
Как oracle хранит данные
Обновлено: 06.07.2024
Среди самых важных характеристик любой базы данных следует назвать производительность, надежность и простоту администрирования. Знание того, как большинство СУБД физически хранят данные во внешней памяти, представление о параметрах этого хранения и соответствующих методах доступа может очень помочь при проектировании баз данных, обладающих заданной производительностью.
Хранение данных во внешней памяти в известных СУБД (Oracle, IBM DB2, Microsoft SQL Server, CA-OpenIngres, решения от Sybase и Informix и др.) организовано очень похожим образом.
Организация хранения
Основными единицами физического хранения являются блок данных, экстент, файл (либо раздел жесткого диска). Логический уровень представления информации включает пространства (либо табличные пространства). Блок данных (block) или страница (page) является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных (Oracle) или для ее различных структур (DB2, Informix, Sybase) и устанавливается при создании. Очень важно сразу правильно выбрать размер блока: в работающей базе изменить его практически невозможно (для этого часто проводят ряд испытаний базы данных-прототипа).
Администратор отводит пространство для базы данных на внешних устройствах большими фрагментами: файлами и разделами диска. В первом случае доступ к диску осуществляется операционной системой, что дает определенные преимущества, например, работа с файлами средствами ОС. Во втором случае с внешним устройством работает сам сервер. При этом достигается более высокая производительность; кроме того, использование дисков необходимо в случае, если кэш ОС не может работать в режиме сквозной (write-through) записи. Диски особенно эффективны для ускорения операций записи данных (подобный механизм поддерживается Oracle, DB2 и Informix; например, в DB2 данная единица размещения называется контейнером).
Пространством внешней памяти, отведенным ему администратором, сервер управляет с помощью экстентов (extent), т.е. непрерывных последовательностей блоков. Информация о наличии экстентов для объекта схемы данных находится в специальных управляющих структурах, реализация которых зависит от СУБД. На управление экстентами (выделение пространства, освобождение, слияние) тратятся определенные ресурсы, поэтому для достижения эффективности нужно правильно определять их параметры. СУБД от Oracle, IBM, Informix позволяют определять параметры этих структур, а в Sybase экстенты имеет постоянный размер, равный 8 страницам. Уменьшение размера экстента будет способствовать более эффективному использованию памяти, однако при этом возрастают накладные расходы на управление большим количеством экстентов, что может замедлить операции вставки большого количества строк в таблицу. Кроме того, сервер может иметь ограничение на максимальное количество экстентов для таблицы. При слишком большом размере экстентов могут возникнуть проблемы с выделением для них необходимого количества памяти. Обычно определяется размер начального экстента, размер второго и правило определения размеров следующих экстентов. На рис. 2 иллюстрируется взаимосвязь блоков, экстентов и файлов баз данных.
В Informix существует еще одна единица физического хранения, промежуточная между файлом (или разделом диска) и экстентом, — это «чанк» (от английского chunk, что дословно переводится как «емкость»). Чанк позволяет более гибко управлять очень большими массивами внешней памяти. В одном разделе диска или файле администратор может создать несколько чанков. Чанк также служит единицей зеркалирования.
Общим для СУБД Oracle, DB2 и Informix является понятие пространства (для Oracle и DB2 это табличное пространство). Различные логические структуры данных, такие как таблицы и индексы, временные таблицы и словарь данных размещены в табличных пространствах. В DB2 и Informix дополнительно можно устанавливать размер страницы отдельно для каждой из этих структур. Группировка хранимых данных по пространствам производится по ряду признаков: частота изменения данных, характер работы с данными (преимущественно чтение или запись и т.п.), скорость роста объема данных, важность и т.п. Таким образом, например, только читаемые таблицы помещаются в одно пространство, для которого установлены одни параметры хранения, таблицы транзакций размещаются в пространстве с другими параметрами и т.д. (рис. 3).
Одна логическая единица данных (таблица или индекс) размещается точно в одном пространстве, которое может быть отображено на несколько физических устройств или файлов. При этом физически разнесены (располагаться на разных дисках) могут не только логические единицы данных (таблицы отдельно от индексов), но и данные одной логической структуры (таблица на нескольких дисках). Такой способ хранения называется горизонтальной фрагментацией: таблица делится на фрагменты по строкам. В Oracle вместо термина «фрагментация» используется «секционирование» (partitioning). Фрагментация — один из способов повышения производительности.
Могут применяться различные схемы записи данных во фрагментированные таблицы. Одна из них — круговая (round-robin), когда некоторая часть вставляемых в таблицу строк записывается в первый фрагмент, другая часть — в следующий и так далее по кругу. В данном случае за счет распараллеливания может быть увеличена производительность операций модификации данных и запросов. Существует и другая схема, включающая логическое разделение строк таблицы по ключу («кластеризация»). Данная схема позволяет избежать перерасхода процессорного времени и уменьшить общий объем операций ввода/вывода. Ее суть в том, что при создании таблицы все пространство значений ключа таблицы разбивается на несколько интервалов, а строкам с ключами, принадлежащими разным интервалам, назначаются различные месторасположения. Впоследствии, при обработке запроса, данная информация учитывается оптимизатором. Если производится поиск по ключу, то оптимизатор может удалять из рассмотрения фрагменты таблицы, не удовлетворяющие условию выборки. Например, создание кластеризованной таблицы будет выглядеть следующим образом (этот и все остальные SQL-скрипты приведены для Oracle):
Здесь создаются два раздела part1 и part2, каждый из которых размещен в своем табличном пространстве (tblspace1 и tblspace2). Записи со значением поля num от 1 до 499 будут располагаться в первом разделе, а записи с номерами от 500 до 1000 — во втором (рис. 4).
Тогда при запросе:
оптимизатор будет производить поиск только в разделе part1, что может дать ощутимый выигрыш в производительности в таблице с десятками тысяч строк.
Подобные механизмы фрагментации данных поддерживают практически все современные СУБД, что часто используется при создании систем высокой производительности.
Методы доступа
Современные СУБД предоставляют достаточно широкий набор различных методов доступа, которые чаще всего являются теми или иными видами индексирования — способа отображения ключа индексирования в адрес хранимой записи. Используются следующие типы индексных структур: на основе B-дерева (B-tree); на основе хэш-функции или хеширование (hashing); на базе битовых шкал или индексов (bitmap). Индекс может служить различным целям: для ускорения доступа к записям одной таблицы и для ускорения операций соединения, тогда он называется индексом соединения. Если в качестве ключа индексирования используется некоторая функция атрибутов таблицы, такой индекс называют «основанным на функции» (function-based). Скажем, можно создать такой индекс для ускорения поиска с учетом регистра символов для таблицы Famous (таблица 1):
Отличают также «кластеризованный» (clustered) индекс. При его использовании все записи таблицы упорядочиваются по его ключу; поэтому кластеризованный индекс более экономно расходует память и обычно быстрее опрашивается. Для таблицы, таким образом, можно создать лишь один такой индекс.
B-деревья универсальны и обеспечивают хорошую скорость доступа как при просмотрах по диапазонам, так и при выборке единичной записи по значению ключа, однако характеризуются относительно большим объемом памяти для хранения и затратами на поддержание в актуальном состоянии, включающими обычно балансировку дерева. Такой индекс имеет один существенный недостаток — он может быть использован только в запросах по ведущим столбцам. Например, если в таблице Famous создан составной индекс по столбцам fullname, birth и sex:
смогут использовать этот индекс, а в следующих запросах:
оптимизатор не сможет им воспользоваться, что связано с архитектурными особенностями данного типа индексирования. В данном примере индекс может быть использован при запросах по fullname, birth, sex либо fullname, birth либо только fullname. Несмотря на этот недостаток, индексы B-деревьев наиболее распространены и используются во всех рассматриваемых СУБД. Для B-дерева можно задать «степень использования страницы индекса» (fillfactor); так, в Oracle используются параметры PCTUSED и PCTFREE для блоков базы данных в том числе и индексных. При создании индекса его страницы заполняются только на указанный процент (рис. 5). При увеличении процента использования страницы увеличится скорость операций изменения индекса, однако возрастут также расходы на хранение и может увеличиться время выполнения запросов.
Каждая СУБД может иметь ряд дополнительных параметров, предоставляющих разработчику расширенные возможности конфигурирования В-деревьев.
Хэш-индекс имеет небольшие накладные расходы на хранение, однако требует, чтобы распределение значений ключа индексирования было относительно постоянно, в противном случае потребуется частая переделка индекса на основе новой хэш-функции. Индексы на основе хэш-функций хорошо подходят для различного рода справочных таблиц. При этом не требуется, чтобы индексируемый столбец имел много повторяющихся значений, как того требуют битовые индексы.
Битовые индексы также очень компактны и полезны для столбцов с большим процентом повторения значений ключа. Обычно используют следующее правило: если количество повторяющихся значений столбца более 99% от общего количества строк таблицы, тогда целесообразно рассмотреть использование битового индекса. Так, таблица Famous могла бы выиграть от использования двух битовых индексов — по столбцам SEX и MARRIED.
Битовые индексы обладают очень важным свойством: если производится запрос, включающий сложное условие выборки, которое составлено из предикатов OR, AND, NOT и «=», то оптимизатор может использовать имеющиеся по конкретным столбцам битовые индексы, объединяя их. B-деревья этого делать не позволяют (для этого потребовалось бы построить составной индекс по этим столбцам, специально для ускорения данного запроса). В рассматриваемом примере запрос вида:
может использовать оба битовых индекса emp_ind_02 и emp_ind_03. Однако тот же запрос не сможет использовать два отдельных индекса по этим же столбцам. Битовые карты полезны в хранилищах, где преобладают длинные транзакции и данные читаются чаще чем записываются, однако они неэффективны в приложениях с короткими транзакциями, характерными для OLTP-систем.
В DB2 используется оптимизированный вариант B-дерева с двунаправленными указателями и «упреждающей регистрацией обновлений» (write-ahead logging), что позволяет ускорить вставку данных. При создании индекса можно также использовать некоторые опции, например, указать серверу о необходимости хранить в структуре индекса дополнительные часто запрашиваемые значения атрибутов.
В СУБД Oracle помимо многочисленных индексов используются «индексно-упорядоченные» (index-organized) таблицы и кластеры. В первом случае вся таблица индексирована по первичному ключу и организована в виде B-дерева.
Подобный метод организации хранения хорошо подходит для часто опрашиваемых больших (более 5 тыс. строк) и очень больших таблиц с небольшим объемом операций, для которых критично время выполнения запроса на точное совпадение по первичному ключу, например:
Экономия времени при выполнении таких запросов может составлять от 15 до 400% в зависимости от длины строки [1].
Кластер Oracle — это структура для хранения одной или нескольких таблиц, главным образом служащая для ускорения операций их соединения, в которой строки таблиц, удовлетворяющие условию соединения, хранятся вместе. Столбцы, используемые для соединения, называются кластерным ключом. Значения кластерного ключа сохраняются один раз (дубликаты исключаются). Для доступа по кластерному ключу могут использоваться как B-деревья, так и хэш-структуры, в этом случае кластер является хэш-кластером. Стоит также упомянуть битовый индекс соединения (bitmap join), ускоряющий операции объединения таблиц. В Sybase используются B-деревья, а индекс может быть как кластеризованным так и обычным. В Informix можно применять кластеризованные, битовые и индексы, основанные на функции.
Проблемы управления внешней памятью
Распространенной проблемой для администраторов при управлении физическим хранением является фрагментация различных структур внешней памяти, которая чаще обусловлена операциями удаления. В отличие от преднамеренной фрагментации, такая «фрагментация» обычно ухудшает производительность. Встречается фрагментация на уровне блоков, когда в блоке остается свободное пространство после удаления строк из таблицы, на уровне экстентов, когда заполненные экстенты чередуются с незаполненными, появившимися после операций удаления таблиц, и т.п. Укажем лишь часть из проблем, которые могут быть обусловлены фрагментацией.
Фрагментация неизбежна и поэтому является нормальным явлением, и не всегда ухудшает характеристики базы данных. Индексы также подвержены проблемам фрагментации пространства, и могут стать несбалансированными, поэтому SQL-оператор ALTER INDEX обычно имеет опцию REBUILD, позволяющую перестроить индекс. Индекс также можно удалить и создать заново даже в работающей базе данных.
Заключение
Эффективность использования любых методов доступа зависит от распределения данных в запрашиваемых таблицах, от стратегии работы оптимизатора СУБД и от возможностей диалекта SQL. Поэтому приведенные рекомендации носят достаточно общий характер — все определяется конкретной ситуацией. Решения, принимаемые на этапах физического проектирования и настройки, чаще всего представляют собой компромисс между достижением требуемых характеристик, которые часто противоречат друг другу. За выигрыш в скорости обработки запросов, которую дает индекс, приходится платить дополнительными ресурсами памяти на его размещение и процессорным временем для его поддержки в актуальном состоянии. К сожалению, трудно привести конкретные оценки: многое зависит от конфигурации сервера, настройки ОС и СУБД и т.п.
Рассмотренный перечень методов доступа не является полным. Описаны лишь распространенные технологии, которые можно назвать традиционными. Например, за кадром остались возможности современных СУБД, связанные с реализацией расширяемой системы типов данных. Сюда относят технологии расширителей (Extender) IBM, DataBlade (Informix) и картриджей (Oracle). Тем не менее, перечисленный арсенал средств достаточно богат сам по себе. Адекватное представление об этих средствах позволяет сделать проектируемые базы данных и их приложения менее зависимыми от конкретной СУБД.
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
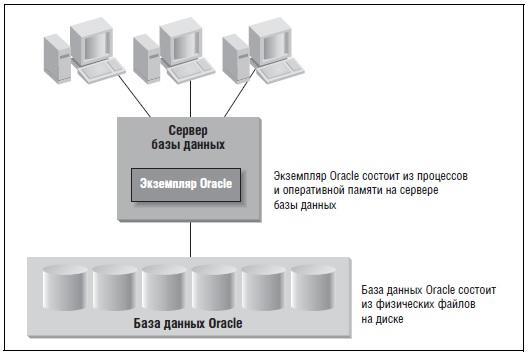
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
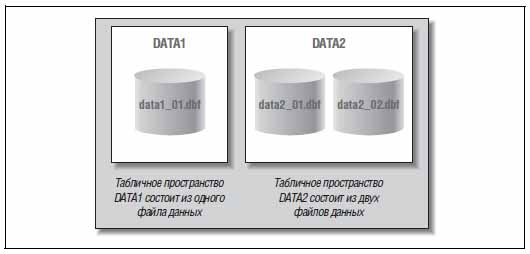
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
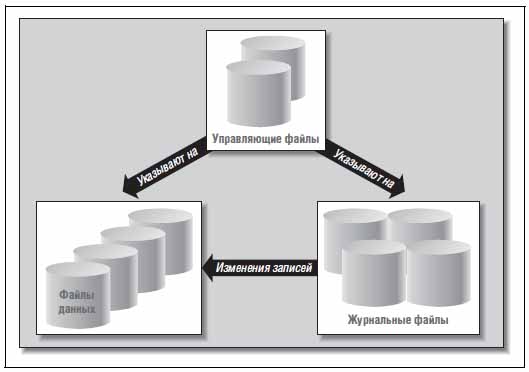
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Когда вы меняете данные в БД, то ваши изменения сначала идут в кэш, а потом асинхронно в нескольких потоках (число можно сконфигурировать) пишутся на диск. Синхронно же пишется специальных лог (оперативный журнальный файл), чтобы была возможность восстановить данные после сбоя, если они еще не успели с кэша сброситься на диск. Данный подход позволяет выиграть в скорости, так как в этом случае на диск все пишется последовательно в один файл, причем можно настроить так, чтобы писалось параллельно на два или больше дисков, тем самым увеличивая надежность защиты от потери изменений. Описанных файлов должно быть несколько, и они используются по кругу: как только все данные защищенные одним из лог файлов были записаны фоновым процессом в блоки данных на диск, то данный лог файл может быть переиспользован. Таким образом в какой-то мере это позволяет еще и сэкономить, имея ультрабыстрые диски небольшого размера только для небольших журнальных файлов используемых по кругу.
Обычно я рассказываю об этом, когда мне предлагают что-то сохранять просто в файл на диске, так как это будет «быстрее» за счет того, что мы будет писать все данные последовательно и головке жесткого диска не надо будет бегать и искать рэндомные блоки. Я все же настаиваю, что мы тут ничего не выиграем, так как будем писать на медленный диск, который скоро всего активно используется множеством других процессов для записи огромного количества различных логов, а Oracle синхронно тоже пишет у себя на диск только последовательно, как я описал выше.
Механизм восстановления данных
В СУБД Oracle можно включить архивацию вышеописанных оперативных журнальных файлов, и все изменения будут архивироваться. Таким образом при потере любого диска с блоками данных мы можем восстановить их на любой момент времени, включая момент прямо перед падением, накатив на последние архивные журнальные файлы текущий оперативный журнал.
Stand by копия
Вышеупомянутые архивные файлы можно отправлять по сети и на лету применять к копии БД. Таким образом у вас всегда под рукой будет горячая копия с минимальным запаздыванием данных. В некоторых приложениях, где нет необходимости показывать данные с точностью до последнего момента, можно настроить такую БД только на чтение и разгрузить основной экземпляр БД, причем таких экземпляров на чтение может быть несколько.
Подвисание некоторых запросов на запись
При зависании некоторых ваших запросов в произвольный момент времени стоит заглянуть в alert.log на предмет наличия incomplete checkpoint. Это говорит о том, что ваши оперативные журнальные файлы слишком большие или их слишком мало, таким образом, защищаемые ими данные не успевают сбрасываться из кэша на диск, а СУБД заполнила уже все доступные оперативные журнальные файлы и хочет использовать их по кругу повторно, чего делать ни в коем случае нельзя, вот и появляется пауза. Хотя если ваше приложение работает на java, то в первую очередь я бы загляну на наличия Full GC в логах.
Неблокирующее чтение и сегмент отката
Одной из наиболее замечательных особенностей СУБД Oracle является неблокирующее чтение, которое достигается за счет сегмента отката. Запросы к Oracle на чтение никогда не блокируются, так как данные почти всегда могут быть прочитаны из сегмента отката.
Сегмент отката дает еще одну плюшку: из него можно попытаться считать немного устаревшие данные для какой-нибудь таблицы, которые были в ней на определенный момент. Называется данная фича — flashback.
Однако иногда сегмент отката может подложить свинью: если у вас есть большой job для bulk удаления данных (удаление генерирует всех больше данных в сегменте отката), то вы можете получить ORA-01555: snapshot too old. Главное что в этом случае надо помнить — это то, что не надо переписывать ваш job, чтобы он коммитил через каждые N операций, а нужно использовать отдельный специально созданный сегмент отката для таких операций.
Уровни изоляции транзакций
В Oracle вообще нет уровня изоляции READ_UNCOMMITED. Дело в том, что в других базах данных он используется для достижения максимального параллелизма путем удаления блокировок чтения. Но в Oracle чтение и так всегда выполняется без блокировок, таким образом мы уже имеем все преимущества, которые может дать этот уровень, не вводя никаких дополнительных ограничений.
Вообще, в Oracle явно доступно всего два уровня изоляции: по умолчанию используется READ_COMMITTED, но при желании вы можете установить SERIALIZABLE.
Однако на уровне операторов (SELECT, UPDATE и т.д.) у вас по умолчанию уже есть REPEATABLE_READ, т.е. в рамках одного оператора вы всегда получаете согласованное чтение, что достигается конечно же за счет сегмента отката. Мне всегда очень нравился пример приводимый Томом Кайтом для описания того, что это дает. Допустим у вас есть очень большая таблица со счетами и вы выполняете SELECT на получение суммы. В Oracle, в отличие от многих других БД, даже если в середине вашего запроса другая транзакция переведет некоторую суммы с первого счета на последний, вы в итоге все равно получите данные актуальные на начало вашего запроса, так как дойдя до последний строчки ваш SELECT увидит, что строчка была изменена, пойдет в сегмент отката и прочитает данные, которые были в этой ячейке на момент начала выполнения запроса. Во многих других базах данных, вы получите ответ в виде суммы, никогда не существующей в вашей таблице. Однако в Oracle в данном случае есть опасность получить ORA-01555: snapshot too old.
В дополнение к стандартным уровням изоляции в Oracle еще есть так называемые READ_ONLY транзакции, которые дают REPEATABLE_READ в рамках всей транзакции, а не только в рамках одного оператора. Но как следует из названия, в такой транзакции вы можете выполнять только чтение.
Позвольте Oracle кэшировать ваши данные эффективно
В Oracle все данные читаются-пишутся не прямо на диск, а через кэш. По умолчанию кэш основан на LRU алгоритме, так что если вы читаете какую-нибудь очень большую табличку по идентификатору в больших количествах, запрашивая в каждый раз новую строчку, то такие запросы могут вытеснять из кэша небольшую статическую табличку, которой бы самое милое дело постоянно находиться в кэше. Для таких целей при создании таблицы вы можете указать специальный вид кэша, куда будут ходить запросы к вашим таблицам. Так для первой таблицы в вышеописанном примере подойдет кэш RECYCLE, который по сути не хранит никакие данные, а сразу их выбрасывает из кэша. А для второй таблицы подойдет кэш KEEP, который позволить хранить в кэше небольшие статические таблице и запросы ко всем остальным таблицам не будут вытеснять данные статических таблиц из кэша.
Пустые строки
В оракл есть одна очень интересная особенность, от которой они теперь уже никогда не смогут избавиться. Дело в том, что если вы кладете в БД пустую строку, то она сохраниться как NULL. Таким образом при последующем чтении вы никогда не получите пустой строки, а только NULL. Имейте так же в виду, что по этой же причине пустые строки не попадают в индекс, так что если вы будете делать запросы, план выполнения которых, будет использовать индекс, то ваше пустые (вернее NULL) строки вы никогда не получите, но об этом чуть позже.
Индексы
Кроме всем известных индексов в виде B-деревьев в Oracle еще есть так называемые битовые индексы, которые показывают очень высокую производительность на запросах к таблицам в которых есть колонки с очень разреженными значениями. Особенно эффективно в этом случае будут работать запросы (по сравнению с обычными индексами) в которых присутствуют сложные комбинации OR и AND к разряженным столбцам. Данный индекс храниться не в B-дереве, а в битовых картах, что и дает возможность быстрого выполнения описанных запросов. Вопрос в количестве уникальных значений в таблице при которых данный индекс еще будет более предпочтителен весьма сложен: это может быть как 10 уникальных значений, так и 10 000. Здесь надо создавать индекс на конкретной таблице и смотреть что получается. Главное не пытайтесь использовать данный индекс на таблицах с большим количеством вставок и обновлений индексируемой колонки, так как такие операции будут блокировать довольно большие участки в индексируемой таблице и ваша система может встать колом или даже поймаете deadlock.
Одна из вещей, которая меня всегда очень радовала в Oracle — это возможность создания индекса по функции. Т.е. если вам в запросах приходиться использовать какую-нибудь функцию, то вы можете построить по ней индекс и значительно ускорить операции чтения.
Еще одно интересное свойство индексов, о котором необходимо знать, это то, что в индексе не хранятся значения NULL. Таким образом если вы будете делать запросы с условием <, > или <> по индексируемой колонке, то в ответ строчек со значением NULL в индексируемой колонке вы обратно не получите. С другой стороны данное свойство можно очень эффективно использовать дня некоторых специфичных случаев. Например, у вас есть очень большая табличка в которой хранятся ордера, которая никогда не чистится. И существует фоновый процесс, который обязан все ордера отсылать в какую-нибудь backoffice систему. Первое решение, которое напрашивается — это завести еще одну колонку с флагом is_sent, где изначально стоит 0 и при отсылке мы будем проставлять 1. Т.е. фоновый процесс при каждом запуске будет делать запрос к таблице с условием is_sent=0. Битовый индекс вы здесь использовать не можете, так как табличка очень активно пополняется. Обычный индекс на основе В-дерева будет занимать очень много места, так как нужно хранить ссылки на огромное количество строчек. Но если мы слегка поменяем нашу логику и в качестве пометки отсылки, и в колонку is_sent будем класть NULL вместо 1, то индекс у нас будет крошечный, так как в любой момент в нем будут храниться только не NULL значения, а их будет очень мало.
Таблицы бывают разные
Кроме обычных таблиц в oracle как и во многих других БД есть так называемые индекс-таблицы, когда данные таблицы непосредственно лежат в индекс-дереве первичного ключа. Таким образом достигается сразу две вещи: во первых для чтения данных по первичному ключу вы имеете на одно чтение меньше, во вторых данные в таблице получаются упорядоченными по первичному ключу, так что операция ORDER BY PK будет выполняться без дополнительной сортировки. К недостаткам можно отнести тот факт, что отличить логирование в оперативные журнальные файлы данного индекса вы уже не сможете.
Еще один замечательный тип таблиц — это кластерные таблицы, которые позволяют хранить данные из двух или более таблиц кластеризованные по одному значению ключа в одном блоке данных. Это может быть весьма эффективно если вы всегда используете какие-нибудь таблицы совместно.
На основе кластерных таблиц есть еще кластерные хэш-таблицы, в которых для доступа вместо B-дерева используется таблица на основе хеша кластерного ключа. Звучит, конечно, очень интересно, но, честно говоря, на практике никогда не сталкивался.
Связывание переменных
Наверное об этом уже наслышан каждый программист, но я все же упомяну о такой обязательной техники, как связывание переменных. Дело в том, что для каждого уникального запроса строится план разбора и кладется в кэш. Если различных запросов очень много, как, например, весьма распространенный запрос по ID, то на каждый запрос буден генериться свой план, к тому же они будут вытеснять из кэша все другие планы, что может в разы увеличить время отклика вашей базы данных.
Стоит так же заметить, что не стоит этим злоупотреблять и использовать связывание для столбцов с небольшим количеством различных значений, как-то флаг is_deleted, ведь различных запросов в этом случае будет не так много, а, возможно, для более конкретного запроса СУБД удастся построить более эффективный план.
Еще пара заметок для программиста
Если у вас колонка имеет тип VARCHAR2(100), то попытка туда запихнуть строку longString.substring(0, 100) не факт, что увенчается успехом, так как ограничение 100 в определении колонки по умолчанию относится к количеству байтов, а не символов, поэтому при наличии двухбайтовых символов вы можете попасть впросак. На самом деле данное поведение можно немного сконфигурировать, подробнее можно почитать тут. Хорошо если вы еще не пытаетесь выполнить вставку в бесконечном цикле, по принципу делать пока не получиться, ведь это «получиться» в данном случае никогда не наступит.
Ну и общая рекомендация для всех типов БД: никогда не делайте update всех колонок в таблице при изменении одного поля объекта. Кажется весьма очевидным, но как показывает практика, данный антипаттерн часто имеет место быть, поэтому я настоятельно рекомендую проверить, что ваши фреймворки делают UPDATE только действительно измененных полей.

Рассматривается использование следующего поколения LOB-объектов: SecureFiles (сохраняемые файлы), которые объединяют лучшее качества внешних файлов (external files) и LOB-объектов базы данных для хранения неструктурированных данных, которые допускают также шифрование, сжатие, однократное хранение нескольких одинаковых объектов (deduplication – дедупликация) и т.д.
Внутренние двоичные объекты (BLOB) базы данных и файлы операционной системы
Что находится в базе данных Oracle? В большинстве случаев это - данные, хранимые в виде, пригодном для простого преобразования в некий определенный шаблон заданного типа данных: имена пользователей, остатки на счетах, коды состояний и т.п. Но со столь же большой долей вероятности может понадобиться хранение данных в неструктурированном или полуструктурированном виде. Например, изображения, текстовые документы, таблицы, XML-файлы и так далее. Как хранятся эти типы данных?
Обычно используется два подхода: такие данные хранятся в базе данных как LOB-объектов (BLOB для двоичных и CLOB для символьных данных) или в виде файлов операционной системы, а в базе данных хранятся на них ссылки.
Каждый подход имеет достоинства и недостатки. Файлы операционной системы могут кешироваться и журналироваться средствами операционной системы, что ускоряет их восстановление после сбоев. К тому же они обычно занимают меньше места, чем данные в базе данных, поскольку могут быть сжаты.
Существуют также средства, которые позволяют распознавать такие структуры (patterns) в файлах и удалять повторяющиеся элементы для более эффективного хранения. Но они не являются частью базы данных и не имеют ее свойств. Резервное копирование таких файлов не выполняется, не доступны тонкости политики безопасности, эти файлы не являются частью транзакций, то есть целостность данных - первичная концепция базы данных Oracle - на них не распространяется.
Как же воспользоваться преимуществами каждого подхода? В Oracle Database 11g имеется ответ – SecureFiles (сохраняемые файлы), совершенно новая инфраструктура в базе данных, которая объединяет лучшие особенности LOB-объектов базы данных и файлов операционной системы. Давайте рассмотрим, как они работают. (Кстати, традиционные LOB-объекты до сих пор доступны в виде так называемых BasicFiles).
Практический пример
Представляется, что лучше всего представить концепцию SecureFiles с помощью простого примера. Предположим, вы разрабатываете систему документооборота, в которой хотите поместить в таблицу копии договоров. Обычно отсканированные документы представляют собой не текстовые, а PDF-файлы, а некоторые - документы MS Word или даже отсканированные рисунки. Это отличный пример для использования BLOB-объектов, так как такой столбец таблицы должен содержать двоичные данные.
Традиционное до Oracle Database 11g определение таблицы было бы следующим:
Реальные файлы хранятся в двоичном формате в столбце ORIG_FILE. Другие параметры показывают, что LOB-объект не должен кешироваться и журналироваться в операциях, что он хранится в строке таблицы, имеет размер порции (chunk) 4 КБ, и lob-сегмент находится в табличном пространстве USERS. Поскольку это явно не определено, LOB-объекты хранятся в Oracle Database 11g в общепринятом формате (BasicFiles).
Если надо хранить LOB-объект в виде SecureFile, то все, что необходимо сделать, это при создании таблицы дописать фразу store as securefile, как показано ниже:
Для того чтобы создать LOB-объект в виде SecureFile, необходимо выполнить два условия, причем оба выполняются по умолчанию (так что можно быть спокойным).
Параметр инициализации db_securefile должен быть установлен в permitted (значение по умолчанию). Я объясню, что это за параметр позднее.
Созданное табличное пространство, где размещаются сохраняемые (securefile) файлы, должно быть Automatic Segment Space Management (ASSM). ASSM - режим по умолчанию при создании табличного пространства в Oracle Database 11g, поэтому он уже установлен для табличного пространства. Если это всё же не так, тогда необходимо размещать SecureFiles в другом табличном ASSM-пространстве.
После того, как таблица создана, можно загружать данные тем же способом, как и обычные (до 11g) LOB-объекты (BasicFile). Не надо изменять приложения и не надо запоминать какой-то специальный синтаксис.
Вот пример небольшой программы, которая загружает данные в таблицу:
Эта программа 100 раз загружает файл contract.pdf в 100 строк таблицы. Заранее надо иметь определенный объект типа directory, названный SECFILE, определяющий директорию операционной системы, где расположен файл contract.pdf. Ниже приводится пример, в котором файл contract.pdf расположен в директории /opt/oracle.
Один раз сохранив LOB-объект как SecureFile, вы получаете множество возможностей для выполнения оптимальных действий. Приведем несколько примеров этих весьма полезных возможностей.
Однократное хранение нескольких одинаковых объектов (deduplication)
Дедупликация, вероятно, самая яркая возможность SecureFiles, поскольку из всех преимуществ файлов операционной системы перед внутренними BLOB-объектами она наиболее востребована. Допустим, в таблице хранится пять записей, каждая с BLOB-объектом. Три из них одинаковы. Если была бы возможность однократного хранения BLOB-объекта и размещения ссылки на него в других двух записях, это существенно бы уменьшило занимаемое место. Это возможно для файлов операционной системы, но не для LOB-объектов в Oracle Database 10g. Для SecureFile это легко реализуется с помощью свойства дедупликации. Его можно определить при создании таблицы или позднее:
В процессе дедупликации СУБД хеширует значения столбцов в каждой строке и сравнивает хеш-значения друг с другом. Если хеш-значения совпадают, то сохраняются они, а не исходный BLOB-объект. Когда добавляется новая запись, то вычисляется хеш, и если он совпадает со значением в другой строке, то сохраняется хеш-значение, в противном случае сохраняется реальное значение.
Теперь давайте определим объем пространства, сохраненного в результате дедупликации.
Определение занимаемого пространства LOB-сегментом можно выполнить с помощью пакета DBMS_SPACE. Ниже демонстрируется пример программы, показывающей занимаемое место:
Этот скрипт показывает объем занимаемого LOB-объектами пространства. Вот результат до процесса дедупликации:
и после дедупликации:
В приведенных данных достаточно сравнить только одну метрику used_bytes, которая показывает точное количество байтов, занимаемых LOB-столбцом. До дедупликации он занимал 4,923,392 байтов, или около 5 Мбайт, а уменьшился до 57,344 байт, что составляет около 57 Кбайт, то есть всего лишь около одного процента от исходного размера. Так получилось потому, что процесс дедупликации 100 раз нашел строки с одним и тем же значением (помните, мы в LOB-столбец всех строк поместили одно и тоже значение) и сохранил его только в одной строке, а в остальных – только указатели.
Можно обратить результат дедупликации:
Посмотрим после этого снова на занимаемое место:
Мы видим, что значение USED_BYTES выросло до исходной величины около 5 Мбайт.
Сжатие (Compression)
Другой возможностью SecureFiles является сжатие. Можно сжимать содержимое LOB-объектов, используя следующие SQL-предложение:
Сейчас, если выполнить PL/SQL-блок, вычисляющий объем:
то увидим, что значение used_bytes сейчас равно 1,646,592, или около 1,5 MB, что существенно меньше 5 MB.
Сжатие отличается от дедупликации. Сжатие происходит внутри LOB-столбца, в строке – каждый LOB-объект сжимается независимо от других. При дедупликации проверяются все строки, повторные значения удаляются и заменяются указателями. Если есть две существенно отличающиеся строки, дедупликация не уменьшит занимаемый размер, а сжатие может оптимизировать место, занимаемое LOB-объектами. Можно как сжимать, так и дедуплицировать данные.
Сжатие требует работы CPU, поэтому в зависимости от количества сжимаемых данных, сжатие может потерять смысл. Например, имеется много изображений в формате JPEG, которые уже сжаты, поэтому дальнейшее сжатие не уменьшит занимаемое место. С другой стороны, если CLOB-объектом является XML-документ, то сжатие может получиться существенным. Процесс SecureFiles-сжатия автоматически определяет, сжимаются ли данные или только расходуется процессорное время.
Индексы Oracle Text могут быть созданы как LOB-ы сжатых SecureFiles (compressed SecureFiles LOBs). Это главное преимущество хранения неструктурированных данных в базе данных Oracle по сравнению сжатыми файлами файловой системы.
Так же отметим, что сжатие LOB-объектов не зависит от сжатия таблиц. Если сжимается таблица CONTRACTS_SEC, то её LOB-объекты не сжимаются. Сжатие LOB-объектов будет происходить только при использовании приведенного выше SQL-предложения.
В Oracle Database 11g R2 есть третья возможность сжатия в дополнение к HIGH и MEDIUM: LOW. Как следует из её имени, в этом случае коэффициент сжатия минимальный, но намного меньше потребление ресурсов CPU, а также более высокая скорость процесса. В этом случае используется блок-базируемое сжатие без потерь (block-based lossless compression), подобное быстрому алгоритму LempelZivOberhumer (LZO) .
Рассмотрим пример LOW-сжатия таблицы, содержащей SecureFiles:
Если опустить фразу LOW, то по умолчанию сжатие будет выполнено в варианте MEDIUM. LOW-сжатие можно указать не только при создании таблицы; также можно применить LOW-сжатие, чтобы изменить существующий столбец.
Рассмотрим пример с этой же таблицей и столбцом. Для начала мы изменим столбец как несжатый:
Далее установим для столбца low-сжатие:
Шифрование (Encryption)
Перед проведением шифрования необходимо установить крипто-блокнот (encryption wallet). (Полное описание encryption wallet можно найти в Oracle Magazine в моей статье «Transparent Data Encryption»
Кратко перечислим основные действия:
- Установить, если еще не задан, в файле sqlnet.ora параметр, определяющий расположение крипто-блокнота: Директория /opt/oracle/orawall уже должна существовать, в противном случае ее необходимо создать.
- Создать крипто-блокнот: Это предложение создает крипто-блокнот с паролем mypass и открывает его.
- Предыдущие два шага выполняются только один раз. После того, как крипто-блокнот создан и открыт, он остается открытым, пока работает база данных (до тех пор, пока она полностью не завершит работу). Если база данных перезапускается, необходимо открыть wallet предложением:
Если LOB-столбец SecureFile показан как зашифрованный, то шифруются все значения этого столбца во всех строках этой таблицы. После шифрования нельзя использовать обычный (Conventional Export or Import) экспорт и импорт этой таблицы, а необходимо использовать утилиту Data Pump.
Кеширование (Caching)
Возможность кеширования – одно из преимуществ хранения неструктурированных данных в файлах операционной системы, а не во внутренних объектах базы данных. Файлы могут кешироваться в файловых буферах операционной системы. Внутренние объекты базы данных могут кешироваться базой данных. Тем не менее, в некоторых случаях кеширование может снизить производительность. LOB-объекты обычно очень велики (отсюда и название Large OBjects) и, если они попадают в кеш, то большинство количество других блоков будут оттуда вытеснены, чтобы дать место поступившему LOB-объекту. LOB-объект, возможно, и не будет потом использоваться, но при его записи в кеш используемые блоки оттуда будут удалены. Поэтому в большинстве случаев всё-таки следует отключить кеширование LOB-объектов.
В приведенном примере для CONTRACTS_SEC использовалась фраза nocache для отключения кеширования. Для включения кеширования следует изменить таблицу:
Это действие включает кеширование LOB-объектов. Отметим, что это кеширование относится только к LOB-объектам. Оставшаяся часть таблицы кешируется по тем же правилам, что и любая другая таблица, вне зависимости от того, установлено ли кеширование LOB-объектов таблицы, или нет.
Преимущества от кеширования сильно зависят от приложений. В приложении, работающем с мелкими (thumbnail ) рисунками, производительность, возможно, при кешировании увеличиться. Тем не менее, для больших документов или рисунков кеширование лучше отключить. Securefiles позволяют это контролировать.
Журналирование (Logging)
Журналирование определяет, как изменения данных в LOB-объектах записываются в поток redo-журнала. По умолчанию для них установлено полное журналирование, как для всех остальных данных. Но, поскольку данные в LOB-объектах обычно велики, вероятно, захочется в некоторых случаях отключить журналирование. Фраза NOLOGING, использованная в предыдущем примере, делает именно это.
Для SecureFiles имеется еще одно значение для этой фразы — filesystem_like_logging— как показано ниже:
Отметим, что выделенная жирным шрифтом строка, включает ведение redo-журнала для метаданных LOB-объектов, но не для самих LOB-объектов. Это похоже на файловую систему, когда метаданные файлов записываются в журналы файловой системы. Эта возможность облегчает восстановление после сбоев.
Читайте также: