
Что такое каналы памяти на материнской плате
Обновлено: 21.08.2024
Приветствую. Люди попадаются в комментариях "разнокалиберные". Одни знатоки, вторые неопытные и не посвященные, а третья категория, те кто пытаются понять и научится, но из-за обилия информации, путаются и делают ошибочные выводы. Решил выделить на канале ряд статей, посвященных новичкам. Постараюсь без тяжелых формулировок и терминологий, донести до новичков ту информацию, что важна. Рассмотрю вопросы взятые из комментариев и постараюсь "по-простому", дать ответ. Без углублений в термины, где будет уместно, для понимания, приведу примеры.
Статью "разобью" на пункты в виде вопросов. Комментарии оставлю открытыми, с единственной просьбой писать без заумных мыслей.
Пункт 2:"Двухканальный режим". Обещал писать коротко и понятно. Вот краткое резюме: В двухканальном "быстрее". Далее укажу почему и как активировать. Для задействования такого режима, устанавливают две плашки ОЗУ одинакового объёма. Порядок установки для двухканального режима прописывается в описании к материнской плате. Это может быть установка планки "по цветам" или "через одну" и тд.
Теперь поговорим почему. Скорость оперативки вещь хитрая и "в двух словах" рассказать не выйдет, по этому не стану пока грузить таймингами, а перейду к пропускной скорости которая пропорциональна частоте и ширине шины. Не комильфо получилось объяснить. Давайте на примере. Скорость автомобилей на трассе зависит от: ширины трассы, средней скорости автомобилей, погодных условий и тд. Вот и у ОЗУ, на скорость воздействуют не один фактор. Позже рассмотрим каждый в отдельности. А пока вернемся к двухканальности. Представьте 32Гб ОЗУ 1 планкой. С шириной шины: 64 бит. Сколько бы пользователь не накидывал гигабайтов, ширина остается 64 бит. Это как если при провозе миллиона людей, ширина дороги составляла бы 1.5 метра. То есть даже если задействовать 100 машин, то проезжать будут только по одной. А теперь двухканальный режим. При этом ширина шины становится дополнительно шире на 64 бита. То есть становится уже дорога в два раза шире. Возвращаясь к примеру, по дороге проедут уже сразу по 2 машины, что ускорит результат. Вот и выходит увеличение скорости в 2 раза.
Пункт 3:"Тайминги ОЗУ". В начале статьи писал, что эта публикация для новичков и без заумных формулировок и пояснений. Поэтому скажу кратко: новичку вдаваться в подробности, нет резона. Неопытному и непонимающему в "железе" человеку, категорически рекомендую вычеркнуть это определение из памяти. Однако, если забыть о таймингах не получается, то постарайтесь кратко запомнить одно: эти тайминги обозначают задержку сигнала динамической ОЗУ. Но как уже писал и повторю: неопытному пользователю, который только начинает знакомство с ПК, значения латентности будут только сбивать с толку. Для "дотошных" на канале опубликована статья, где подробно описано о таймингах памяти.
Пункт 4:"Частота". Выше показатель, быстрее обработка. Производительность ОЗУ напрямую отображается в частоте. Так например у DDR частота 200 Мгц, а уже у DDR4 достигает 3333 МГц. В качестве примера используйте автомобиль и "максимальную" скорость. Память DDR4 с частотой 3200 МГц, быстрее чем DDR4 2133 МГц. Отступление для собирающих игровой пк: частота ОЗУ не поднимает FPS. Если подвести итоги 4 пункта, получится короткий вывод: частота оперативки влияет на скорость работы ОЗУ.
Пункт 5:"Количество(ёмкость) памяти". Этот показатель олицетворяет объём информации, который записывается в ОЗУ. Разумеется чем больше этот объём, там быстрее операция будет завершена. Так например в играх, загрузка уровней напрямую зависит от такой ёмкости. В качестве примера это автобус и автомобиль. Задача перевезти людей двигаясь с одинаковой скоростью. В итоге людей перевезут, однако автобус выполнит это быстрее, так как за раз будет брать в 4 раза больше, а легковой автомобиль будет это делать в 4 раза дольше. Поэтому выбирайте планки "максимального" объёма.
На этом статью заканчиваю. Подписывайтесь. Ставьте лайки. До свидания.

При разгоне памяти имеет значение каждый нюанс, даже тонкости разводки конкретной материнской платы. Что же такое I-топология, T-топология и Daisy Chain? Давайте разберемся, какие бывают, как влияют длина канала и качество согласования волнового сопротивления линии связи. Рассмотрим, какую конфигурацию ОЗУ лучше выбрать в конкретных условиях.
Виды топологий материнских плат
Топологией называют схему соединения между собой функциональных узлов с помощью каналов связи. Применительно к компьютерной технике, существуют два вида соединения центрального процессора с оперативной памятью — в виде буквы «T» и Daisy Chain.

T-топология обеспечивает равноценные условия обмена информацией центрального процессора с каждой парой модулей ОЗУ. Поскольку они соединены параллельно, такая схема лучше оптимизирована для работы с четырьмя планками. С двумя модулями оперативки результат разгона будет хуже.
Большинство пользователей использует именно две планки памяти, поэтому схема не получила большого распространения. Она используется в премиальных материнских платах, где важен большой объем ОЗУ — например, ASRock X570 Extreme4.
Daisy Chain (переводится как «цепочка гирлянд») означает последовательное соединение модулей. Схема лучше подходит для двух планок памяти. При этом они обязательно должны быть установлены в «первые» слоты A2 и B2, то есть в ближайшие к процессору каналы связи. Если подключить все четыре модуля, задействовав неприоритетные слоты А1 и В1, частотные показатели ухудшатся. Топология очень популярна и используется в большинстве материнских плат.

Читать пример разгона процессора AMD Ryzen 9 3900X на материнской плате GIGABYTE X570 AORUS PRO с топологией Daisy Chain
Частный случай Daisy Chain, когда отсутствуют два дополнительных слота (не из-за экономии, а для достижения максимальных частот) называется I-топологией.

Эта схема подразумевает максимально возможный разгон оперативной памяти. Из-за отсутствия «хвостов» в виде неприоритетных слотов, обеспечивается наилучшее согласование канала связи процессора с двумя модулями ОЗУ. Пример такой материнской платы — ASUS ROG Strix X570-I Gaming.
Нужно понимать, что в бюджетных платах наличие всего двух слотов обусловлено экономией при производстве. Эта двухслотовость не имеет ничего общего с геймерскими решениями, предназначенными для экстремального разгона.
Как влияет длина канала связи
Как известно, скорость распространения электрического сигнала в проводнике равна скорости света. Давайте условно примем длину дорожки печатной платы, которая идет от процессора до оперативной памяти и обратно, равной 10 сантиметрам. Таким образом, время преодоления этого участка сигналом составляет 0,33 наносекунды. Это время затрачивается лишь на преодоление длины проводника, без учета времени на внутренние процессы. То есть, оперативная память минимум через 0,16 наносекунд получит сигнал, переданный процессором. И еще через 0,16 наносекунд ЦП получит ответ от ОЗУ.
Задержка накладывает ограничение на максимальное количество тактов в единицу времени при работе связки оперативная память — процессор. Нетрудно пересчитать ее в частоту, которая в данном случае составит 3 ГГц (а эффективная частота памяти, то есть, с удвоенным количеством передаваемых данных за такт — 6 ГГц).
Таким образом, чем длиннее канал связи, тем меньше максимальная частота ОЗУ. При T-топологии расстояние дорожек от ЦП до памяти одинаковое, но общая длина каналов больше, чем у Daisy Chain.

Как влияет согласование канала связи
Частота работы оперативной памяти соответствует радиочастотному диапазону: сигнал обмена процессора и ОЗУ, по сути, является радиосигналом. Поэтому условия переноса этого сигнала в проводнике полностью подчиняются законам распространения радиоволн.
Для надежной передачи радиосигнала, без потерь и переотражений от неоднородностей тракта передачи данных, необходимо, чтобы волновое сопротивление источника сигнала (процессора) и канала связи и нагрузки (оперативной памяти) были равны. В случае несоответствия волновых сопротивлений на каком-либо участке, возникает неоднородность. Радиосигнал частично проходит дальше к потребителю и частично отражается обратно — в сторону источника. Происходит наложение на последующий сигнал, что приводит к искажениям и возникновению ошибок при обработке оперативной памятью.
Очевидно, что при неискаженном сигнале разогнанная оперативная память работает на своих максимальных устойчивых значениях частот. При появлении искажений из-за несогласования волновых сопротивлений, происходит снижение стабильной рабочей частоты. Это случается, если не соблюдать рекомендации производителя — например, использовать только два модуля ОЗУ в материнской плате с Т-топологией.
Что такое ранг оперативной памяти и почему он важен
Рангом называется блок данных, состоящий из микросхем памяти, расположенных на модуле. Ранг не имеет ничего общего с физическим расположением микросхем на одной или обеих сторонах модуля.

Например, один ранг памяти можно набрать восемью микросхемами, имеющими ширину шины 8 бит, или шестнадцатью микросхемами, имеющими ширину 4 бита (см. рисунок). Общий объем памяти одного ранга равен сумме объемов памяти каждой микросхемы, входящей в этот ранг.
Двухранговая память состоит из двух одноранговых комплектов микросхем. На одном физическом модуле размещаются два полноценных логических узла, которые используют один канал связи на двоих. При работе они поочередно подключаются к этому каналу, что накладывает ограничение на разгон — контроллеру памяти труднее работать с двумя модулями, чем с одним.

Читать сравнение сравнение однорангового и двухрангового модулей ОЗУ
Как определить топологию
Большинство производителей предпочитают не указывать, какая топология шины памяти применяется в их материнских платах. Как же узнать схему соединения для конкретной модели? Самый простой вариант — отыскать в руководстве по эксплуатации информацию о том, с каким количеством модулей ОЗУ обеспечивается максимальная частота. Если с четырьмя, то применяется T-топология, а если с двумя — однозначно Daisy Chain. Когда производитель рекомендует устанавливать пару модулей в приоритетные слоты, то это тоже означает, что применена «гирлянда», или последовательное соединение модулей.

Для AMD энтузиасты создали специальную таблицу. Достаточно забить в поиске название материнской платы и посмотреть столбец «Memory Topology».
Рекомендации по конфигурациям ОЗУ
Материнские платы с T-топологией шины памяти оптимизированы для четырех одноранговых модулей памяти и обеспечивают с ними наилучший разгон. Несколько хуже будет с двумя одноранговыми модулями. Еще хуже — при наличии двух двухранговых плашек. И совсем плохой результат достигается с четырьмя двухранговыми модулями.
Топология Daisy Chain лучше всего подходит для двух одноранговых модулей памяти — это самый распространенный вариант при сборке ПК. Чуть хуже будет с двумя двухранговыми модулями. Еще хуже— с четырьмя одноранговыми плашками. И совсем плохая ситуация в случае с четырьмя двухранговыми модулями.

Если говорить о цифрах, то память на Daisy Chain топологии гонится лучше, чем на Т-топологии. Так, инженер компании MSI в лекции «В чем ключ к разгону памяти?» приводит конкретные примеры для контроллера IMC процессоров Intel 9-го поколения. При T-топологии компании удалось добиться максимальной частоты 4400 МГц при работе с четырьмя и 4133 МГц — с двумя модулями. Для Daisy Chain предел достигнут при 4600 МГЦ у двух планок, но за это пришлось заплатить нестабильной работой четырех — всего 4000 МГц.
Современные платы для энтузиастов поддерживают память частотой вплоть до 5400–5600 МГц.
На практике, топология платы имеет значение лишь когда мы говорим о работе памяти на частотах свыше 3600–3800 МГц. При меньших значениях ее влияние ничтожно и обращать на это внимание не стоит.

В продолжение рубрики "конспект админа" хотелось бы разобраться в нюансах технологий ОЗУ современного железа: в регистровой памяти, рангах, банках памяти и прочем. Подробнее коснемся надежности хранения данных в памяти и тех технологий, которые несчетное число раз на дню избавляют администраторов от печалей BSOD.
Сегодня на рынке представлены, в основном, модули с памятью DDR SDRAM: DDR2, DDR3, DDR4. Разные поколения отличаются между собой рядом характеристик – в целом, каждое следующее поколение "быстрее, выше, сильнее", а для любознательных вот табличка:
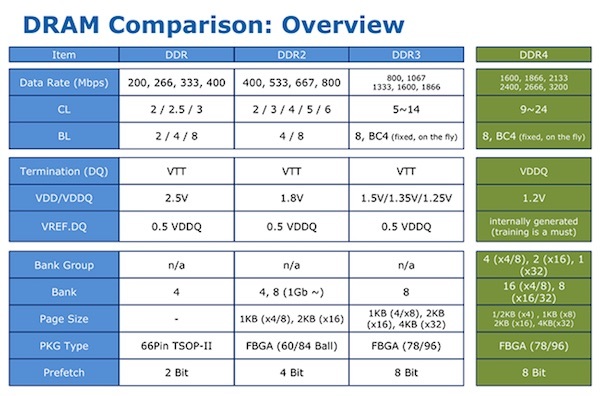
Для подбора правильной памяти больший интерес представляют сами модули:
RDIMM — регистровая (буферизованная) память. Удобна для установки большого объема оперативной памяти по сравнению с небуферизованными модулями. Из минусов – более низкая производительность;
UDIMM (unregistered DRAM) — нерегистровая или небуферизованная память — это оперативная память, которая не содержит никаких буферов или регистров;
LRDIMM — эти модули обеспечивают более высокие скорости при большей емкости по сравнению с двухранговыми или четырехранговыми модулями RDIMM, за счёт использования дополнительных микросхем буфера памяти;
HDIMM (HyperCloud DIMM, HCDIMM) — модули с виртуальными рангами, которые имеют большую плотность и обеспечивают более высокую скорость работы. Например, 4 физических ранга в таких модулях могут быть представлены для контроллера как 2 виртуальных;
Попытка одновременно использовать эти типы может вызвать самые разные печальные последствия, вплоть до порчи материнской платы или самой памяти. Но возможно использование одного типа модулей с разными характеристиками, так как они обратно совместимы по тактовой частоте. Правда, итоговая частота работы подсистемы памяти будет ограничена возможностями самого медленного модуля или контроллера памяти.
Для всех типов памяти SDRAM есть общий набор базовых характеристик, влияющий на объем и производительность:
частота и режим работы;
Конечно, отличий на самом деле больше, но для сборки правильно работающей системы можно ограничиться этими.
Понятно, что чем выше частота — тем выше общая производительность памяти. Но память все равно не будет работать быстрее, чем ей позволяет контроллер на материнской плате. Кроме того, все современные модули умеют работать в в многоканальном режиме, который увеличивает общую производительность до четырех раз.
Режимы работы можно условно разделить на четыре группы:
Single Mode — одноканальный или ассиметричный. Включается, когда в системе установлен только один модуль памяти или все модули отличаются друг от друга. Фактически, означает отсутствие многоканального доступа;
Dual Mode — двухканальный или симметричный. Слоты памяти группируются по каналам, в каждом из которых устанавливается одинаковый объем памяти. Это позволяет увеличить скорость работы на 5-10 % в играх, и до 70 % в тяжелых графических приложениях. Модули памяти необходимо устанавливать парами на разные каналы. Производители материнских плат обычно выделяют парные слоты одним цветом;
Для максимального быстродействия лучше устанавливать одинаковые модули с максимально возможной для системы частотой. При этом используйте установку парами или группами — в зависимости от доступного многоканального режима работы.
Ранг (rank) — область памяти из нескольких чипов памяти в 64 бита (72 бита при наличии ECC, о чем поговорим позже). В зависимости от конструкции модуль может содержать один, два или четыре ранга.
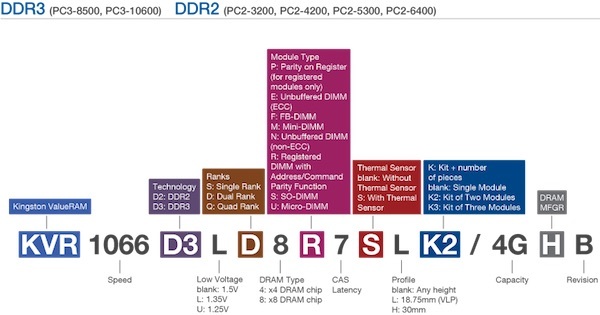
Узнать этот параметр можно из маркировки на модуле памяти. Например уKingston число рангов легко вычислить по одной из трех букв в середине маркировки: S (Single — одногоранговая), D (Dual — двухранговая), Q (Quad — четырехранговая).
Пример полной расшифровки маркировки на модулях Kingston:
Серверные материнские платы ограничены суммарным числом рангов памяти, с которыми могут работать. Например, если максимально может быть установлено восемь рангов при уже установленных четырех двухранговых модулях, то в свободные слоты память добавить не получится.
Перед покупкой модулей есть смысл уточнить, какие типы памяти поддерживает процессор сервера. Например, Xeon E5/E5 v2 поддерживают одно-, двух- и четырехранговые регистровые модули DIMM (RDIMM), LRDIMM и не буферизированные ECC DIMM (ECC UDIMM) DDR3. А процессоры Xeon E5 v3 поддерживают одно- и двухранговые регистровые модули DIMM, а также LRDIMM DDR4.
Тайминги или латентность памяти (CAS Latency, CL) — величина задержки в тактах от поступления команды до ее исполнения. Числа таймингов указывают параметры следующих операций:
CL (CAS Latency) – время, которое проходит между запросом процессора некоторых данных из памяти и моментом выдачи этих данных памятью;
tRCD (задержка от RAS до CAS) – время, которое должно пройти с момента обращения к строке матрицы (RAS) до обращения к столбцу матрицы (CAS) с нужными данными;
tRP (RAS Precharge) – интервал от закрытия доступа к одной строке матрицы, и до начала доступа к другой;
tRAS – пауза для возврата памяти в состояние ожидания следующего запроса;
Разумеется, чем меньше тайминги – тем лучше для скорости. Но за низкую латентность придется заплатить тактовой частотой: чем ниже тайминги, тем меньше допустимая для памяти тактовая частота. Поэтому правильным выбором будет "золотая середина".
Существуют и специальные более дорогие модули с пометкой "Low Latency", которые могут работать на более высокой частоте при низких таймингах. При расширении памяти желательно подбирать модули с таймингами, аналогичными уже установленным.
Для коррекции нерегулярных ошибок применяется ECC-память, которая содержит дополнительную микросхему для обнаружения и исправления ошибок в отдельных битах.
Метод коррекции ошибок работает следующим образом:
При записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит.
Когда процессор считывает данные, то выполняется расчет контрольной суммы полученных данных и сравнение с исходным значением. Если суммы не совпадают – это ошибка.
Технология Advanced ECC способна исправлять многобитовые ошибки в одной микросхеме, и с ней возможно восстановление данных даже при отказе всего модуля DRAM.
Исправление ошибок нужно отдельно включить в BIOS
Большинство серверных модулей памяти являются регистровыми (буферизованными) – они содержат регистры контроля передачи данных.
Регистры также позволяют устанавливать большие объемы памяти, но из-за них образуются дополнительные задержки в работе. Дело в том, что каждое чтение и запись буферизуются в регистре на один такт, прежде чем попадут с шины памяти в чип DRAM, поэтому регистровая память оказывается медленнее не регистровой на один такт.
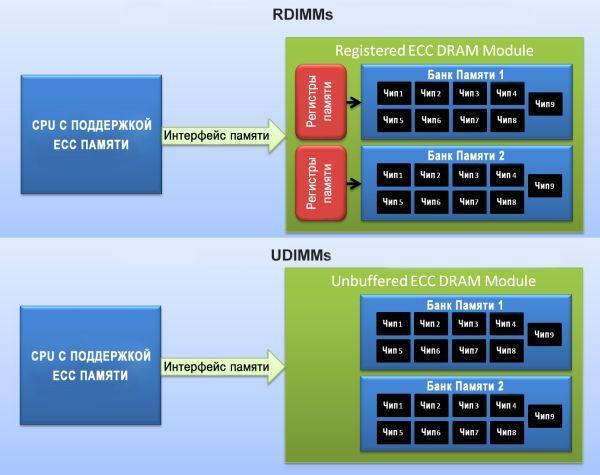
Все регистровые модули и память с полной буферизацией также поддерживают ECC, а вот обратное не всегда справедливо. Из соображений надежности для сервера лучше использовать регистровую память.
Для правильной и быстрой работы нескольких процессоров, нужно каждому из них выделить свой банк памяти для доступа "напрямую". Об организации этих банков в конкретном сервере лучше почитать в документации, но общее правило такое: память распределяем между банками поровну и в каждый ставим модули одного типа.
Если пришлось поставить в сервер модули с меньшей частотой, чем требуется материнской плате – нужно включить в BIOS дополнительные циклы ожидания при работе процессора с памятью.
Для автоматического учета всех правил и рекомендаций по установке модулей можно использовать специальные утилиты от вендора. Например, у HP есть Online DDR4 (DDR3) Memory Configuration Tool.
Вместо пространственного заключения приведу общие рекомендации по выбору памяти:
Для многопроцессорных серверов HP рекомендуется использовать только регистровую память c функцией коррекции ошибок (ECC RDIMM), а для однопроцессорных — небуферизированную с ECC (UDIMM). Планки UDIMM для серверов HP лучше выбирать от этого же производителя, чтобы избежать самопроизвольных перезагрузок.
В случае с RDIMM лучше выбирать одно- и двухранговые модули (1rx4, 2rx4). Для оптимальной производительности используйте двухранговые модули памяти в конфигурациях 1 или 2 DIMM на канал. Создание конфигурации из 3 DIMM с установкой модулей в третий банк памяти значительно снижает производительность.
Список короткий, но здесь все самое необходимое и наименее очевидное. Конечно же, старый как мир принцип RTFM никто не отменял.
В этой статье посмотрим на то как одноканал уменьшает скорость работы современных процессоров. Стоит напомнить, что во времена выхода DDR4 платформы с двумя каналами были у 4-х ядерных процессоров, тогда как сейчас есть 16 ядер у AMD и 10 ядер у Intel. И, естественно, шина к памяти теперь делиться на все эти ядра, тогда как и во времена 4-х ядер двухканал не был абсолютно достаточным.
Само собой производители в курсе проблемы. Так и Intel и AMD улучшают работу кеш памяти. Собственно следующее обновление AMD будет как бы минорным, то есть особо не инновационным, но благодаря трёхмерному кешу большого объёма от не самых архитектурно значимых изменений появится большой прирост в производительности. Intel же, кроме оптимизации работы с кешами, форсирует выход памяти DDR5, которая тоже немного уменьшит проблемы недостаточности двухканала для современных процессоров.

Собственно в этой статье мы как раз и посмотрим на изменение пропускной способности, так как по задержкам разницы не будет.
Что такое каналы памяти?
В современных процессорах контроллер оперативной памяти встроен в сам процессор и для обычных не серверных решений он имеет два канала.

И эта связь физическая, то есть контакты планок памяти физически приходят в разные контроллеры. Часть планок в один контроллер, часть во второй.

Если же к одному из контроллеров память не подключена, то этот контроллер ничего и не делает.
Собственно и планки памяти зачастую продаются как раз таки комплектами по две штуки, а иногда и по 4, так как есть платформы с 4-х канальными контроллерами памяти в процессорах.
Почему изменение каналов влияет на производительность?
Как понять, что процессор ограничен ПСП памяти?
Особенно это хорошо заметно в видеокартах некоторых моделей до тех поколений, где частоты динамически задаются от ограничения TDP. Там от разгона памяти увеличение энергопотребления самой памяти может составлять 2-3 Ватта, а при этом сама видеокарта начинает потреблять на 20-30 Ватт больше несмотря на то, что и до разгона памяти и после него показывалась загрузка в 100%. Просто раньше было 100%, но с простоями от ожидания информации, а после разгона памяти 100% стали с меньшими простоями. Сейчас с ограничением TPD и динамической частотой на картах от разгона памяти ситуация другая. Эффективная работа приводит к увеличению потребления из-за чего на 10-50 МГц режутся частоты ядер. Но при этом на меньших частотах видеокарта при разогнанной памяти всё равно быстрее, чем с более высокими, но с простоями от недостатка информации.
С процессорами это проявляется не так сильно и видно чаще у тех, кто вначале до предела разгоняет ядра, а после этого начинает до предела гнать память. И в этом случае чуть больший нагрев процессора от более эффективно работающей подсистемы памяти делает процессор менее стабильным в разгоне.
Ну и теперь приступим к практике.
Тестовая система
Процессор: intel i9 9900k в стоке,
Видеокарта: RTX 2070 в стоке.
Бенчмарки.
По задержкам по цифрам есть небольшая разница, и она обусловлена тем, что на один контроллер всё таки больше нагрузки, но разница по задержкам мизерная и сильно повлиять на результаты она не может. А вот пропускная способность меняется очень сильно.
По чтению и записи падение практически двукратное.
Ну и теперь посмотрим как это отражается на производительности компьютера.
Тесты в архиваторах
Добавление второго канала даёт прирост почти на 70%.
Возьмём другой архиватор. 7-Zip.

Тут прирост уже всего около 20%.
Бенчмарки
А есть задачи где прироста нет в принципе, то есть задача оптимизирована так, что максимально эффективно использует кеш процессора.
Например Cinebench R15.

Тесты в играх
Теория по играм
Понятное дело, что тут важна практика, но давайте всё таки цепанём немного теории.

За имитацию обсчётов у нас будет CPU тест в 3D Mark.
В тесте анимация происходит не за счёт отрисовки элементов, а за счёт просчёта положения частиц.

Но это только первая часть работы процессора.

Тут нам поможет тест 3D Mark API бенчмарк.
Он делает тесты в DX11, DX11 мультипоточном, DX 12 и Вулкане.
Начнём с однопоточного DX11.
Дальше у нас DX11 мультипоток.
Тут уже точно это не погрешность. От двухканала прирост больше 35%.
В новых API ситуация уже кардинально отличается.
На вулкане прирост около 75%.
Но главное отличие, конечно, ещё и в том, что данные в видеопамять поступают через северный мост процессора. То есть в моменты, когда идёт подгрузка текстур ширина канала ещё сильнее начинает ограничивать производительность процессора.

Этот процесс в бенчмарках сложно было бы подловить. Но думаю все знакомы с какими-то подлагами игры на подгрузках и с одноканалом эти подлагивания будут сильнее.
Практические тесты в играх
Игр в тест я взял не много, но выбрал на разных движках и API. Есть на 11DX, есть на 12 и есть на вулкане. Всего игр 4. Во всех играх стоят максимальные настройки, но со сниженным разрешением рендеринга.
В тестах важно рассматривать как изменяются показатели в динамики в зависимости от текущей сцены, так что этот раздел статьи стоит смотреть в видео версии:




Выводы
Видео на YouTube канале "Этот компьютер"
Читайте также: