Что такое кэш java
Обновлено: 07.07.2024
В Java 5 для оптимизации памяти и улучшения производительности появилась функция кеширования класса-оболочки Integer. Прежде чем говорить об этой функции, рассмотрим следующий пример :
В примере, на первый взгляд, нет ничего необычного. Все тривиально просто : определены 4 переменные, которым попарно присвоены одинаковые значения. С точки зрения Java, это четыре разных объекта. Поэтому попарные сравнения оператором '==' теоретически должны вернуть логическое false.
Примечание : необходимо отметить, что оператор сравнения '==' проверяет ссылки на объекты; значения объектов проверяются оператором equals. Поэтому в примере для целочисленных объектов лучше было бы использовать сравнение с оператором equals, т.е. if (integer3.equals(integer4))
Что странно в этом примере, так это разное поведение операторов сравнения : два похожих сравнения целочисленных объектов в операторах if возвращают различные логические значения. Но, вот, если значения переменных второй пары снизить до 125, т.е. определить значения в диапазоне от -128 до +127, то результаты сравнений будут одинаковы положительные (true).
Данное поведение целочисленных объектов объясняется использованием функции кэширования, введенное в Java 5. Целочисленные объекты кэшируются внутри, и повторно используются через те же связанные объекты. Это применимо для значений в диапазоне от -128 до + 127.
Автоупаковка и автораспаковка объектов
Целочисленное кэширование работает только при автоупаковке. При создании целочисленного объекта с помощью конструктора кэширование не работает. Автоупаковка (autoboxing) – это автоматическое преобразование, выполненное компилятором Java из примитива в соответствующий ему тип класса оболочки Java. Это все равно, что использовать valueOf следующим образом :
Автораспаковка (unboxing) – это преобразование класса-обёртки в соответствующий ему примитивный тип. Если при распаковке класс-обёртка был равен null, произойдет исключение java.lang.NullPointerException.
Поскольку арифметические операторы и операторы сравнения (исключение == и !=) применяются только к примитивным типам, приходилось делать распаковку вручную, что заметно снижало читабельность выражений, делая их громоздкими.
Благодаря автораспаковке можно смело использовать выражения, пренебрегая методами конвертации. Теперь это контролирует компилятор Java.
Таким образом, чтобы в примере достичь ожидаемого результата, следовало бы использовать конструктор, а не автоупаковку и автораспаковку, т.е. одну из переменных (или обе) инициализировать конструктором :
Таким образом, теперь мы знаем, где это кэширование должно быть реализовано в источнике Java JDK. Давайте посмотрим на исходный код метода valueOf от JDK (сборка 25 Java JDK 1.8.0).
Вот мы и вышли на класс IntegerCache, определяющий различное поведение целочисленных объектов.
Класс IntegerCache
IntegerCache – это внутренний статический класс объекта Integer. Он хорошо документирован в JDK. Посмотрим на его код :
В комментарии Javadoc ясно говорится, что данный класс предназначен для кэширования и для поддержки автоупаковки значений в диапазоне от -128 до 127. Максимальное значение 127 может быть изменено с помощью VM аргумента -XX:AutoBoxCacheMax=size. Таким образом, кэширование происходит в цикле for-loop. Он просто работает от минимального до максимального значений и создает целочисленные экземпляры, которые хранит в массиве 'cache'. Кэширование выполняется при первом использовании класса Integer. После этого кэшированные экземпляры используются вместо создания нового экземпляра (во время autoboxing).
Когда функция кэширования была впервые представлена в Java 5, диапазон значений был зафиксирован от -128 до +127. Позже в Java 6, максимальное значение диапазона было соотнесено с java.lang.Integer.IntegerCache.high, а аргумент VM позволяет установить бо́льшее значение, что придает гибкости для настройки производительности в соответствии с использованием приложения.
Другие кэшированные классы-оболочки
Кэширование касается не только класса-оболочки Integer. Имеются аналогичные реализации кэширования для других классов-оболочек целочисленных типов :
- ByteCache
- ShortCache
- LongCache
- CharacterCache
Классы Byte, Short, Long имеют фиксированный диапазон кэширования, т. е. значения от -128 до 127 включительно. Класс Character кэширует значения в диапазоне от 0 до 127 включительно. Диапазон кэширования этих классов не может быть изменен с помощью аргумента VM, как это делается для Integer.
Принудительное использование кэша в спецификации языка Java
В спецификации языка Java отмечено, что если значение p является целочисленным литералом типа int в диапазоне от -128 до 127 включительно (§3.10.1), или логическим литералом 'true' или 'false' (§3.10.3), или символьным литералом между ‘\u0000’ и ‘\u007f’ включительно (§3.10.4), то пусть тогда a и b являются результатами любых двух преобразований упаковки p. В этом случае всегда будет выполняться условие a == b.
Приведённая инструкция гарантирует, что ссылка на объекты со значениями от -128 до 127 должна быть одинаковой.
В идеале, упаковка примитивного значения всегда будет иметь идентичную ссылку. На практике это может оказаться невозможным с использованием существующих методов реализации. Правило выше – это прагматический компромисс, требующий, чтобы некоторые общие ценности всегда были упакованы в неразличимые объекты. Реализация может кэшировать их (быстро или медленно). Для других значений правило запрещает любые предположения относительно идентичности упакованных значений со стороны программиста. Это позволяет (но не требует) совместное использование некоторых или всех этих ссылок. Обратите внимание, что целочисленные литералы типа long могут быть общими, но не обязательными.
Для не очень мощных устройств в большинстве случаях кэширование обеспечивает желанное поведение. Менее ограниченные по памяти устройства (VM) могли бы, например, кэшировать все char и короткие значения, а также int и длинные значения в диапазоне от -32K до +32K.
Многократно вычитывая одни и те же данные, встает вопрос оптимизации, данные не меняются или редко меняются, это различные справочники и др. информация, т.е. функция получения данных по ключу — детерминирована. Тут наверно все понимают — нужен Кеш! Зачем всякий раз повторно выполнять поиск данных или вычисление?
Так вот здесь я покажу как делать кеш в Java Spring и поскольку это тесно связанно скорее всего с Базой данных, то и как сделать это в СУБД на примере одной конкретной.
- Кеш в Spring
- Кеш в Oracle PL-SQL функции
Кеш в Spring
Далее все поступают примерно одинаково, в Java используют различные HasMap, ConcurrentMap и др. В Spring тоже для это есть решение, простое, удобное, эффективное. Я думаю что в большинстве случаев это поможет в решении задачи. И так, все что нужно, это включить кеш и аннотировать функцию.
Делаем кеш доступным
Кешируем данные поиска функции
В аннотации указывается название кеша и есть еще другие параметры. Работает как и ожидается так, первый раз код выполняется, результат поиска помещается в кеш по ключу (в данном случае name) и последующие вызовы код уже не выполняется, а данные извлекаются из кеша.
Пример реализации репозитория «Person» с использованием кеша
Проверяю что получилось
В тесте вызываю два раза
, первый раз происходит вызов, поиск, в второй раз результат берется уже из кеша. Это видно в консоли

Удобно, можно точечно оптимизировать существующий функционал. Если в функции более одного аргумента, то можно указать имя параметра, какой использовать в качестве ключа.
Есть и более сложные схемы получения ключа, это в документации.
Но конечно встанет вопрос, как обновить данные в кеше? Для этой цели есть две аннотации.
Первая это @CachePut
Функция с этой аннотацией будет всегда вызывать код, а результат помещать в кеш, таким образом она сможет обновить кеш.
Добавлю в репозиторий два метода: удаления и добавления Person
Выполню поиск Person, удалю, добавлю, опять поиск, но по прежнему буду получать одно и тоже лицо из кеша, пока не вызову «findByNameAndPut»

Другая аннотация это @CacheEvict
Позволяет не просто посещать хранилище кеша, но и выселять. Этот процесс полезен для удаления устаревших или неиспользуемых данных из кеша.
По умолчанию Spring для кеша использует — ConcurrentMapCache, если есть свой отличный класс для организации кеша, то это возможно указать в CacheManager
Там же указываются имена кешей, их может быть несколько. В xml конфигурации это указывается так:

Кеш в Oracle PL-SQL функции
Ну и в конце, тем кто не пренебрегает мощностью СУБД, а использует ее, могут использовать кеширование на уровне БД, в дополнение или как альтернативу. Так например в Oracle не менее элегантно можно превратить обычную функцию, в функцию с кешированием результата, добавив к ней
После изменения данных в таблице, кеш будет перестроен, можно тонко настроить правило кеша с помощью
В этом уроке мы быстро рассмотрим и узнаем о кэш-памяти кода Jvm.
2. Что такое Кэш кода?
Проще говоря, Кэш кода JVM-это область, где JVM хранит свой байт-код, скомпилированный в машинный код . Каждый блок исполняемого машинного кода мы называем методом . Метод | может быть полным или онлайновым методом Java.
Компилятор just-in-time (JIT) является крупнейшим потребителем области кэша кода. Вот почему некоторые разработчики называют эту память кэшем JIT-кода.
3. Настройка кэша кода
- InitialCodeCacheSize – начальный размер кэша кода, по умолчанию 160K
- ReservedCodeCacheSize– максимальный размер по умолчанию составляет 48 МБ
- CodeCacheExpansionSize – размер расширения кэша кода, 32 КБ или 64 КБ
Увеличение ReservedCodeCacheSize может быть решением, но обычно это только временный обходной путь.
К счастью, JVM предлагает опцию UseCodeCacheFlushing для управления очисткой области кэша кода . Его значение по умолчанию равно false. Когда мы включаем его, он освобождает занятую область при выполнении следующих условий:
- кэш кода заполнен; эта область сбрасывается, если ее размер превышает определенный порог
- определенный интервал проходит с момента последней очистки
- предварительно скомпилированный код недостаточно горяч. Для каждого скомпилированного метода JVM отслеживает специальный счетчик горячности. Если значение этого счетчика меньше вычисленного порога, JVM освобождает этот фрагмент предварительно скомпилированного кода
4. Использование Кэша кода
Чтобы контролировать использование кэша кода, нам нужно отслеживать размер используемой в данный момент памяти.
Чтобы получить информацию об использовании кэша кода, мы можем указать параметр –XX:+PrintCodeCache JVM . После запуска нашего приложения мы увидим аналогичный результат:
Давайте посмотрим, что означает каждое из этих значений:
Опция PrintCodeCache очень полезна, так как мы можем:
- посмотрите, когда произойдет промывка
- определите, достигли ли мы критической точки использования памяти
5. Сегментированный Кэш Кода
Начиная с Java 9 , JVM делит кэш кода на три отдельных сегмента, каждый из которых содержит определенный тип скомпилированного кода . Чтобы быть более конкретным, есть три сегмента:
- Сегмент non-method содержит внутренний связанный код JVM, такой как интерпретатор байт-кода. По умолчанию этот сегмент составляет около 5 МБ. Кроме того, можно настроить размер сегмента с помощью флага настройки -XX:NonNMethodCodeHeapSize
- Сегмент профилированного кода содержит слегка оптимизированный код с потенциально коротким временем жизни. Несмотря на то, что размер сегмента по умолчанию составляет около 122 МБ, мы можем изменить его с помощью флага настройки -XX:ProfiledCodeHeapSize
- Непрофильный сегмент содержит полностью оптимизированный код с потенциально длительным сроком службы. Точно так же по умолчанию он составляет около 122 МБ. Это значение, конечно, настраивается с помощью флага настройки -XX:NonProfiledCodeHeapSize
Эта новая структура по-разному обрабатывает различные типы скомпилированного кода, что приводит к повышению общей производительности.
Например, отделение короткоживущего скомпилированного кода от долгоживущего кода повышает производительность метода sweeper-главным образом потому, что он должен сканировать меньшую область памяти.
6. Заключение
В этой краткой статье представлено краткое введение в кэш кода JVM.
Кроме того, мы представили некоторые варианты использования и настройки для мониторинга и диагностики этой области памяти.

Кэш - это временное хранилище для данных, которые с наибольшей вероятностью могут быть повторно запрошены. Загрузка данных из кэша осуществляется быстрее, чем из хранилища с исходными данными, но и его объём существенно ограничен.
Алгоритмы кэширования
Алгоритмы кэширования - это подробный список инструкций, который указывает, какие элементы следует отбрасывать в кэш. Их еще называют алгоритмами вытеснения или политиками вытеснения.
Когда кэш заполнен, алгоритм должен выбрать, какую именно запись следует из него удалить, чтобы записать новую, более актуальную информацию.
Least recently used - LRU (Вытеснение давно неиспользуемых)
LRU - это алгоритм, при котором вытесняются элементы, которые дольше всего не запрашивались. Соответственно, необходимо хранить время последнего запроса к элементу. И как только кэш становится заполненным, необходимо вытеснить из него элемент, который дольше всего не запрашивался.
Общая реализация этого алгоритма требует сохранения «бита возраста» для элемента и за счет этого происходит отслеживание наименее используемых элементов. В подобной реализации, при каждом обращении к элементу меняется его «возраст».

LRU на самом деле является семейством алгоритмов кэширования, в которое входит 2Q, а также LRU/K.
Для реализации понадобятся две структуры данных:
- Хеш-таблица, которая будет хранить закэшированные значения.
- Очередь, которая будет хранить приоритеты элементов и выполнять следующие операции:
- Добавить пару значение и приоритет.
- Извлечь (удалить и вернуть) значение с наименьшим приоритетом.
- Проверяем, есть ли значение в кэше:
- Если значение уже есть, то обновляем время последнего к нему запроса и возвращаем значение.
- Если значения нет в кэше - вычисляем его.
- Если кэш заполнен, то вытесняем самый старый элемент.
Достоинства:
- константное время выполнения и использование памяти.
Недостатки:
- алгоритм не учитывает ситуации, когда к определенным элементам обращаются часто, но с периодом, превышающим размер кэша (т.е. элемент успевает покинуть кэш).
Псевдо-LRU - PLRU
PLRU - это алгоритм, который улучшает производительность LRU тем, что использует приблизительный возраст, вместо поддержания точного возраста каждого элемента.
Most Recently Used - MRU (Наиболее недавно использовавшийся)
MRU - алгоритм, который удаляет самые последние использованные элементы в первую очередь. Он наиболее полезен в случаях, когда чем старше элемент, тем больше обращений к нему происходит.
Least-Frequently Used - LFU (Наименее часто используемый)
LFU - алгоритм, который подсчитывает частоту использования каждого элемента и удаляет те, к которым обращаются реже всего.
В LFU каждому элементу присваивается counter - счётчик. При повторном обращении к элементу его счётчик увеличивается на единицу. Таким образом, когда кэш заполняется, необходимо найти элемент с наименьшим счётчиком и заменить его новым элементом. Если же все элементы в кэше имеют одинаковый счётчик, то в этом случае вытеснение осуществляется по методу FIFO: первым вошёл - первым вышел.
Недостатки:
- много обращений к элементу за короткое время накручивает счётчик и в результате элемент зависает в кэше.
- алгоритм не учитывает “возраст” элементов.
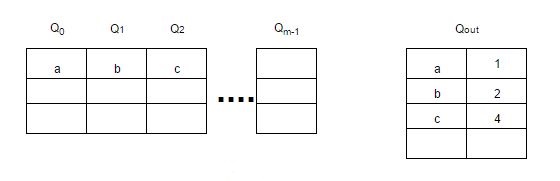
Multi queue - MQ (Алгоритм многопоточного кэширования)
MQ - алгоритм, использующий несколько LRU очередей - Q0, Q1, …, Qn, между которыми элементы ранжируются/перемещаются в зависимости от частоты обращения к ним.
В дополнение к очередям используется буфер “истории” - Qout, где хранятся все идентификаторы элементов со счётчиками (частота обращения к элементу). При заполнении Qout удаляется самый старый элемент.
Элементы остаются в LRU очередях в течение заданного времени жизни, которое динамически определяется специальным алгоритмом.
Если к очереди не ссылались в течение её времени жизни, то её приоритет понижается с Qi до Qi-1 или удаляется из кэша, если приоритет равен 0 - Q0.
Каждая очередь также имеет максимальное количество обращений к её элементам. Поэтому если к элементу в очереди Qi обращаются более 2i раз, то этот элемент перемещается в очередь Qi+1.
При заполнении кэша, будет вытеснен элемент из очереди Q0, который дольше всех не использовался.
Картинка для наглядности:
![mq-replacement-algortithm.jpg]()
Другие алгоритмы
Алгоритмов кэширования достаточно много, поэтому на данный момент не все здесь рассмотрены. С полным списком можно ознакомиться здесь.
Со временем буду дополнять.
Полезные ссылки
Алгоритмы кэширования - статья на wiki.
LRU (Least Recently Used) - подробная статья о LRU с примерами реализации на C, C++, Java.
LRU, метод вытеснения из кэша - статья о том, как быстро реализовать алгоритм LRU.
Least Frequently Used (LFU) Cache Implementation - статья о LFU с примером на C++.
LFU cache in O(1) in Java - пример реализации LFU на Java.
Алгоритмы кэширования - что-то вроде презентации некоторых алгоритмов кэширования в формате PDF.Читайте также: