
Задачи адресации компьютеров или узлов
Обновлено: 04.07.2024
Узлы IP-сети имеют уникальные физические и логические адреса . Физический устанавливается изготовителем аппаратных средств, например МАС- адрес сетевой карты NIC , который "прошивается" в ПЗУ . Логический адрес устанавливается пользователем (администратором) или назначается динамически протоколом DHCP из диапазона выделенных адресов. Логические адреса узлов в IP-сетях версии IPv4, используемой в настоящее время, содержат 32 двоичных разряда, т. е. 4 байта. Каждый из 4 байт адреса в технической документации отображается десятичным числом, а байты разделяются точкой, например, 172.100.220.14. Часть этого адреса (старшие разряды) является номером сети, а другая часть (младшие разряды) – номером узла в сети. Таким образом, IP-адреса являются иерархическими, в отличие от плоских МАС-адресов. В соответствии с тем, какая часть адреса относится к номеру сети, а какая – к номеру узла, адреса делятся на классы. Для уникальной адресации узлов используются три класса адресов.
В адресе класса А старший байт задает адрес сети , а три младших байта – адрес узла ( host ).
В адресе класса В два старших байта задают адрес сети , а два младших байта – адрес узла ( host ).
В адресе класса С три старших байта задают адрес сети , а младший байт – адрес узла.
Существует также многоадресный (multicast) класс D и резервный класс E. Дополнительная информация по классам и адресам приведена в таблице 7.1.
Номер узла ( адрес host ) не может состоять только из одних единиц или нулей. Если в поле адреса узла все нули, это значит, что задается номер ( адрес ) сети или подсети. Если же в этом поле все двоичные разряды равны единице, то это означает широковещательный ( broadcast ) адрес , предназначенный всем узлам сети, в которой находится узел, сформировавший данный пакет, т.е. источник передаваемой информации. Этим объясняется уменьшение максимального числа узлов в сети на 2 (см. таблицу 7.1). Таким образом, максимальное число узлов в сети класса С будет равно 2 8 - 2 = 254.
Старший разряд адреса класса А всегда равен 0, поэтому адреса сетей могут находиться в диапазоне от 1 до 127. Однако адрес 127.0.0.1 предназначен для самотестирования, по этому адресу узел обращается к самому себе, проверяя, установлен ли протокол TCP /IP на этом хосте. Поэтому адрес сети 127.0.0.0 не входит в состав адресов таблицы 7.1.
С целью сокращения количества адресов, которыми оперирует маршрутизатор , в его таблице маршрутизации задаются адреса сетей , а не узлов. В то же время в адресной части пакета задаются адреса узлов (см. рис. 6.7). Поэтому маршрутизатор , получив пакет, должен из адреса назначения получить адрес сети . Эту операцию маршрутизатор реализует путем логического умножения сетевого адреса узла на маску. Число разрядов маски равно числу разрядов IP-адреса. Непрерывная последовательность единиц в старших разрядах маски задает число разрядов адреса, относящихся к номеру сети. Младшие разряды маски, равные нулю, соответствуют разрядам адреса узла в сети. При логическом умножении адреса узла на маску получается адрес сети. Например, при умножении IP-адреса 192.100.12.67 на стандартную маску класса С, равную 255.255.255.0, получается следующий результат:
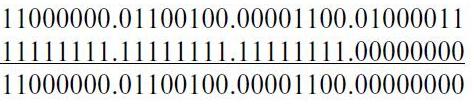
т. е. получен номер сети 192.100.12.0.
Аналогичная запись предыдущего адреса с соответствующей маской класса С может также иметь следующий вид: 192.100.12.67/24, означающий, что маска содержит единицы в 24 старших разрядах. При этом 24 старших разряда будут одинаковы для всех узлов сети, т.е. образуют общую часть адреса, называемую префиксом. Именно префикс имеет обозначение /24.
Стандартная маска адреса класса В имеет 16 единиц в старших разрядах и 16 нулей в младших. Поэтому если адрес узла будет равен 172.16.37.103/16, адрес сети будет равен 172.16.0.0. Маска адреса класса А имеет 8 единиц в старших разрядах и 24 нуля в младших. Поэтому, например, адресу узла 10.116.37.103/8 соответствует адрес сети 10.0.0.0.
Разбиение адресов на классы жестко задает максимальное количество узлов в сети. Этому соответствуют протоколы маршрутизации типа Classful, которые требуют, чтобы использовалась единая (стандартная) маска сети . Например, в сети с адресом 192.168.187.0 может использоваться стандартная маска 255.255.255.0, а в сети 172.16.0.0 используется стандартная маска 255.255.0.0.
7.2. Формирование подсетей
В ряде случаев для удобства управления администратор может самостоятельно формировать подсети внутри выделенного ему адресного пространства . Например, администратору выделен адрес сети 198.11.163.0 класса С, и ему необходимо создать 10 компьютерных подсетей по 14 узлов. Для адресации 10 подсетей потребуется 4 разряда адреса. Таким образом, маска должна иметь единицы в 28 старших двоичных разрядах и 4 нуля в младших – 11111111.11111111.11111111.11110000, т. е. маска будет 255.255.255.240. В этом случае максимально может быть задано 16 подсетей по 14 узлов в каждой (таблица 7.2). Из 16 подсетей администратор использует 10, а оставшиеся 6 использоваться не будут.
Следовательно, если задан адрес 198.11.163.83 с маской 255.255.255.240, то после логического умножения адреса на маску будет получен адрес подсети:

т. е. подсеть 198.11.163.80 сети 198.11.163.0, а номер узла равен 3 (0011).
С помощью маски 255.255.255.224 в адресном пространстве 198.11.163.0/24 можно сформировать 8 подсетей по 30 узлов в каждой, а с помощью маски 255.255.255.248 можно задать 32 подсети по 6 узлов. Используя маски разной длины для создания подсетей, администратор может формировать подсети разного размера в пределах одной автономной системы. Таким образом, маски переменной длины (Variable-Length Subnet Mask – VLSM) позволяют создавать подсети разного размера, гибко задавая границы между полем адреса сети и полем адреса узла. VLSM дают возможность задействовать больше чем одну маску подсети в пределах выделенного адресного пространства сети.
Например, для формирования сетей по 30 узлов в каждой требуется 27 разрядов маски, содержащих единицы, а для создания сети, соединяющей пару маршрутизаторов (" точка-точка "), требуется всего два адреса, т.е. маска должна иметь 30 единиц. Поэтому часть адресного пространства может быть использована для создания сетей по 30 узлов, а незанятые адреса – для формирования пары адресов для связей " точка-точка ".
При использовании маски в 30 двоичных разрядов два младших разряда адреса позволяют сформировать 4 адреса, из которых первый нужен для адресации сети, второй и третий – для адресации узлов, а четвертый – в качестве широковещательного адреса .
В примере ( рис. 7.1, таблица 7.3), адресное пространство 192.168.100.0/27 использовано для создания 8 подсетей по 32 адреса в каждой, т. е. маска имеет единицы в 27 старших двоичных разрядах.
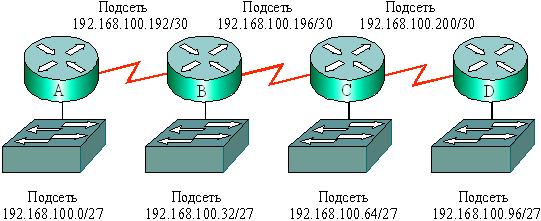
Рис. 7.1. Пример использования масок переменной длины
Одна из последних подсетей ( подсеть 6) разделена на субподсети. При этом используется маска , содержащая не 27 единиц, а 30 единиц в старших разрядах. Таким образом, за счет применения VLSM может быть сформировано 7 подсетей с числом узлов до 30 и восемь субподсетей с числом узлов 2. Каждая из субподсетей имеет диапазон адресов, используемых для связей " точка-точка ". В распределенной составной сети ( рис. 7.1) – четыре локальных сети (192.168.100.0/27, 192.168.100.32/27, 192.168.100.64/27, 192.168.100.96/27) и три сети " точка-точка ".
Таким образом, маски переменной длины VLSM позволяют создавать подсети разного размера. Например, сеть 198.11.163.0/24 может быть разбита на десять подсетей: две подсети по 62 узла в каждой, две подсети по 30 узлов, 2 подсети по 14 узлов и 4 подсети по 6 узлов в каждой (таблица 7.4). Соответственно, маски будут иметь размер: 26 – для первых двух подсетей, 27 – для третьей и четвертой подсетей, 28 – для пятой и шестой, 29 – для четырех последних подсетей. Естественно, что могут быть реализованы и другие варианты деления сети на подсети и субподсети.
Важно помнить, что только неиспользованные подсети могут далее делиться на субподсети. Если какой-то адрес подсети уже задействован, то подсеть на субподсети далее делиться не может.
На рис. 7.2 представлен еще один пример формирования пяти подсетей с маской длиной 26 единиц из адреса 172.16.32.0/23:
- 172.16.32.0/26 – 10101100.00010000.00100000.00000000;
- 172.16.32.64/26 – 10101100.00010000.00100000.01000000;
- 172.16.32.128/26 – 10101100.00010000.00100000.10000000;
- 172.16.32.192/26 – 10101100.00010000.00100000.11000000;
- 172.16.33.0/26 – 10101100.00010000.00100001.00000000;
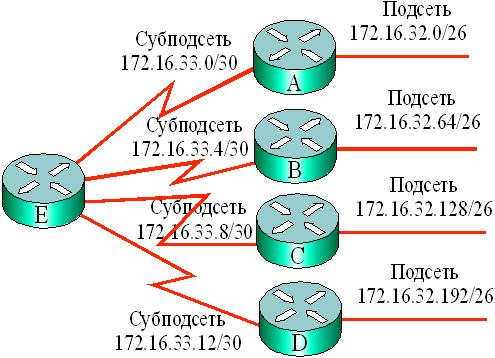
Одну из подсетей, например 172.16.33.0/26, далее подразделили на субподсети с маской длиной 30 разрядов.
Не все протоколы маршрутизации поддерживают VLSM, например, первая версия протокола RIPv1 не поддерживает маскирование подсетей переменной длины. Маскирование переменной длины VLSM поддерживают протоколы Open Shortest Path First ( OSPF ), Integrated IS-IS , Enhanced Interior Gateway Routing Protocol ( EIGRP ), протокол второй версии RIP v2, а также статическая маршрутизация .
При проектировании сетей может быть поставлена и обратная задача, когда несколько отдельных адресов необходимо объединить в один общий ( агрегированный ) адрес . Выше было отмечено, что общую часть адреса, представленную старшими разрядами, называют префиксом. В ряде случаев это сокращает число записей в таблице маршрутизации . Например, сети
могут быть агрегированы (объединены) так, чтобы маршрутизаторы использовали только один маршрут для объединенной ( агрегированной ) сети 172.16.14.0/23, поскольку 23 разряда адреса обеих сетей одинаковы.
Тип маршрутизации, применяющий агрегированные адреса, получил название бесклассовой междоменной маршрутизации (Classless Interdomain Routing – CIDR ) на основе префикса. Агрегирование маршрутов уменьшает нагрузку на маршрутизаторы.
Ниже рассмотрен следующий пример агрегирования адресов. Группа из четырех подсетей:
может быть представлена суммарным (агрегированным) адресом
поскольку 22 разряда адреса у них одинаковы.
Аналогично группа из других четырех подсетей:
может быть представлена агрегированным адресом
поскольку 22 разряда адреса у них также одинаковы.
Третья группа подсетей:
может быть представлена агрегированным адресом
поскольку у них одинаковы 22 разряда адреса.
Агрегирование приведенных выше адресов иллюстрирует рис. 7.3. Вместо адресов четырех подсетей в таблице маршрутизации каждого из маршрутизаторов А, В, С используется адрес только одного (агрегированного) маршрута с префиксом в 22 двоичных разряда. Адреса четырех указанных подсетей имеют общую часть – префикс, который используется как единый совокупный адрес . В маршрутизаторе D можно сформировать агрегированный адрес всех трех групп подсетей. Он будет иметь адрес 192.168.16.0/20, т. е. маска ( префикс ) содержит 20 единиц в старших разрядах, поскольку все представленные на рис. 7.3 адреса имеют двадцать одинаковых старших двоичных разрядов адреса.
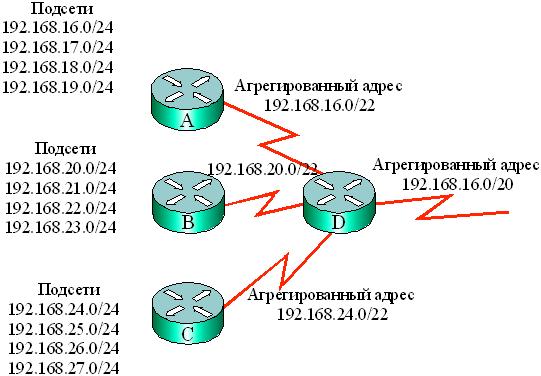
Таким образом, итоговый суммарный маршрут трех групп подсетей ( рис. 7.3) содержит префикс на 20 бит , общий для всех адресов в указанной сети – 192.168.16.0/20 – 11000000.10101000.00010000.00000000. Двадцать старших разрядов адреса (11000000.10101000.0001) используются как единый адрес организации, которая подключается к сети Интернет через маршрутизатор D.
Чтобы функционировала маршрутизация на основе префикса, адреса должны быть назначены иерархическим способом. Маршрутизатор должен знать номера всех присоединенных к нему подсетей и не должен сообщать другим маршрутизаторам о каждой подсети, если он может послать один совокупный маршрут ( aggregate routes). Маршрутизатор , который задействует совокупные маршруты, реже обращается к таблице маршрутизации.
Маршрутизация на основе префикса и масок переменной длины возможна, если маршрутизаторы сети используют бесклассовый (classless) протокол маршрутизации , например OSPF или EIGRP . Бесклассовые протоколы маршрутизации передают в обновлениях маршрутизации ( routing updates) 32-разрядные IP-адреса и соответствующие маски.

Нахождение маски подсети
- Различия начинаются в 3-ем байте. Запишем его в двоичной форме
- Все адреса подсети, включая SUBNET и BROADCAST, имеют общую часть – адрес сети; битам адреса сети в маске соответствуют единицы. Определим биты адреса сети и запишем маску по границе бит сети и узла.
- Запишем ответ в префиксном виде: 20

Принадлежность узла к сети
Определить, входит ли узел с IP- адресом 172.16.156.140 в подсеть 172.16.0.0/17.- Для решения задачи найдем максимально возможный адрес узла в данной подсети (HOSTMAX). Он будет предпоследним, т.е. HOSTMAX=BROADCAST-1.
- HOSTMAX=172.16.127.254. Сравним его с исходным IP=172.16.156.140. Получим, что заданный адрес больше максимального в исходной подсети.
- Ответ: нет, не входит.

Суммарный статический маршрут
Для уменьшения числа записей в таблице маршрутизации можно объединить несколько статических маршрутов в один. Это возможно при следующих условиях:
· Сети назначения являются смежными и могут быть объединены в один сетевой адрес.
· Все статические маршруты используют один и тот же выходной интерфейс или один IP-адрес следующего перехода.
Рассмотрим адреса LAN A, LAN B, LAN C и распишем отличные от 0 октеты в двоичном коде:

Смотрим на двоичный код второго октета и ищем совпадающие и меняющиеся биты. Все совпадающие биты переписываем, остальное справа обнуляем и получается суммарный адрес – 172.144.0.0
Для этого адреса ищем маску: считаем совпадающие биты (выделены желтым). Их 14, значит маска будет /14 или 255.252.0.0


Таблица маршрутизации для маршрутизатора
Рассмотрим таблицу маршрутизации на примере маршрутизатора R1

Router>enable
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is 0.0.0.0 to network 0.0.0.0
12.0.0.0/30 is subnetted, 4 subnets
C 12.135.73.0 is directly connected, FastEthernet0/0
C 12.135.73.8 is directly connected, FastEthernet2/0
C 12.135.73.12 is directly connected, FastEthernet1/0
R 12.135.73.16 [120/1] via 12.135.73.10, 00:00:16, FastEthernet2/0
[120/1] via 12.135.73.14, 00:00:16, FastEthernet1/0
R 192.168.0.0/22 [120/1] via 12.135.73.10, 00:00:16, FastEthernet2/0
R 192.168.128.0/24 [120/1] via 12.135.73.14, 00:00:16, FastEthernet1/0
S* 0.0.0.0/0 is directly connected, FastEthernet0/0
[1/0] via 12.135.73.1
С - Connected - маршрутизаторы, подключенные напрямую
S - Static - статические маршруты, заданные системным администратором
R - RIP - маршруты, известные благодаря работе протокола RIP
Если компьютер подключен к маршрутизатору R1 через еще один хоп (маршрутизатор R2 или R3), то в таблице маршрутизации будет указан интерфейс, через который можно получить доступ до требуемого компьютера. Например, " R 192.168.0.0/22 [120/1] via 12.135.73.10, 00:00:16, FastEthernet2/0" для доступа к компьютеру PC0.
В таблице маршрутизации всегда указываются Subnet адреса подключенных устройств.
Деление диапазона сетей на подсети
Дана сеть 192.168.128.0/24
Поделить на сети:
Для начала посмотрим на маску нашей сети. Маска 24. значит у нас есть диапазон 192.168.128.0- 192.168.128.255 из 254 узлов
1)Берем сеть 192.168.128.0/24 и делим её на 2 подсети. Получаем:
192.168.128.0/25 и 192.168.128.128/25 в каждой из которых по 126 узлов.
Одну оставляем 192.168.128.128/25 для под сети А(в которой 100 узлов)
С 192.168.128.0/25 работаем дальше.
2)Берем сеть 192.168.128.0/25 и делим её на 2 подсети. Получаем:
192.168.128.0/26 и 192.168.128.64/26 в каждой из которых по 62 узлов.
Одну оставляем 192.168.128.64/26 для под сети B(в которой 50 узлов)
С 192.168.128.0/26 работаем дальше.
3)Берем сеть 192.168.128.0/26 и делим её на 2 подсети. Получаем:
192.168.128.0/27 и 192.168.128.32/27 в каждой из которых по 30 узлов.
Одну оставляем 192.168.128. 32 /27 для под сети C(в которой 25 узлов)
С 192.168.128.0/27 работаем дальше.
4)Берем сеть 192.168.128.0/27 и делим её на 2 подсети. Получаем:
192.168.128.0/28 и 192.168.128.16/28 в каждой из которых по 14 узлов.
Оставляем две сети, так как 14 узлов слишком много для Оставшихся подсетей.
С 192.168.128.0/28 и 192.168.128.16/28 работаем дальше.
5)Берем сеть 192.168.128.0/28 и делим её на 2 подсети. Получаем:
192.168.128.0/29 и 192.168.128.8/29 в каждой из которых по 6 узлов.
Одну оставляем 192.168.128.8 /29 для под сети D(в которой 4 узла)
С 192.168.128.0/29 работаем дальше.
6)Берем сеть 192.168.128.0/29 и делим её на 2 подсети. Получаем:
192.168.128.0/30 и 192.168.128.4/30 в каждой из которых по 2 узла.
192.168.128.0/30 для под сети E(в которой 2 узла)
192.168.128.4/30 для под сети F(в которой 2 узла)
Всё сеть поделена. у нас ещё осталась подесть 192.168.128.16/28, которую мы получили в 4 пункте, но она не пригодилась.
- 192.168.128.128/25 - подсеть А
- 192.168.128.64/26 - подсеть B
- 192.168.128.32/27 - подсеть C
- 192.168.128.8/29 - подсеть D
- 192.168.128.4/30 - подсеть E
- 192.168.128.0/30 - подсеть F
ACL (с теорией)
ACL-список — это ряд команд IOS, определяющих, пересылает ли маршрутизатор пакеты или сбрасывает их, исходя из информации в заголовке пакета. ACL-списки являются одной из наиболее используемых функций операционной системы Cisco IOS.
В зависимости от конфигурации ACL-списки выполняют следующие задачи:
Ограничение сетевого трафика для повышения производительности сети. Например, если корпоративная политика запрещает видеотрафик в сети, необходимо настроить и применить ACL- списки, блокирующие данный тип трафика. Подобные меры значительно снижают нагрузку на сеть и повышают её производительность.
Вторая задача ACL-списков — управление потоком трафика. ACL- списки могут ограничивать доставку обновлений маршрутизации. Настройка сети, устраняющая необходимость в обновлениях маршрутизации, позволяет избежать лишнего использования полосы пропускания.
Списки контроля доступа обеспечивают базовый уровень безопасности в отношении доступа к сети. ACL-списки могут открыть доступ к части сети одному узлу и закрыть его для других узлов. Например, доступ к сети отдела кадров может быть ограничен и разрешён только авторизованным пользователям.
ACL-списки осуществляют фильтрацию трафика на основе типа трафика. Например, ACL-список может разрешать трафик электронной почты, но при этом блокировать весь трафик протокола Telnet.
Маршрутизатор работает как фильтр пакетов, перенаправляет или отбрасывает пакеты на основе правил фильтрации. Фильтрующий пакеты маршрутизатор извлекает определённую информацию из поступающего на него пакета.
Для оценки сетевого трафика, ACL-список извлекает следующую информацию из заголовка пакета уровня 3:
IP-адрес назначения;
ACL-список также может извлекать информацию более высокого уровня
из заголовка уровня 4, включая:
порт источника TCP/UDP;
Существует два типа ACL-списков Cisco для IPv4: стандартные и
расширенные ACL-списки.
Стандартные ACL-списки можно использовать для разрешения или
отклонения прохождения трафика только на основе IPv4-адреса источника.
Пример стандартного ACL-списка:
• access-list 10 permit 192.168.30.0 0.0.0.255 - разрешён весь трафик от 192.168.30.0/24. Из - за неявного правила «deny any» в конце списка данный ACL- список блокирует весь остальной трафик .
Пример расширенного ACL- списка :
• access-list 103 permit tcp 192.168.30.0 0.0.0.255 any eq 80 - ACL- список
Расширенные ACL-списки фильтруют IPv4-пакеты, исходя из нескольких признаков:
TCP или UDP порты источника;
TCP или UDP порты назначения;
Стандартные и расширенные списки контроля доступа можно создавать с помощью номера или имени. Номер присваивается в зависимости то того, какой протокол будет фильтроваться. (От 1 до 99) и (от 1300 до 1999) - стандартный ACL-список протокола IP, (От 100 до 199) и (от 2000 до 2699) - расширенный ACL-список протокола IP.
Присвоение имён ACL-спискам упрощает понимание функции того или иного списка. Например, ACL-списку, настроенному для запрета FTP, можно присвоить имя «NO_FTP».
Логика ACL- списка .
access-list 2 deny 192.168.10.10
access-list 2 permit 192.168.10.0 0.0.0.255
access-list 2 deny 192.168.0.0 0.0.255.255
access-list 2 permit 192.0.0.0 0.255.255.255
Когда трафик поступает на маршрутизатор, он сравнивается с записями в порядке, заданном в ACL-списке. Маршрутизатор продолжает обработку пакетов, пока не обнаружит совпадение. Маршрутизатор обрабатывает пакет на основе первого найденного совпадения, остальные записи маршрутизатором не учитываются.
ВОТ ЭТО ТИПА ОЧЕНЬ НУЖНО:
Стандартный ACL позволяет указывать только IP-адрес отправителя:
Применение ACL на интерфейсе :
Расширенный ACL, при указании протоколов IP, ICMP, TCP, UDP и др., позволяет указывать IP-адреса отправителя и получателя:
Еще одной проблемой, которую нужно учитывать при объединении трех и более компьютеров, является проблема их адресации, точнее сказать адресации их сетевых интерфейсов 3 Иногда вместо точного "адрес сетевого интерфейса " мы будем использовать упрощенное выражение "адрес узла сети". . Один компьютер может иметь несколько сетевых интерфейсов. Например, для образования физического кольца каждый компьютер должен быть оснащен как минимум двумя сетевыми интерфейсами для связи с двумя соседями. А для создания полносвязной структуры из N компьютеров необходимо, чтобы у каждого из них имелся N-1 интерфейс .
Адреса могут использоваться для идентификации не только отдельных интерфейсов, но и их групп ( групповые адреса). С помощью групповых адресов данные могут направляться сразу нескольким узлам. Во многих технологиях компьютерных сетей поддерживаются так называемые широковещательные адреса . Данные, направленные по такому адресу, должны быть доставлены всем узлам сети.
Множество всех адресов, которые являются допустимыми в рамках некоторой схемы адресации, называется адресным пространством . Адресное пространство может иметь плоскую (линейную) (рис. 4.9) или иерархическую (рис. 4.10) организацию. В первом случае множество адресов никак не структурировано.
При иерархической схеме адресации оно организовано в виде вложенных друг в друга подгрупп, которые, последовательно сужая адресуемую область, в конце концов определяют отдельный сетевой интерфейс .
Рис. 4.10. Иерархическая структура адресного пространства.
На рис. 4.10 показана трехуровневая структура адресного пространства, при которой адрес конечного узла задается тремя составляющими: идентификатором группы (K), в которую входит данный узел, идентификатором подгруппы (L) и, наконец, идентификатором узла (n), однозначно определяющим его в подгруппе . Иерархическая адресация во многих случаях оказывается более рациональной, чем плоская. В больших сетях, состоящих из многих тысяч узлов, использование плоских адресов может привести к большим издержкам — конечным узлам и коммуникационному оборудованию придется работать с таблицами адресов, состоящими из тысяч записей. А иерархическая система адресации позволяет при перемещении данных до определенного момента пользоваться только старшей составляющей адреса, затем для дальнейшей локализации адресата следующей по старшинству частью, и в конечном счете — младшей частью. Примером иерархически организованных адресов служат обычные почтовые адреса, в которых последовательно уточняется местонахождение адресата: страна, город, улица, дом, квартира.
К адресу сетевого интерфейса и схеме его назначения можно предъявить несколько требований:
Нетрудно заметить, что эти требования противоречивы — например, адрес , имеющий иерархическую структуру, скорее всего, будет менее компактным, чем плоский. Символьные имена удобны, но из-за переменного формата и потенциально большой длины их передача по сети не очень экономична. Так как все перечисленные требования трудно совместить в рамках какой-либо одной схемы адресации, на практике обычно используется сразу несколько схем, так что сетевой интерфейс компьютера может одновременно иметь несколько адресов-имен. Каждый адрес используется в той ситуации, когда соответствующий вид адресации наиболее удобен. А для преобразования адресов из одного вида в другой используются специальные вспомогательные протоколы, которые называют иногда протоколами разрешения адресов (address resolution) .
Примером плоского числового адреса является МАС- адрес , используемый для однозначной идентификации сетевых интерфейсов в локальных сетях. Такой адрес обычно применяется только аппаратурой, поэтому его стараются сделать по возможности компактным и записывают в виде двоичного или шестнадцатеричного значения, например 0081005e24a8. Когда задаются МАС-адреса, вручную ничего делать не нужно, так как они обычно встраиваются в аппаратуру компанией-изготовителем; их называют еще аппаратными (hardware) адресами . Использование плоских адресов является жестким решением — при замене аппаратуры, например сетевого адаптера, изменяется и адрес сетевого интерфейса компьютера.
Проблема установления соответствия между адресами различных типов, которой занимаются протоколы разрешения адресов, может решаться как централизованными, так и распределенными средствами. В случае централизованного подхода в сети выделяется один или несколько компьютеров (серверов имен), в которых хранится таблица соответствия друг другу имен различных типов, например символьных имен и числовых номеров. Все остальные компьютеры обращаются к серверу имен, чтобы по символьному имени найти числовой номер компьютера, с которым необходимо обменяться данными.
Адреса могут использоваться для идентификации:
- отдельных интерфейсов;
- их групп (групповые адреса);
- сразу всех сетевых интерфейсов сети ( широковещательные адреса ).
Адреса могут быть:
- числовыми и символьными ;
- аппаратными и сетевыми ;
- плоскими и иерархическими.
Для преобразования адресов из одного вида в другой используются протоколы разрешения адресов ( address resolution ).
Еще одной важнейшей задачей построения сетей является создание эффективного механизма коммутации. В следующей лекции мы рассмотрим это фундаментальное понятие с самых общих позиций.
Основная функция любого процессора, ради которой он и создается, — это выполнение команд. Система команд , выполняемых процессором, представляет собой нечто подобное таблице истинности логических элементов или таблице режимов работы более сложных логических микросхем. То есть она определяет логику работы процессора и его реакцию на те или иные комбинации внешних событий.
Написание программ для микропроцессорной системы — важнейший и часто наиболее трудоемкий этап разработки такой системы. А для создания эффективных программ необходимо иметь хотя бы самое общее представление о системе команд используемого процессора. Самые компактные и быстрые программы и подпрограммы создаются на языке Ассемблер , использование которого без знания системы команд абсолютно невозможно, ведь язык Ассемблер представляет собой символьную запись цифровых кодов машинного языка , кодов команд процессора. Конечно, для разработки программного обеспечения существуют всевозможные программные средства . Пользоваться ими обычно можно и без знания системы команд процессора. Чаще всего применяются языки программирования высокого уровня, такие как Паскаль и Си . Однако знание системы команд и языка Ассемблер позволяет в несколько раз повысить эффективность некоторых наиболее важных частей программного обеспечения любой микропроцессорной системы — от микроконтроллера до персонального компьютера.
Именно поэтому в данной главе мы рассмотрим основные типы команд , имеющиеся у большинства процессоров, и особенности их применения.
Каждая команда , выбираемая (читаемая) из памяти процессором, определяет алгоритм поведения процессора на ближайшие несколько тактов. Код команды говорит о том, какую операцию предстоит выполнить процессору и с какими операндами (то есть кодами данных), где взять исходную информацию для выполнения команды и куда поместить результат (если необходимо). Код команды может занимать от одного до нескольких байт , причем процессор узнает о том, сколько байт команды ему надо читать, из первого прочитанного им байта или слова. В процессоре код команды расшифровывается и преобразуется в набор микроопераций , выполняемых отдельными узлами процессора. Но разработчику микропроцессорных систем это знание не слишком важно, ему важен только результат выполнения той или иной команды.
3.1. Адресация операндов
3.1.1. Методы адресации
Количество методов адресации в различных процессорах может быть от 4 до 16. Рассмотрим несколько типичных методов адресации операндов , используемых сейчас в большинстве микропроцессоров.
Непосредственная адресация (рис. 3.1) предполагает, что операнд (входной) находится в памяти непосредственно за кодом команды. Операнд обычно представляет собой константу, которую надо куда-то переслать, к чему-то прибавить и т.д. Например, команда может состоять в том, чтобы прибавить число 6 к содержимому какого-то внутреннего регистра процессора. Это число 6 будет располагаться в памяти, внутри программы в адресе, следующем за кодом данной команды сложения.
Прямая (она же абсолютная) адресация (рис. 3.2) предполагает, что операнд (входной или выходной) находится в памяти по адресу, код которого находится внутри программы сразу же за кодом команды. Например, команда может состоять в том, чтобы очистить (сделать нулевым) содержимое ячейки памяти с адресом 1000000. Код этого адреса 1000000 будет располагаться в памяти, внутри программы в следующем адресе за кодом данной команды очистки.
Регистровая адресация (рис. 3.3) предполагает, что операнд (входной или выходной) находится во внутреннем регистре процессора. Например, команда может состоять в том, чтобы переслать число из нулевого регистра в первый. Номера обоих регистров (0 и 1) будут определяться кодом команды пересылки .
Косвенно-регистровая (она же косвенная) адресация предполагает, что во внутреннем регистре процессора находится не сам операнд , а его адрес в памяти (рис. 3.4). Например, команда может состоять в том, чтобы очистить ячейку памяти с адресом, находящимся в нулевом регистре. Номер этого регистра (0) будет определяться кодом команды очистки.
Реже встречаются еще два метода адресации .
Автоинкрементная адресация очень близка к косвенной адресации, но отличается от нее тем, что после выполнения команды содержимое используемого регистра увеличивается на единицу или на два. Этот метод адресации очень удобен, например, при последовательной обработке кодов из массива данных, находящегося в памяти. После обработки какого-то кода адрес в регистре будет указывать уже на следующий код из массива. При использовании косвенной адресации в данном случае пришлось бы увеличивать содержимое этого регистра отдельной командой.
Автодекрементная адресация работает похоже на автоинкрементную, но только содержимое выбранного регистра уменьшается на единицу или на два перед выполнением команды. Эта адресация также удобна при обработке массивов данных. Совместное использование автоинкрементной и автодекрементной адресаций позволяет организовать память стекового типа (см. раздел 2.4.2).
Из других распространенных методов адресации можно упомянуть об индексных методах, которые предполагают для вычисления адреса операнда прибавление к содержимому регистра заданной константы (индекса). Код этой константы располагается в памяти непосредственно за кодом команды.
Отметим, что выбор того или иного метода адресации в значительной степени определяет время выполнения команды. Самая быстрая адресация — это регистровая, так как она не требует дополнительных циклов обмена по магистрали. Если же адресация требует обращения к памяти, то время выполнения команды будет увеличиваться за счет длительности необходимых циклов обращения к памяти. Понятно, что чем больше внутренних регистров у процессора, тем чаще и свободнее можно применять регистровую адресацию, и тем быстрее будет работать система в целом.
3.1.2. Сегментирование памяти
Говоря об адресации, нельзя обойти вопрос о сегментировании памяти, применяемой в некоторых процессорах, например в процессорах IBM PC-совместимых персональных компьютеров.
В процессоре Intel 8086 сегментирование памяти организовано следующим образом.
Вся память системы представляется не в виде непрерывного пространства, а в виде нескольких кусков — сегментов заданного размера (по 64 Кбайта), положение которых в пространстве памяти можно изменять программным путем.
Для хранения кодов адресов памяти используются не отдельные регистры, а пары регистров:
- сегментный регистр определяет адрес начала сегмента (то есть положение сегмента в памяти);
- регистр указателя (регистр смещения) определяет положение рабочего адреса внутри сегмента.
При этом физический 20-разрядный адрес памяти, выставляемый на внешнюю шину адреса , образуется так, как показано на рис. 3.5, то есть путем сложения смещения и адреса сегмента со сдвигом на 4 бита. Положение этого адреса в памяти показано на рис. 3.6.
Сегмент может начинаться только на 16-байтной границе памяти (так как адрес начала сегмента, по сути, имеет четыре младших нулевых разряда, как видно из рис. 3.5), то есть с адреса, кратного 16. Эти допустимые границы сегментов называются границами параграфов.
Отметим, что введение сегментирования , прежде всего, связано с тем, что внутренние регистры процессора 16-разрядные, а физический адрес памяти 20-разрядный (16-разрядный адрес позволяет использовать память только в 64 Кбайт, что явно недостаточно). В появившемся в то же время процессоре MC68000 фирмы Motorola внутренние регистры 32-разрядные, поэтому там проблемы сегментирования памяти не возникает.
Рис. 3.5. Формирование физического адреса памяти из адреса сегмента и смещения.
Рис. 3.6. Физический адрес в сегменте (все коды — шестнадцатеричные).
Применяются и более сложные методы сегментирования памяти. Например, в процессоре Intel 80286 в так называемом защищенном режиме адрес памяти вычисляется в соответствии с рис. 3.7.
В сегментном регистре в данном случае хранится не базовый (начальный) адрес сегментов, а коды селекторов, определяющие адреса в памяти, по которым хранятся дескрипторы (то есть описатели) сегментов. Область памяти с дескрипторами называется таблицей дескрипторов. Каждый дескриптор сегмента содержит базовый адрес сегмента, размер сегмента (от 1 до 64 Кбайт) и его атрибуты. Базовый адрес сегмента имеет разрядность 24 бит, что обеспечивает адресацию 16 Мбайт физической памяти.
Рис. 3.7. Адресация памяти в защищенном режиме процессора Intel 80286.
Таким образом, на сумматор , вычисляющий физический адрес памяти, подается не содержимое сегментного регистра, как в предыдущем случае, а базовый адрес сегмента из таблицы дескрипторов.
Еще более сложный метод адресации памяти с сегментированием использован в процессоре Intel 80386 и в более поздних моделях процессоров фирмы Intel. Этот метод иллюстрируется рис. 3.8.
Адрес памяти (физический адрес) вычисляется в три этапа. Сначала вычисляется так называемый эффективный адрес (32-разрядный) путем суммирования трех компонентов: базы, индекса и смещения (Base, Index, Displacement ), причем возможно умножение индекса на масштаб (Scale). Эти компоненты имеют следующий смысл:
Рис. 3.8. Формирование физического адреса памяти процессора 80386 в защищенном режиме.
Затем специальный блок сегментации вычисляет 32-разрядный линейный адрес, который представляет собой сумму базового адреса сегмента из сегментного регистра с эффективным адресом. Наконец, физический 32-битный адрес памяти образуется путем преобразования линейного адреса блоком страничной переадресации, который осуществляет перевод линейного адреса в физический страницами по 4 Кбайта.
В любом случае сегментирование позволяет выделить в памяти один или несколько сегментов для данных и один или несколько сегментов для программ. Переход от одного сегмента к другому сводится всего лишь к изменению содержимого сегментного регистра. Иногда это бывает очень удобно. Но для программиста работать с сегментированной памятью обычно сложнее, чем с непрерывной, несегментированной памятью, так как приходится следить за границами сегментов, за их описанием, переключением и т.д.
3.1.3. Адресация байтов и слов
Многие процессоры, имеющие разрядность 16 или 32, способны адресовать не только целое слово в памяти (16-разрядное или 32-разрядное), но и отдельные байты. Каждому байту в каждом слове при этом отводится свой адрес.
Так, в случае 16-разрядных процессоров все слова в памяти (16-разрядные) имеют четные адреса. А байты, входящие в эти слова, могут иметь как четные адреса, так и нечетные.
Например, пусть 16-разрядная ячейка памяти имеет адрес 23420 , и в ней хранится код 2А5Е (рис. 3.9).
При обращении к целому слову (с содержимым 2А5Е ) процессор выставляет адрес 23420 . При обращении к младшему байту этой ячейки (с содержимым 5Е ) процессор выставляет тот же самый адрес 23420 , но использует команду, адресующую байт, а не слово. При обращении к старшему байту этой же ячейки (с содержимым 2А ) процессор выставляет адрес 23421 и использует команду, адресующую байт. Следующая по порядку 16-разрядная ячейка памяти с содержимым 487F будет иметь адрес 23422 , то есть опять же четный. Ее байты будут иметь адреса 23422 и 23423 .
Для различия байтовых и словных циклов обмена на магистрали в шине управления предусматривается специальный сигнал байтового обмена. Для работы с байтами в систему команд процессора вводятся специальные команды или предусматриваются методы байтовой адресации.
Читайте также: