
Что такое процессорный конвейер
Обновлено: 07.07.2024
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода.
При параллелизме совмещение операций достигается путем воспроизведения аппаратной обрабатывающей структуры в нескольких копиях. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения конвейризованных процессоров будем считать, что набор команд процессора включает типичные арифметические и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических командах используется трехадресный формат, типичный для RISC-процессоров; команды обработки используют регистровую адресацию, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды - IF (по адресу, заданному счетчиком команд РС, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров - ID;
- выполнение операции / вычисление исполнительного адреса памяти - EX;
- обращение к памяти - MEM;
- запоминание результата - WB.
Для организации конвейра мы можем разбить выполнение команд на указанные этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать буферные регистровые станции. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Работу конвейера можно условно представить в виде временной диаграммы (рис.1), на которой изображены выполняемые команды, номера тактов и этапы выполнения команд.
| Номер команды | Номер такта | ||||
| Команда i | IF | ID | EX | MEM | WB |
| Команда i+1 | IF | ID | EX | MEM | WB |
| Команда i+2 | IF | ID | EX | MEM | WB |
| Команда i+3 | IF | ID | EX | MEM | WB |
| Команда i+4 | IF | ID | EX | MEM | WB |
Рис. 1. Диаграмма работы простейшего конвейера.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением буферными регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рис.2). Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. При конвейерной организации длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере.
Конвейеризация эффективна тогда, когда загрузка конвейера близка к полной, скорость подачи новых команд и операндов соответствует максимальной производительности конвейера, а времена обработки на всех этапах конвейра одинаковы.
Рис. 2. Эффект конвейеризации при выполнении команд: а) неконвейризованное исполнение, б) конвейризованное исполнение.
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения. Например, машина может иметь только один порт записи в регистровый файл, но при определенных обстоятельствах конвейеру может потребоваться выполнить две записи в регистровый файл в одном такте. Когда последовательность команд наталкивается на такой конфликт, конвейер приостанавливает выполнение одной из команд до тех пор, пока не станет доступным требуемое устройство. Структурные конфликты возникают, например, и в машинах, в которых имеется единственный конвейер памяти для команд и данных. В этом случае, когда одна команда содержит обращение к памяти за данными, оно будет конфликтовать с выборкой более поздней команды из памяти.
2. Конфликты по данным возникающие в том случае, когда применение конвейерной обработки может изменить порядок обращений за операндами так, что этот порядок будет отличаться от порядка, который наблюдается при последовательном выполнении команд на неконвейерной машине.
ADD R1,R2,R3 - сложить R2 и R3, результат записать в R1
SUB R4,R1,R5 - из R1 вычесть R5, результат записать в R4
Команда ADD записывает результат в регистр R1, а команда SUB читает это значение. Если не предпринять никаких мер для того, чтобы предотвратить этот конфликт, команда SUB прочитает неправильное значение и попытается его использовать.
Конфликты по данным могут быть устранены на этапе генерации кода компилятором. Многие современные компиляторы используют технику планирования команд для улучшения производительности конвейера.
Например, для оператора А = B + С компилятор скорее всего сгенерирует следующую последовательность команд
| Номер команды | Номер такта | |||||
| LW R1,В | IF | ID | EX | MEM | WB | |
| LW R2,С | IF | ID | EX | MEM | WB | |
| ADD R3,R1,R2 | IF | ID | Stall | EX | MEM | WB |
| SW A,R3 | IF | Stall | ID | EX | MEM | WB |
Рис. 2. Конвейерное выполнение оператора А = В + С
Очевидно, выполнение команды ADD должно быть приостановлено до тех пор, пока не станет доступным поступающий из памяти операнд C.
Для данного простого примера компилятор никак не может улучшить ситуацию, однако в ряде более общих случаев он может реорганизовать последовательность команд так, чтобы избежать приостановок конвейера. Эта техника, называемая планированием загрузки конвейера (pipeline scheduling) или планированием потока команд (instruction scheduling), использовалась начиная с 60-х годов и стала особой областью интереса в 80-х годах, когда конвейерные машины стали более распространенными.
Пусть, например, имеется последовательность операторов: a = b + c; d = e - f;
Если код не оптимизирован, при выполнении каждого из этих операторов возникнет по одному такту приостановки. Но существует вариант переупорядочения команд, когда приостановки конвейера не произойдет.
В общем случае планирование загрузки конвейера компилятором может требовать увеличенного количества регистров.
Кроме того, существуют и аппаратные методы, позволяющие изменить порядок выполнения команд программы так, чтобы минимизировать приостановки конвейера.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конвейер команд
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
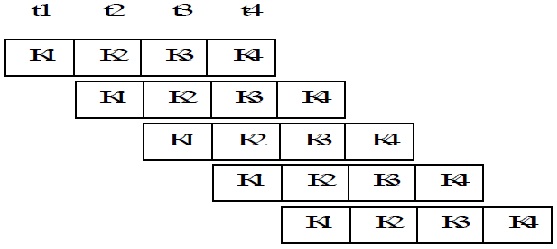
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
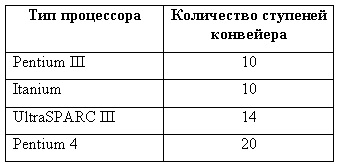
Суперконвейер
Трубопровод (также конвейер команд или процессор трубопровод ) описывает своего род «сборочная линия» в микропроцессорах , с которым обработка машинных инструкций разбиваются на подзадачи, которые проводятся в течение нескольких команд параллельно. Этот принцип, часто также сокращенно называемый конвейерной обработкой , является широко распространенной микроархитектурой современных процессоров.
Вместо всей команды в течение тактового цикла процессора обрабатывается только одна подзадача, хотя различные подзадачи нескольких команд обрабатываются одновременно. Поскольку эти подзадачи проще (и, следовательно, быстрее), чем обработка всей команды за один этап, конвейерная обработка может повысить эффективность тактовой частоты микропроцессора. В целом для одной команды теперь требуется несколько циклов для выполнения, но поскольку команда «завершается» в каждом цикле из-за квазипараллельной обработки нескольких команд, с помощью этого метода увеличивается общая пропускная способность.
Отдельные подзадачи трубопровода называются этапы трубопровода , этапы трубопровода или же участки трубопровода . Эти этапы разделены тактируемыми конвейерными регистрами . В дополнение к конвейеру команд в современных системах используются различные другие конвейеры, например арифметический конвейер в блоке с плавающей запятой .
Содержание
пример
Пример четырехэтапного конвейера команд:
A - Загрузить код инструкции (IF, Instruction Fetch) На этапе подготовки команды команда, адресуемая счетчиком команд, загружается из основной памяти. Затем счетчик команд увеличивается. B - инструкция по декодированию и загрузка данных (ID, инструкция по декодированию) На этапе декодирования и загрузки загруженная команда декодируется (1-я половина тактового сигнала), и необходимые данные загружаются из основной памяти и набора регистров (2-я половина тактового сигнала). C - выполнить команду (EX, Execution) Декодированная инструкция выполняется на этапе выполнения. Результат буферизуется защелкой конвейера . D - вернуть результаты (WB, Write Back) На этапе сохранения результатов результат записывается обратно в основную память или в набор регистров.
Синхронизация
Чем проще одноступенчатый, тем выше частота, с которой он может работать. В современном ЦП с частотой ядра в диапазоне гигагерц (1 ГГц
1 миллиард тактов в секунду) конвейер команд может иметь длину более 30 этапов (см. Микроархитектуру Intel NetBurst ). Тактовая частота ядра - это время, необходимое инструкции для прохождения одного этапа конвейера. В конвейере с k этапами инструкция обрабатывается за k циклов по k этапов. Поскольку в каждом цикле загружается новая инструкция, в идеале одна инструкция за цикл также покидает конвейер.
Время цикла определяется временем цикла конвейера и рассчитывается из максимума всех задержек стадий и дополнительных усилий , вызванных промежуточным хранением результатов в регистрах конвейера. τ м > τ я > d
Время цикла: τ знак равно Максимум я ( τ я ) + d знак равно τ м + d > (\ tau _ ) + d = \ tau _ + d>
повышение производительности
Конвейерная обработка увеличивает общую пропускную способность по сравнению с обработкой инструкций без конвейерной обработки. Общее время конвейерной обработки с этапами и командами со временем цикла получается из: k п τ
Общая продолжительность: Т k знак равно ( k + п - 1 ) ⋅ τ = (к + п-1) \ CDOT \ тау>
Изначально конвейер пуст и будет заполняться пошагово. После каждого этапа в конвейер загружается новая инструкция и выполняется другая инструкция. Поэтому остальные команды выполняются поэтапно. k ⋅ τ ( п - 1 ) ⋅ τ
Если вы теперь составите частное от общего времени выполнения для обработки команд с конвейерной обработкой и без нее, вы получите ускорение . Это представляет собой выигрыш в производительности, который достигается за счет процесса конвейерной обработки:
Предполагая, что всегда имеется достаточно инструкций для заполнения конвейера и что время цикла без конвейера в несколько раз больше, тогда предельное значение ускорения приводит для n к бесконечности: k
Это означает, что производительность может быть увеличена с увеличением количества ступеней . Однако обработка команды не может быть разделена на какое-либо количество этапов, и время цикла не может быть короче. Увеличение количества стадий также имеет более серьезные последствия, если возникают конфликты данных или элементов управления. Затраты на оборудование также увеличиваются с увеличением количества ступеней . k τ k
Конфликты
Если для обработки инструкции на одном этапе конвейера необходимо, чтобы сначала обрабатывалась инструкция, которая расположена дальше по конвейеру, то говорят о зависимостях . Это может привести к конфликтам ( опасностям ). Могут возникнуть три типа конфликтов:
- Конфликт ресурсов, когда одному этапу конвейера требуется доступ к ресурсу, который уже используется другим этапом.
- Конфликты данных
- на уровне команды: данные, используемые в команде, недоступны
- На уровне передачи: содержимое регистра, которое используется на шаге, недоступно
Эти конфликты требуют, чтобы соответствующие команды ожидали («остановились») в начале конвейера, что создает «пробелы» (также называемые «пузырями») в конвейере. В результате конвейер используется неоптимально и пропускная способность падает. Поэтому стараются максимально избегать этих конфликтов:
Конфликты ресурсов можно разрешить, добавив дополнительные функциональные блоки. Многие конфликты данных можно разрешить с помощью пересылки , при которой результаты дальнейших этапов обратного конвейера транспортируются вперед, как только они становятся доступными (а не в конце конвейера).
Количество конфликтов потока управления можно объяснить сокращением предсказания ветвления (англ. Branch prediction ). Здесь спекулятивные расчеты продолжаются до тех пор, пока не станет ясно, подтвердился ли прогноз. В случае неверного предсказания ветвления команды, выполненные за это время, должны быть отброшены ( очистка конвейера ), что занимает много времени, особенно в архитектурах с длинным конвейером (таких как Intel Pentium 4 или IBM Power5 ). Следовательно, в этих архитектурах используются очень сложные методы прогнозирования ветвлений, так что ЦП должен отбрасывать содержимое конвейера команд только менее чем в одном проценте выполняемых ветвлений.
Преимущества и недостатки
Преимущество длинных конвейеров - значительное увеличение скорости обработки. Недостатком является то, что одновременно обрабатывается много команд. В случае промывки конвейера все инструкции в конвейере должны быть отброшены, а затем конвейер снова заполнен. Для этого требуется перезагрузка инструкций из основной памяти или кеша инструкций ЦП, так что результатом большого времени ожидания является простоя процессора. Другими словами, чем больше количество команд между изменениями потока управления , тем больше выигрыш от конвейерной обработки, так как конвейер нужно очистить снова только после длительного периода использования при полной нагрузке .
Использование программного обеспечения
Программист может умело использовать знания о существовании конвейеров для оптимального использования процессора. В частности, можно избежать конфликтов потока управления.
Использование флагов вместо условных переходов
Если в архитектуре присутствует перенос (флаг переноса) и команды, позволяющие включать его в вычислительные команды, вы можете использовать его для установки логических переменных без ветвления.
Пример (8086 в синтаксисе Intel, т.е. в форме command destination,source ):
менее эффективно:Прыжки в более редком случае
Если в ветке известно, какой случай более вероятен, ветвление должно быть выполнено в менее вероятном случае. Если z. Например, если блок выполняется только в редких случаях, его не следует пропускать, если он не выполняется (как это было бы в структурном программировании), а должен быть расположен где-то в другом месте, переходить к нему с помощью условного перехода и возвращаться с помощью безусловного перехода, так что обычно не разветвленный.
Пример (8086):
много ветвей:Чередуйте разные ресурсы
Поскольку доступ к памяти и использование арифметико-логического устройства занимает относительно много времени, это может помочь поочередно использовать различные ресурсы по мере возможности.
Читайте также: