
Как вызвать процедуру oracle связанного в виду библиотеки ora из кода sas
Обновлено: 16.07.2024
Хотел написать ETL на получение данных из Oracle в SAS.
Выгрузку делаю с помощью SAS SQL, но столкнулся с проблемой, SAS не позволяет работать с конструкцией вида
START WITH . CONNECT BY .
Селект в скобках передается и выполняется в Oracle. Поэтому можно использовать любые конструкции Oracle SQL, включая START WITH . CONNECT BY.
| alex1610 |
|---|
| Спасибо, а есть вообще какие-нибудь рекомендации когда целесообразно использовать SAS SQL, а когда DATA STEP в SAS BASE при извлечении информации из СУБД? |
Собственно Олег это вам и посоветовал. Единственно, что для вашего требования надо добавить в его пример это create table <libname.tablename> as, чтобы результат того, что наколбасил Oracle, получить в виде набора данных SAS.
Чистый SAS/SQL действительно ограничен и "тормознут" (SAS оптимизирует запросы по своим собственным правилам), поэтому при работе с таблицами SAS его надо использовать как можно меньше, для выгрузки из СУБД в связке с SAS/ACCESS использовать вполне можно и нужно, т.к. с SAS/ACCESS можно давать стране угля.
Практически это тоже самое, но реализуется через LIBNAME statement, без необходимости писать proc sql для Pass-Through Facility.
имеется группа исполнителей и набор фактов, в котором указано на сколько то или иное конкретное лицо уложилось в срок выполнения своей работы или просрочило ее. Необходимо посчитать риски по доверии той или иной работы отдельному исполнителю.
Где можно почитать о решении на Base SAS этой задачи? я так понял данный отчет строится на основе компонента SAS Risk management, но опять таки, никакой документации с примерами не нашел.
имеется группа исполнителей и набор фактов, в котором указано на сколько то или иное конкретное лицо уложилось в срок выполнения своей работы или просрочило ее. Необходимо посчитать риски по доверии той или иной работы отдельному исполнителю.
Где можно почитать о решении на Base SAS этой задачи? я так понял данный отчет строится на основе компонента SAS Risk management, но опять таки, никакой документации с примерами не нашел.
имеется группа исполнителей и набор фактов, в котором указано на сколько то или иное конкретное лицо уложилось в срок выполнения своей работы или просрочило ее. Необходимо посчитать риски по доверии той или иной работы отдельному исполнителю.
Где можно почитать о решении на Base SAS этой задачи? я так понял данный отчет строится на основе компонента SAS Risk management, но опять таки, никакой документации с примерами не нашел.
Начнем с SAS Risk Management. Это не компонент, а продукт включающий в себя методологию и кастамизированое решение (а точней различные решения для разных предметных областей) с использованием платформы SAS (решение это обычно допиливают). Стоит оно отдельных денег и содержит уже ряд отчетов и доки, но судя по тому что Вы не знаете как строить отчет у Вас этого продукта нет. Туту собственно есть два варианта поидти и купить (что ради одного очета глупо) или реализовать это самому с использованием компонентов платформы SAS, которые у вас уже есть. Я вижу тут следующий подход:
1) Готовите табличку с данными для отчета, например с помощью написание скрипта на SAS/BASE. Для расчета рисков воспользуйтесь внешней или внутреней методологией. Конечно есть некая методология в SAS Risk Management, но это стоит денег, да и реализовать на SAS/BASE можно что угодно, а не обязательно конкретную методологию от SAS.
2) На основе таблички делаете инфокарту или, если надо, куб, а на кубе инфокарту (необходимо SAS Information Map Studio).
3) На инфокарте делаете отчет (необходимо SAS Web Report Studio).
При такой установке на сервере устанавливается SAS Management Console - АРМ администратора SAS, через который настраиваются все службы SAS на сервере, включая Metadata Server. У меня дома и на работе служба Metadata Server работает через порт 8561.
Чтобы проверить запущена ли эта служба на вашем компьютере зайдите в Панель управления -> Администрирование -> Службы.
Создаю Socket cervice:
Start Interactively завершается успешно SASAppServ 5001 запускается. Лог чистый.
Choose the path for the /sasweb URL:
C:\SAS\intrnet\SasWeb
Choose the path for the CGI executables:
C:\SAS\intrnet\executables
где C:\SAS\intrnet\SasWeb и C:\SAS\intrnet\executables пустые директории на диске
Да, еще в файле broker.cfg пробовал менять
в логе " You are trying to use the numeric format EURDFDDW with the character variable mydate."
тоже ничем хорошим не закончилось
в логе " You are trying to use the numeric format EURDFDDW with the character variable mydate."
тоже ничем хорошим не закончилось
Ну во-первых, вы используете некий format EURDFDDw., а для input надо использовать informat. Во-вторых, вместо w надо видимо подставлять длину ввиде цифры.
Ладно это была лирика, а теперь по существу. Если надо преобразовать строку вида 15.05.2012 в дату формата 15052012, я бы сделал так:
где mydate - строковое поле длиной 10 с записью вида 15.05.2012
newdate - числовое поле длиной 8 с датой в формате 15052012
DDMMYY10. - стандартный informat DDMMYYw.
DDMMYYn8. - стандартный format DDMMYYxw.
Для начала нужно убедиться, что в вашу лицензию входит компонент SAS/ACCESS Interface to Oracle (сделать это можно запустив proc setinit; и убедиться что в перечне компонент есть описанный выше см предыдущий пост).
Есть несколько способов соединения:

В таком случае можно обращаться к таблицам oracle следующими способами:


Хочется отметь, что второй вариант более подходит для людей который изначально привыкли писать SQL запросы.
В следующем посте рассмотрим альтернативный способ соединения с БД Oracle.
SAS connect to Oracle. Part 2. Pass-Through.
Мы уже рассмотрели способ соединения с Oracle по средством libname.
Теперь рассмотрим способ Pass-Through или еще такой способ называют push down.
В данном случае выполняемый код "проваливается в базу данных" и обратно возвращается результат запроса.

Прошу обратить внимание, что время выгрузки идентично примерам из предыдущего поста и составляет чуть меньше 10 секунд.
А теперь добавим еще один параметр readbuff=100000 в строку соединения и получим:

И лога видно, что время выгрузки меньше 5 секунд на 1 миллион записей. В принципе с этим параметром можно поиграть, но при такой конструкции про него лучше не забывать.
SAS connect to Oracle. Part 3. BULKLOAD.
В предыдущих примерах мы рассматривали задачу загрузки данных из Oracle в SAS.
Теперь же давай попробуем из положить из SAS в Oracle.

В данном примере мы видим, что время выгрузки данных в Oracle существенно больше чем время загрузки, а именно более 2-х минут против 10 секунд загрузки.

Здесь также видим превышение 2-х минут.
3. Proc sql + BULKLOAD

В данном примере мы использовали опцию BULKLOAD и время выгрузки уменьшилось с более чем 2-х минут до 11 секунд.
P.S. Для работы параметра BULKLOAD вам необходимо чтобы стоял полный клиент Oracle, а именно в директории Oracle_HOME\\product\11.2.0\client_1\BIN находился файл: sqlldr.exe.
У меня изначально была поставлена легкая версия клиента и этот файл отсутствовал. Пришлось переставлять клиента.
SAS connect to Oracle. Part 4. Hints.
Всем добрый день.
Сегодня рассмотрим задачу использования Oracle Hints при обращении к БД Oracle из SAS.
Для этого вам потребуется всего лишь в строку соединения добавить следующие слова:
preserve_comments
А теперь рассмотрим примеры:
Пример довольно простой - мы хотим узнать сколько строк в некой таблице Oracle
1. Вариант (без preserve_comments)

Прошу обратить внимание на Log данного запроса из которого видно, что наш parallel hint был вычеркнут из запроса.
2. Вариант (c preserve_comments)

А в этом варианте видно, что выражение с hint дошло до oracle именно в том виде в котором мы написали.
Для получения подробных логов необходимо использовать подключение следующих опций:

Однако хочу предостеречь от постоянного использования данной опции, т.к. сильно раздуваются лог файлы.
Использовать данную опцию стоит лишь на этапе отладки кода. В дальнейшем ее нужно отключать.
Также данную опцию часто просят включать в службе поддержки SAS для предоставлении более детальных логов в случае возникновения вопросов(ошибок) связанных с взаимодействием с внешними базами данных.
Однако макроциклы не являются единственными инструментами для разработки программ, управляемых данными.
Один из таких инструментов — процедура CALL EXECUTE. Процедура CALL EXECUTE принимает единственный аргумент, который является символьной строкой или символьным выражением. Символьное выражение обычно представляет собой объединение строк, содержащих элементы кода SAS, которые должны быть выполнены после их разрешения. Выражение аргумента может включать символьные константы, переменные шага данных, ссылки на макропеременные, а также ссылки на макросы. Процедура CALL EXECUTE динамически создает код SAS во время итераций шага DATA. Этот код выполняется после завершения шага DATA. Это позволяет превратить шаг DATA, который выполняет итерации в таблице драйверов, в эффективный генератор кода SAS, который аналогичен генератору макросов SAS.
Однако довольно своеобразные правила разрешения аргументов процедуры CALL EXECUTE могут затруднить ее использование. Давайте проясним этот вопрос.
Строка аргумента не имеет ссылки на макрос или макропеременную
Если строка аргумента для процедуры CALL EXECUTE содержит код SAS без ссылок на макросы и макропеременные, этот код просто извлекается из текущего шага DATA и добавляется в очередь после текущего шага DATA. По мере того, как выполняется шаг DATA, код добавляется к очереди столько раз, сколько итераций шага DATA выполняется. После завершения этапа DATA код в очереди выполняется в порядке его создания.
Преимущество этой модели заключается в том, что строка аргумента может представлять собой объединение символьных констант (в одиночных или двойных кавычках) и переменных SAS, которые заменяются их значениями при вызове процедуры CALL EXECUTE для каждой итерации шага DATA. Это приводит к созданию динамически генерируемого кода SAS, точно так же, как в итеративном макроцикле SAS.
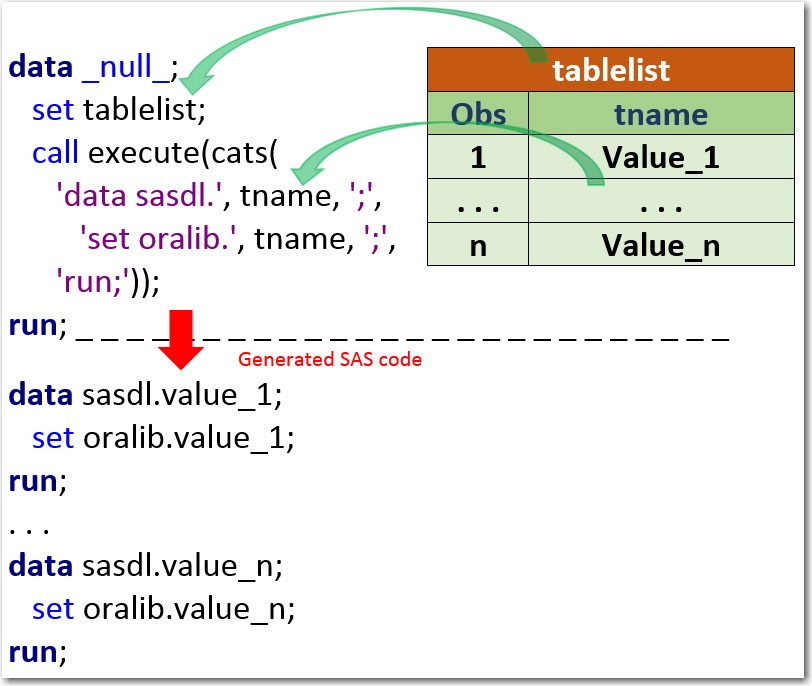
Рассмотрим следующий пример. Предположим, что нам нужно загрузить несколько таблиц Oracle в таблицы SAS.
Шаг 1. Создание таблицы драйверов
Чтобы наш процесс стал процессом, управляемым данными, давайте создадим таблицу драйверов, содержащую список имен таблиц, которые необходимо извлечь и загрузить:
Эта программа запускается только один раз и создает таблицу драйверов parmdl.tablelist.
Шаг 2. Загрузка нескольких таблиц
Затем вы можете использовать следующую программу, управляемую данными, которая запускается каждый раз, когда вам нужно перезагрузить таблицы Oracle в SAS:
Чтобы объединить компоненты аргумента CALL EXECUTE, я использовал функцию cats (), которая возвращает объединенную строку без начального и завершающего пробелов.
При запуске этой программы после шага данных _null_ добавляются и выполняются следующие операторы (данные получены из журнала SAS):
В этом примере мы используем шаг _null_ для обработки списка таблиц (parmdl.tablelist). Для каждого значения столбца tname создается новый шаг данных. Этот шаг данных выполняется после шага данных _null_. Этот процесс показан на следующей схеме:
Строка аргумента содержит ссылку на макропеременную в двойных кавычках
Если аргумент CALL EXECUTE содержит ссылки на макропеременные в двойных кавычках, эти ссылки будут разрешены предварительным обработчиком макросов SAS во время компиляции шага DATA. Ничего необычного. Например, следующий код будет выполняться точно так же, как указано выше, и ссылки на макропеременные &olib и &slib будут разрешены в oralib и sasdl соответственно:
Строка аргумента содержит ссылку на макрос или макропеременную в одинарных кавычках
Здесь начинается интересное. Если аргумент процедуры CALL EXECUTE содержит ссылку на макрос или макропеременную в одинарных кавычках, этот аргумент все равно будет разрешен до того как код будет извлечен из шага DATA. Однако это извлечение выполняется не обработчиком макросов во время компиляции шага DATA, как для двойных кавычек. Ссылки на макросы или макропеременные в одинарных кавычках разрешаются самой процедурой CALL EXECUTE. Например, следующий код будет выполняться точно так же, как указано выше, и ссылки на макропеременные &olib и &slib будут разрешены процедурой CALL EXECUTE:
Соображения, касающиеся синхронизации
ВНИМАНИЕ: Если ваш макрос содержит некоторые конструкции, не связанные с макросом, для присваивания макропеременных во время выполнения — например, CALL SYMPUT или SYMPUTX (на шаге DATA) или предложение INTO (в PROC SQL) — то разрешение ссылок на эти макропеременные процедурой CALL EXECUTE произойдет слишком рано, прежде чем будет извлечен и выполнен сгенерированный макросом код. Это приведет к неразрешенным макропеременным. Давайте запустим следующий код, который извлекает таблицы Oracle в таблицы SAS, как указано выше, а также изменяет положения столбцов по названиям столбцов в алфавитном порядке:
Как и ожидалось, в журнале SAS появятся неразрешенные ссылки на макропеременные:
РЕШЕНИЕ: Чтобы избежать проблем с синхронизацией, когда ссылка на макрос разрешается процедурой CALL EXECUTE слишком рано, до того как будут присвоены во время исполнения шагов макросов, мы можем удалить CALL EXECUTE из привилегии разрешения макроса. Чтобы это сделать, можно замаскировать символы & и % с помощью функции макроса %nrstr. При этом процедура CALL EXECUTE "перестает видеть макросы", поэтому она извлечет код макроса без разрешения этого кода. В этом случае разрешение макроса произойдет после шага DATA, в котором находится процедура CALL EXECUTE. Если аргумент CALL EXECUTE вызывает макрос, то можно включить его в функцию макроса %nrstr. Следующий код будет работать корректно:
При выполнении этого шага DATA добавляются и выполняются следующие операторы (данные получены из журнала SAS):
Параметр CALL EXECUTE — переменная SAS
Аргумент процедуры CALL EXECUTE необязательно должен быть символьной константой или включать символьную константу. Он может представлять собой переменную SAS, точнее, символьную переменную. В этом случае поведение процедуры CALL EXECUTE аналогично поведению для аргументов в одинарных кавычках. Это означает, что если ссылка на макрос является частью значения аргумента, ее нужно замаскировать, используя макрофункцию %nrstr(), чтобы избежать упомянутой выше проблемы с синхронизацией.
В этом случае аргумент CALL EXECUTE может выглядеть следующим образом:
Делаем процедуру CALL EXECUTE полностью управляемой данными
В приведенных выше примерах мы использовали драйвер таблиц tablelist для получения значений одного параметра макроса для каждой итерации шага данных. Однако таблицу драйверов можно использовать не только для динамического присвоения значений одному или нескольким параметрам макроса, но и для управления тем, какой макрос будет выполняться на каждой итерации шага данных. На следующей схеме показана программа SAS, полностью управляемая данными:

Заключение
CALL EXECUTE — мощный инструмент для разработки приложений SAS, управляемых данными. Надеюсь, из этой статьи вы поняли, как избежать недостатков этого инструмента и эффективно использовать его для своих целей. Я буду рад вашим комментариям и хотел бы услышать ваши впечатления от использования процедуры CALL EXECUTE.
В предыдущей статье мы познакомились с интерфейсом SAS UE, терминологией SAS Base, типами данных, основными требованиях к синтаксису SAS Base, а также рассмотрели распространенные синтаксические ошибки.
Сегодня я расскажу, как можно получить доступ к данным различных форматов. Обратите внимание, что в данной статье имеются ссылки на документацию, которая поможет вам подробнее ознакомиться с рассматриваемыми примерами.

Что такое библиотеки SAS?
Библиотека в SAS – это метод централизованного хранения и прозрачного использования данных в программах SAS. Библиотека может быть папкой или каталогом на вашем компьютере или располагаться на внешнем жестком диске, FLASH-накопителе или компакт-диске и так далее.
Существует два типа библиотек: постоянные и временные. Постоянные библиотеки SAS сохраняются до тех пор, пока вы их не удалите. Постоянная библиотека доступна для обработки в последующих сеансах SAS. Временная библиотека SAS существует только для текущего сеанса SAS.
Файлы SAS, созданные во время сеанса, хранятся в специальном рабочем пространстве, которое может быть или не быть внешним носителем. Это рабочее пространство обычно назначается по умолчанию с именем Work. Файлы во временной рабочей библиотеке могут использоваться на любом шаге в программе SAS, но они не доступны для последующих сессий SAS. Файлы, хранящиеся в рабочей библиотеке, удаляются в конце сеанса SAS.
Назначаем пользовательскую библиотеку.
Рассмотрим простой случай назначения библиотеки: наборы данных SAS находятся в одной директории c:\habrahabr. Есть два способа решения этой задачи.
1 способ:
Настроить библиотеку без программного кода. Во вкладке «Библиотеки» в SAS UE выбрать «Новая библиотека»:

Далее появится окно для настройки пользовательской библиотеки:

Имя библиотеки – library reference (или libref). Libref – это «псевдоним» (ссылка) для «хранилища», в котором находятся файлы. Название библиотеке задается в соответствии с правилами именования переменных в SAS (см. Урок 1), но на него выделяется не более 8 символов.
Правила именования библиотек, переменных, наборов данных и пр. в SAS можно изучить в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation SAS Language Reference: Concepts в разделе Names in the SAS Language.
Обратите внимание, что библиотека назначена на все время сеанса SAS, но переопределять ее параметры можно.
Далее задаем путь к наборам данных SAS.

После назначения библиотеки она появляется в левой панели SAS UE.

2 способ:
Назначить библиотеку программным путем. Назначение библиотеки SAS реализуется с помощью глобального оператора LIBNAME. Информацию по указанному оператору можно изучить в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation / Global Statements.
Рассмотрим общий синтаксис глобального оператора LIBNAME.
libref – имя библиотеки.
engine — имя «движка», например, для наборов данных SAS – это BASE (но его можно не указывать, он задан по умолчанию). Если вы хотите создать новую библиотеку с другим «движком», отличным от механизма по умолчанию, вы можете отменить автоматический выбор.
Справочники, которые могут вам пригодиться при изучении механизмов подключения: SAS/ACCESS for Relational Databases и SAS Engines.
«Движки» SAS/ACCESS являются механизмами оператора LIBNAME, которые обеспечивают доступ к чтению, записи и обновлению более чем 60 реляционных и нереляционных баз данных, файлов ПК, устройств хранения данных и распределенных файловых систем.
'SAS-library' – путь к библиотеке, если путь задается с помощью макропеременной (будет рассматриваться в данном цикле статей), используются парные двойные кавычки. Во всех остальных случаях можно использовать парные одинарные кавычки.
options — допустимые опции. Простейшим примером является опция ACCSESS=READONLY, которая назначает атрибут «только для чтения» для всей библиотеки SAS. Со всем перечнем допустимых опций можно ознакомиться в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation /Global Statements.
engine/host-options — являются одним или несколькими параметрами, которые перечислены в общей форме keyword = value.
Рассмотрим синтаксис оператора LIBNAME на практике. Назначим библиотеку Habr только для чтения:
Запустим код и проверим Log:

Просматриваем содержимое библиотеки SAS.
Один из вариантов просмотра содержимого библиотеки – использование процедуры PROC CONTENTS. Ознакомиться с процедурами, используемыми в SAS, можно в справочнике SAS 9.4 Procedures by Name and Product.
Процедура PROC CONTENTS позволяет создавать вывод, который описывает либо содержимое библиотеки SAS, либо информацию дескриптора для отдельного набора данных SAS. Чтобы просмотреть содержимое библиотеки SAS, мы можем использовать следующую общую форму процедуры:
Параметр NODS (который означает «no details») подавляет печать подробной информации о каждом файле при указании опции _ALL_.
Для конкретной библиотеки код будет выглядеть следующим образом:
Фрагмент вывода процедуры:

Обратите внимание, что в библиотеке также хранятся другие типы файлов, например catalog, index. О них можно прочитать в справочнике SAS 9.4 Companion for Windows, Fifth Edition.
Файлы с member type DATA являются стандартными наборами данных SAS. Второй вариант просмотра содержимого библиотеки – использовать процедуру PROC DATASETS:
Просмотр информации о конкретном наборе данных SAS реализуется следующим образом:
Обратите внимание на обращение к таблице в пользовательской библиотеке. Имя после data= двухуровневое: имя_библиотеки.имя_таблицы. В случае набора данных, хранящемся во временной библиотеке WORK, в обращении после data= можно использовать одноуровневое имя.
Например, в случае кода:
выведется информация о наборе данных charities, находящемся во временной библиотеке WORK.
Рассмотрим вывод процедуры для набора данных charities в пользовательской библиотеке HABR:

Служебная информация о таблице, получаемая в результате вывода, называется дескриптором.
Дескриптор содежит общую информацию о наборе данных: его название и имя библиотеки, типе, «движке», дате и времени создания и последнего изменения, количестве наблюдений и переменных, общей длине наблюдений, индексах, сортировке, сжатии, размере страницы и их количестве, информацию об атрибутах переменных.
Читаем электронные таблицы.
Чтение файла EXCEL можно реализовать несколькими способами. В этой статье мы рассмотрим назначение библиотеки для файла excel.
Для назначения библиотеки SAS будем использовать электронную таблицу products.xlsx, хранящуюся в директории c:\workshop\habrahabr\products.xlsx. Данный документ выглядит следующим образом: он содержит 4 листа, каждый из которых станет отдельным набором данных SAS. Фрагмент данного документа представлен ниже:

Общий синтаксис назначения библиотеки такой же, как и в случае наборов данных SAS, меняется только механизм подключения:
Существует несколько механизмов для обработки файла excel, у всех свои особенности и настройки, с которыми можно ознакомиться в документации.
Результат выполнения оператора libname представлены ниже. Фрагмент Log:

Информацию о библиотеке посмотрим через процедуру PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Результат выполнения оператора LIBNAME представлены ниже. Фрагмент Log:

Информацию о библиотеке посмотрим через PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Результат выполнения оператора libname представлены ниже.

Информацию о библиотеке посмотрим через PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Создаем детализированные отчеты.
После получения доступа к требуемым данным рассмотрим процедуру для создания отчетов PROC PRINT. Подробную информацию о ней можно получить в справочнике SAS 9.4 Procedures by Name and Product. Распечатаем детализированный отчет, используя таблицу German из системной библиотеки sasuser.
Для начала изучим дескриптор указанной таблицы, нас интересуют атрибуты столбцов:
Фрагмент вывода процедуры:

Создадим детализированный отчет, удовлетворяющий представленным ниже требованиям:
-
Не включайте переменные Change и Retain в отчет:
Оператор VAR определяет переменные для печати. Оператор выводит их в том порядке, в котором вы их перечислили.

В данном условии нам необходимо использовать фильтр в операторе WHERE.
Обратите внимание, что при работе с текстовыми переменными важен регистр, а также вы обязательно заключаете требуемое значение в парные кавычки (двойные или одинарные).
Вывод данной программы SAS:

По умолчанию процедура PROC PRINT выводит номера строк, для того, чтобы убрать данный столбец, можно использовать опцию NOOBS (‘no observation’). В этом случае программный код выглядит следующим образом:
Операторы сравнения вы можете записывать привычными символами, а можете использовать мнемоники, как представлено в примере. Вывод данной программы представлен ниже:

Идентификатором наблюдения можно определить любую переменную. Когда вы указываете одну или несколько переменных в операторе ID, он использует форматированные значения этих переменных для идентификации строк. Обратите внимание, что если одновременно переменная указана в операторе VAR и в операторе ID, то она выведется два раза. Также при использовании оператора ID нет необходимости в опции NOOBS.
В нашем случае программа SAS будет иметь следующий вид:
Результаты выполнения кода представлены ниже:

Стоит отметить, что при задании атрибутов таких как ярлык и формат, они будут использованы только на определенном шаге PROC для создания требуемого отчета.
Для задания ярлыка используется оператор LABEL.
Общий синтаксис оператора LABEL выглядит следующим образом:
В ярлыке вы можете использовать любые символы, в том числе и пробелы, количество символов не должно превышать 256. Ярлыки переменных будут использованы для создания отчетов.
Не все процедуры «видят» ярлыки. Для того, чтобы процедура PROC PRINT выводила в отчет ярлыки, а не имена переменных, в опциях необходимо указать label (или split=). Опция SPLIT указывает разделитель, который контролирует разрывы в заголовках столбцов. Используем оператор LABEL в нашем программном коде:
1 вариант

2 вариант
(с использованием опции split=)
В опции split= указывается разделитель (обязательно в кавычках). Код в данном случае выглядит следующим образом (обратите внимание на использование разделителей в операторе Label):

Оператор TITLE задает заголовок в отчете, оператор FOOTNOTE задает нижний колонтитул.
Как и в случае оператора LIBNAME, данные операторы являются глобальными и действуют во время всего сеанса SAS до тех пор, пока вы не переопределите их значения. Вы можете использовать TITLE и FOOTNOTE как вне шагов PROC, так и непосредственно в них.
Общий синтаксис операторов:
Text-string – данный аргумент является строкой, которая может содержать до 512 символов. Вам необходимо заключать такие строки в одиночные или двойные кавычки. Текст отображается точно так же, как вы вводите его в операторе, включая прописные, строчные буквы и пробелы.
Также для настройки заголовков и нижних колонтитулов можно использовать стили:

Итак, возвращаясь к разрабатываемому отчету:
Результат выполнения программы:

Формат – это правило вывода значений переменных в отчет. Необходимо понимать, что формат не меняет значения в наборе данных SAS. Типы форматов соответствуют типу данных, но разбиты на категории: числовые, символьные, даты, время, дата-время.
Всю информацию о форматах можно найти в справочнике SAS 9.4 Formats and Informats: Reference. Также поддерживается возможность создания пользовательских форматов, об этом мы поговорим в следующих статьях.
Общий синтаксис оператора FORMAT.
variable – одна или несколько переменных, к которым небходимо применить формат.
DEFAULT=default-format – определяет временный формат по умолчанию для отображения значений переменных, которые не указаны в операторе FORMAT, используется в шаге DATA.
format – определяет формат, который используется для отображения переменных.
Общий синтаксис использованиея формата в операторе FORMAT следующий:
$ — признак текстового формата
Format – название формата
w — ширина формата, количество всех выводимых символов в значении
d — количество десятичных знаков
Формат всегда оканчивается на точку или на количество десятичных знаков. Стоит отметить, что при неверном выборе ширины формата значения в выводе могут «обрезаться». Давайте рассмотрим пример:
| Значение переменной | Формат | Результат |
|---|---|---|
| 34566.78 | DOLLAR10.2 | $34,566.78 |
| 34566.78 | DOLLAR9.2 | $34566.78 |
| 34566.78 | DOLLAR8.2 | 34566.78 |
| 34566.78 | DOLLAR7.2 | 34566.8 |
| 34566.78 | DOLLAR6.2 | 34567 |
| 34566.78 | DOLLAR4.2 | 35E3 |
При этом значение в наборе данных SAS остается неизменным:
Результат выполнения шага:

Отчет выглядит следующим образом:

Для группировки переменных используется оператор BY. Группировка переменных по определенным значениям подразумевает сортировку таблицы. Это связано с обработкой данных SAS Base.
Отсортировать набор данных можно с помощью процедуры PROC SORT.
При сортировке набора данных вам необходимо указать источник (исходный набор данных), группирующую переменную или переменные, а также при необходимости выходной (промежуточный) набор данных.
Давайте проверим вышеизложенное. Если посмотреть на отчет, выводимый в п.7 данной статьи, столбец Gender отсортирован по полу по убыванию. Так ли это?
Результат выполнения процедуры представлен ниже:

Таким образом, мы получили требуемый детализированный отчет на основании набора German в библиотеке Sasuser.
Исключение возникает, когда механизм PL / SQL встречает инструкцию, которую он не может выполнить из-за ошибки, возникающей во время выполнения. Эти ошибки не будут регистрироваться во время компиляции, и, следовательно, их необходимо обрабатывать только во время выполнения.
Например, если механизм PL / SQL получает инструкцию делить любое число на «0», то механизм PL / SQL выбрасывает его как исключение. Исключение возникает только во время выполнения движком PL / SQL.
Исключения будут препятствовать дальнейшему выполнению программы, поэтому, чтобы избежать такого условия, они должны быть записаны и обработаны отдельно. Этот процесс называется обработкой исключений, при которой программист обрабатывает исключение, которое может возникнуть во время выполнения.
В этом уроке вы изучите следующие темы:
Синтаксис обработки исключений
Приведенный ниже синтаксис объясняет, как перехватить и обработать исключение.

Синтаксис Объяснение:
- В приведенном выше синтаксисе блок обработки исключений содержит последовательность условий WHEN для обработки исключения.
- Каждое условие WHEN сопровождается именем исключения, которое, как ожидается, будет вызвано во время выполнения.
- Когда какое-либо исключение возникает во время выполнения, механизм PL / SQL будет искать в этой части исключение в части обработки исключений. Он будет начинаться с первого предложения WHEN и последовательно будет выполнять поиск.
- Если он обнаружил обработку исключения для возникшего исключения, то он выполнит эту конкретную часть кода обработки.
- Если ни одно из условий «WHEN» не присутствует в исключении, которое было сгенерировано, то механизм PL / SQL выполнит часть «WHEN OTHERS» (если присутствует). Это общее для всех исключений.
- После выполнения исключения управление деталями выйдет из текущего блока.
- Только одна исключительная часть может быть выполнена для блока во время выполнения. После его выполнения контроллер пропустит оставшуюся часть обработки исключений и выйдет из текущего блока.
Примечание: КОГДА ДРУГИЕ должны всегда быть в последней позиции последовательности. Часть обработки исключений, присутствующая после WHEN OTHERS, никогда не будет выполнена, так как элемент управления выйдет из блока после выполнения WHEN OTHERS.
Типы исключений
В Pl / SQL есть два типа исключений.
- Предопределенные исключения
- Пользовательское исключение
Предопределенные исключения
Oracle предопределил некоторые распространенные исключения. Эти исключения имеют уникальное имя исключения и номер ошибки. Эти исключения уже определены в пакете STANDARD в Oracle. В коде мы можем напрямую использовать эти предопределенные имена исключений для их обработки.
Ниже приведены несколько предопределенных исключений
Пользовательское исключение
В Oracle, кроме предопределенных выше исключений, программист может создавать свои собственные исключения и обрабатывать их. Они могут быть созданы на уровне подпрограммы в части объявления. Эти исключения видны только в этой подпрограмме. Исключением, определенным в спецификации пакета, является общедоступное исключение, и оно видно везде, где доступен пакет. <
Синтаксис: на уровне подпрограммы
- В приведенном выше синтаксисе переменная «имя-исключения» определена как тип «ИСКЛЮЧЕНИЕ».
- Это можно использовать аналогично предопределенному исключению.
Синтаксис: на уровне спецификации пакета
- В приведенном выше синтаксисе переменная «имя_исключения» определена как тип «ИСКЛЮЧЕНИЕ» в спецификации пакета <имя_пакета>.
- Это может использоваться в базе данных везде, где может быть вызван пакет «имя_пакета».
PL / SQL повышает исключение
Все предопределенные исключения возникают неявно при возникновении ошибки. Но определенные пользователем исключения должны быть вызваны явно. Это может быть достигнуто с помощью ключевого слова «Поднять». Это может быть использовано любым из способов, указанных ниже.

Синтаксис Объяснение:
- В приведенном выше синтаксисе ключевое слово RAISE используется в блоке обработки исключений.
- Всякий раз, когда программа встречает исключение «имя_исключения», исключение обрабатывается и будет нормально завершено
- Но ключевое слово «RAISE» в части обработки исключений распространит это конкретное исключение в родительскую программу.
Примечание. При возведении исключения в родительский блок возникающее исключение также должно быть видно в родительском блоке, иначе oracle выдаст ошибку.
- Мы можем использовать ключевое слово «RAISE», за которым следует имя исключения, чтобы вызвать это конкретное пользовательское / предопределенное исключение. Это может использоваться как в части исполнения, так и в части обработки исключений, чтобы вызвать исключение.

Синтаксис Объяснение:
- В приведенном выше синтаксисе ключевое слово RAISE используется в части выполнения, за которой следует исключение «имя_исключения».
- Это вызовет это конкретное исключение во время выполнения, и это необходимо обработать или поднять дальше.
Пример 1 : В этом примере мы увидим
- Как объявить исключение
- Как поднять заявленное исключение и
- Как распространить это на основной блок


Объяснение кода:
- Строка кода 2 : объявление переменной «sample_exception» в качестве типа EXCEPTION.
- Строка кода 3 : Объявление процедуры nested_block.
- Строка кода 6 : печать выписки «Внутри вложенного блока».
- Строка кода 7: печать оператора «Повышение sample_exception из вложенного блока».
- Строка кода 8: Вызов исключения с помощью RAISE sample_exception.
- Строка кода 10: обработчик исключений для исключения sample_exception во вложенном блоке.
- Строка кода 11: печать оператора «Исключение, захваченное во вложенном блоке. Подъем к основному блоку ».
- Строка кода 12: Возврат исключения к основному блоку (распространение на основной блок).
- Строка кода 15: печать выписки «Внутри основного блока».
- Строка кода 16: печать оператора «Вызов вложенного блока».
- Строка кода 17: вызов процедуры nested_block.
- Строка кода 19: обработчик исключений для sample_exception в основном блоке.
- Строка кода 20: печать заявления «Исключение зафиксировано в основном блоке».
Важные моменты, на которые следует обратить внимание в исключении
Резюме
После этой главы. Вы должны быть в состоянии работать для следующих аспектов исключений Pl SQL
Читайте также: