Если в файле robots txt присутствуют директивы user agent и user agent googlebot то
Обновлено: 07.07.2024
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
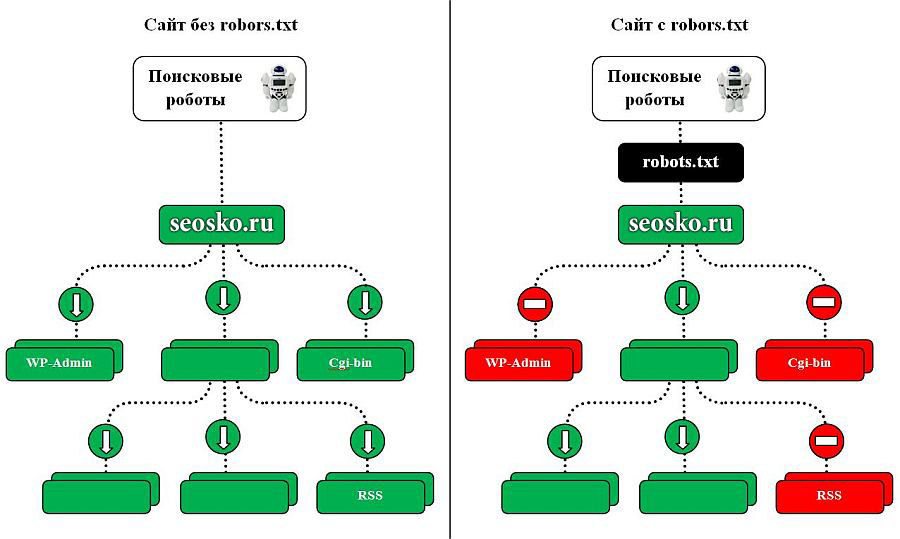
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:
User-agent: *
Для конкретного бота:
User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Crawl-delay
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt

Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
Пример robots.txt
Как добавить и где находится robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt

В конце статьи приведу несколько типичных ошибок файла robots.txt
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Если вы применяете сервис управления хостингом сайта, например Wix или Blogger, вероятно, вам не понадобится редактировать файл robots.txt напрямую или у вас даже не будет такой возможности. Ваш провайдер может указывать поисковым системам, нужно ли сканировать ваш контент, с помощью страницы настроек поиска или какого-нибудь другого инструмента.
Если вы хотите запретить или разрешить поисковым системам обработку определенной страницы, попробуйте найти в сервисе управления хостингом сайта информацию о том, как управлять видимостью представленного на сайте контента в поисковых системах. Пример запроса: "wix как скрыть страницу от поисковых систем".
Ниже приведен пример простого файла robots.txt с двумя правилами.
Более подробные сведения вы найдете в разделе Синтаксис.
Основные рекомендации по созданию файла robots.txt
Чтобы создать файл robots.txt и сделать его доступным, необходимо выполнить четыре действия:
Как создать файл robots.txt
Создать файл robots.txt можно в любом текстовом редакторе, таком как Блокнот, TextEdit, vi или Emacs. Не используйте текстовые процессоры, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами. Обязательно сохраните файл в кодировке UTF-8, если в диалоговом окне будет доступен выбор.
Правила в отношении формата и расположения файла
Как добавить правила в файл robots.txt
Правила – это инструкции для поисковых роботов. Таким образом роботы понимают, какие разделы сайта можно сканировать. Добавляя правила в файл robots.txt, учитывайте следующее:
- В составе файла robots.txt – одна группа или более .
- Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами или инструкциями. Каждая группа начинается со строки User-agent , определяющей, какому роботу адресованы правила.
- Группа содержит следующую информацию:
- К какому агенту пользователя относятся директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
Директивы, которые используются в файлах robots.txt
Все директивы, кроме sitemap , поддерживают подстановочный знак * для обозначения префикса или суффикса пути, а также всего пути.
Строки, не соответствующие ни одной из этих директив, игнорируются.
Ознакомьтесь со спецификацией Google для файлов robots.txt, где подробно описаны все директивы.
Как загрузить файл robots.txt
Сохраненный на компьютере файл robots.txt необходимо загрузить на сайт и сделать доступным для поисковых роботов. Специального инструмента для этого не существует, поскольку способ загрузки зависит от вашего сайта и серверной архитектуры. Обратитесь к своему хостинг-провайдеру или попробуйте самостоятельно найти его документацию (пример запроса: "загрузка файлов infomaniak").
После загрузки файла robots.txt проверьте, доступен ли он для роботов и может ли Google обработать его.
Как протестировать разметку файла robots.txt
Для этой цели Google предлагает два средства:
- Инструмент проверки файла robots.txt в Search Console. Этот инструмент можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
- Если вы разработчик, мы рекомендуем применить библиотеку с открытым исходным кодом, которая также используется в Google Поиске. С помощью этого инструмента файлы robots.txt можно локально тестировать прямо на компьютере.
Когда вы загрузите и протестируете файл robots.txt, поисковые роботы Google автоматически найдут его и начнут применять. С вашей стороны никаких действий не требуется. Если вы внесли в файл robots.txt изменения и хотите как можно скорее обновить кешированную копию, следуйте инструкциям в этой статье.
Полезные правила
Вот несколько распространенных правил для файла robots.txt:
Следует учесть, что в некоторых случаях URL веб-сайта могут индексироваться, даже если они не были просканированы.
Чтобы запретить сканирование целого каталога, поставьте косую черту после его названия.
Сканировать весь сайт может только робот googlebot-news .
Робот Unnecessarybot не может сканировать сайт, а все остальные могут.
Это правило запрещает сканирование отдельной страницы.
Например, можно запретить сканирование страницы useless_file.html .
Это правило скрывает определенное изображение от робота Google Картинок.
Например, вы можете запретить сканировать изображение dogs.jpg .
Это правило скрывает все изображения на сайте от робота Google Картинок.
Google не сможет индексировать изображения и видео, которые недоступны для сканирования.
Это правило запрещает сканировать все файлы определенного типа.
Например, вы можете запретить роботам доступ ко всем файлам .jpg .
Это правило запрещает сканировать весь сайт, но при этом он может обрабатываться роботом Mediapartners-Google
Робот Mediapartners-Google сможет получить доступ к удаленным вами из результатов поиска страницам, чтобы подобрать объявления для показа тому или иному пользователю.
Например, эта функция позволяет исключить все файлы .xls .
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
User-agent – это директива, указывающая, для какой поисковой системы и какого конкретно робота прописываются инструкции в файле robots.txt.
С данного правила начинается любой корректный Robots. Все боты при обращении к файлу проверяют записи, начинающиеся с User-Agent, где учитываются подстроки с названиями ботов поисковиков (Yandex, Google и пр.) либо “*”.
На заметку.Если строки User-agent: *, User-agent: Yandex или User-agent: Google не указаны в файле, то по умолчанию робот считает, что никаких ограничений на индексацию у него нет.
Примеры использования директивы User-agent в robots.txt
Если в файле задавать конкретного робота, то он будет следовать инструкциям, которые относятся только к нему.
Пример использования нескольких User-agent в robots.txt
Данная инструкция лишь обращается к определенному поисковому роботу или всем роботам, а уже под директивой прописываются непосредственно команды для него/них.
Для корректной настройки файла Robots не стоит допускать пустые строки между директивами User-agent и Disallow, Allow, идущими в пределах одной директивы User-agent, к которой они относятся.
Пример некорректного отображения строк в файле Robots:
Пример корректного отображения строк в файле Robots:
Как видите, директории в роботсе делятся на блоки, и в каждом из них прописываются указания для всех ботов или для определенного.
Роботы Яндекс и Google
У популярнейших поисковых систем присутствует большое количество роботов, и все они выполняют определенные функции. Благодаря robots.txt вы можете контролировать действия каждого из них. Но некоторые роботы держатся в секрете поисковыми система. Ниже перечислены все публичные роботы Яндекса и Гугла с кратким описанием.
Роботы Яндекс:
Роботы Google:
- Googlebot. Это основной робот поискового гиганта, индексирующий главный текстовый контент страниц и обеспечивающий формирование органической выдачи.
- GoogleBot (Google Smartphone). Главный индексирующий бот Гугла для смартфонов и планшетов.
- Googlebot-News. Робот, индексирующий новостные публикации сайта.
- Googlebot-Video. Включает в поисковую выдачу видеофайлы.
- Googlebot-Image. Робот, занимающийся графическим контентом веб-ресурсов.
- AdsBot-Google. Проверяет качество целевых страниц – скорость загрузки, релевантность контента, удобство навигации и так далее.
- AdsBot-Google-Mobile-Apps. Оценивает качество мобильных приложений по тому же принципу, что и предыдущий бот.
- Mediapartners-Google. Робот контекстной рекламы, включающий сайт в индекс и оценивающий его для дальнейшего размещения рекламных блоков.
- Mediapartners-Google (Google Mobile AdSense). Аналогичный предыдущему бот, только отвечает за размещение релевантной рекламы для мобильных устройств.
Зачастую в файле Robots прописывают директории сразу для всех роботов поисковиков Google и Яндекс. Но для специфических задач оптимизаторы дают указания роботам разных поисковых систем отдельно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов "Энциклопедия интернет-маркетинга", в рамках которого редакция пуб…
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
Если вы уже знакомы с основами составления robots.txt, можете сразу переходить к пункту 3 «Составление robots.txt».
- Введение
- Что такое robots.txt
- Директивы и спецсимволы robots.txt
- Настройка Google Search Consloe (GSC)
- Как составить правильный robots.txt самостоятельно
- Распространенные ошибки при составлении robots.txt
- Заключение
- Полезные ссылки
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
<Директива><двоеточие><пробел><документ, к которому применяется директива>
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс — Yandex (список роботов Яндекса, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google — Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится — «*»
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
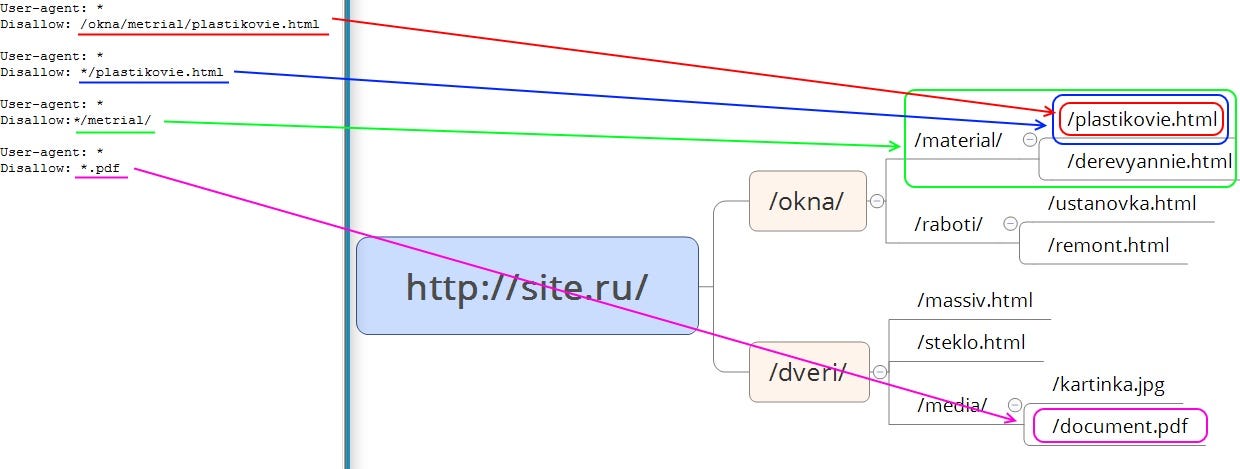
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
![]()
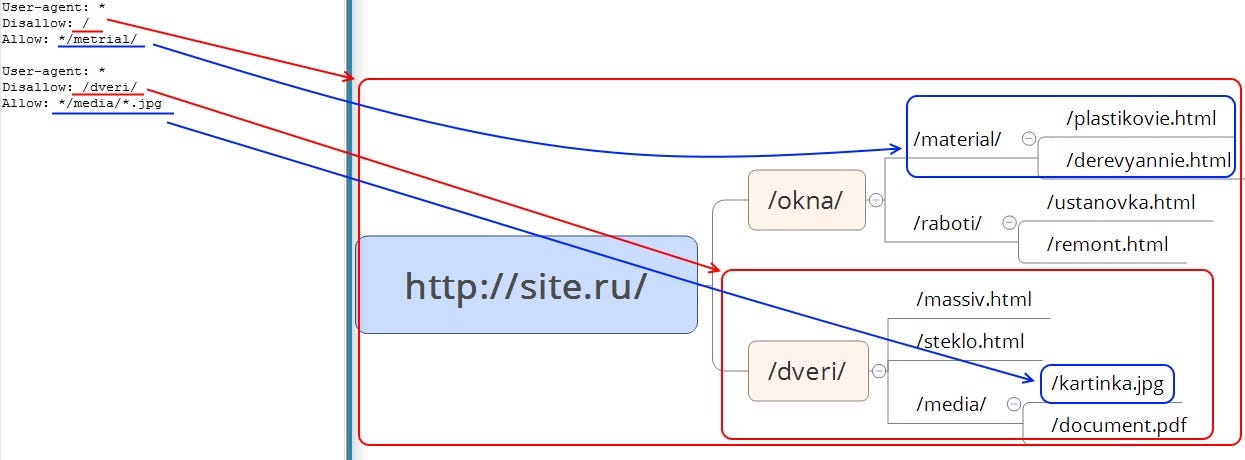
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
- Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
- Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
- Стоит обратить внимание на правила применения директив Disallow-Allow: «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
![]()
Sitemap — директива для указания пути к файлу xml-карты сайта.
- Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
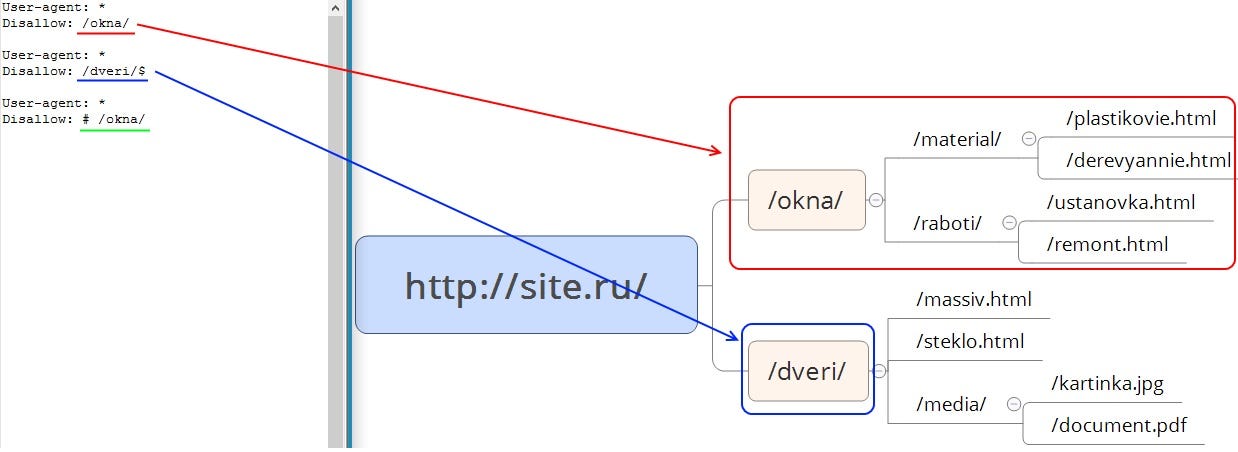
Спецсимволы
![]()
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
- Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
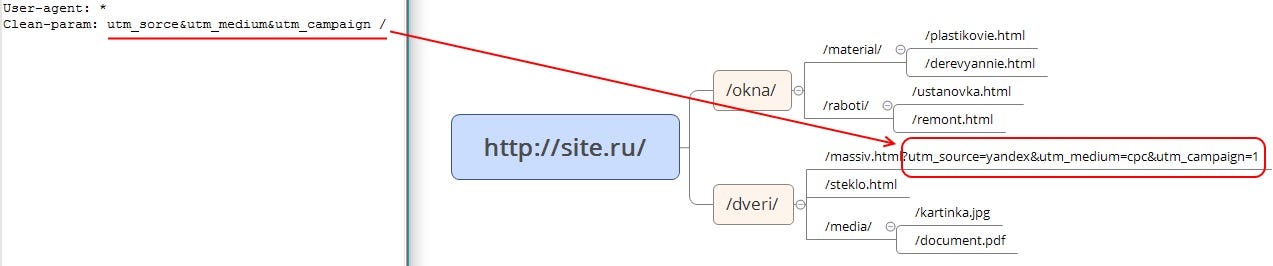
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
![]()
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
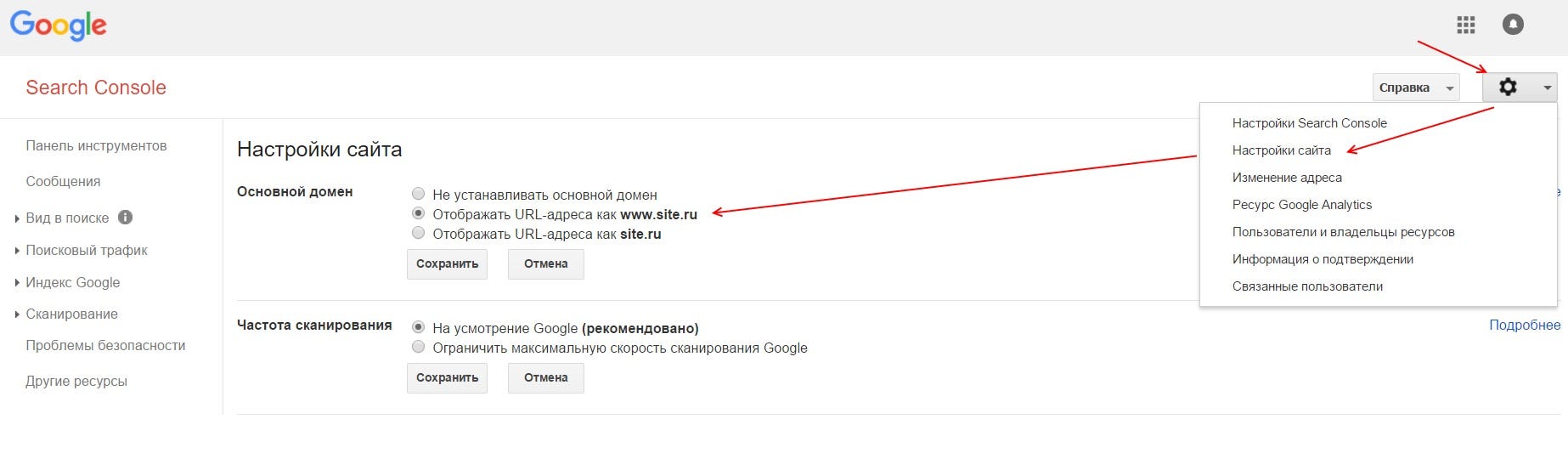
Рис. 5. Расположение определения главного зеркала в GSC![]()
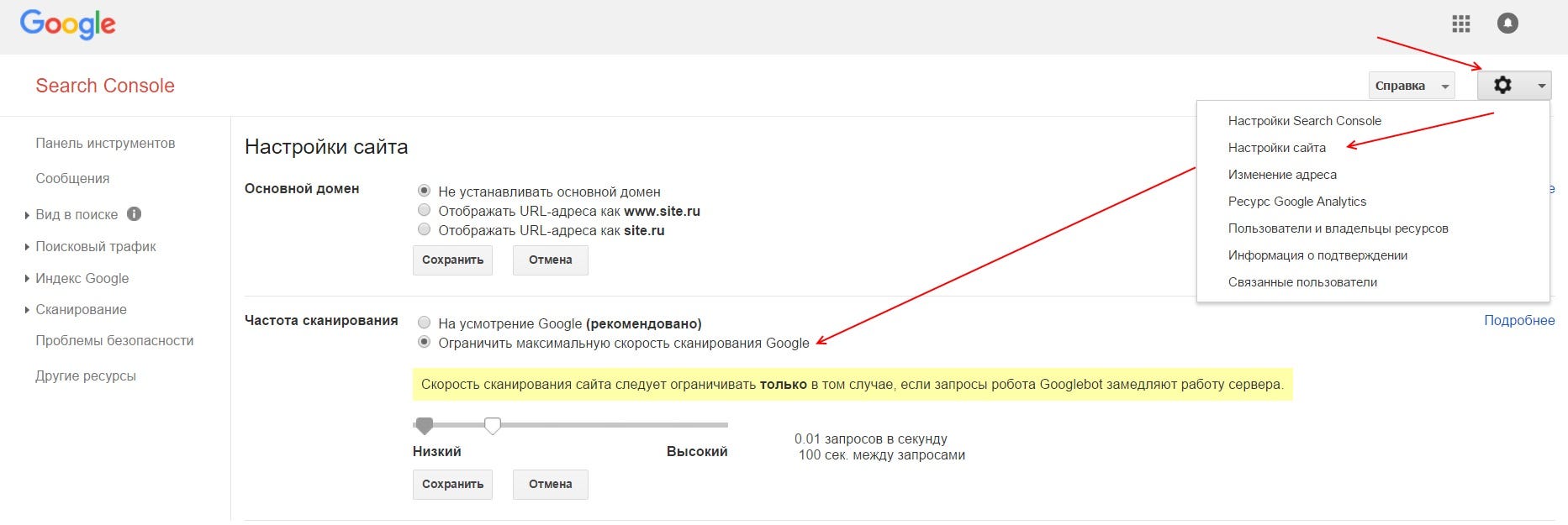
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Рис. 6. Частота сканирования сайта в Google Search Console![]()
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» — «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
- В поле «Параметр» добавляется сам параметр. Это поле является регистрозависимым.
- В поле «Изменяет ли этот параметр содержание страницы, которое видит пользователь?», вне зависимости от реального значения параметра, рекомендуем выбирать пункт «Да, параметр изменяет, реорганизует или ограничивает содержимое страницы», так как при выборе варианта «Нет, параметр не влияет на содержимое страницы (например, отслеживает использование) есть вероятность того что, одна страница с параметром все же попадет в индекс.
- Выбор в поле «Как этот параметр влияет на содержимое страницы?» влияет только на то как этот параметр будет отображаться в списке других параметров в GSC, поэтому допускается выбор любого значения.
- В блоке «Какие URL содержащие этот параметр, должен сканировать робот Googlebot?» выбор должен делаться исходя из того, что за параметр вводится. Если это метки для отслеживания, рекомендуется выбирать «Никакие URL». Если это какие-то GET параметры для продвигаемых страниц, выбирать стоит «Каждый URL».
![]()
Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
Мета-тег noindex, как наиболее эффективный способ удалить страницу из индекса .
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта /api/ и /tmp/ , несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Запрет конкретного раздела сайта
Запрет сканирования определенного файла
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Противоречия директив
Общее правило — если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов .
Может показаться, что файл /admin/js/global.js попадает под правило блокировки содержащего его раздела Disallow: /admin/ . Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
Список распространенных User-Agent
Советы по использованию операторов
Как упоминалось выше, широко применяются два оператора: * и $ . С их помощью можно:
1. Заблокировать определённые типы файлов.
В примере выше астериск * указывает на любые символы в названии файла, а оператор $ гарантирует, что расширение .json находится точно в конце адреса, и правило не затрагивает страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром ? , после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Читайте также: