколько дисков, вы можете настроить RAID массив, чтобы данные хранились не на одном разделе, а синхронно копировались на несколько, это может в несколько раз увеличить производительность.
sudo zpool create pool0 zraid /dev/sda /dev/sdb /dev/sdc
Обратите внимание, что диски должны иметь одинаковый раздел. Если вам не нужен RAID, вы можете настроить обычное зеркалирование на второй диск. Это увеличивает надежность хранения данных:
sudo zpool create pool0 mirror sda sdb
Теперь данные будут писаться на оба диска. Такую же вещь можно проделать с разделами, но здесь нет смысла, поскольку если жесткий диск накроется, то данные вы потеряете, а прироста производительности не увидите. Вы можете использовать даже файлы, для создания файловых систем.
Вы можете добавить новый жесткий диск или раздел к пулу:
sudo zpool attach pool0 /dev/sdd
Или удалить устройство из пула:
sudo zpool detach pool0 /dev/sdd
Чтобы удалить пул используйте команду destroy:
sudo zpool destroy pool0
Для проверки раздела на ошибки используйте команду scrub:
sudo zpool scrub pool0

Статистику использования пула можно посмотреть с помощью команды iostat:
sudo zpool iostat pool0

Файловые системы ZFS
Теперь нужно создать файловые системы на только что созданном пуле. Создадим три файловые системы, data, files и media. Для этого используется команда zfs:
sudo zfs create pool0/data
$ sudo zfs create pool0/files
$ sudo zfs create pool0/media

Файловые системы готовы, дальше рассмотрим монтирование zfs.

Монтирование ZFS
Точка монтирования для пула и для каждой созданной в нем файловой системы создается в корневом каталоге. Например, в нашем случае точки монтирования выглядят так:

Или можно использовать такую команду:
Чтобы размонтировать файловую систему для одного из созданных разделов используйте команду zfs umount:
sudo zfs umount /pool0/data

Затем можно ее обратно примонтировать:
sudo zfs mount pool0/data

Параметры файловой системы
Кроме всего прочего, вы можете настроить различные параметры файловой системы ZFS, например, можно изменить точку монтирования или способ сжатия. Вы можете посмотреть все текущие параметры для файловой системы или пула с помощью команды:
sudo zfs get all pool0/files

Сначала включим сжатие:
sudo zfs set compression=gzip pool0/files
Затем отключим проверку контрольных сумм:
sudo zfs set checksum=off pool0/files
Смотрим точку монтирования:
sudo zfs get mountpoint pool0/files
Затем установим свою:
sudo zfs set mountpoint=/mnt pool0/files

Теперь раздел будет монтироваться в /mnt, настройки можно изменить для каждого из разделов.
Снимки состояния ZFS
Снапшоты zfs или снимки состояния могут использоваться восстановления данных. Благодаря особенностям файловой системы снимки можно создавать мгновенно. Для создания снимка просто наберите:
sudo zfs snapshot pool0/files pool0/files@shot1
Для восстановления используйте:
sudo zfs rollback pool0/files@shot1
Посмотреть список снимков вы можете командой:
sudo zfs list -t snapshot
А удалить ненужный снимок:
sudo zfs destory pool0/files@shot1
Выводы
В этой статье мы рассмотрели как работает файловая система zfs, как выполняется настройка zfs и как ее использовать. Это очень перспективная файловая система, с огромным набором функций, которая способна сравняться, а в некоторых областях и обойти Btrfs. Надеюсь, эта информация была полезной для вас, если у вас остались вопросы, спрашивайте в комментариях!
Ребята, подскажите мануал, как ставить ZFS и программный RAID1.
Машина такая:
Материнка: ASUS P8Z77-V LX2
Процессор: Intel Core i7-377 3.4GHz
8 ядер.
16 Гб оперативки.
2 SATA-диска по 1 терабайту.
AMD64 соответственно.
Можно настроить RAID и в биосе, но я слышал, что такие рэйды фейковые, и предпочтительно настраивать программный рэйд в FreeBSD.
Что сначала, что потом: RAID или ZFS?
Ребята, подскажите мануал, как ставить ZFS и программный RAID1.
Машина такая:
Материнка: ASUS P8Z77-V LX2
Процессор: Intel Core i7-377 3.4GHz
8 ядер.
16 Гб оперативки.
2 SATA-диска по 1 терабайту.
AMD64 соответственно.
Можно настроить RAID и в биосе, но я слышал, что такие рэйды фейковые, и предпочтительно настраивать программный рэйд в FreeBSD.
Что сначала, что потом: RAID или ZFS?
давайте так, мухи - RAID, отдельно, котлеты - ZFS, тоже.
RAID - не имеет отношения к FS (filesystems)
ZFS - файловая система, это если рассматривать ее верхний уровень.
RAID'ы бывают: программные (soft-raid), аппаратные - hw-raid.
Рейды в hardware исполнении можно разделить: ATA/PATA и SAS/SCSI
Fake-RAID - это дешевые рейды, с уровнем не более чем 0,1,0+1
Что есть Fake-RAID: это полу-программный или полу-хардверный рейд, первый вариант
более правильный по названию.
В чем смысл, в том что для Fake-RAID, можно создавать RAID0,1,0+1 через BIOS
контроллера, только создавать - это означает что в специальной области диска
создаются метаданные описывающие RAID, а все остальное делает драйвер.
Вывод - fake-raid это полупрограммный, более правильно программный рейд.
Во FreeBSD поддерживаются Fake-RAID'ы только на ATA/PATA контроллерах, и то
не все:
- посредством ataraid и утилиты atacontrol (устаревшая конструкция)
- посредством graid (на базе GEOM, взамен ataraid)
отдельно для программных рейдов на базе GEOM, существуют реализации:
- gconcat (а-ля JBOD)
- gstripe (а-ля RAID0)
- gmirror (RAID1)
- graid3
Еще несколько слов о FAKE-RAID'ах, ataraid/graid поддерживают НЕ все известные
в "природе" рейды, мало того, часть fake-raid'ов поддерживается только на READ
- без возможности управления из OS, часть на READ-WRITE - с возможностью
управления из OS.
Для того чтобы программный рейд (в случае FAKE: 0/1) управлялся из OS, его
следует создавать в OS, и ни в коем случае не из BIOS контроллера FAKE-RAID'а.
Во FreeBSD НЕ ПОДДЕРЖИВАЮТСЯ SCSI Fake-RAID'ы
Есть и другие, но уже устаревшие средства создания программных рейдов.
Для поддержки HARDWARE RAID ничего не нужно, за исключением утилит управления,
таких во FreeBSD не много, а значит, реорганизовать HW-RAID на ходу без таких
утилит невозможно! Только из BIOS HW-RAID'а, что означает ПРОСТОЙ сервера,
точнее OSю
ZFS - как было сказано, это мощная файловая система, которую СТРОГО не советуют
использовать поверх каких бы то ни было RAID'ов, в силу конструктива.
Одна из первых рекомендаций - использование HBA контроллеров для direct access HDD.
В ZFS имеются могучие встроенные средства реализации разных уровней RAID, кеширования
и журналирования, ведение снапшотов и тд и тп.
Другая важна рекомендация - чем больше RAM, тем быстрей и оптимальней работает ZFS,
вот почему в ZFS есть несколько уровней кеширования и для отдельных из них
советуют использовать SSD (это еще одна отдельная тема: какие и почему), аналогично
и для журнала - тоже советуют использовать SSD (еще одна тема).
При создании различных RAID'ов поддерживаемых ZFS - необходимо изучить, какие
есть ограничения и рекомендации по кол-ву используемых дисков, группировке их
и какие есть ограничения, не смешивать разные виды рейдов в одном пуле и тд и тп.
Как минимум, ZFS это и создание/управление пулом ("томами") + файловая система с массой
встроенных современных достижений: кеширование, журналирование, снимки.
Ключевые слова: ARC,L2ARC,кеширование, уровни, HBA контроллеры, дедупликация и
zpool, mirror, raidz, raidz2 и тд и тп.
Руководство по ZFS на русском или английском на Oracle и другие полезные
FAQ и Recomendation в сети.
К сожалению, книг по ZFS нет и даже нет книг с хорошими главами по ZFS.
Старайтесь структуризировать знания и опыт по мере работы, иначе это будут просто
сваленные в кучу кирпичи, в отличие от тех из которых выстраивается здание:
свалили - построили, свалили - построили и тд и тп.
Читайте также: