
В чем состоит цель enterprise фреймворков safe less
Обновлено: 06.07.2024
Организационный дизайн на основе четырех типов Agile-команд.
Ограничение в виде этих четырех типов команд работает как мощный шаблон для эффективного организационного дизайна.
— Мэтью Скелтон и Мануэль Пайс
Общий принцип
До сих пор выстраивание команд вокруг фич и компонентов была стандартным подходом для команд и ART в SAFe и Agile в целом.
В своей книге «Топологии команд» Мэтью Скелтон и Мануэль Пайс предложили новую концепцию организации разработчиков решений с использованием четырех основных типов команд:
Каждому типу соответствует набор определенных действий и обязанностей. Как отмечалось в приведенной выше цитате, Скелтон и Пайс полагают, что этих четырех типов абсолютно достаточно, чтобы значительно упростить работу по организационному дизайну.
В настоящей статье описываются упомянутые выше типы команд и их применимость как к формированию Agile-команд в контексте SAFe, так и к организации ART. Применение этой концепции обеспечивает новые и улучшенные шаблоны масштабирования для организаций, разрабатывающих даже огромные и очень сложные программно-аппаратные комплексы и киберфизические системы.
Детальное описание
Любое программное решение можно рассматривать с двух точек зрения:
- С точки зрения доставки ценности, которая определяется функциональностью, поставляемой клиентам и конечным пользователям.
- С технической точки зрения, то есть то, как архитектурные компоненты системы взаимодействуют между собой и с внешним миром для реализации этой функциональности.
Организация команд вокруг фич (фиче-команды) и компонентов (компонентные команды) была и остается доминирующей моделью в Agile. Это позволяет каждой Agile-команде оставаться сфокусированной на выполняемой работе на протяжении длительного времени и в то же время ограничивает их когнитивную нагрузку. Другими словами, командам не обязательно понимать всю систему в целом; они могут сосредоточиться на той части системы, за которую они отвечают.
Однако, этот подход не лишен проблем. Характерные особенности фиче-команды часто неясны и не всегда подразумевают комплексную доставку ценности. Также противоречивы и мотивы создания «компонентных» команд. Обычно решения по созданию компонентных команд принимаются из-за стремления к оптимизации ресурсов вокруг конкретных технических знаний и повторного использования программного обеспечения. Зачастую это приводит к тому, что команды становятся излишне специализированными или сильно привязываются к технологиям, что увеличивает зависимости и тормозит поток.
В своей книге Скелтон и Пайс описывают альтернативный подход. Они описывают четыре типа команд, что позволяет улучшить и упростить задачу организации вокруг поставки ценности (рисунок 1):

Рисунок 1. Четыре фундаментальных типа команд
Эти четыре типа команд в совокупности с определенной структурой самих команд, обеспечивают лучшую и более четкую модель для формирования Agile-команд в SAFe. С этой целью ниже подробно описывается каждый из этих типов , а также обязанности и подходы в работе, присущие каждому из них.
Потоковые команды (Stream-Aligned Teams)
Термин «потоковый, ориентированный на поток» подчеркивает важность организации команд для доставки непрерывного «потока» ценности в рамках потока разработки, который создает, эксплуатирует и поддерживает продукт или решение. Скелтон и Пайс определяют поточную команду следующим образом:
Потоковая команда ориентирована на единый ценностный поток работы, наделена полномочиями создавать и доставлять ценность для заказчиков, клиентов или пользователей максимально быстро, безопасно и независимо, насколько это возможно, не требуя передачи другим командам для выполнения части работы.
В SAFe команды работают в рамках ART, которые являются частями крупных потоков разработки. Редко одна потоковая команда создает все решение. Чаще всего потоковые команды поддерживают только часть потока создания ценности, ориентированную на один из следующих аспектов:
- конкретное решение или подмножество решений,
- набор фич,
- сегмент пользователей,
- конкретные шаги клиентского пути (customer journey),
- конкретная предметная область бизнеса (бизнес-домен),
- соответствие нормативным и регуляторным требованиям,
- новые инновационные продукты.
Определяющим фактором является наличие у потоковой команды полномочий и ответственности для создания и доставки ценности для клиентов с минимальной зависимостью от других команд. Для этого требуется, чтобы потоковые команды были кросс-функциональными и включали все навыки, необходимые для создания и поддержки любых разрабатываемых фич и компонентов. Предполагается, что потоковые команды являются долгоживущими, что позволяет, развивать и накапливать знания и экспертизу, повышая эффективность в долгосрочной перспективе.
Обязанности и подходы потоковых команд:
Для каждого типа команд Скелтон и Пайс определяют набор ожидаемых подходов в работе. В контексте SAFe мы интерпретируем их как обязанности потоковых команд и выделяем следующие:
Команды сложных подсистем (Complicated Subsystem Teams)
Хотя создание потоковых команд является разумным и преимущественным подходом, маловероятно, что можно будет обойтись командами только такого типа. По мере укрупнения и усложнения решений возникает вероятность появления подсистем, например, при сочетании программных и аппаратных компонентов. Создание и эксплуатация подобных подсистем может требовать специальных знаний и опыта. Скелтон и Пайс подтверждают это, вводя определение команды сложной подсистемы:
Команда сложной подсистемы отвечает за создание и поддержку части системы, которая до такой степени зависит от специальных знаний, что для понимания подсистемы и внесения изменений в нее большинство членов команды должны быть квалифицированными специалистами в этой области знаний.
Обязывание членов потоковых команд постоянно получать новые знания и навыки, необходимые суммарно всеми потенциальными подсистемами, и поддерживать их на требуемом уровне, создало бы слишком большую когнитивную нагрузку. Команды могут быть подавлены сложностью, не имея возможности сосредоточиться на предметной области, которую они действительно могут освоить. Вместо этого, команды сложных подсистем берут на себя большую часть этой нагрузки, возлагая на себя ответственность за создание и обслуживание тех частей системы, которые требуют глубоких технических знаний и их постоянной актуализации.
Команда сложной подсистемы может разрабатывать такие вещи, как:
- узкоспециализированные системные компоненты, часто используемые в нескольких системах,
- критичные с точки зрения безопасности элементы систем, выход из строя которых может дорого обойтись,
- специальные алгоритмы или бизнес-правила, критичные для использования в предметной области,
- часть киберфизической системы (например, модуль управления двигателем в автономном транспортном средстве).
Хотя на подсистемы можно декомпозировать практически любое решение, не для каждой подсистемы требуется специализированная команда. Уровень опыта, сложность и риск должны быть единственными решающими факторами для создания команды сложной подсистемы.
В этом и состоит отличие от традиционных компонентных команд, которые создаются по многим другим важным причинам, например, из-за необходимости повторного использования компонентов или поддержания архитектурной целостности. Грубо говоря, один ART не должен содержать более 1-3 команд сложных подсистем.
Обязанности и подходы команд сложных подсистем:
Платформенные команды (Platform Teams)
Платформенная команда предоставляет базовые внутренние сервисы, необходимые потоковым командам для поставки сервисов или функционала более высокого уровня, тем самым снижая их когнитивную нагрузку.
Акцент на платформенных командах как на «поставщиках услуг» (service providers) сильно влияет на работу этих команд. Платформы рассматриваются как «продукты», разработанные для их клиентов, которыми в данном случае являются потоковые команды. В данном контексте также применимы такие методы, как клиентоориентированность (клиентоцентричность) и дизайн-мышление. Кроме того, предоставляемые командами сервисы должны быть хорошо документированы, просты в использовании, соответствовать целям, быть легковесными и иметь возможность повторного использования.
Обязанности и подходы платформенных команд:
Вспомогательные команды (Enabling Teams)
Вспомогательные команды помогают потоковым командам получать недостающие способности, обычно в определенной технической области или области управления продуктом.
Одним из примеров вспомогательной команды в SAFe является System Team, которая помогает командам ART (среди прочего) создавать и поддерживать конвейер непрерывной поставки (CDP, Continuous Delivery Pipeline). Хорошими более специализированными примерами областей, в которых вспомогательные команды способны предоставить экспертные знания и поддержку, могут быть:
- внедрение DevOps-практик,
- автоматизированное тестирование,
- инструменты для непрерывной интеграции и сборки,
- практики обеспечения качества (Quality Assurance, QA) и тестирования,
- безопасность,
- среды (окружения) и конфигурации.
Когда потоковым командам необходимо интегрироваться с определенной платформой или подсистемой, вспомогательные команды могут оказывать в этом первоначальную помощь. Однако, вспомогательные команды не предназначены для исправления проблем с качеством работы потоковых команд. Скорее, они работают с ними в течение коротких периодов времени, как правило в одного или нескольких PI, чтобы внедрить требуемые практики в потоковую команду и улучшить навыки её членов.
Обязанности и подходы вспомогательных команд:
Agile-команды в ART
В SAFe команды работают как часть Agile Release Train (ART). При формировании ART и команд, которые их составляют, может быть полезно визуализировать эти команды в терминах типов, к которым они относятся. Для пояснения различных типов команд можно воспользоваться схемой, показанной на рисунке 2.
Потоковая команда представлена прямоугольником со стрелкой на конце, квадрат используется для представления команды сложной подсистемы, прямоугольником обозначена платформенная команда и пунктирным эллипсом отмечена вспомогательная команда.
Эти обозначения также можно использовать для визуализации взаимодействий между командами посредством их взаимного расположения. Для полноты картины к этим обозначениям могут быть добавлены имена конкретных команд. Визуализация команд таким образом помогает сравнить альтернативные варианты структуры ART, а также получить представление о том, насколько хорошо та или иная структура согласуется с потоком ценности.

Рисунок 2. Применение типологий к Agile-командам в ART
Применение типов команд в масштабе
Мы обсудили, как типы команд могут помочь в организации команд в рамках ART. Но многим предприятиям также необходимо организовывать ART, которые являются частью более крупных Solution Trains. К счастью, эти типы могут быть легко расширены, что позволяет найти здоровый компромисс при организации ART (рисунок 3).
Примечание. Основным исключением из этого правила являются вспомогательные команды. Несмотря на то, что на предприятии чаще всего формируются две или три вспомогательные команды и все они работают над одной и той же целью, маловероятно, что они будут составлять целый ART.
При масштабировании этих типов до ART требуется учесть некоторые дополнительные моменты.
Потоковый ART
Потоковый ART, как и потоковая команда, будет иметь необходимый состав специалистов, обладающих требуемыми навыками и полномочиями для поставки ценности, будь то полный продукт, сервис, подсистема, или какая-либо часть решения, над которой они работают.
Зоны ответственности этих потоковых ART в целом такие же, как и у потоковых команд. Варианты их организации по определенному типу здесь применимы так же, как описано ранее.
ART сложной подсистемы
Большинство крупных систем также включают обширные подсистемы. Это означает, что ART сложных подсистем являются обычным явлением при построении крупномасштабных систем, опять же, для того, чтобы снизить когнитивную нагрузку на потоковые ART. Например, навигационная система для автономного транспортного средства вполне может потребовать целого ART сложной подсистемы.
Платформенный ART
Точно так же Solution Trains обычно имеют платформенные ART, обслуживающие потоковые ART. Продолжая пример автономного транспортного средства, система связи, управляющая данными, передаваемыми между различными подсистемами, вероятнее всего, будет представлена как платформенный ART с четко определенными интерфейсами.

Рисунок 3. Сочетание АRТ различных типов в рамках Solution Train
Во всех этих примерах ART состоят из команд одного из четырех типов. Например, в рамках ART сложной подсистемы, разрабатывающей навигационную систему, одна или несколько потоковых команд могут разрабатывать функции, относящиеся к анализу окружения. Точно так же может существовать команда сложной подсистемы, специализирующаяся на алгоритмах маршрутизации. Таким образом, применение топологий фрактально.
Конечно, существует промежуточный паттерн, согласно которому в рамках одного ART может быть набор команд, работающих над одной платформой или сложной подсистемой. В этом случае для минимизации взаимозависимостей необходимо тщательно следить за распределением работ.
Резюме
В этой статье представлены новые шаблоны для решения проблемы организации Agile-команд и ART для разработки крупномасштабных систем и программного обеспечения. Применение четырех основных типов может упростить эту сложную проблему.
Конечно, все это требует постоянного анализа того, насколько хорошо нам служат наши нынешние организационные модели. Таким образом, организации должны постоянно проверять и адаптировать (Inspect and Adapt, I&A) и, при необходимости, реорганизовывать свою структуру, чтобы следовать ценностям, движущим рынок. Именно этого требует организационная гибкость (Organizational Agility).
О переводчиках
Александр Киверин
Ак Барс Цифровые Технологии, Технический директор
В менеджменте ИТ более 10 лет, выстраивал работу команд как небольших проектов в сфере E-commerce, так и крупных Enterprise-решений в сфере трейдинга, медицины и финтеха. Последние 4 года участвую в трансформации и развитии Ак Барс Банка, чтобы наши клиенты жили лучше. Certified SAFe ® Agilist.
Игорь Ларченко
Deutsche Telekom IT Russia, Scrum мастер
В IT более 25 лет. Прошел путь от разработчика до Enterprise архитектора в таких областях, как индустрия гостеприимства, компьютерные системы, финтех, нефть и газ. С 2015 года сфокусирован на формировании команд, управлении процессами в IT и их настройкой на большом масштабе. Professional Scrum Master, Professional Scrum Product Owner, Certified SAFe ® Agilist.
SAFe and Scaled Agile Framework are registered trademarks of Scaled Agile, Inc.
Nokia использовала фреймворки масштабирования Agile: LeSS и SAFe. Какую проблему они решали и как?
Перевод статьи Ари Тикка и Рана Нюмана LeSS SAFe comparison выполнен с разрешения авторов.

Как Large-Scale Scrum (LeSS), так и Scaled Agile Framework (SAFe) имеют публичные истории применения в компании Nokia. Однако, не многие знают, что Nokia представляла собой две большие слабо связанные компании. LeSS использовался и преимущественно используется в Nokia Networks (сейчас называется так же), в то время как SAFe в основном использовался в подразделениях Nokia Mobile Phones (сейчас по большей части принадлежат Microsoft или закрыты).
Обе части Nokia постепенно начали сталкиваться с одной и той же проблемой, которую позже пытались решить масштабированием Agile: узкоспециализированные подразделения и необходимость координации. Крупные организации по всему миру сталкиваются с этой же проблемой. История Nokia позволяет понять и сравнить, что же эти подходы предлагают.
В больших организациях культура и организационная структура ограничивают то, что дозволено делать людям. Мы сочувствуем тем, кто делает все возможное внутри такой системы.
В течение долгого времени Nokia росла на 35% каждый год, чем очень сложно управлять. Естественным решением была специализация: компонентные и функциональные команды, специалисты знают, что нужно делать, но решения принимают менеджеры, а команды их исполняют. Так было и в Nokia Networks, и в Nokia Mobile Phones. Обе компании отчаянно возлагали надежды на то, что со всем этим справится программное и проектное управление.
Давайте ограничимся Scrum-командой (команда + владелец продукта + Scrum-мастер). Взаимообучение происходит внутри команды с помощью инспекции и адаптации к рынку. В этом случае обучение создает ценность. Вот, что вам следовало бы масштабировать.
И LeSS, и SAFe базируются на Scrum на уровне команд. Каждый из фреймворков имеет собственный набор бережливых (Lean) и гибких (Agile) практик для поддержки масштабирования. Ключевое отличие в том, как предлагаемые процесс и организационная структура стимулируют обучение, поскольку Организации обучаются подобно лошадям.
SAFe и проблема Nokia Mobile Phones
Новая модель телефона Nokia ориентировалась на ограниченный срок службы, а также были сжатые сроки ее выпуска. Огромный бэклог (план) включал детализированные старые и новые фичи по многочисленным компонентам. Каждый компонент требовал реализации фич по всем частям системы, как например новый целостный дизайн пользовательского интерфейса.
Исполнение Программы
– SAFe
Если посмотреть на рынок, кажется, что это было решением проблемы, осознанной многими организациями.
Детализированный процесс похож на истории очень хороших продаж. Все начинается с текущих обстоятельств, а потом обязательно вылезает что-нибудь новенькое
Обучение в SAFe
LeSS в Nokia Networks
Nokia Networks производит невероятно сложные продукты с длительным сроком службы. Для некоторых продуктов требовалось обеспечить 20-летний срок обслуживания. И по-прежнему разработка в основном координировалась внутри программ с тяжеловесными релизами, часто длящимися годами.
Большее через меньшее.
– LeSS
Если организация новая и развивающаяся, то LeSS может быть идеальным вариантом, чтобы избежать смертельного штопора.
Обучение в LeSS
Не осталось никаких сомнений, насколько критично обучение в LeSS. Затраты на координацию превращаются в инвестиции в обучение. Традиционно LeSS поддерживает это через обмен опытом, что и в каком случае сработало.
Стратегическое решение
Какой путь выбрать? Решение сильно зависит от того, как лица, принимающие решения, осознают ситуацию в организации.
LeSS же предлагает радикальное долгосрочное решение. Простота LeSS делает его многосторонним. Организации самых различных типов могут использовать его в течение долгого времени. Тем не менее, из-за этой многогранности, лицам, принимающим решения, включая топ-менеджмент, требуется больше понимания и смелости, чтобы выбрать этот путь.
В следующих заметках блога мы более детально исследуем, к примеру, различные варианты масштабирования Scrum, а также сравним организационные слои SAFe и клиенто-ориентированные команды LeSS. Мы опишем: 1) лидерство и власть; 2) организационную структуру и иерархию; 3) поток ценности; 4) обучение, адаптацию и непрерывное улучшение.
Мы запускаем серию ознакомительных статей про SAFe для менеджеров проектов. В них мы расскажем о преимуществах, структуре и ролях Scaled Agile Framework, а также о том, где проектные менеджеры могут найти себе применение в данном подходе. Первая часть посвящена обзору подхода с точки зрения классического проектного управления.
Часть 1: Место проектов в SAFe
SAFe – один из наиболее популярных в мире подходов для организации работы гибкой компании. Его преимущество перед другими методами состоит в следующем:
- возможность охватить портфельный, программный уровни, а также уровень крупных комплексных продуктов и решений;
- подробно описанная ролевая структура, включающая менеджерские и технические роли на всех уровнях организации бизнеса;
- подробная база знаний, разноуровневые тренинги, большое профессиональное сообщество;
- высокий уровень структурирования и описания процессов, что упрощает внедрение подхода;
- описанный процесс бюджетирования;
- поддержка процесса разработки компонентными командами.
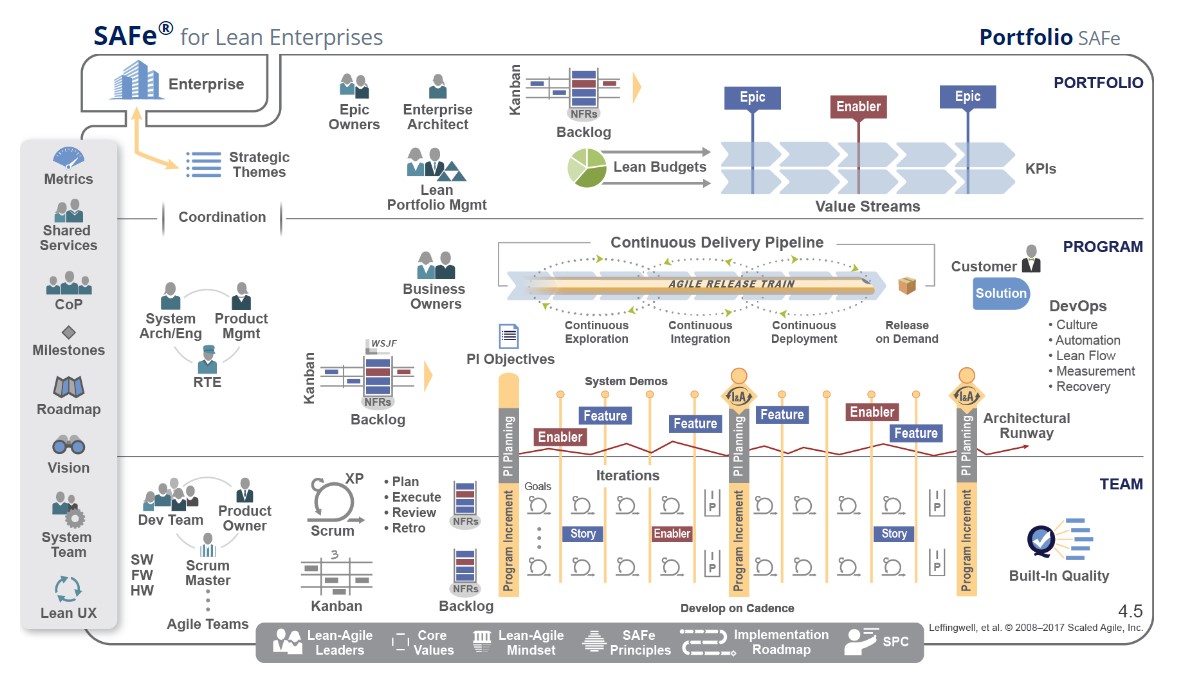
В минимальном виде SAFe выглядит как уровни Team + Program. Уровни Portfolio и Large Solution опциональны в зависимости от потребностей организации. В этой статье мы не будем рассматривать уровень Large Solution и сконцентрируемся на трёх основных.
Командный уровень
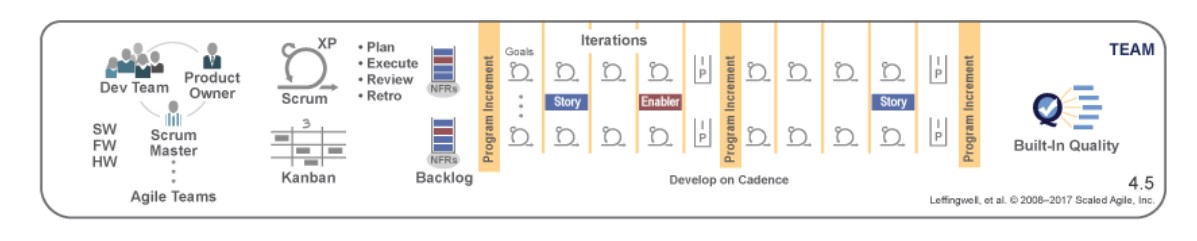
На уровне команд SAFe придерживается базовых принципов гибкой разработки, описанных в Agile-манифесте и поддерживает итеративно-инкрементальную разработку по фреймворку Scrum или методу Kanban. Команды итеративно разрабатывают элементы продукта двухнедельными итерациями (спринтами) и проводят демонстрации результатов своей работы и ретроспективу.
Единица управления на данном уровне – команда, реализующая пользовательские истории из бэклога. Роли на данном уровне такие же, как и в классическом Scrum: Владелец продукта, Scrum-мастер, член команды разработки.
Программный уровень
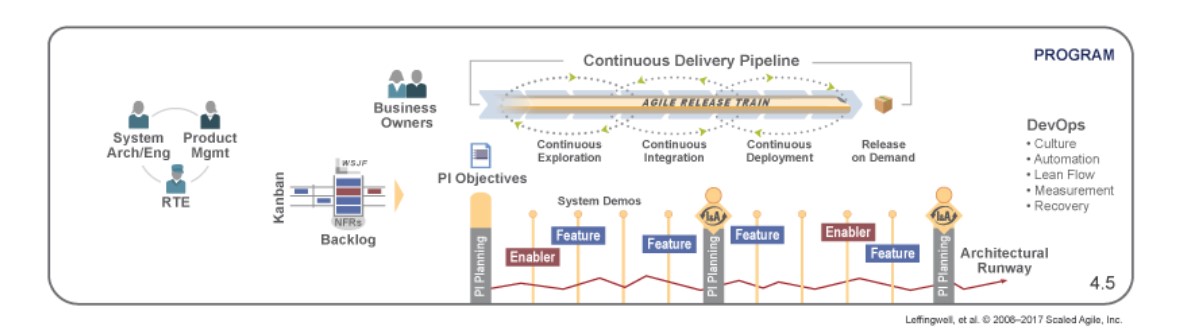
Уровень программы является ключевым как со стороны бизнеса, так и с точки зрения координации. На этом уровне все ресурсы, команды, заинтересованные лица кооперируются вокруг одной важной цели, чаще всего представляющую собой поток создания ценности (Value Stream) или продукт. Синхронизируют свою работу команды при помощи совместных сессий планирования (Program Increment Planning) в начале каждого квартала и демонстрации интегрированного инкремента продукта (System Demos) каждые 2 недели и ретроспективы (Inspect & Adapt) в конце каждого квартала.
Соответственно, все роли и процессы ориентированы на поставку ценных элементов функциональности. Метафорой этого процесса является “Поезд” (Agile Release Train).
ART – это долгоживущая группа команд, заинтересованных лиц и других участников, объединённых общей целью, создающая в едином ритме общее решение или его часть. Длина итераций и частота общего планирования внутри поезда фиксирована.
Управляет продуктом и владеет бэклогом поезда команда Продуктового менеджмента (Product Management). В неё входят Владельцы продуктов отдельных команд, а также Продуктовые менеджеры. Они выявляют потребности клиентов, формируют дорожную карту и приоритезируют элементы функциональности. Говоря простыми словами, Представители бизнеса ставят цели, а команда Продуктового менеджмента стараются их достичь силами команд.
Также на программном уровне есть роль Системного архитектора (System Architect). Архитектор определяет архитектуру будущего решения, направляет работу команды с технической стороны системы, взаимодействия подсистем и нефункциональных требований к системе.
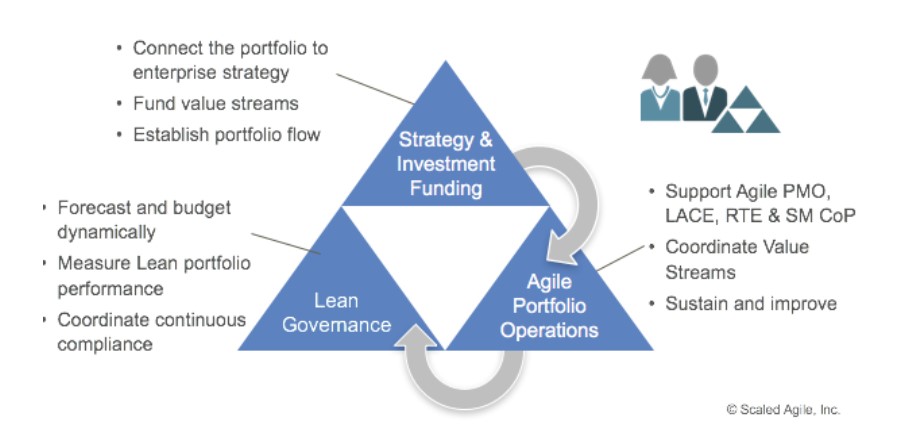
Уровень Портфеля
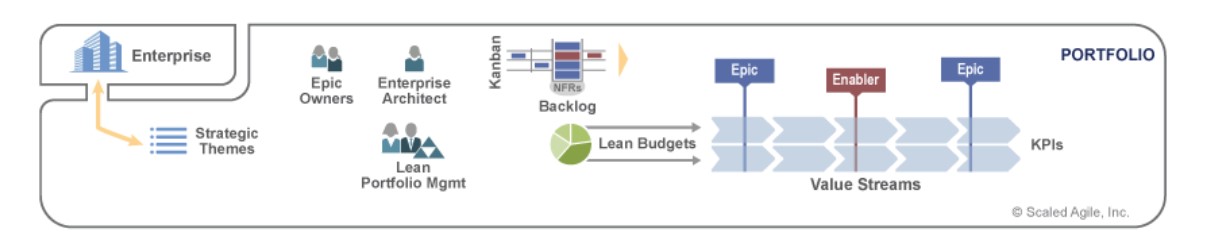
Цель портфельного уровня – согласование стратегии компании с реализацией портфеля за счёт организации процессов вокруг потоков создания ценности. Этот уровень появляется, если у организации несколько потоков создания ценности.
Портфель в SAFe состоит из Потоков создания ценности. Это могут быть продукты или направления деятельности организации. На этом уровне определяется стратегия инвестирования, бюджеты и показатели эффективности. Также на этом уровне реализуется функция принятия решения самого высокого уровня – портфельное управление (Lean Portfolio Management). И хотя глядя на схему может показаться, что Менеджер портфеля это некая отдельная роль, но это не так. На самом деле это группа функций, исполняемая людьми, которые могут также исполнять другие высокоуровневые роли в организации.
Корпоративный архитектор (Enterprise Architect) принимает решения относительно архитектуры всех систем в компании и их взаимодействия, для их гармоничного взаимодействия внутри организации.
Что делать менеджерам проектов дальше?
Цифровизация, ускорение запуска инноваций, продолжающийся рост роли Интернета привели к тому, что уровень неопределённости бизнеса в целом и проектов в частности вырос. И предпосылок для замедления этого роста не наблюдается. Технологии, потребности, конкурентное окружение и прочие факторы меняются не только постоянно, но и с высокой скоростью. Со временем всё меньше организаций будут предпочитать классическое проектное управление гибким подходам в качестве инструмента развития своего бизнеса. А в большинстве Agile-методологий нет роли менеджера проекта. Увы, но это так.
Если организация хочет сохранить ценных, опытных и компетентных менеджеров проектов и использовать их потенциал в своём бизнесе, ей придётся приспособить их для исполнения новых функций. А менеджерам проектов, чтобы остаться в игре, придётся освоить новые роли и навыки. Какие, мы расскажем во второй части нашей статьи.
В этой, восемнадцатой статье из серии «Менеджмент цифрового мира» (оглавление) я буду рассказывать о фреймворках масштабирования Agile на большие подразделения или компанию в целом. Эту тему я уже начал в прошлой статье «Kanban и Lean - эволюция вместо революции»: Kanban также позволяет оркестровать работу в рамках компании, но он нем я здесь говорить больше не буду.
Отмечу, что ячейкой организации в любом случае является автономная самоорганизующаяся Agile-команда, поэтому совместимость способов управления с Agile-культурой является принципиальным требованием. Опыт показывает, что многие подходы менеджмента, основанные на уважении авторитета руководителя, полагаемого безусловным, или следовании за непогрешимым лидером не выдерживают столкновения с Agile-культурой: сотрудники могут просто уйти целой командой. И если руководство привыкло к такому стилю управления, то в Agile нет никакого смысла. С другой стороны, как я говорил в статьях «Три вызова цифрового мира» и «Цифровой мир: от физического труда — к умственному» методы регулярного менеджмента в цифровом мире перестают работать, а Agile-методы являются одной из работающих альтернатив, что подробно рассмотрено в статье «Agile – ответ IT на вызовы цифрового мира».
Фреймворки имеют разную сложность и рассчитаны на компании или подразделения разного размера. При этом большинство из них рассчитано на короткие цепочки создания ценности, когда одна кроссфункциональная команда делает продукт, поставляемый потребителям. Как я писал в статье «Место Agile-команд в компании», в условиях неопределенности и быстрого изменения условий работы компании в VUCA-мире короткие цепочки являются естественным способом организации труда, способным быстро реагировать на изменения, в отличие от стабильных условий функционирования, которые ведут к специализации и образованию длинных цепочек из функциональных подразделений.
Большинство фреймворков, о которых я буду говорить, ориентированы на обеспечение только основной операционной работы компании. Однако, следует учитывать, что границы ответственности команд могут быть существенно различны. Достаточно распространенной является практика, когда в ответственность команд передается найм и увольнение сотрудников, их обучение, а также финансовая ответственность за создаваемый продукт, то есть команда становится независимым подразделением.
В других случаях HR остаются независимым подразделением, так же как бухгалтерия и юридическая служба, и тогда их работа может быть организована как сервисная инфраструктура для команд, работающая по Kanban или одним из гибридных Agile-методов. Сохранение традиционной организации тоже возможно, однако, важно обеспечить хорошее качество сервиса и не служить препятствием для движения команд основного операционного контура.
И перед тем, как перейти к обзору фреймворков я хочу порекомендовать доклад Асхата Уразбаева «Фреймворки масштабирования Agile» на SECR-2017 со сравнением разных фреймворков.
Начну я с наиболее простого Scrum of Scrums, который появился раньше других. Он применяется в случае, если у вам в компании есть независимые Scrum-команды, каждая из которых делает свой продукт. Тогда для работы надо общими вопросами достаточно собрать команду Product Owner для обсуждения стратегии развития продуктов и координации усилий, и команду Scrum Master для обсуждения и координации вопросов организации. Если в командах есть Tech Lead, отвечающий за технологии и обучение им сотрудников, то добавляется еще координирующая команда из них.
Однако, бывают ситуации, когда одна команда не может обеспечить развитие продукта в требуемой темпе, ее мощности не хватает. Ведь размер команды ограничен, эффективно работает команда в 7-9 человек, а если их становится сильно больше, то необходимо дополнительное структурирование. Есть относительно простой способ нарастить команду до 15-20 человек, представленный на схеме. Это конструкция из мини-команд, каждая из которых состоит из опытного сотрудника и 1-2 стажеров, для которых опытный является наставником для стажеров. При этом операционные вопросы взаимодействия решаются командой из руководителей мини-команд.
Другой относительно простой способ – это собрать Integration Team из представителей отдельный команд, которая будет решать вопросы координации и зависимостей. Это предлагает Nexus и достаточно в случае, когда зависимости являются достаточно слабыми.
Более сложный фреймворк – Large Scaled Scrum (LeSS) (русское описание) – несколько команд на одном продукте с общим Product Owner, BackLog, спринтами, планированием, демо и поставкой, это позволяет объединить до 8 команд. У фреймворка есть huge вариант, применяемый для больших компаний и рассчитанный на работу 1000+ человек.
Ответственность команды не ограничивается выполнением основных производственных задач, она имеет много планов и фокусов, и логично, когда это реализуется через отдельные организационные структуры. Это мы видели на примере Scrum of Scrum, который организует две структуры управления – продуктовую и организационную, иногда дополняемую третьей, технологической. Более сложной конструкцией является Spotify фреймворк, который заслуживает отдельного рассмотрения.
Основной производственной единицей в ней является клан (tribe) в 100-200 человек, который работает над отдельным продуктом. Он представляет собой матрицу: делится на кроссфункциональные производственные отряды (squad) и функциональные отделы (chapter). Отряды реализуют новый функционал и состоят из специалистов разных специализаций, которые дополняют друг друга. А отделы координируют работы специалистов из разных команд, использующих общие технологии, решая такие задачи, как разработка мобильных интерфейсов в едином стиле, однородная работа серверной части или развитие технологий тестирования. Отметим, что отделы работают над применением технологий в рамках продукта, а вот для развития технологий в целом по компании существуют еще гильдии (guild) по интересам. По мере роста компании над кланами появились структуры следующего уровня – альянсы (alliance) и бизнес-единицы (business unit).
Конструкция – очень сложная и многоплановая и во многом обусловленная контекстом компании. Spotify ей делится, но с предостережением: «используйте наши опыт, но не пытайтесь тупо скопировать, оно не взлетит, мы это точно знаем, потому что у нас самих конструкция развивается и растет». Но много попыток именно механического копирования, обычно неудачных. А вот идеи заложены плодотворные.
При этом в самой компании Spotify организационная структура развивается очень быстро. И я хочу интересующимся порекомендовать доклад Yuliya Kurapatenkava на Saint TeamLeadConf-2018, в котором она рассказывала про логику развития (мой конспект есть в отчете с конференции, сам доклад по-английски). И вы можете сравнить то, что звучит в докладе с тем описанием фреймворка, которое доступно по ссылке в начале раздела и фиксирует состояние несколько лет ранее.
Здесь стоит рассмотреть практическое применение подобных фреймворков. Один продукт, над которым работают несколько команд, далеко не всегда означает единственный продукт в смысле софта, более того, часто речь идет об одном бизнес-продукте, поддержка которого со стороны софта требует общей серверной части и нескольких приложений на разных платформах – web и мобильных. Естественным образом для того, чтобы какой-то новый функционала стал доступен конечным пользователям, он часто должен быть реализован в серверной части и для каждой из платформ. И тут может быть два подхода: сделать команды, каждая из которых сосредоточенна вокруг каждого софтверного продукта, при этом только она работает с кодовой базой продукта и отвечает за его архитектуру. В этом случае для организации могут применяться фреймворки, подобные LeSS.
Однако, то что задача по реализации нового функционала делится на несколько, каждую из которых выполняет своя команда, сильно увеличивает количество необходимых синхронизаций и время разработки. Поэтому часто применяется и другой способ организации, кросс-функциональные команды, включающие специалистов по всем приложениям и делают все доработки для новой фичи. При этом возникает общее владение кодом, и надо дополнительно принимать меры для удержания целостности архитектуры каждого приложения, а также обучения и передачи опыта, потому что внутри команды такие специалисты не могут учиться. И это получается структура, похожая на клан в Spotify.
Так вот, в зависимости от потока задач и этапа развития компании предпочтительная структура может сильно изменяться. И сейчас IT-компании умеют достаточно быстро и успешно перестраивать свою структуру в зависимости от потребностей развития продукта. Я хочу сослаться на опыт компании ivi. На TeamLeadConf-2018 Евгений Россинский рассказывал, как они обеспечивали целостность продуктов и поддерживали знания разработчиков при переходе к кроссфункциональным командам от команд, собранных вокруг отдельных приложений. А через год TeamLeadConf-2019 он же рассказывал как за год они для решения задач реинжиниринга ядра продукта вернулись к командам, организованным по приложениям, провели реинжиниринг, а затем – снова перешли к кросс-функциональным командам, и все это - за один год, и продолжая мониторинг производительности, чтобы не допустить деградации.
Компания ivi предоставляет чистый цифровой продукт. Однако, похожая бизнес-структура сейчас характерна и для банков и для туроператоров, потому что их продукты сейчас все больше и больше перемещаются в цифровую сферу. Но, насколько я знаю, быстро пересобираться таким образом они еще не умеют, да и для IT опыт ivi является передовым. И, думаю, это может дать хорошее представление о том, какова она – динамично развивающаяся и перестраивающаяся современная цифровая компания, насоклько быстро она умеет изменяться.
Scaled Agile Framework (SAFe) является самым сложным Agile-фреймворком, но при этом – самым популярным. Это сложная конструкция уровня компании с управлением потоками создания ценности и архитектурой. На мой взгляд, популярность этого фреймворка сродни популярности PMBOK или RUP – в нем есть все и на все случаи жизни, и предлагается просто взять нужное. Те, кто читал мою статью «Развитие и провал регулярного менеджмента в IT» не удивятся моему мнению, что у это – неработоспособная конструкция, хотя и привлекательная в своем инженерном совершенстве. И он не будет работать по тем же самым причинам – его сложность превышает разумный предел, при этом обвинить сам фреймворк будет невозможно, всегда окажется, что это вы не смогли его правильно реализовать.
Но дело не только в сложности фреймворка: SAFe пытается за счет сложных регламентов превратить запутанную область в сложную, а это – невозможно (подробнее о сложности областей – в моей статье «Место Agile-команд в компании»). Однако, SAFe может быть полезен как теоретический источник, подобно PMBOK. Кстати, автором фреймворка является Дин Леффингуэлл (Dean Leffingwell), один из авторов RUP.
Довольно интересен фреймворк Enterprise Scrum предлагает переход от создания IT-продукта к поставке ценности, управляемой набором связанных метрик. К сожалению, в отличие от всего остального он не завершен. Его создатель Mike Beedle, кстати, один из авторов Agile-манифеста был, к сожалению убит в Чикаго весной 2018 года, и работа не завершена. Однако, на сайте есть достаточно подробная конструкция системы метрик, совместимая с Agile-методами управления, и, возможно, она вам окажется полезной при конструировании собственной, хотя в готовом виде ее, естественно, брать не стоит. Поэтому я и даю ссылку.
На этом я завершаю эту статью. Полное оглавление серии «Менеджмент цифрового мира» можно увидеть у меня на сайте. В следующей статье мы поговорим про кейсы Agile-трансформации. Продолжение следует…
Читайте также: