
Как упорядочены элементы массива в памяти компьютера
Обновлено: 08.07.2024
5. ОДНОМЕРНЫЕ И ДВУМЕРНЫЕ МАССИВЫ (ТАБЛИЦЫ)
Массив — это пронумерованная последовательность величин одинакового типа, обозначаемая одним именем. Элементы массива располагаются в последовательных ячейках памяти, обозначаются именем массива и индексом. Каждое из значений, составляющих массив, называется его компонентой (или элементом массива).
Массив данных в программе рассматривается как переменная структурированного типа. Массиву присваивается имя, посредством которого можно ссылаться как на массив данных в целом, так и на любую из его компонент.
Переменные, представляющие компоненты массивов, называются переменными с индексами в отличие от простых переменных, представляющих в программе элементарные данные. Индекс в обозначении компонент массивов может быть константой, переменной или выражением порядкового типа.
Если за каждым элементом массива закреплен только один его порядковый номер, то такой массив называется линейным. Вообще количество индексов элементов массива определяет размерность массива. По этом признаку массивы делятся на одномерные (линейные), двумерные, трёхмерные и т.д.
Пример: числовая последовательность четных натуральных чисел 2, 4, 6, . N представляет собой линейный массив, элементы которого можно обозначить А[1]=2, А[2]=4, А[3]=6, . А[К]=2*(К+1), где К — номер элемента, а 2, 4, 6, . N — значения. Индекс (порядковый номер элемента) записывается в квадратных скобках после имени массива.
Например, A[7] — седьмой элемент массива А; D[6] — шестой элемент массива D.
Для размещения массива в памяти ЭВМ отводится поле памяти, размер которого определяется типом, длиной и количеством компонент массива. В языке Pascal эта информация задается в разделе описаний. Массив описывается так:
— описывается массив В, состоящий из 5 элементов и символьный массив R, состоящий из 34 элементов. Для массива В будет выделено 5*6=30 байт памяти, для массива R — 1*34=34 байта памяти.
Базовый тип элементов массива может быть любым, за исключением файлового.
Заполнить массив можно следующим образом:
1) с помощью оператора присваивания. Этот способ заполнения элементов массива особенно удобен, когда между элементами существует какая-либо зависимость, например, арифметическая или геометрическая прогрессии, или элементы связаны между собой реккурентным соотношением.
Задача 1. Заполнить одномерный массив элементами, отвечающими следующему соотношению:
a 1 =1; a 2 =1; a i =a i -2 +a i -1 (i = 3, 4, . n).
Другой вариант присваисвания значений элементам массива — заполнение значениями, полученными с помощью датчика случайных чисел.
Задача 2. Заполнить одномерный массив с помощью датчика случайных чисел таким образом, чтобы все его элементы были различны.
2) ввод значений элементов массива с клавиатуры используется обычно тогда, когда между элементами не наблюдается никакой зависимости. Например, последовательность чисел 1, 2, -5, 6, -111, 0 может быть введена в память следующим образом:
Над элементами массивами чаще всего выполняются такие действия, как
а) поиск значений;
б) сортировка элементов в порядке возрастания или убывания;
в) подсчет элементов в массиве, удовлетворяющих заданному условию.
Cумму элементов массива можно подсчитать по формуле S=S+A[I] первоначально задав S=0. Количество элементов массива можно подсчитать по формуле К=К+1, первоначально задав К=0. Произведение элементов массива можно подсчитать по формуле P = P * A[I], первоначально задав P = 1.
Задача 3. Дан линейный массив целых чисел. Подсчитать, сколько в нем различных чисел.
Тест: N = 10; элементы массива - 1, 2, 2, 2, -1, 1, 0, 34, 3, 3. Ответ: 6.
Задача 4. Дан линейный массив. Упорядочить его элементы в порядке возрастания.
Тест: N = 10; элементы массива - 1, 2, 2, 2, -1, 1, 0, 34, 3, 3.
Ответ: -1, -1, 0, 1, 2, 2, 2, 3, 3, 34.
Если два массива являются массивами эквивалентых типов, то возможно присваивание одного массива другому. При этом все компоненты присваиваемого массива копируются в тот массив,оторому присваивается значение. Типы массивов будут эквивалентными, если эти массивы описываются совместно или описываются идентификатором одного и того же типа. Например , в описании
типы переменных A, B эквивалентны, и поэтому данные переменные совместимы по присваиванию; тип переменных C, D также один и тот же, и поэтому данные переменные также совместны по присваиванию. Но тип переменных C, D не эквивалентен типам переменных A, B, E, поэтому, например, A и D не совместны по присваиванию. Эти особенности необходимо учитывать при работе с массивами.
При решении практических задач часто приходится иметь дело с различными таблицами данных, математическим эквивалентом которых служат матрицы. Такой способ организации данных, при котором каждый элемент определяется номером строки и номером столбца, на пересечении которых он расположен, называется двумерным массивом или таблицей.
Например, данные о планетах Солнечной системы представлены следующей таблицей:
В современном мире ежесекундно происходит обработка огромного числа данных с помощью компьютера. Если необходимо обрабатывать данные одного типа — числа, символы, строки и др., то для их хранения можно воспользоваться типом данных, который называется массив.
Массив — упорядоченная последовательность данных, состоящая из конечного числа элементов, имеющих один и тот же тип, и обозначаемая одним именем.
Массив является структурированным (составным) типом данных. Это означает, что величина, описанная как массив, состоит из конечного числа других величин. Так, например, можно создать массивы из 10 целых или 100 вещественных чисел. Тип элементов массива называют базовым типом. Все элементы массива упорядочены по индексам (номерам элементов), определяющим местоположение элемента в массиве. В языке С++ элементы массива всегда нумеруются с нуля.
Массиву присваивается имя, посредством которого можно ссылаться на него как на единое целое. Элементы, образующие массив, упорядочены так, что каждому элементу соответствует номер (индекс), определяющий его место в общей последовательности (примеры 11.1—11.3). Индексы могут быть выражением, значение которого принадлежит любому простому типу, кроме вещественного. Индексы должны быть неотрицательными. Доступ к каждому отдельному элементу осуществляется обращением к имени массива с указанием индекса нужного элемента, индекс элемента записывается после имени в квадратных скобках (пример 11.4).
Впервые тип данных массив появился в языке Фортран (создан в период с 1954 по 1957 г. в корпорации IBM). Уже первые версии языка поддерживали трехмерные массивы (в 1980 г. максимальная размерность массива была увеличена до 7). Массивы были необходимы для создания математических библиотек, в частности содержащих процедуры решения систем линейных уравнений.
Пример 11.1. В 10 А классе 25 учащихся. Известен рост каждого в сантиметрах. Для хранения значений роста можно использовать массив А, состоящий из 25 целых чисел.
Индекс каждого элемента — порядковый номер учащегося из списка в классном журнале. Поскольку элементы массива нумеруются от нуля, то запись а[5] — рост ученика, который в журнале записан под номером 6.
Пример 11.2. Каждый день в декабре измеряли температуру воздуха. Для хранения значений температуры можно использовать массив t , состоящий из 31 вещественного числа.
Индекс элемента — номер дня в декабре со сдвигом на 1. Запись t[15] — температура воздуха 16 декабря.
Пример 11.3. В 10 Б классе 27 учащихся. В классном журнале указаны фамилия и имя каждого учащегося. Для хранения списка учащихся можно использовать массив s , состоящий из 27 строк.
Индекс каждого элемента — порядковый номер ученика из списка в классном журнале. Тогда запись s[5] — фамилия и имя учащегося под № 6.
Пример 11.4. Обращение к элементу массива: а[3], t[i], s[n-1] .
Язык программирования С++ поддерживает работу с массивами, которые достались ему в наследство от языка С. Однако работа с такими массивами требует глубокого понимания того, как они размещаются в памяти компьютера. В качестве альтернативы рекомендуется использовать шаблоны классов, которые описаны в стандартной библиотеке: array<> и vector<>.11.2. Описание массивов
Мы будем рассматривать работу с массивом, используя тип данных vector , реализованный в стандартной библиотеке. Этот тип данных, как и уже знакомый вам тип данных string , является шаблонным классом, поэтому многие команды для работы будут одинаковыми.
Для работы с типом данных vector необходимо подключить одноименную библиотеку:
Для создания вектора используется следующая команда:
vector < тип элементов > имя_массива ( количество элементов );
Имя массива является идентификатором и задается по тем же правилам, что и имена любых других переменных.
Тип элементов задает значение базового типа для данного массива. Базовый тип может быть любым из известных вам типов (примеры 11.5–11.7).
Размер массива — количество элементов в нем.
Понятие вектора широко применяется в физике и математике. Так, например, в физике вектор рассматривается как структура, имеющая одновременно величину (модуль) и направление. Многомерные векторы используются в квантовой механике. В геометрии под векторами понимают направленные отрезки. Арифметическим вектором называют упорядоченную совокупность из n чисел. Вектор может рассматриваться как последовательность (кортеж) однородных элементов. Именно в таком виде вектор понимается в программировании.
Пример 11.5. Опишем массив, рассмотренный в примере 11.1. Размер описанного массива 25 элементов.
vector < int > a ( 25 );
Пример 11.6. Опишем массив, рассмотренный в примере 11.2. Размер описанного массива — 31 элемент.
vector < double > t ( 31 );
Пример 11.7. Опишем массив, рассмотренный в примере 11.3.
vector < string > s ( 27 );
Пример 11.8. Опишем массив, всем элементам которого вначале присваивается значение –1:
vector < int > a ( 25 , -1 );
11.3. Операции над массивами
Массивы, описанные типом данных vector , можно использовать в операциях присваивания. В результате выполнения этой команды все элементы одного массива будут переписаны во второй (пример 11.9). Если в описании векторы имеют разный размер, то он будет преобразован, поскольку векторы являются динамическими структурами, которые могут изменять свой размер во время выполнения программы.
Векторы можно сравнивать. При сравнении используют операции сравнения «==» и «!=». Векторы равны, если они содержат одинаковые элементы на тех же позициях, иначе они не равны.
Другие операции для массива как для типа данных не определены.
Пример 11.9. Пусть массивы a и b описаны следующим образом:
vector < int > a ( 25 ), b ( 30 );
В результате выполнения команды:
размер массива a будет увеличен до 30 элементов, все элементы в массиве a будут иметь те же значения, что и в массиве b .
В результате выполнения команды:
размер массива b будет уменьшен до 25 элементов, все элементы в массиве b будут иметь те же значения, что и в массиве a . Значения последних 5 элементов, которые исходно были в векторе b , будут потеряны.
Пример 11.10. Операции над индексированными переменными:
sr = ( t [ 0 ] + T [ 29 ]) / 2 ;
b [ k ] = a [ k ] * 2 ;
if ( s [ i ] < 0 ) …
n = s [ i ]. length ();
11.4. Ввод и вывод элементов массива
Для того чтобы работать с массивом, необходимо задать начальные значения элементов массива. Сделать это можно несколькими способами:
1) определение элементов массива как констант;
2) ввод элементов массива с клавиатуры;
3) использование случайных чисел для определения значений;
4) использование функций (собственных или стандартных) для определения значений;
5) ввод элементов массива из текстового файла.
Элементам массива можно задать значения при описании (примеры 11.11, 11.12). В этом случае количество элементов не задается, а определяется автоматически.
При вводе элементов массива с клавиатуры каждый элемент должен вводится отдельно. Если количество вводимых элементов определено, то можно воспользоваться циклом for (пример 11.13).
При описании вектора его размер может быть задан переменной. Важно, чтобы значение этой переменной было определено до описания вектора. Это значение может быть задано с помощью команды присваивания или введено с клавиатуры (пример 11.14).
При вводе строк нужно помнить, что пробел используется как разделитель. Если использовать для ввода команду cin , то элементами массива могут быть только отдельные слова строки ( пример 11.15). Если нужно, чтобы элементами массива были строки с пробелами, то для ввода необходима команда getline (пример 11.16).
Иногда бывает удобно задавать элементы массива случайным образом. Для этого используется функция rand(), которая генерирует случайное целое число из промежутка [0 ; 32768). Если элементы массива должны принадлежать отрезку [a ; b], то можно определить значение элемента массива как a[i]= rand() % (b – a + 1) + a ; (пример 11.17).
Вещественное случайное число в промежутке [0, 32.768) можно получить так: a[i]= 1. * rand() / 1000 ;
Выводить элементы массива можно в строку (пример 11.18) или в столбец (пример 11.19). Если элементы массива выводятся в строку, то между ними нужно выводить символ-разделитель (чаще всего используют пробел), иначе все числа будут распечатаны подряд как одно число с большим количеством цифр. Выводить элементы массива можно не только в прямом порядке, но и в обратном (пример 11.20).
Пример 11.21. Написать программу, которая сформирует массив из n четных чисел из отрезка [20, 70] случайным образом. Записать числа из массива в текстовый файл. Вывести на экран k -й элемент массива.
Этапы выполнения задания
I. Исходные данные: количество элементов n и массив a.
II Результат: искомый элемент.
III. Алгоритм решения задачи.
1. Ввод исходных данных.
2. Генерация массива.
2.1. Для того чтобы элементы массива были только четными, необходимо каждый полученный элемент умножать на 2.
2.2. Поскольку элементы умножаются на два, границы исходного отрезка нужно уменьшить в два раза.
2.3. Вывод массива по элементам.
3. Ввод значения k и вывод результата.
IV. Описание переменных:
n, k – int, a – vector <int>.
Пример 11.22. Написать программу, которая прочитает из текстового файла список фамилий учащихся, запишет их в массив и выведет из списка фамилии с номерами от k1 до k2 .
Этапы выполнения задания
I. Исходные данные: массив s и количество учащихся n, номера фамилий – k1 и k2 .
II. Результат: список заданных фамилий.
III. Алгоритм решения задачи.
Ввод исходных данных.
2. Вывод результата.
IV. Описание переменных:
n, k1, k2 – int, a – vector <string>.
Если для тестирования программы используются фамилии, написанные кириллицей, то важно сохранить текстовый файл в той же кодировке, которая устанавливается для консоли. По умолчанию для Блокнота может быть установлена кодировка UTF-8.
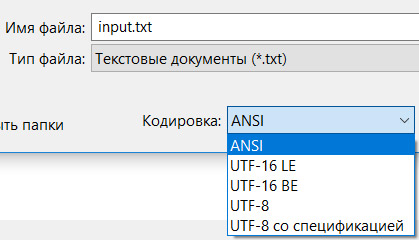
Пример 11.11. Описание числового массива, элементы которого являются константами.
Пример 11.12. Описание массива, элементы которого являются строковыми константами.
Пример 11.13. Ввести элементы массива a с клавиатуры.
vector < int > a ( 10 );
cout << "vvedi 10 chisel" << endl ;
for ( int i = 0 ; i < 10 ; i ++)
Пример 11.14. Ввести заданное количество элементов массива a .
cout << "kol-vo chisel" << endl ;
vector < int > a ( n );
cout << "vvedi chisla" << endl ;
for ( int i = 0 ; i < n ; i ++)
Пример 11.15. Ввод массива строк (без пробелов):
cout << "kol-vo elementov" << endl ;
vector < string > s ( n );
cout << "vvedi slova " << endl ;
for ( int i = 0 ; i < n ; i ++)
Пример 11.16. Ввод массива строк (с пробелами):
cout << "kol-vo elementov" << endl ;
vector < string > s ( n );
cout << "vvedi stroki" << endl ;
for ( int i = 0 ; i < n ; i ++)
getline ( cin , s [ i ]);
Пример 11.17. Случайным образом задать n элементов массива А. Каждый элемент — число из отрезка [-20; 20] .
cout << "kol-vo elementov" << endl ;
vector < int > a ( n );
for ( int i = 0 ; i < n ; i ++)
a [ i ] = rand () % 41 - 20 ;
Пример 11.18. Вывод элементов массива в строку (через пробел):
for ( int i = 0 ; i < n ; i ++)
Если элементы массива задаются случайным образом, то после генерации их нужно вывести. Это необходимо для проверки правильности работы, иначе непонятно, с какими данными работает программа.
Пример 11.19. Вывод элементов массива в столбец (по одному в строке):
for ( int i = 0 ; i < n ; i ++)
Пример 11.20. Вывод элементов массива в строку (в обратном порядке):
Продолжаем разговор об основах построения вычислительной техники. На этот раз рассмотрим массивы. Это структура в памяти компьютера в виде элементов, расположенных друг за другом. В классическом понимании эти элементы однотипные. В отдельных технологиях элементы могут быть разных типов, но это уже совсем другая история. Массивы это чрезвычайно часто используемая абстракция. С помощью них организуются вычисления при обработке практически любых данных. Это голос, изображения, видео и разные поля величин в многомерных координатных пространствах.
На сегодня у нас задача сложения всех элементов массива. Какие частные вопросы мы рассмотрим:
- технические подробности доступа к элементам массива в памяти компьютера,
- продолжим освоение циклических конструкций языка си,
- вызов функций.
Процессор с регистровым файлом.
Схема простейшего процессора из прошлых статей слишком примитивна для освещения поставленных вопросов. Немного доработаем ее до представленной схемы.
В основном, нам тут покажется знакомыми многие детали.
Никуда не исчез регистр счетчика инструкций, он же регистр указателя инструкции PC .
Как и раньше он занимается изъятием из памяти очередной инструкции из памяти.
Помогает ему в этом сумматор текущего адреса инструкции с единицей.
Выбранная инструкция поступает в регистр команды на временное хранение.
Как можно заметить, теперь нет отдельной памяти для программ и для данных. Есть одна общая память. Поэтому доступ за инструкцией и за данными осуществляется по очереди. Пока происходит выборка данных инструкция хранится в своем регистре и через дешифратор команд управляет всеми потоками данных в процессоре. Теперь рассмотрим одну важную конструкцию. Это пара регистров R1 и R2 . Их выходы подключаются к арифметико-логическому устройству , служащему не просто для арифметических операций, а для вычисления адреса, где хранятся данные.
Рассмотрим расположение массива в памяти. Самый первый элемент массива программисты называют нулевым элементом и на это есть причины технического характера. Для доступа к элементам массива в один из регистров, называемый базой, заносится адрес нулевого элемента. Тогда второй регистр будет хранить индекс элемента и в совокупности это будет весьма удобной схемой. На рисунке регистр R1 указывает на ячейку 2 . Регистр R2 хранит число 3, которое является индексом элемента 6 . Мы получили к нему доступ, хотя полный адрес числа 6 нам совершенно не интересен. Если в R2 поместить ноль, то получим доступ к нулевому элементу массива. Хоть абстракции и позволяют программистам не заботиться о таких технических вопросах, но по видимому понятие нулевого элемента прижилось надежно.Итак, база и индекс позволяют организовать удобный доступ к элементам массива. В языках Си и С++ синтаксически определено, что имя массива является указателем на нулевой элемент. Также индекс массива, указывающийся в квадратных скобках может быть вычисляемой величиной в процессе работы программы.
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).

Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.

Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.

- N дерево
- Сбалансированное дерево
- Дерево Бинарного Поиска
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».

Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Читайте также: