
Как вытащить текст из пдф файла
Обновлено: 07.07.2024
5 Оценок: 1 (Ваша: ) Необходимо вытащить информацию из PDF или извлечь текст, картинки, таблицы и другие графические элементы? Вы можете копировать данные с помощью программ на ПК для редакции ПДФ, софта для распознавания символов или переформатировать файл в другое расширение в онлайн-сервисе. В этой статье мы расскажем, как скопировать текст из ПДФ тремя способами.
Хотите копировать текст из ПДФ в два клика?
Скачайте удобный PDF редактор
Способ 1: программы для работы с ПДФ
Самый оптимальный способ — использовать приложения для копирования и извлечения информации из ПДФ. Для работы программное обеспечение потребуется установить на компьютер, однако это с лихвой окупит удобство и обширный функционал подобного софта. Вы сможете просматривать файлы, копировать текст, оставлять комментарии, ставить цифровые подписи, конвертировать документы в любые форматы и многое другое.
PDF Commander
Программа для работы с PDF, которая содержит инструменты для создания документов с нуля, редактирования страниц, конвертации и объединения медиафайлов в другие форматы. Вы сможете перевести ПДФ в JPEG, BMP, PNG, TIFF, WMF и TXT. Также у вас будет возможность извлекать картинки и разбивать документ на отдельные листы.
Преимущества PDF Commander:
- Опции для создания документов с нуля: настройка параметров страниц, размещение картинок, штампов и т.д..
- Объединение медиафайлов и преобразование материала в другие форматы.
- Удобный просмотр, а также создание закладок и заметок.
- Установка пароля на открытие и редактирование, а также скрытие личной информации и изменение метаданных.
- Извлечение изображений и разбиение файла на отдельные листы.
- Удобный интерфейс на русском языке.
Как скопировать текст из ПДФ в Ворд? Выполните несколько простых действий:
-
Скачайте редактор на компьютер и запустите установщик. Во время инсталляции выполните стандартные действия: примите пользовательское соглашение, укажите папку и создайте ярлык на рабочий стол. Откройте ПО и в стартовом меню нажмите на подходящее действие. Также можно перетащить медиафайл в окно софта.
Adobe Reader
Бесплатный ридер для просмотра и комментирования PDF. С его помощью вы сможете создать закладки и заметки, а также выделять часть текста. Чтобы преобразовать весь проект в Ворд, Эксель или другой формат, потребуется приобрести платную подписку. Также про-версия открывает доступ к другим функциям: создание, коррекция, подпись, шифрование и переформатирование медиаданных. Платный пакет отличается высокой стоимостью: 1159 рублей в месяц.
- Удобный просмотр и перелистывание.
- Опции для создания закладок и комментариев.
- Совместный доступ и просмотр аннотаций других пользователей.
- Возможность скопировать отдельные предложения или выделить все.
- Бесплатный просмоторщик на русском языке.
- Отсутствие функций для редактирования.
- Невозможность переформатировать работу в TXT или DOC.
Evince
Софт с открытым исходным кодом для чтения многостраничных документов, поддерживающая несколько медиаформатов. Она предлагает полноэкранный режим просмотра и опцию слайд-шоу для автоматической смены листов. Поддерживаемые расширения: PostScript, DVI, DjVu, многостраничный TIFF, OpenDocument Presentation, XPS, изображения, CBR, CBZ, CB7 и MS Word.
Софт позволяет выделять и извлекать предложения, искать слова в нем и переносить данные в буфер обмена и Ворд. Вы способны скопировать текст из PDF, даже если проект защищен паролем.
- Поиск слов.
- Встроенный менеджер печати.
- Копирование медиаданных из закодированного документа.
- Бесплатность и меню на русском языке.
- Отсутствие опций для редактирования.
- Нельзя конвертировать материал в текстовый формат.
Способ 2: применение OCR
Оптическое распознавание позволяет копировать символы в отсканированных и защищенных документах. Воспользуйтесь программой ABBYY FineReader. Она автоматически получает изображения со сканеров, файловых серверов, факсов и электронной почты, а также библиотек Microsoft SharePoint. Затем она выполняет оптическое распознавание символов (OCR) и позволяет добавлять медиаданные. Приложение является платным, для использования функций потребуется приобрести его за 8990 р.
Для копирования просто откройте медиафайл в софте и конвертируйте его в Word. Также можно отсканировать бумажный носитель или добавить фотографию с разборчивыми надписями.
Способ 3: Онлайн-сервисы для конвертации PDF
У вас есть возможность перевести PDF-документы в текстовый материал в браузере с помощью онлайн-сервисов. Они способны быстро переформатировать проект без изменения содержания. Однако они зависят от качества интернет-соединения, часто зависают, а также позволяют проводить лишь ограниченное количество операций в сутки.
PDFCandy
Веб-ресурс, позволяющий не только извлечь текстовый слой, но и произвести оптическое определение символов. Помимо конвертации платформа предлагает инструменты для объединения, сжатия и редактирования медиафайлов.
Как копировать текст в ПДФ? Загрузите нужный документ с персонального компьютера или облачного хранилища, а затем скачайте результат в подходящем расширении, например DOCX или TXT.
Особенности сервиса PDFCandy:
- Конвертация в другие медиаформаты.
- Вы не сможете скопировать отдельные фразы.
- Невозможно извлечь изображения и другие графические элементы.
- Оптическое распознавание текстовых данных.
PDFtoText
Бесплатный конвертер, который позволяет быстро обработать материал и скачать результат в TXT, DOC, DOCX. Вы способны провести до 20 операций одновременно и произвести пакетную коррекцию. Затем итог можно загрузить архивом.
Чтобы использовать PDFtoText, импортируйте файлы или перетащите их в окно загрузки, а затем скачайте на ПК.
Заключение
Теперь вы знаете, как копировать текст из ПДФ с помощью программного обеспечения, специального приложения для оптического определения символов (OCR) или через онлайн-ресурсы.
Компьютерные приложения позволят просматривать и комментировать материал. Софт PDF Commander также содержит инструменты для оформления, объединения и коррекции работы.
Платформа для оптического распознавания позволит копировать сведения даже из отсканированных и защищенных документов. Однако они отличаются высокой стоимость. Например, базовую версию приложение ABBYY FineReader можно купить за 8990 р.
Онлайн-сервисы предназначены для быстрого переформатирования без изменения содержания. Однако они зависят от качества интернет-соединения, а также позволяют проводить ограниченное количество операций за один раз.
Ответы на часто задаваемые вопросы:
Если необходимо вытащить сведения, вы можете воспользоваться разными способами: использовать ПО на компьютер или применить веб-платформу. Первый вариант позволит выделить надписи, а также переформатировать документ в другое расширение. Онлайн-ресурсы предлагают только возможность конвертировать в DOC, DOCX, TXT.
Чтобы извлечь данные из отсканированного или защищенного проекта, воспользуйтесь средством для оптического определения символов. Например, программой ABBYY FineReader или OCR CuneiForm.
Появление иероглифов в основном связано со следующими причинами:
Решить эти трудности позволят специальные программы, например, Evince и ABBYY FineReader.
Как скопировать текст из ПДФ, если он не копируется?Возможно материал защищен от редактирования и копирования данных. Вы можете увидеть, заблокирован ли он при его открытии в софте. Откройте меню «Свойства» и во вкладке «Безопасность» указано, разрешено ли копирование содержимого. При запрете определенных действий вам потребуется снять защиту и использовать программное обеспечение.

Рассмотрев ранее, как можно создавать PDF-документ, разными способами: и онлайн, и оффлайн и даже средствами Microsoft Office, пришло время рассказать, как произвести обратное действие.
Рассмотрим, как вытащить из PDF-документа текст, так чтобы можно было потом его редактировать в Word и подобных ему текстовых редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
Adobe Reader и аналоги
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
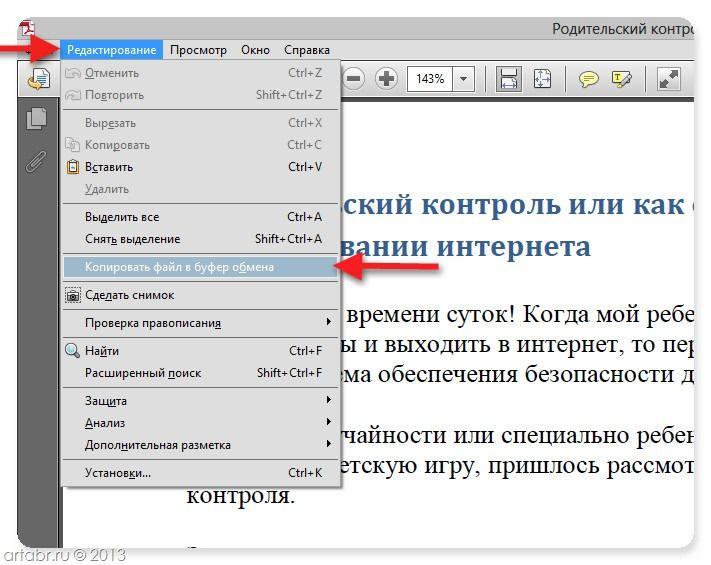
А дальше, стандартные действия: открываем Word, создаем новый документ и нажимаем кнопку Вставить или воспользуемся быстрыми клавишами (Ctrl+V).
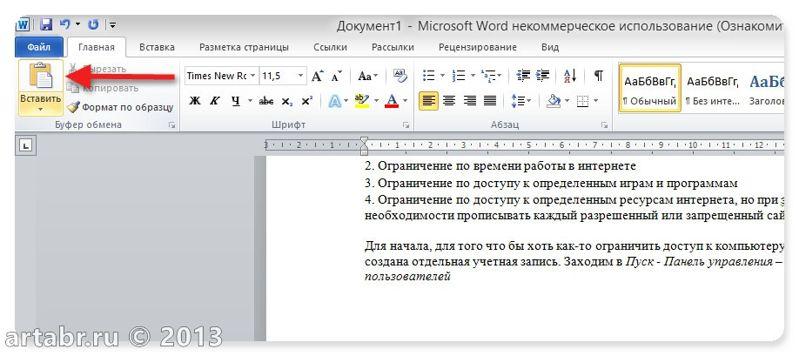
Все, можно спокойно редактировать полученный текст.
Обратите внимание, при использовании данного метода не сохраняется форматирование текста и нет возможности вытащить изображения.Если вам, все таки, во что бы то ни стало нужно извлечь изображение из PDF-документа, чтобы не использовать какие-нибудь программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого вы скопировали текст, но не получилось скопировать картинку.
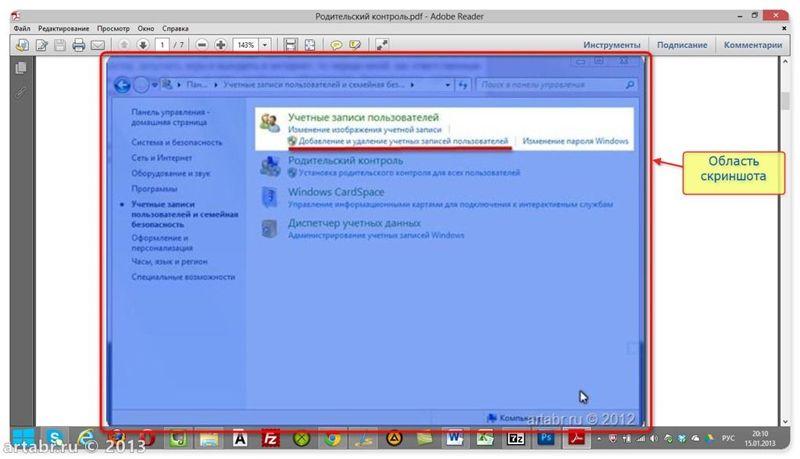
И полученное изображение вставьте в Word. Должно получиться вот так:
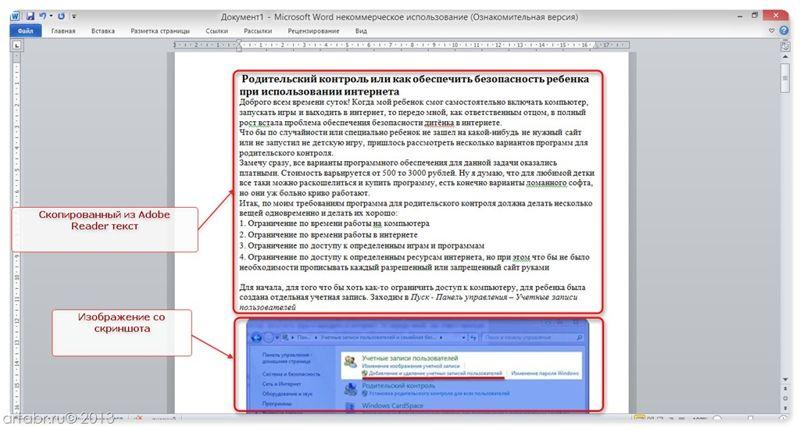
Понятно, что качество изображения будет оставлять желать лучшего, но как запасной вариант вполне подойдет.
В других просмотрщиках нужно будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда Выделить текст):
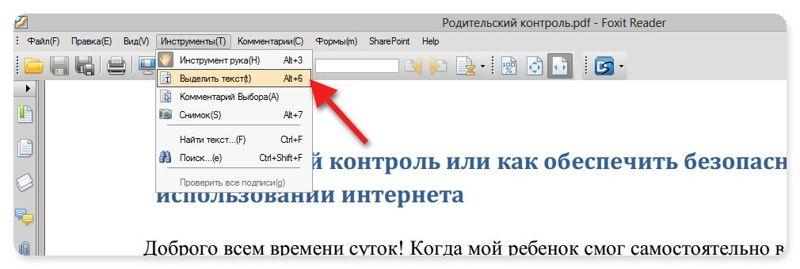
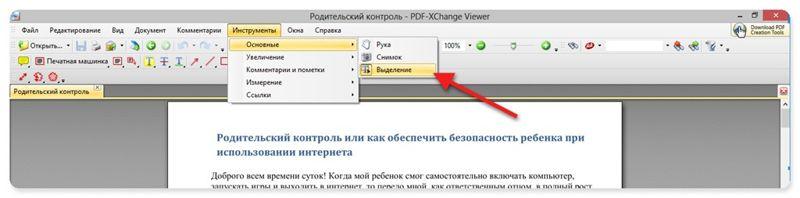
А вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
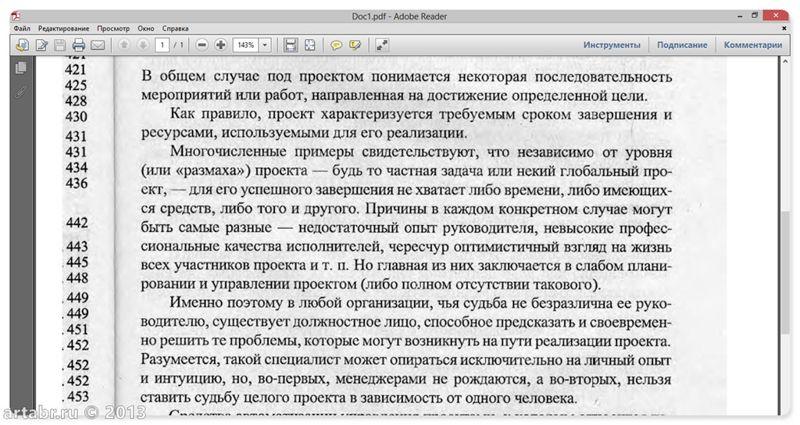
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
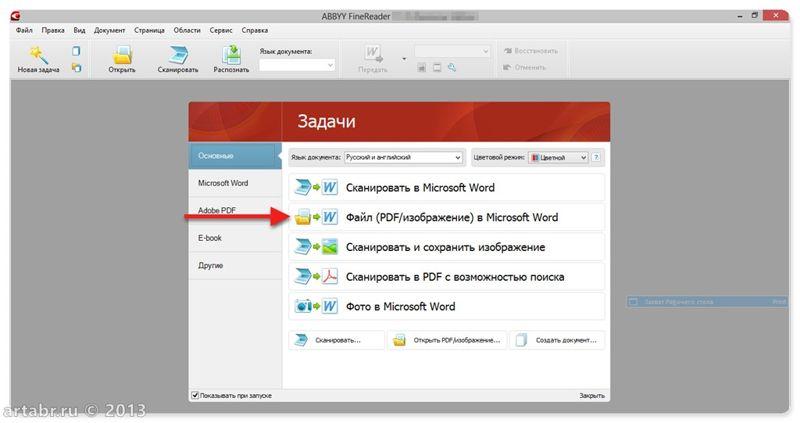
И все! Система сама распознает текст и отправляет его в Word

Онлайн-сервисы для конвертирования PDF-файлов
Вариант с онлайн-сервисами я уже описывал, единственно, что могу добавить еще пару подобных сервисов:
И опять же, ни один из онлайн-сервисов не работает с изображениями, и если текст у вас отсканирован и сохранен в формате PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но остальные имеют право на существование, потому что не каждый день требуется преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ преобразования PDF-файлов, напишите мне в комментариях.
Спасибо за внимание!
P.S. Лирическое отступление:
( 7 оценок, среднее 4.71 из 5 )В прошлом занимался руководством организации по монтажу сложного технологического оборудования и трубопроводов.
Сегодня разработчик WordPress и WooCommerce. Пишу плагины, разрабатываю сайты, собираю ножи.
Являюсь автором и ведущим проекта Финты WordPress.
Приветствую, друзья! Мне намедни сделали предложение написать обзор программы для конвертирования PDF-файлов в редактируемый формат. Естественно, Приветствую всех! Возвращаясь к теме создания PDF-документов, хочу открыть небольшие секреты создания документов с навигацией. Привет, всем! Частенько сталкиваясь по работе с распечаткой PDF-файлов на разных устройствах, от принтеров И снова, здрасте! Это опять я, и мы снова говорим про формат PDF. А Доброго времени суток! Как и обещал, рассказываю о еще одном способе создания PDF-документов. Правда Приветствую всех! Продолжая тему создания документов в формате PDF, в этой статье поговорим о
Вот такое искажение текста идет, если через буфер обмена
oaenoiaie .aaaeoi.; yeaeo.iiiay oaaeeoa; nenoaia oi.aaeaiey
aacaie aaiiuo; i.ia.aiia aiaeeca e ninoaaeaiey .anienaiee;
i.ia.aiia i.acaioaoee; a.aoe.aneee .aaaeoi.; i.ia.aiia ia-
neo.eaaiey oaen-iiaaia; naoaaia i.ia.aiiiia iaania.aiea:
yeaeo.iiiay ii.oa, eiiiu.oa.iua e oaeaeiioa.aioee e a..;
i.ia.aiiu ia.aaiaa; niaoeaeece.iaaiiua i.ia.aiiu oi.aa-
eai.aneie aayoaeuiinoe: aaaaiey aieoiaioia, eiio.iey ca en-
iieiaieai i.eeacia e a..
2 4 Eioaa.e.iaaiiue iaeao
Приветствую! В вашем случае есть масса вариантов. Это может быть и версия ридеров и офиса не подходит, и кодировка кривая или вообще файл защищен от копирования. Сложно что-то сказать-сделать когда файла перед глазами нет. Свяжитесь со мной по почте. Постараюсь помочь.
Скажите пожалуйста, я правильно понял если в документе установлен запрет на копирование, то я ничего сделать не смогу кроме как распознавать платной программой?
Да, правильно. Можно попробовать сломать, но проще распознать. Fine Reader имеет 30 дневный доступ бесплатный, думаю этого должно хватить чтобы распознать несколько файлов
добрый день, подскажите пожалуйста как Вы сделали такой вид статей? Или это так и было уже в готовом виде шаблона?
Добрый день! В принципе все было в шаблоне, я только немного допили. Хотел уточнить: а какой такой вид?
Пробуйте изменить шрифт, скорее всего в документе используется шрифт, который не поддерживает кириллицу.
Можно с легкостью скопировать содержимое файла PDF если автор документа не применил настройки защиты, запрещающие возможность копирования. Если требуется скопировать большое количество информации из файла PDF, можно легко экспортировать документ PDF в формат Word, Excel или PowerPoint.

Быстро преобразовывайте файлы PDF в Word онлайн

Быстро преобразовывайте файлы PDF в Excel онлайн
Убедитесь, что копирование содержимого разрешено
Нажмите правой кнопкой мыши на документ и выберите Свойства документа.
Нажмите вкладку Защита и просмотрите пункт Сводка по ограничениям документа.
Копирование определенного содержимого из документа PDF
Правой кнопкой мыши нажмите на документ и выберите Выбрать инструмент из всплывающего меню.
Перетащите для выделения текста или нажмите для выделения изображения.
Правой кнопкой мыши нажмите на выделенный элемент и нажмите Копировать.
Копирование документа PDF полностью (только для приложения Windows Reader DC, недоступно для браузера)
Выберите Редактирование > Копировать файл в буфер обмена.
Инструмент Снимок используется для копирования фрагмента в качестве изображения, которое можно вставить в другие приложения.
Выберите Редактирование > Сделать снимок..
Перетащите прямоугольник в пределах области для копирования и отпустите кнопку мыши.
Нажмите клавишу Esc для выхода из режима Снимок.
В другом приложении выберите Редактирование > Вставить, чтобы вставить скопированное изображение.

Недавно столкнулся с задачей: научиться вытаскивать текст из PDF запоминая его позицию на странице. И, конечно же, в несложной поначалу задаче вылезли подводные камни. Как же в итоге получилось это решить? Ответ под катом.
Немного о PDF формате
PDF (Portable Document Format) — популярный межплатформенный формат документов, использующий язык PostScript. Основное его предназначение — корректное отображение на различных операционных системах и т. д.
- слова могут быть нелогично разбиты на части. Например отображение слова «алгоритмы» записано, грубо говоря, тремя частями: отобрази «алг» «орит» «мы»
- строчки в тексте и слова в строчках могут отображаться совсем не в том порядке, как мы привыкли читать
- в одних документах пробелы задаются явно (т.е. есть команды содержащие ' '), в других — они образуются при помощи того, что соседние слова отображаются друг от друга на некотором расстоянии
Потому желание парсить pdf самостоятельно пропало моментально.
p.s. от всего этого невольно вспомнилась цитата
Тем, кто любит колбасу и уважает закон, лучше не видеть, как делается то и другое
Затем, поигравшись с несколькими библиотеками (pdfminer, pdfbox), я решил остановиться на iText.
Немного про iText
Простой способ вытащить текст из PDF
Вот этот код неплохо извлекает текст из PDF, но не предоставляет какой-либо информации, о его расположении в документе.
А теперь разберемся во всем по порядку.
PdfReader — класс, читающий PDF. Умеет конструироваться не только от имени файла, но и от InputStream, Url или RandomAccessFileOrArray.
TextExtractionStrategy — интерфейс, определяющий стратегию извлечения текста. Подробнее о нем — ниже.
SimpleTextExtractionStrategy — класс, реализующий TextExtractionStrategy. Несмотря на название, очень неплохо вытаскивает текст из PDF (справляется с переменчивой структурой PDF, а именно, если сначала текст идет в двух колонках, а затем переключается на обычное написание во всю страницу.
PdfTextExtractor — статический класс, содержащий лишь 2 метода getTextFromPage с одной разницей — указываем мы явно стратегию извлечения текста или нет.
Вытаскиваем текст, запоминая координаты
Для этого нам нужно обратить внимание на интерфейс TextExtractionStrategy. А именно на эти две функции:
— при вызове getTextFromPage эта функция вызывается при каждой команде, отображающей текст. В TextRenderInfo хранится вся необходимая информация: текст, шрифт, координаты.
— эта функция вызывается перед окончанием getTextFromPage и ее результат вернется пользователю.
В качестве образца, научимся простейшим образом вытаскивать пары вида <y-координата строки, текст строки> для каждой строки на странице.
А основной код выглядит так:
Примечания
Конечно, для хорошего извлечения текста надо добавить всякие фишки для корректной обработки текста в нескольких колонках, обработки пробелов не заданных явно и т.д., но я не хочу в пределах этой статьи углубляться в такие детали.
И еще хотелось бы отметить, что это лишь малая часть возможностей библиотеки. При помощи нее можно создавать документы, добавлять текст и изображения в уже существующие (включая водяные знаки).
Читайте также: