
Из чего состоит индекс файла
Обновлено: 16.07.2024
При этой стратегии файловое пространство не разделяется на области, но для каждой записи добавляется 2 указателя: указатель на предыдущую запись в цепочке синонимов и указатель на следующую запись в цепочке синонимов. Отсутствие соответствующей ссылки обозначается специальным символом, например нулем. Для каждой новой записи вычисляется значение хэш-функции, и если данный адрес свободен, то запись попадает на заданное место и становится первой в цепочке синонимов. Если адрес, соответствующий полученному значению хэш-функции, занят, то по наличию ссылок определяется, является ли запись, расположенная по указанному адресу, первой в цепочке синонимов. Если да, то новая запись располагается на первом свободном месте и для нее устанавливаются соответствующие ссылки: она становится второй в цепочке синонимов, на нее ссылается первая запись, а она ссылается на следующую, если таковая есть.
Если запись, которая занимает требуемое место, не является первой записью в цепочке синонимов, значит, она занимает данное место "незаконно" и при появлении "законного владельца" должна быть "выселена", то есть перемещена на новое место. Механизм перемещения аналогичен занесению новой записи, которая уже имеет синоним, занесенный в файл. Для этой записи ищется первое свободное место и корректируются соответствующие ссылки: в записи, которая является предыдущей в цепочке синонимов для перемещаемой записи, заносится указатель на новое место перемещаемой записи, указатели же в самой перемещаемой записи остаются прежние.
После перемещения "незаконной" записи вновь вносимая запись занимает свое законное место и становится первой записью в новой цепочке синонимов.
Механизмы удаления записей во многом аналогичны механизмам удаления в стратегии с областью переполнения. Однако еще раз кратко опишем их.
Если удаляемая запись является первой записью в цепочке синонимов, то после удаления на ее место перемещается следующая (вторая) запись из цепочки синонимов и проводится соответствующая корректировка указателя третьей записи в цепочке синонимов, если таковая существует.
Если же удаляется запись, которая находится в середине цепочки синонимов, то производится только корректировка указателей: в предшествующей записи указатель на удаляемую запись заменяется указателем на следующую за удаляемой запись, а в записи, следующей за удаляемой, указатель на предыдущую запись заменяется на указатель на запись, предшествующую удаляемой.
Вопросы для самостоятельной работы
- Сравнить обе стратегии и определить, какая из них будет наиболее перспективной и в каких случаях.
- Разработать алгоритмы удаления записей для первой и второй стратегий. Показать, как определяются ссылки.
Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также и файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной
интерпретацией, то сумеете разобраться в сути, несмотря на некоторую путаницу в терминологии. Наверное, это отчасти связано с тем, что область баз данных является достаточно молодой областью знаний, и несмотря на то, что здесь уже выработалась определенная терминология, многие поставщики коммерческих СУБД предпочитают свой упрощенный сленг при описании собственных продуктов. Иногда это связано с тем, что в целях рекламы они не хотят ссылаться на старые, хорошо известные модели и методы организации информации в системе, а изобретают новые названия при описании своих моделей, тем самым пытаясь разрекламировать эффективность своих продуктов. Хорошее знание принципов организации данных поможет вам объективно оценивать решения, предлагаемые поставщиками современных СУБД , и не попадаться на рекламные крючки.
Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл , а основная область образует файл , для которого создается индекс . Но нам удобнее рассматривать эти две части совместно, так как именно взаимодействие этих частей и определяет использование механизма индексации для ускорения доступа к записям.
Мы предполагаем, что сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом.Эти файлы имеют еще дополнительные названия, которые напрямую связаны c методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также индексно-последовательными файлами. Смысл этих названий нам будет ясен после того, как мы более подробно рассмотрим механизмы организации данных файлов.
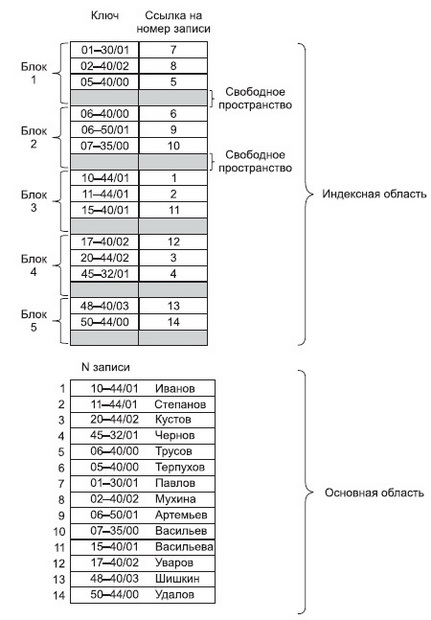
Файлы с плотным индексом, или индексно-прямые файлы
Рассмотрим файлы с плотным индексом.В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в них имеет следующий вид:
Здесь значение ключа — это значение первичного ключа, а номер записи — это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой
записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
Длина доступа к произвольной записи оценивается не в абсолютных значениях, а в количестве обращений к устройству внешней памяти , которым обычно является диск. Именно обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в оперативной памяти.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является логарифмический, или бинарный, поиск . Очень хорошо изложил этот алгоритм барон Мюнхгаузен, когда он объяснял, как поймать льва в пустыне. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то определяется сначала, не является ли элемент искомым, а если нет, то в какой половине его надо искать. Следующим шагом мы определенную половину также делим пополам и производим аналогичные сравнения, и т. д., пока не обнаружим искомый элемент. Максимальное количество шагов поиска определяется двоичным логарифмом от общего числа элементов в искомом пространстве поиска:
где N — число элементов.
Однако в нашем случае является существенным только число обращений к диску при поиске записи по заданному значению первичного ключа. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а потом путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи.
На диске записи файлов хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и операционной системой. В одном блоке могут размещаться несколько записей. Поэтому нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от заданного числа блоков плюс единица. Зачем нужна единица? После поиска номера записи в индексной области мы должны еще обратиться к основной области файла. Поэтому формула для вычисления максимального времени доступа в количестве обращений к диску выглядит следующим образом:
Давайте рассмотрим конкретный пример и сравним время доступа при последовательном просмотре и при организации плотного индекса.
Допустим, что мы имеем следующие исходные данные:
Длина записи файла ( LZ ) — 128 байт. Длина первичного ключа ( LK ) — 12 байт. Количество записей в файле ( KZ ) — 100000. Размер блока ( LB ) — 1024 байт.
Рассчитаем размер индексной записи. Для представления целого числа в пределах 100000 нам потребуется 3 байта, можем считать, что у нас допустима только четная адресация, поэтому нам надо отвести 4 байта для хранения номера записи, тогда длина индексной записи будет равна сумме размера ключа и ссылки на номер записи, то есть:
LI = LK + 4 = I2 + 4 = 16 байт .
Определим количество индексных блоков, которое требуется для обеспечения ссылок на заданное количество записей. Для этого сначала определим, сколько индексных записей может храниться в одном блоке:
KIZB = LB/LI = 1024/16 = 64 индексных записи в одном блоке .
Теперь определим необходимое количество индексных блоков:
KIB = KZ/KZIB = 100000/64 = 1563 блока .
Мы округлили в большую сторону, потому что пространство выделяется целыми блоками, и последний блок у нас будет заполнен не полностью.
А теперь мы уже можем вычислить максимальное количество обращений к диску при поиске произвольной записи:
Tпоиска = log2KIB + 1 = log21563 + 1 = 11 + 1 = 12 обращений к диску .
Логарифм мы тоже округляем, так как считаем количество обращений, а оно должно быть целым числом.
Следовательно, для поиска произвольной записи по первичному ключу при организации плотного индекса потребуется не более 12 обращений к диску. А теперь оценим, какой выигрыш мы получаем, ведь организация индекса связана с дополнительными накладными расходами на его поддержку, поэтому такая организация может быть оправдана только в том случае, когда она действительно дает значительный выигрыш. Если бы мы не создавали индексное пространство, то при произвольном хранении записей в основной области нам бы в худшем случае было необходимо просмотреть все блоки, в которых хранится файл, временем просмотра записей внутри блока мы пренебрегаем, так как этот процесс происходит в оперативной памяти.
Количество блоков, которое необходимо для хранения всех 100 000 записей, мы определим по следующей формуле:
KBO = KZ/(LB/LZ) = 100000/(1024/128) = 12500 блоков .
И это означает, что максимальное время доступа равно 12500 обращений к диску. Да, действительно, выигрыш существенный.
Рассмотрим, как осуществляются операции добавления и удаления новых записей.
При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 9.7):
увеличить изображение
Рис. 9.7. Пример организации файла с плотным индексом
После определения блока, в который должен быть занесен индекс, этот блок копируется в оперативную память, там он модифицируется путем вставки в нужное место новой записи (благо в оперативной памяти это делается на несколько порядков быстрее, чем на диске) и, измененный, записывается обратно на диск.
Определим максимальное количество обращений к диску, которое требуется при добавлении записи, — это количество обращений, необходимое для поиска записи плюс одно обращение для занесения измененного индексного блока и плюс одно обращение для занесения записи в основную область.
T добавления = log2N + 1 + 1 + 1 .
Естественно, в процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи. Однако первый способ потребует дополнительного времени на перестройку индексной области, а второй увеличит время на доступ к произвольной записи и потребует организации дополнительных ссылок в блоках на область переполнения.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.
Индексирование в базах данных
Индекс в базе данных аналогичен предметному указателю в книге. Это — вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге с предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. При использовании индексов в базе данных искомым объектом может быть одна или несколько записей файла. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они могут существенным образом повысить ее производительность. Как и в случае с предметным указателем книги, читатель может найти определение интересующего его понятия, просмотрев всю книгу, но это потребует слишком много времени. А предметный указатель, ключевые слова в котором расположены в алфавитном порядке, позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, — индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
Первичный индекс - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе поля ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи. Индекс кластеризации - это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по неключевому полю, и на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации. Вторичный индекс - это индекс, который определен на поле файла данных, отличном от поля, по которому выполняется упорядочение.Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов. Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс содержит индексные записи только для некоторых значений ключа поиска в данном файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в данном файле. Ключ поиска для индекса может состоять из нескольких полей.
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным последовательным файлом, или индексно-последовательным файлом. Эта структура является компромиссом между файлами с полностью последовательной и полностью произвольной организацией. В таком файле записи могут обрабатываться как последовательно, так и выборочно, с произвольным доступом, осуществляемым на основу поиска по заданному значению ключа с использованием индекса. Индексированный последовательный файл имеет более универсальную структуру, которая обычно включает следующие компоненты:
- первичная область хранения;
- отдельный индекс или несколько индексов;
- область переполнения.
Обычно большая часть первичного индекса может храниться в оперативной памяти, что позволяет обрабатывать его намного быстрее. Для ускорения поиска могут применяться специальные методы доступа, например метод бинарного поиска. Основным недостатком использования первичного индекса (как и при работе с любым другим отсортированным файлом) является необходимость соблюдения последовательности сортировки при вставке и удалении записей. Эти проблемы усложняются тем, что требуется поддерживать порядок сортировки как в файле данных, так и в индексном файле. В подобном случае может использоваться метод, заключающийся в применении области переполнения и цепочки связанных указателей, аналогично методу, используемому для разрешения конфликтов в хэшированных файлах.
Вторичные индексы
Вторичный индекс также является упорядоченным файлом, аналогичным первичному индексу. Однако связанный с первичным индексом файл данных всегда отсортирован по ключу этого индекса, тогда как файл данных, связанный со вторичным индексом, не обязательно должен быть отсортирован по ключу индексации. Кроме того, ключ вторичного индекса может содержать повторяющиеся значения, что не допускается для значений ключа первичного индекса. Для работы с такими повторяющимися значениями ключа вторичного индекса обычно используются перечисленные ниже методы.
- Создание плотного вторичного индекса, который соответствует всем записям файла данных, но при этом в нем допускается наличие дубликатов.
- Создание вторичного индекса со значениями для всех уникальных значений ключа. При этом указатели блоков являются многозначными, поскольку каждое его значение соответствует одному из дубликатов ключа в файле данных.
- Создание вторичного индекса со значениями для всех уникальных значений ключа. Но при этом указатели блоков указывают не на файл данных, а на сегмент, который содержит указатели на соответствующие записи файла данных.
Вторичные индексы повышают производительность обработки запросов, в которых для поиска используются атрибуты, отличные от атрибута первичного ключа. Однако такое повышение производительности запросов требует дополнительной обработки, связанной с сопровождением индексов при обновлении информации в базе данных. Эта задача решается на этапе физического проектирования базы данных.
Многоуровневые индексы
При возрастании размера индексного файла и расширении его содержимого на большое количество страниц время поиска нужного индекса также значительно возрастает. Обратившись к многоуровневому индексу, можно попробовать решить эту проблему путем сокращения диапазона поиска. Данная операция выполняется над индексом аналогично тому, как это делается в случае файлов другого типа, т.е. посредством расщепления индекса на несколько субиндексов меньшего размера и создания индекса для этих субиндексов. На каждой странице файла данных могут храниться две записи. Кроме того, в качестве иллюстрации здесь показано, что на каждой странице индекса также хранятся две индексные записи, но на практике на каждой такой странице может храниться намного больше индексных записей. Каждая индексная запись содержит значение ключа доступа и адрес страницы. Хранимое значение ключа доступа является наибольшим на адресуемой странице.
Усовершенствованные сбалансированные древовидные индексы
Дерево - это структура данных, используемая во многих СУБД для хранения данных или индексов. Дерево состоит из иерархии узлов (node), в которой каждый узел, за исключением корня (root), имеет родительский (parent) узел, а также один, несколько или ни одного дочернего (child) узла. Корень не имеет родительского узла. Узел, который не имеет дочерних узлов, называется листом (leaf). Глубина дерева - это максимальное количество уровней между корнем и листом. Глубина дерева может быть различной для разных путей доступа к листам. Сбалансированное дерево, В-дерево, В-Тгее - это дерево, у которого глубина дерева одинакова для всех листов. Степень (degree), порядок (order) дерева - это максимально допустимое количество дочерних узлов для каждого родительского узла. Большие степени обычно используются для создания более широких и менее глубоких деревьев.Поскольку время доступа в древовидной структуре зависит от глубины, а не от ширины, обычно принято использовать более "разветвленные" и менее глубокие деревья.
Бинарное дерево, binary tree - это дерево порядка 2, в котором каждый узел имеет не больше двух дочерних узлов.Усовершенствованные сбалансированные древовидные индексы определяются по следующим правилам.
Файл: Информационные технологии в юридической деятельности.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлена: 23.07.2019
Скачиваний: 259
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
О114: в том, чтобы структурировать исходную информацию относительно самой системы и внешней по отношению к ней среде
В115: Определите третий этап процесса системного моделирования
О115: построение модели данных предметной области
В116: Что понимается под объектно-ориентированным программированием
О116: особая модель написания кода, которая помогает упорядочить работу с данными в среде программирования и в которой объектный подход играет ведущую роль
В117: Что устанавливает элемент управления BorderStyle ?
О117: тип границы
В118: Линейный алгоритм (линейная структура) – это
О118: такой алгоритм, в котором все действия выполняются последовательно друг за другом и только один раз
В119: Что такое объект в Visual Basic ?
О119: комбинация программного кода и данных, воспринимаемая как единица, которой можно каким-либо образом манипулировать
В120: Концентратор это
О120: центральное устройство, объединяющее в сеть отдельные кабельные сегменты или отдельные локальные сети
В121: Седьмой уровень модели OSI ?
В122: Пятый уровень модели OSI ?
В123: Файлообменные сети (пиринговые сети) – это
О123: специальное программное обеспечение, с помощью которого пользователи могут обмениваться друг с другом через интернет различными файлами
В124: За что отвечает сеансовый уровень?
О124: за установление и поддержку коммуникационного канала между двумя узлами
В125: Какая топология является старейшим способом передачи сигналов, имеющих начало в коммутации телефонных станций?
О125: звездообразная топология
В126: В каких сетях хорошо работает традиционная шинная топология?
О126: в небольших сетях
В127: Что может выступать в качестве коммуникационной среды?
О127: токопроводящий кабель, оптоволокно, УКВ-волны
В128: Гипертекст – это
О128: множество отдельных текстов, которые имеют ссылки друг на друга
В129: Шестой уровень модели OSI ?
В130: Головной узел – это
О130: синхронный коммуникационный канал
В131: Что является задачей канального уровня в локальной сети?
О131: компоновать передаваемые биты данных в виде фреймов или кадров
В132: Топология – это:
О132: физическая конфигурация сети в совокупности с ее логическими характеристиками
В133: Магистраль – это
О133: быстродействующая среда передачи информации, соединяющая сети и центральные сетевые устройства в масштабах этажа всего здания или нескольких удаленных площадок
В134: Что такое подсхема?
О134: описание части БД, соответствующее нуждам отдельного пользователя
В135: Для чего используется язык манипулирования данными?
О135: для выполнения операций с БД(выборка, удаление записи)
В136: Из чего состоит индекс файла?
О136: из списка элементов, каждый из которых содержит значение для идентификации свойств записи (или значения поля ключа), за которым следует указание о местоположении данной записи
В137: Что является целью любой информационной системы?
О137: обработка данных об объектах реального мира
В138: Что является общим требованием (свойством) всех моделей?
О138: подобие их реальному объекту или системе-оригиналу и возможность использования их для получения информации о системе-оригинале
В139: Что лежит в основе четвертого этапа процесса системного моделирования?
О139: преобразование ИЛМ данных в имитационную или программную модель системы , которая непосредственно реализует ее в форме, специально предназначенной для исследования с использованием вычислительной техники
В140: С чем связан процесс функционирования системы?
О140: с изменением свойств системы или отдельных ее элементов во времени
В141: Как может быть представлен процесс системного моделирования?
О141: в форме взаимосвязанных этапов, на каждом из которых выполняются определенные действия, направленные на построение и дальнейшее использование ИЛМ системы
В142: Что означает реализация пятого этапа в рамках системного моделирования?
О142: выполнение серии экспериментов с программной моделью системы на той или иной вычислительной платформе
В143: Как называют совокупность признаков или условий изменения состояний системы?
В144: Главное назначение первого этапа процесса системного моделирования – это
О144: логическое осмысление решаемой проблемы в рамках системного моделирования
В145: Как должна быть зафиксирована вся доступная информация о решении проблемы на втором этапе процесса системного моделирования?
О145: в виде структурированной информации, в которой были бы выделены все параметры и факторы входных управляющих и влияющих воздействий, выходные результаты работы системы и показатели, оценивающие степень достижения системой целей функционирования
В146: Свойство – это
О146: атрибут объекта, определяющий его характеристики, такие как размер, цвет, положение на экране или состояние объекта, например, доступность или видимость
В145: Инкапсуляция – это:
О145: объединение в единое целое данных и алгоритмов обработки этих данных
В146: Что устанавливают элементы управления Left и Top ?
О146: местоположение верхнего левого угла формы
В147: Событие – это
О147: действие или ситуация, связанная с объектом
В148: Четвертый уровень модели OSI ?
В149: Какие недостатки есть у звездообразной топологии?
О149: концентраторы являются единственной точкой отказа: при выходе его из строя все подключенные узлы теряют возможность передачи данных
В150: Компьютерная сеть – это
О150: совокупность компьютеров, устройств печати, сетевых устройств и компьютерных программ, связанных между собой кабелями или радиоволнами
В151: Первый уровень модели OSI ?
В152: Что представляет собой шинная топология?
О152: кабель, последовательно соединяющий компьютеры и серверы в виде цепочки, имеющей начальную и конечную точку

В153: Чем управляет физический уровень?
О153: скоростью передачи данных, анализом потока ошибок и уровнями напряжения , используемых для передачи сигналом
В154: Пакет – это
О154: модуль данных, имеющий определенный формат, пригодный для передачи информации по сети в виде некоторого сигнала
В155: Мосты – это:
О155: сетевые устройства, которые позволяют удлинить локальную сеть или объединить несколько локальных сетей, соединяя таким образом многочисленные рабочие станции , серверы и другие сетевые устройства для взаимодействия
В156: Второй уровень модели OSI ?
О157: язык разметки гипертекста
В158: Сколько уровней включает в себя модель OSI ?
В159: Для чего применяют специальные кабельные модемы?
О159: для преобразования кабельного сигнала в сигнал, используемый компьютером
В160: а что отвечают устройства, используемые на физическом уровне?
О160: за генерирование, передачи и прием данных
В161: Третий уровень модели OSI ?
В162: Информация о параметрах объекта управления на будущий период – это
О162: плановая информация
В163: Какое свойство информации отражает прагматический аспект?
В164: Какой параметр информации означает степень близости получаемой информации к реальному состоянию объекта, процесса, явления?
В165: По стадии обработки информация бывает:
В166: Скорость передачи информации составляет 4Мбит/сек. Какая это мера оценки информации?
В167: Совокупность фактов, явлений, событий, представляющих интерес, подлежащих регистрации и обработке – это
В168: Смысловые связи между элементами языка отражает:
В169: Информацию, полученную в результате эксперимента, называют:
В170: Технология – это
О170: описание принципов и методов производства, наука о производстве материальных благ
В171: По месту возникновения информация бывает?
В172: Способ – это
О172: прием выполнения какой-либо работы
В173: Какая система кодирования ориентируется на проведение предварительной классификации объектов либо на основе иерархической системы, либо на основе фасетной системы?
В174: Что отображает синтаксическая адекватность?
О174: формальные структурные характеристики информации
В175: Коэффициент информативности рассчитывается как отношение количества информации к объему данных. Какая информация имеется ввиду?
В176: Структурной единицей экономической информации является:
В177: Инструментарий ИТ это
О177: одна или несколько программ
В178: Чем обеспечивается доступность информации восприятию пользователя?
О178: выполнением соответствующих процедур ее получения и преобразования, а также согласованием ее семантической формы с тезаурусом пользователя
В179: Принцип это
О179: основное исходное положение учения, основная особенность в устройстве чего-либо
В180: Информация, согласованная по семантической форме с тезаурусом пользователя, называется:
В181: Информационный поток характеризуется:
О181: скоростью , объемом, адресностью, полнотой, плотностью
В182: Процесс принятия решения состоит из следующих стадий:
О182: принятия решения, реализация решения, подготовка решения, получения данных, формирования альтернатив решения, выявления предпочтений, оценка решения, формирования альтернатив
В183: Логически неделимым элементом экономической информации является:
В184: Какой параметр информации отражает ее способность реагировать на изменения исходных данных без нарушения необходимой точности?
В185: Какая информация снижает эффективность принимаемых решений?
О185: как неполная, так и избыточная
В186: Технологии обработки информации, используемые как общий инструмент в различных предметных областях, называются
В187: Какое кодирование используется для иерархической классификационной структуры?
В188: Процесс, использующий совокупность средств и методов сбора, обработки и передачи данных (первичной информации) для получения информации нового качества о состоянии объекта, процесса или явления – это
О188: информационная технология
В189: Какой подход получил наибольшее признание для измерения смыслового содержания информации?
В190: Понятие полноты информации связано с ее:
В191: На каких процессорах может работать ОС Windows NT ?
О191: на процессорах Intel , Alpha , Power PC
В192: С помощью какого инструмента в Exel можно определить оптимальное для каких-либо условий решение?
О192: поиск решения, подбор параметра, анализ данных
В193: Что такое индексация
О193: обработка скаченных страниц
В194: Современное понимание экономической ИС предполагает наличие в ней таких элементов, как:
О194: программы, компьютеры, люди, оборудование
В195: К процессу обработки информации и данных относятся процедуры:
О195: отображение, преобразование
В196: Модель накопления данных рассматривается на следующих уровнях:
О196: физическом, логическом, концептуальном
В197: Когда обращаются к имитационному моделированию?
О197: тогда, когда изучаемая экономическая система настолько сложна, что не может быть сведена ни к аналитической, ни к чиленной оптимизационной модели
В198: Продукт «Регрессия» находится в:
В199: Что подразумевает простой поиск?
О199: в поле запроса вводится одно или несколько слов, которые могут характеризовать содержание документа
В200: К процессу накопления данных относятся процедуры:
О200: хранение, актуализация
В201: Какой метод контроля предполагает сопоставления фактических данных с нормативными, проверку непротиворечивости показателей?
В202: Сколько методов нелинейной оптимизации используются в «Поиске решения»?
В203: На каком уровне управления функция учета практически отсутствует?
В204: Что такое структурирование?
О204: процесс подготовки пачки однотипных документов путем объединения файла
О205: встроенный язык программирования
В206: За что отвечают устройства, используемые на физическом уровне?
О206: за генерирование, передачи и прием данных
В207: Основным элементом преобразования информации в системах управления является
О207: принятие решения
В208: К процессу обмена данными относятся процедуры:
О208: передача, организация сети
В209: Какое количество переменных можно использовать для расчета по одной формуле в таблице подстановки?
В210: Какой язык поддерживается в современных СУБД?
О210: единый интегрированный язык, обеспечивающий необходимыми средствами работу с БД, начиная от ее создания и кончая созданием необходимого интерфейса пользователя
В211: Производственная подсистема информационной системы включает следующие задачи:
О211: анализа работы оборудования, разработки календарных планов, управления запасами, планирования объемов работ, управления портфелем заказов
В212: В процессе декомпозиции элементов в ИС выделяют следующие части:
О212: базовую, функциональную
В213: В каком случае используется регрессионный анализ?
О213: когда должна быть определена связь между различными явлениями, процессами в одиночной экономической операции
В214: Какие типы задач можно решать с помощью «Поиска решения»?
О214: линейной и нелинейной оптимизации
В215: В какое обеспечение входят анализ существующей системы управления, где будет использоваться ИС, и выявление задач, подлежащих автоматизации?
В216: На каком уровне управления организационно-экономическим объектом разрабатываются цели управления, внешняя политика, материальные, финансовые и трудовые ресурсы, а также долгосрочные планы?
В217: В хозяйственной практике производственных и коммерческих объектов типовыми видами деятельности, определяющими функциональный признак классификации ИС, являются:
О217: финансовая, кадровая, производственная, маркетинговая
В219: ИС в экономике, в отличие от других ИС, характеризуются таким элементом, как:
В220: Доступ к сети – это:
О220: взаимодействие узлов сети со средой передачи данных для обмена информацией с другими узлами
В221: Для чего обычно используется элемент управления «Флажок»?
О221: для предоставления пользователю выбора»Да/Нет»
В222: Что является целью заключительного этапа процесса системного моделирования?
О222: внесение изменений в существующую модель, направленные на обеспечение ее адекватности решаемой проблемы
Хотя технология хеширования и может дать высокую эффективность, но для её реализации не всегда удается найти соответствующую функцию, поэтому при организации доступа к данным широко используются индексные файлы.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 7). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.

Рис. 7. Индексированный и индексный файлы
Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Обычно индекс определяется для одного отношения, и ключом является значение простого или составного атрибута.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных- Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс (а это дополнительное время) в индексный файл. Поэтому при выборе поля индексирования всегда важно уточнить, который из двух показателей важнее: скорость выборки или скорость обновления.
осуществлять последовательный доступ к индексированному файлу в соответствии со значениями индексного поля для составления запросов на поиск наборов записей;
осуществлять прямой доступ к отдельным записям индексированного файла на основе заданного значения индексного поля для составления запросов для заданных значений индекса;
организовать запросы, не требующие обращения к индексированному файлу, а лишь приводящие к проверке наличия данного значения в индексном файле.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
В зависимости от организации индексной и основной областей различают два типа файлов: индексно-прямые файлы и индексно-последовательные файлы. При рассмотрении определенной технологии будем, прежде всего обращать внимание на ее достоинства и слабые места, а также на поддерживаемые ею способы поиска информации, вставки и удаления записи.

Файловая система . На каждом носителе информации (гибком, жестком или лазерном диске) может храниться большое количество файлов. Порядок хранения файлов на диске определяется используемой файловой системой.
Каждый диск разбивается на две области: обла сть хранения файлов и каталог. Каталог содержит имя файла и указание на начало его размещения на диске. Если провести аналогию диска с книгой, то область хранения файлов соответствует ее содержанию, а каталог - оглавлению. Причем книга состоит из страниц, а диск - из секторов.
Для дисков с небольшим количеством файлов (до нескольких десятков) может использоваться одноуровневая файловая система , когда каталог (оглавление диска) представляет собой линейную последовательность имен файлов (табл. 1.2). Такой каталог можно сравнить с оглавлением детской книжки, которое содержит только названия отдельных рассказов.
Если на диске хранятся сотни и тысячи файлов, то для удобства поиска используется многоуровневая иерархическая файловая система , которая имеет древовидную структуру. Такую иерархическую систему можно сравнить, например, с оглавлением данного учебника, которое представляет собой иерархическую систему разделов, глав, параграфов и пунктов.
Начальный, корневой каталог содержит вложенные каталоги 1-го уровня, в свою очередь, каждый из последних может содержать вложенные каталоги 2-го уровня и так далее. Необходимо отметить, что в каталогах всех уровней могут храниться и файлы.
Например, в корневом каталоге могут находиться два вложенных каталога 1-го уровня (Каталог_1, Каталог_2) и один файл (Файл_1). В свою очередь, в каталоге 1-го уровня (Каталог_1) находятся два вложенных каталога второго уровня (Каталог_1.1 и Каталог_1.2) и один файл (Файл_1.1) - рис. 1.3.
Файловая система - это система хранения файлов и организации каталогов.
Рассмотрим иерархическую файловую систему на конкретном примере. Каждый диск имеет логическое имя (А:, В: - гибкие диски, С:, D:, Е: и так далее - жесткие и лазерные диски).
Пусть в корневом каталоге диска С: имеются два каталога 1-го уровня (GAMES, TEXT), а в каталоге GAMES один каталог 2-го уровня (CHESS). При этом в каталоге TEXT имеется файл proba.txt, а в каталоге CHESS - файл chess.exe (рис. 1.4).
| Рис. 1.4. Пример иерархической файловой системы |
Путь к файлу . Как найти имеющиеся файлы (chess.exe, proba.txt) в данной иерархической файловой системе? Для этого необходимо указать путь к файлу. В путь к файлу входят записываемые через разделитель "\" логическое имя диска и последовательность имен вложенных друг в друга каталогов, в последнем из которых содержится нужный файл. Пути к вышеперечисленным файлам можно записать следующим образом:
Путь к файлу вместе с именем файла называют иногда полным именем файла.
Пример полного имени файла:
Представление файловой системы с помощью графического интерфейса . Иерархическая файловая система MS-DOS, содержащая каталоги и файлы, представлена в операционной системе Windows с помощью графического интерфейса в форме иерархической системы папок и документов. Папка в Windows является аналогом каталога MS-DOS
Однако иерархическая структура этих систем несколько различается. В иерархической файловой системе MS-DOS вершиной иерархии объектов является корневой каталог диска, который можно сравнить со стволом дерева, на котором растут ветки (подкаталоги), а на ветках располагаются листья (файлы).
В Windows на вершине иерархии папок находится папка Рабочий стол. Следующий уровень представлен папками Мой компьютер, Корзина и Сетевое окружение (если компьютер подключен к локальной сети) - рис. 1.5.
| Рис. 1.5. Иерархическая структура папок |
Если мы хотим ознакомиться с ресурсами компьютера, необходимо открыть папку Мой компьютер.
1. В окне Мой компьютер находятся значки имеющихся в компьютере дисков. Активизация (щелчок) значка любого диска выводит в левой части окна информацию о его емкости, занятой и свободной частях.
Читайте также: